Quay, GCR etc.. • Self hosted. Generic Best Practice: • One layer for base, one for user configuration and one for application • Leverage ‘USER’ directive to run programs inside container as non-root. • Ensure regular scanning of images. • Use environment variables for runtime configuration.
or group • Separate namespaces for Dev/Test/Staging/Build • Specify Resource Quota (cpu, mem, #pods, #services, #RCs, #PersistentVolumeClaims) for each namespace
you are using calico networking. • Check this document[1]. • Cross verify the kops supported version for k8s cluster. [1].https://github.com/kubernetes/kops/blob/master/docs/upgrade_from_kops_1.6_to_1.7_calico_cid r_migration.md
is available. - kubectl top • Cluster monitoring using Prometheus and Grafana. • Configure Prometheus alerts to notify on slack/email etc. using alertmanager. - Prometheus nodeexporter and prometheus-core manifest must specify resources or might lead to consume more and more resources Other tools:- • Datadog/sysdig/weave-scope etc.
own tool, create database, secrets etc. • Creates deployment templates. • Helm is good tool from k8s community. • kubectl or k8s API • Label nodes script. Kops has artifact to specify in cluster.yml
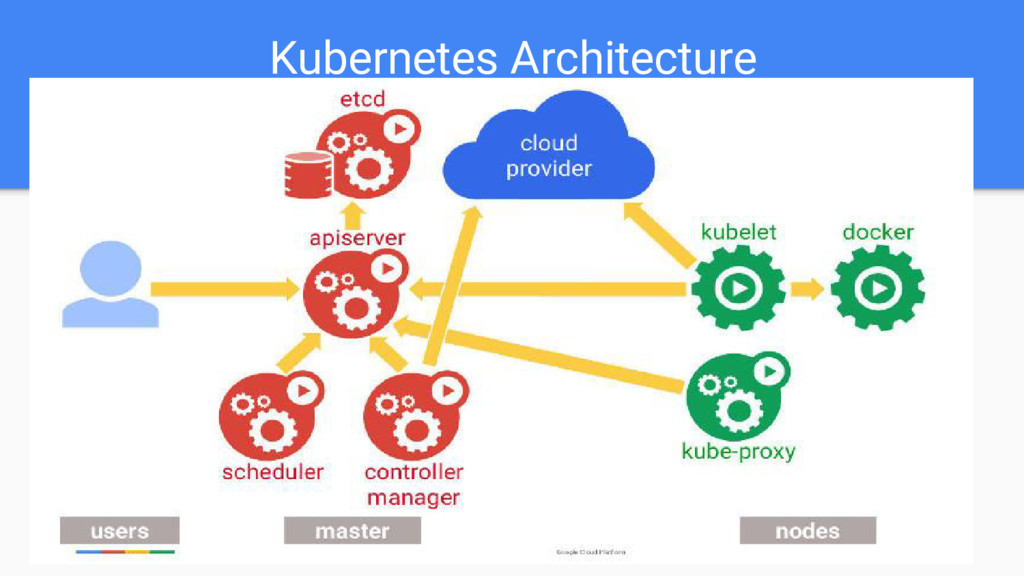
maintained in ETCD which is a distributed - key-value store • Deployment considerations for ETCD - Fault-tolerant cluster - Storage for ETCD (Network and IO latency directly affects ETCD) - ETCD data backup and restore - Reshifter(https://github.com/mhausenblas/reshifter) - Ark • Enable TLS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Logging • EFK [Elasticsearch-Fluentd-Kibana] addon from Kubernetes repository. • Use](https://files.speakerdeck.com/presentations/d1d1b5fcf1b145a9a562a618f98fe0dc/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
![Don’t Forget • Kubeval [1]. • Kubernetes-dashboard. • Heapster •](https://files.speakerdeck.com/presentations/d1d1b5fcf1b145a9a562a618f98fe0dc/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
![Thanks! Contact us: Big Binary 203, Jewel Towers [email protected] https://www.bigbinary.com](https://files.speakerdeck.com/presentations/d1d1b5fcf1b145a9a562a618f98fe0dc/slide_35.jpg){kind=link}