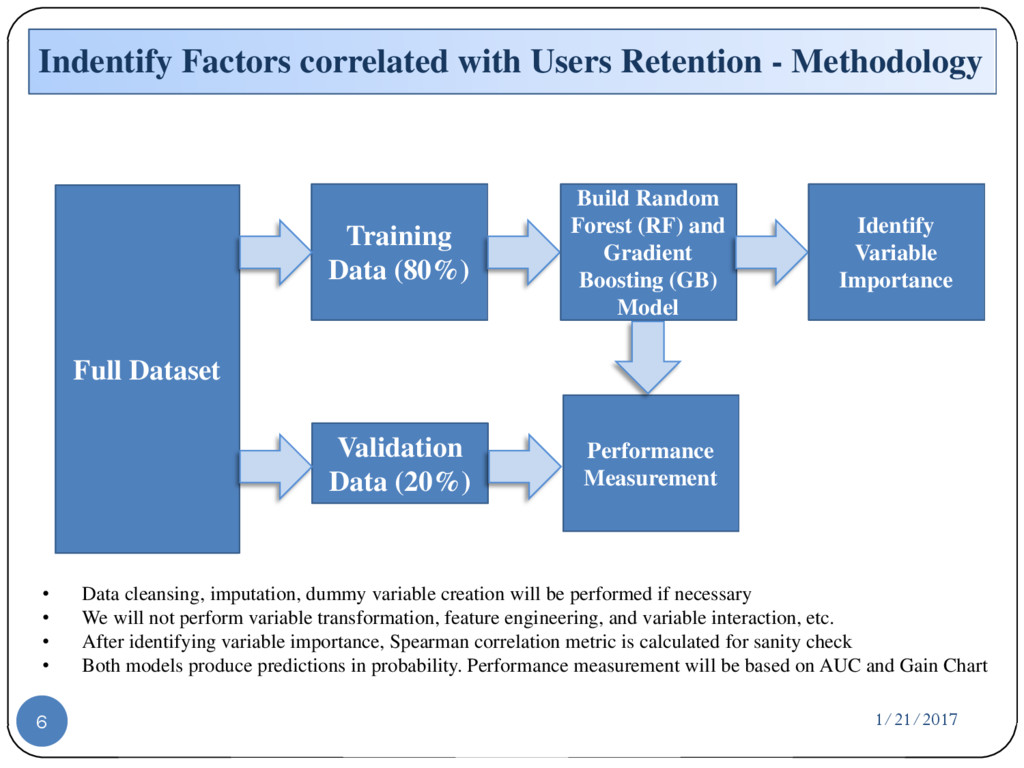
Full Dataset Training Data (80%) Validation Data (20%) Build Random Forest (RF) and Gradient Boosting (GB) Model Identify Variable Importance Performance Measurement • Data cleansing, imputation, dummy variable creation will be performed if necessary • We will not perform variable transformation, feature engineering, and variable interaction, etc. • After identifying variable importance, Spearman correlation metric is calculated for sanity check • Both models produce predictions in probability. Performance measurement will be based on AUC and Gain Chart
{kind=link}
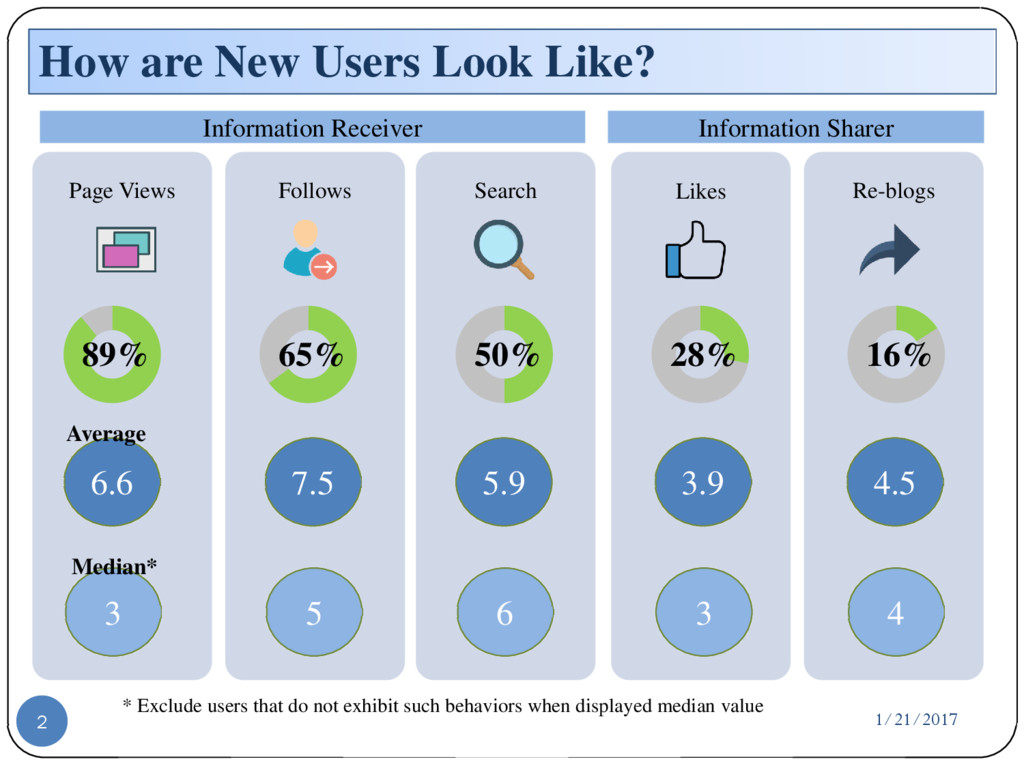{kind=link}
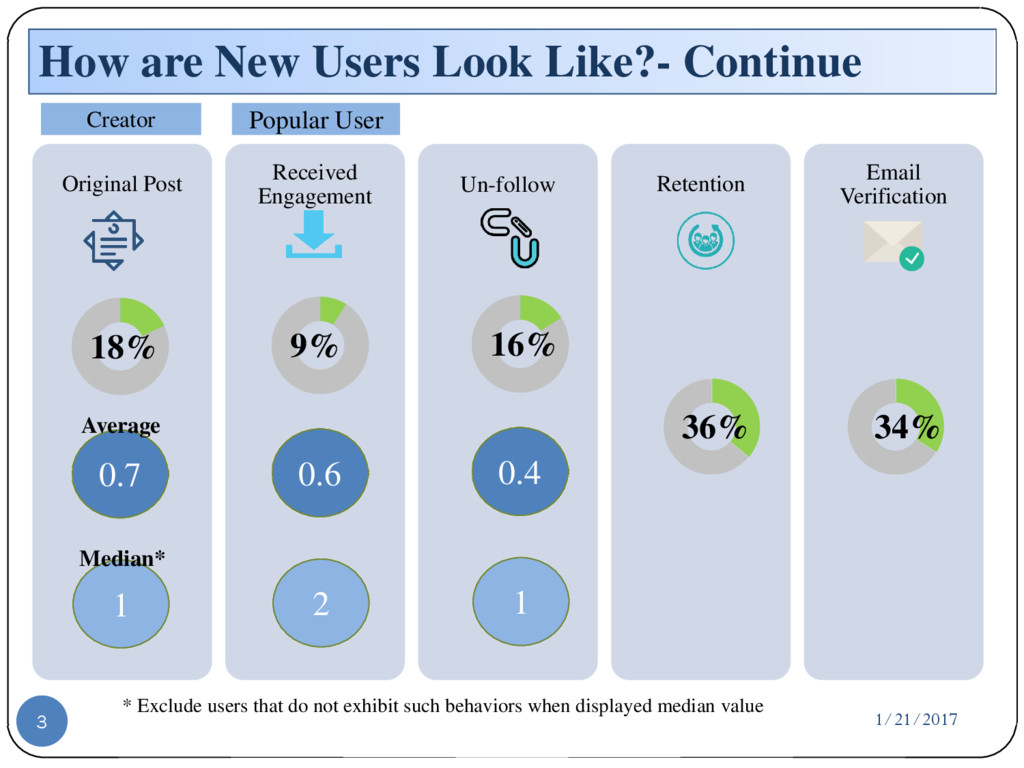{kind=link}
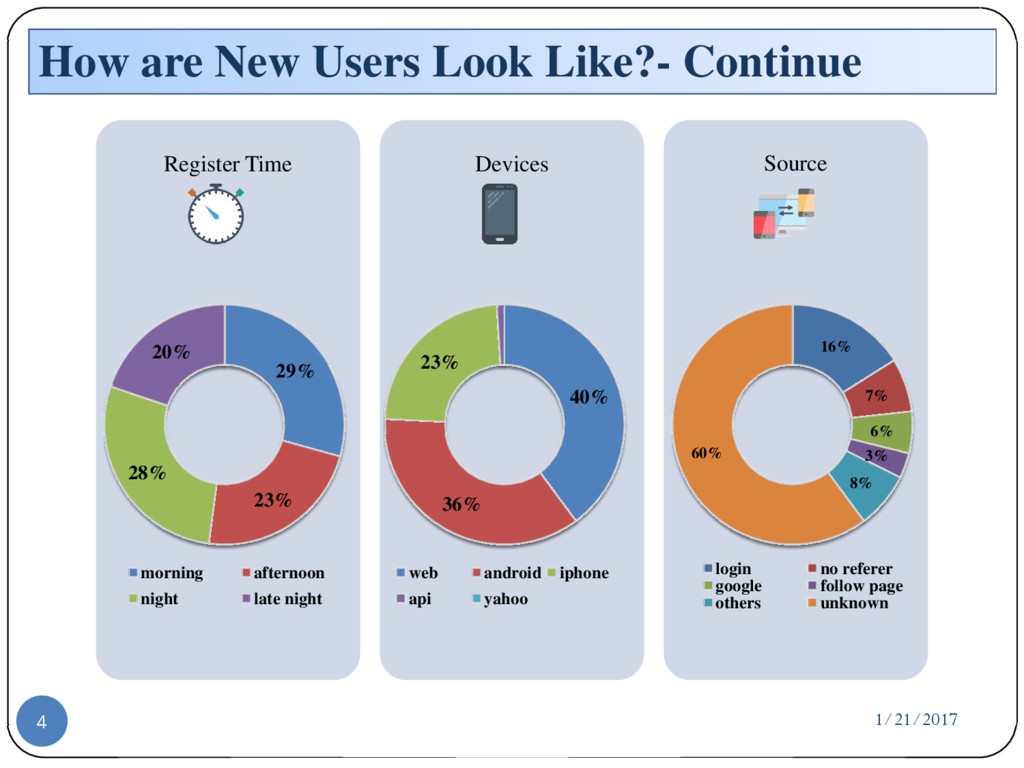{kind=link}
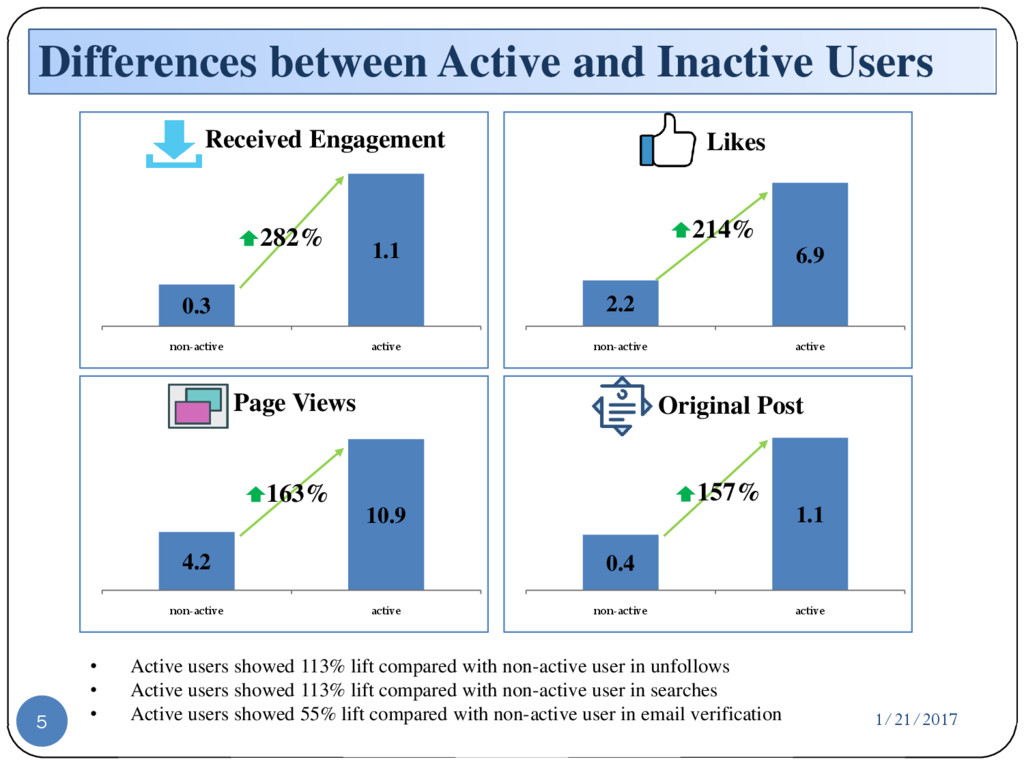{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
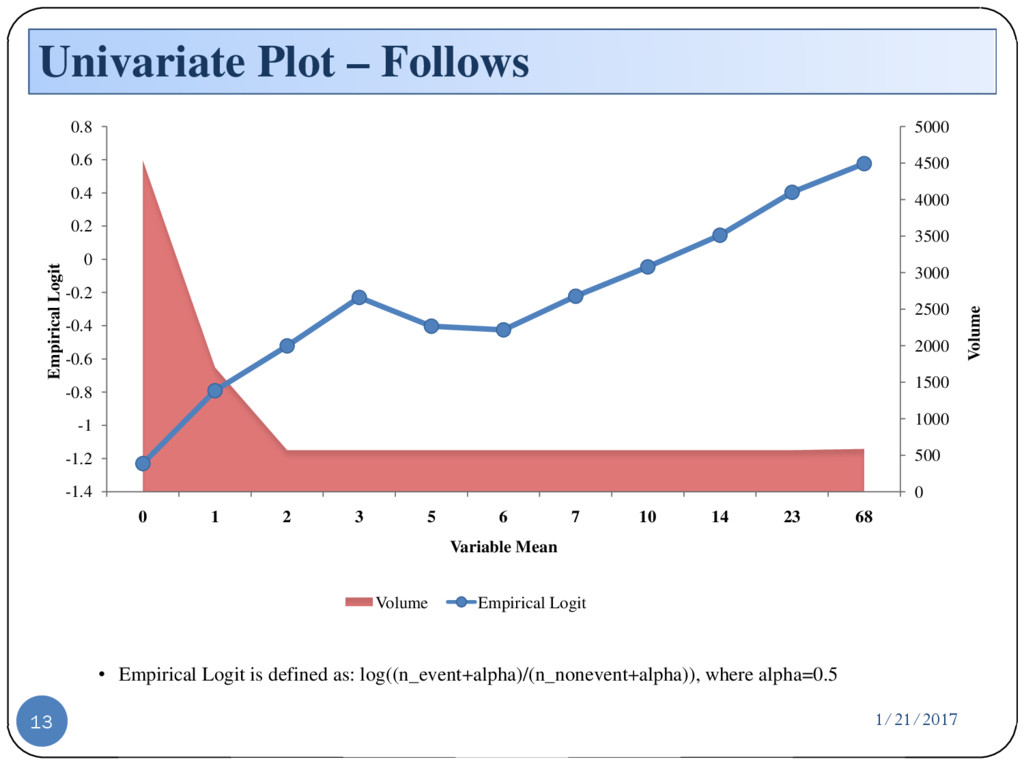{kind=link}
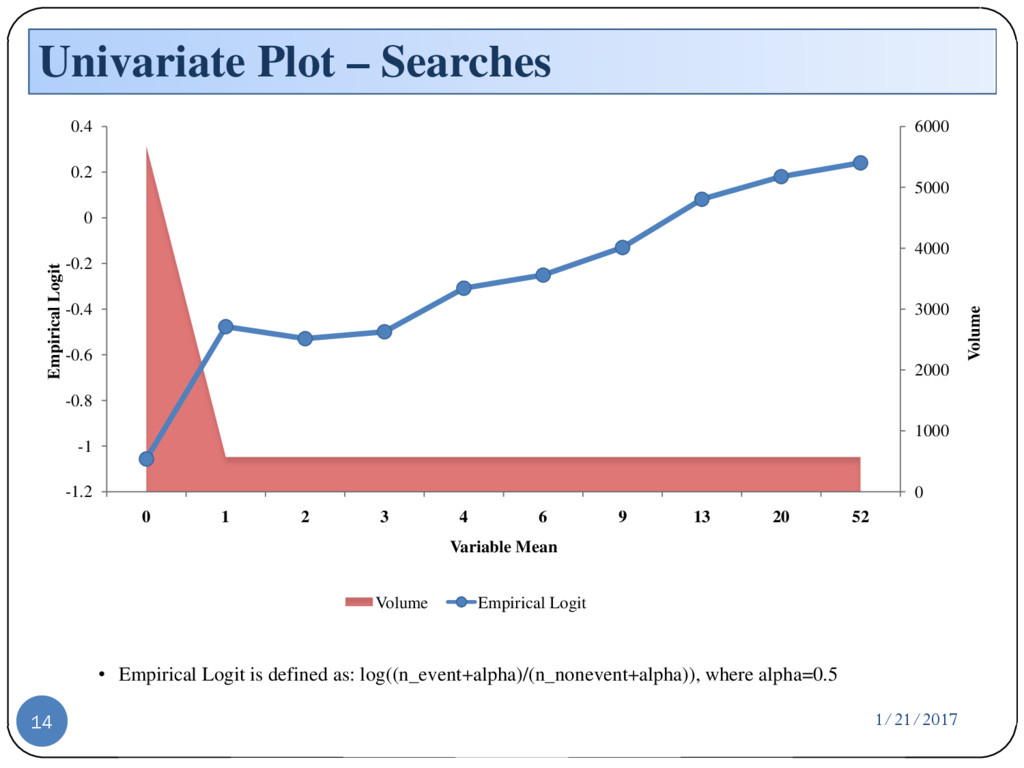{kind=link}
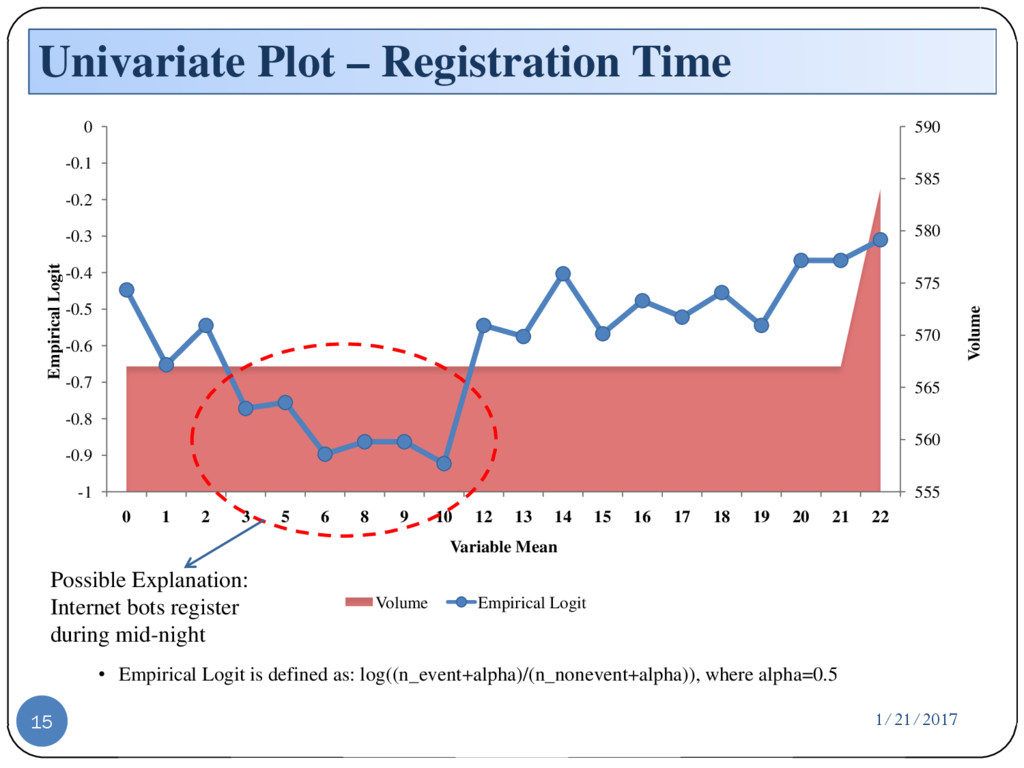{kind=link}