Lightning talk given at Kubernetes + CNCF meetup in Bengaluru on 16th September
Meetup link - https://www.meetup.com/kubernetes-india-meetup/events/295710022/
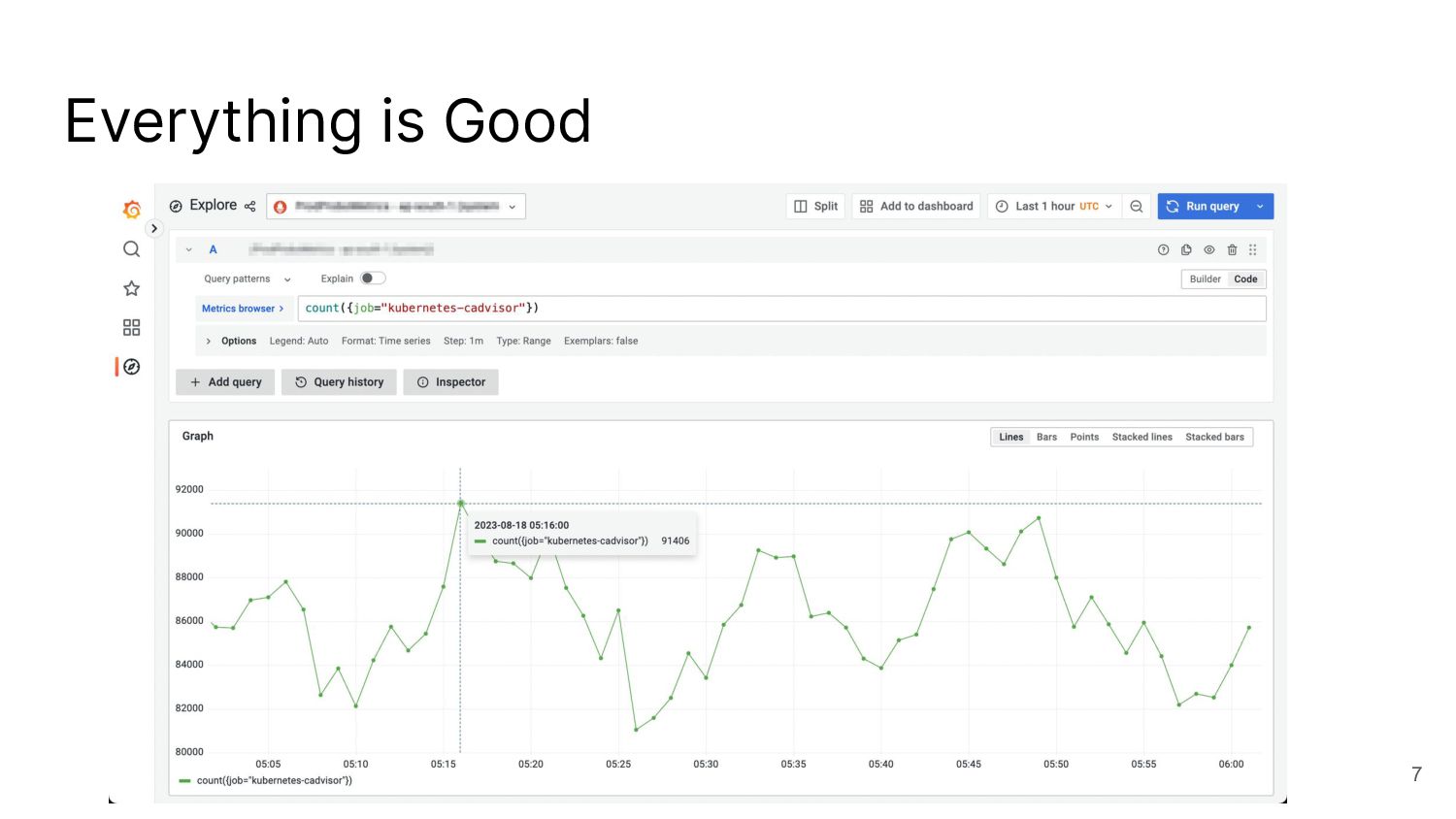
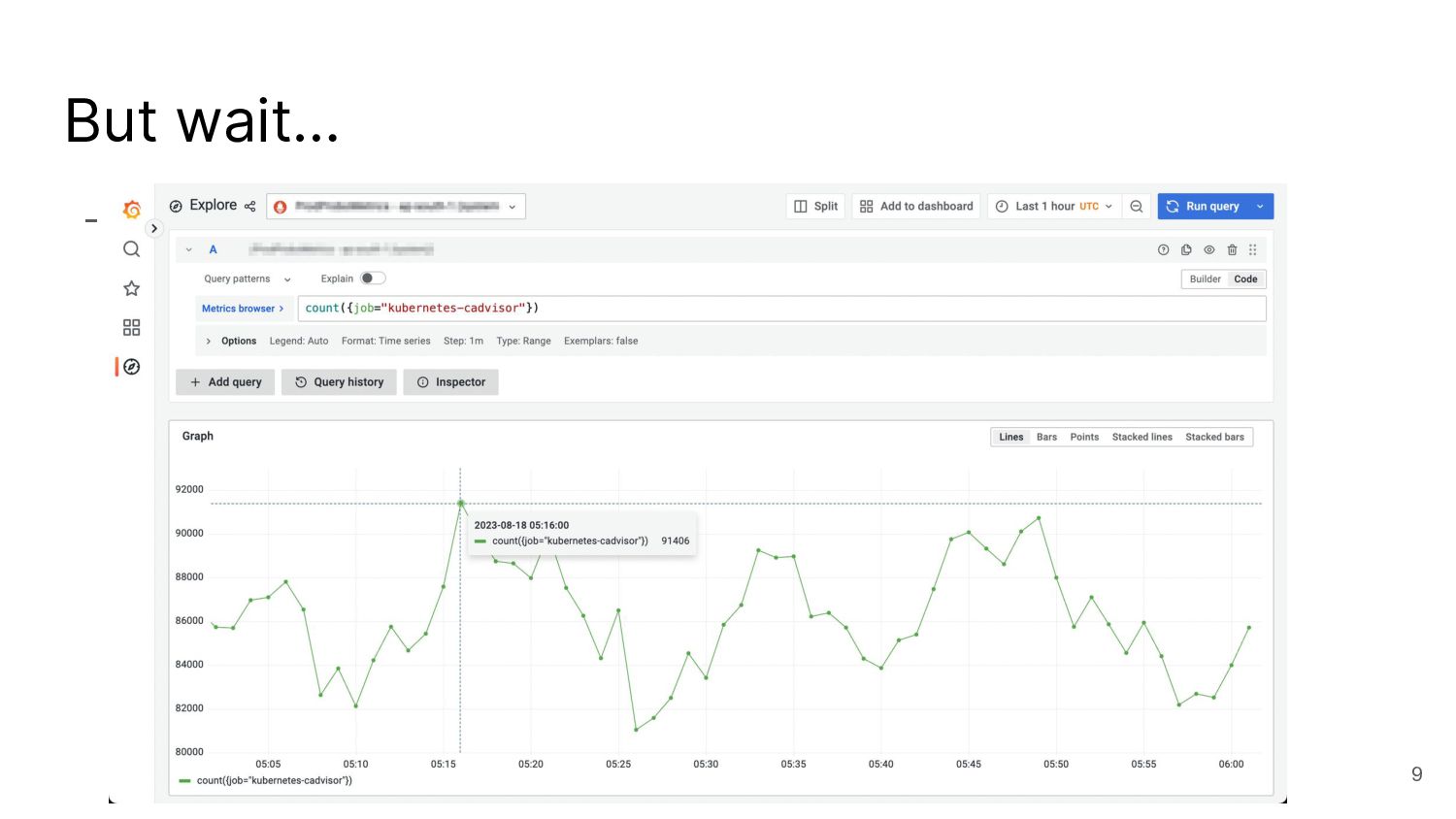
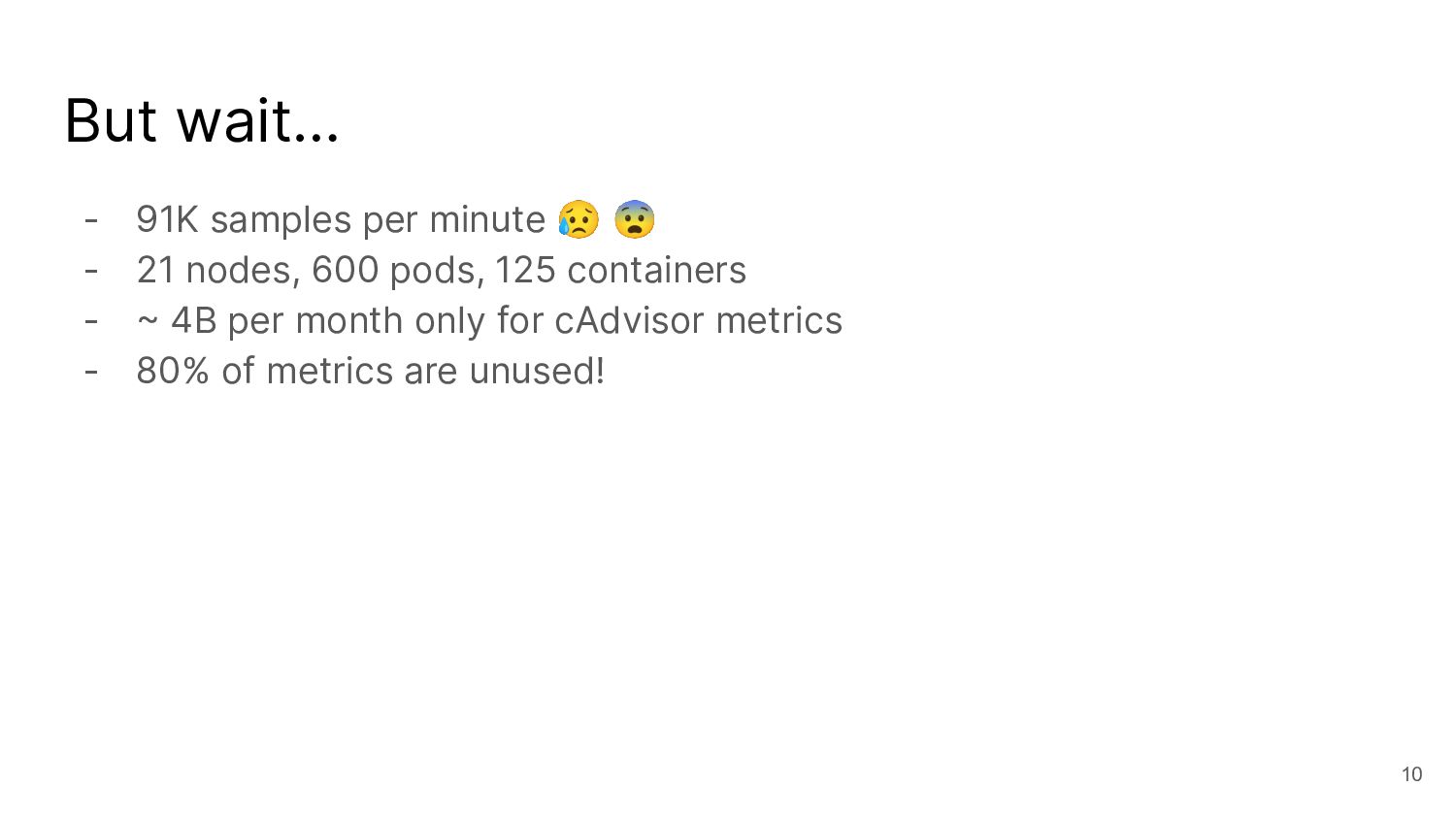
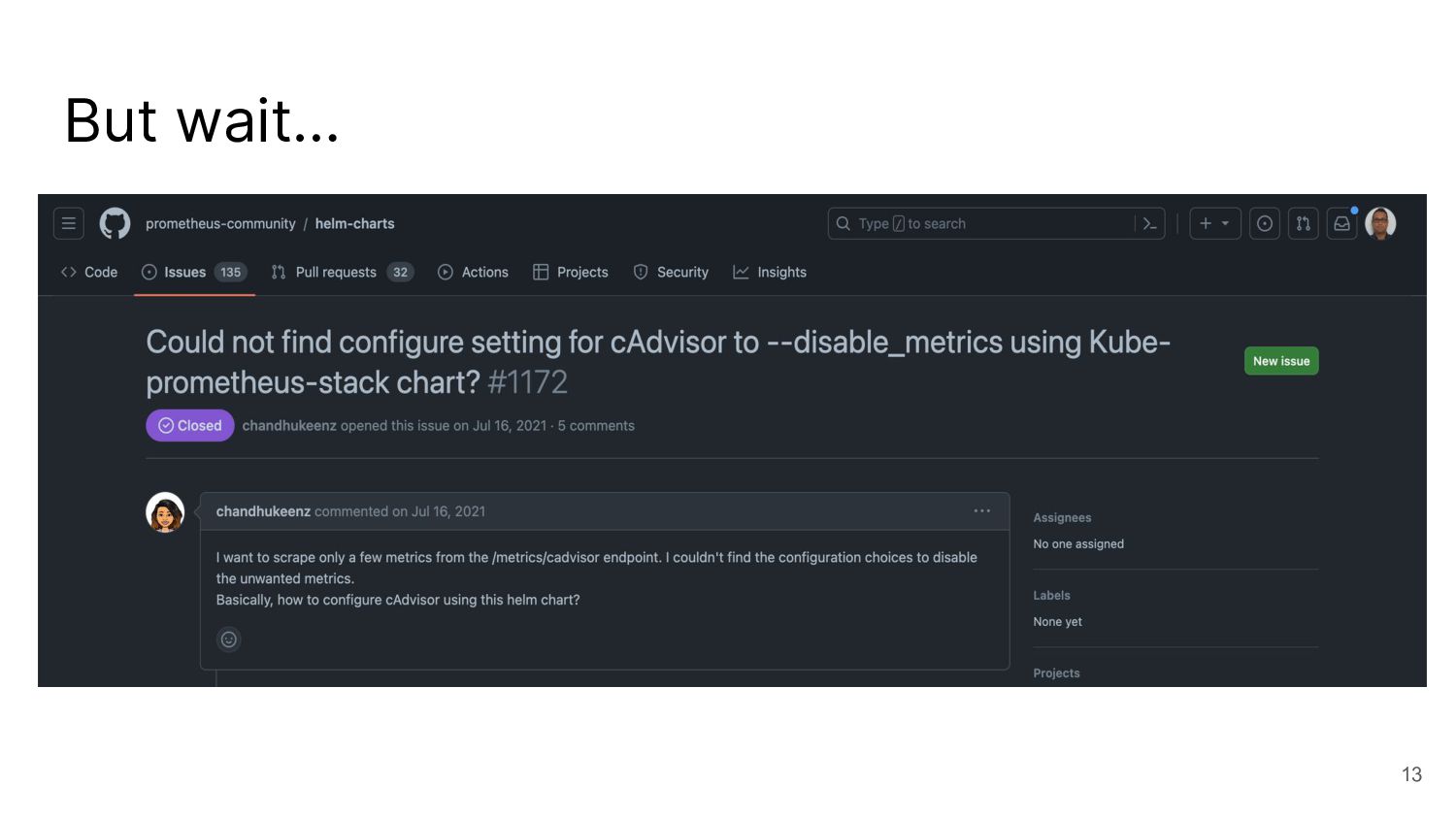
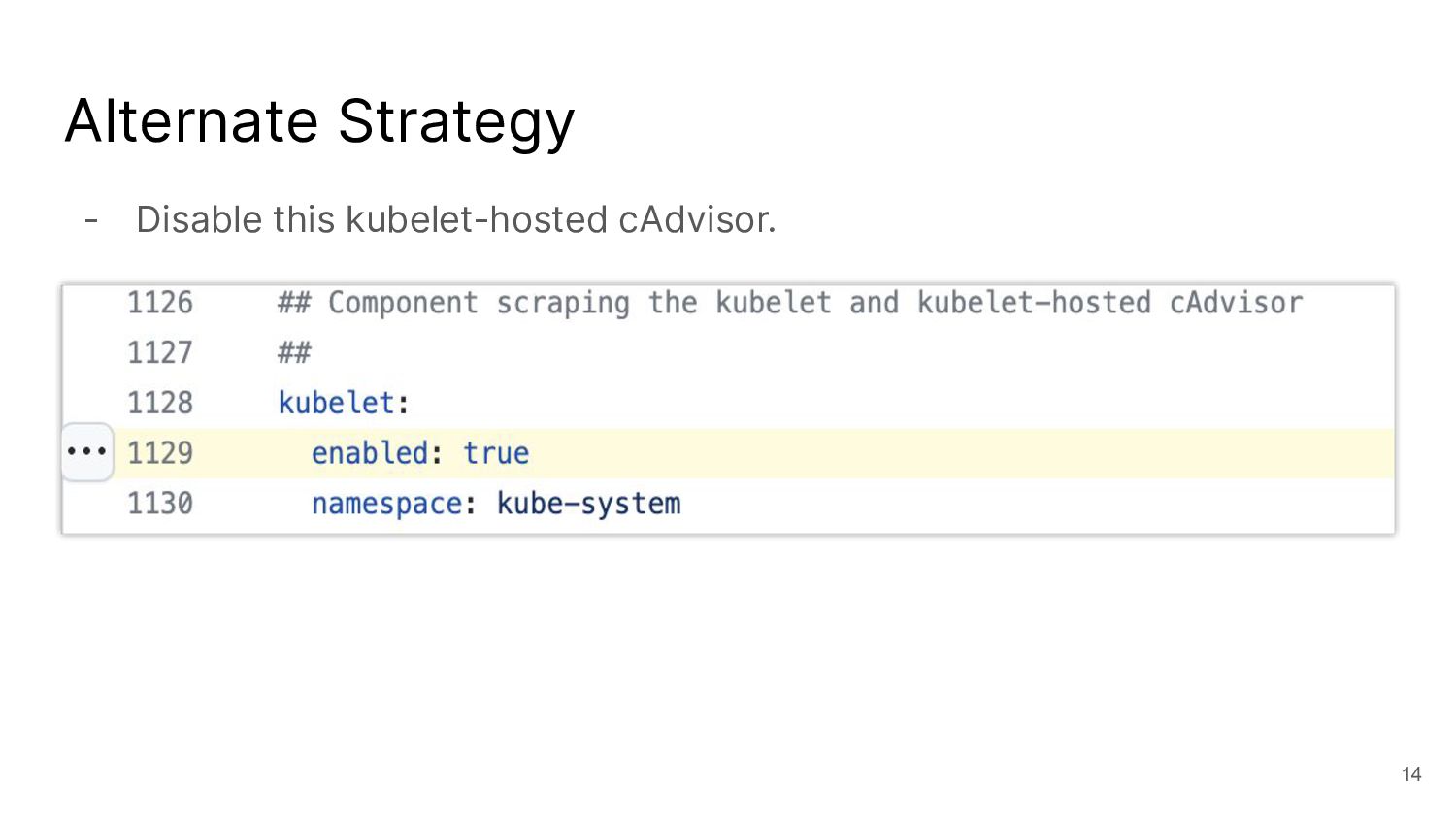
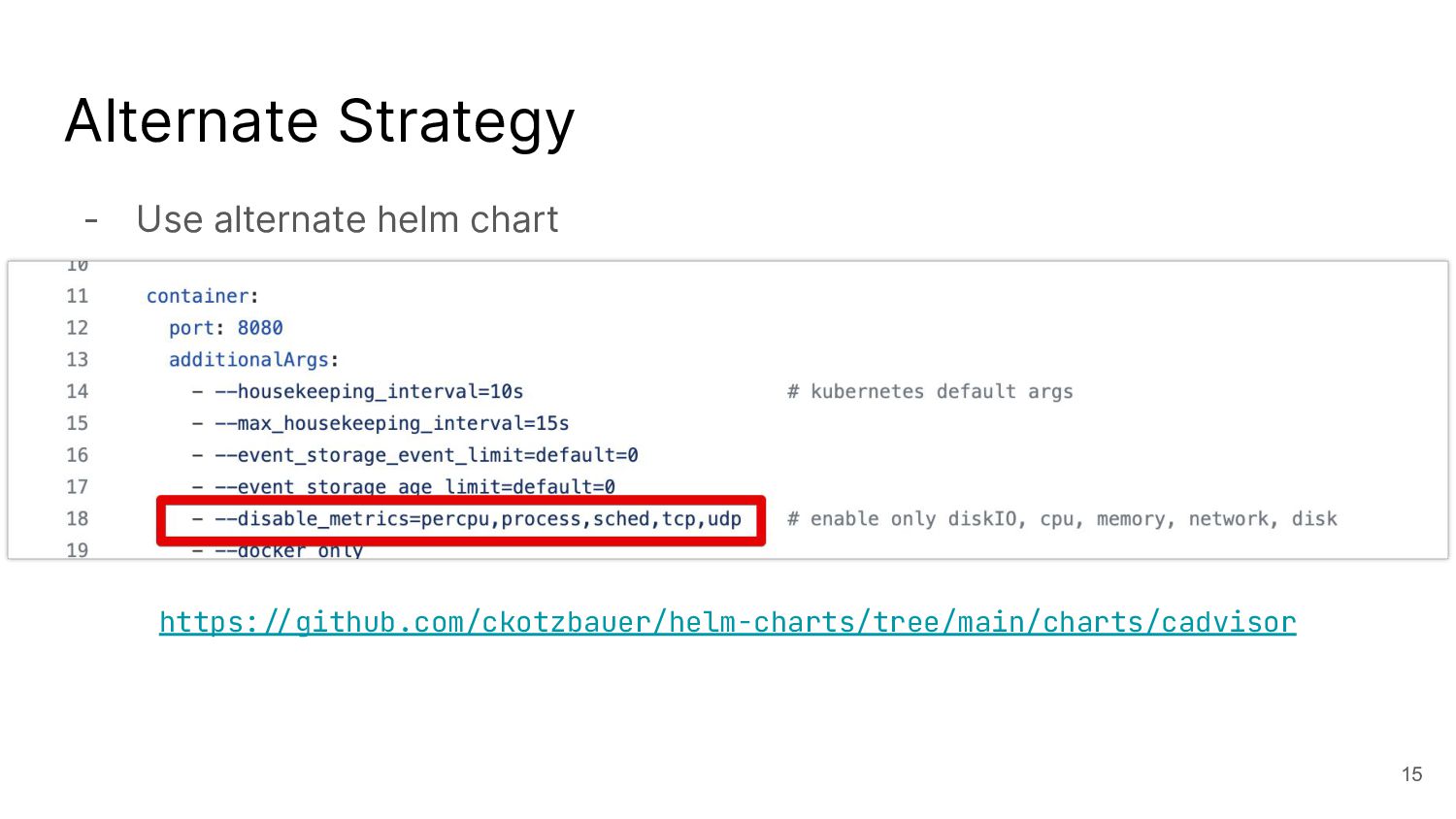
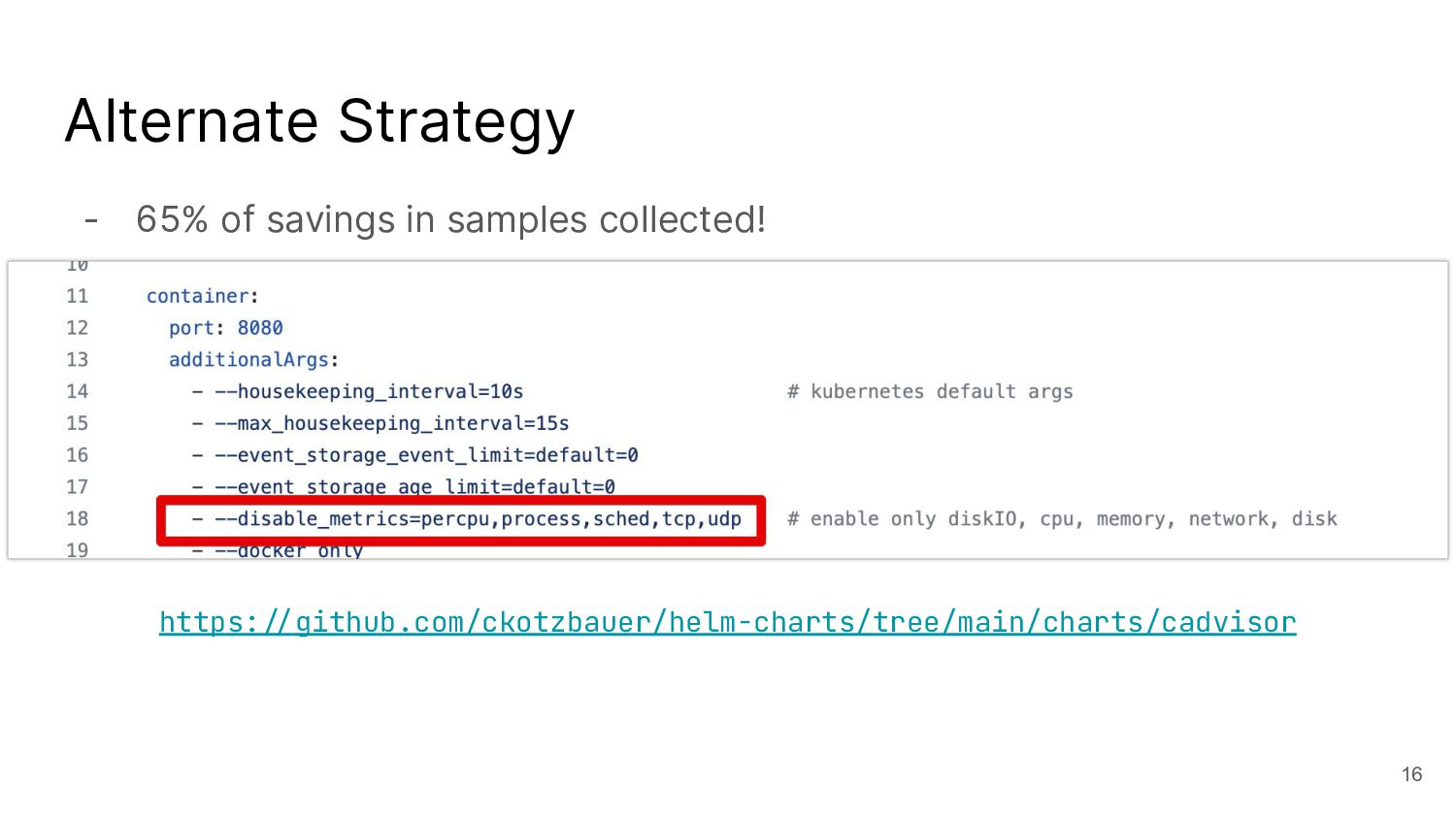
I talked about a story on reducing the number of metrics with cAdvisor, which is not possible with the out-of-the-box helm chart.
Related blog posts -
Kubernetes Monitoring with Prometheus and Grafana
How to restart Kubernetes Pods with kubectl
Read more of my writing at https://last9.io/blog/authors/prathamesh
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}