is cattle - ephemeral • Services are dynamic • Cloud Native Environments A 3 node cluster running 10 namespaces with 5 deployments with a replica set of ~3-5 with 10 config maps emits whooping 16566 time series per minute using the popular kube-state-metrics library 6
mitigate problems quickly • To debug a failure • To know how the system is behaving in real time • To co-relate an outage to a hardware failure • To fi nd anomalies and patterns • To trace a payment failure • To fi nd out unknown failures before they happen • To prevent hampering customer experience and business impact 11
it and pay for the data that is unused! • Slow dashboards, concurrent access woes • No real time alerting • Cost vs. Performance vs. Retention tradeo ff s 31
{kind=link}
{kind=link}
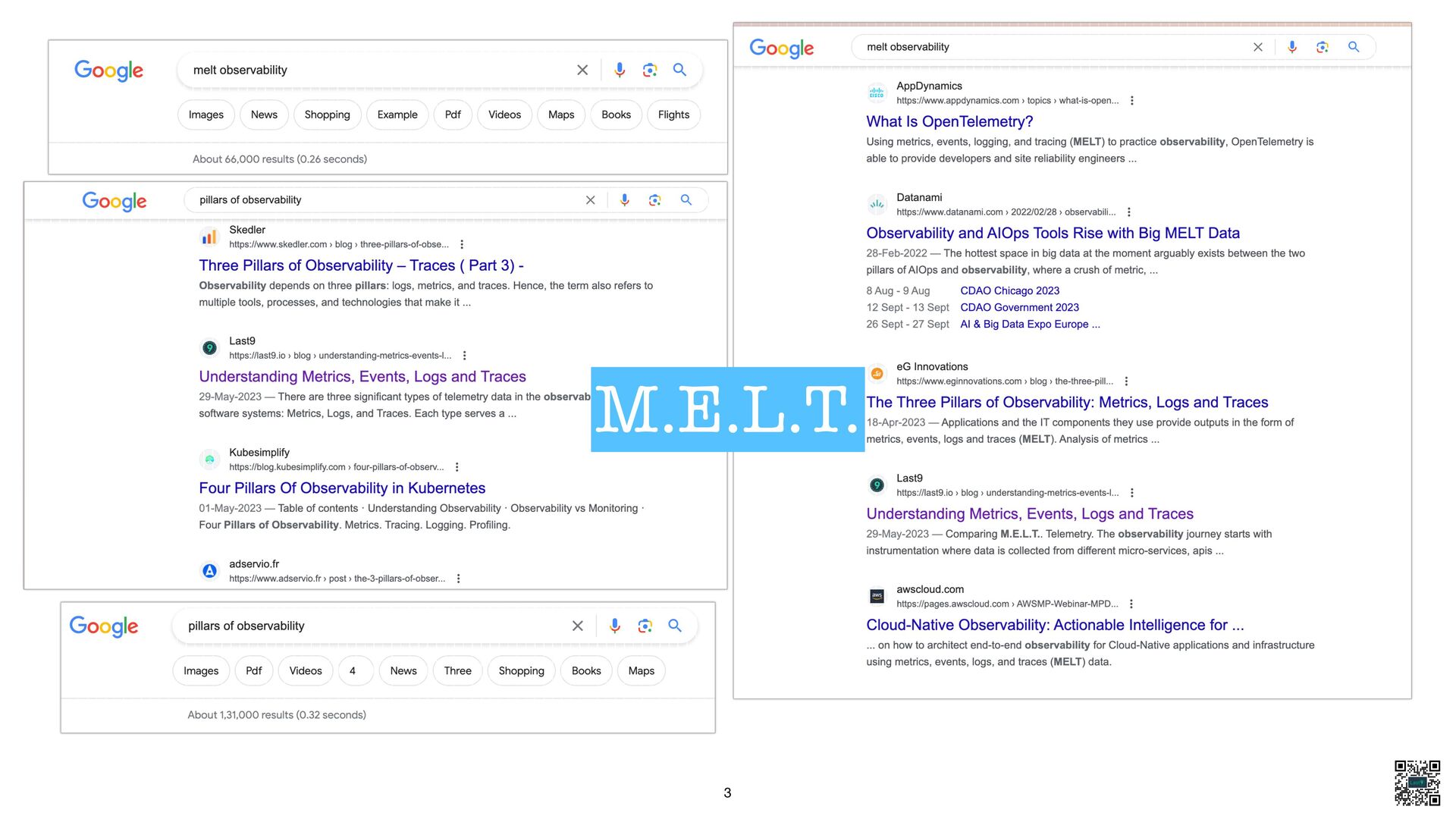{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
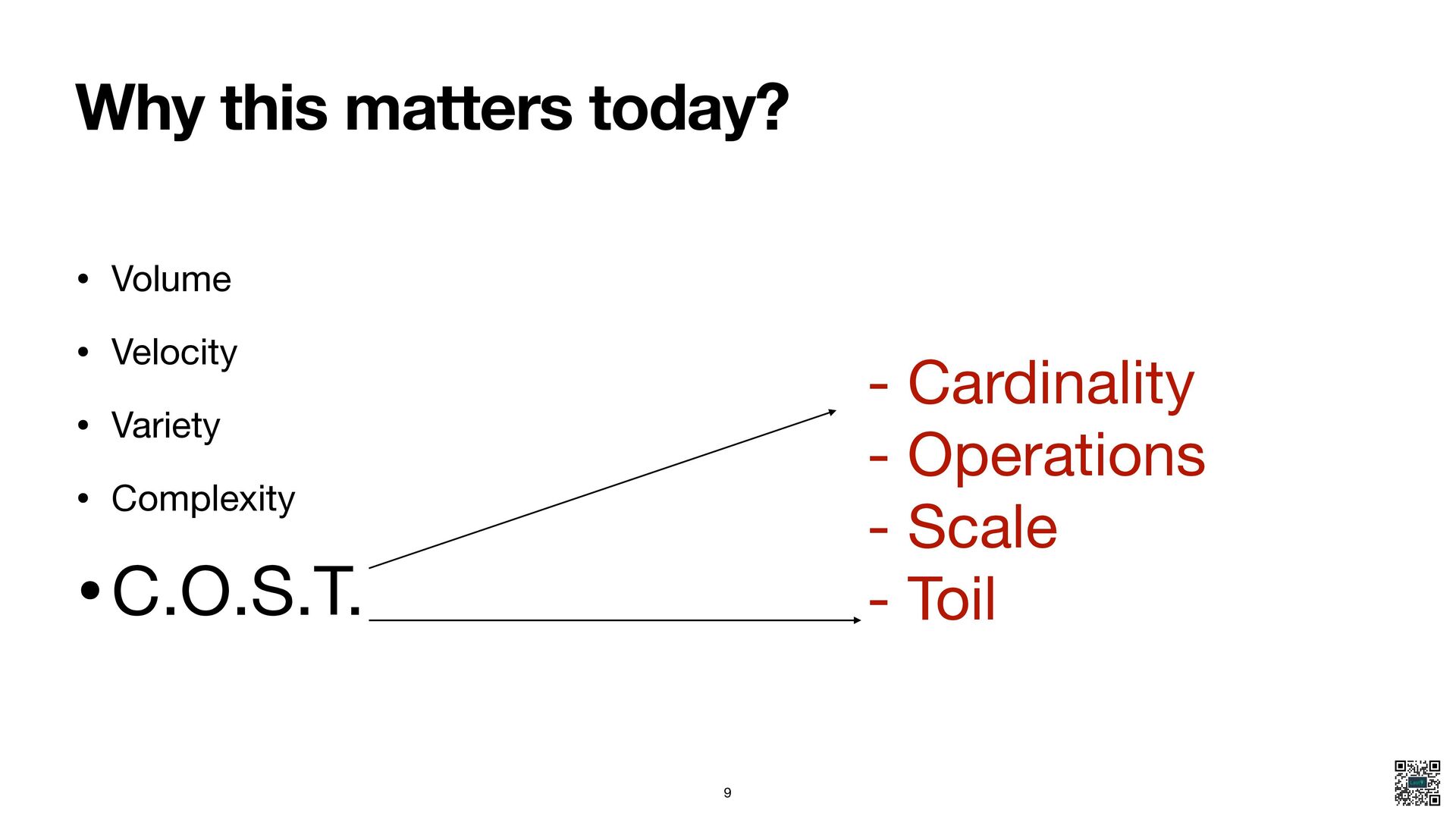{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
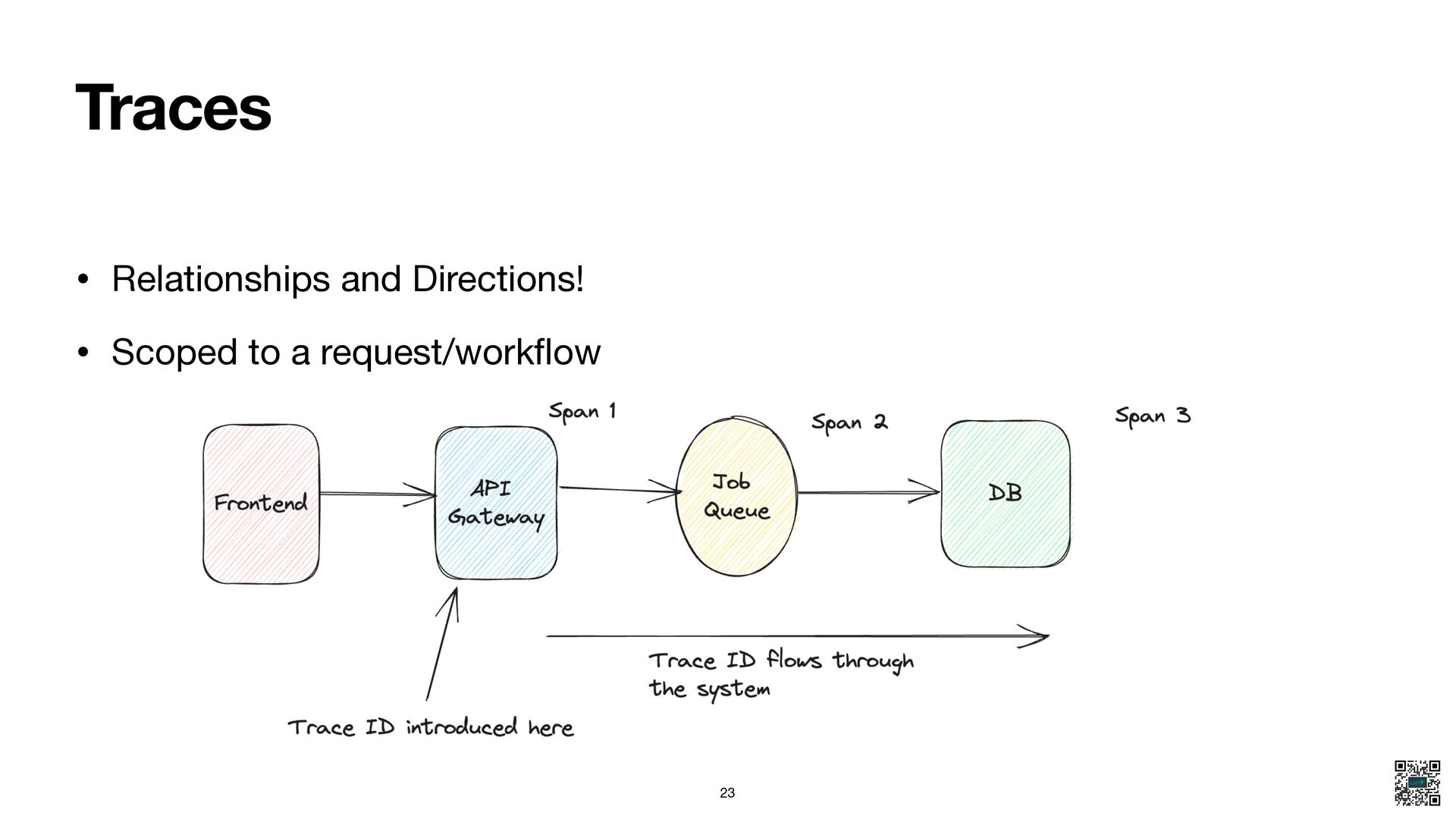{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
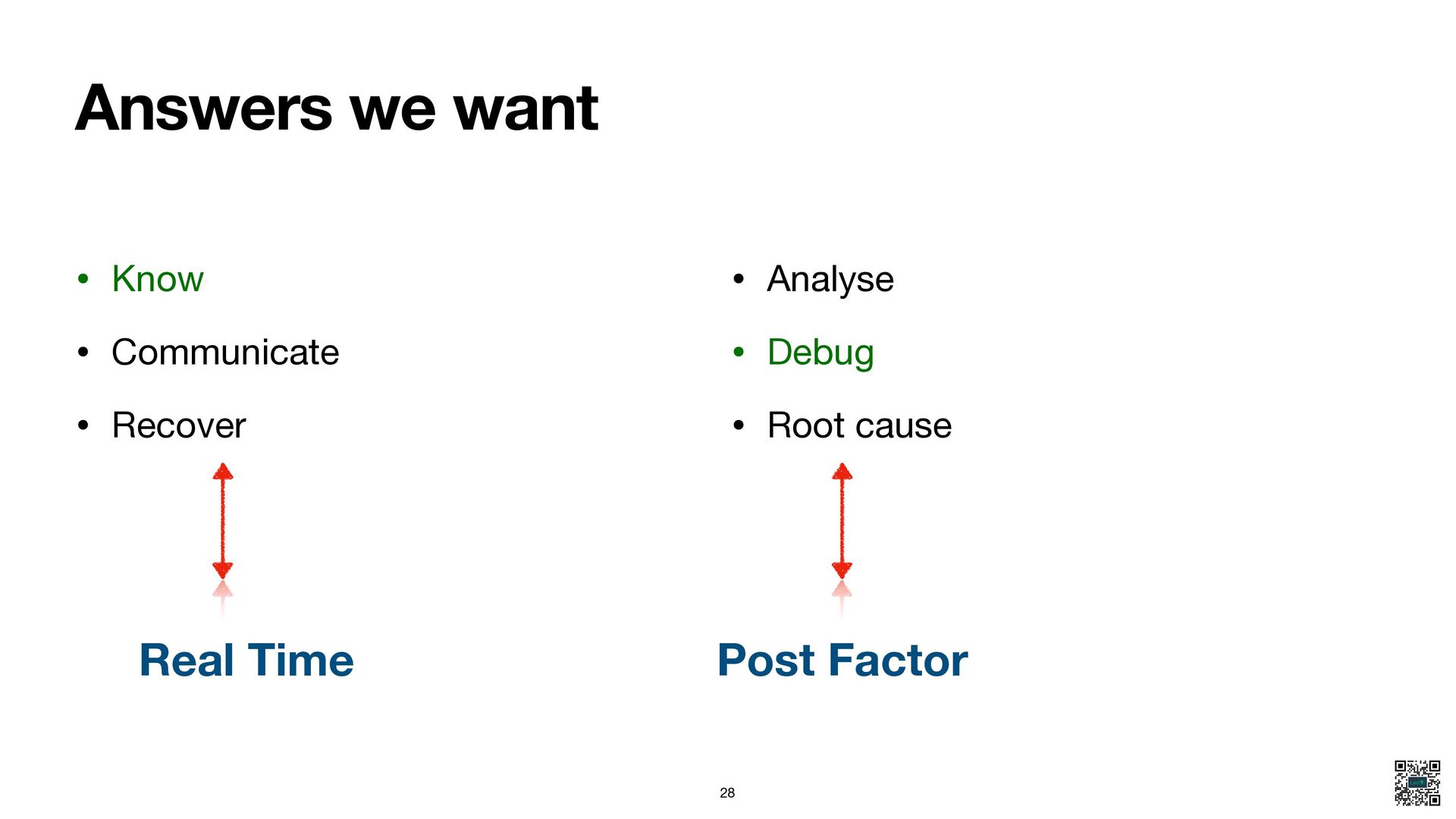{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}