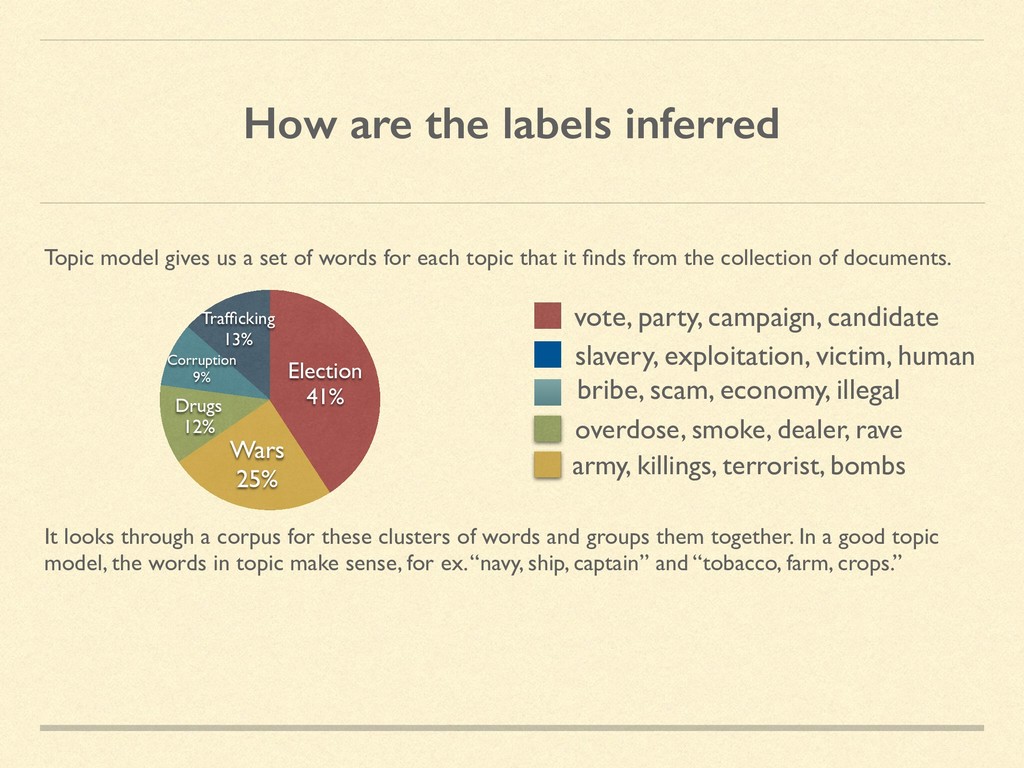
set of words for each topic that it finds from the collection of documents. It looks through a corpus for these clusters of words and groups them together. In a good topic model, the words in topic make sense, for ex. “navy, ship, captain” and “tobacco, farm, crops.” army, killings, terrorist, bombs Trafficking 13% Corruption 9% Drugs 12% Wars 25% Election 41% overdose, smoke, dealer, rave bribe, scam, economy, illegal vote, party, campaign, candidate slavery, exploitation, victim, human
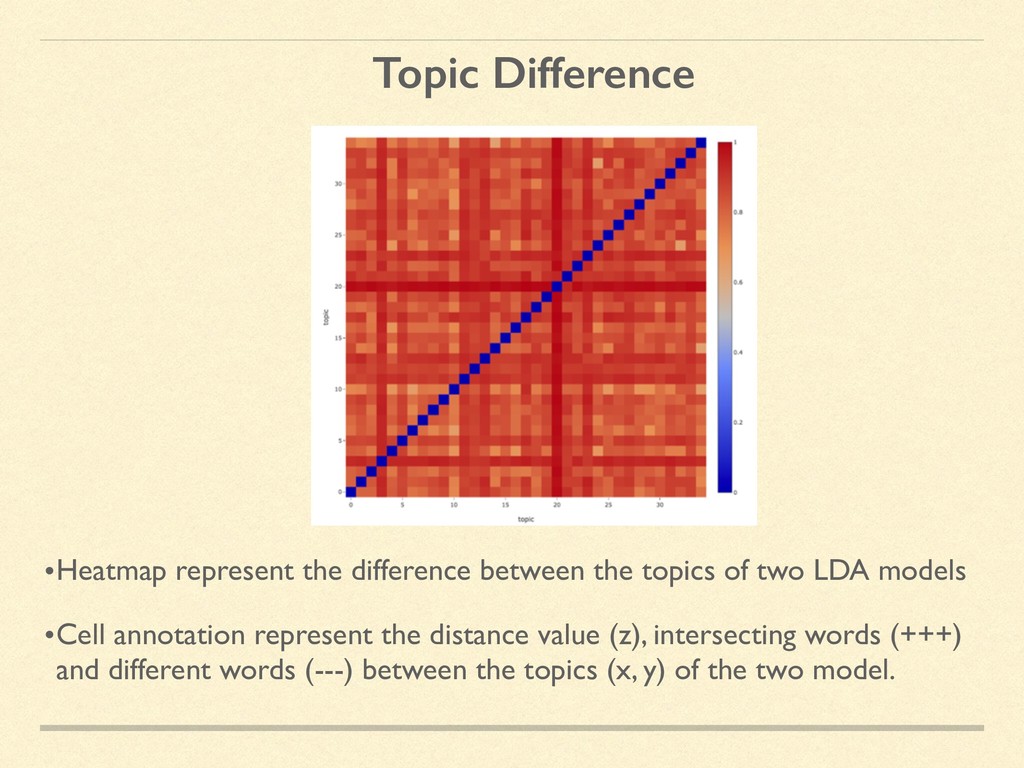
two LDA models •Cell annotation represent the distance value (z), intersecting words (+++) and different words (---) between the topics (x, y) of the two model.
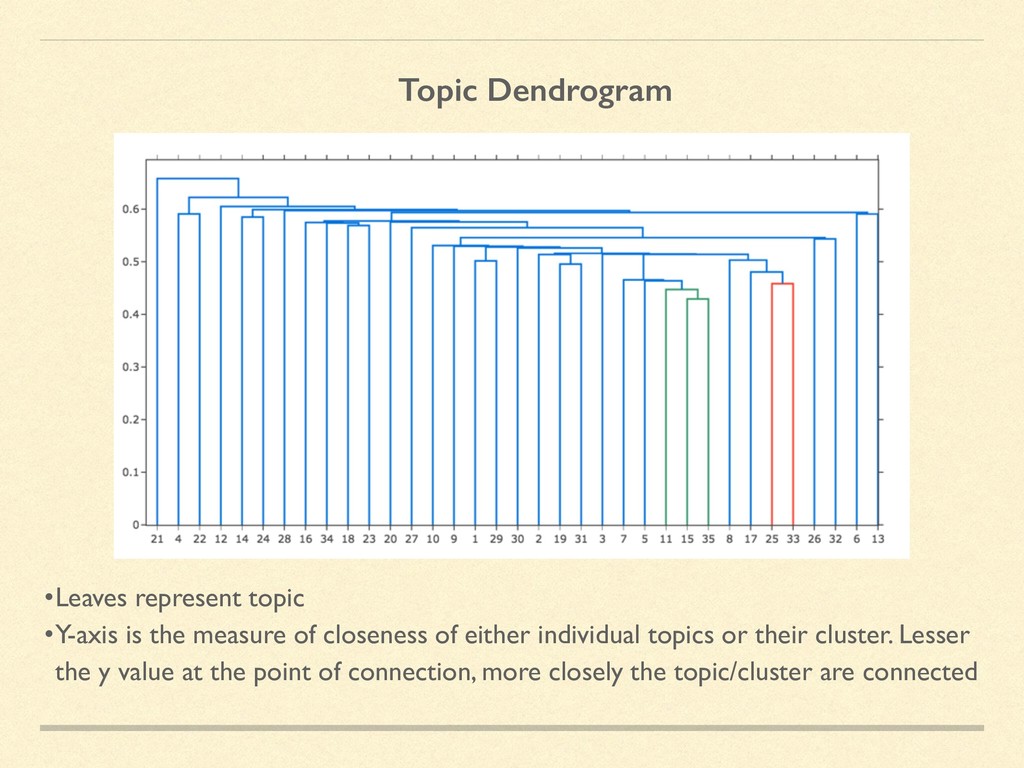
topics created based on their distance •Node’s label define the topic no. and top 10 words •Edge’s label define the intersecting/different words between the two connected topics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}