Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIエージェントの継続的改善のためオブザーバビリティ
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
PharmaX(旧YOJO Technologies)開発チーム
June 18, 2025
Technology
2.7k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIエージェントの継続的改善のためオブザーバビリティ
PharmaX(旧YOJO Technologies)開発チーム
June 18, 2025
More Decks by PharmaX(旧YOJO Technologies)開発チーム
See All by PharmaX(旧YOJO Technologies)開発チーム
PdMによるLiveバイブコーディング〜プロトタイプ開発実践〜
pharma_x_tech
1
85
2025.10.28_CodexとClaude Codeの比較検討 社内座談会
pharma_x_tech
2
640
LLMのアウトプットの評価と改善 〜DSPyによるプロンプト最適化入門によせて〜
pharma_x_tech
6
1.2k
2025.09.02_AIコーディングを利用した開発自動化を目指しての座談会
pharma_x_tech
5
360
AIコーディングを前提にした開発プロセス再設計〜開発生産性向上に向けた試行錯誤〜
pharma_x_tech
4
450
AIエージェントの評価・改善サイクル
pharma_x_tech
2
640
MCP & Computer Useをフル活用した社内効率化事例〜現在地と将来の展望
pharma_x_tech
1
470
Roo CodeとClaude Code比較してみた
pharma_x_tech
5
6.4k
Roo Codeにすべてを委ねるためのルール運用
pharma_x_tech
1
1.6k
Other Decks in Technology
See All in Technology
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
VPCセキュリティ対応の最新事情
nagisa53
1
290
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
490
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
14
4.8k
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
470
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.3k
発表と総括 / Presentations and Summary
ks91
PRO
0
190
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
410
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
1
240
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
Featured
See All Featured
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
560
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Ethics towards AI in product and experience design
skipperchong
2
330
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Navigating Weather and Climate Data
rabernat
0
400
BBQ
matthewcrist
89
10k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.5k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
We Are The Robots
honzajavorek
0
280
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Transcript
2025.6.18 #AI_Engineering_findy AIエージェントの継続的改善のための オブザーバビリティ
(C)PharmaX Inc. 2025 All Rights Reserve 2 自己紹介 上野彰大 PharmaX共同創業者・CTO/AX事業部長
好きな料理はオムライスと白湯とコーラ マイブームはLLMとRust X:@ueeeeniki
(C)PharmaX Inc. 2025 All Rights Reserve 3 個人でも勉強会コミュニティ StudyCoも運営
(C)PharmaX Inc. 2025 All Rights Reserve 4 自社としては LLMを中心に勉強会を月 1回程度開催
(C)PharmaX Inc. 2025 All Rights Reserve 5 医療アドバイザーに体調 のことをいつでも気軽に相 談できる
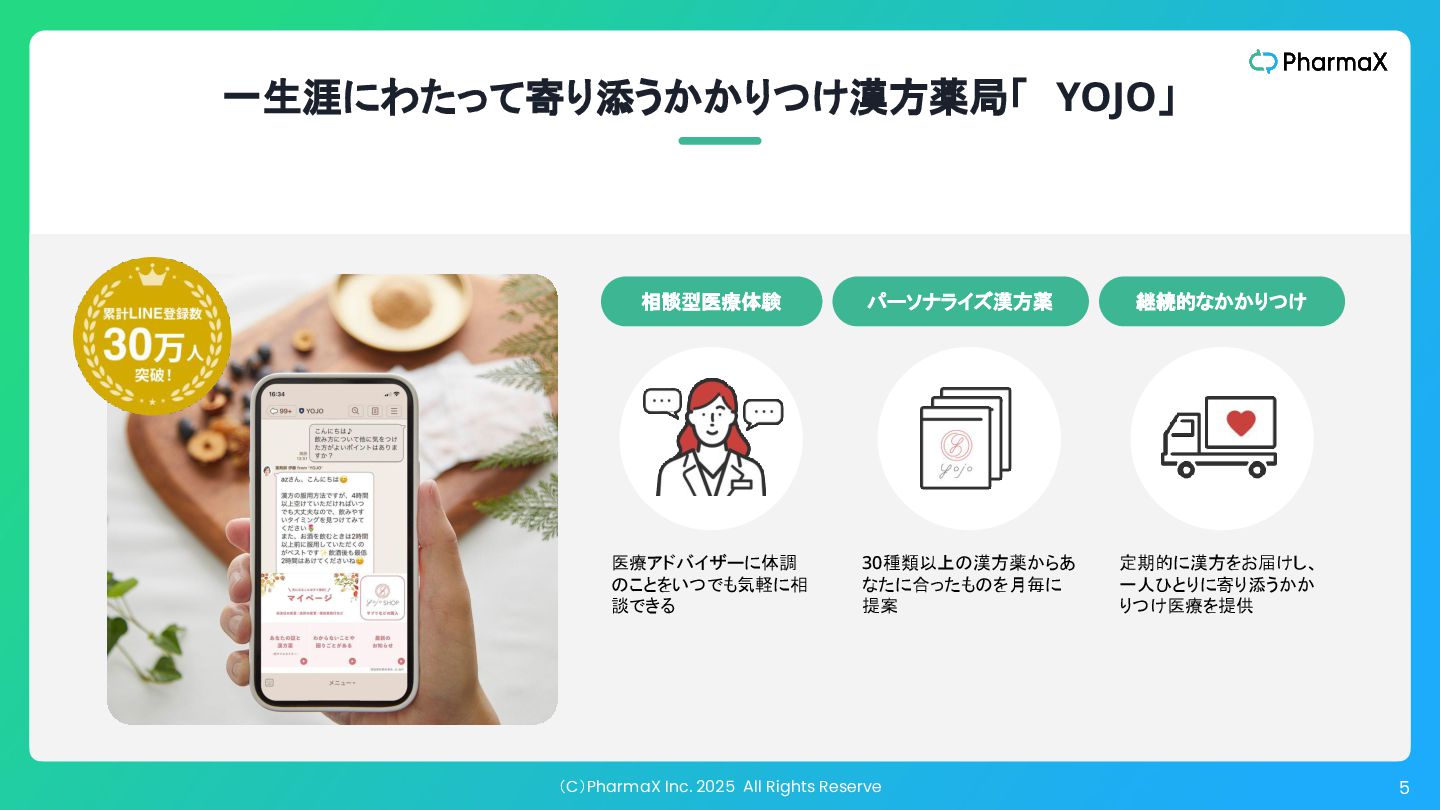
相談型医療体験 30種類以上の漢方薬からあ なたに合ったものを月毎に 提案 パーソナライズ漢方薬 定期的に漢方をお届けし、 一人ひとりに寄り添うかか りつけ医療を提供 継続的なかかりつけ 一生涯にわたって寄り添うかかりつけ漢方薬局「 YOJO」
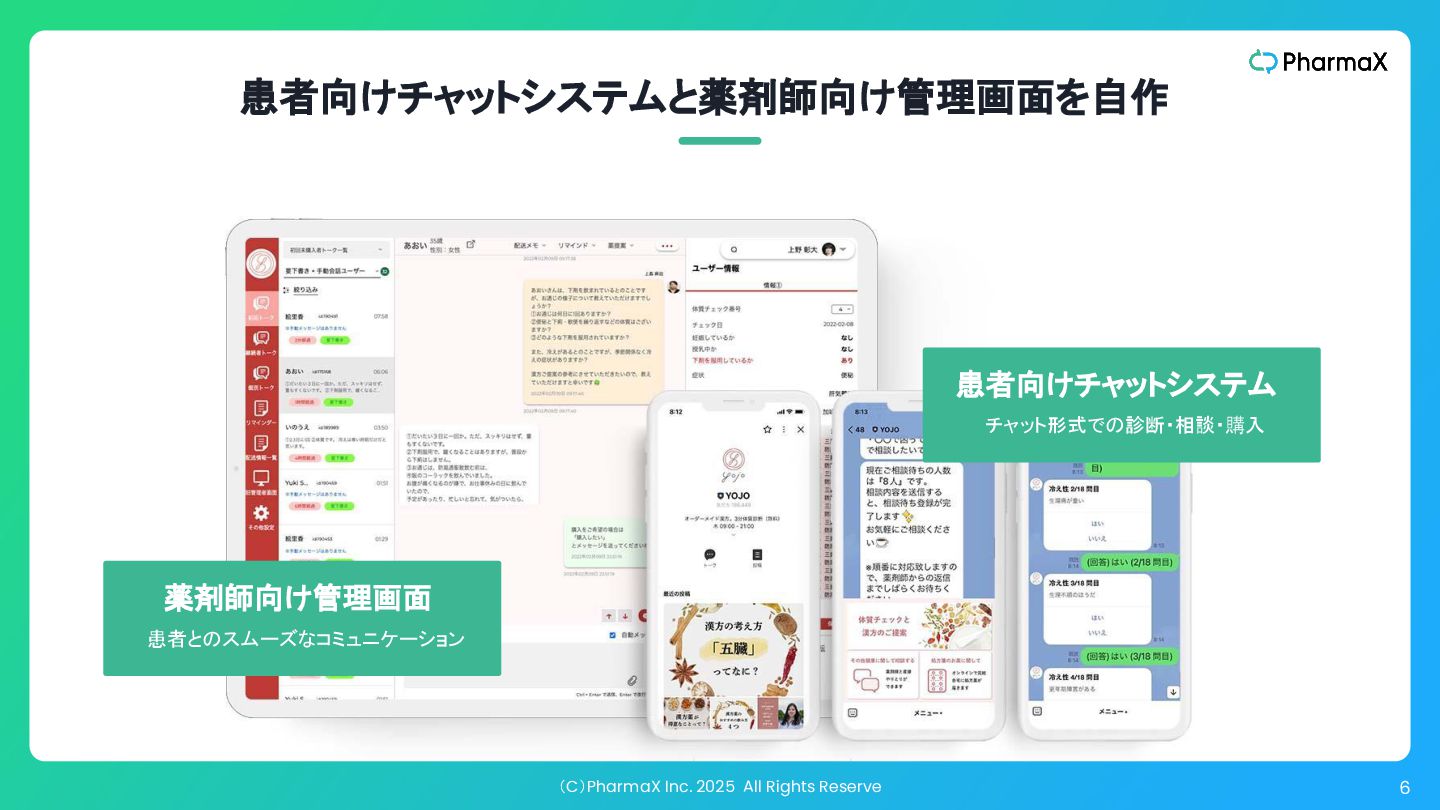
(C)PharmaX Inc. 2025 All Rights Reserve 6 患者向けチャットシステムと薬剤師向け管理画面を自作 患者とのスムーズなコミュニケーション 薬剤師向け管理画面
チャット形式での診断・相談・購入 患者向けチャットシステム
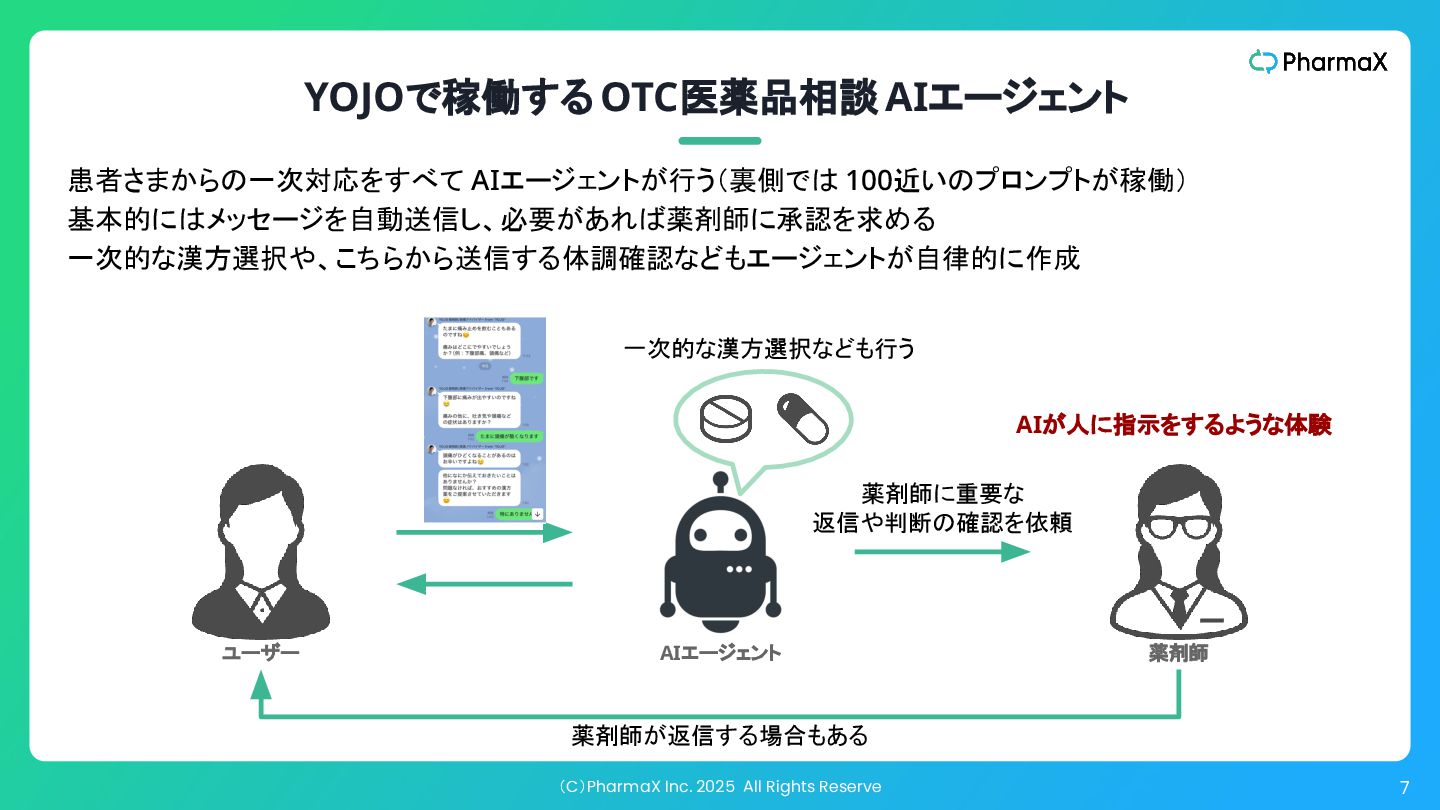
(C)PharmaX Inc. 2025 All Rights Reserve 7 YOJOで稼働する OTC医薬品相談 AIエージェント
患者さまからの一次対応をすべて AIエージェントが行う(裏側では 100近いのプロンプトが稼働) 基本的にはメッセージを自動送信し、必要があれば薬剤師に承認を求める 一次的な漢方選択や、こちらから送信する体調確認などもエージェントが自律的に作成 薬剤師に重要な 返信や判断の確認を依頼 一次的な漢方選択なども行う 薬剤師が返信する場合もある AIエージェント 薬剤師 ユーザー AIが人に指示をするような体験
(C)PharmaX Inc. 2025 All Rights Reserve 8 医療業界を横断する 2つの事業領域 YOJO
toC事業 BtoC/BtoB両事業でAIエージェントを実装することで患者満足度世界一の医療体験を実現 AX toB事業 “まだ誰も見たことのない ”10Xな医療体験の実現 既存医療インフラの AIによる劇的なアップデート
9 (C)PharmaX Inc. 2025 All Rights Reserve Agentic Workflow
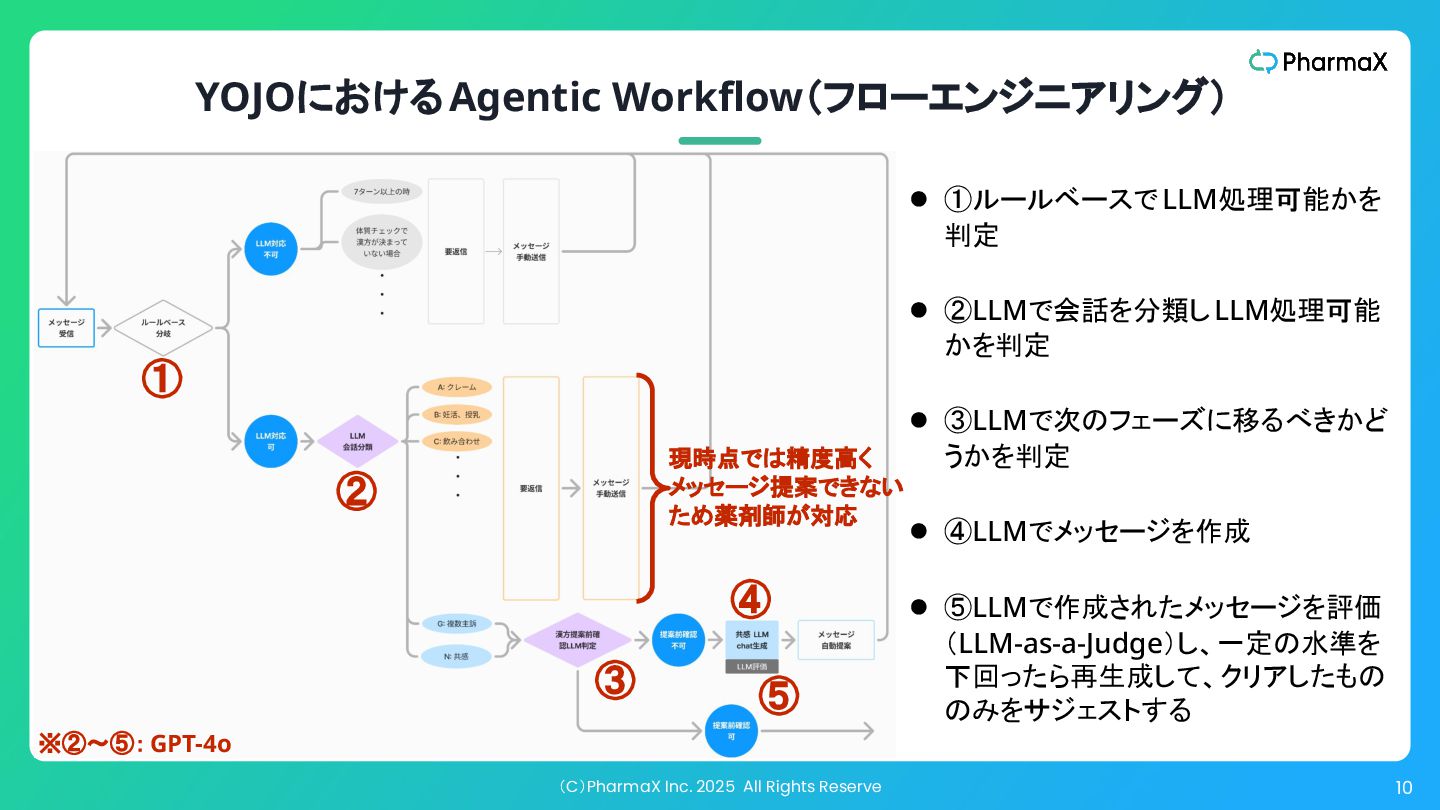
(C)PharmaX Inc. 2025 All Rights Reserve 10 YOJOにおけるAgentic Workflow(フローエンジニアリング) ①
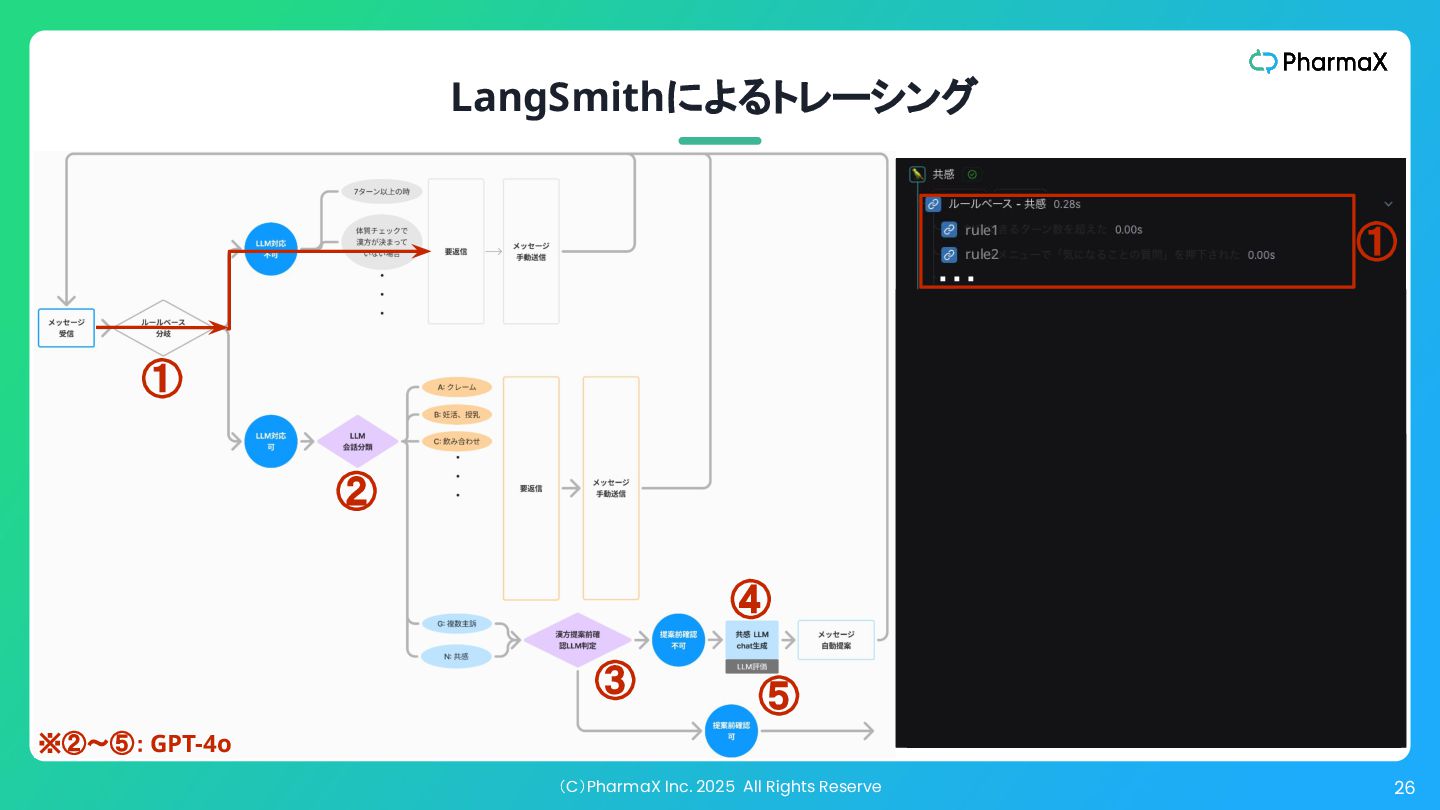
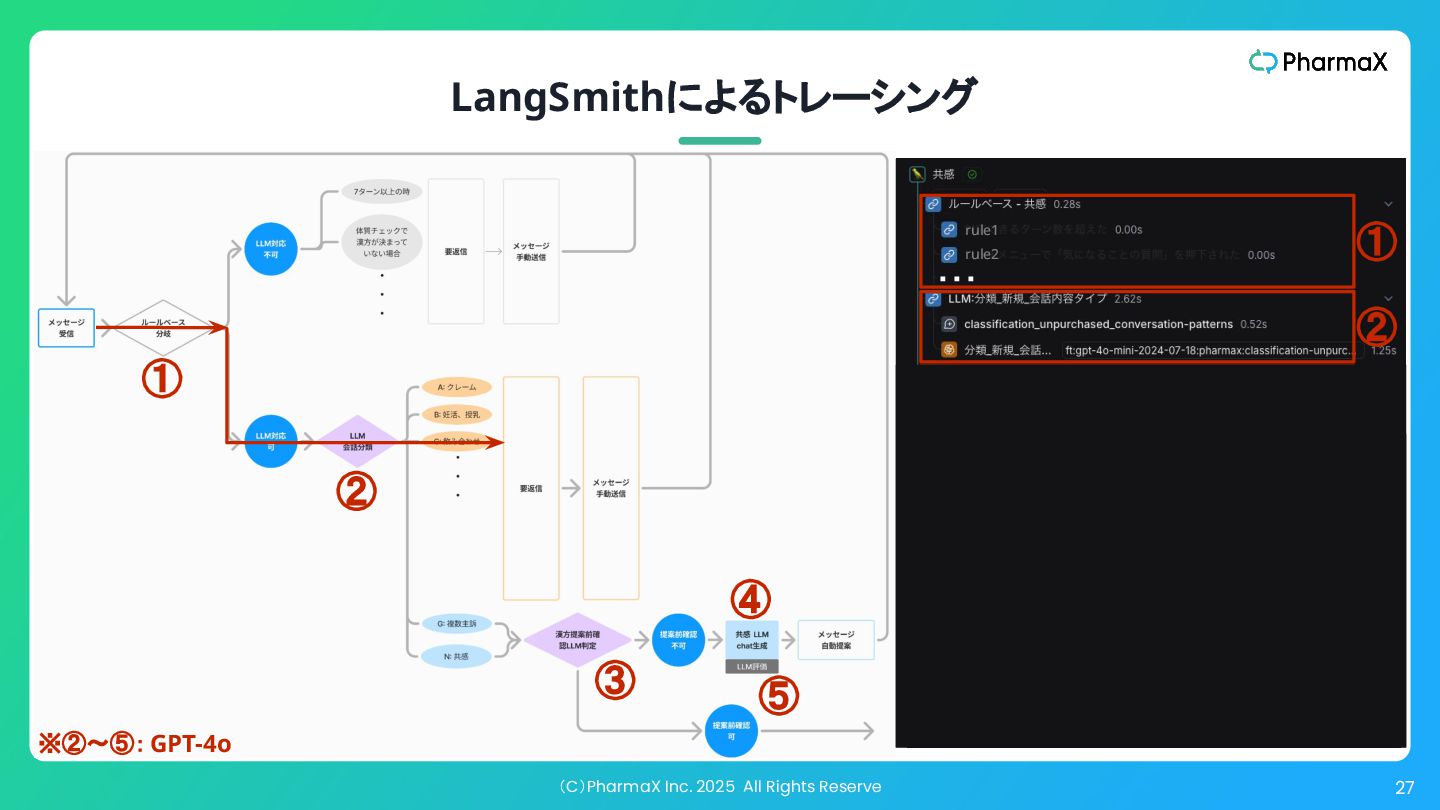
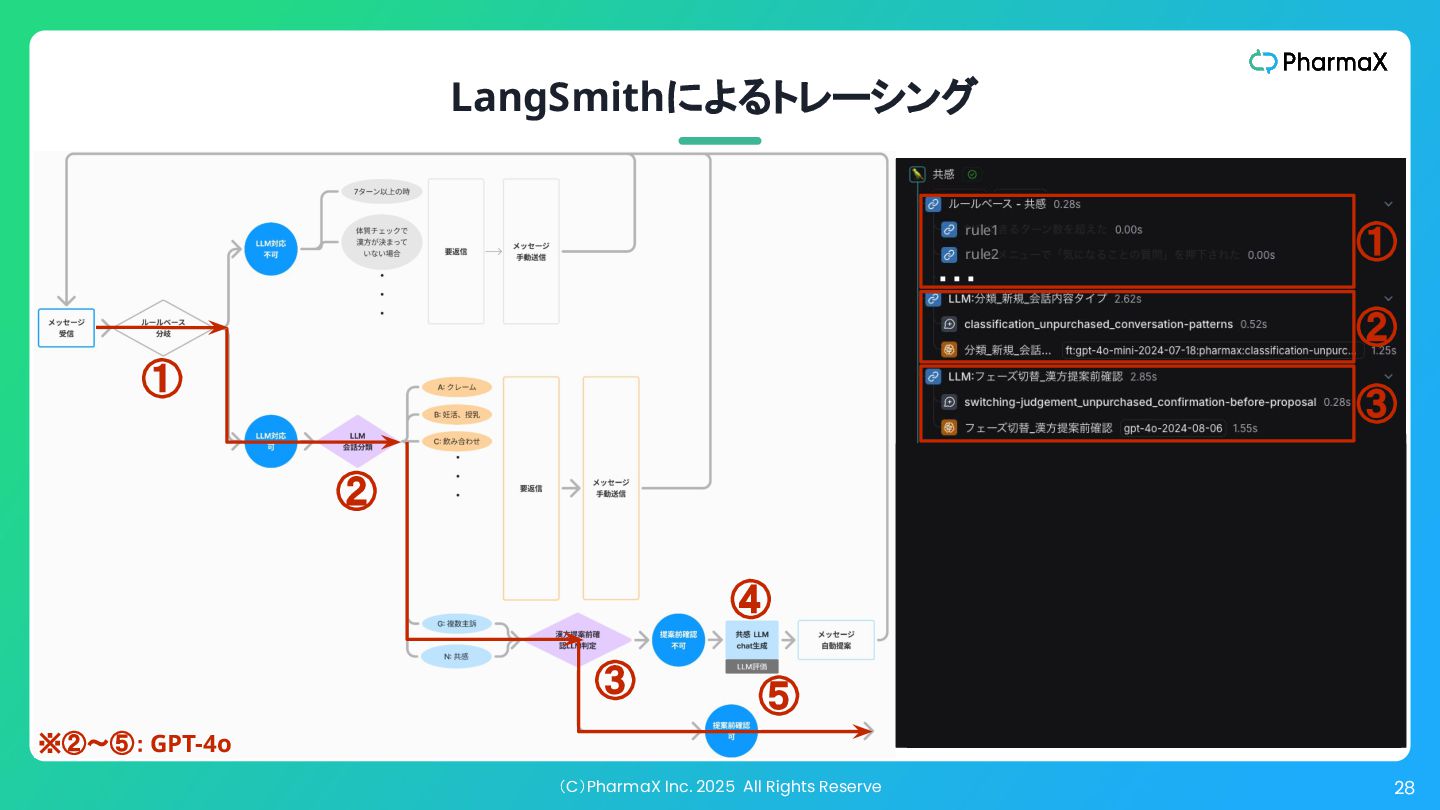
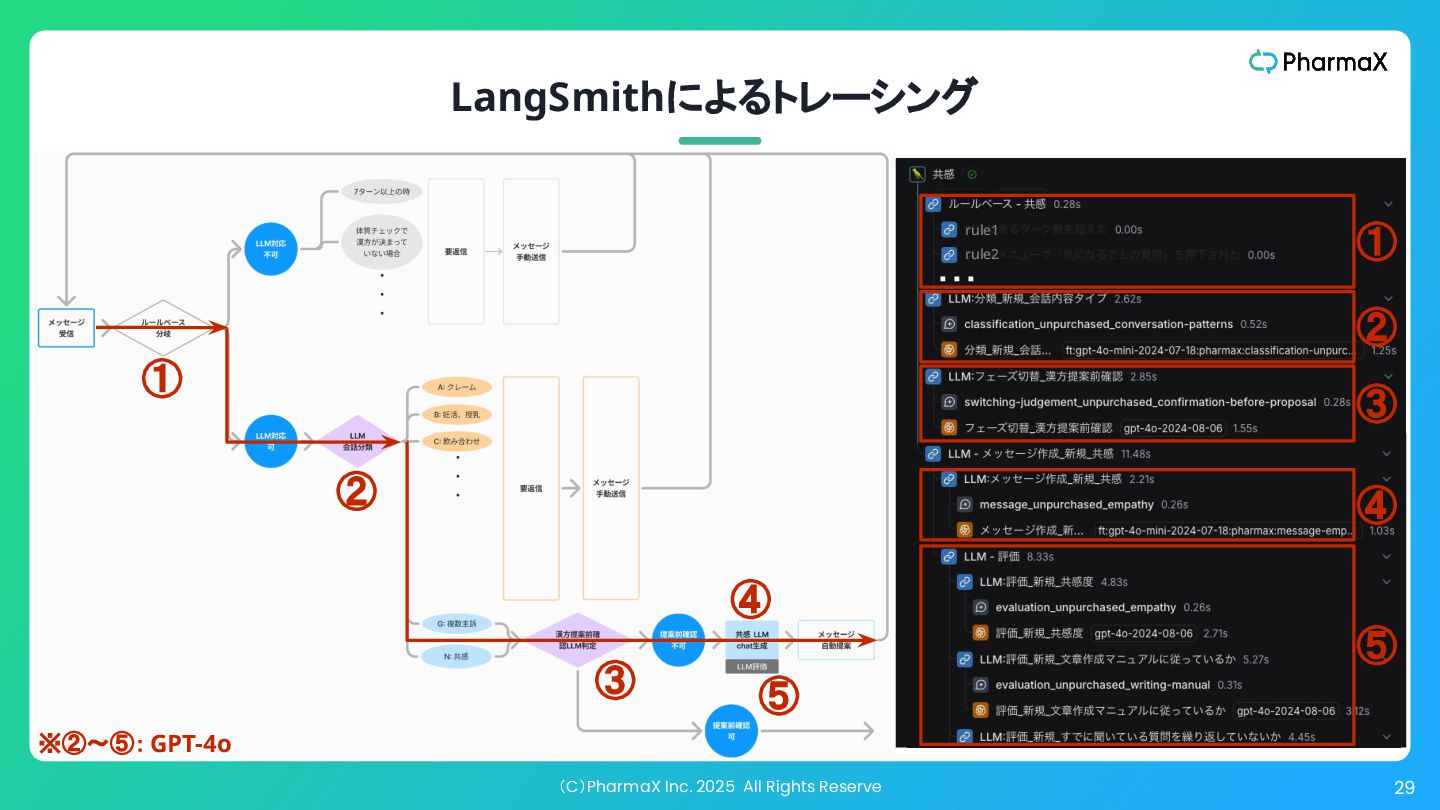
② ④ • ①ルールベースでLLM処理可能かを 判定 • ②LLMで会話を分類しLLM処理可能 かを判定 • ③LLMで次のフェーズに移るべきかど うかを判定 • ④LLMでメッセージを作成 • ⑤LLMで作成されたメッセージを評価 (LLM-as-a-Judge)し、一定の水準を 下回ったら再生成して、クリアしたもの のみをサジェストする 現時点では精度高く メッセージ提案できない ため薬剤師が対応 ③ ⑤ ※②〜⑤: GPT-4o
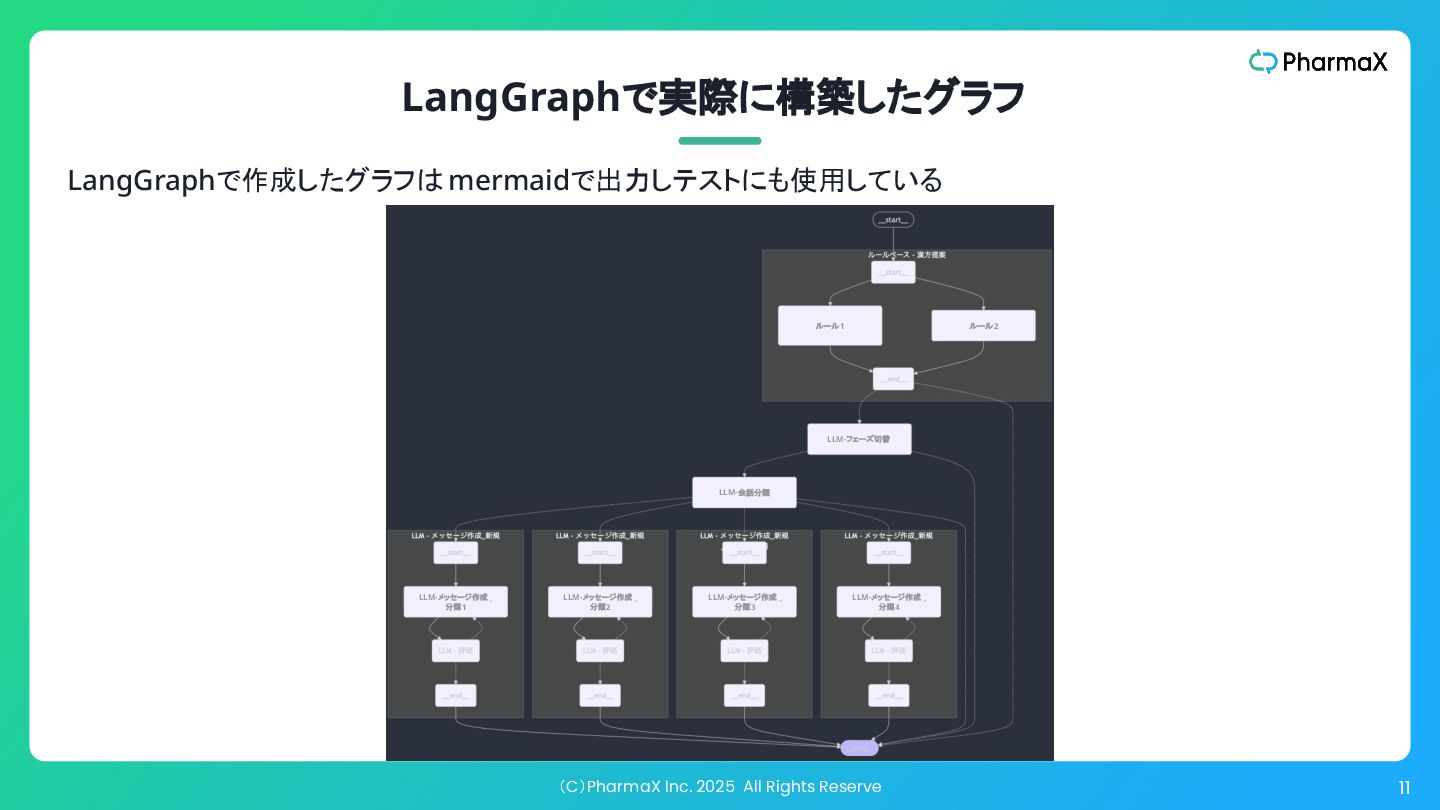
(C)PharmaX Inc. 2025 All Rights Reserve 11 LangGraphで実際に構築したグラフ ルール1 ルール2
LLM-メッセージ作成 _ 分類4 LLM-会話分類 LLM-メッセージ作成 _ 分類1 LLM-メッセージ作成 _ 分類2 LLM-メッセージ作成 _ 分類3 LLM-フェーズ切替 LangGraphで作成したグラフはmermaidで出力しテストにも使用している
(C)PharmaX Inc. 2025 All Rights Reserve 12 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ① ② ④ ③ ⑤ ※②〜⑤: GPT-4o
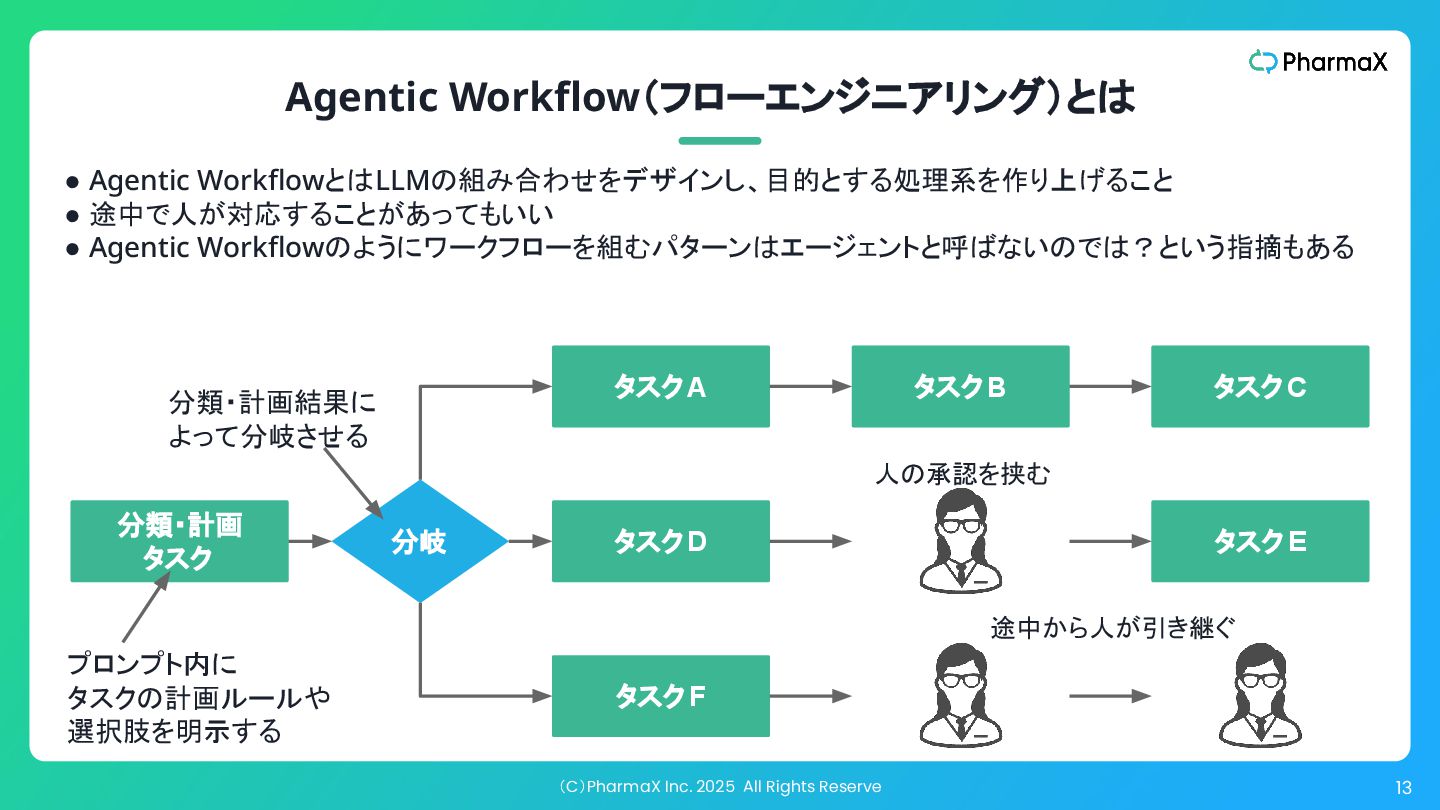
(C)PharmaX Inc. 2025 All Rights Reserve 13 プロンプト内に タスクの計画ルールや 選択肢を明示する
Agentic Workflow(フローエンジニアリング)とは • Agentic WorkflowとはLLMの組み合わせをデザインし、目的とする処理系を作り上げること • 途中で人が対応することがあってもいい • Agentic Workflowのようにワークフローを組むパターンはエージェントと呼ばないのでは?という指摘もある 分類・計画 タスク タスクA タスクB タスクC タスクD タスクE タスクF 分岐 人の承認を挟む 途中から人が引き継ぐ 分類・計画結果に よって分岐させる
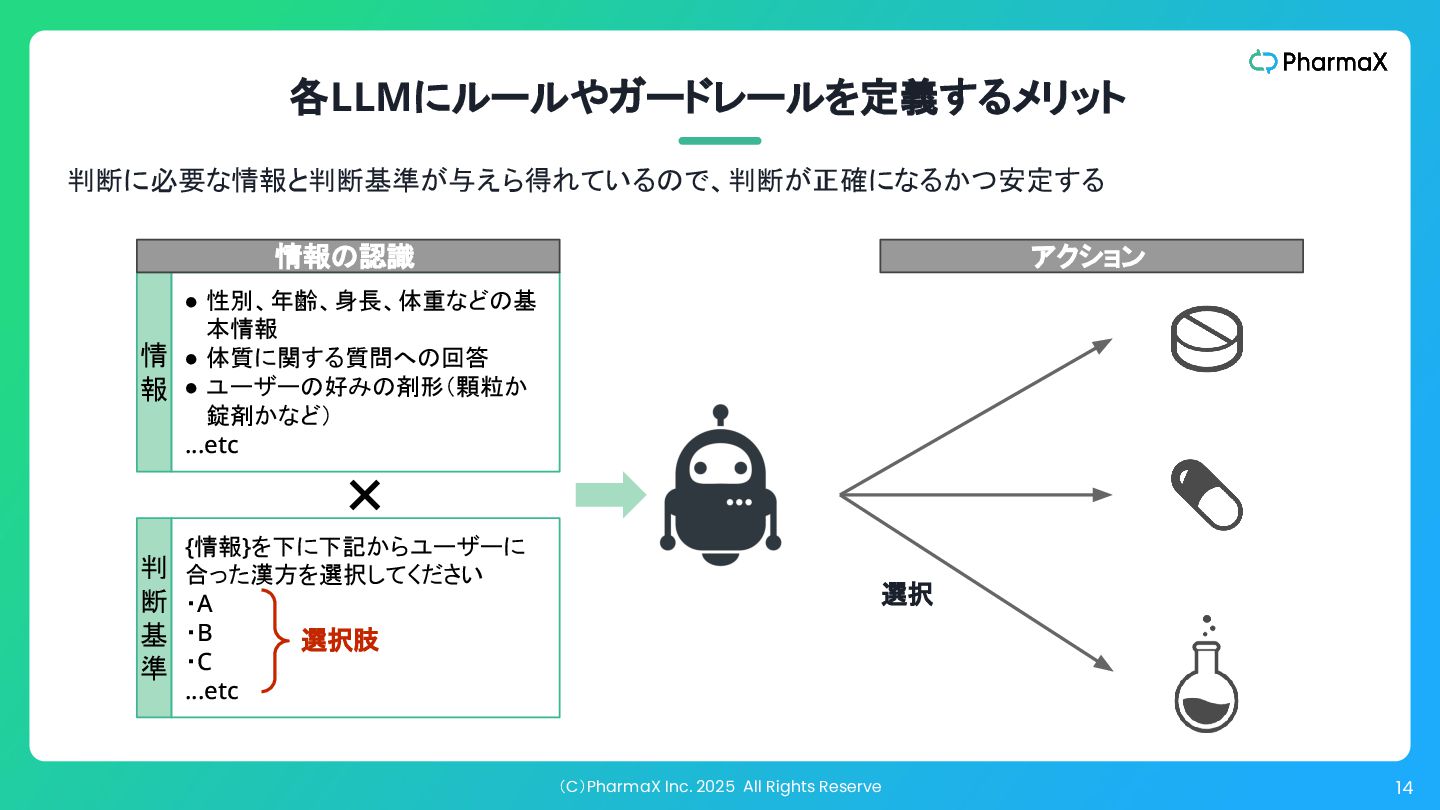
(C)PharmaX Inc. 2025 All Rights Reserve 14 各LLMにルールやガードレールを定義するメリット 判断に必要な情報と判断基準が与えら得れているので、判断が正確になるかつ安定する •
性別、年齢、身長、体重などの基 本情報 • 体質に関する質問への回答 • ユーザーの好みの剤形(顆粒か 錠剤かなど) …etc {情報}を下に下記からユーザーに 合った漢方を選択してください ・A ・B ・C …etc ✕ 選択肢 選択 情 報 判 断 基 準 アクション 情報の認識
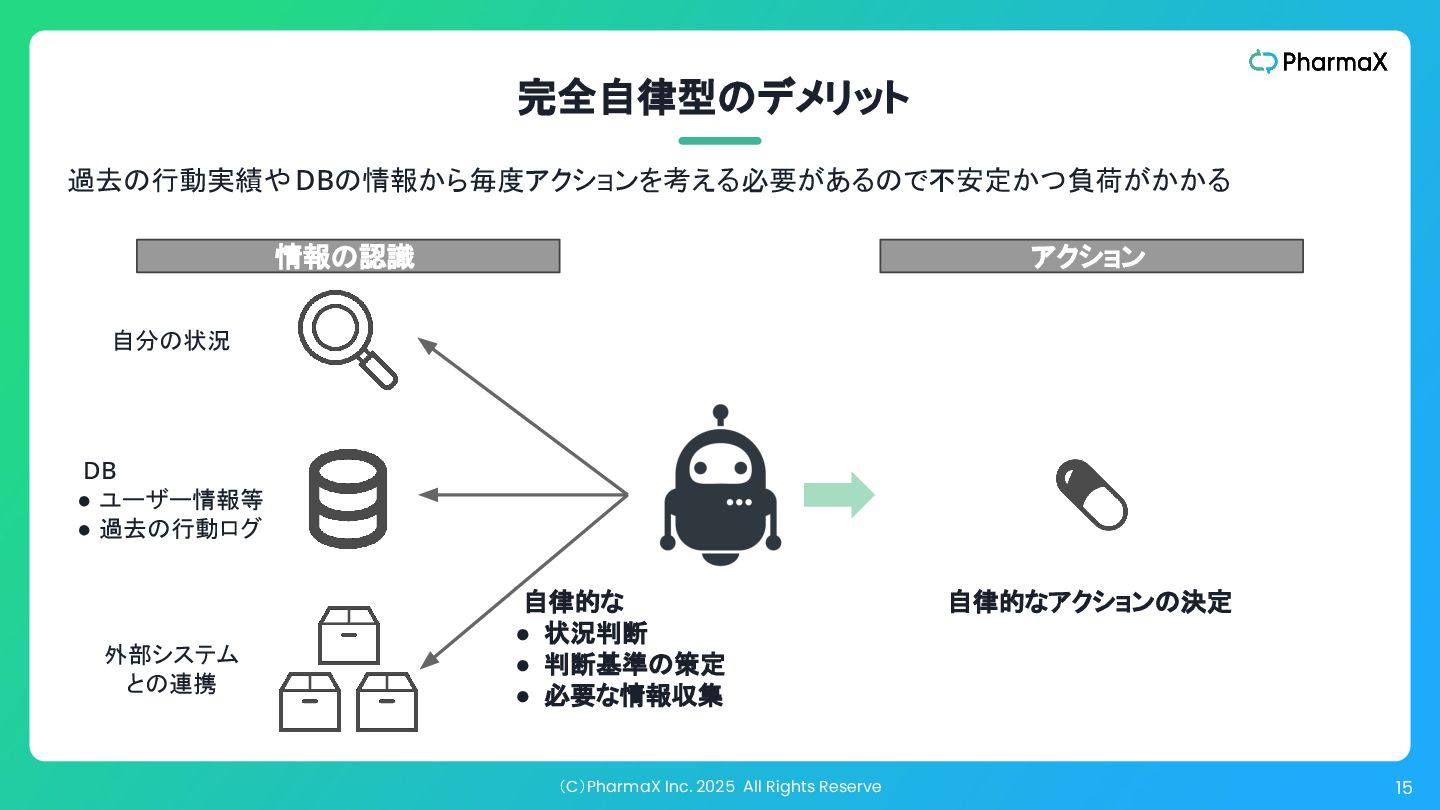
(C)PharmaX Inc. 2025 All Rights Reserve 15 自律的なアクションの決定 外部システム との連携
完全自律型のデメリット 情報の認識 過去の行動実績やDBの情報から毎度アクションを考える必要があるので不安定かつ負荷がかかる 自律的な • 状況判断 • 判断基準の策定 • 必要な情報収集 アクション 自分の状況 DB • ユーザー情報等 • 過去の行動ログ
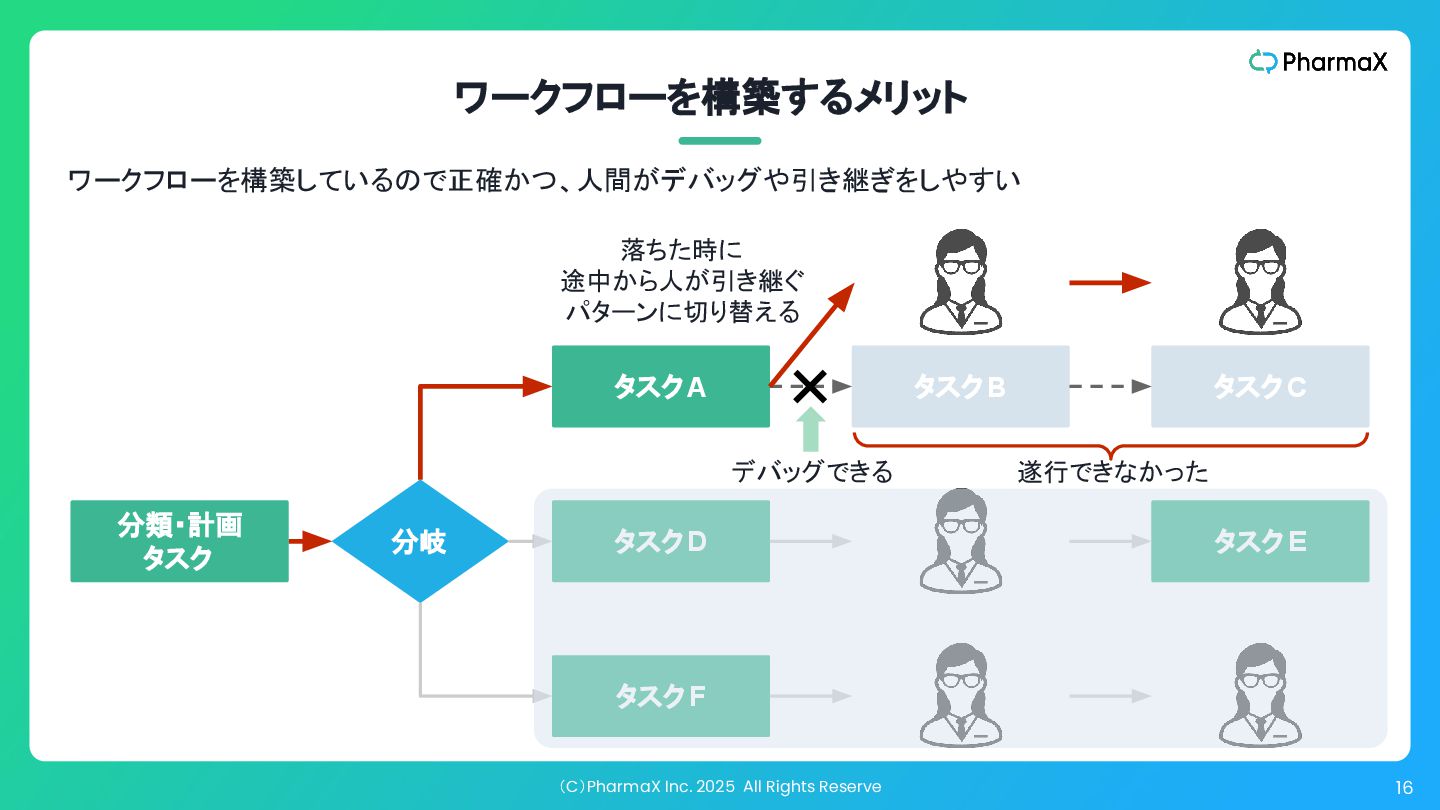
(C)PharmaX Inc. 2025 All Rights Reserve 16 ワークフローを構築するメリット タスクA タスクB
タスクC タスクD タスクE タスクF 分岐 ✕ 落ちた時に 途中から人が引き継ぐ パターンに切り替える デバッグできる 遂行できなかった ワークフローを構築しているので正確かつ、人間がデバッグや引き継ぎをしやすい 分類・計画 タスク
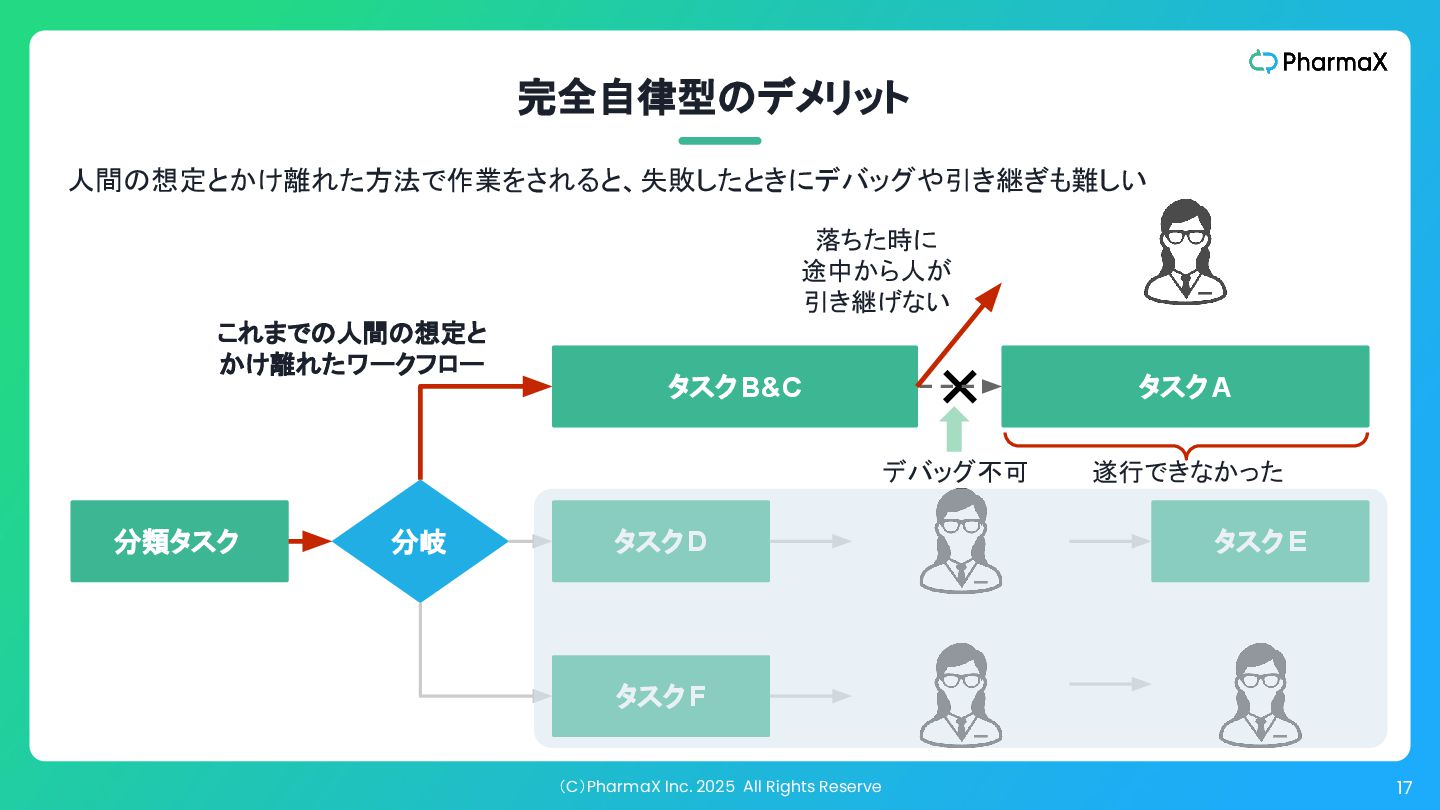
(C)PharmaX Inc. 2025 All Rights Reserve 17 完全自律型のデメリット 分類タスク タスクD
タスクE タスクF 分岐 タスクB&C タスクA これまでの人間の想定と かけ離れたワークフロー 落ちた時に 途中から人が 引き継げない ✕ 遂行できなかった デバッグ不可 人間の想定とかけ離れた方法で作業をされると、失敗したときにデバッグや引き継ぎも難しい
18 (C)PharmaX Inc. 2025 All Rights Reserve AIエージェントの開発サイクルと LLMOps
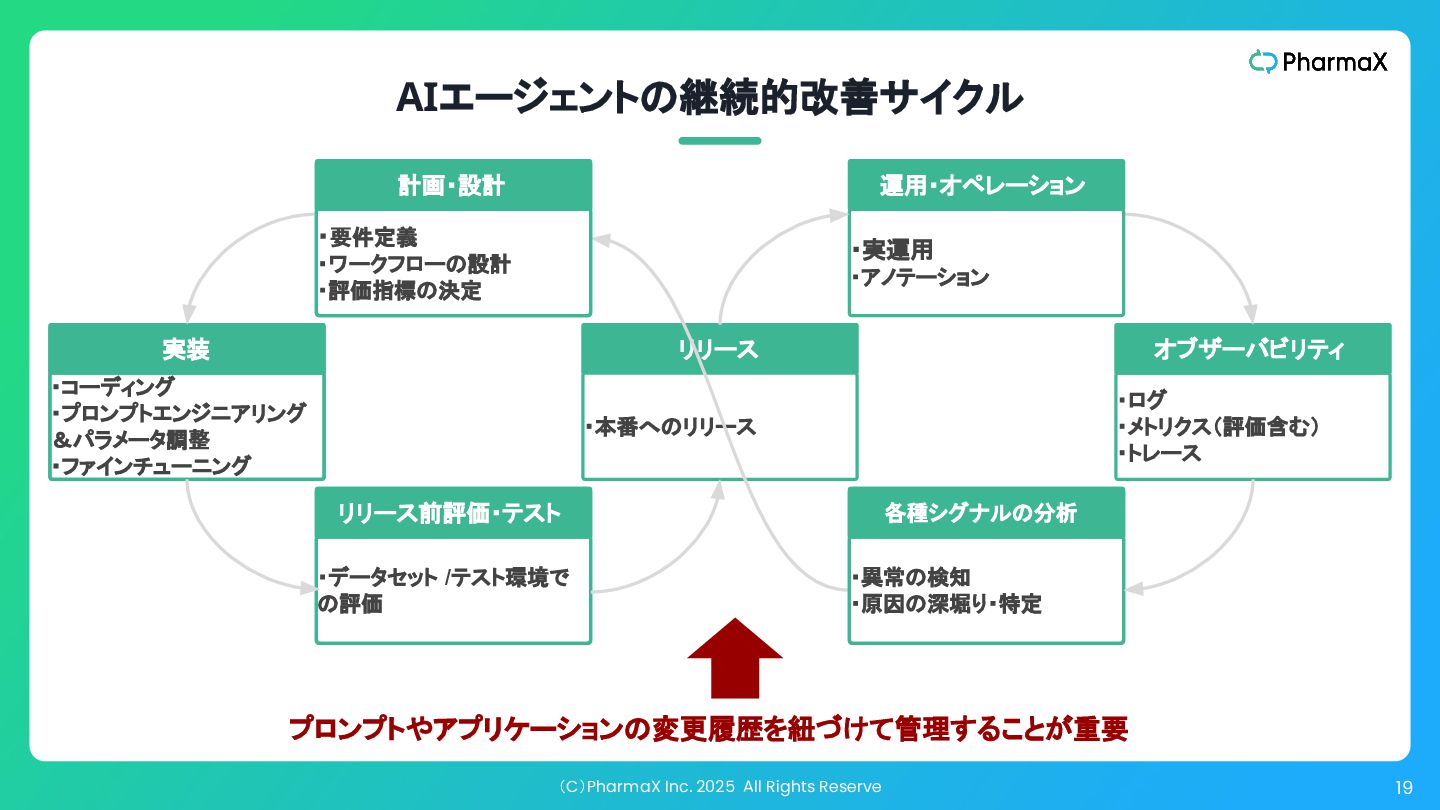
(C)PharmaX Inc. 2025 All Rights Reserve 19 オブザーバビリティ 実装 リリース
・本番へのリリース ・ログ ・メトリクス(評価含む) ・トレース ・コーディング ・プロンプトエンジニアリング &パラメータ調整 ・ファインチューニング AIエージェントの継続的改善サイクル 各種シグナルの分析 ・異常の検知 ・原因の深堀り・特定 ・要件定義 ・ワークフローの設計 ・評価指標の決定 計画・設計 リリース前評価・テスト ・データセット /テスト環境で の評価 ・実運用 ・アノテーション 運用・オペレーション プロンプトやアプリケーションの変更履歴を紐づけて管理することが重要
(C)PharmaX Inc. 2025 All Rights Reserve 20 LLMOpsと従来のMLOpsの違い LLMOps MLOps
モデルアップデート ・モデルがアップデートされることが前提 ・新データ →再学習 →デプロイが中心 ・必ずしもモデルの再学習を伴わない ・プロンプト・パラメータ調整がメイン 主要な改善手法 ・データ収集・前処理 →モデル学習・評価 →再学習によるパフォーマンスの向上 ・プロンプトエンジニアリングパラメータ調整 ・RAG ・ファインチューニング等 評価の特徴 ・定量的指標中心(精度、 F1スコアなど) ・比較的客観的な評価が可能 ・出力が確率的で自由度が高い ・LLM-as-a-Judge等の新手法が必要 ・多面的評価(品質・安全性・コスト) 監視・観測の重点 ・モデルの変更履歴管理 ・本番でのモデル精度の評価 ・モデル精度の劣化の検知 ・プロンプト・パラメータ変更履歴管理 ・本番でのアウトプットの評価 ・予期せぬ挙動の検知 必ずしもモデルのアップデートを伴わないため、改善サイクルを短くできるのが MLOpsの特徴
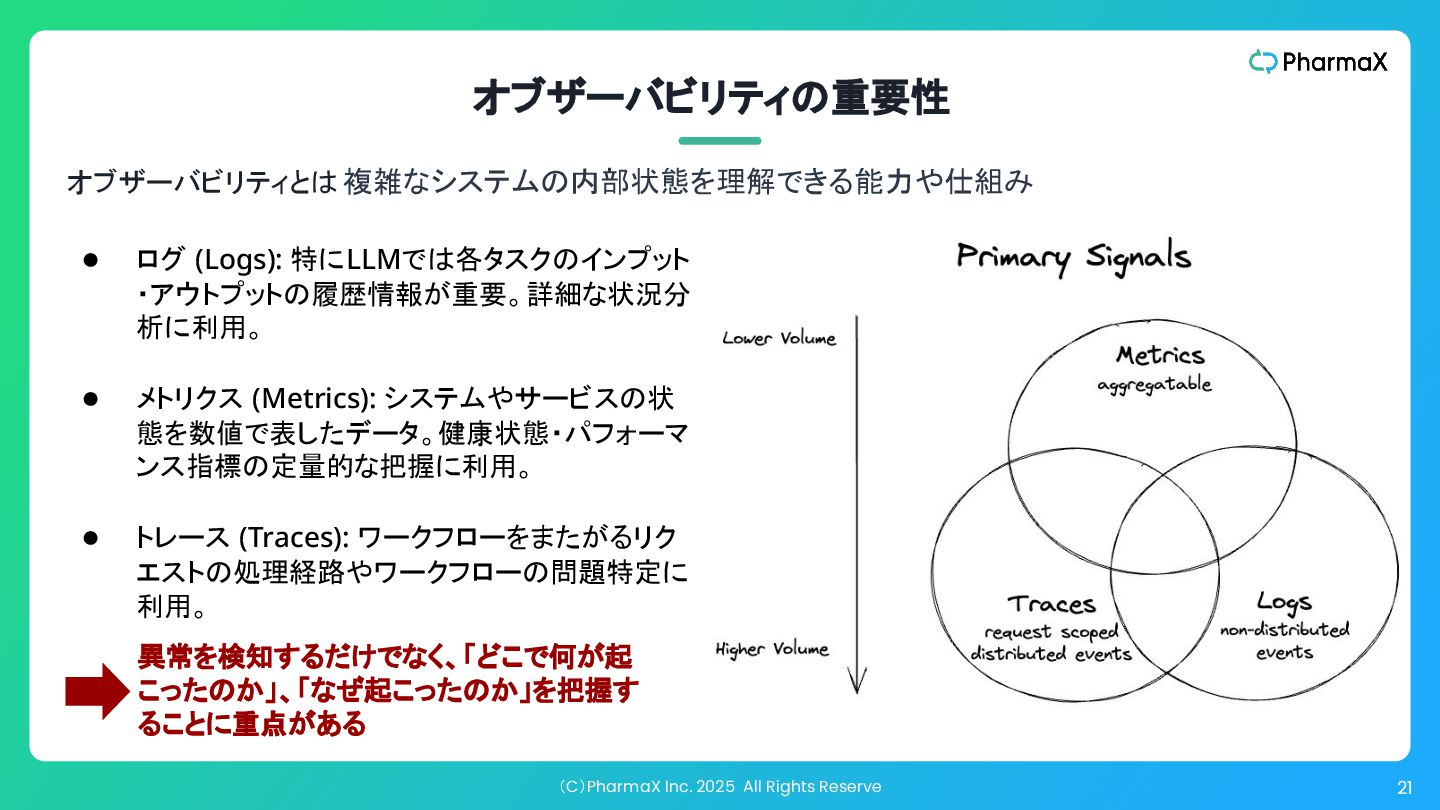
(C)PharmaX Inc. 2025 All Rights Reserve 21 異常を検知するだけでなく、「どこで何が起 こったのか」、「なぜ起こったのか」を把握す ることに重点がある
オブザーバビリティの重要性 オブザーバビリティとは 複雑なシステムの内部状態を理解できる能力や仕組み • ログ (Logs): 特にLLMでは各タスクのインプット ・アウトプットの履歴情報が重要。詳細な状況分 析に利用。 • メトリクス (Metrics): システムやサービスの状 態を数値で表したデータ。健康状態・パフォーマ ンス指標の定量的な把握に利用。 • トレース (Traces): ワークフローをまたがるリク エストの処理経路やワークフローの問題特定に 利用。
(C)PharmaX Inc. 2025 All Rights Reserve 22 LLMアプリケーションにおけるオブザーバビリティの例 問い合わせ対応するAIチャットボットを運用していたとする、、、 •
ログの活用 :ユーザー質問と生成された回答のペアを分析し、「どんな種類の質問で的外れな回答が増え ているか」というパターンを発見可能 • メトリクスの活用 :評価の回答品質スコアの時系列変化を見ると、「先週火曜日の夕方から急激に品質スコ アが低下している」ことが判明する • トレースの活用 :回答生成の各ステップを追跡すると、「外部知識ベースへの接続が失敗している」「プロン プト前処理部分が正しく動作していない」といった具体的な処理の問題点を特定できる 3つの情報を組み合わせることで、、、 「先週のプロンプト更新でトークン節約のため説明文を短くしたところ、ナレッジベースを検索して回答に含めてく ださい』という重要な指示部分まで削除されてしまい、 LLMが社内データベースを参照せずに回答するようになっ た」という根本原因にたどり着ける 「チャットボットの回答品質が下がった」という現象を検知するだけでなく、「なぜ下がったのか」「ど のように修正すべきか」まで迅速に把握できる
(C)PharmaX Inc. 2025 All Rights Reserve 23 LLMOpsの重要プラクティス抜粋 必ずしもモデルのアップデートを伴わないため、改善サイクルを短くできるのが MLOpsの特徴
• オブザーバビリティ(ログ・メトリクス・トレース) ◦ ログやメトリクスは従来のシステムに対する考え方の延長線上で理解・カバーしやすいの で、トレースに説明の重点を置く • プロンプトやパラメータを中心とする変更履歴管理 ◦ 学習を伴わない従来の機械学習モデルと比較すると変更することもそのものも履歴の管 理も非常に簡単になった ◦ 非エンジニア以外も変更可能にすることができれば改善速度がさらに向上 • 出力の評価 ◦ 従来の機械学習と比較しても自由度が高く、精度を評価しづらい&多面的な評価が必要 ◦ 評価結果を定量的に表すことができれば、メトリクスの一種として捉えられる
24 (C)PharmaX Inc. 2025 All Rights Reserve トレーシングとプロンプト管理
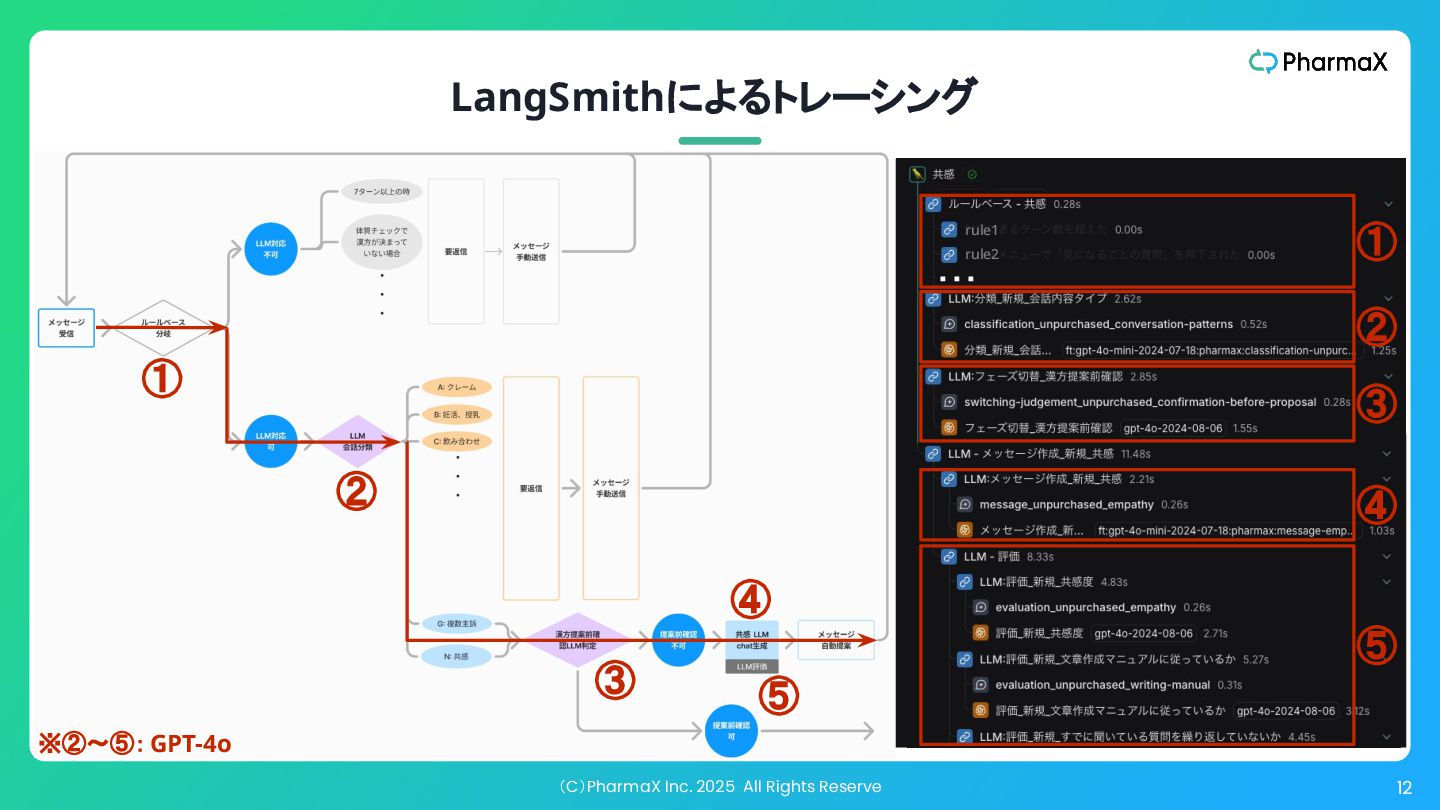
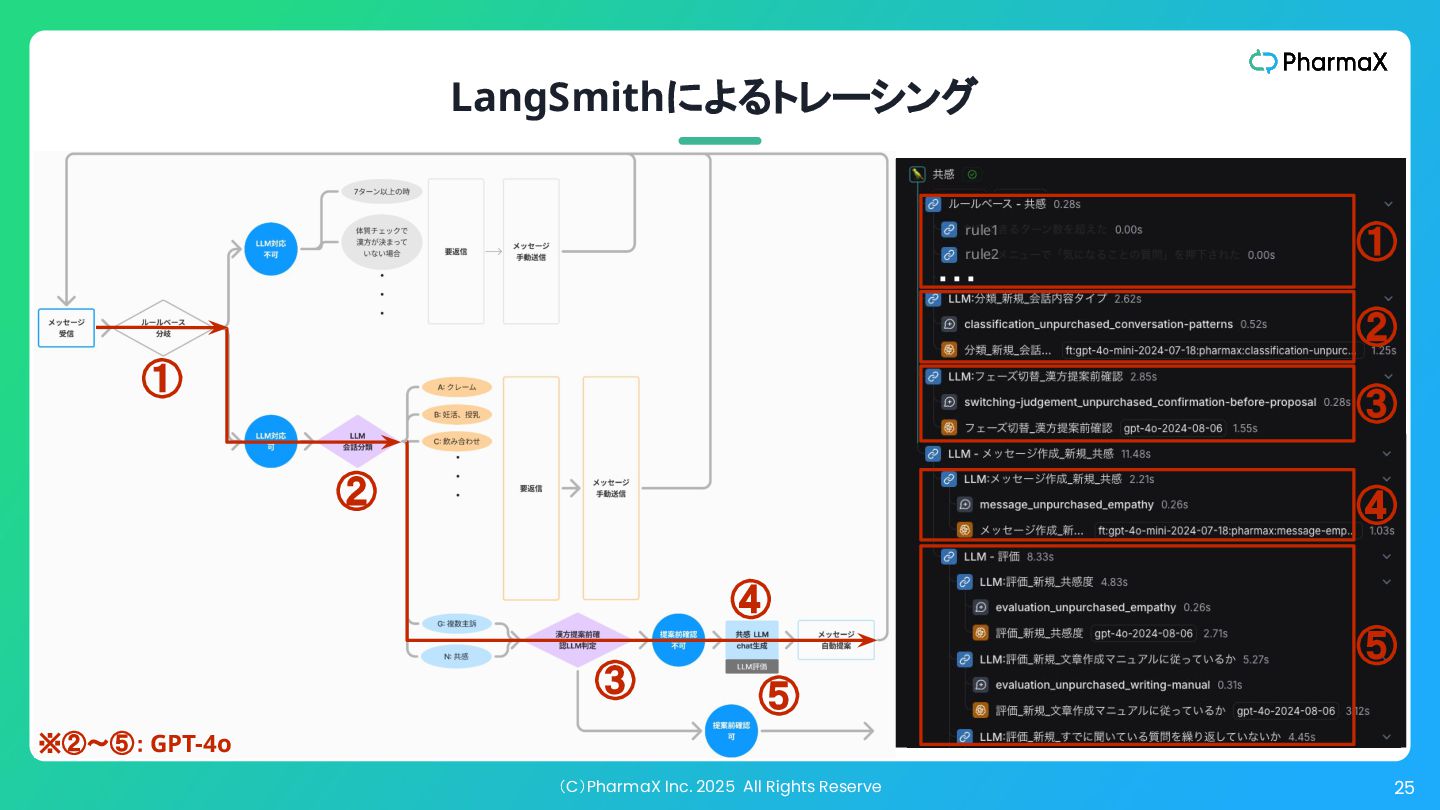
(C)PharmaX Inc. 2025 All Rights Reserve 25 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ① ② ④ ③ ⑤ ※②〜⑤: GPT-4o
(C)PharmaX Inc. 2025 All Rights Reserve 26 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ① ② ④ ③ ⑤ ※②〜⑤: GPT-4o
(C)PharmaX Inc. 2025 All Rights Reserve 27 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ① ② ④ ③ ⑤ ※②〜⑤: GPT-4o
(C)PharmaX Inc. 2025 All Rights Reserve 28 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ① ② ④ ③ ⑤ ※②〜⑤: GPT-4o
(C)PharmaX Inc. 2025 All Rights Reserve 29 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ① ② ④ ③ ⑤ ※②〜⑤: GPT-4o
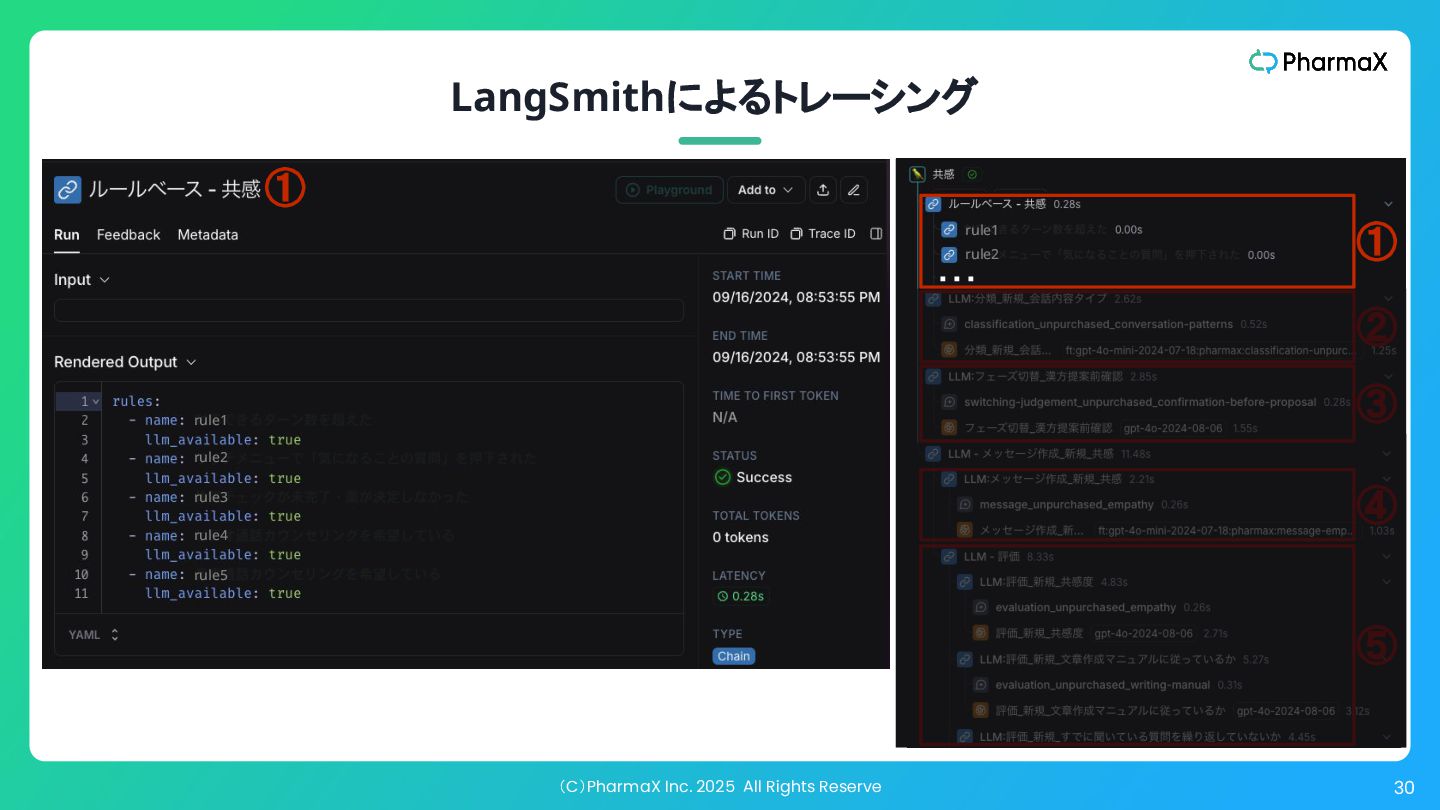
(C)PharmaX Inc. 2025 All Rights Reserve 30 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ rule1 rule2 rule3 rule4 rule5 ①
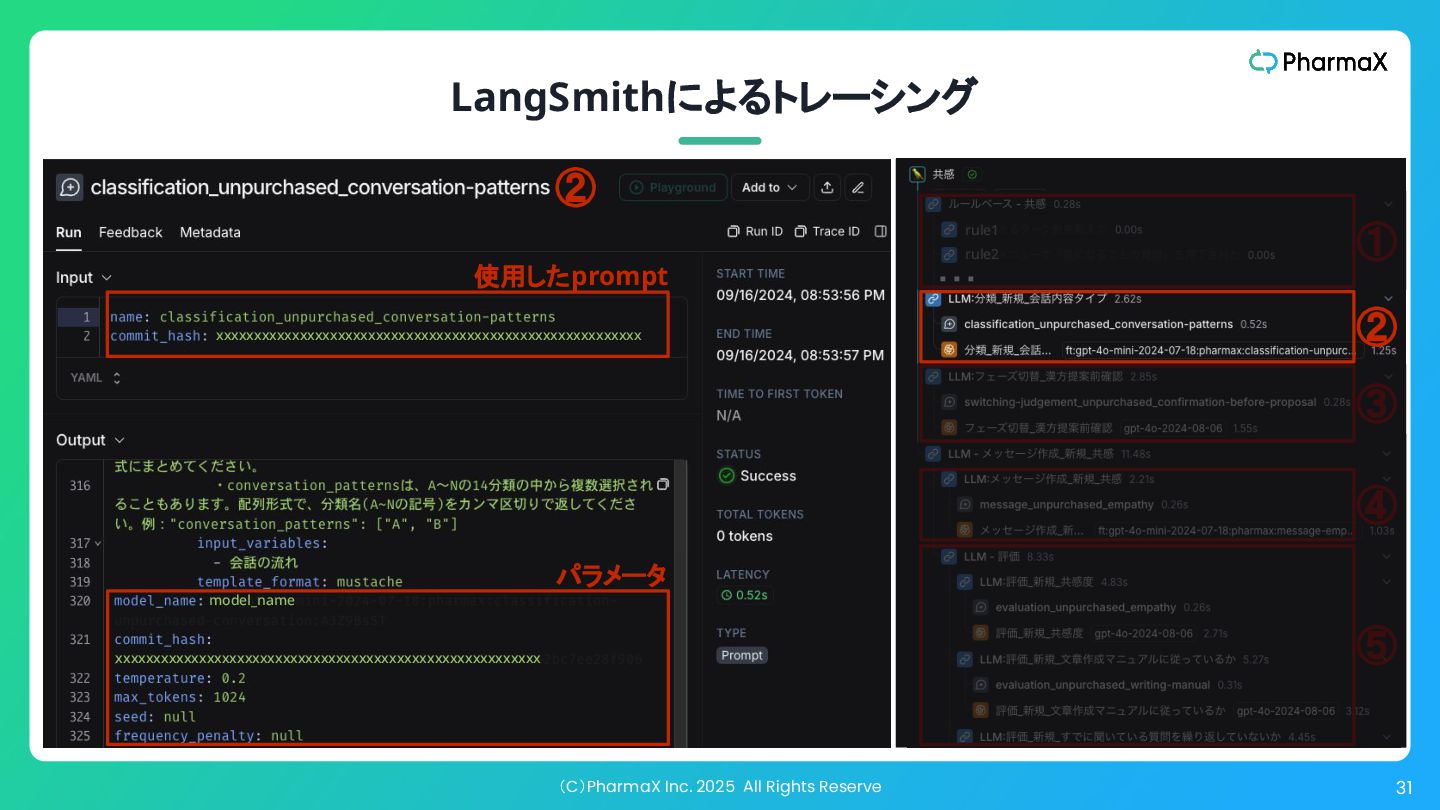
(C)PharmaX Inc. 2025 All Rights Reserve 31 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ ② model_name xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx パラメータ 使用したprompt
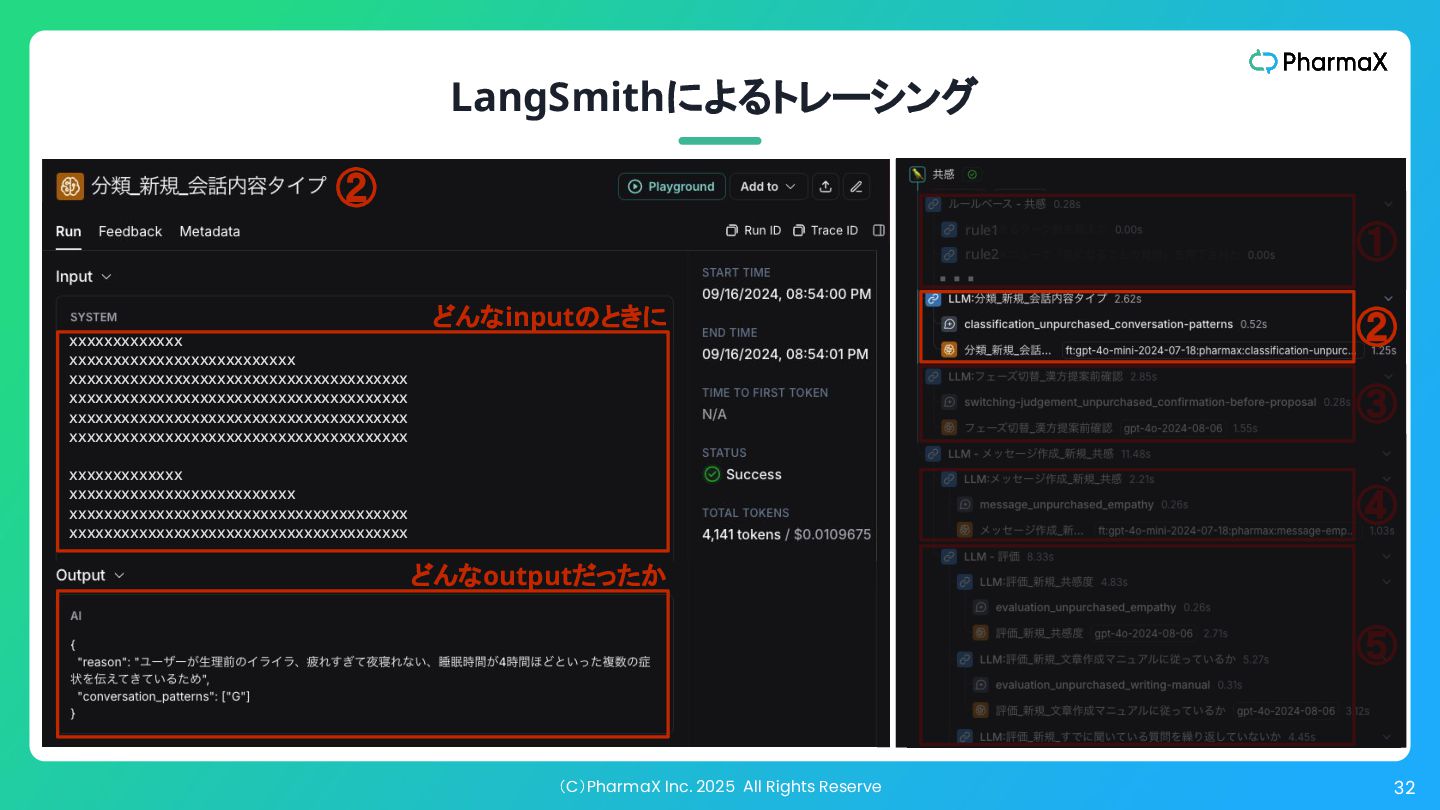
(C)PharmaX Inc. 2025 All Rights Reserve 32 LangSmithによるトレーシング rule1 ①
② ③ ④ ⑤ ・・・ rule2 ④ ⑤ xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx どんなoutputだったか どんなinputのときに ②
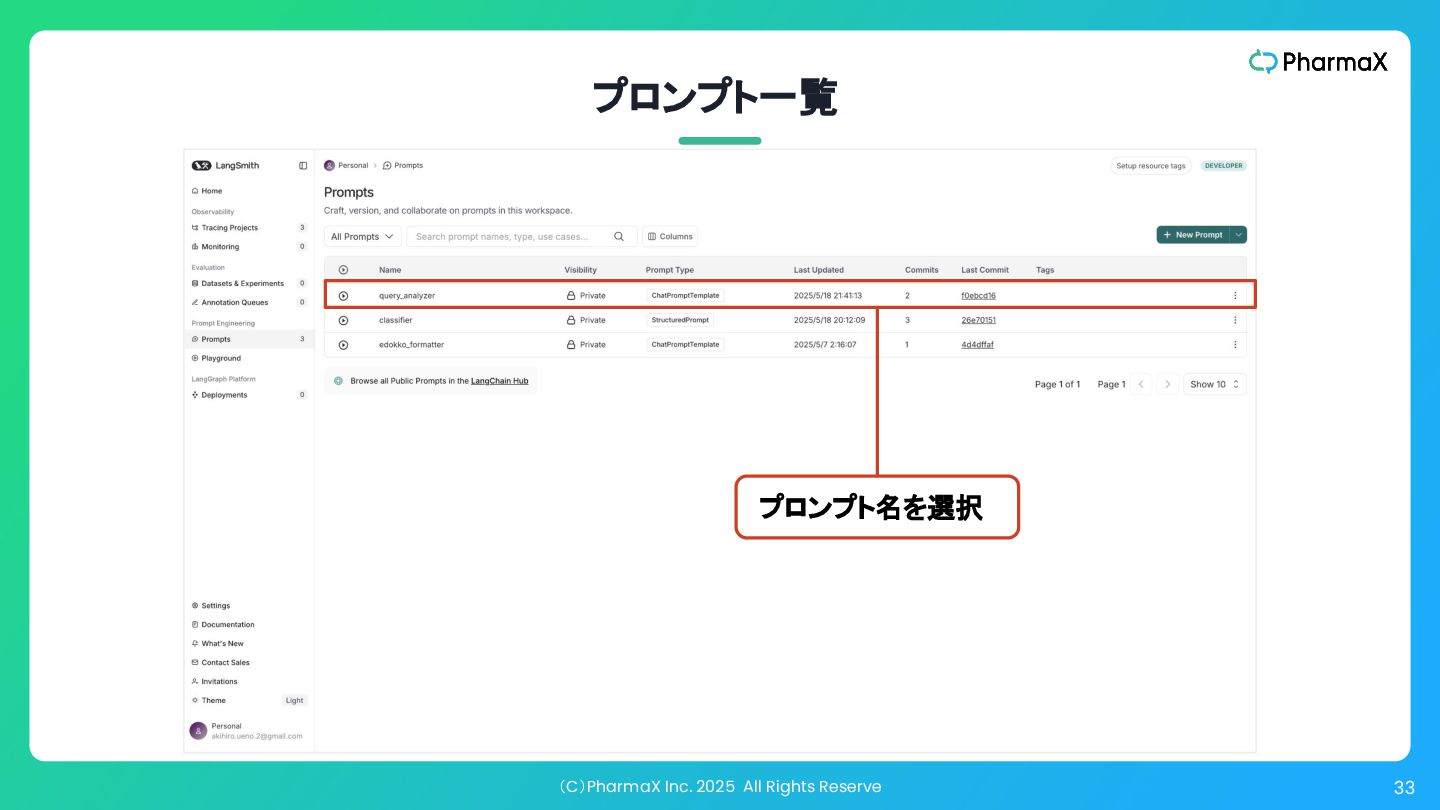
(C)PharmaX Inc. 2025 All Rights Reserve 33 プロンプト一覧 プロンプト名を選択
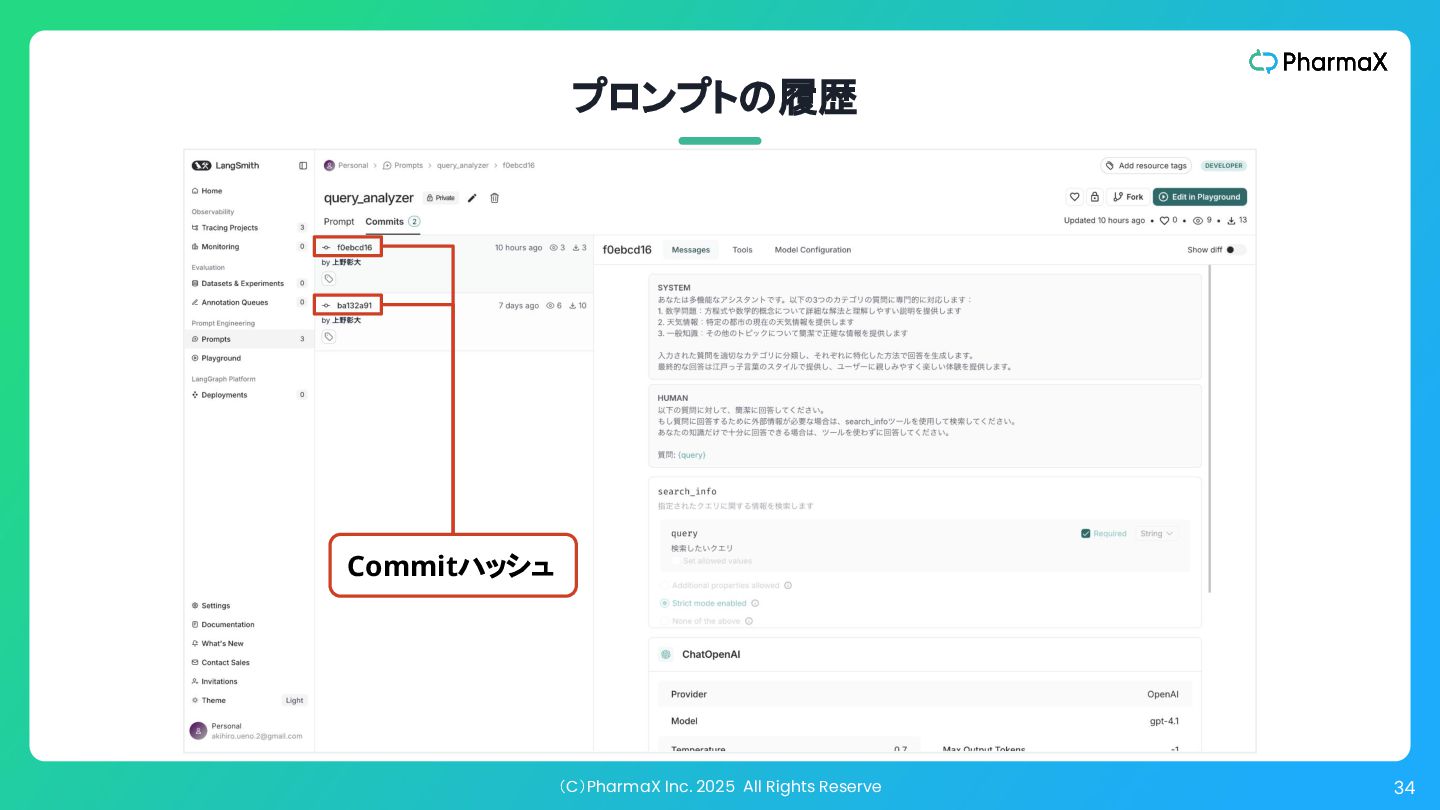
(C)PharmaX Inc. 2025 All Rights Reserve 34 プロンプトの履歴 Commitハッシュ
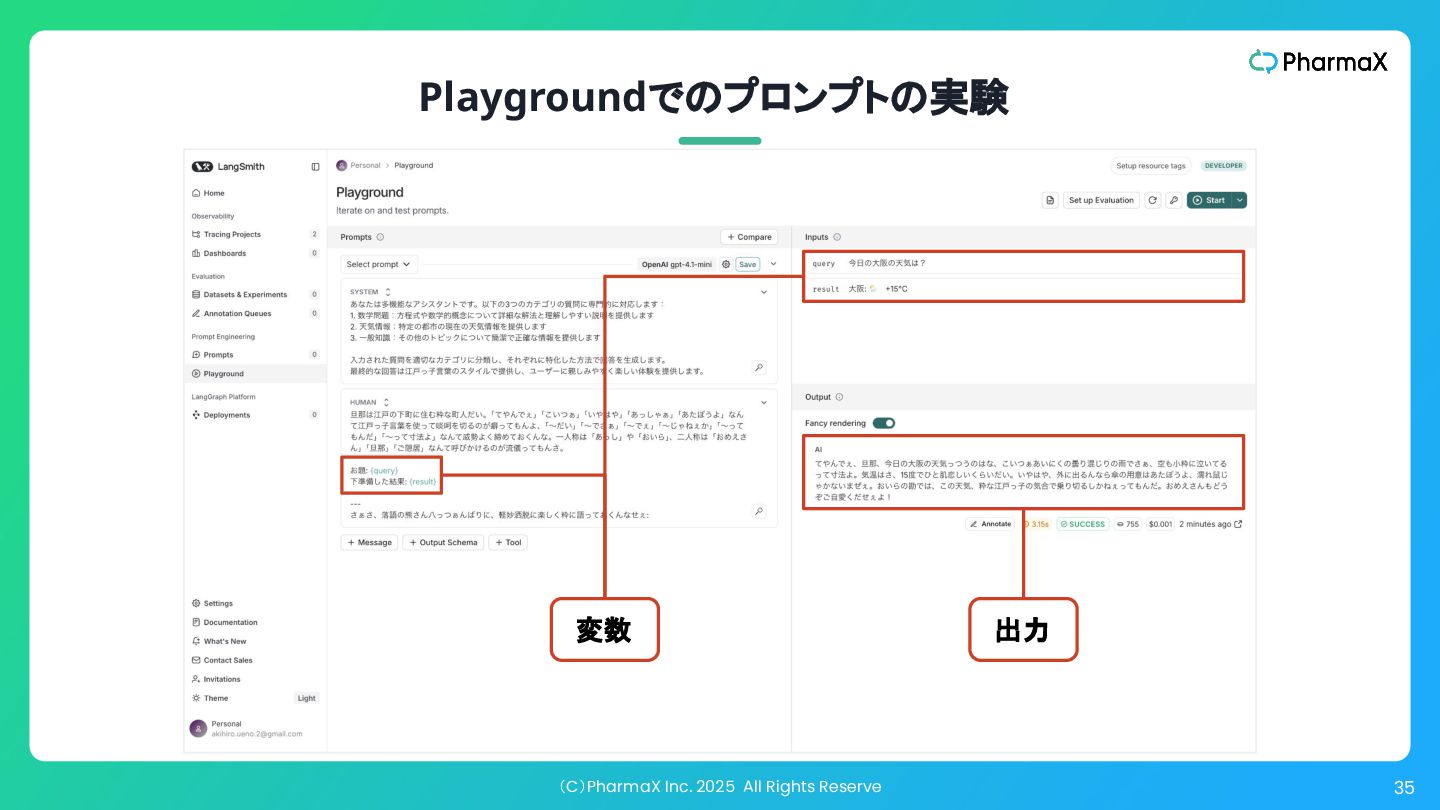
(C)PharmaX Inc. 2025 All Rights Reserve 35 Playgroundでのプロンプトの実験 変数 出力
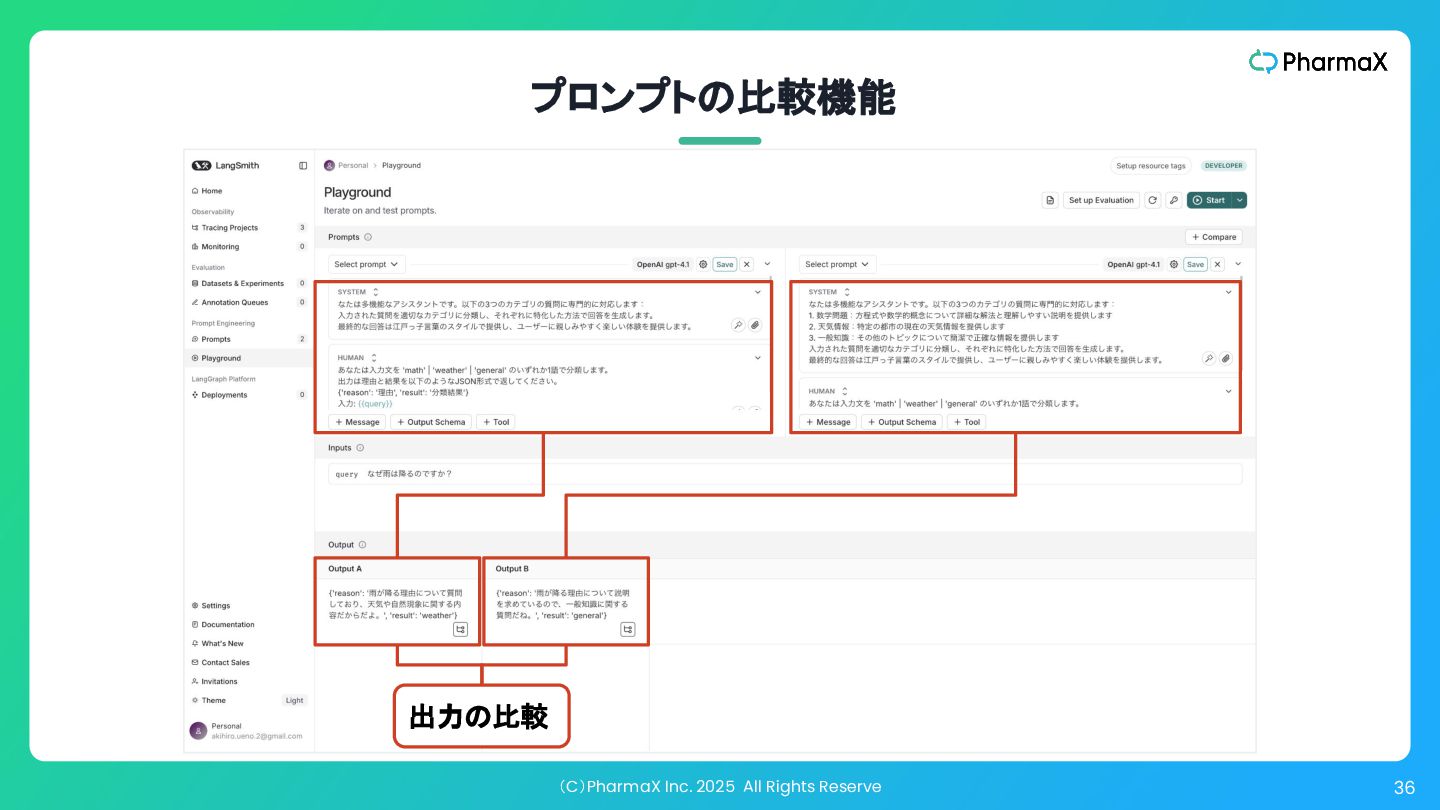
(C)PharmaX Inc. 2025 All Rights Reserve 36 プロンプトの比較機能 出力の比較
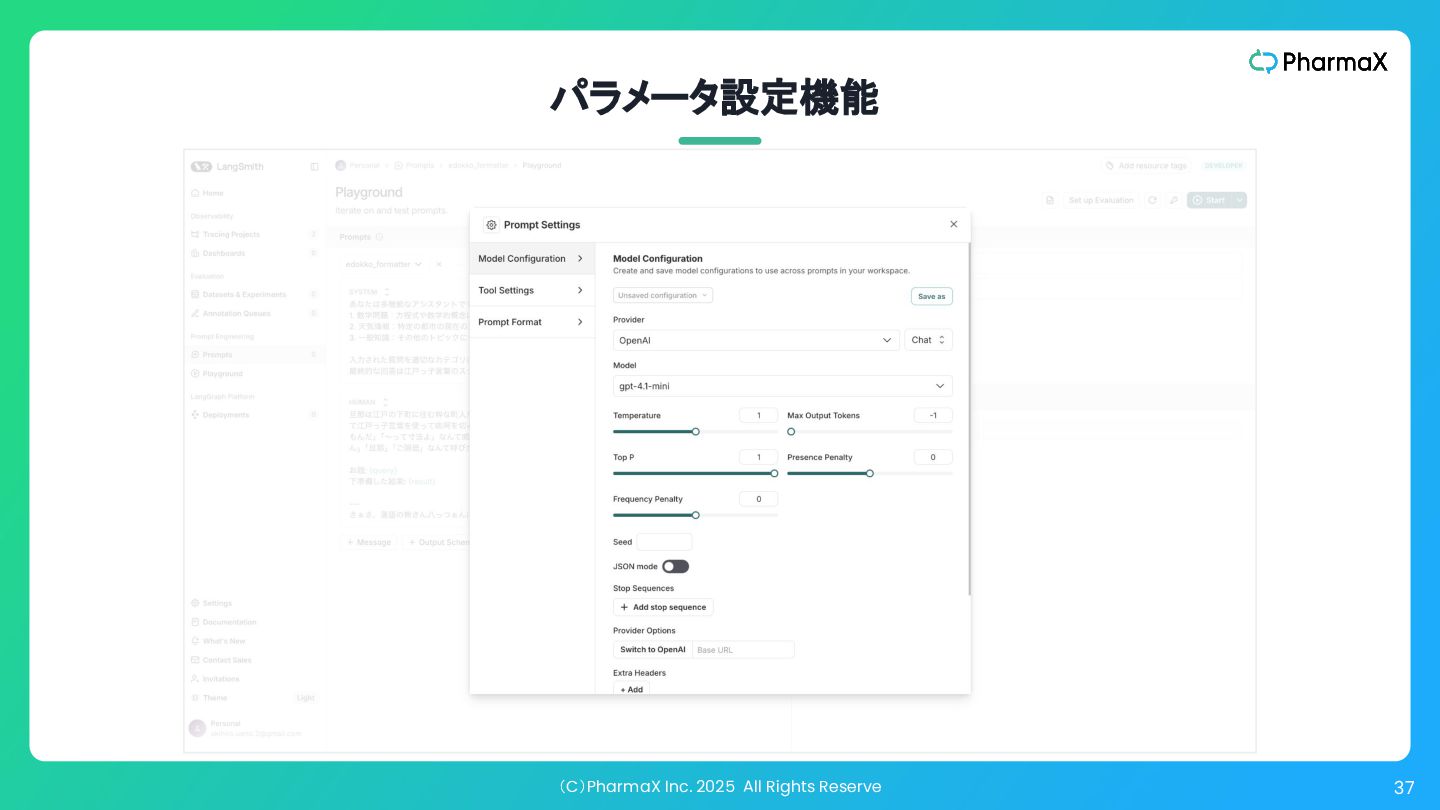
(C)PharmaX Inc. 2025 All Rights Reserve 37 パラメータ設定機能
(C)PharmaX Inc. 2025 All Rights Reserve 38 • LangSmithを使うことで、処理の過程が記録されるため、どこでどのような出力がされて、どこ でなぜ処理が終了したのかが一目瞭然
◦ ルールベース処理のようなLLMではない処理も記録することが可能 ◦ どのRunにどのプロンプトが使用されていたのか?ということも分かる • プロンプトやパラメータのバージョン管理も LangSmith上で行うことで、どのバージョンのときに どのような処理がされていたのかを後から確認することができる ◦ 開発者以外も含む複数人でプロンプト等を変更できるため、高速で PDCAを回すことが可 能になる ◦ 後述するオンライン評価でもどのタイミングでプロンプトやパラメータを変更したかを確認で きることは重要 LangSmithによるトレースとプロンプト管理 LangSmithを活用することでAgentic Workflowの処理のトレースの可視化とプロンプトの履歴管理
39 (C)PharmaX Inc. 2025 All Rights Reserve LLMの出力の評価
(C)PharmaX Inc. 2025 All Rights Reserve 40 評価とはなにか?なぜ評価が必要なのか • AIの出力の評価とは、AIの出力結果の”良し悪し”を定量的・定性的に判断すること
• 分類問題や回帰問題などであれば、単純に正答率や誤差を評価すればいい • 一方で自由度の高いLLMの出力の評価は、分類問題などとは異なり、正解が 1つに定まるわけ でないので難しい ◦ 例えば、「日本で一番高い山は?」という質問に「富士山」「富士山です」「富士山に決まってんだろー が!」「富士山。標高 3776.12 m。その優美な風貌は …(略)」と答えるのはどれも正解 • LLMの出力を定量的に評価できれば、プロンプトやパラメータの変更前後で評価の平均点を比 べるというような統計的な比較も可能になる AIの出力の評価に関するプラクティス自体は LLMの発展の前から存在していたが、 LLM特有の論点もある
(C)PharmaX Inc. 2025 All Rights Reserve 41 出力の質の評価指標のパターン LLMアプリケーションの出力結果の評価という時にも、複数の評価指標を指すことがあるので注意 •
ヒューリスティックな自動評価では限界がある ◦ 「絵文字は2つまで」のようなレベルならルールベースで評価することも可能 ◦ 期待するアウトプットと実際のアウトプットを( embedding distanceやlevenshtein distanceで)比較してスコアリングすることはできる • LLMエージェントの出力の妥当性をLLMでスコアリング(合格/不合格判定)する LLM-as-a-Judgeも有効 ◦ 一般的な観点だけではなく、下記のようなアプリケーション独自の観点でも評価する必要が ある ▪ 自社の回答のライティングマニュアルに従っているか ▪ (VTuberなどが)キャラクター設定に合っているか
(C)PharmaX Inc. 2025 All Rights Reserve 42 評価用のプロンプトのイメージ LLMからのメッセージ提案を評価させるためのプロンプトを定義し、 LLMにLLMの評価をさせる
System あなた(assistant)には、別のassistant(chat-assistant)のメッ セージを評価していただきます。 ## chat-assistantの前提 chat-assistantの役割は、PharmaX株式会社のYOJOという サービスのかかりつけ薬剤師です。健康や漢方の専門家とし て、常にユーザーの感情に寄り添いアドバイスをします。 ...(略) User chat-assistantの最後の返答がどの程度下記の文章作成マニュ アルに従っているかで0〜100点のスコアを付けて下さい ## 文章のライティング方針 ・丁寧に対応する ・謝罪では絵文字を使わずに、文章だけで表現する ・難しい漢字はひらがなで書く ・細かい説明は箇条書きで書く ...(略) 評価用プロンプト
(C)PharmaX Inc. 2025 All Rights Reserve 43 LLM-as-a-Judgeの必要性 LLMアプリケーションの出力結果を LLMで評価することをLLM-as-a-Judgeという
• LLMの出力を人が評価するのは、工数・コスト・速度の観点から限界があるので、 LLMにLLMの 出力を評価をさせようというアイデア ◦ 人で評価する場合、異なる評価者の間で評価基準を一致させるのは難しいが、 LLMなら 可能 ◦ LLMであればプロンプトを作り込めば、専門家にしかできない評価も高精度にさせることが できる
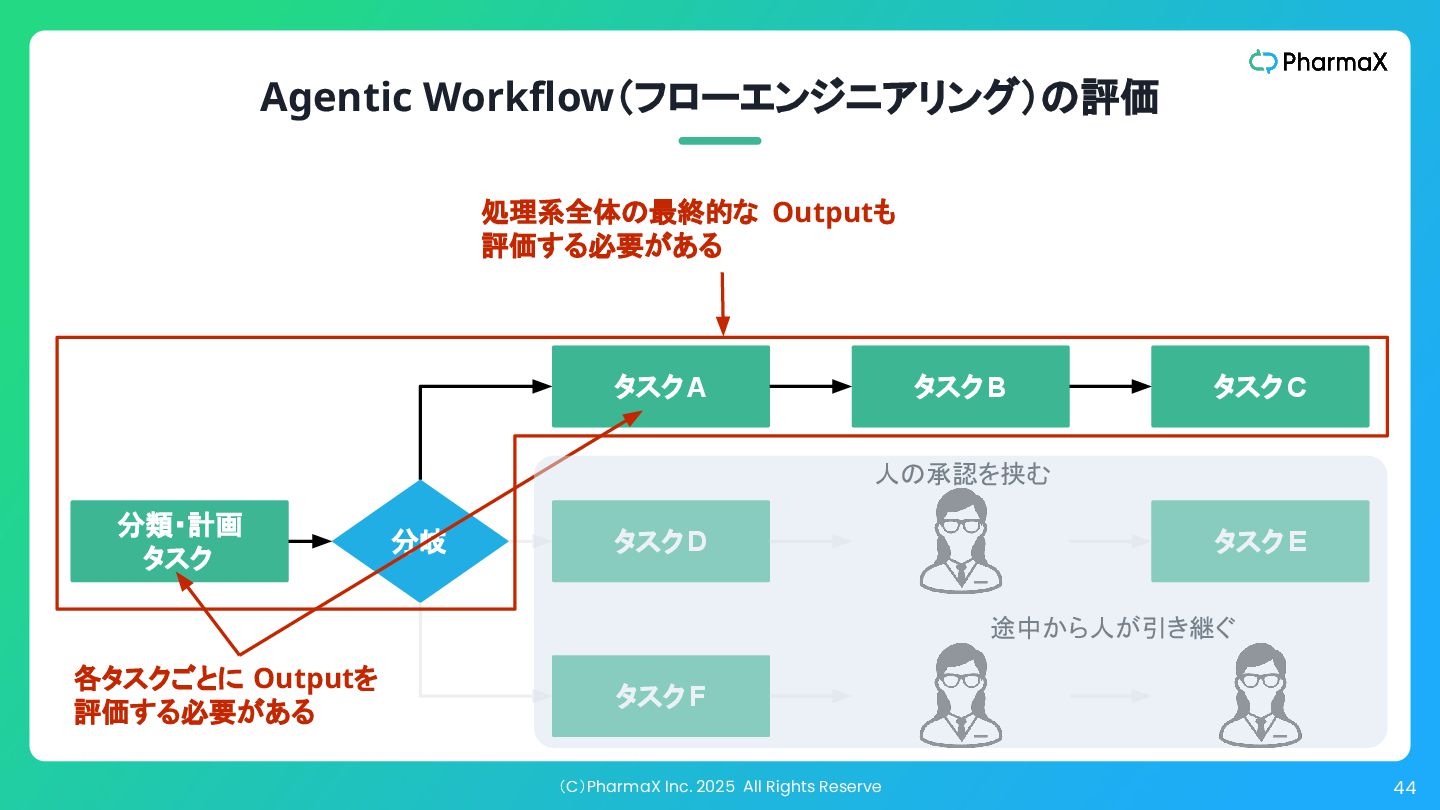
(C)PharmaX Inc. 2025 All Rights Reserve 44 Agentic Workflow(フローエンジニアリング)の評価 分類・計画
タスク タスクA タスクB タスクC タスクD タスクE タスクF 分岐 人の承認を挟む 途中から人が引き継ぐ 処理系全体の最終的な Outputも 評価する必要がある 各タスクごとに Outputを 評価する必要がある
45 (C)PharmaX Inc. 2025 All Rights Reserve リリース前の評価
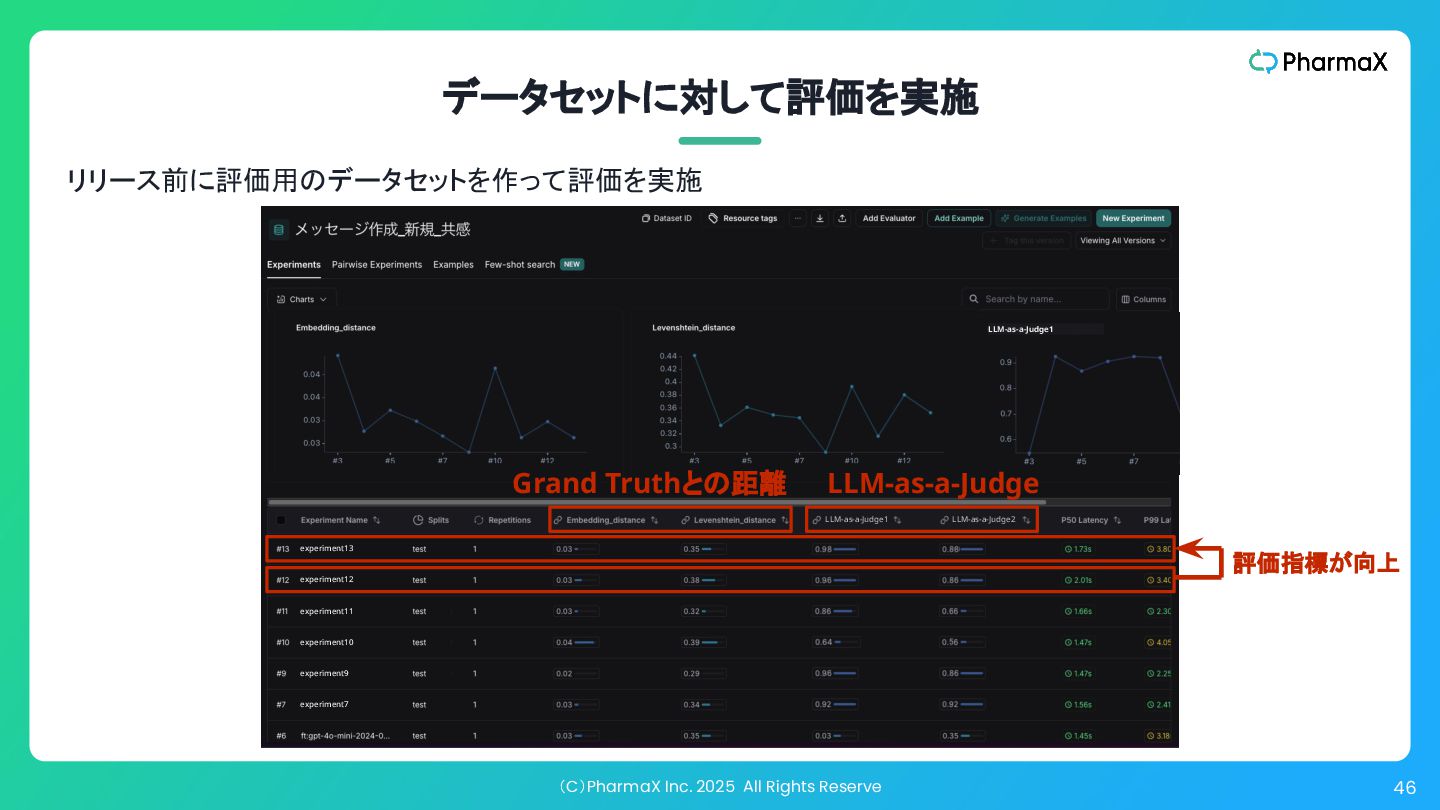
(C)PharmaX Inc. 2025 All Rights Reserve 46 データセットに対して評価を実施 リリース前に評価用のデータセットを作って評価を実施 experiment6
experiment13 experiment12 experiment11 experiment10 experiment9 experiment7 LLM-as-a-Judge1 LLM-as-a-Judge2 LLM-as-a-Judge1 評価指標が向上 LLM-as-a-Judge Grand Truthとの距離
47 (C)PharmaX Inc. 2025 All Rights Reserve リリース後評価
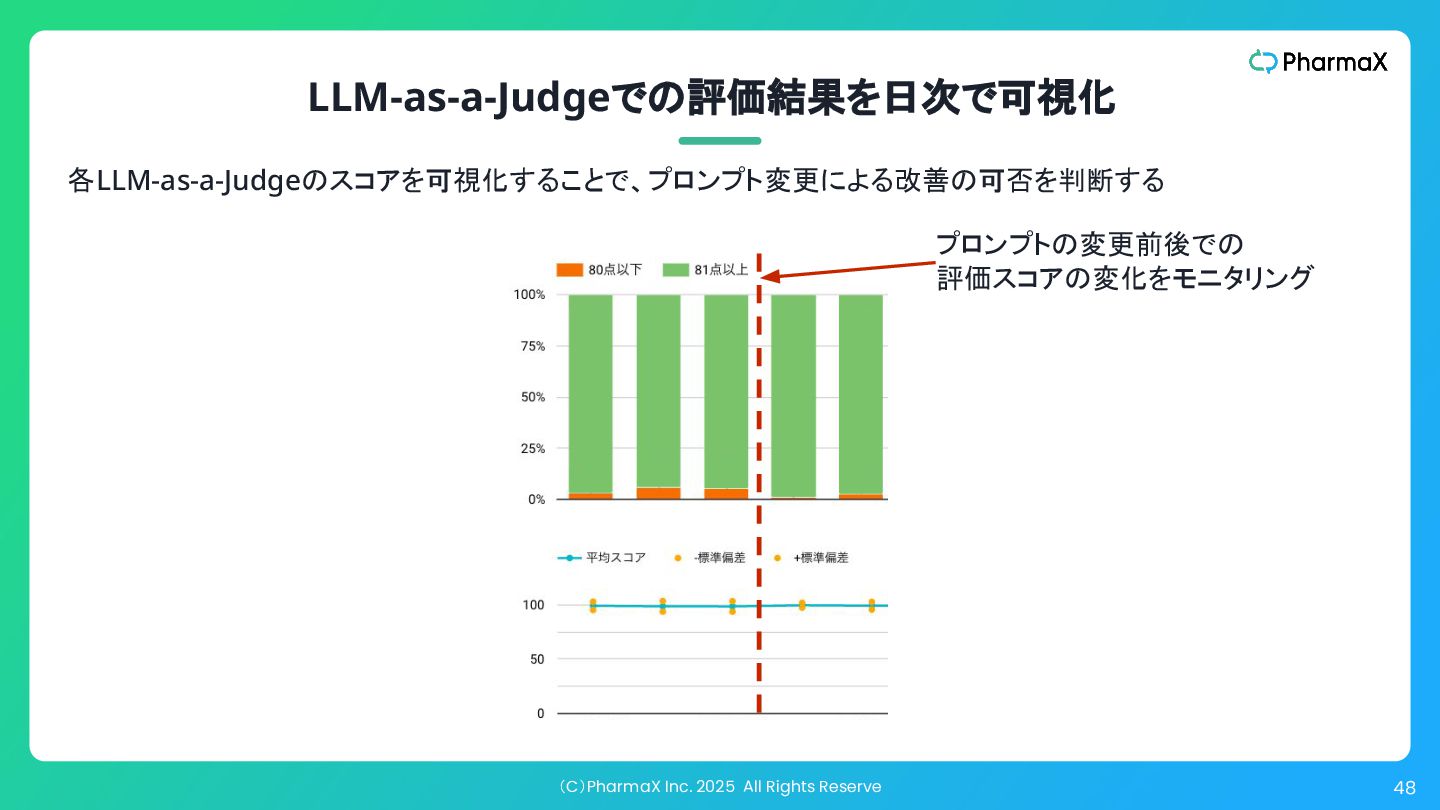
(C)PharmaX Inc. 2025 All Rights Reserve 48 プロンプトの変更前後での 評価スコアの変化をモニタリング LLM-as-a-Judgeでの評価結果を日次で可視化
各LLM-as-a-Judgeのスコアを可視化することで、プロンプト変更による改善の可否を判断する
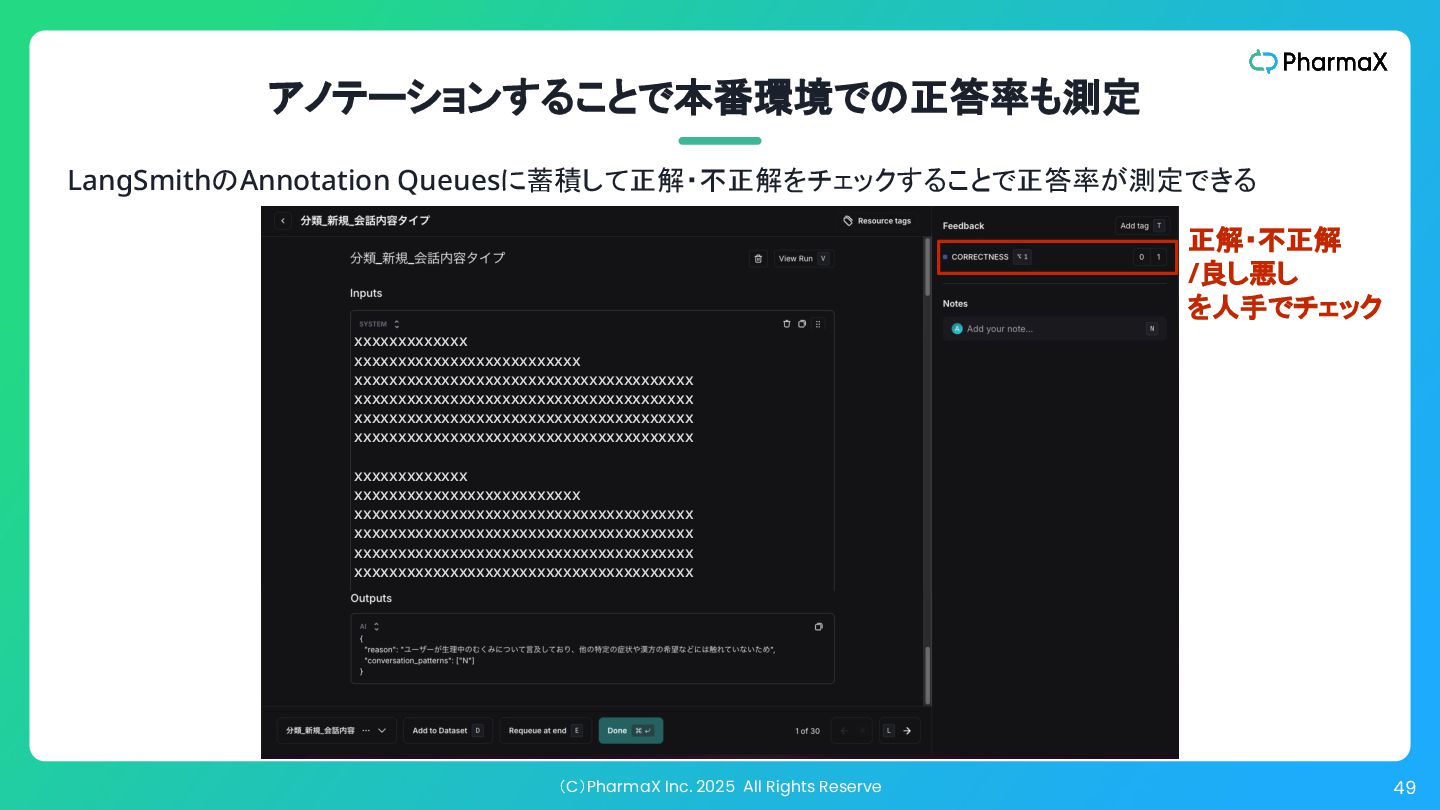
(C)PharmaX Inc. 2025 All Rights Reserve 49 アノテーションすることで本番環境での正答率も測定 xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 正解・不正解 /良し悪し を人手でチェック LangSmithのAnnotation Queuesに蓄積して正解・不正解をチェックすることで正答率が測定できる
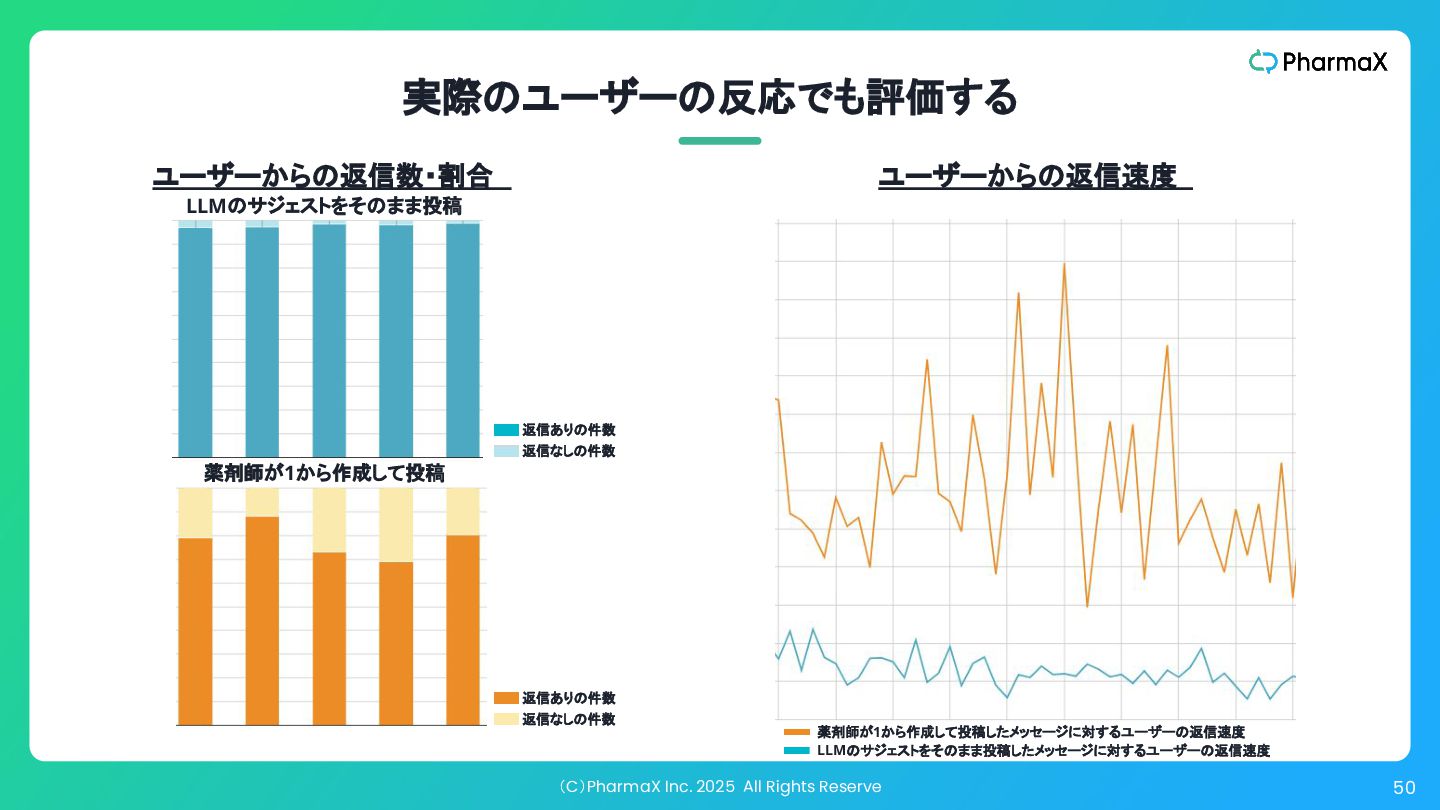
(C)PharmaX Inc. 2025 All Rights Reserve 50 実際のユーザーの反応でも評価する ユーザーからの返信数・割合 返信ありの件数
返信なしの件数 返信ありの件数 返信なしの件数 LLMのサジェストをそのまま投稿 薬剤師が1から作成して投稿 ユーザーからの返信速度 LLMのサジェストをそのまま投稿したメッセージに対するユーザーの返信速度 薬剤師が1から作成して投稿したメッセージに対するユーザーの返信速度
51 (C)PharmaX Inc. 2025 All Rights Reserve リリース後 データセットの運用と継続的改善 〜プロンプトエンジニアリング以外の改善手法〜
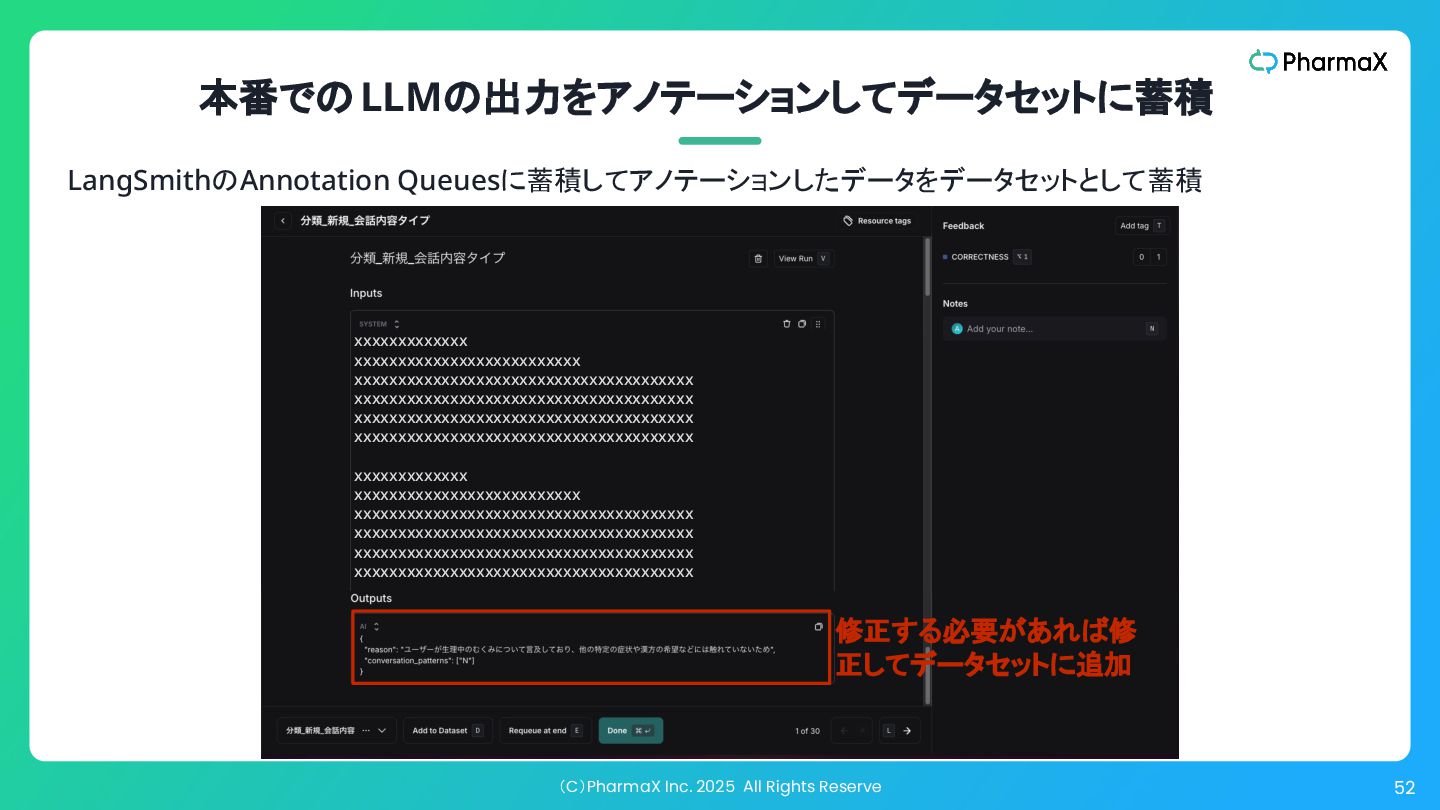
(C)PharmaX Inc. 2025 All Rights Reserve 52 本番でのLLMの出力をアノテーションしてデータセットに蓄積 xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx LangSmithのAnnotation Queuesに蓄積してアノテーションしたデータをデータセットとして蓄積 修正する必要があれば修 正してデータセットに追加
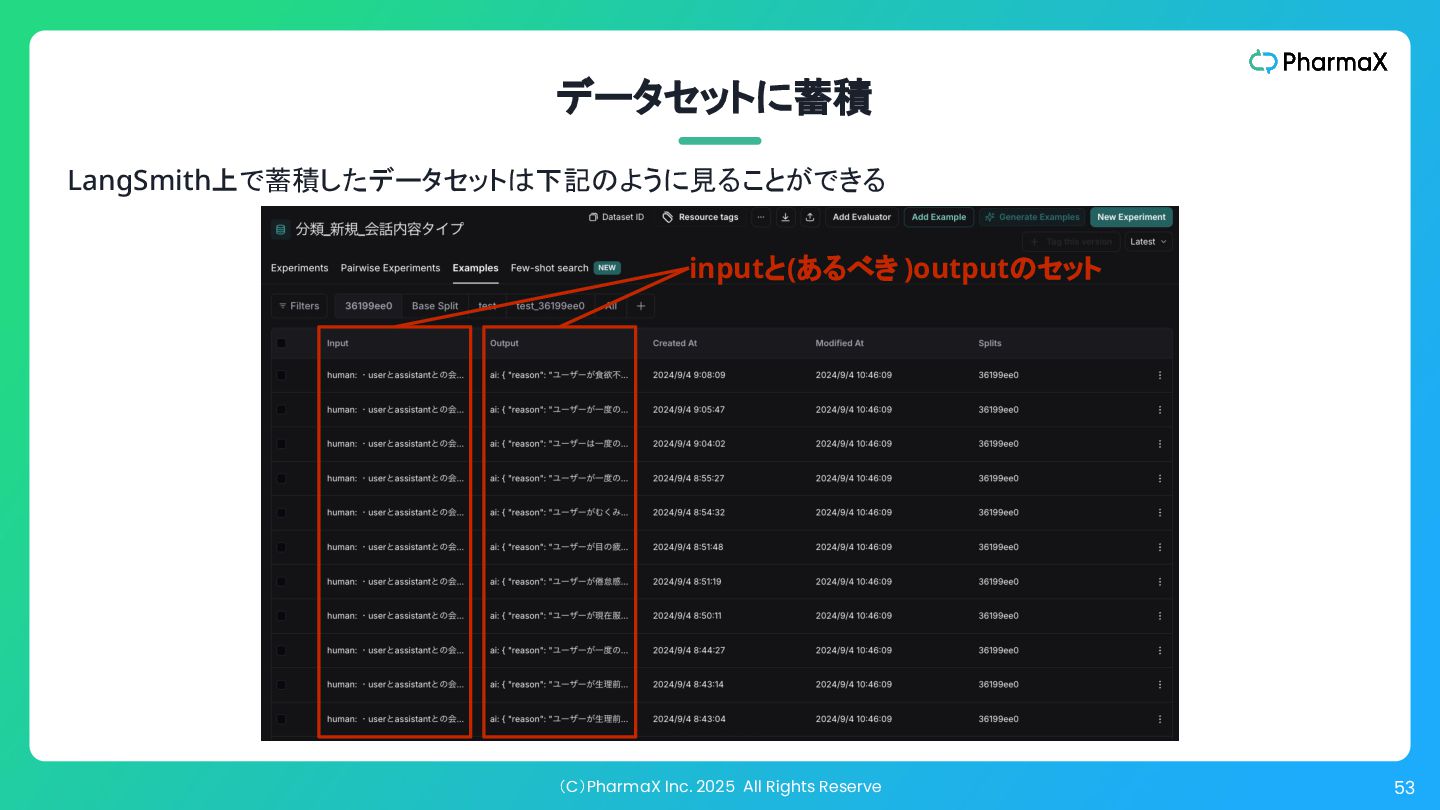
(C)PharmaX Inc. 2025 All Rights Reserve 53 データセットに蓄積 LangSmith上で蓄積したデータセットは下記のように見ることができる inputと(あるべき
)outputのセット
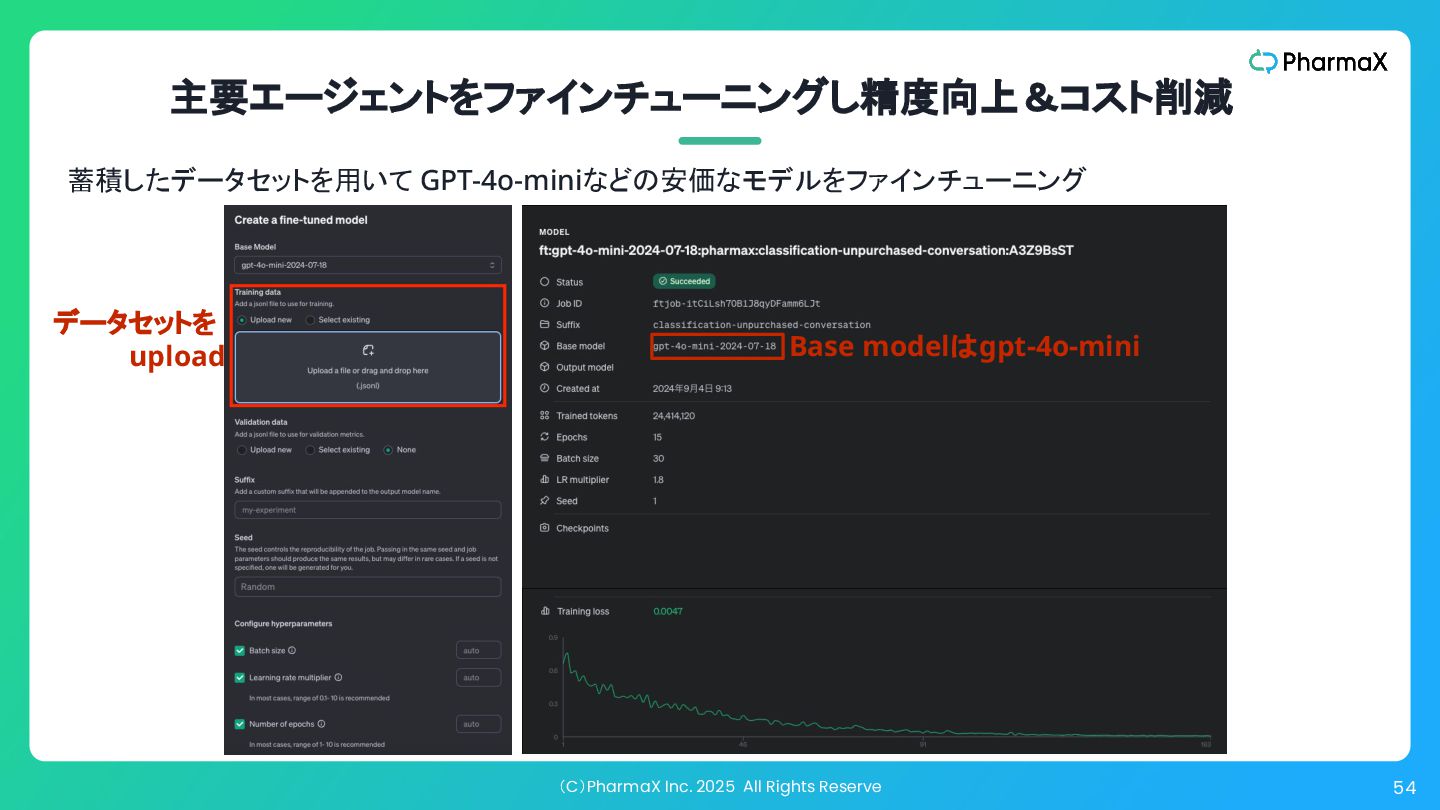
(C)PharmaX Inc. 2025 All Rights Reserve 54 主要エージェントをファインチューニングし精度向上&コスト削減 蓄積したデータセットを用いて GPT-4o-miniなどの安価なモデルをファインチューニング
データセットを upload Base modelはgpt-4o-mini
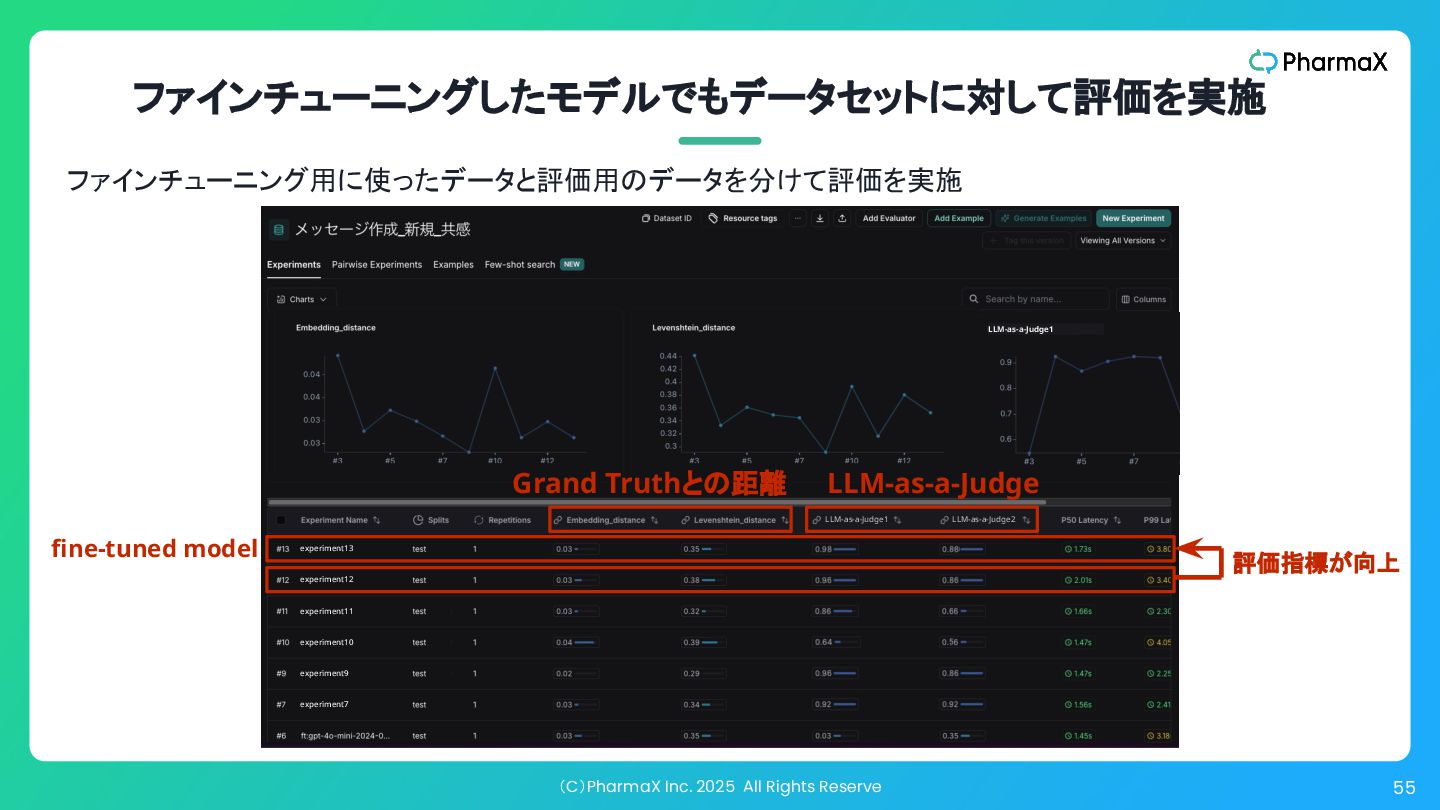
(C)PharmaX Inc. 2025 All Rights Reserve 55 ファインチューニングしたモデルでもデータセットに対して評価を実施 ファインチューニング用に使ったデータと評価用のデータを分けて評価を実施 experiment6
experiment13 experiment12 experiment11 experiment10 experiment9 experiment7 LLM-as-a-Judge1 LLM-as-a-Judge2 LLM-as-a-Judge1 fine-tuned model 評価指標が向上 LLM-as-a-Judge Grand Truthとの距離
(C)PharmaX Inc. 2025 All Rights Reserve 56 ファインチューニングしたモデルのコスト削減効果 gpt-4o-2024-08-06
$2.50 / 1M input tokens $10.00 / 1M output tokens gpt-4o-2024-05-13 $5.00 / 1M input tokens $15.00 / 1M output tokens gpt-4o-mini $0.150 / 1M input tokens $0.600 / 1M output tokens fine-tuned gpt-4o-mini $0.30 / 1M input tokens $1.20 / 1M output token ファインチューニングすることで劇的にコストを下げることができる 約1/10
(C)PharmaX Inc. 2025 All Rights Reserve 57 ファインチューニングの運用について • アノテーションしてGPT-4oの出力を修正したデータセットで
GPT-4o-miniをファインチューニング することができれば、GPT-4oよりも性能が高くかつコストも安いfine-tuned GPT-4o-miniを作 成することができる • 一方で、アノテーションも楽ではないので、性能向上のためにファインチューニングをするのは、 プロンプトエンジニアリングで性能向上が見込めなくなってからの最終手段と捉えた方がいい ◦ プロンプトエンジニアリングの方が PDCAサイクルは短いので、性能向上のための第一選 択はあくまでプロンプトエンジニアリング 性能も高めたいのならアノテーションしてファインチューニングする必要がある
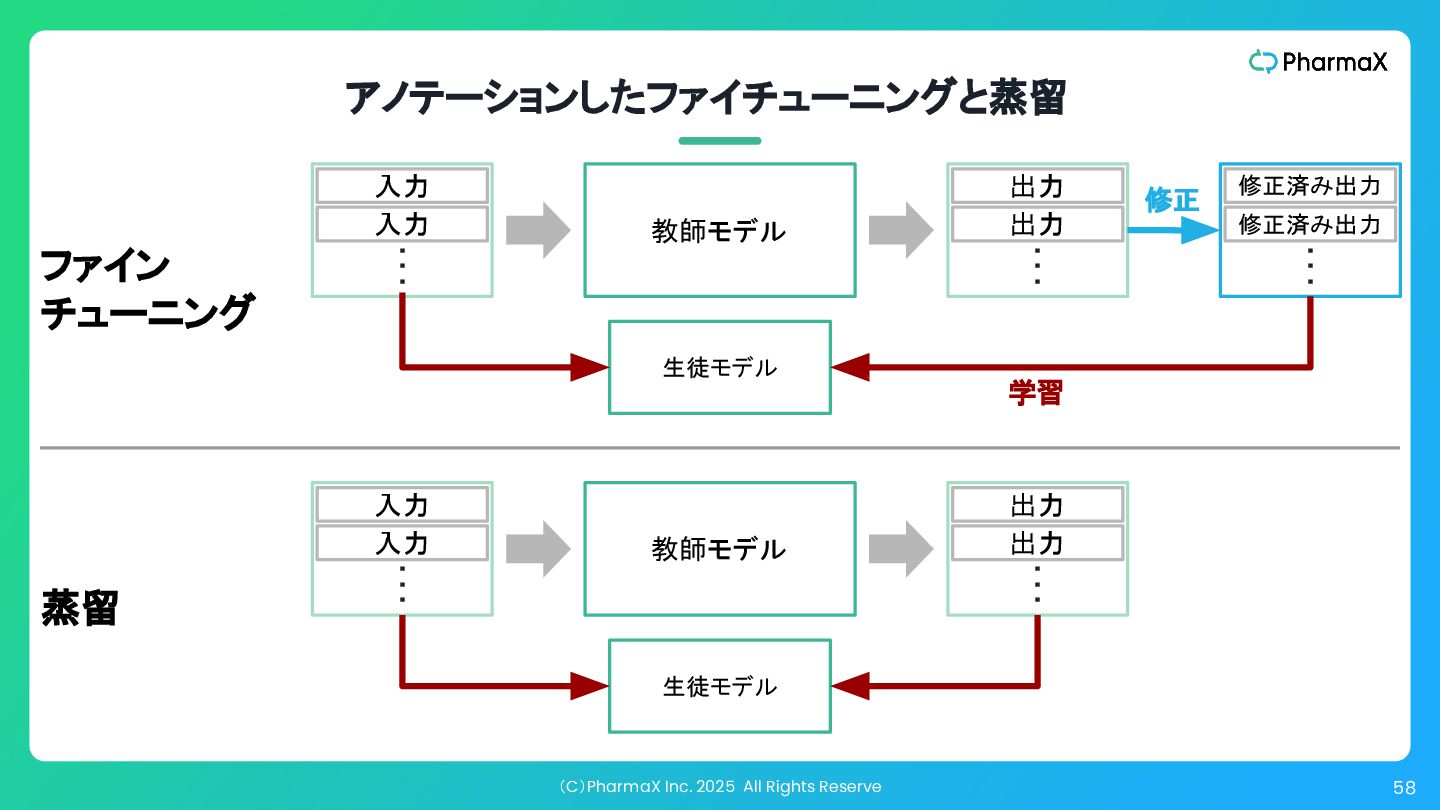
(C)PharmaX Inc. 2025 All Rights Reserve 58 アノテーションしたファイチューニングと蒸留 教師モデル 生徒モデル
入力 入力 ・ ・ ・ 出力 出力 ・ ・ ・ 教師モデル 生徒モデル 入力 入力 ・ ・ ・ 出力 出力 ・ ・ ・ 修正済み出力 修正済み出力 ・ ・ ・ 蒸留 ファイン チューニング 学習 修正
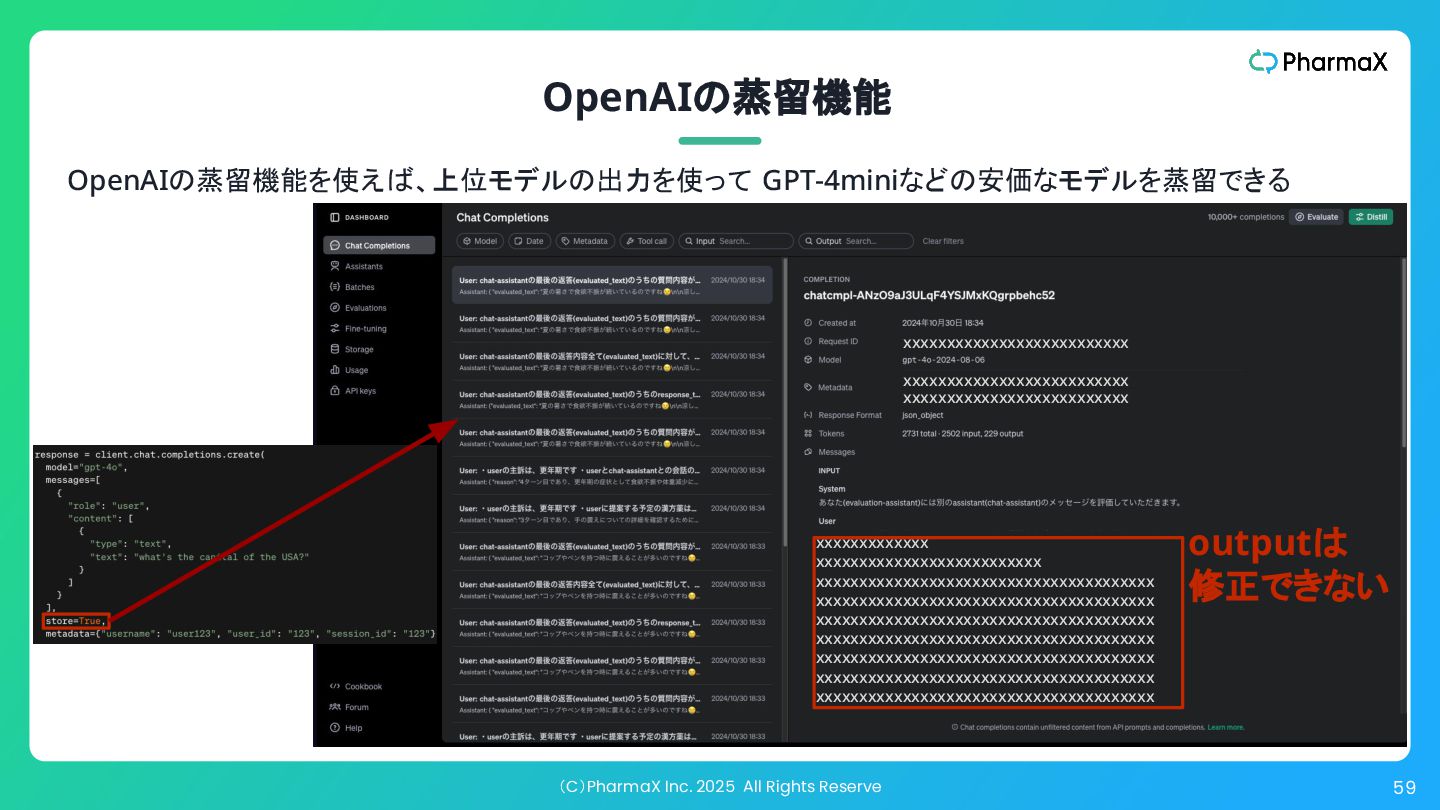
(C)PharmaX Inc. 2025 All Rights Reserve 59 OpenAIの蒸留機能 OpenAIの蒸留機能を使えば、上位モデルの出力を使って GPT-4miniなどの安価なモデルを蒸留できる
xxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxx outputは 修正できない
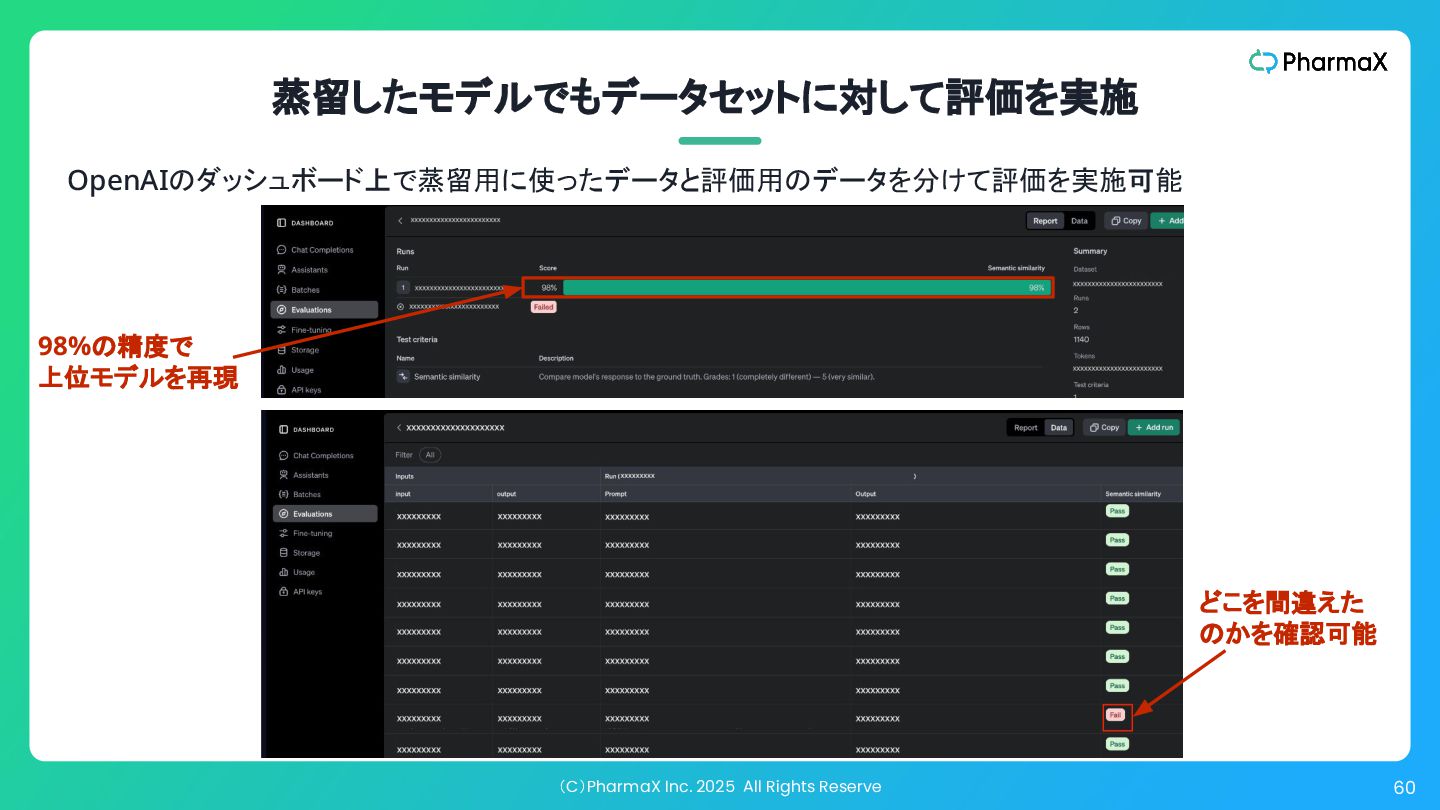
(C)PharmaX Inc. 2025 All Rights Reserve 60 蒸留したモデルでもデータセットに対して評価を実施 OpenAIのダッシュボード上で蒸留用に使ったデータと評価用のデータを分けて評価を実施可能 98%の精度で
上位モデルを再現 どこを間違えた のかを確認可能
(C)PharmaX Inc. 2025 All Rights Reserve 61 • 本番での教師モデルの入出力を使って安価なモデルを 蒸留することができる
◦ OpenAIのネイティブ機能はデータを貯めることそのものには値段がかからないがデータ の修正はできない (※ 最新の公式ドキュメントをご確認ください) • 一方で、蓄積したデータのoutputを修正する機能は付いていないので、精度は元データを生成 した上位のモデルを超えることはない ◦ 上位モデルよりも精度も向上させたければ、 LangSmithのようにアノテーション機能を備 えたツールを使って出力を修正する必要がある ◦ データ数さえ確保できれば元データを生成した上位のモデル弱の精度にはなるので、すで に運用中のアプリケーションがあり、精度がミッションクリティカルでなければ、蒸留して安 価なモデルに置き換えることは十分検討の余地あり 蒸留の運用まとめ 大きなモデルの入出力を使って小さなモデルを学習させることで安価で軽量なモデルを作成可能
62 (C)PharmaX Inc. 2025 All Rights Reserve まとめ
(C)PharmaX Inc. 2025 All Rights Reserve 63 • 現時点ではあまりにも自由度の高い自律型のエージェントではなく、判断基準やワークフローを 定義したAgentic
Workflowがエージェント開発の現実解ではないか • エージェントを継続的に改善し続けるためには、 LLMOpsのプラクティスを取り入れる必要がある ◦ オブザーバビリティを担保し、プロンプトやパラメータなどのアプリケーションの変更履歴を 管理する必要がある ◦ 従来のアプリケーションと比較しても特にトレースや評価についての議論がホット • 改善はLLMのプロンプトやパラメータの改善を第一選択にしつつも、目的によってファインチュー ニングや蒸留などのプロンプトエンジニアリング以外の改善手法を取ることも検討の余地あり まとめ AIエージェントで価値を届けるためには継続的に改善し続ける必要がある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}