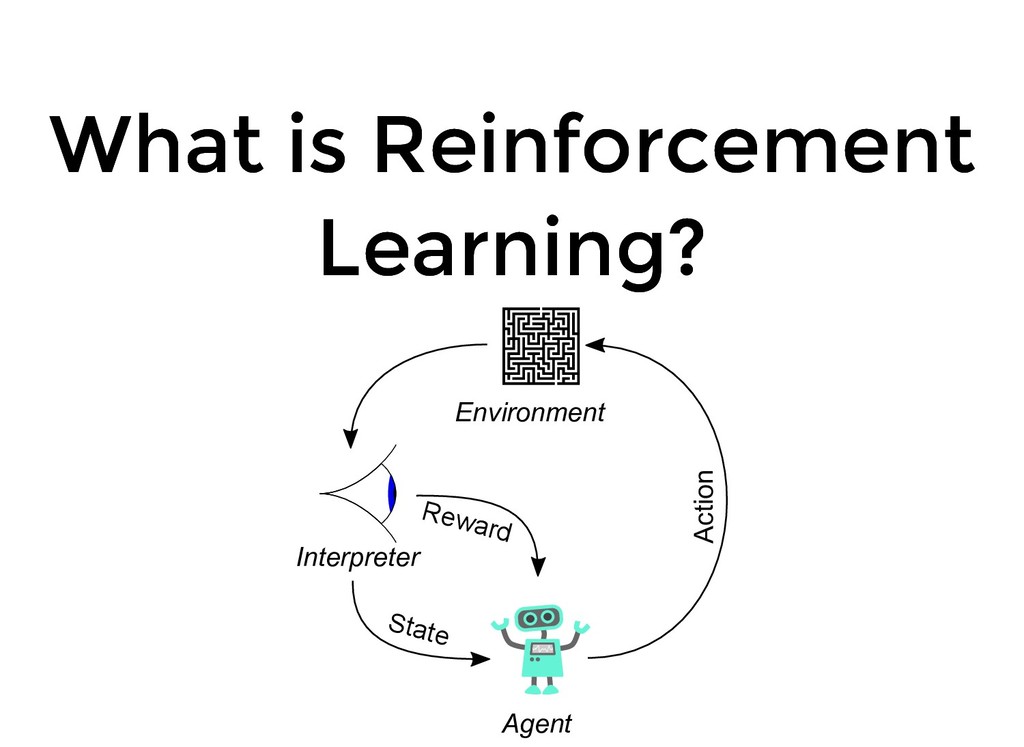
¿Quieres conocer los fundamentos detrás de la tecnología que permitió vencer al campeón mundial de go?, ¿Te gustaría comprender como se le puede enseñar a una maquina a solucionar problemas sin tu intervención directa?
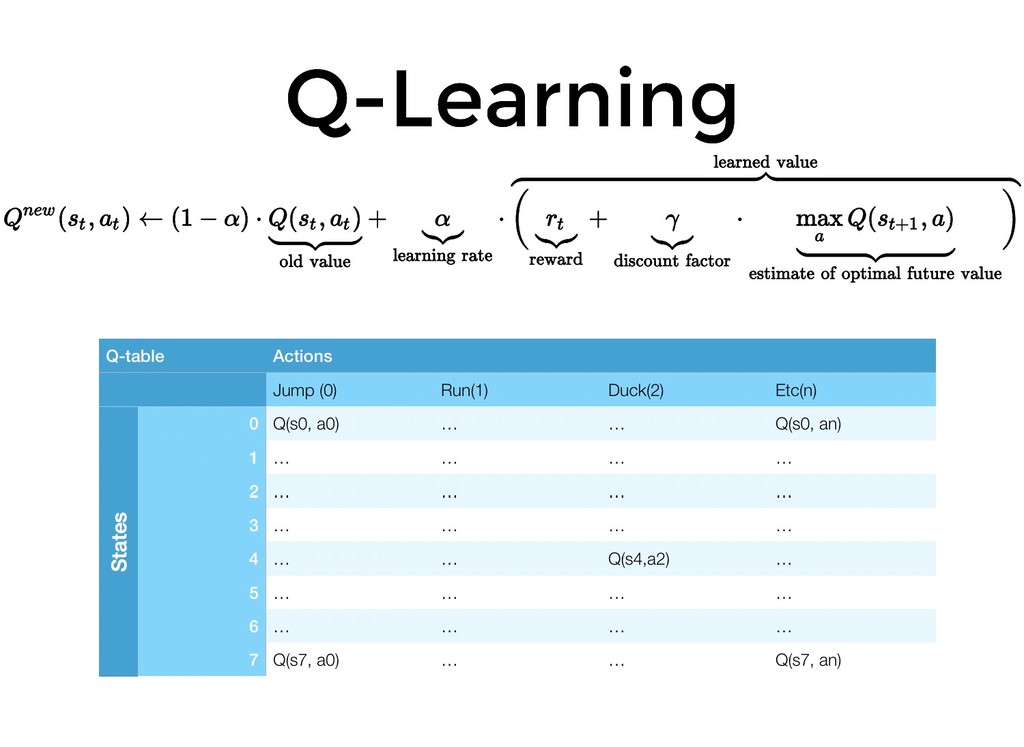
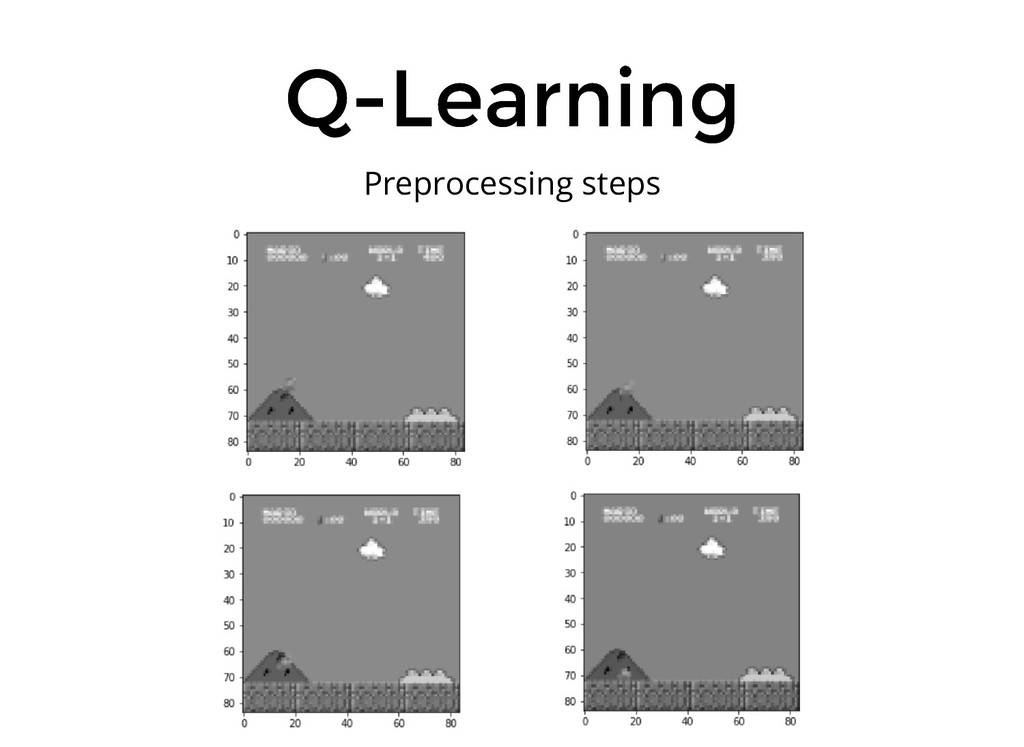
De ser así esta es una charla que no te puedes perder! Mario Bros ya no te necesitara para terminar los niveles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}