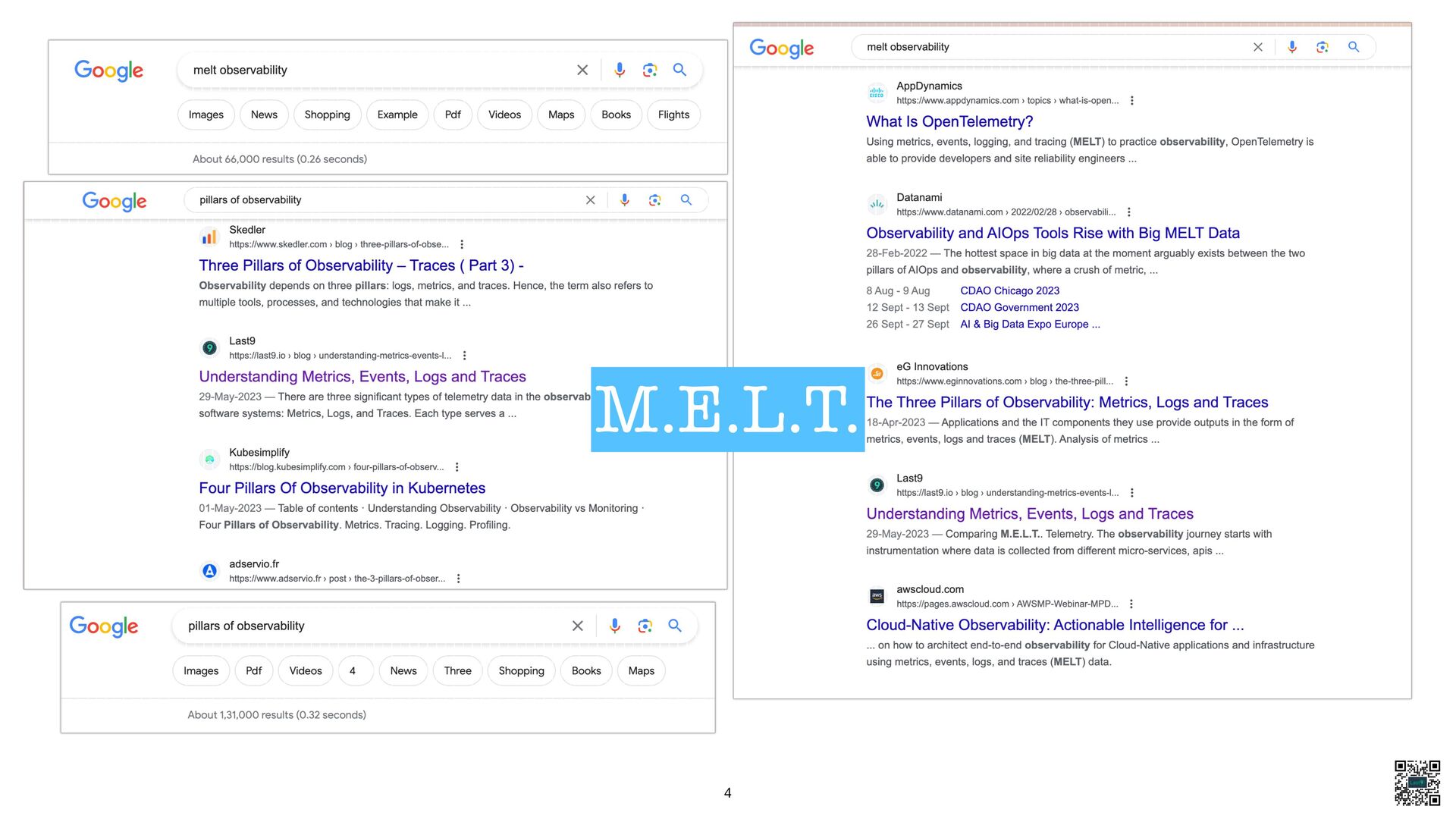
Related blog posts
https://last9.io/blog/understanding-metrics-events-logs-traces-key-pillars-of-observability/
https://last9.io/blog/observability-oss-vs-paid-vs-managed-oss/
https://last9.io/blog/taking-back-control-of-your-monitoring/
Join my Discord community to mingle with like-minded SRE/DevOps folks - https://discord.com/invite/Q3p2EEucx9
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}