wannabe web engineer at Huge) Python Medellin meetups co-organizer Google Cloud Certified Data Engineer Freelancer Machine learning lover Data science FEM - Mentor
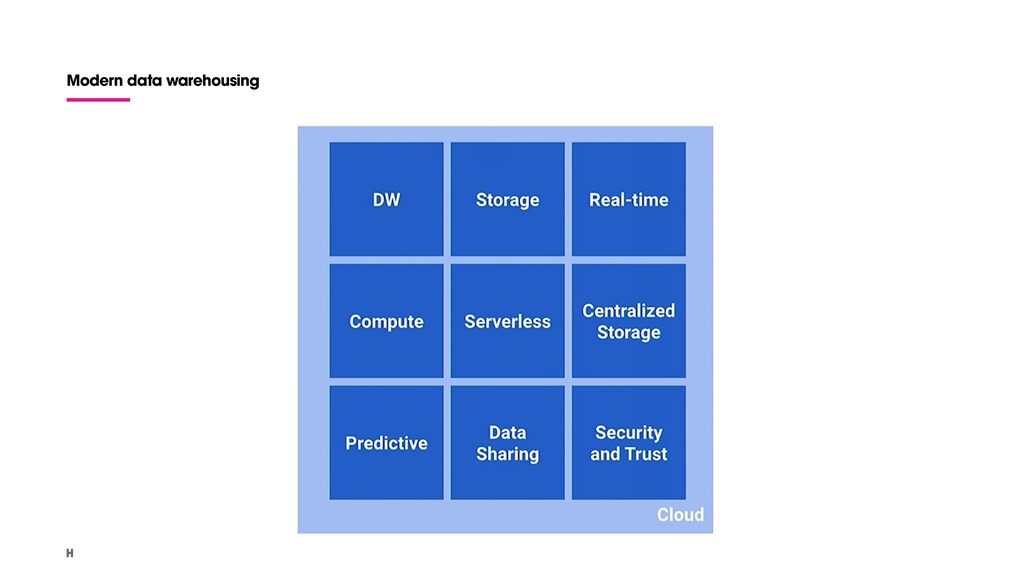
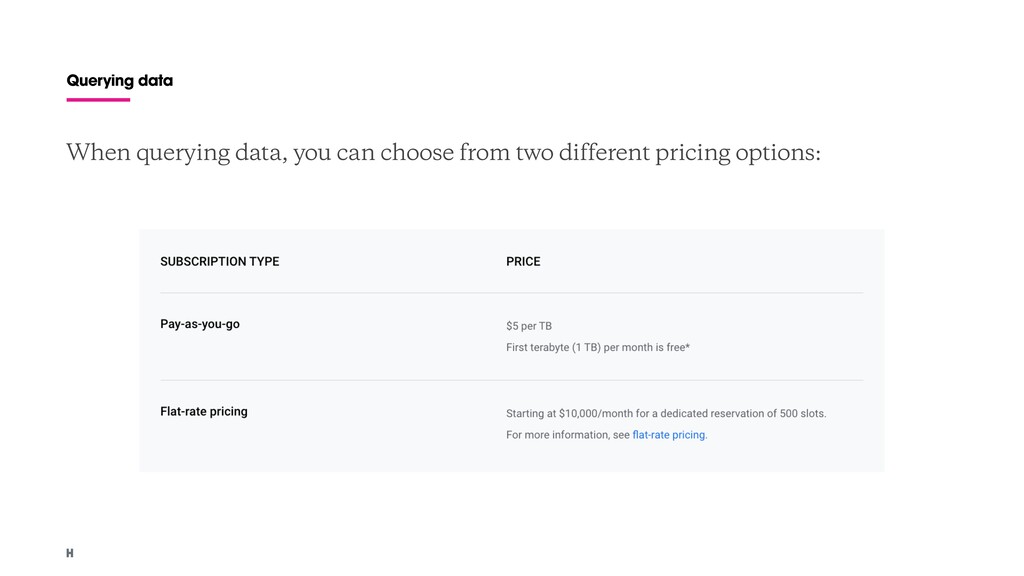
low cost analytics data warehouse. Remarkable features: - NoOps - Pay-as-you-go model - Securely share insights. - Streaming ingestion captures and real time analyses. - Analyze up to 1 TB of data and store 10 GB of data for free each month.
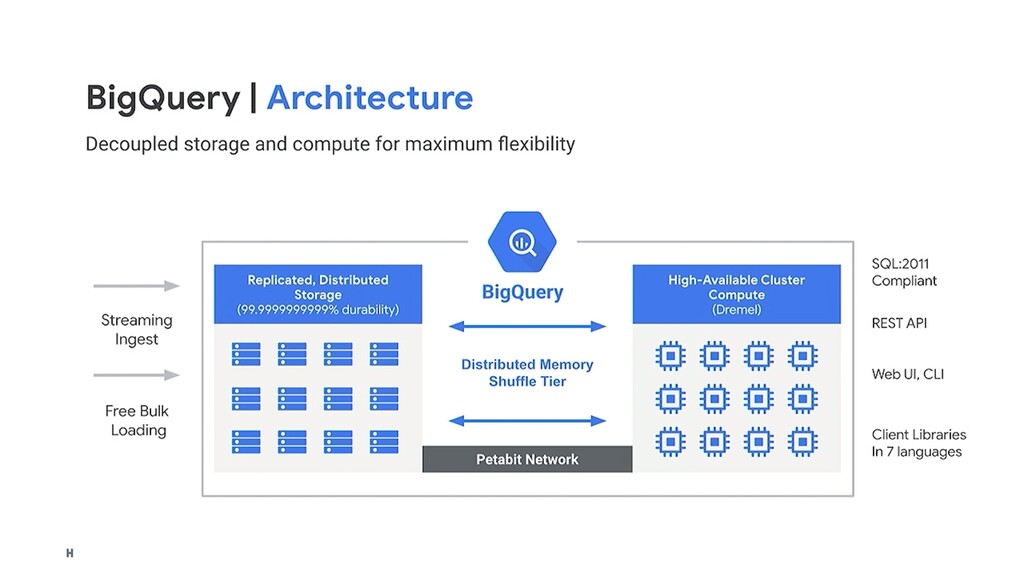
real-time) Automatic high availability: Replicated storage in multiple locations Standard SQL: Reduces code rewrites (Columnar database) Federated query and logical data warehousing: Several external sources Storage and compute separation - Every column is stored in a separated file. Meant for immutable pretty large datasets. (Not a transactional DB)
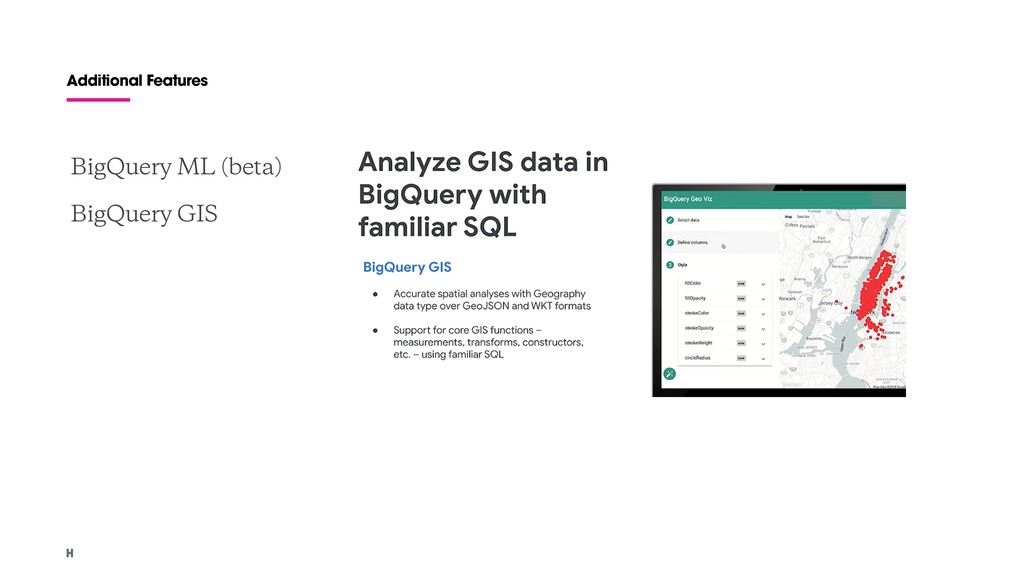
Geospatial data types and functions: SQL support for GeoJSON and WKT. Data transfer service Big data ecosystem integration: Dataproc and Dataflow connectors Petabyte scale Flexible pricing models Data governance and security: Security with fine-grained identity
of tools to connect, process, store, and analyze data both at the edge and in the cloud. Use cases: 1. Predictive maintenance 2. Real-time asset tracking 3. Logistics & supply chain management 4. Smart Cities & Buildings
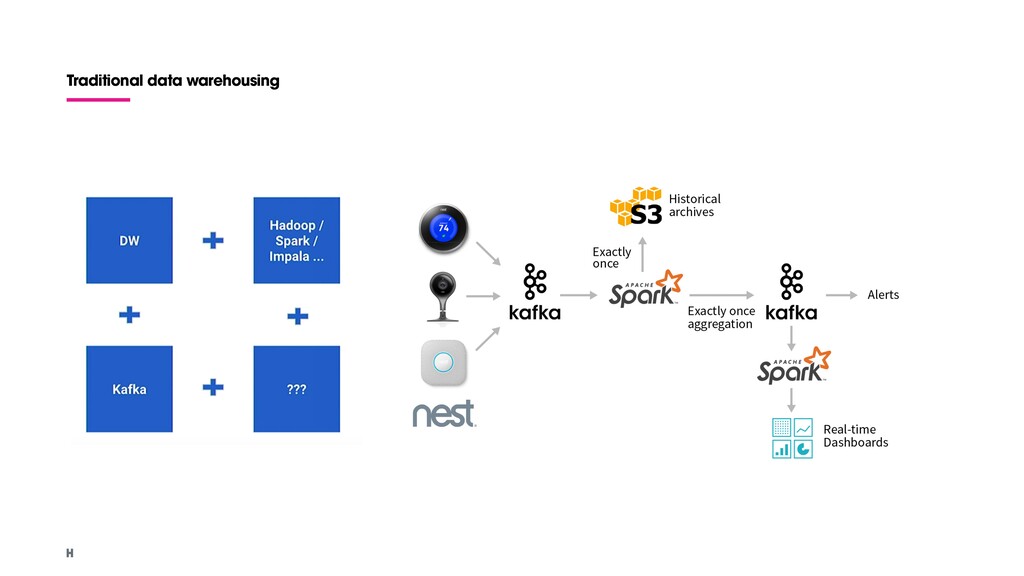
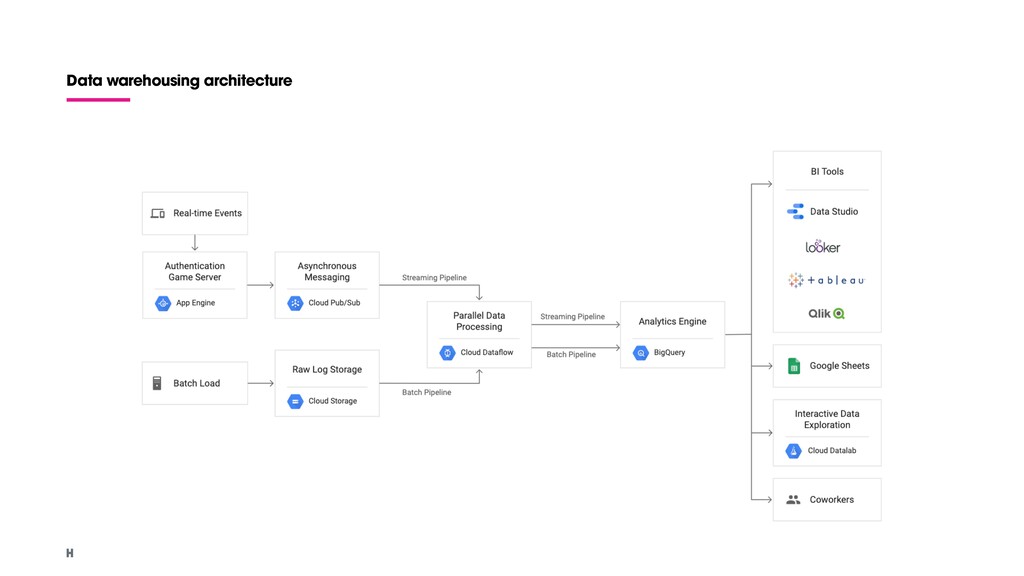
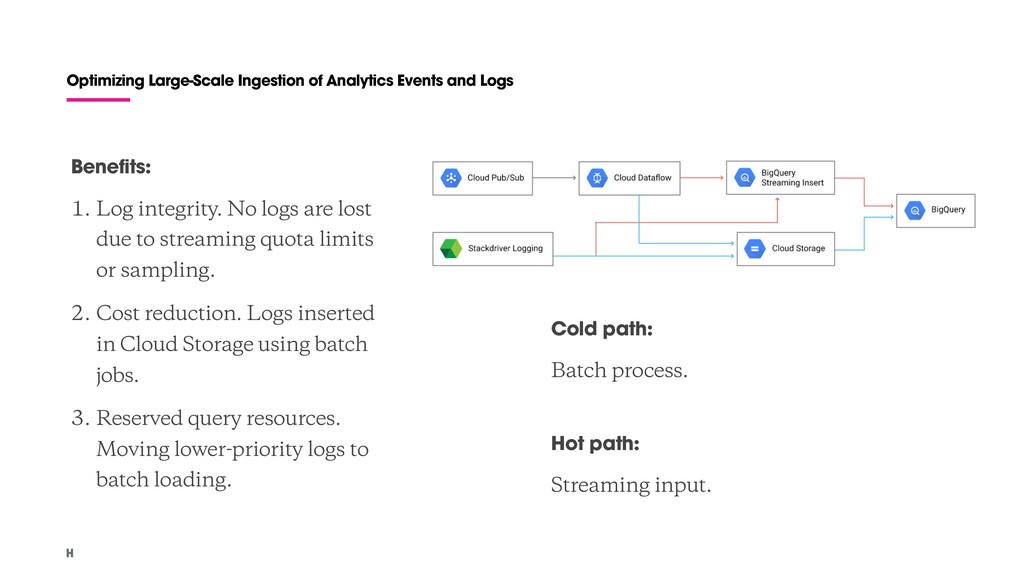
Log integrity. No logs are lost due to streaming quota limits or sampling. 2. Cost reduction. Logs inserted in Cloud Storage using batch jobs. 3. Reserved query resources. Moving lower-priority logs to batch loading. Cold path: Batch process. Hot path: Streaming input.
insight by hosting their data offerings directly in BigQuery, Cloud Storage and Cloud Pub/Sub. Examples: • AccuWeather: min/max temperatures, precipitation, and snowfall • Dow Jones: historical News Snapshots • HouseCanary: historical home price • Xignite: financial market data
-> Repeating fields in the data to gain processing performance. • Always check how many bytes are you reading. • How many bytes are you sending to the next stage. • How many bytes are you writing? • Dont use: SELECT * , What are the relevant columns? • Filter as early as possible. Use WHERE clauses as early as possible. • JOINs => Bigger JOIN first smaller JOIN later. • Check if there is a reasonable approximate functions. • Sorting => Outer most query.
schema when you load data into a table, and when you create an empty table. When you specify a table schema, you must supply each column's name and data type. You may optionally supply a column's description and mode. A column name cannot use any of the following prefixes: • _TABLE_ • _FILE_ • _PARTITION
month, day, hour, minute, second, and subsecond Time: A time, independent of a specific date Timestamp: An absolute point in time, with microsecond precision Struct (Record): Container of ordered fields each with a type (required) and field name (optional) Geography: A pointset on the Earth's surface (a set of points, lines and polygons on the WGS84 reference spheroid, with geodesic edges)
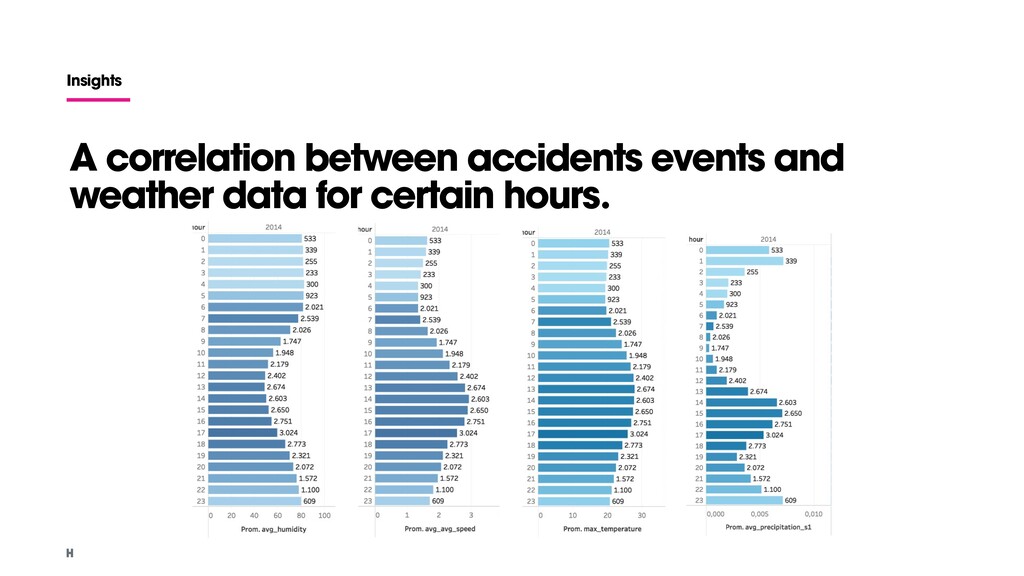
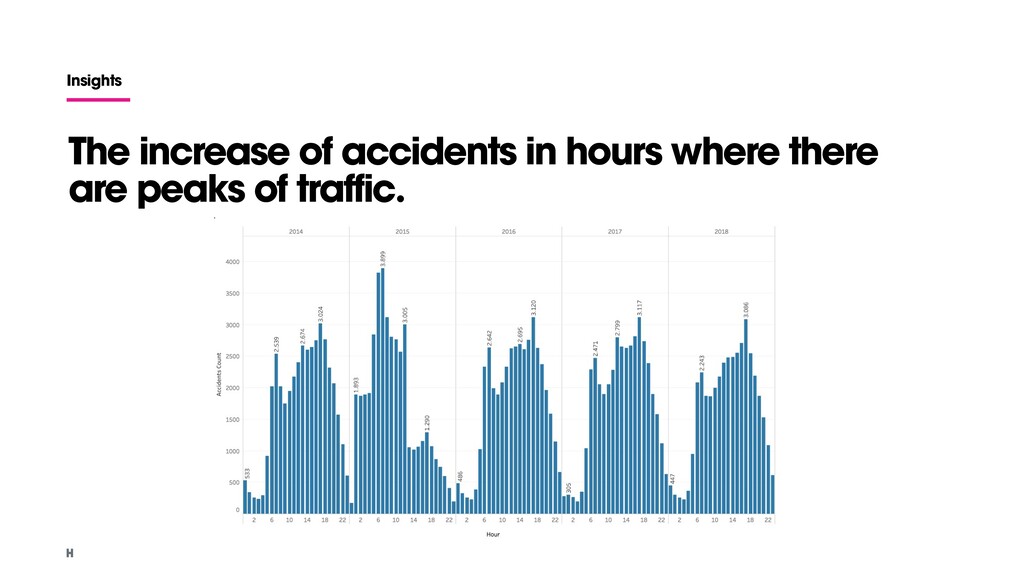
the data collected? Examples: • How does climate affect the way people move? • Is there any relationship between weather and accidents? • Is there a relationship between speed and accidents? • Is traffic linked to pollution? Open datasets Accidents data (2014 - 2018) Weather data Pressure, humidity, wind, temperature and precipitation (2014-2018) Traffic and alerts data Waze data (2017-2018)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}