July~) • Machine Learing: 1.5 year • Kaggle: 1 year • Kaggle Master • TGS 1st place • iMet 7th place • Petfinder 17th place • HPA 36th place @ZFPhalanx
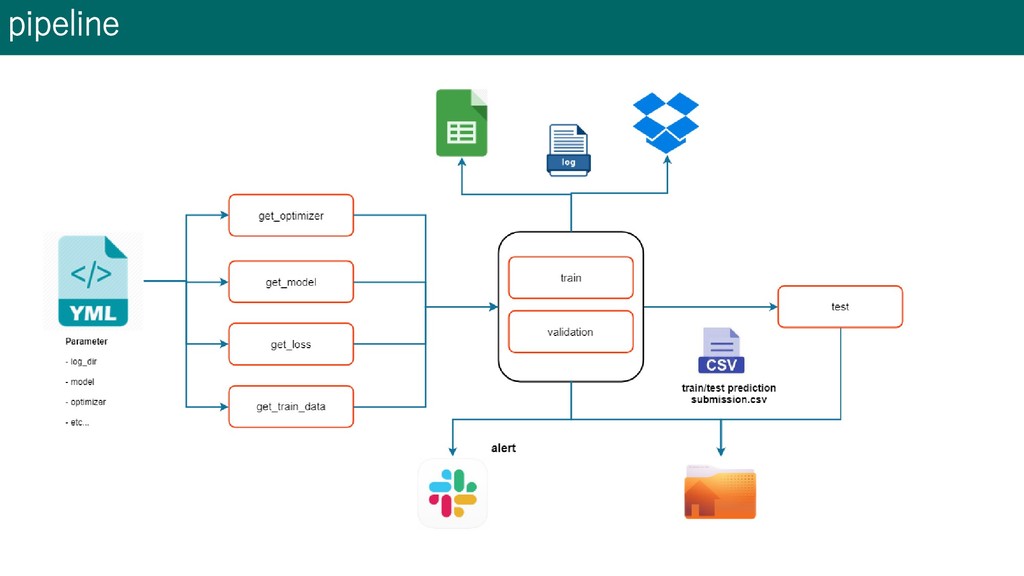
solution • 1st place solution • Summary • My approach to image data competition • Machine resource • pipeline • Approach • Day 1 • Day 2 ~ 2 month • 2 month ~ last day
• Data: artwork from Metropolitan Museum • Task: Multi Label Image Classification • Metric: mean f2 score (calculated by each sample) • 2 stage competition • Kernels-only competition
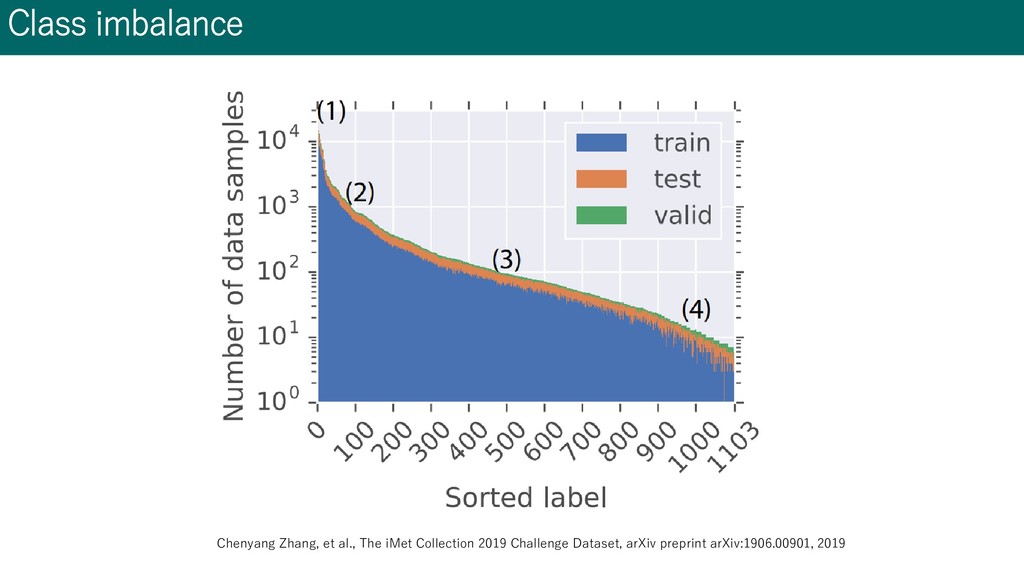
images, 1103 labels • Only one annotator, no verification step Ground truth Tag: landscapes Probably truth Tag: landscapes, Trees, bodies of water, houses
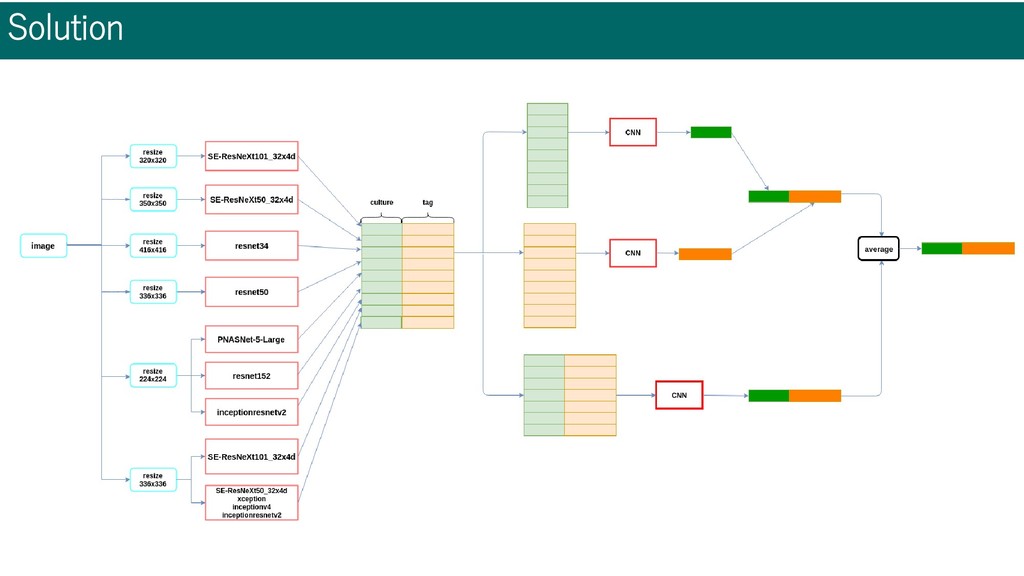
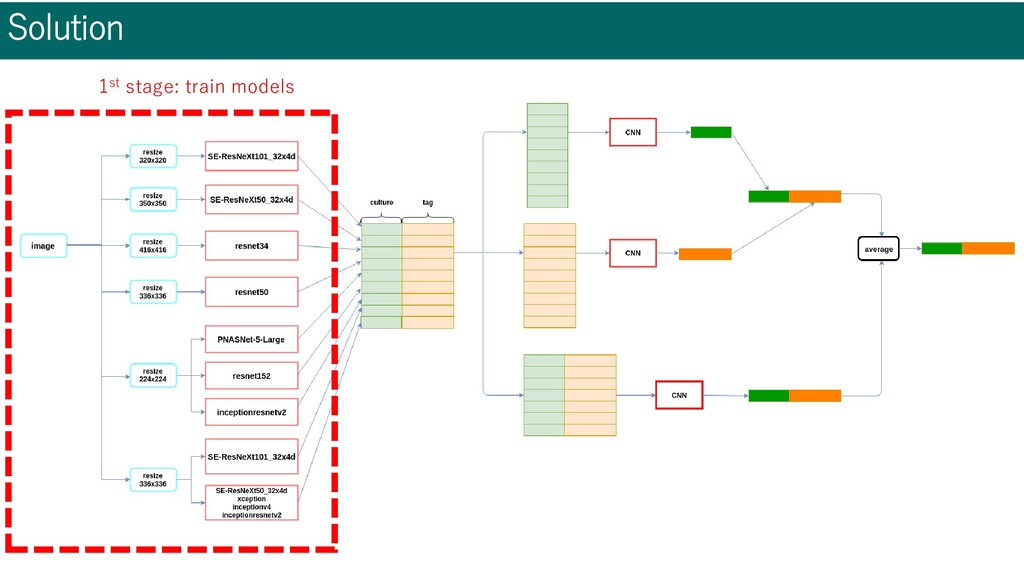
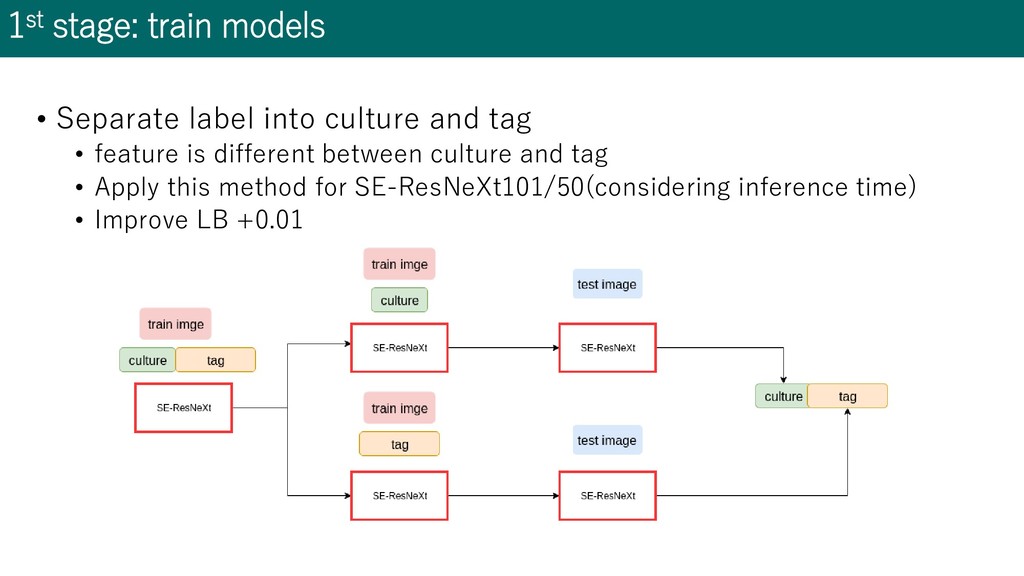
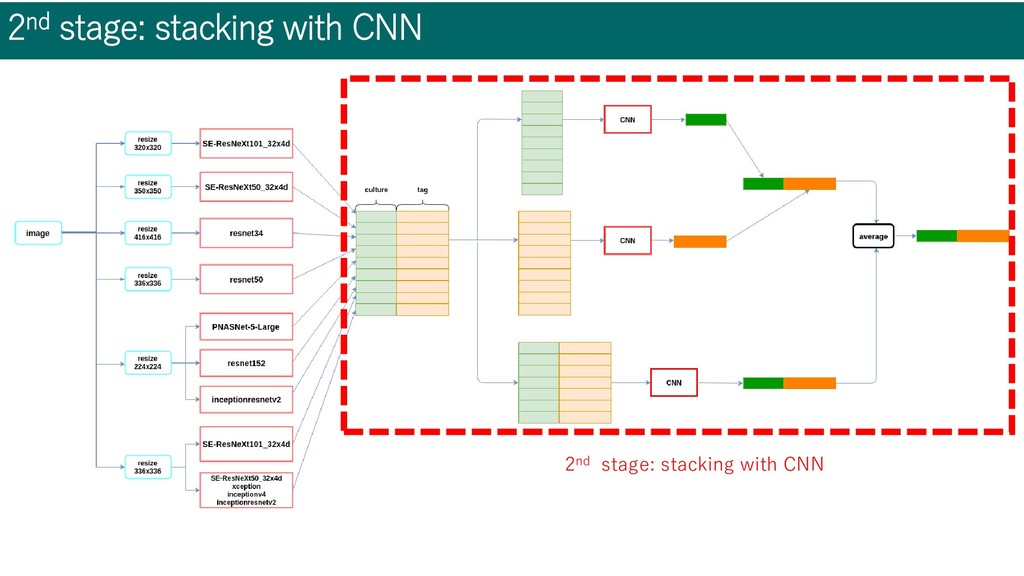
resnet34, PNasNet-5, etc... • Different model have different capability in different labels • Ensemble is effective • Different image size • 224x224, 320x320, 336x336, 350x350, 416x416 • Optimizer: Adam • Augmentation • RandomResizedCrop, Horizontal Flip, Random Erasing
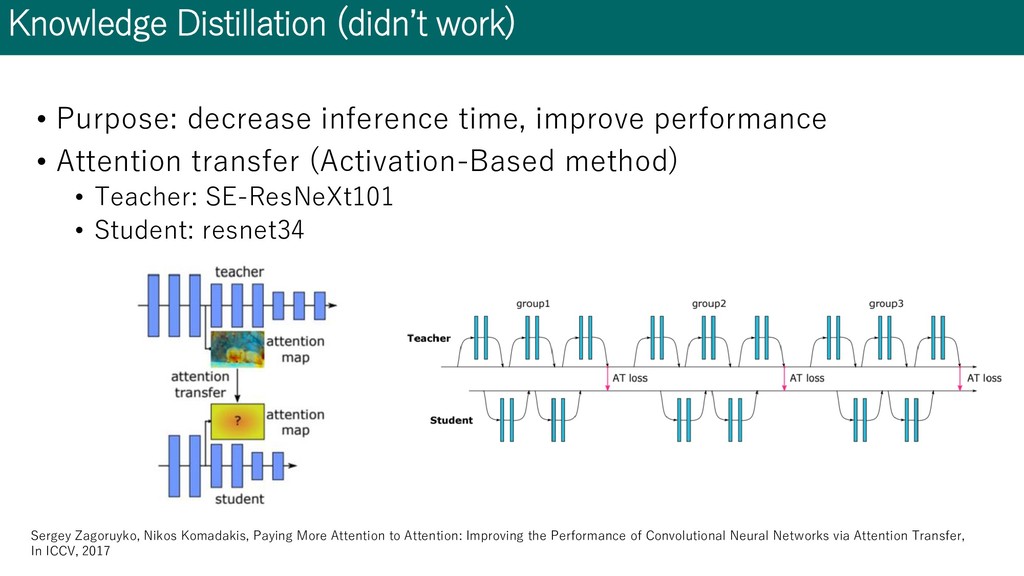
performance • Attention transfer (Activation-Based method) • Teacher: SE-ResNeXt101 • Student: resnet34 Sergey Zagoruyko, Nikos Komadakis, Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer, In ICCV, 2017
• Bit better than binary cross entropy • Drop labels with frequency less than 20(didn’t work) • Metric is calculated by each samples • These classes don’t affect score • Not improve, score is same
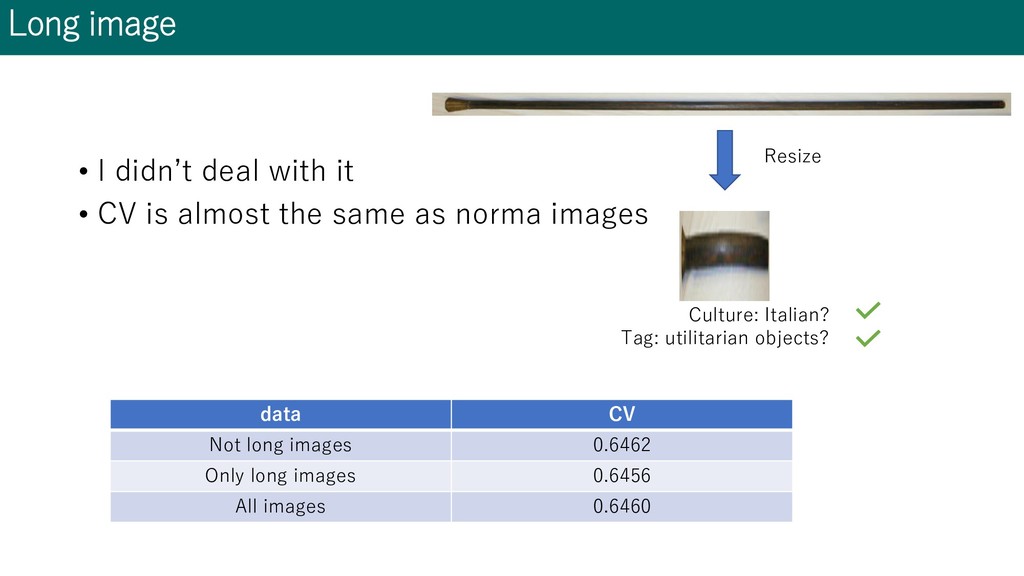
is almost the same as norma images data CV Not long images 0.6462 Only long images 0.6456 All images 0.6460 Culture: Italian? Tag: utilitarian objects? Resize
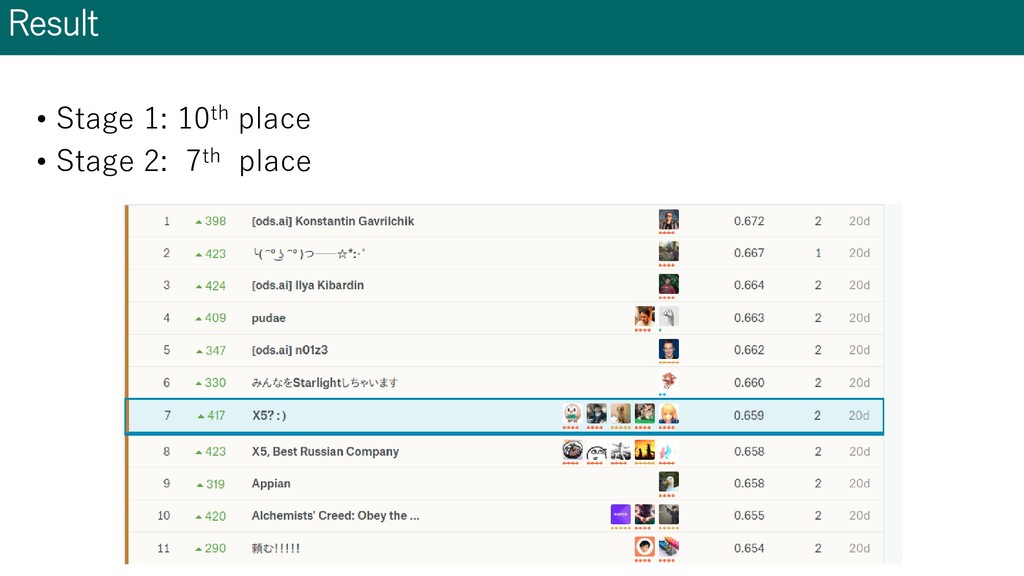
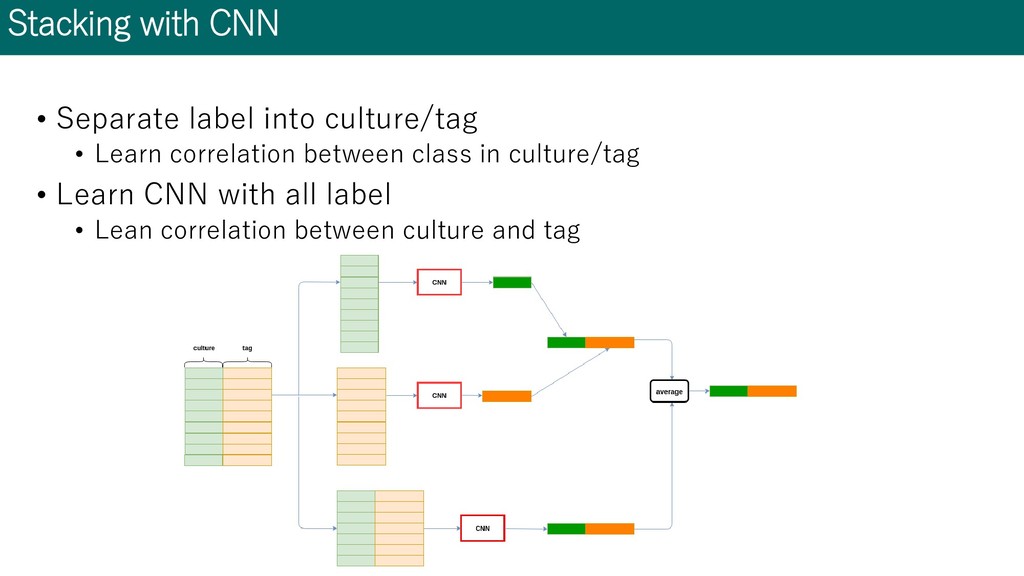
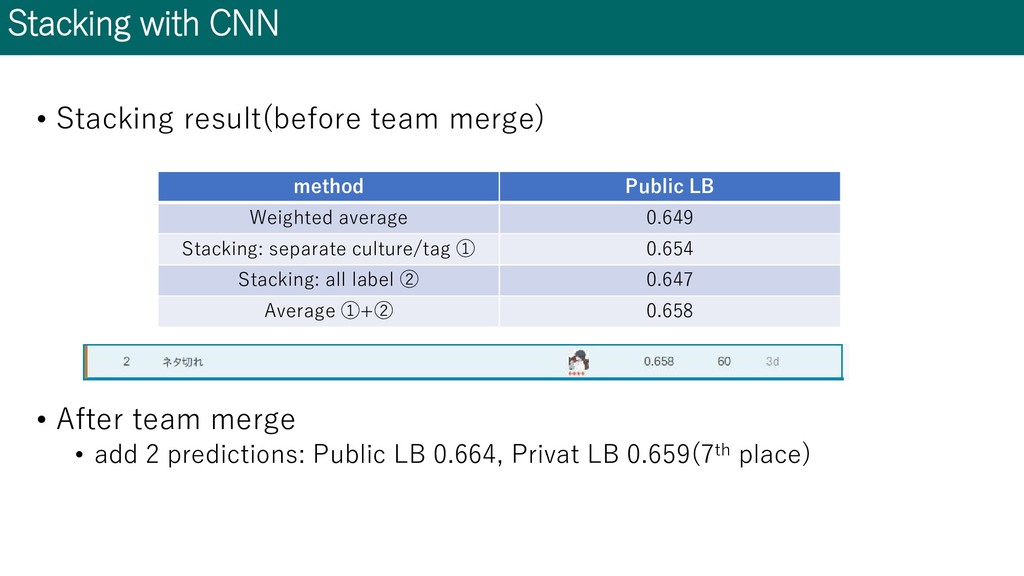
team merge • add 2 predictions: Public LB 0.664, Privat LB 0.659(7th place) method Public LB Weighted average 0.649 Stacking: separate culture/tag ① 0.654 Stacking: all label ② 0.647 Average ①+② 0.658
IMaterialist: 3rd • Model • SENet154, PNasNet-5, SEResNeXt101 • 1st stage: training the zoo • Focal loss, batch size: 1000-1500(accumulation 10-20 times) • 2nd stage: filtering prediction • Drop image from train with very high error • Hard negative mining(5%) • 3rd stage: pseudo labeling • 4th stage: culture and tags separately • Train model with pretrained weight for only tag class(705) • Switch focal loss -> bce
IMaterialist: 3rd • Model • SENet154, PNasNet-5, SEResNeXt101 • 5th stage: second level model • Create binary classification dataset (len(data)*1103) • Predict each class relates to each image • Train lightGBM with below features • Probabilities of each models, sum/division/multiplication of each pair/triple • mean/median/std/max/min of each model • Brightness/colorness of each image • Max side size, binary flag(height more than width or no) • ImagenetNet predictions • Postprocessing: different threshold for culture and tag
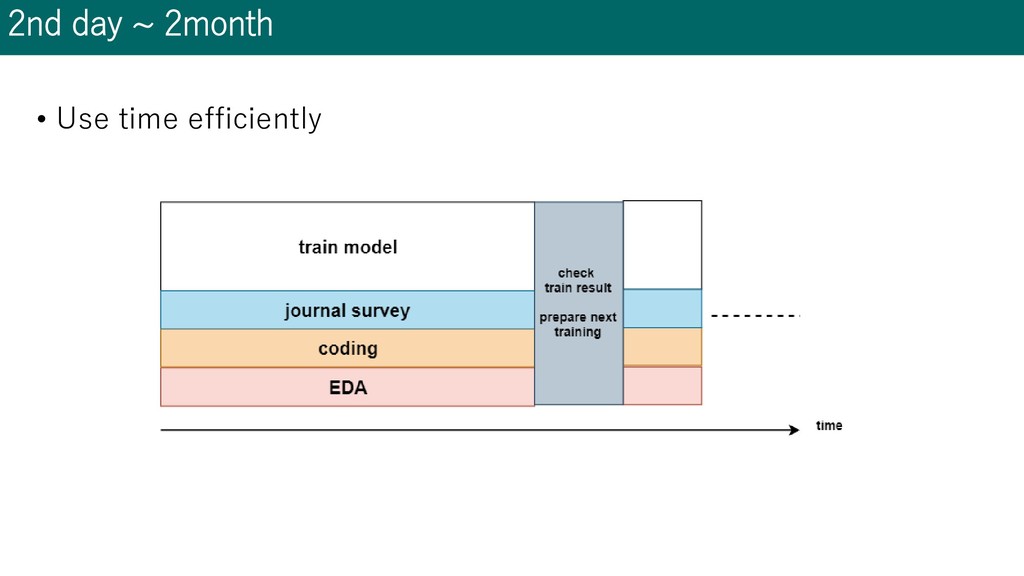
• Paper related to task domain • EDA(30%) • Extract data considering training result • Coding(30%) • Create/fix your pipeline • Implement journal • Fix baseline model(augmentation, modeling, etc...) • Others(10%) • Survey related competition • Read ‘kernel’, ‘discussion’
• Paper related to task domain • EDA(30%) • Extract data considering training result • Coding(30%50%) • Create/fix your pipeline • Implement journal • Fix model(augmentation, modeling, etc...) • Prepare model ensemble
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}