Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LLMのアウトプットの評価と改善 〜DSPyによるプロンプト最適化入門によせて〜
Search
PharmaX(旧YOJO Technologies)開発チーム
October 29, 2025
1.2k
6
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LLMのアウトプットの評価と改善 〜DSPyによるプロンプト最適化入門によせて〜
PharmaX(旧YOJO Technologies)開発チーム
October 29, 2025
More Decks by PharmaX(旧YOJO Technologies)開発チーム
See All by PharmaX(旧YOJO Technologies)開発チーム
PdMによるLiveバイブコーディング〜プロトタイプ開発実践〜
pharma_x_tech
1
85
2025.10.28_CodexとClaude Codeの比較検討 社内座談会
pharma_x_tech
2
640
2025.09.02_AIコーディングを利用した開発自動化を目指しての座談会
pharma_x_tech
5
360
AIコーディングを前提にした開発プロセス再設計〜開発生産性向上に向けた試行錯誤〜
pharma_x_tech
4
450
AIエージェントの評価・改善サイクル
pharma_x_tech
2
640
MCP & Computer Useをフル活用した社内効率化事例〜現在地と将来の展望
pharma_x_tech
1
470
AIエージェントの継続的改善のためオブザーバビリティ
pharma_x_tech
7
2.7k
Roo CodeとClaude Code比較してみた
pharma_x_tech
5
6.4k
Roo Codeにすべてを委ねるためのルール運用
pharma_x_tech
1
1.6k
Featured
See All Featured
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Design in an AI World
tapps
1
270
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
The Cult of Friendly URLs
andyhume
79
7k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Transcript
2025.10.29 LLMのアウトプットの評価と改善 〜DSPyによるプロンプト最適化入門によせて〜
(C)PharmaX Inc. 2025 All Rights Reserve 2 自己紹介 上野彰大 PharmaX共同創業者・CTO/AX事業部長
好きな料理はオムライスと白湯とコーラ マイブームは真夜中のVibe Coding X:@ueeeeniki
(C)PharmaX Inc. 2025 All Rights Reserve 3 個人でも勉強会コミュニティ StudyCoも運営
(C)PharmaX Inc. 2025 All Rights Reserve 4 自社としては LLMを中心に勉強会を月 1回程度開催
5 (C)PharmaX Inc. 2025 All Rights Reserve LLMのアウトプットの改善方法
(C)PharmaX Inc. 2025 All Rights Reserve 6 LLMのアウトプットの改善方法 一般開発者が取れる LLMのアウトプットを改善するメインの方法大きく分けて
2つの方法がある • プロンプトの最適化・改善 ◦ プロンプトの内容そのもの改善(指示内容の改善、 In-Context Learning等) ◦ 必要なデータをどうプロンプトに含ませるか →手軽でPDCAサイクルも短いので、最初に取り組むべき →改善を自動化できれば非常に有効= DSPyの領域 • ファインチューニング ◦ 学習用データを用いてモデルを追加学習 → データの管理も煩雑、学習にかかる金銭的・時間的コストも高いため、 PDCAサイクルも長くなるの でハードルが高い
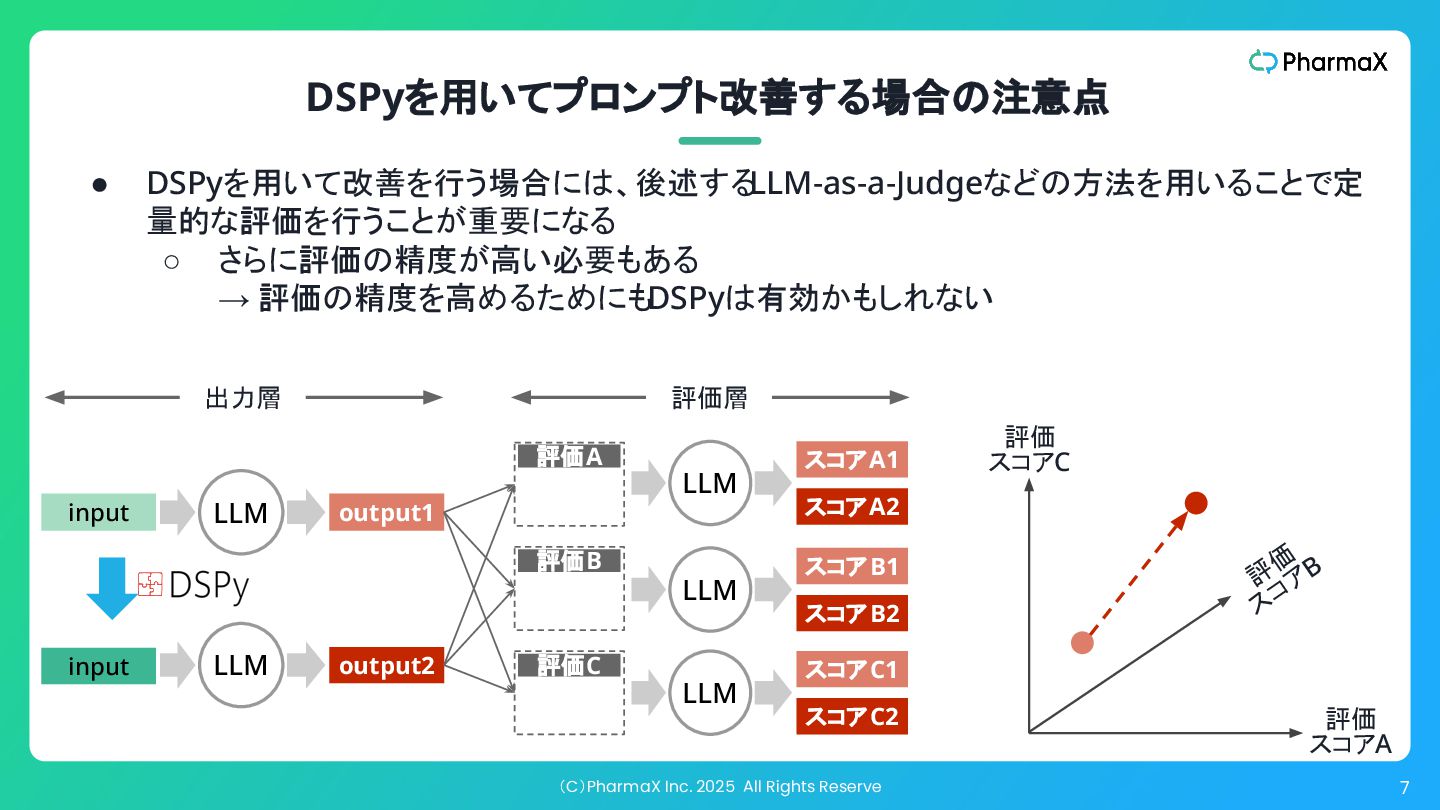
(C)PharmaX Inc. 2025 All Rights Reserve 7 出力層 • DSPyを用いて改善を行う場合には、後述する
LLM-as-a-Judgeなどの方法を用いることで定 量的な評価を行うことが重要になる ◦ さらに評価の精度が高い必要もある → 評価の精度を高めるためにもDSPyは有効かもしれない DSPyを用いてプロンプト改善する場合の注意点 評価 スコアC 評価 スコアA 評 価 ス コア B input output1 LLM 評価A 評価B 評価C スコアA1 スコアA2 スコアB1 スコアB2 スコアC1 スコアC2 input output2 LLM LLM LLM LLM 評価層
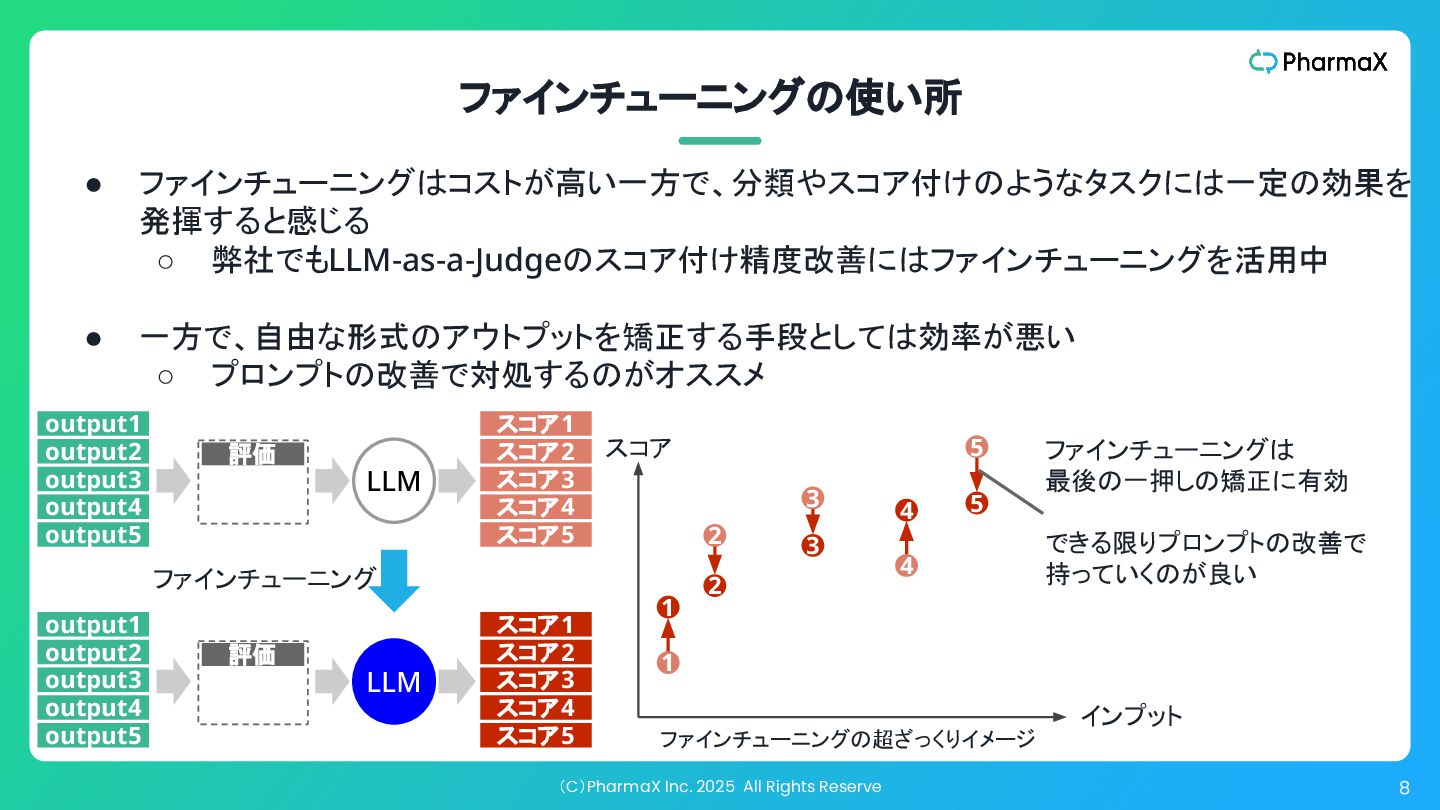
(C)PharmaX Inc. 2025 All Rights Reserve 8 • ファインチューニングはコストが高い一方で、分類やスコア付けのようなタスクには一定の効果を 発揮すると感じる
◦ 弊社でもLLM-as-a-Judgeのスコア付け精度改善にはファインチューニングを活用中 • 一方で、自由な形式のアウトプットを矯正する手段としては効率が悪い ◦ プロンプトの改善で対処するのがオススメ ファインチューニングの使い所 スコア 2 3 1 5 4 インプット ファインチューニングの超ざっくりイメージ 1 2 3 4 5 ファインチューニングは 最後の一押しの矯正に有効 できる限りプロンプトの改善で 持っていくのが良い 評価 スコア2 スコア3 LLM スコア4 スコア1 スコア5 output2 output3 output4 output1 output5 評価 スコア2 スコア3 LLM スコア4 スコア1 スコア5 output2 output3 output4 output1 output5 ファインチューニング
9 (C)PharmaX Inc. 2025 All Rights Reserve LLMのアウトプットの評価
(C)PharmaX Inc. 2025 All Rights Reserve 10 評価とはなにか?なぜ評価が必要なのか • AIの評価とは、AIの出力結果の”良し悪し”を定量的・定性的に判断すること
• 分類問題や回帰問題などであれば、単純に正答率や誤差を評価すればいい • 一方で自由度の高いLLMの出力の評価は、分類問題などとは異なり、正解が 1つに定まるわけ でないので難しい ◦ 例えば、「日本で一番高い山は?」という質問に「富士山」「富士山です」「富士山に決まってんだろー が!」「富士山。標高 3776.12 m。その優美な風貌は …(略)」と答えるのはどれも正解 • LLMの出力を定量的に評価できれば、プロンプトやパラメータの変更前後で評価の平均点を比 べるというような統計的な比較も可能になる AIの評価に関するプラクティス自体は LLMの発展の前から存在していたが、 LLM特有の論点もある
(C)PharmaX Inc. 2025 All Rights Reserve 11 出力の質の評価指標のパターン LLMアプリケーションの出力結果の評価という時にも、複数の評価指標を指すことがあるので注意 •
ヒューリスティックな自動評価では限界がある ◦ 「絵文字は2つまで」のようなレベルならルールベースで評価することも可能 ◦ 期待するアウトプットと実際のアウトプットを( embedding distanceやlevenshtein distanceで)比較してスコアリングすることはできる • LLMエージェントの出力の妥当性をLLMでスコアリング(合格/不合格判定)する LLM-as-a-Judgeも有効 ◦ 一般的な観点だけではなく、下記のようなアプリケーション独自の観点でも評価する必要が ある ▪ 自社の回答のライティングマニュアルに従っているか ▪ (VTuberなどが)キャラクター設定に合っているか
(C)PharmaX Inc. 2025 All Rights Reserve 12 LLM-as-a-Judgeの必要性 LLMアプリケーションの出力結果を LLMで評価することをLLM-as-a-Judgeという
• LLMの出力を人が評価するのは、工数・コスト・速度の観点から限界があるので、 LLMにLLMの 出力を評価をさせようというアイディア ◦ 人で評価する場合、異なる評価者の間で評価基準を一致させるのは難しいが、 LLMなら 可能 ◦ LLMであればプロンプトを作り込めば、専門家にしかできない評価も高精度にさせることが できる
(C)PharmaX Inc. 2025 All Rights Reserve 13 評価用のプロンプトのイメージ LLMからのメッセージ提案を評価させるためのプロンプトを定義し、 LLMにLLMの評価をさせる
System あなた(assistant)には、別のassistant(chat-assistant)のメッ セージを評価していただきます。 ## chat-assistantの前提 chat-assistantの役割は、PharmaX株式会社のYOJOという サービスのかかりつけ薬剤師です。健康や漢方の専門家とし て、常にユーザーの感情に寄り添いアドバイスをします。 ...(略) User chat-assistantの最後の返答がどの程度下記の文章作成マニュ アルに従っているかで0〜100点のスコアを付けて下さい ## 文章のライティング方針 ・丁寧に対応する ・謝罪では絵文字を使わずに、文章だけで表現する ・難しい漢字はひらがなで書く ・細かい説明は箇条書きで書く ...(略) 評価用プロンプト
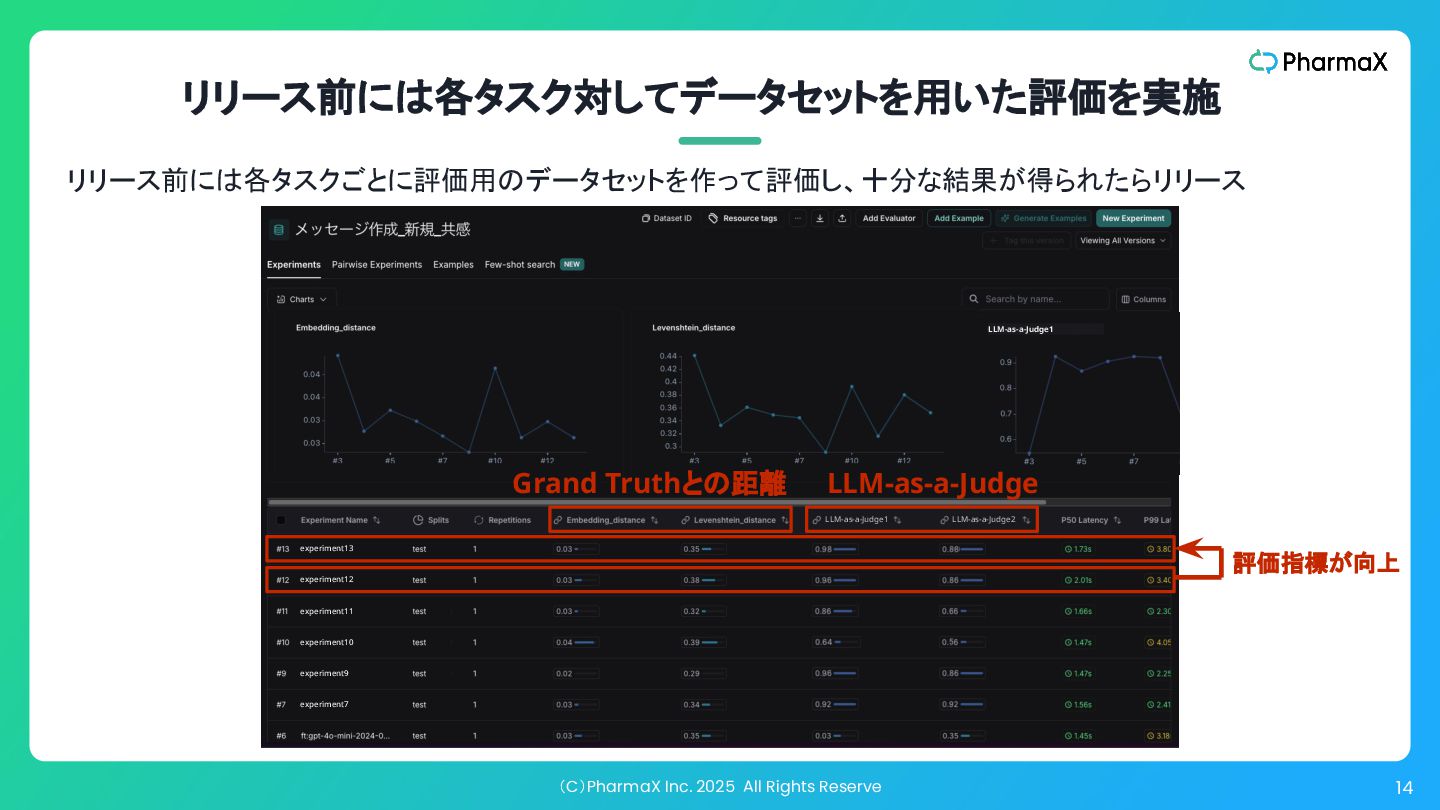
(C)PharmaX Inc. 2025 All Rights Reserve 14 リリース前には各タスク対してデータセットを用いた評価を実施 リリース前には各タスクごとに評価用のデータセットを作って評価し、十分な結果が得られたらリリース experiment6
experiment13 experiment12 experiment11 experiment10 experiment9 experiment7 LLM-as-a-Judge1 LLM-as-a-Judge2 LLM-as-a-Judge1 評価指標が向上 LLM-as-a-Judge Grand Truthとの距離
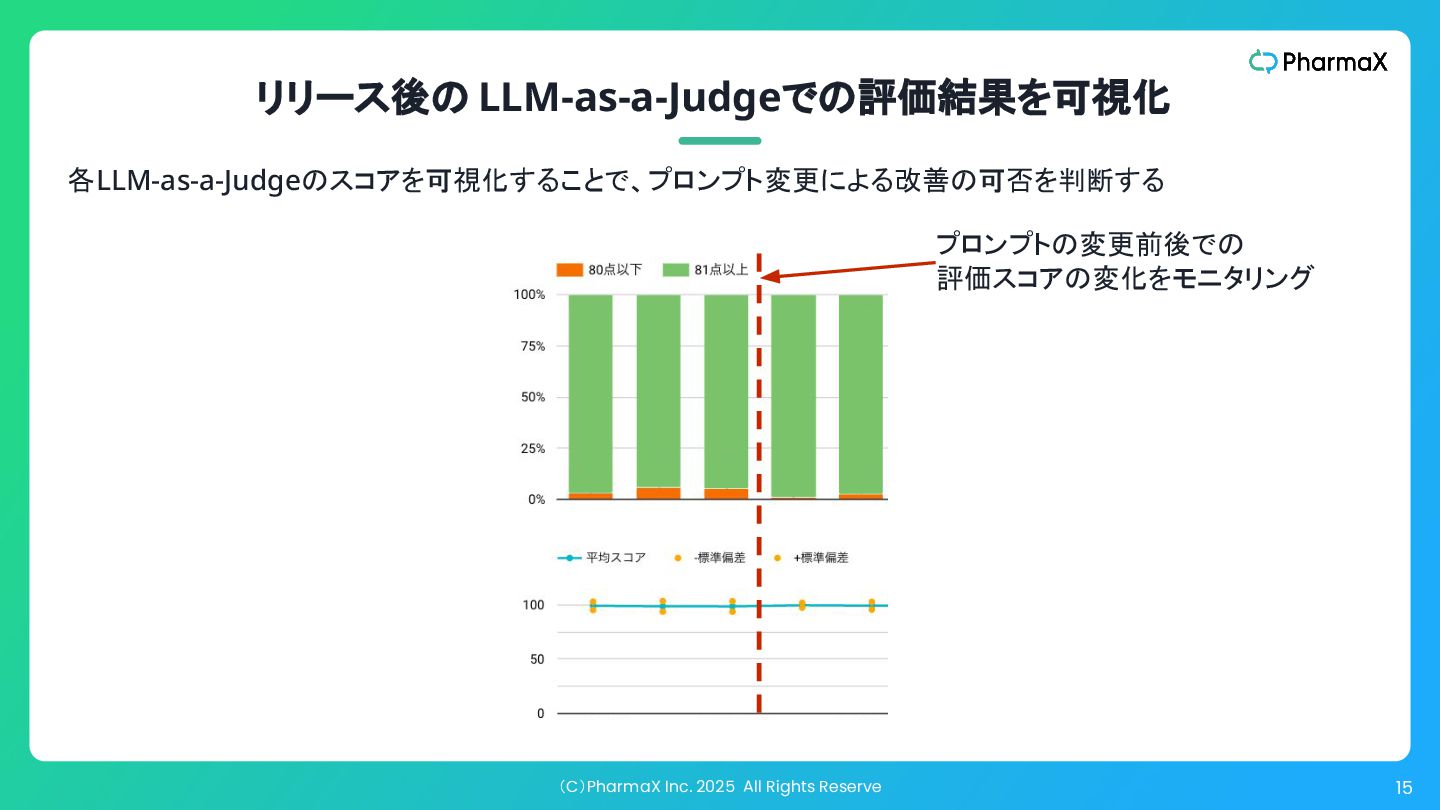
(C)PharmaX Inc. 2025 All Rights Reserve 15 プロンプトの変更前後での 評価スコアの変化をモニタリング リリース後の
LLM-as-a-Judgeでの評価結果を可視化 各LLM-as-a-Judgeのスコアを可視化することで、プロンプト変更による改善の可否を判断する
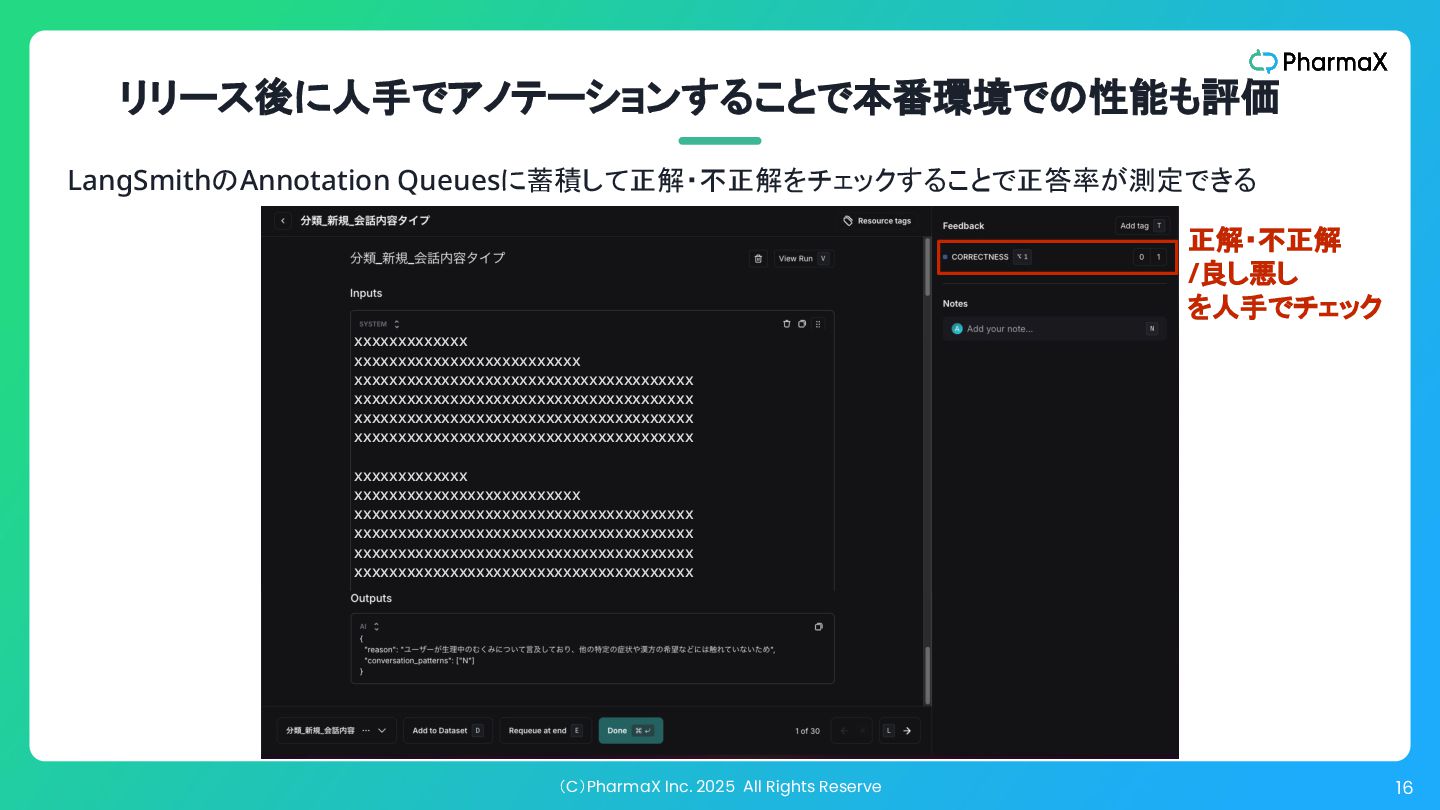
(C)PharmaX Inc. 2025 All Rights Reserve 16 リリース後に人手でアノテーションすることで本番環境での性能も評価 xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 正解・不正解 /良し悪し を人手でチェック LangSmithのAnnotation Queuesに蓄積して正解・不正解をチェックすることで正答率が測定できる
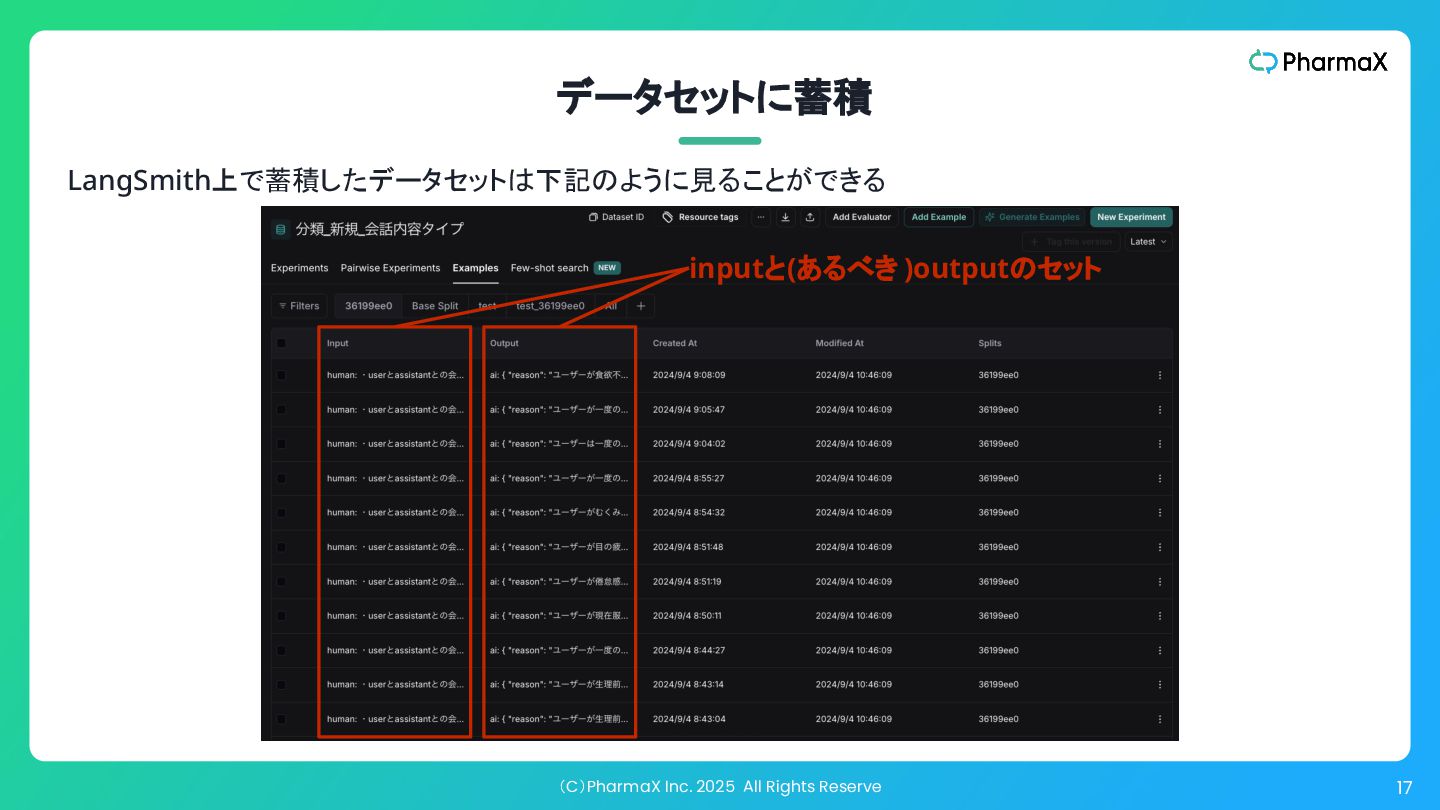
(C)PharmaX Inc. 2025 All Rights Reserve 17 データセットに蓄積 LangSmith上で蓄積したデータセットは下記のように見ることができる inputと(あるべき
)outputのセット
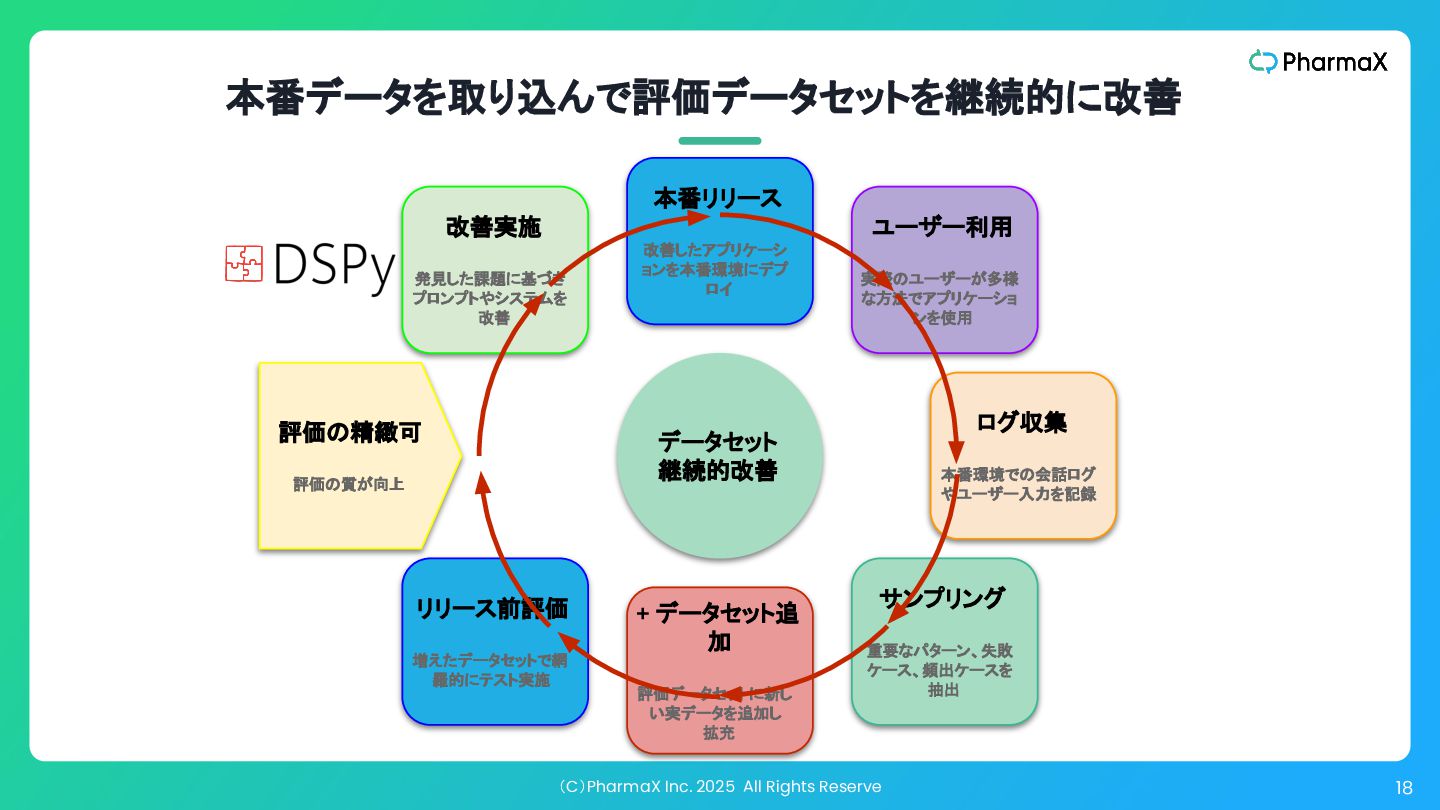
(C)PharmaX Inc. 2025 All Rights Reserve 18 本番データを取り込んで評価データセットを継続的に改善 データセット 継続的改善
本番リリース 改善したアプリケーシ ョンを本番環境にデプ ロイ ログ収集 本番環境での会話ログ やユーザー入力を記録 + データセット追 加 評価データセットに新し い実データを追加し 拡充 ユーザー利用 実際のユーザーが多様 な方法でアプリケーショ ンを使用 サンプリング 重要なパターン、失敗 ケース、頻出ケースを 抽出 改善実施 発見した課題に基づき プロンプトやシステムを 改善 リリース前評価 増えたデータセットで網 羅的にテスト実施 評価の精緻可 評価の質が向上
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}