Scrapy lets you straightforwardly pull data out of the web. It helps you retry if the site is down, extract content from pages using CSS selectors (or XPath), and cover your code with tests. It downloads asynchronously with high performance. You program to a simple model, and it's good for web APIs, too.
Talk info: https://us.pycon.org/2013/schedule/presentation/135/
Full slides and code: https://github.com/paulproteus/scrapy-slides-sphinx
![Scrapy: it GETs the Web Asheesh Laroia [email protected]](https://files.speakerdeck.com/presentations/9e62fa6075740130a4401231381d6749/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
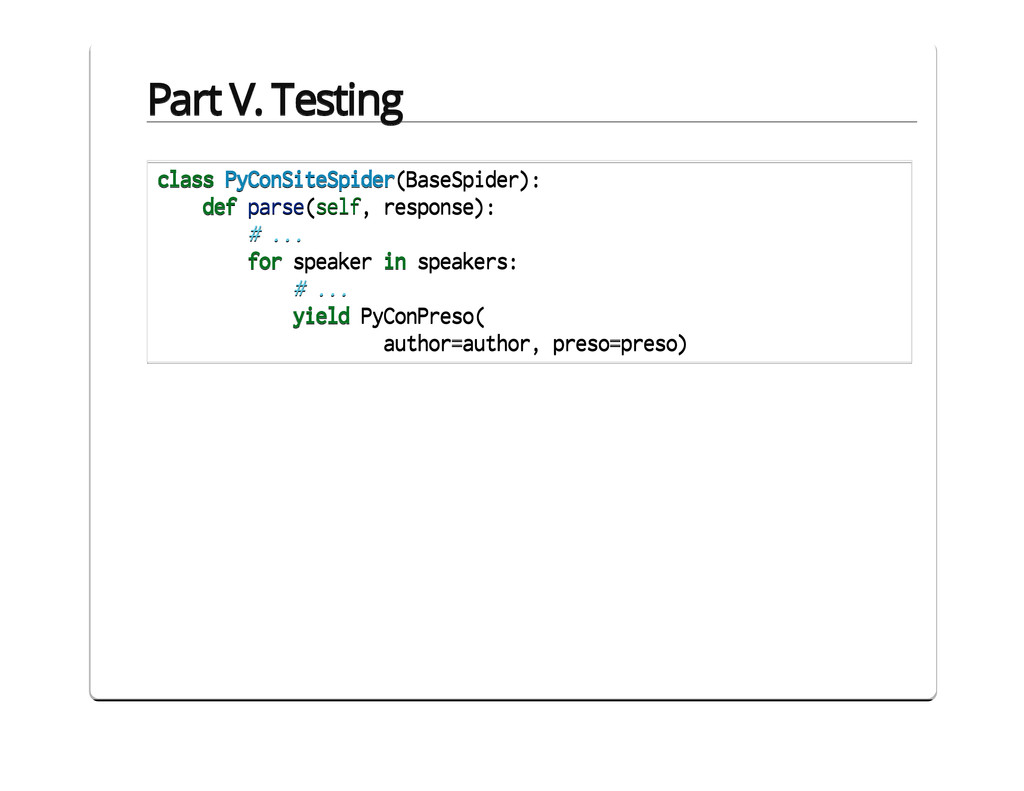{kind=link}
{kind=link}
{kind=link}
{kind=link}
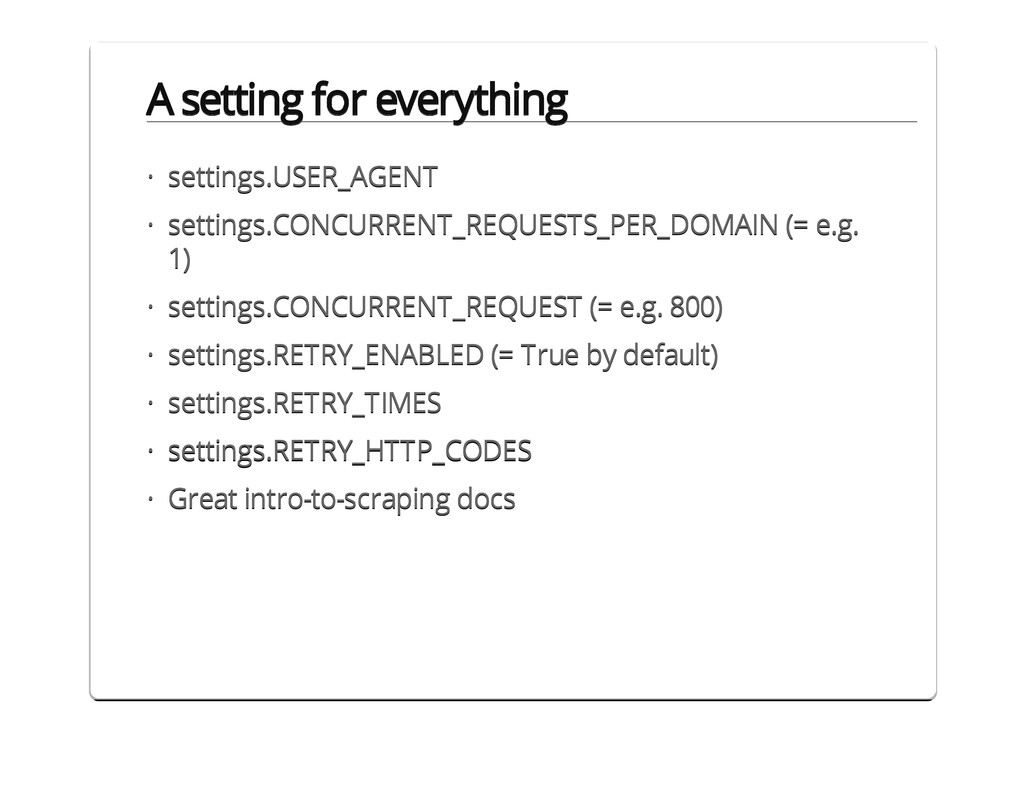{kind=link}
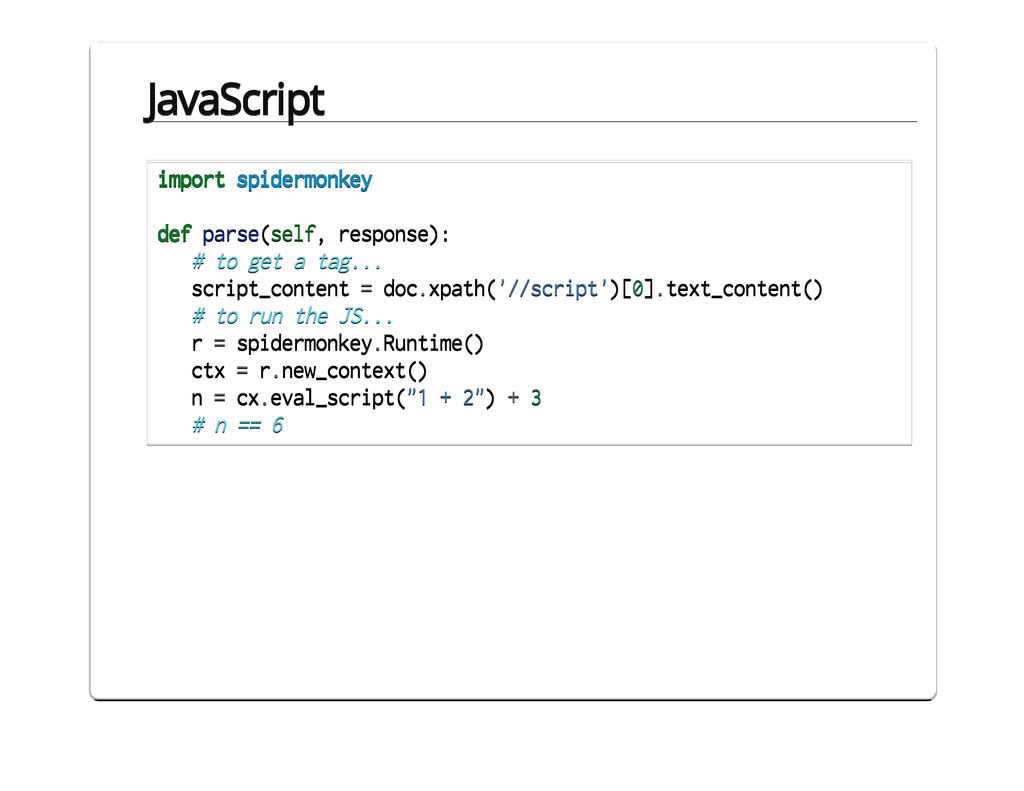{kind=link}
{kind=link}
![JavaScript import spidermonkey def parse(self, response): script_content = doc.xpath('//script')[0].text_content() #](https://files.speakerdeck.com/presentations/9e62fa6075740130a4401231381d6749/slide_48.jpg){kind=link}
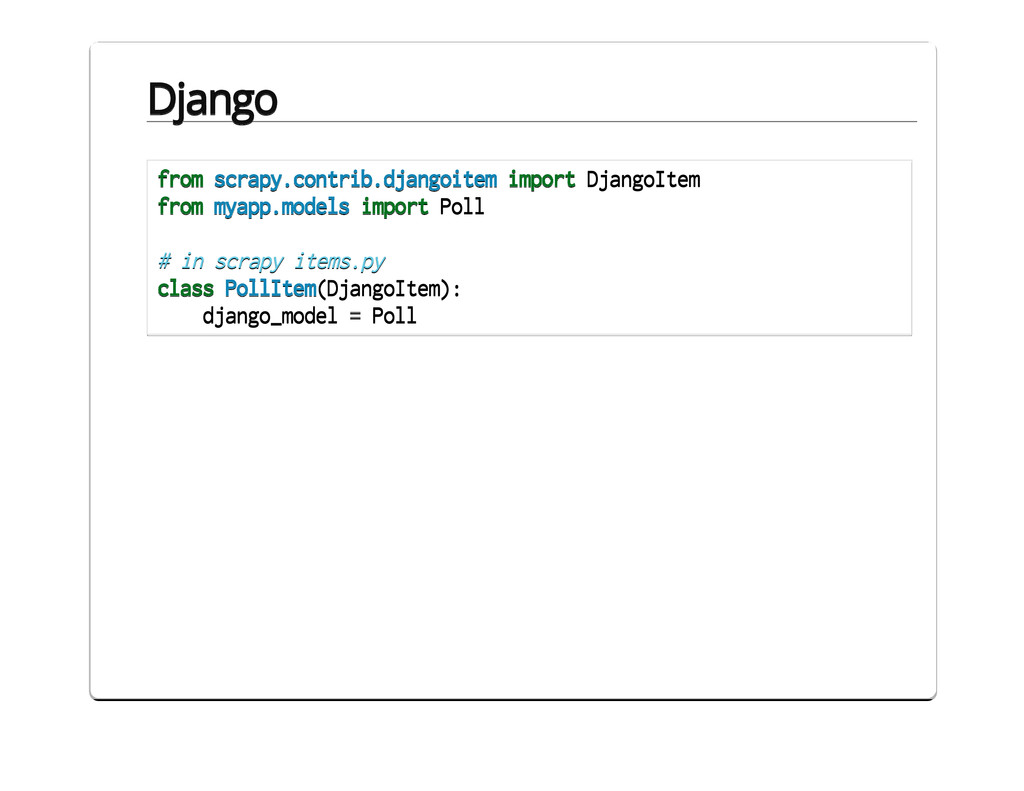{kind=link}
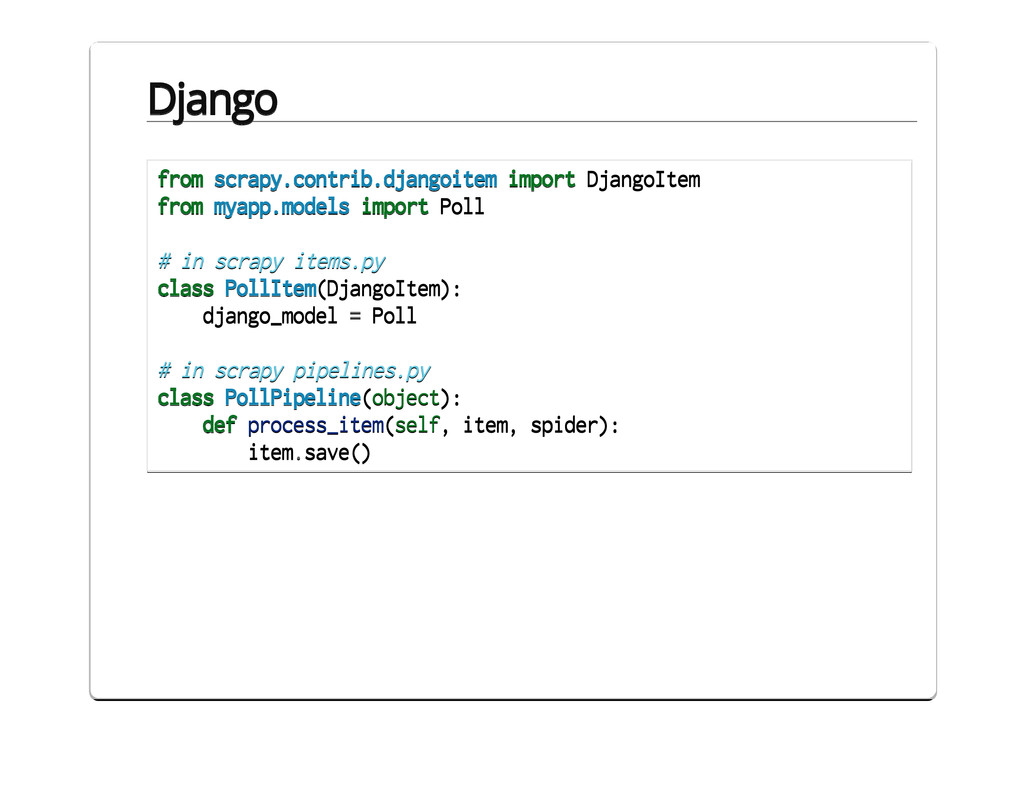{kind=link}
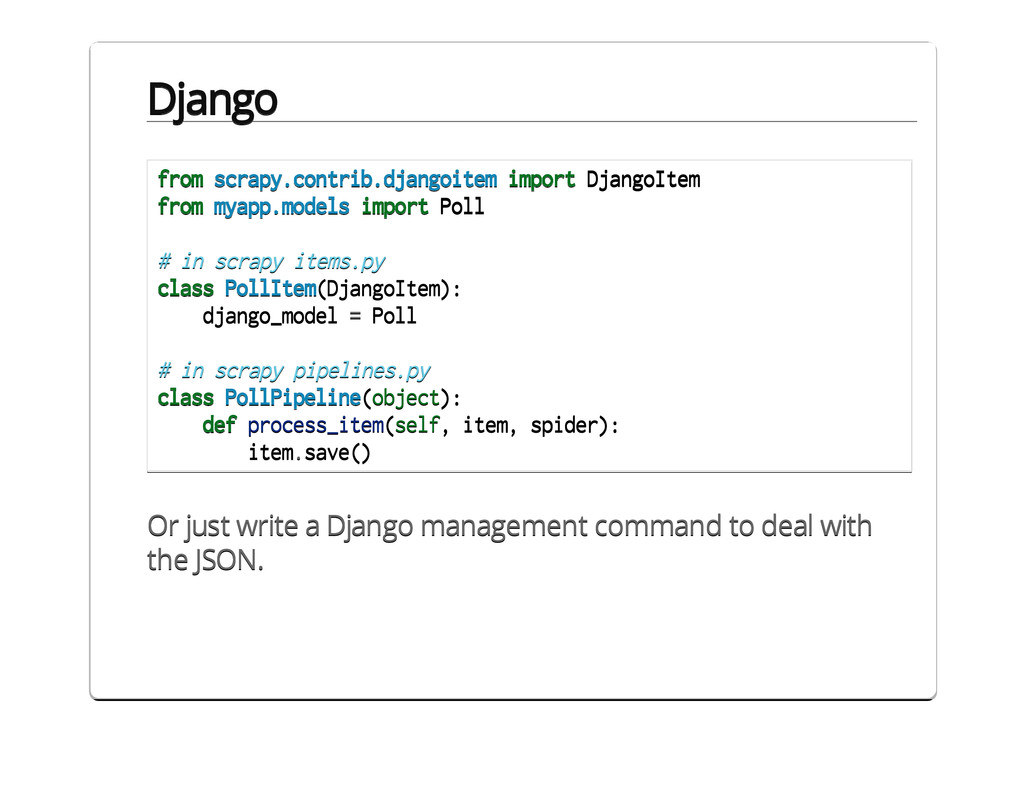{kind=link}
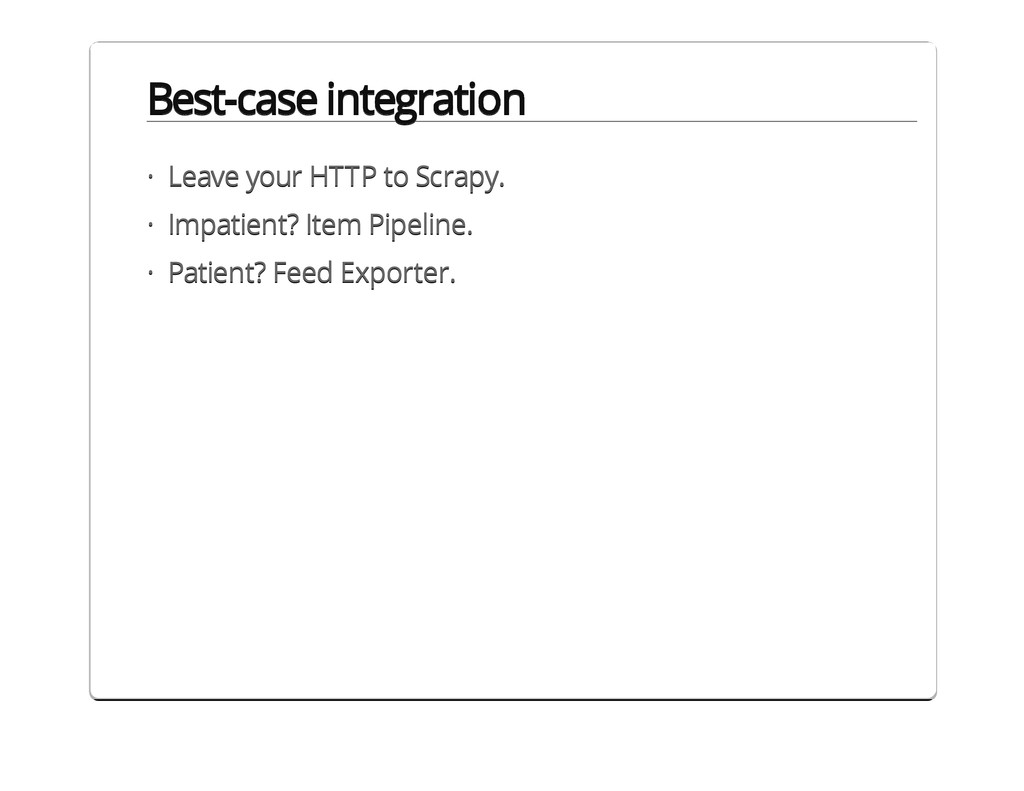{kind=link}
{kind=link}
{kind=link}