логику их взаимодействия • 2 месяца чтобы сносно читать Word файлы • 1 год чтобы хорошо читать все три типа: Word, Excel, PowerPoint • до сих пор находим что-то новое
чтения полного документа в среднем < 1 секунды • Вычитываем те данные которые нам нужны • Легко вносить изменения • Низкий процент ошибок при чтении: ~ 0.7% Но вначале все было совсем не так хорошо.
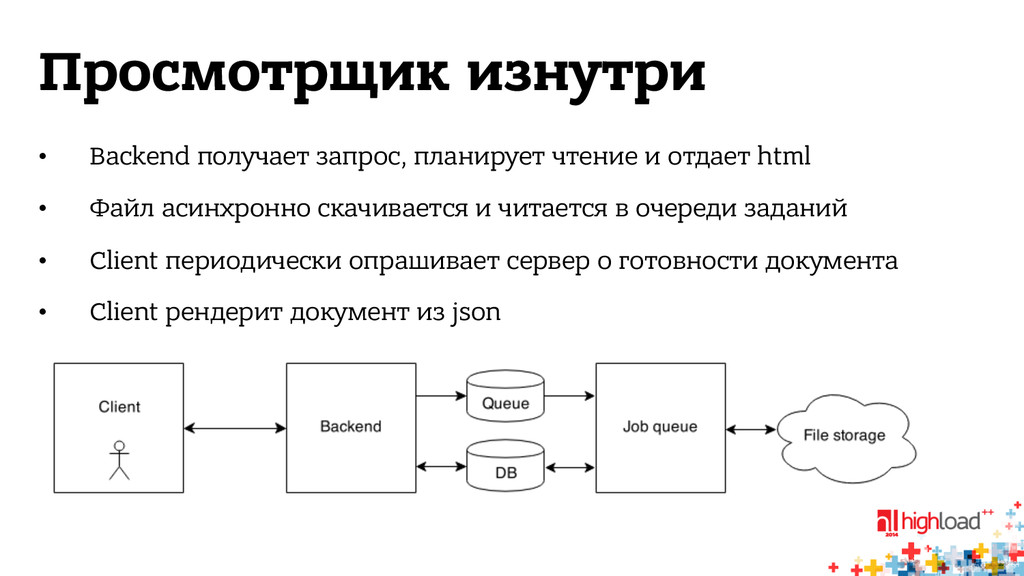
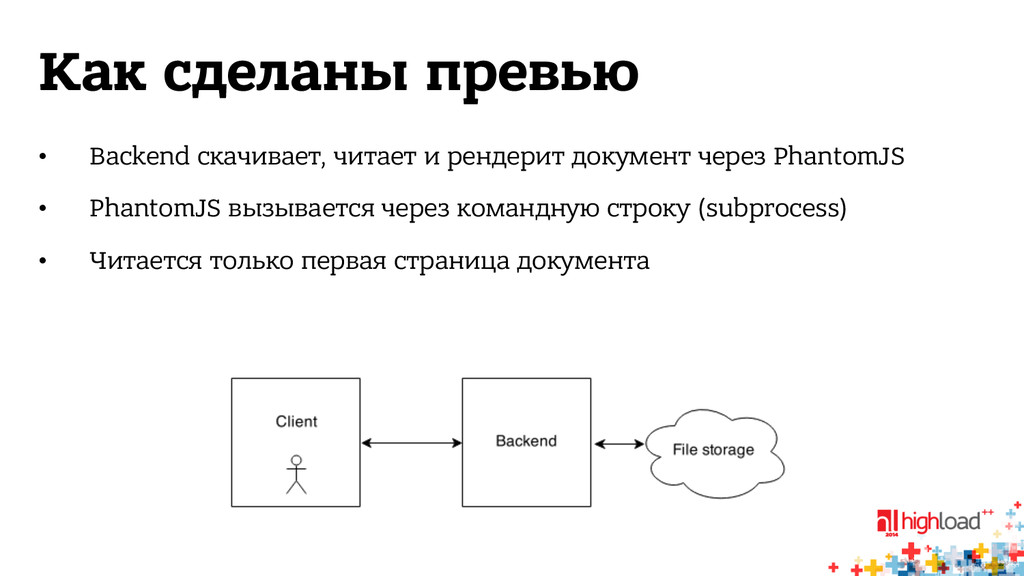
html • Файл асинхронно скачивается и читается в очереди заданий • Client периодически опрашивает сервер о готовности документа • Client рендерит документ из json
- насчет прогнозов. • Не беда – пользователи этого просто не видели • На запуске довольно много ошибок чтения документов • Надо больше разных файлов для исправления! • Читаем пока неудовлетворительно Как быть?
отрендеренный шаблон на stdin • Выключаем индентацию json-данных - 7% (!) ускорения рендеринга • Inline base64 изображения • Выдаем данные в bmp вместо jpeg - все равно масштабировать • Теперь можно профилировать
• Время построения превью в диапазоне 480-800 ms • 30 серверов, более 700 запросов в секунду • Позволяют отловить ошибки логики JS • Но не ошибки работы с конкретным браузером
Нужна нормальная печать документов • Формат, в который читаем, не удобен • Сможем сохранять только в docx • Не храним данные. Документ сохраняется в Облако.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы? Павел Зиновкин Руководитель группы разработки, Почта@Mail.Ru [email protected]](https://files.speakerdeck.com/presentations/c0f03e60634e01322c5476b3db404809/slide_28.jpg){kind=link}