and 2x Google Cloud Certified • Personal field of interest is in penetration testing and accessibility practices • On the side: Running meetups, hackathons, doing tech talks and VR tech enthusiast Renaldi Gondosubroto Founder and Developer Advocate @ GReS Studio @Renaldig @renaldigondosubroto
behavior? How do you want to choose to measure success and what metrics would you like to use? How does the normal behavior align with business objectives?
this affect your service? How can you control the chaos better next time? What metrics need to be reevaluated? What are you already doing now to fix it?
{kind=link}
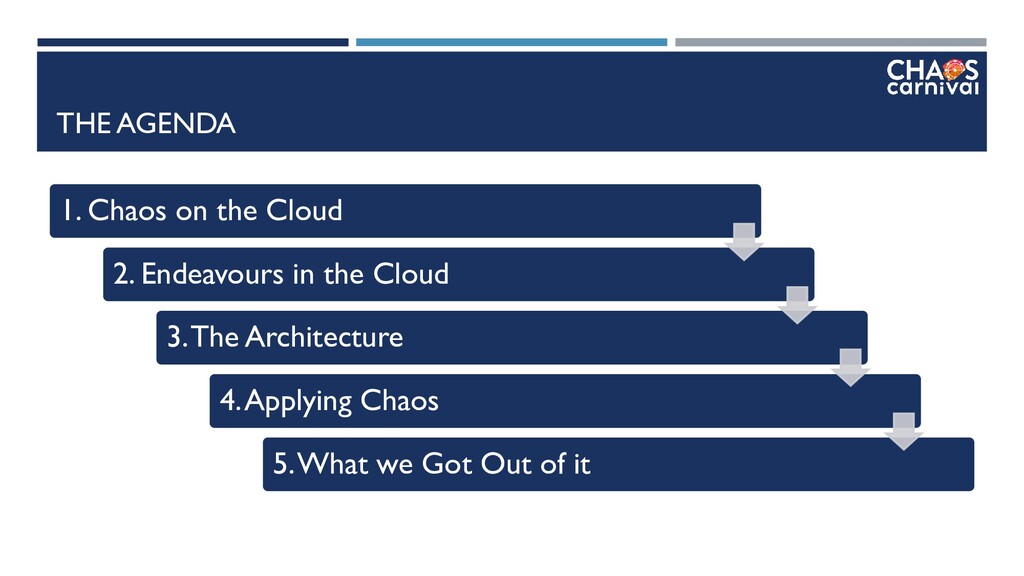{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}