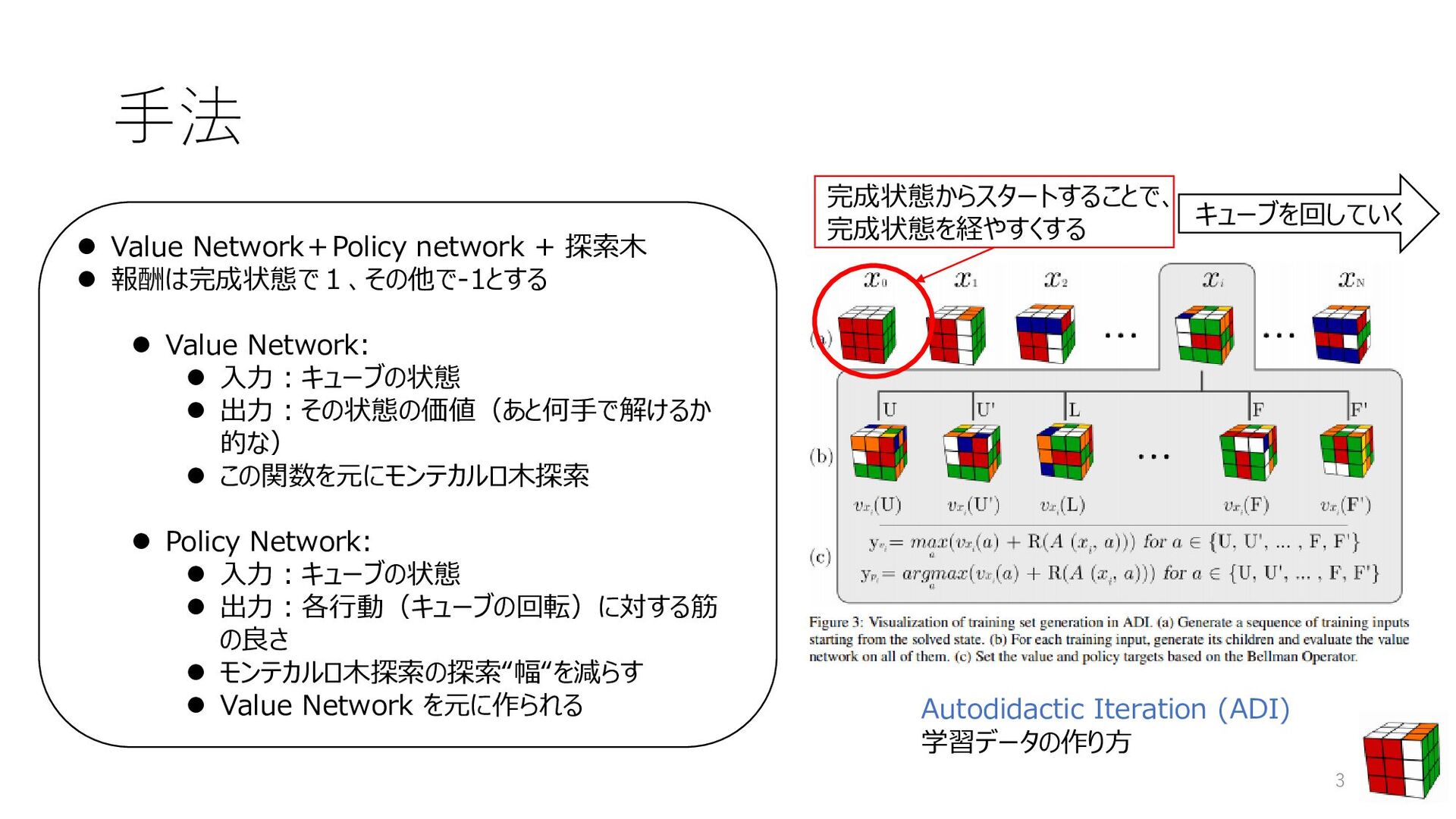
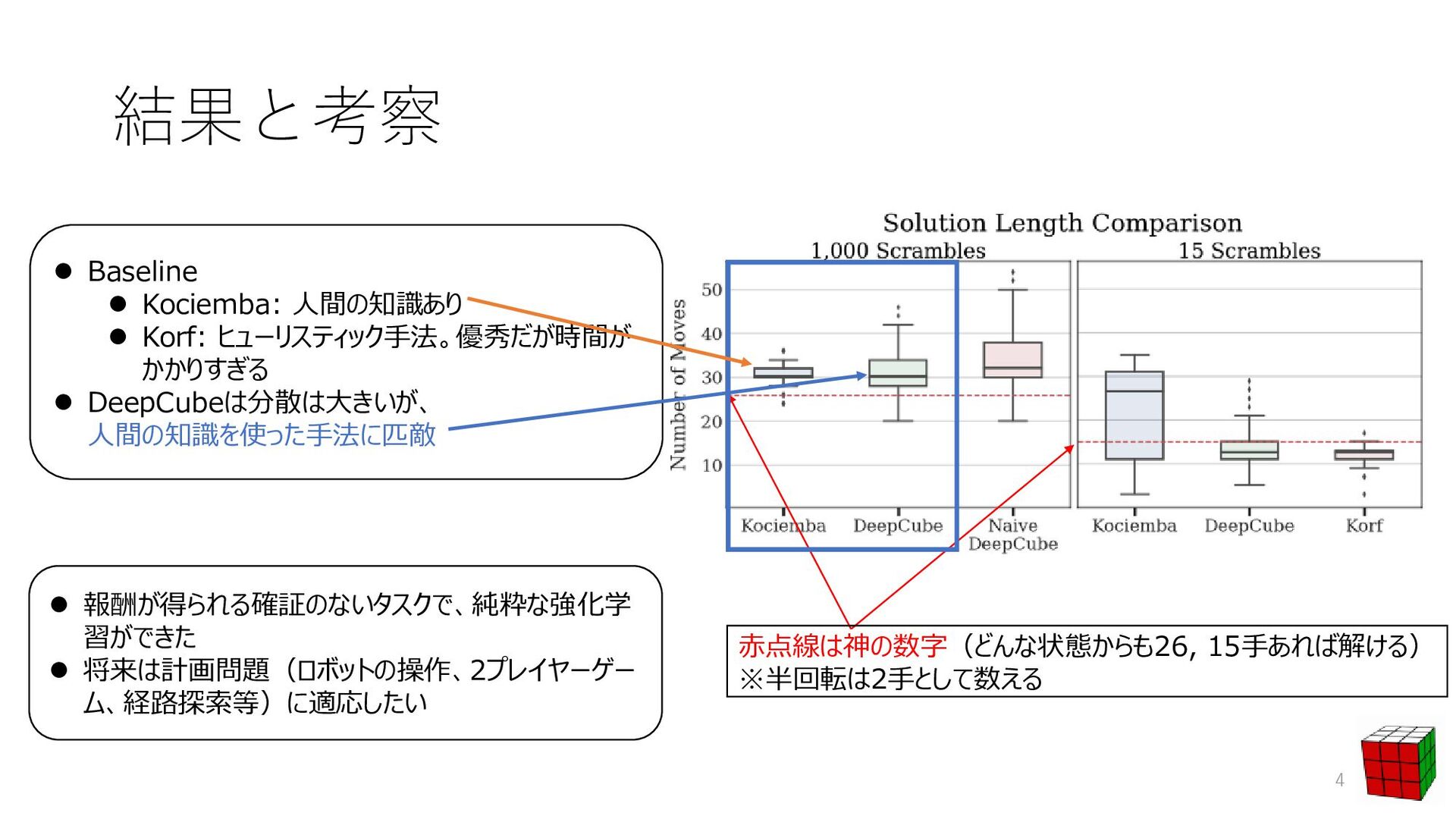
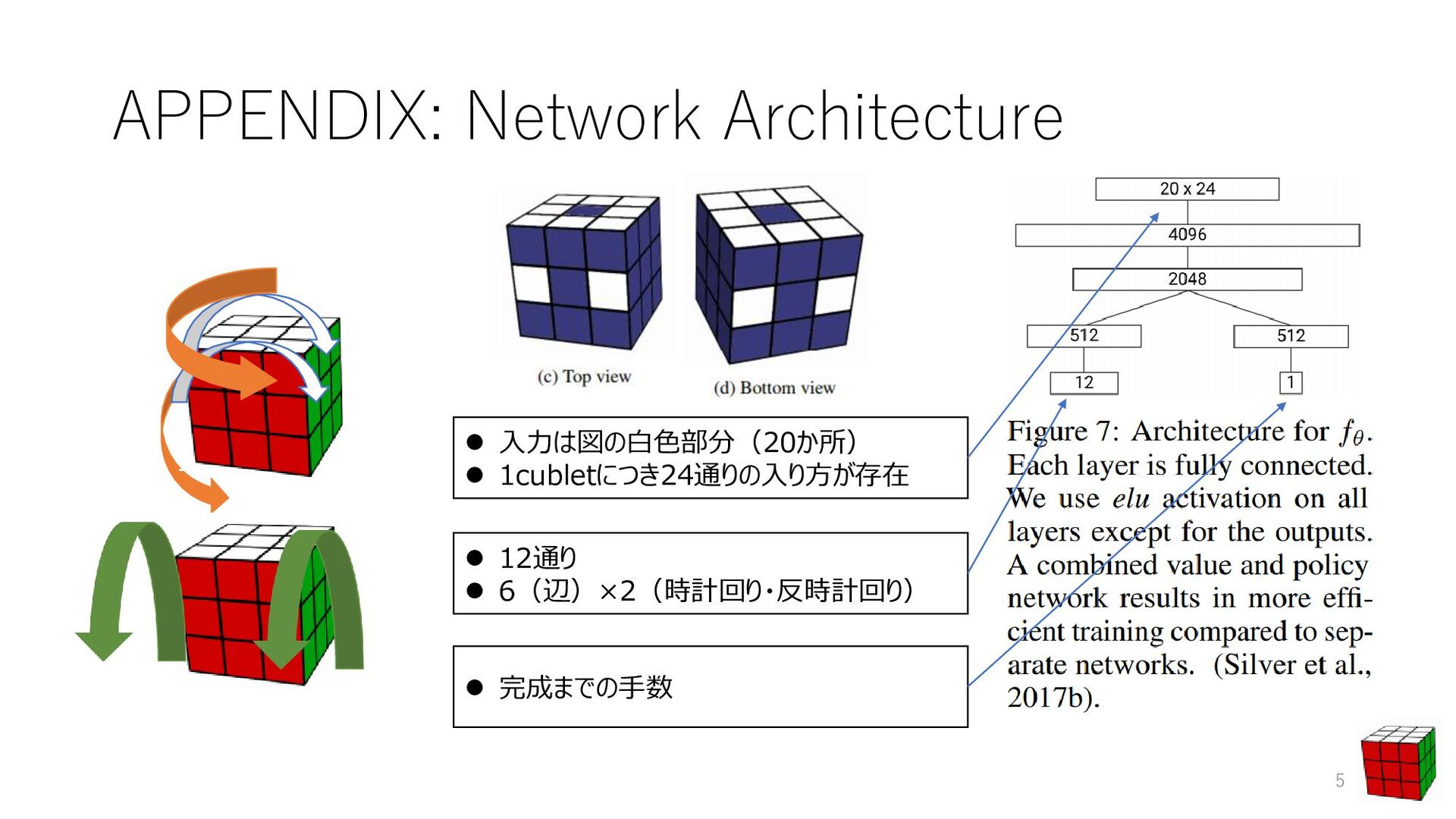
⚫ Alpha Go Zeroとの違い ⚫ 報酬を得るタイミングの少なさ ⚫ Autodidactic Iterationによる学習データの準備 ⚫ 基本的にはキューブの状態を記述した木を探索 ⚫ 木を効率よく探索するのにDeep Learningを用いる 2 [1]SILVER, David, et al. Mastering the game of go without human knowledge. Nature, 2017, 550.7676: 354. ルービックキューブのルール 揃える 完成 バラバラ ・・・・・・・・ ・・・ ・・・・・・・・ モンテカルロ木探索 ⚫ 3× 3× 3の立方体 ⚫ 外側の辺を回せる 各状態の価値がわかる、「価値関数」 がわかればOK
{kind=link}
![概要 ⚫ 強化学習でルービックキューブを解く手法(Deep Cube)論文 ⚫ 人間の知識は一切使用しないで解く (Alpha Go Zero[1] と似た手法)](https://files.speakerdeck.com/presentations/1f41d1c7909f42338765c23fd294e85b/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}