PixieDust is a new Python open source library that helps data scientists and
developers working in Jupyter Notebooks and Apache Spark to be more efficient.
PixieDust speeds up data manipulation and display with features like:
Automated local install of Python and Scala kernels running with Spark Realtime
Spark Job progress monitoring directly from the Notebook
Use Scala directly in your Python notebook.
Variables are automatically transferred from Python to Scala and vice-versa
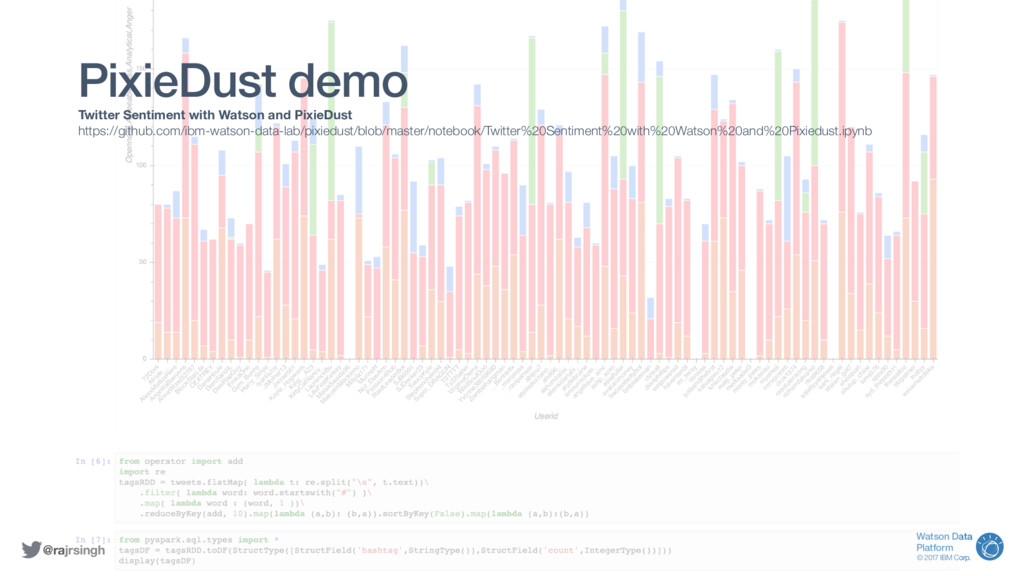
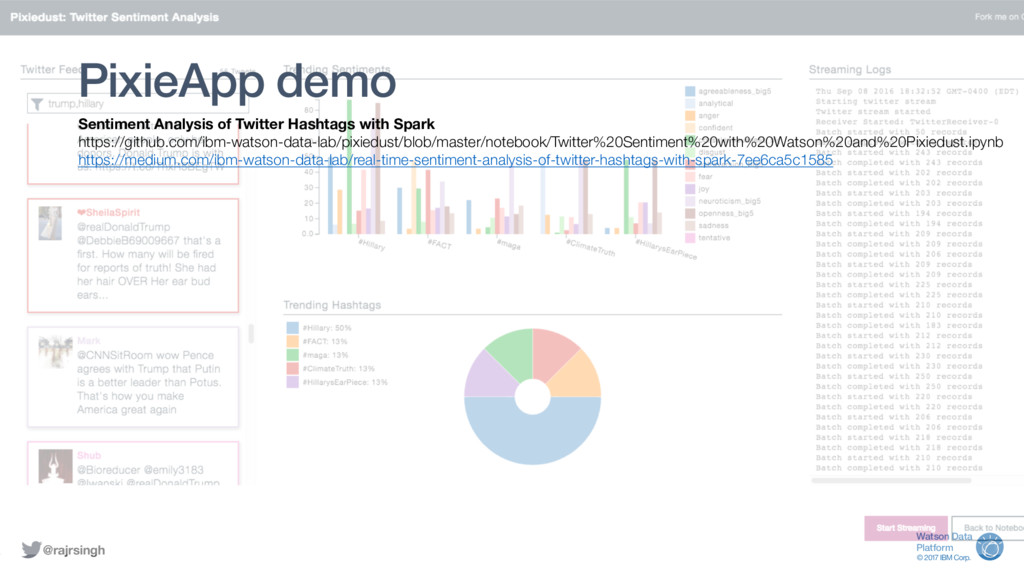
Auto-visualisation of Spark DataFrames using popular chart engines like Matplotlib, Seaborn, Bokeh, or MapBox.
Seamless integration to cloud services
Create embedded apps with your own visualisations or apps using the
PixieDust extensibility APIs. Come along and learn how you can use this tool in your own projects
to visualise and explore data effortlessly with no coding.
If you prefer working with a Scala Notebook, this session is also for you,
as PixieDust can also run on a Scala Kernel.
Imagine being able to visualise your favourite Python chart engines
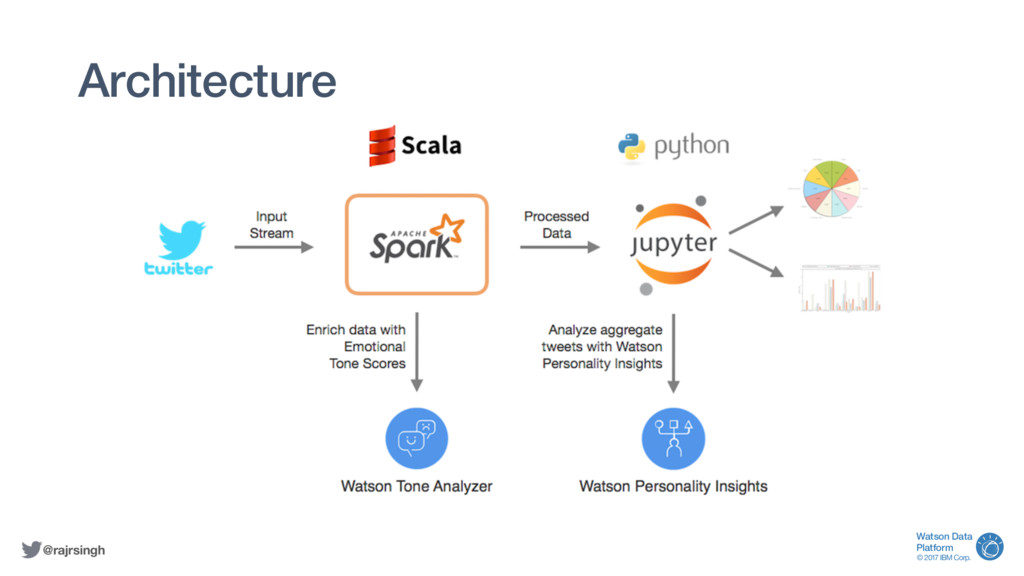
from a Scala Notebook! This session will end with a demo combining Twitter,
Watson Tone Analyser, Spark Streaming, and some fun real-time visualisations -
all running within a Notebook.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}