minimize disk footprint (by utilizing normalization and foreign keys), but now disk space is cheap – doubling disk space costs a fraction of doubling processor speed. 8 * According to NoSQL proponents. Might not actually be true!
minimize disk footprint (by utilizing normalization and foreign keys), but now disk space is cheap – doubling disk space costs a fraction of doubling processor speed. • Sometimes it’s hard to model data into proper relations, and most applications are not as relational as we hope. 8 * According to NoSQL proponents. Might not actually be true!
minimize disk footprint (by utilizing normalization and foreign keys), but now disk space is cheap – doubling disk space costs a fraction of doubling processor speed. • Sometimes it’s hard to model data into proper relations, and most applications are not as relational as we hope. • They’re not very good at scaling, and their distributed applications introduce significant delay and network traffic. 8 * According to NoSQL proponents. Might not actually be true!
integrity • Data is normalized (no orphans or duplicates) • Result: • More tables • More relations • More keys • More indexes 9 * According to NoSQL proponents. Might not actually be true!
per day). • Data does not have complex relations (like Facebook’s messages, which is key:value pairs – for the most part, anyway) 10 * According to NoSQL proponents. Might not actually be true!
per day). • Data does not have complex relations (like Facebook’s messages, which is key:value pairs – for the most part, anyway) • Real-time applications (like Facebook’s messages, which has to build inverted index on <keyword, message*> in real-time) 10 * According to NoSQL proponents. Might not actually be true!
per day). • Data does not have complex relations (like Facebook’s messages, which is key:value pairs – for the most part, anyway) • Real-time applications (like Facebook’s messages, which has to build inverted index on <keyword, message*> in real-time) • Automatic sharding and distributed applications (on a grid, with thousands of nodes and using map/reduce for aggregating data) 10 * According to NoSQL proponents. Might not actually be true!
per day). • Data does not have complex relations (like Facebook’s messages, which is key:value pairs – for the most part, anyway) • Real-time applications (like Facebook’s messages, which has to build inverted index on <keyword, message*> in real-time) • Automatic sharding and distributed applications (on a grid, with thousands of nodes and using map/reduce for aggregating data) • Need for versioning (with timestamps), without significant overhead 10 * According to NoSQL proponents. Might not actually be true!
per day). • Data does not have complex relations (like Facebook’s messages, which is key:value pairs – for the most part, anyway) • Real-time applications (like Facebook’s messages, which has to build inverted index on <keyword, message*> in real-time) • Automatic sharding and distributed applications (on a grid, with thousands of nodes and using map/reduce for aggregating data) • Need for versioning (with timestamps), without significant overhead • Prototyping (you don’t have to migrate database schema during development) 10 * According to NoSQL proponents. Might not actually be true!
built on top of Google File System (GFS), designed to handle petabytes of data, on a cluster of hundreds of thousands of nodes • Many Google services use BigTable: • Gmail, Google Reader • Google Maps, Google Earth • Google Code, Blogger • YouTube, Orkut • Google Search History 12 Source: http://research.google.com/archive/bigtable.html
Currently a top priority project at Apache foundation. • Used by: • Facebook: Messages • Twitter: People search • Yahoo! • Adobe • ... thousands of other real-time applications 13 Source: http://wiki.apache.org/hadoop/Hbase/PoweredBy
that powered Facebook’s messaging platform • An Scalable, High-availability, fault tolerant, elastic and durable structured key-value storage with no single point of failure. 14
that powered Facebook’s messaging platform • An Scalable, High-availability, fault tolerant, elastic and durable structured key-value storage with no single point of failure. • Open sourced in 2008 14
that powered Facebook’s messaging platform • An Scalable, High-availability, fault tolerant, elastic and durable structured key-value storage with no single point of failure. • Open sourced in 2008 • Donated to Apache foundation in 2009 (They moved to HBase in late 2010) – currently a top priority project. 14
that powered Facebook’s messaging platform • An Scalable, High-availability, fault tolerant, elastic and durable structured key-value storage with no single point of failure. • Open sourced in 2008 • Donated to Apache foundation in 2009 (They moved to HBase in late 2010) – currently a top priority project. • Currently being used at: • Digg, Netflix, Cisco, Twitter, ... 14
top priority project at Apache foundation. • Characteristics: • ACID, CRUD, highly distributed, eventually consistent, map/reduce, fault tolerant, RESTful APIs, ... • Many corporations and websites use CouchDB: http://wiki.apache.org/couchdb/CouchDB_in_the_wild 15
urls per day • CERN LHC – for data aggregation system • The New York Times • Forbes • Guardian • Stripe • ShareThis • Wordnik – 3.5TB of data across 20B records 23
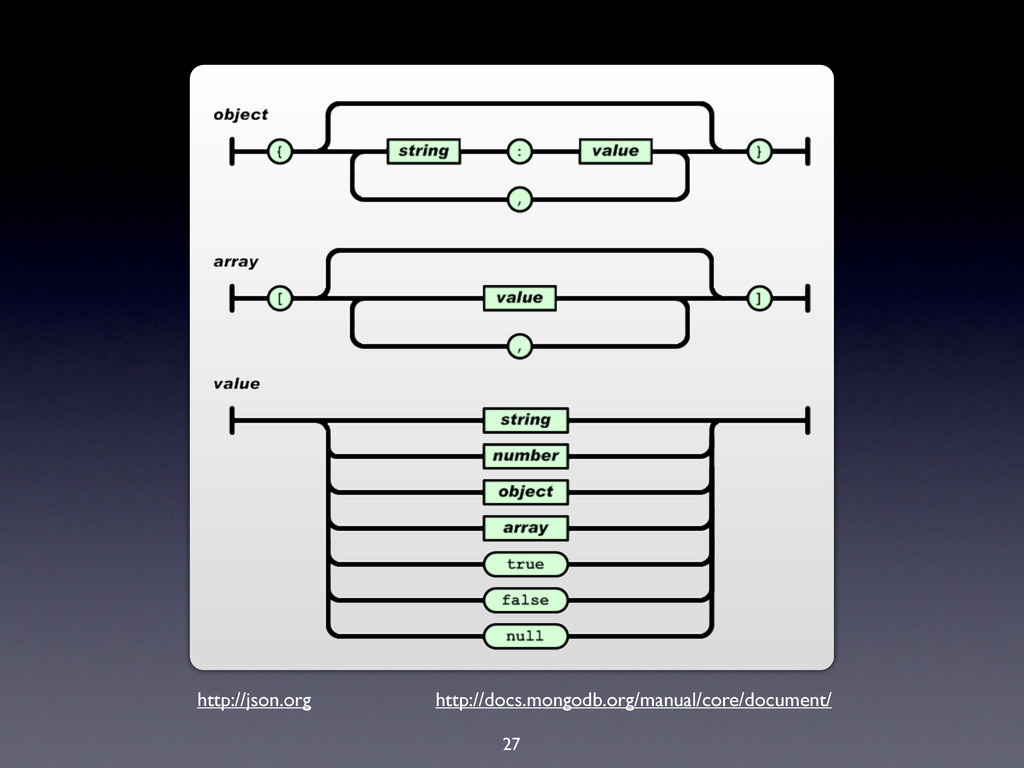
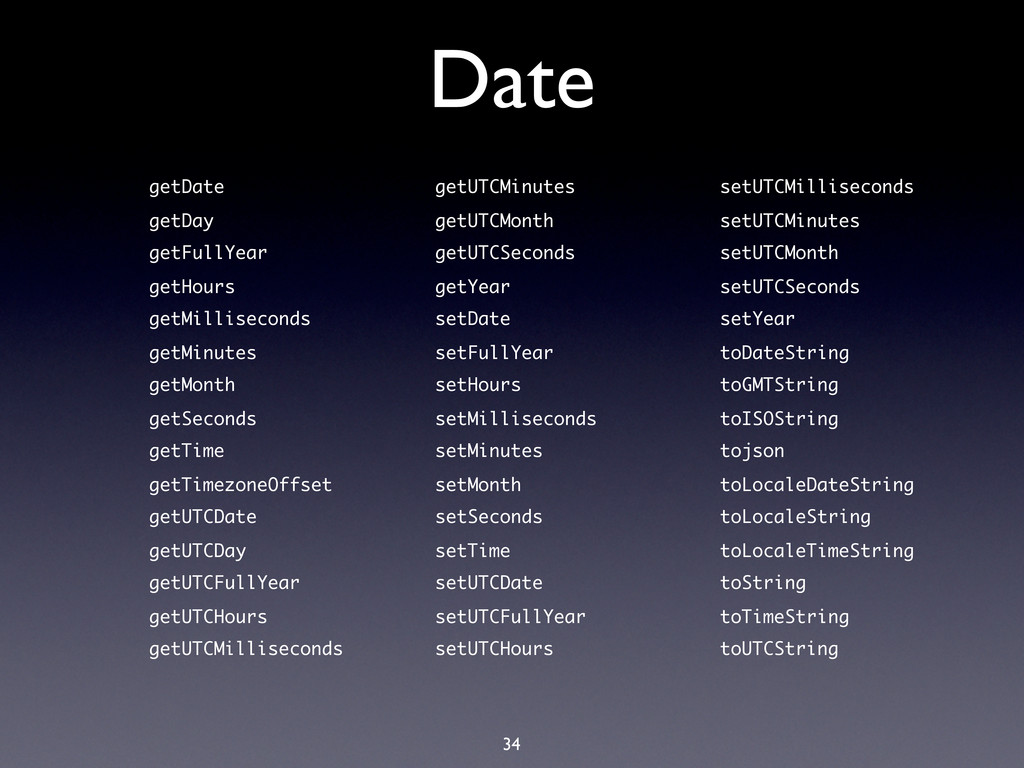
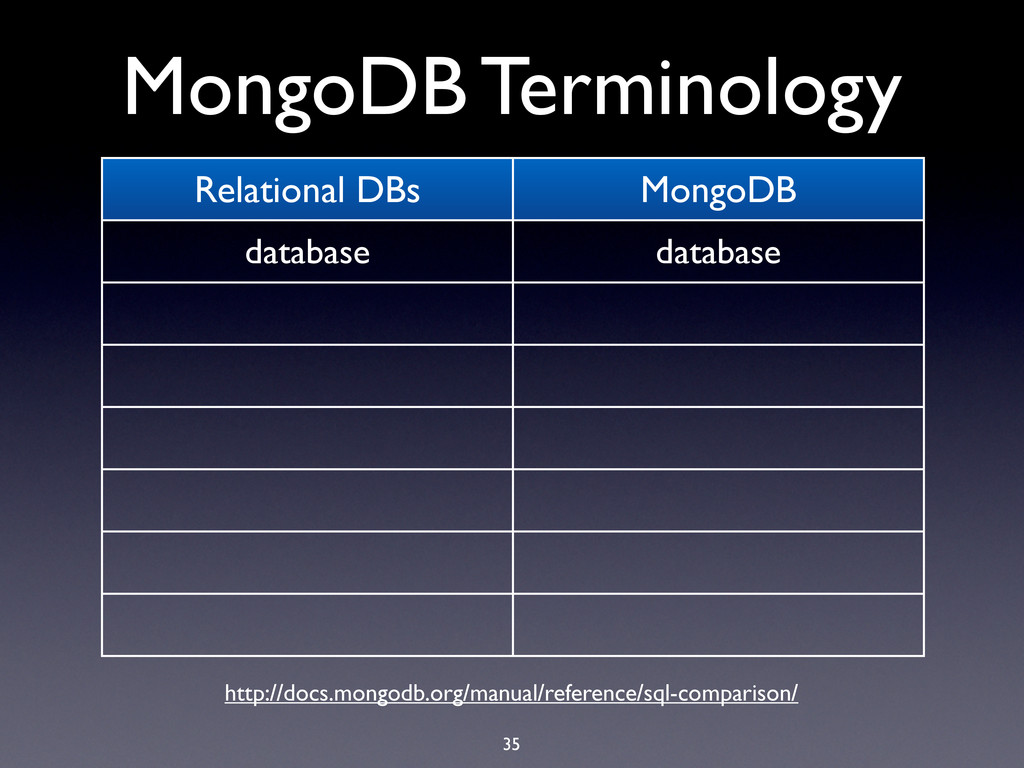
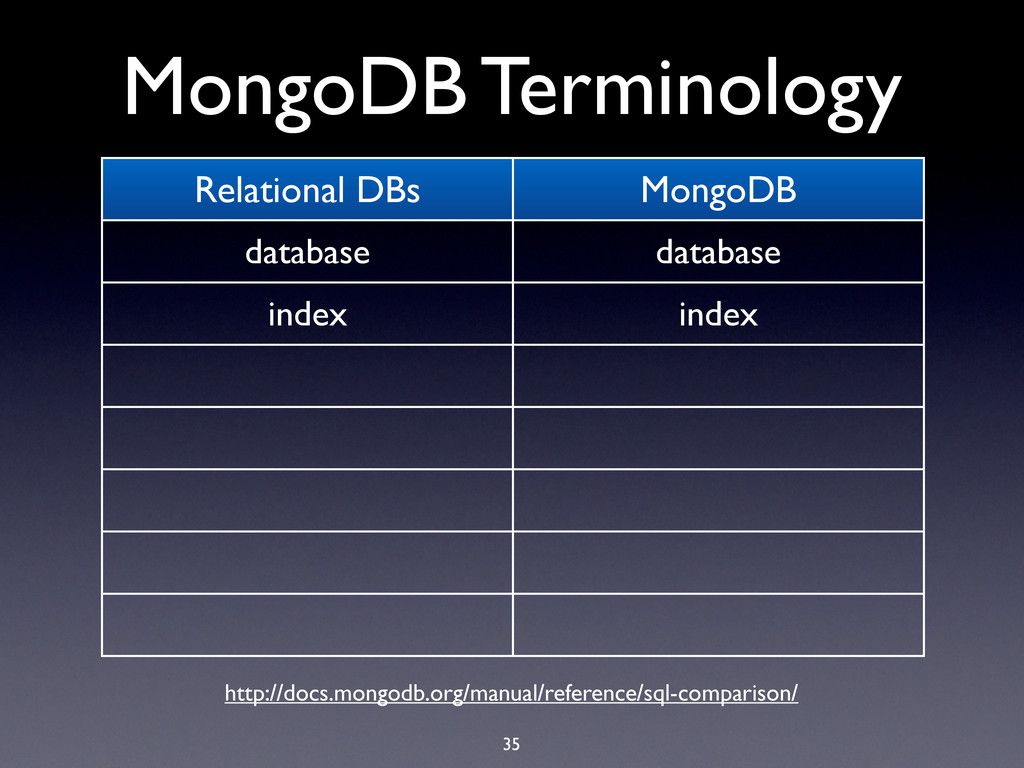
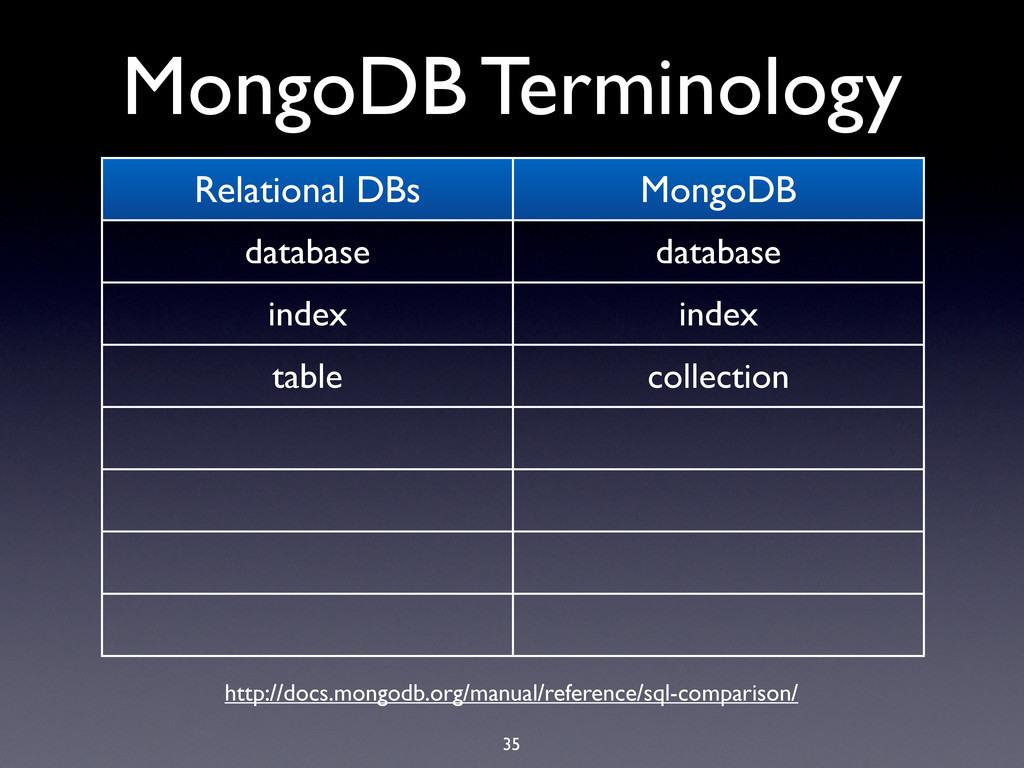
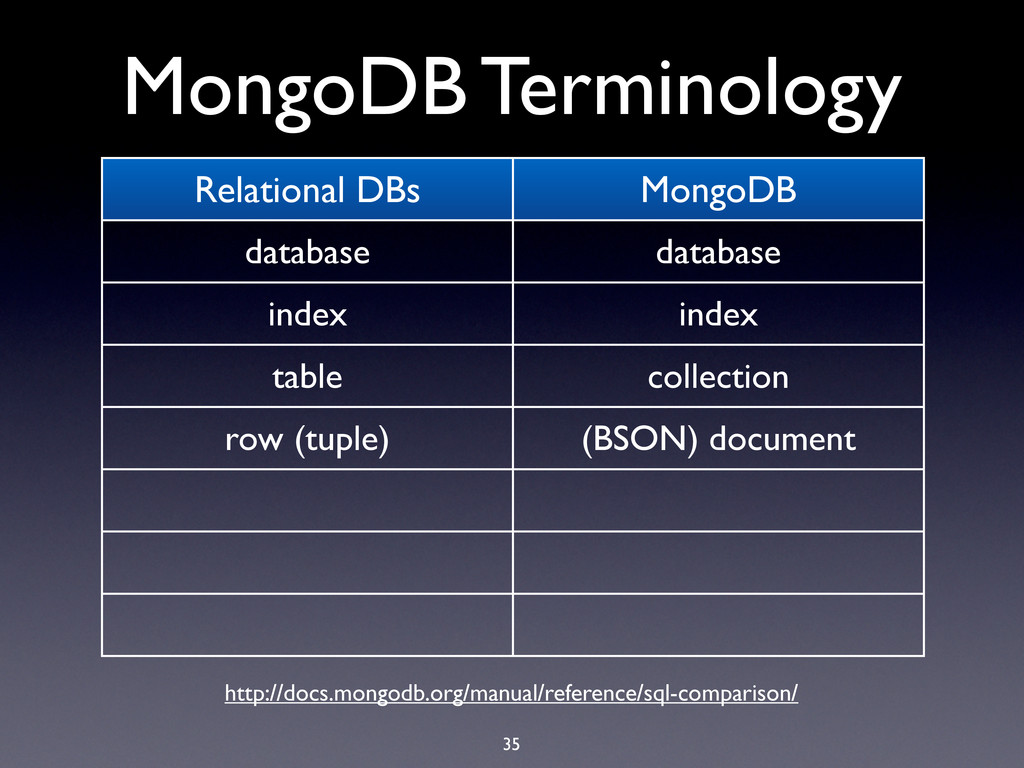
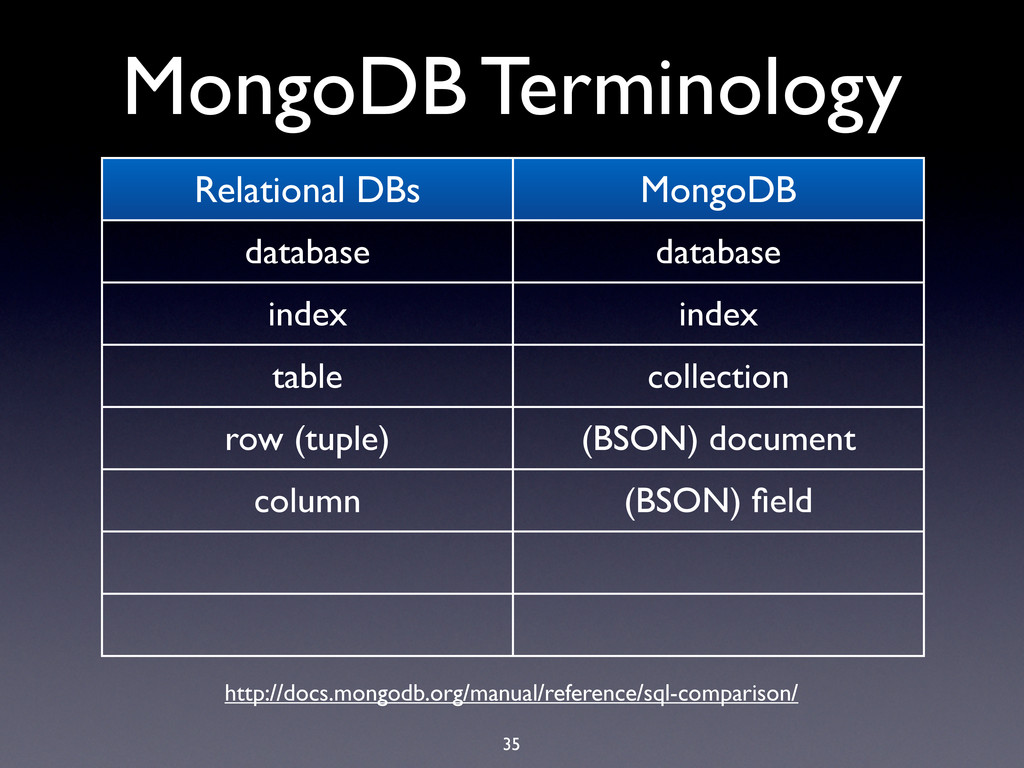
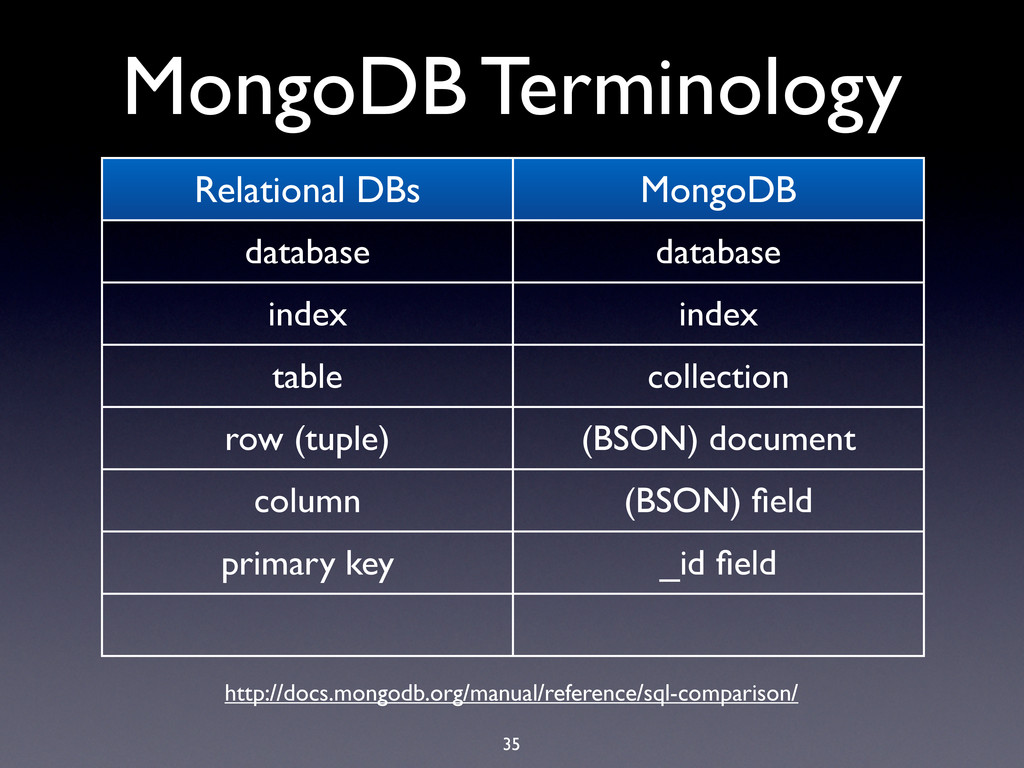
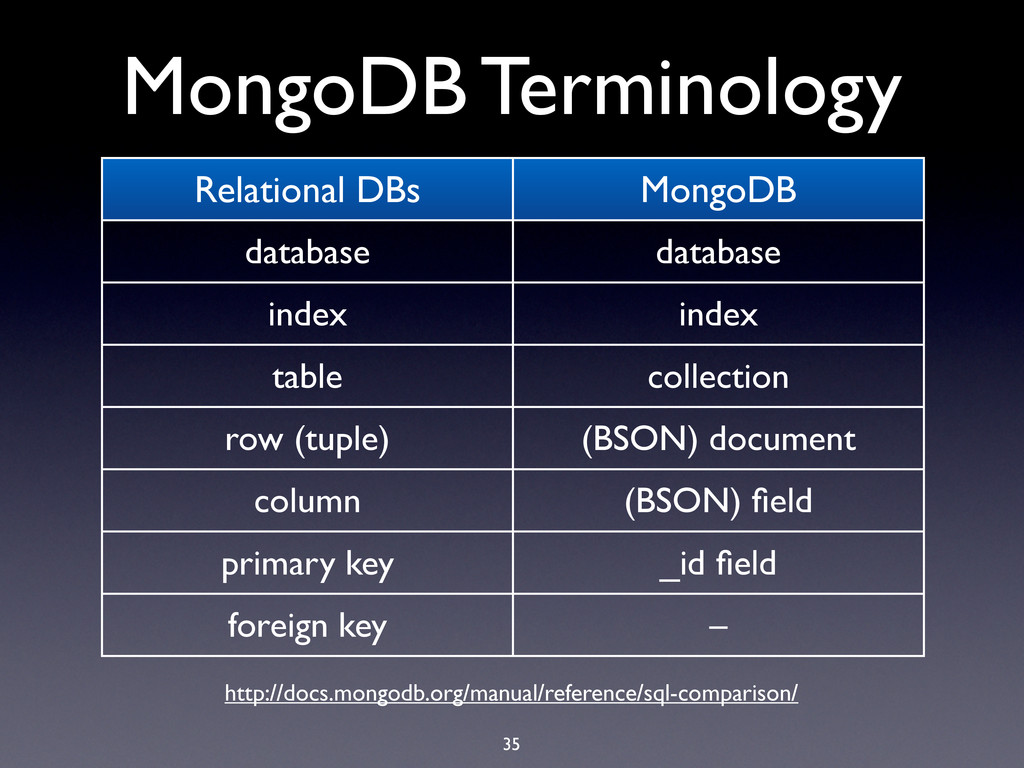
hard limit is 16MB! • BSON documents are used extensively in MongoDB: • Record documents • Query specification documents • Update specification documents
hard limit is 16MB! • BSON documents are used extensively in MongoDB: • Record documents • Query specification documents • Update specification documents • Index specification documents
hard limit is 16MB! • BSON documents are used extensively in MongoDB: • Record documents • Query specification documents • Update specification documents • Index specification documents • Sort order specification documents
hard limit is 16MB! • BSON documents are used extensively in MongoDB: • Record documents • Query specification documents • Update specification documents • Index specification documents • Sort order specification documents • …
a 4-byte value representing the seconds since the Unix epoch, • a 3-byte machine identifier, • a 2-byte process id, and • a 3-byte counter, starting with a random value. 32 http://docs.mongodb.org/manual/reference/object-id/
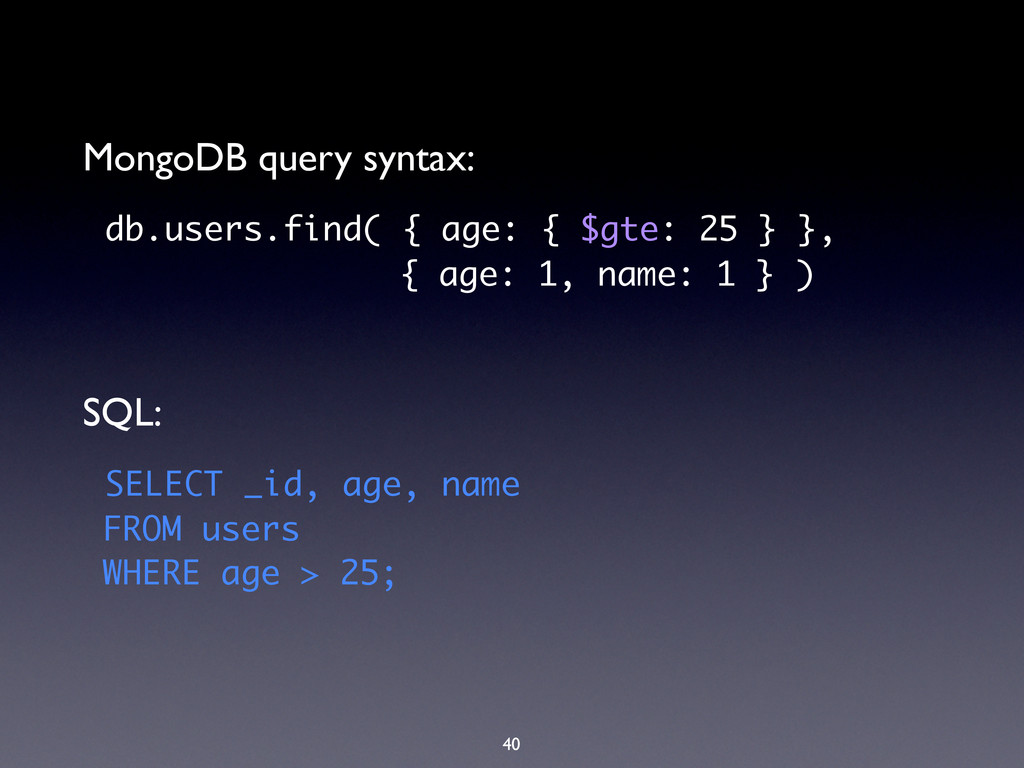
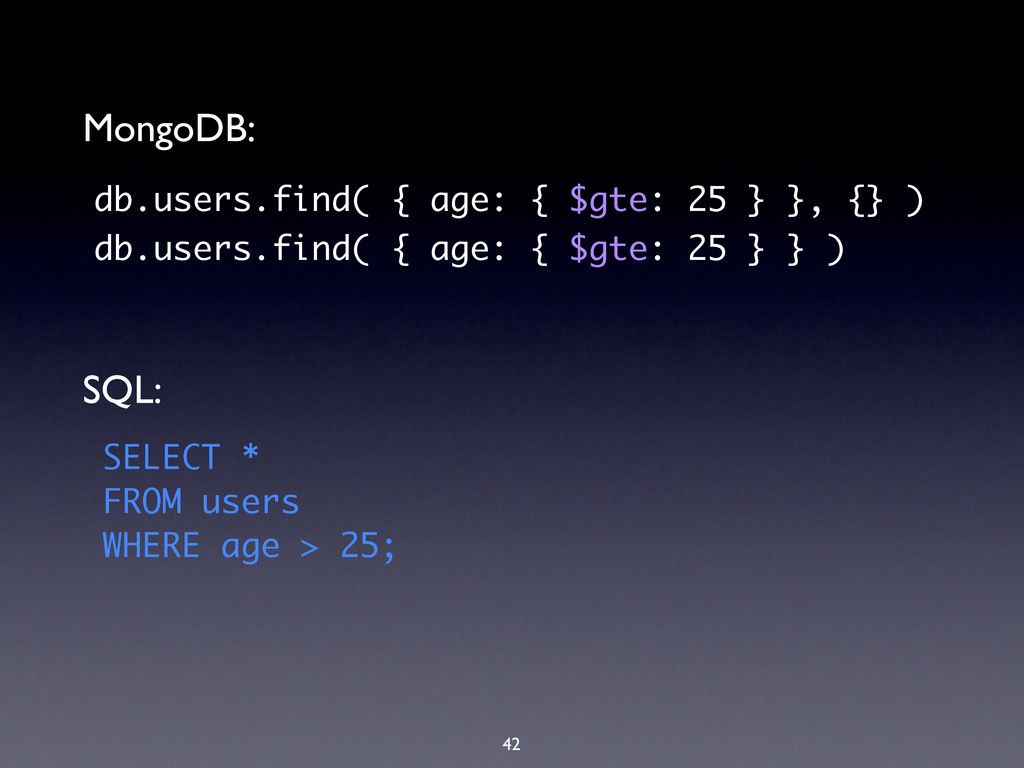
complex queries • Simpler than Map/Reduce • Can $project the output to: • Add or compute new fields • Create virtual sub-objects • Extract sub-fields into top-level objects
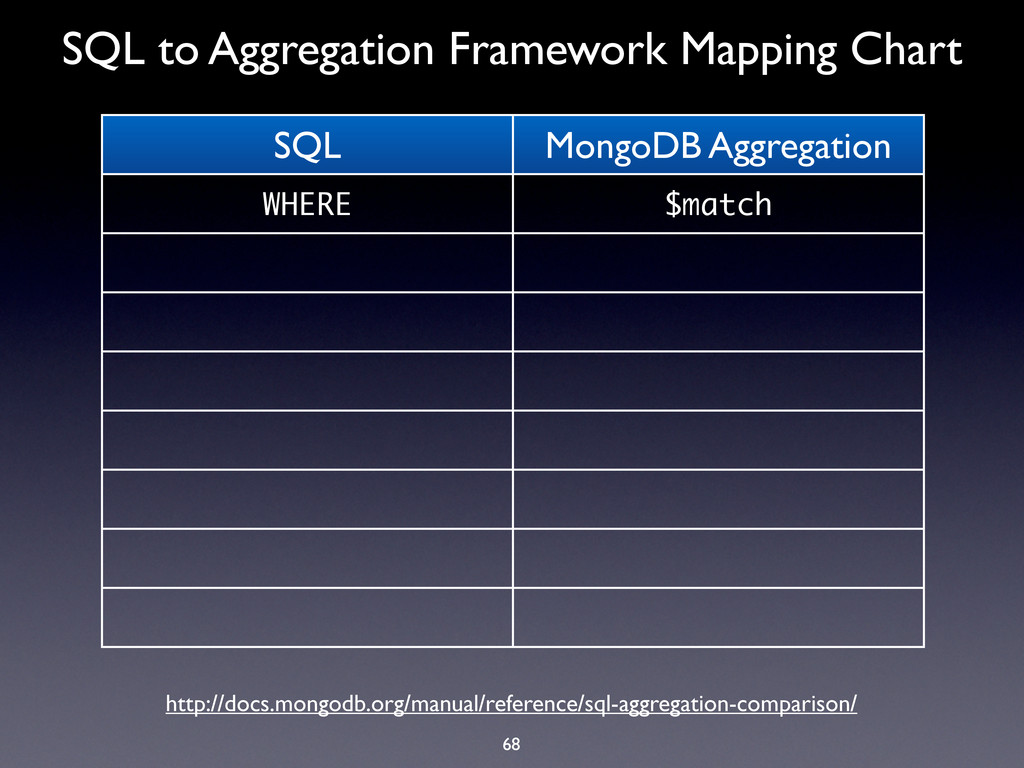
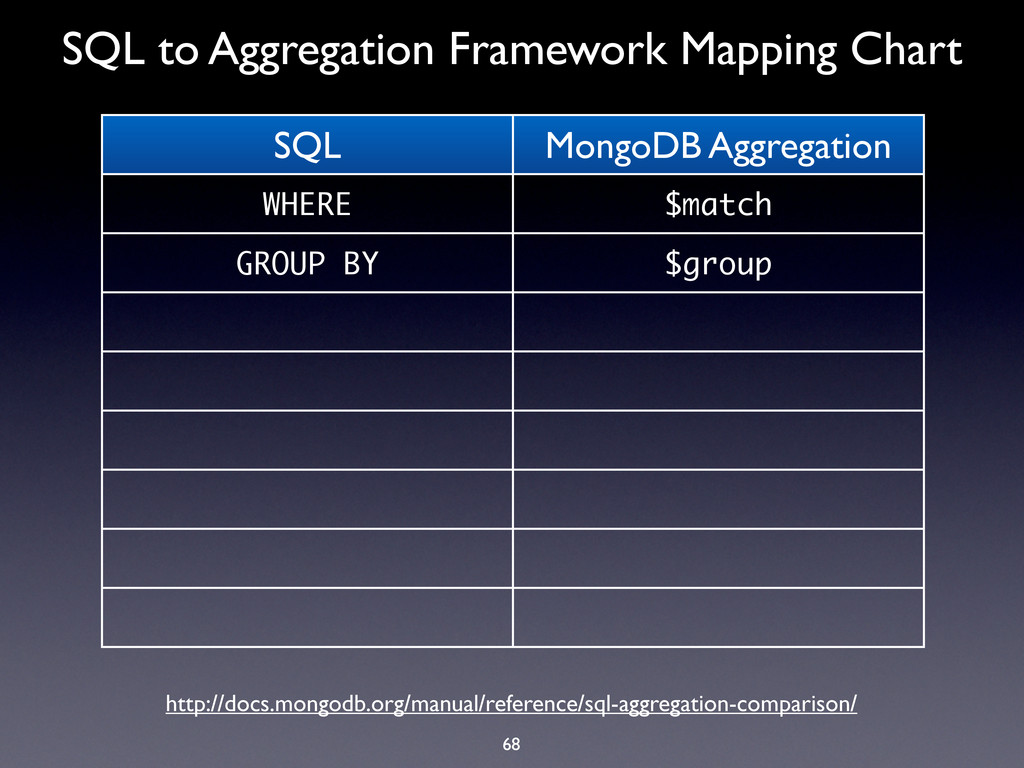
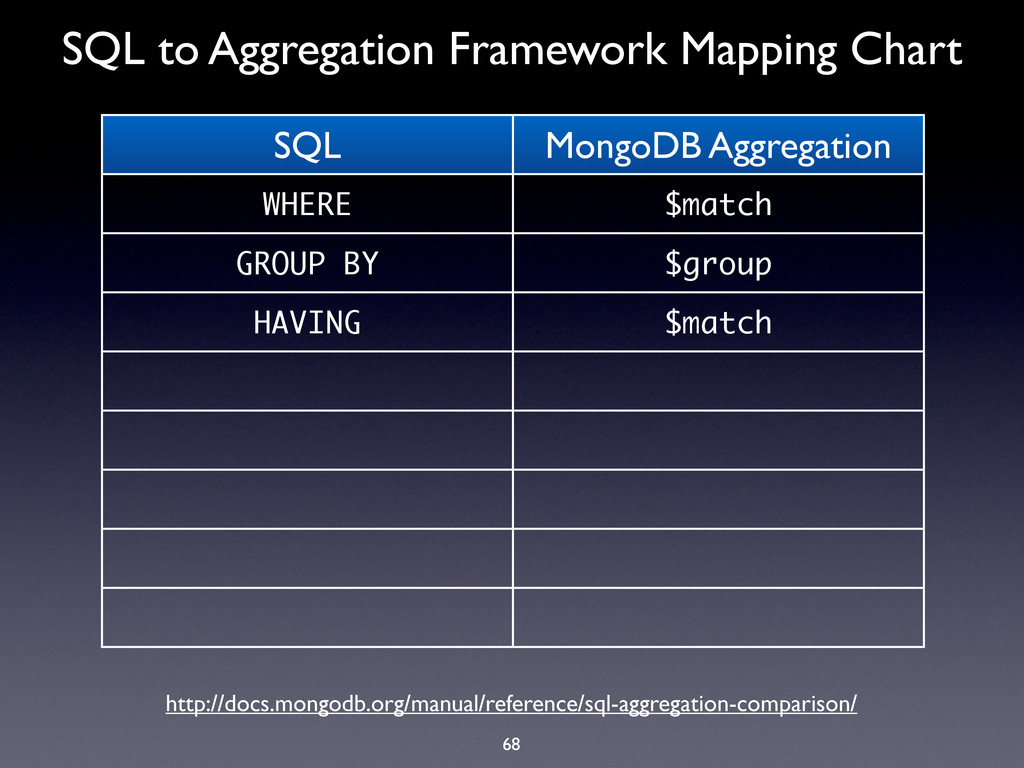
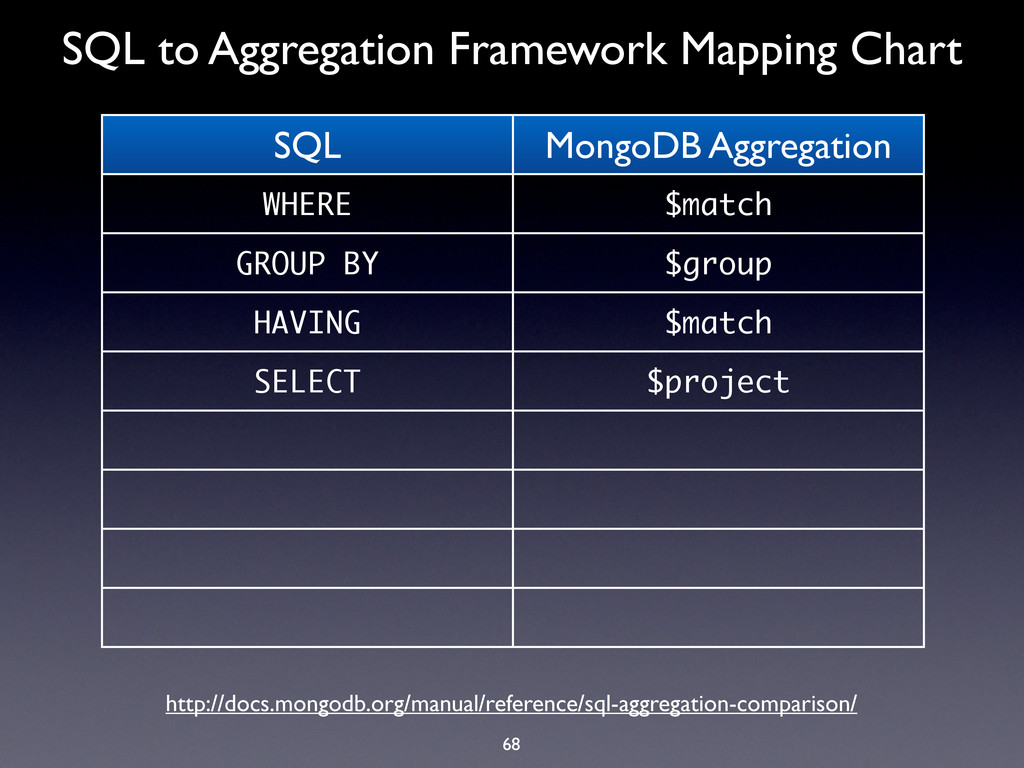
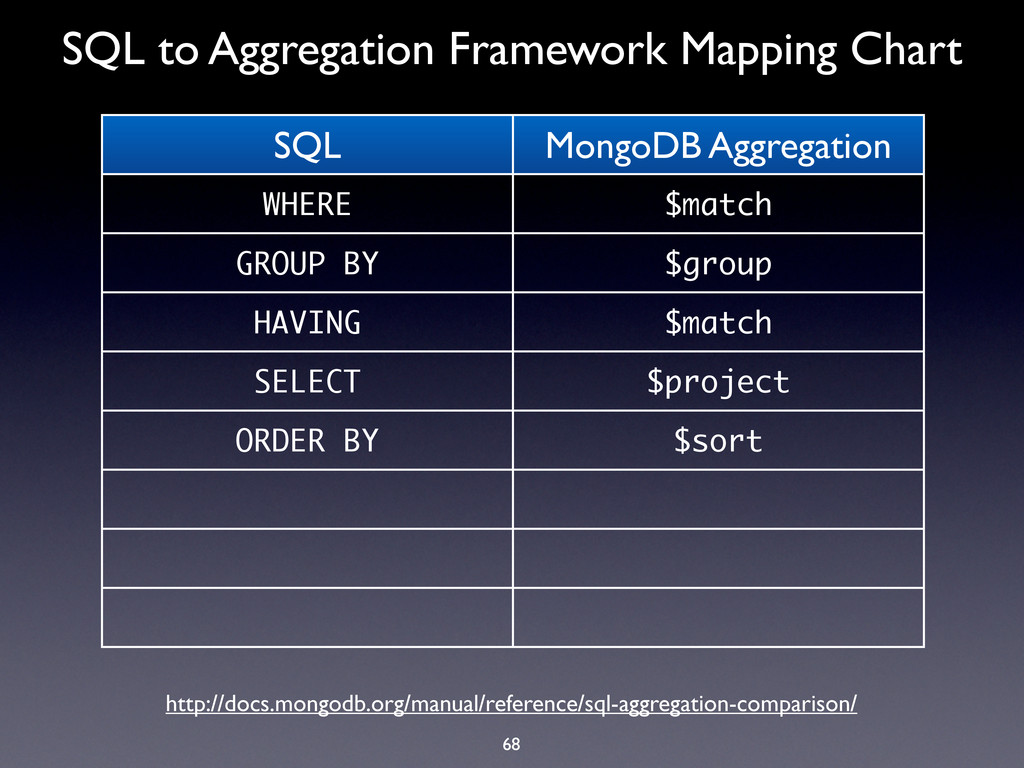
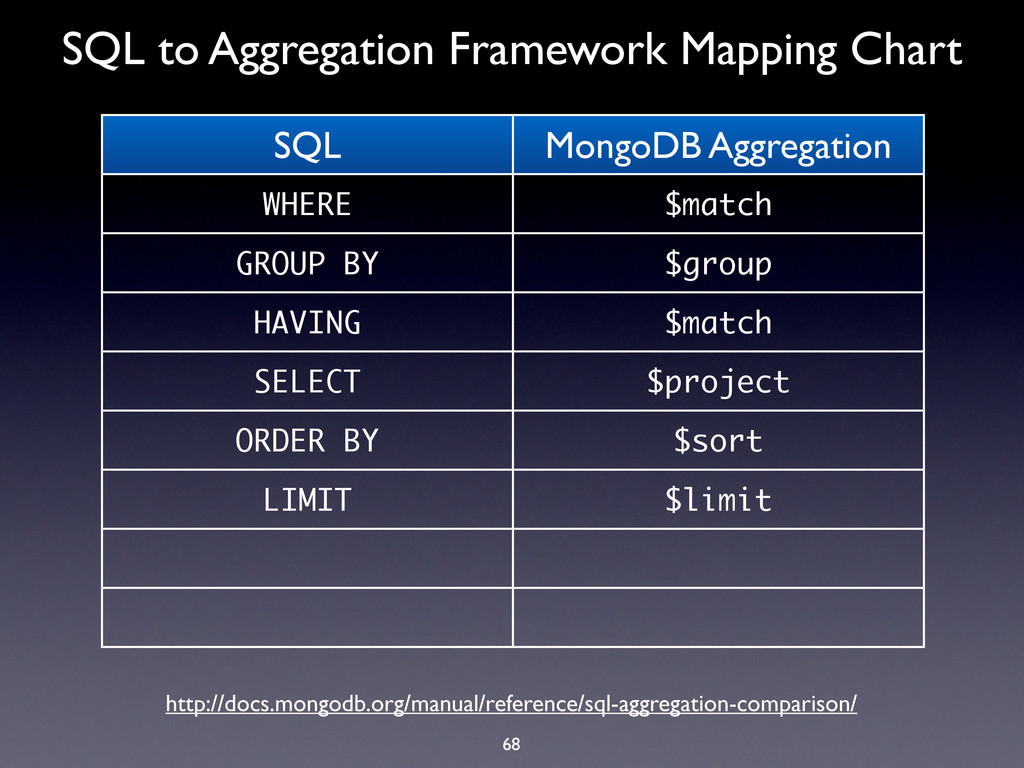
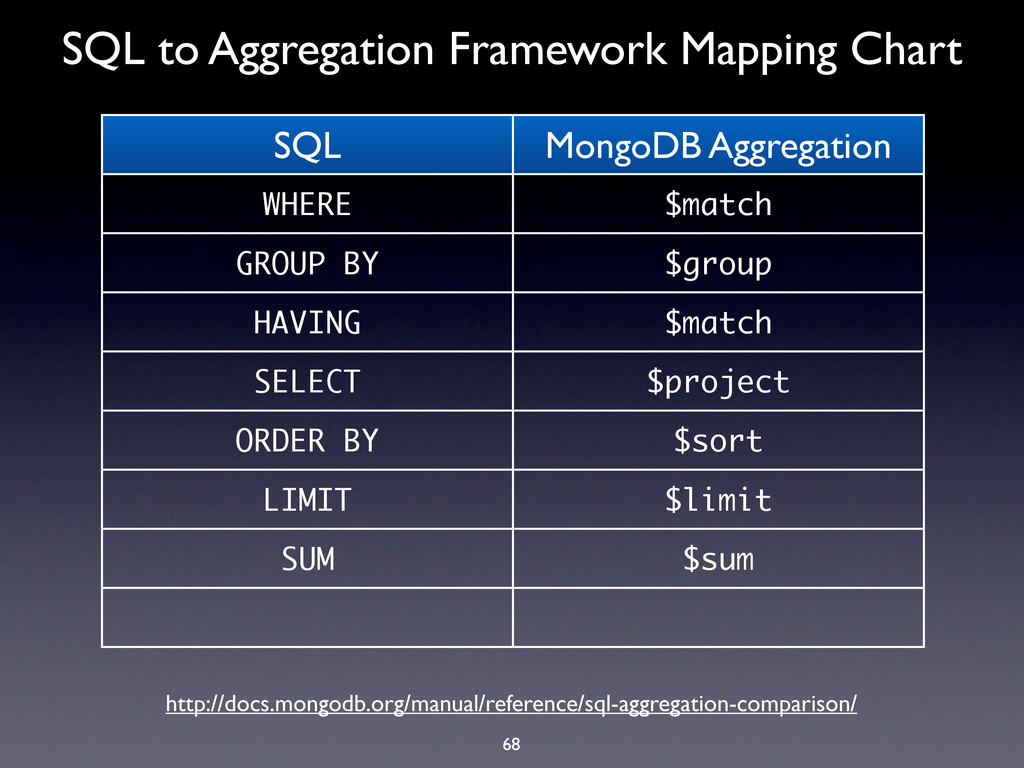
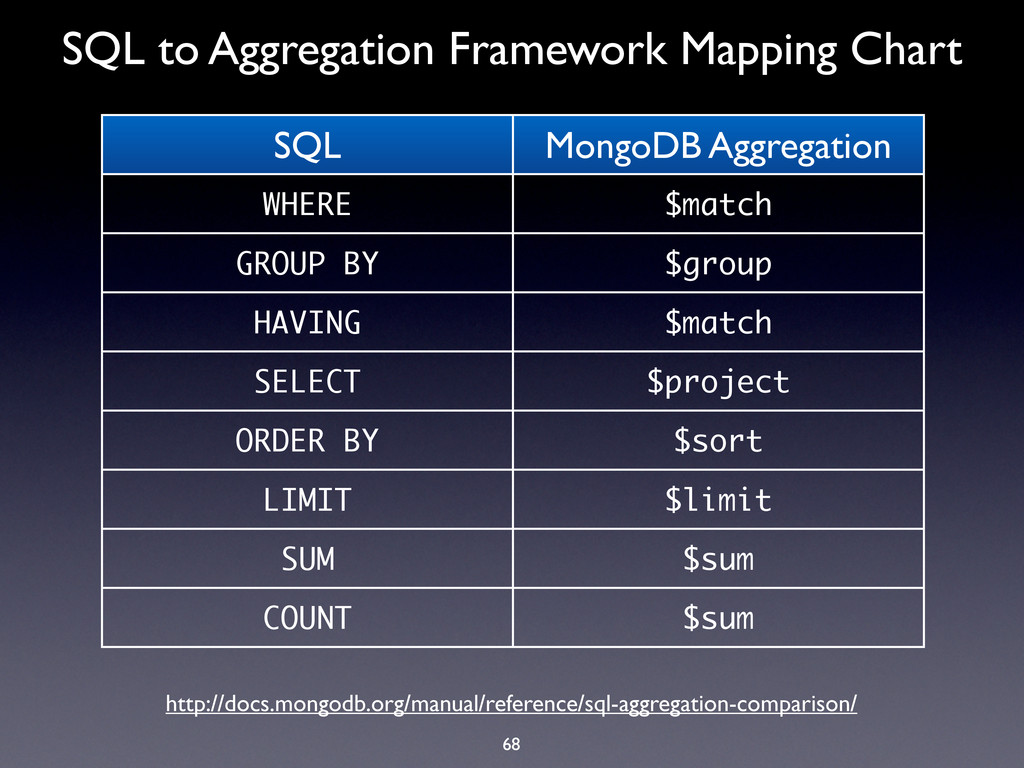
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM $sum COUNT $sum http://docs.mongodb.org/manual/reference/sql-aggregation-comparison/
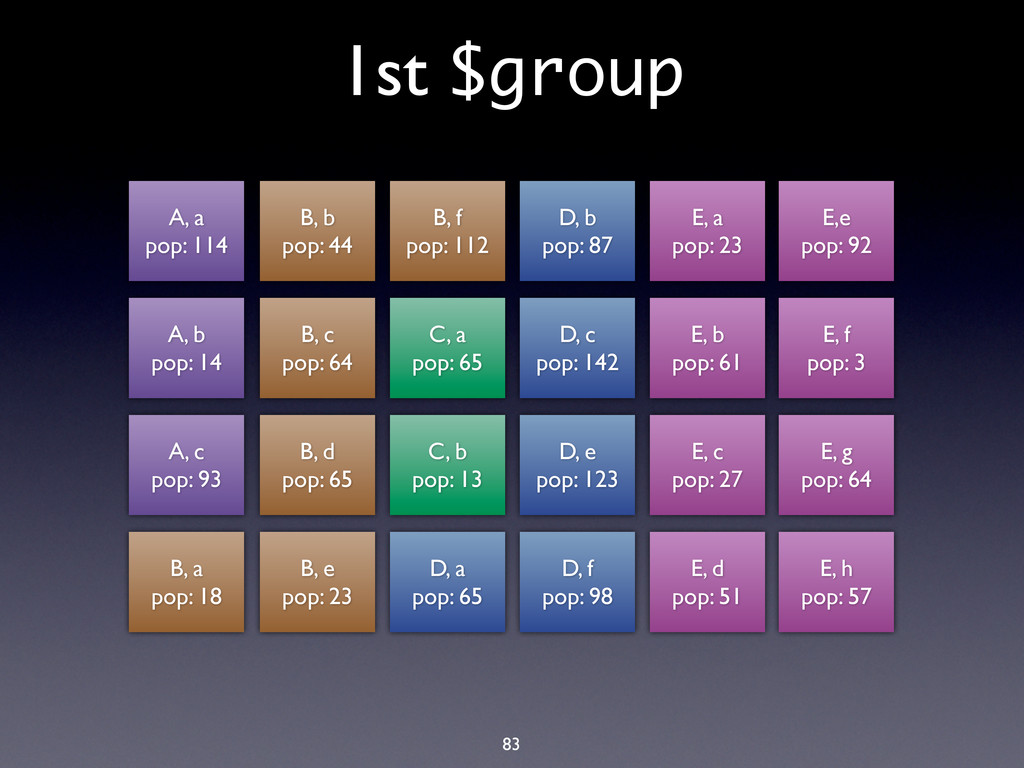
c pop: 93 B, a pop: 18 B, b pop: 44 B, c pop: 64 B, d pop: 65 B, e pop: 23 B, f pop: 112 C, a pop: 65 C, b pop: 13 D, a pop: 65 D, b pop: 87 D, c pop: 142 D, e pop: 123 D, f pop: 98 E, a pop: 23 E, b pop: 61 E, c pop: 27 E, d pop: 51 E,e pop: 92 E, f pop: 3 E, g pop: 64 E, h pop: 57 1st $group
A, c pop: 93 B, a pop: 18 B, b pop: 44 B, c pop: 64 B, d pop: 65 B, e pop: 23 B, f pop: 112 C, a pop: 65 C, b pop: 13 D, a pop: 65 D, b pop: 87 D, c pop: 142 D, e pop: 123 D, f pop: 98 E, a pop: 23 E, b pop: 61 E, c pop: 27 E, d pop: 51 E,e pop: 92 E, f pop: 3 E, g pop: 64 E, h pop: 57
pop: 114 A, b pop: 14 A, c pop: 93 B, a pop: 18 B, e pop: 23 C, a pop: 65 C, b pop: 13 D, a pop: 65 D, b pop: 87 D, c pop: 142 D, e pop: 123 D, f pop: 98 B, b pop: 44 B, c pop: 64 B, d pop: 65 B, f pop: 112 E, a pop: 23 E, c pop: 27 E, d pop: 51 E, h pop: 57 E, b pop: 61 E, g pop: 64 E,e pop: 92 A B C D E
pop: 114 A, b pop: 14 A, c pop: 93 B, a pop: 18 B, e pop: 23 C, a pop: 65 C, b pop: 13 D, a pop: 65 D, b pop: 87 D, c pop: 142 D, e pop: 123 D, f pop: 98 B, b pop: 44 B, c pop: 64 B, d pop: 65 B, f pop: 112 E, a pop: 23 E, c pop: 27 E, d pop: 51 E, h pop: 57 E, b pop: 61 E, g pop: 64 E,e pop: 92 A B C D E
A, a pop: 114 SmallestPop A, b pop: 14 SmallestPop B, a pop: 18 BiggestPop C, a pop: 65 SmallestPop C, b pop: 13 SmallestPop D, a pop: 65 BiggestPop D, c pop: 142 BiggestPop B, f pop: 112 A B C D E BiggestPop E,e pop: 92
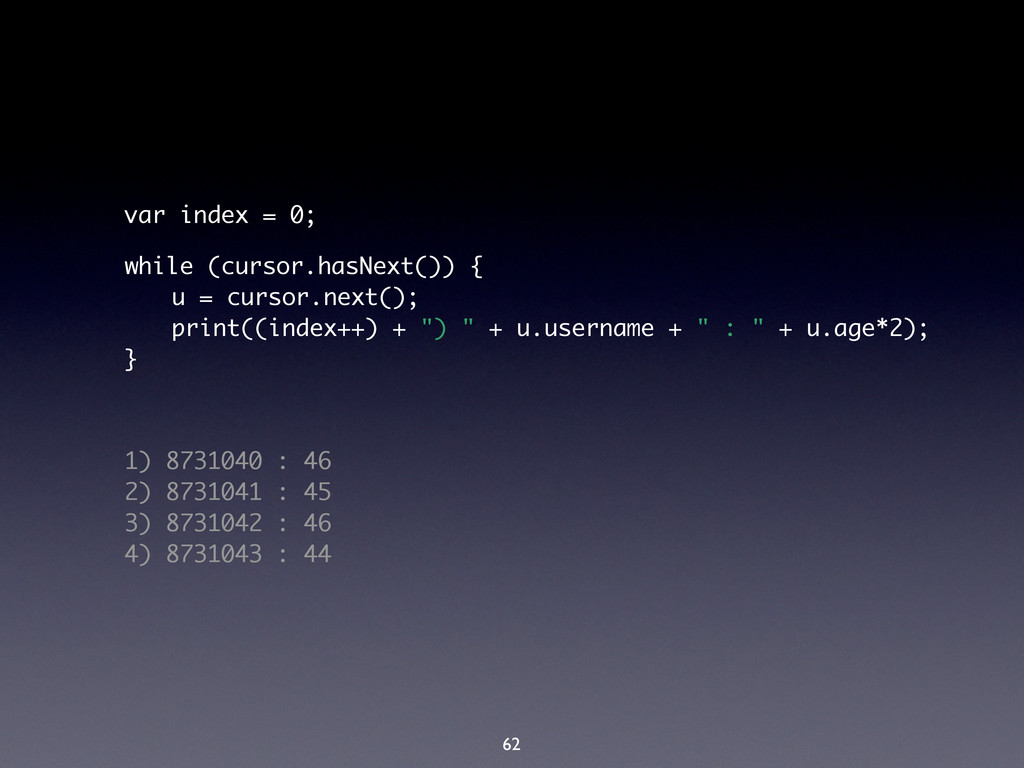
zero, one or more “new” documents (<key, value>) • Reduce • Called once per key emitted • Processes <key, Array[value]> and reduces all the values into a single one • Finalize • Optional – Rounds up all the reduced data 98
27017) @db = @client['sample-db'] @coll = @db['test'] @coll.remove 3.times do |i| @coll.insert({'a' => i+1}) end puts "There are #{@coll.count} records. Here they are:" @coll.find.each { |doc| puts doc.inspect } 103 http://docs.mongodb.org/ecosystem/drivers/ruby and http://api.mongodb.org/ruby/current/
are divided into 256KB chunks, and can be re-assembled fully or partially • No need to load the whole file into memory (can “skip” to the middle of a video) • Uses fs.chunks and fs.files collections by default 114 http://docs.mongodb.org/manual/core/gridfs/
in its entirety, or fail without any change being applied. ⎕ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. 124 http://en.wikipedia.org/wiki/ACID
in its entirety, or fail without any change being applied. ⎕ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. ⎕ Isolation requires that if transactions are executed concurrently, the result is equivalent to their serial execution. A transaction cannot see the partial result of the application of another one. 124 http://en.wikipedia.org/wiki/ACID
in its entirety, or fail without any change being applied. ⎕ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. ⎕ Isolation requires that if transactions are executed concurrently, the result is equivalent to their serial execution. A transaction cannot see the partial result of the application of another one. ⎕ Durability means that the the result of a committed transaction is permanent, even if the database crashes immediately or in the event of a power loss. 124 http://en.wikipedia.org/wiki/ACID
in its entirety, or fail without any change being applied. ⎕ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. ⎕ Isolation requires that if transactions are executed concurrently, the result is equivalent to their serial execution. A transaction cannot see the partial result of the application of another one. ⎕ Durability means that the the result of a committed transaction is permanent, even if the database crashes immediately or in the event of a power loss. 125 http://en.wikipedia.org/wiki/ACID
in its entirety, or fail without any change being applied. ☒ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. ⎕ Isolation requires that if transactions are executed concurrently, the result is equivalent to their serial execution. A transaction cannot see the partial result of the application of another one. ⎕ Durability means that the the result of a committed transaction is permanent, even if the database crashes immediately or in the event of a power loss. 126 http://en.wikipedia.org/wiki/ACID
in its entirety, or fail without any change being applied. ☒ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. ☑ Isolation requires that if transactions are executed concurrently, the result is equivalent to their serial execution. A transaction cannot see the partial result of the application of another one. ⎕ Durability means that the the result of a committed transaction is permanent, even if the database crashes immediately or in the event of a power loss. 127 http://en.wikipedia.org/wiki/ACID
in its entirety, or fail without any change being applied. ☒ Consistency requires that the database only passes from a valid state to the next one, without intermediate points. ☑ Isolation requires that if transactions are executed concurrently, the result is equivalent to their serial execution. A transaction cannot see the partial result of the application of another one. ☒ Durability means that the the result of a committed transaction is permanent, even if the database crashes immediately or in the event of a power loss. 128 http://en.wikipedia.org/wiki/ACID
string keys to string values, or other hstore values • h->"a" (get value for key a) • h?"a" (does h contain key a?) • h@>"a->2" (does key a contain 2?) 132 hstore
• “The Little MongoDB Book” http://openmymind.net/mongodb.pdf • “Why MongoDB Is Awesome?” http://www.slideshare.net/jnunemaker/why-mongodb-is-awesome 135
• “The Little MongoDB Book” http://openmymind.net/mongodb.pdf • “Why MongoDB Is Awesome?” http://www.slideshare.net/jnunemaker/why-mongodb-is-awesome 135
• “The Little MongoDB Book” http://openmymind.net/mongodb.pdf • “Why MongoDB Is Awesome?” http://www.slideshare.net/jnunemaker/why-mongodb-is-awesome 135
• “The Little MongoDB Book” http://openmymind.net/mongodb.pdf • “Why MongoDB Is Awesome?” http://www.slideshare.net/jnunemaker/why-mongodb-is-awesome 135
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Arrays db.inventory.find( { tags: [ 'fruit', 'food', 'citrus' ] }](https://files.speakerdeck.com/presentations/90ff1760aa84013080a356d6fe564fb8/slide_119.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![db.inventory.find( { tags: [ 'fruit', 'food', 'citrus' ] } ).count()](https://files.speakerdeck.com/presentations/90ff1760aa84013080a356d6fe564fb8/slide_125.jpg){kind=link}
![db.inventory.find( { tags: [ 'fruit', 'food', 'citrus' ] } ).sort(](https://files.speakerdeck.com/presentations/90ff1760aa84013080a356d6fe564fb8/slide_126.jpg){kind=link}
![db.inventory.find( { tags: [ 'fruit', 'food', 'citrus' ] } ).sort(](https://files.speakerdeck.com/presentations/90ff1760aa84013080a356d6fe564fb8/slide_127.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}