Outline
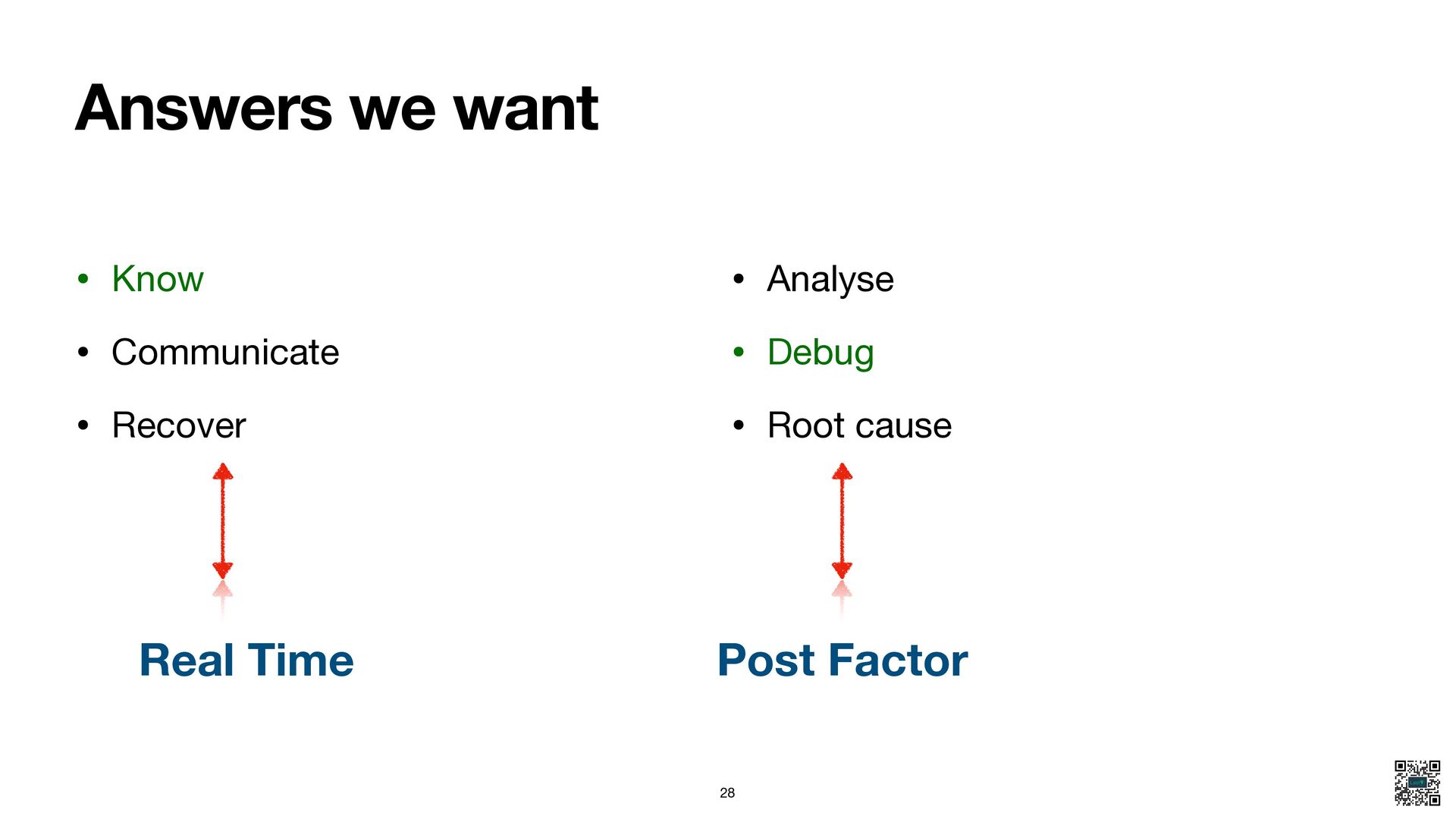
- Two categories of using observability data - monitoring vs. debugging- explain the difference.
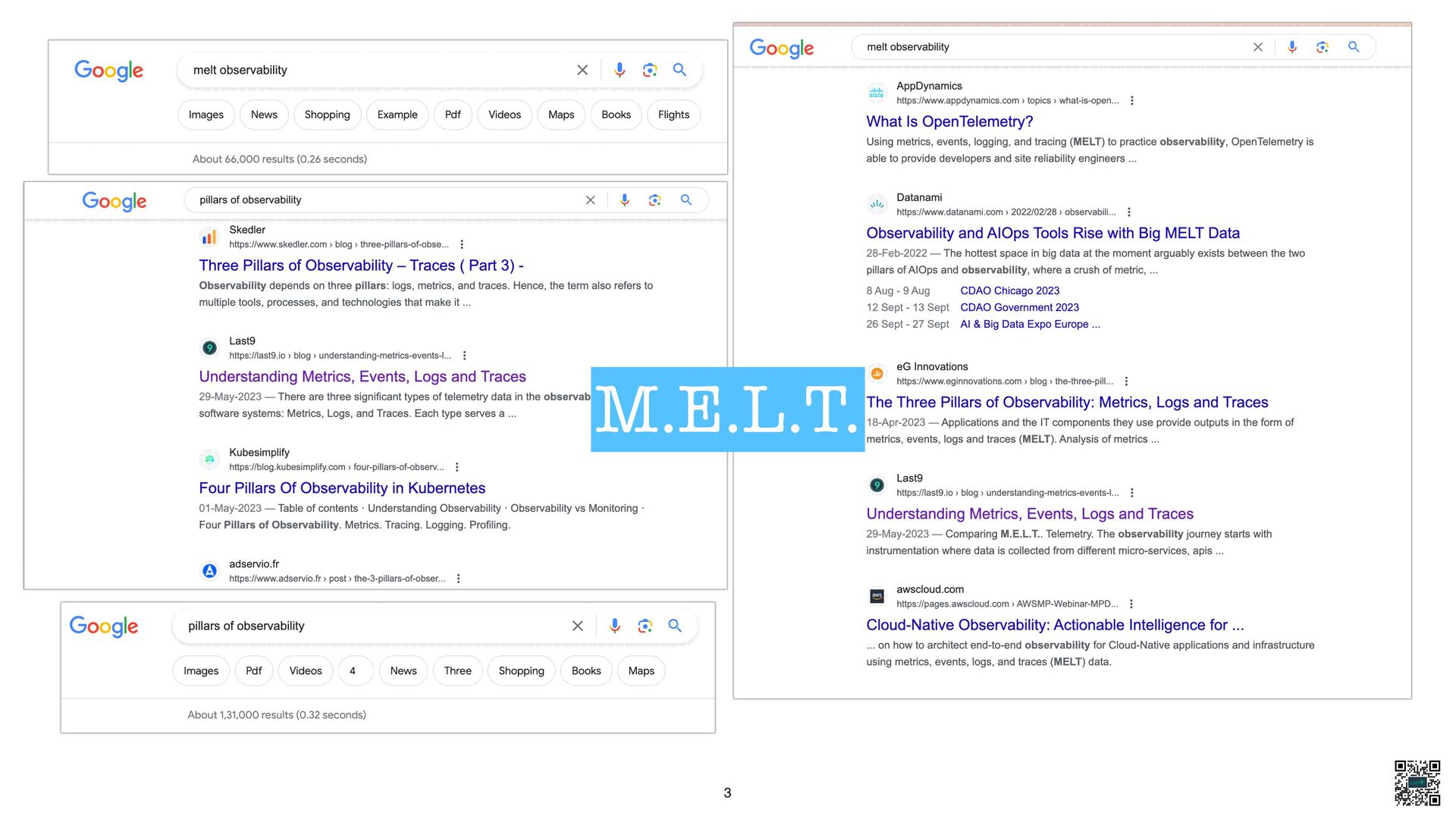
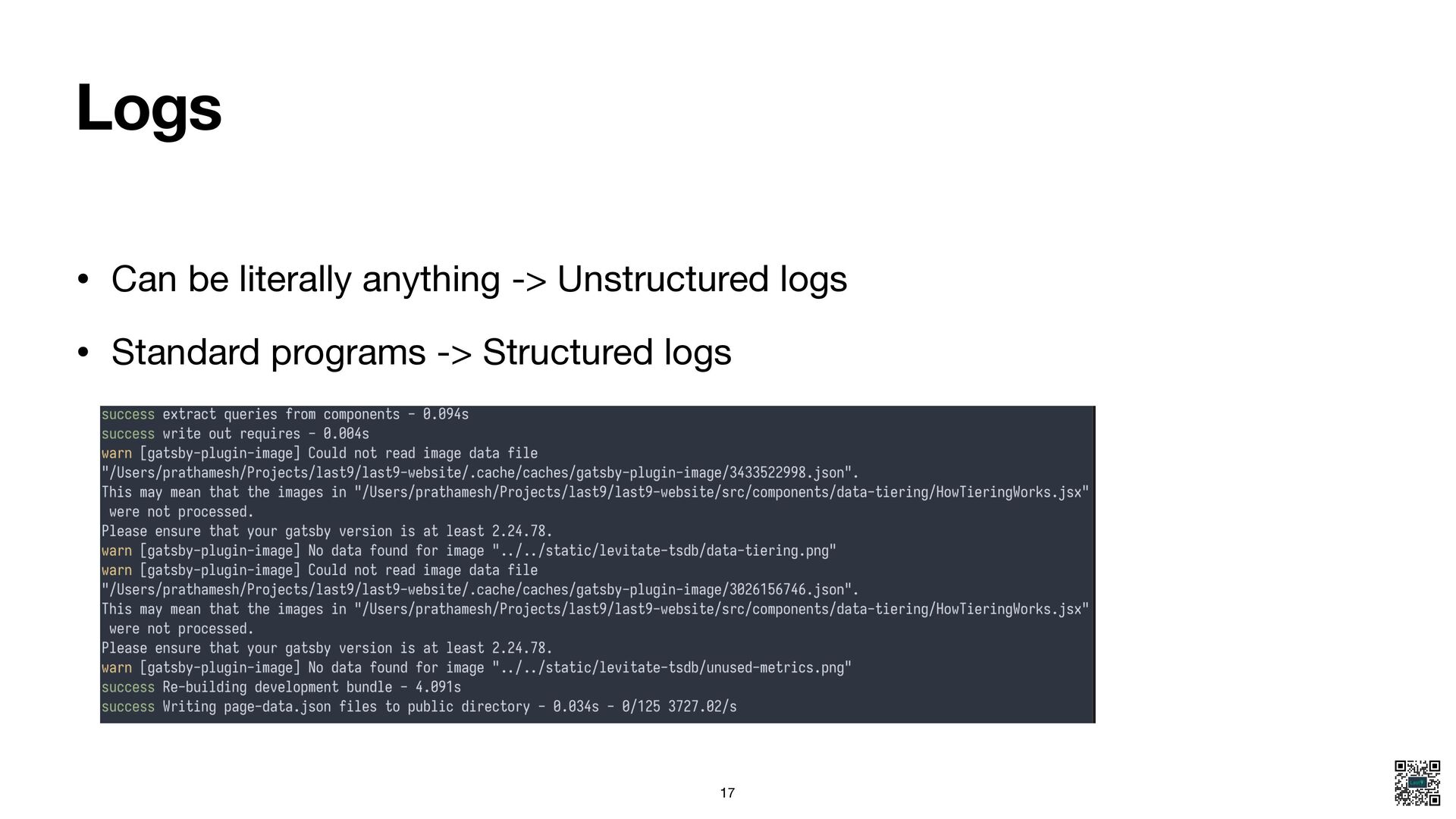
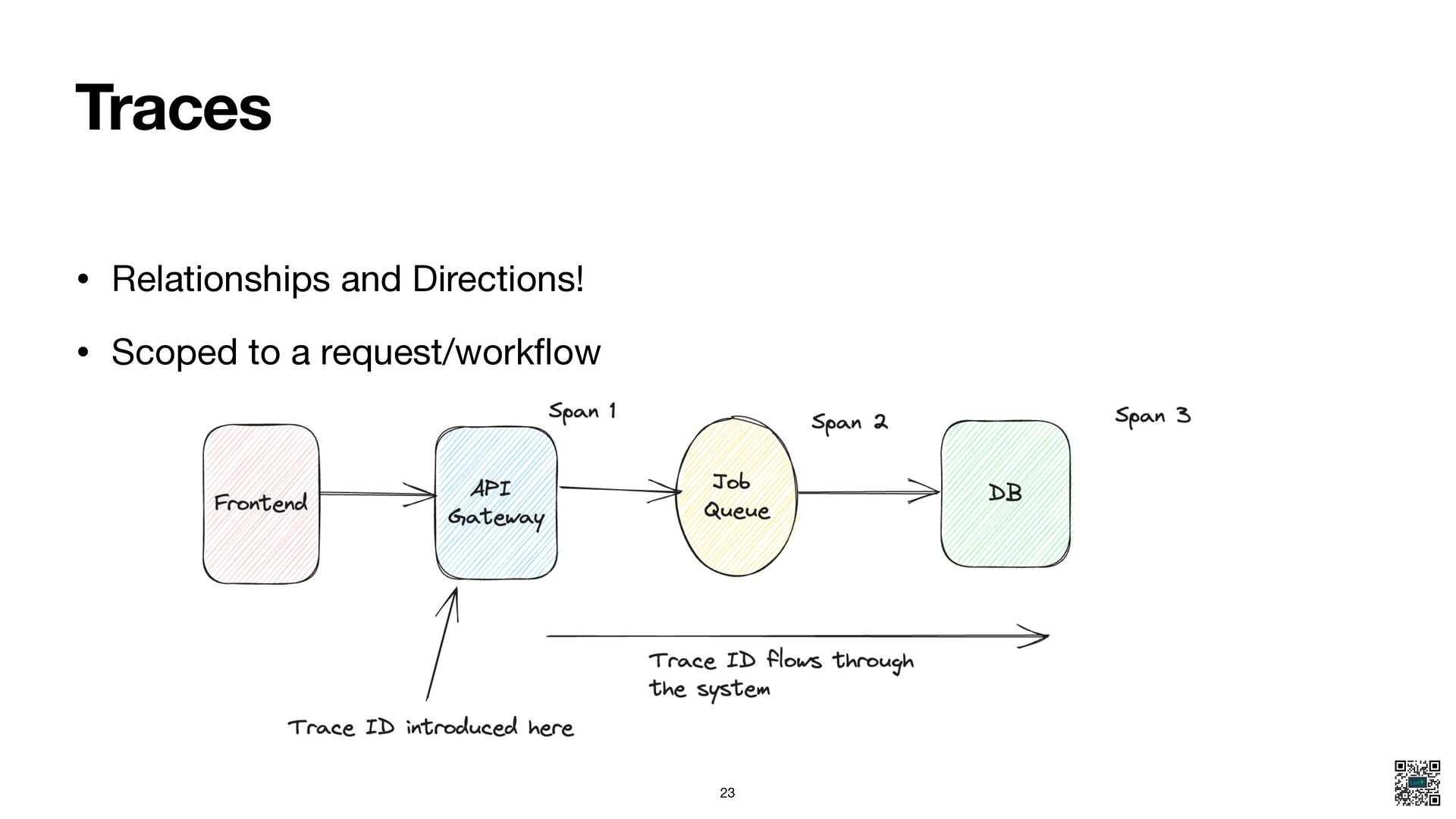
- Explain Metrics, Logs, Traces, and Events in the context of monitoring vs. debugging.
- Rise of open standards
- Importance of OpenTelemetry, OpenMetrics
- Convergence toward common goals
- Vendor-neutral
- Common ground
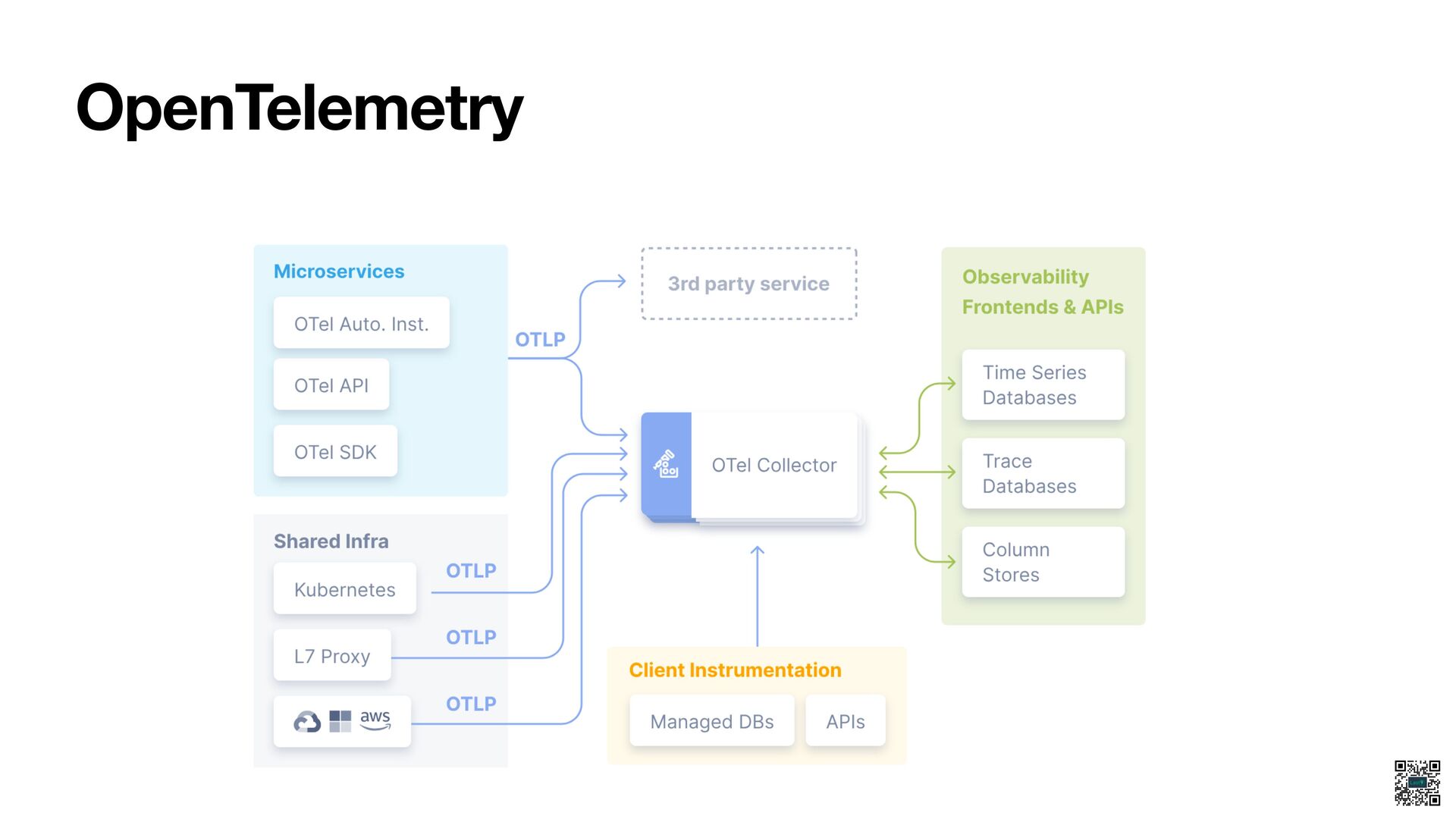
- Application monitoring using OpenTelemetry
- Automatic instrumentation vs. Manual instrumentation
- Not all data is the same
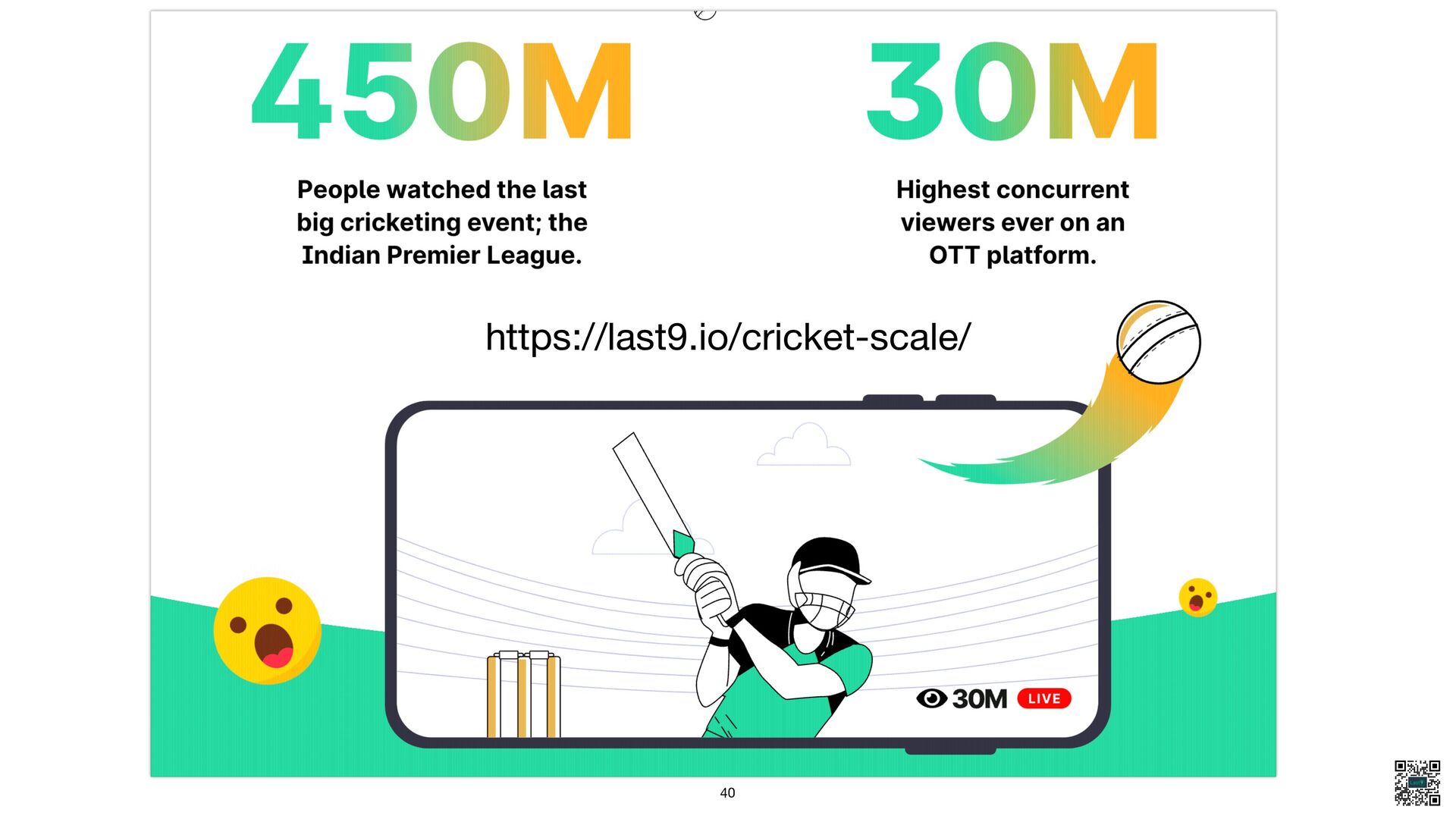
- 80% of metrics are unused
- Control levers for high precision monitoring and o11y
- Treat workloads differently
- Tiers
- Policies
- Data Engineering
- Today’s SRE/DevOps need control levers for managing o11y.
Relevant blog posts
Observability - OSS vs. Paid vs. Managed OSS
Taking back control of your monitoring
What is Prometheus Remote Write
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}