et al., “H3WB: Human3.6M 3D WholeBody Dataset and Benchmark”, ICCV2023 [4] Lutz et al., ”Jointformer: Single-frame lifting transformer with error prediction and refinement for 3d human pose estimation”, ICPR2022 [5] Martinez et al., “A simple yet effective baseline for 3d human pose estimation”, ICCV2017 [6] Wandt et al., “CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild”, CVPR2021 H3WB dataset
Human3.6[10] など) Ø 無⽣物ベース(PASCAL3D+[2] ) p 学習データセット外のオブジェクトで評価 [7] Bala et al., “Openmonkeystudio: Automated markerless pose estimation in freely moving macaques”, Nature2020 [8] Xu et al., ” Animal3d: A comprehensive dataset of 3d animal pose and shape”, ICCV2023 [9] Mahmood et al., “AMASS: Archive of motion capture as surface shapes”, ICCV2019 [10] lonescu et al., “Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments”, TPAMI2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
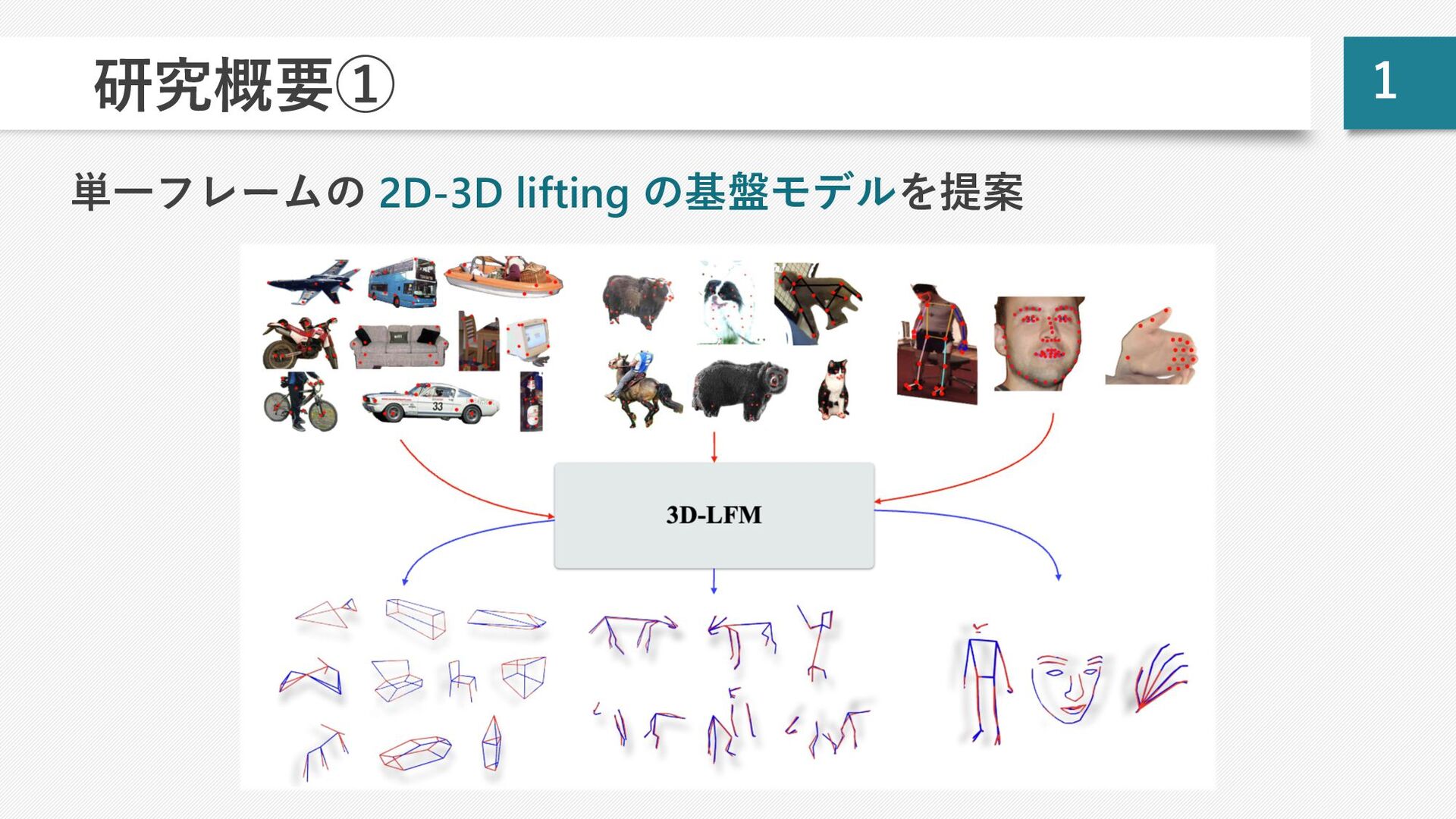
![5 先⾏研究:C3DPO[1] p複数オブジェクトの 2D-3D lifting を扱う pオブジェクトごとのカテゴリ・リグ情報が必要 [1] Novotny et](https://files.speakerdeck.com/presentations/c88f6455328243a69f42e600598196e4/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11 複数オブジェクトの 3D 再構成 pデータセット:PASCAL3D+ dataset[2] p⽐較モデル:C3DPO[1] [2] Xiang et](https://files.speakerdeck.com/presentations/c88f6455328243a69f42e600598196e4/slide_11.jpg){kind=link}
![12 特定オブジェクトにおける評価 pデータセット:H3WB dataset[3] p⽐較モデル:Jointformer[4] 、 SimpleBaseline[5] 、CanonPose[6] [3] Zhu](https://files.speakerdeck.com/presentations/c88f6455328243a69f42e600598196e4/slide_12.jpg){kind=link}
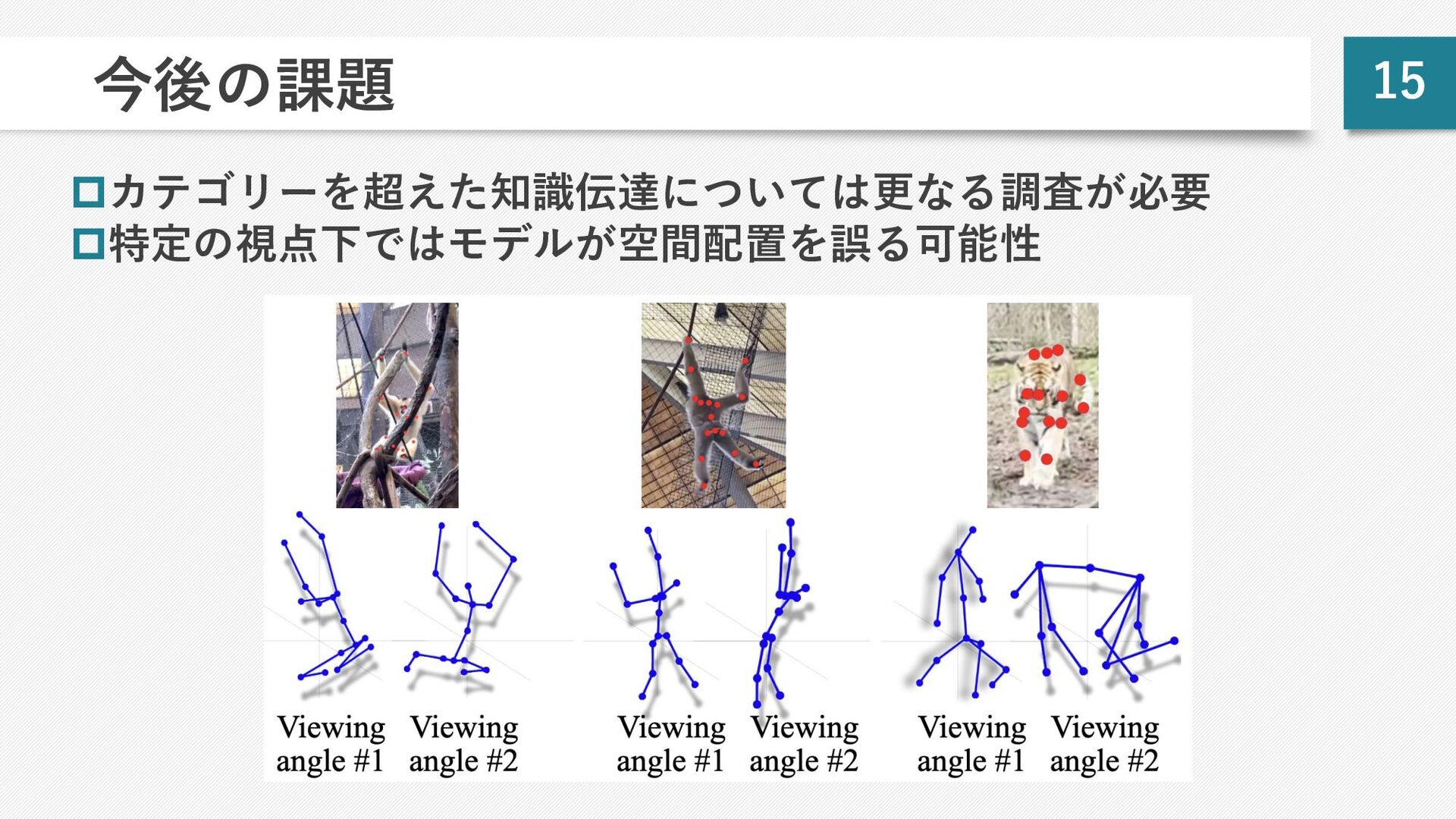
![13 OOD データに対する汎化性能 pあらゆるカテゴリの複合データで学習 Ø 動物ベース(OpenMonkey[7] 、Animals3D[8] など) Ø ⼈体ベース(AMASS[9]、](https://files.speakerdeck.com/presentations/c88f6455328243a69f42e600598196e4/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}