processing of large amounts of data on multiple processors. • Processing is taken to where the data is stored - rather than the other way around Introduction to Hadoop
None for line in lines: line = line.strip() word, count = line.split('\t', 1) count = int(count) # the keys are sorted - checking for key change. if current_word == word: current_count += count reducer.py WORD COUNT else: if current_word: # write result to STDOUT print '%s\t%s' % (current_word, current_count) current_count = count current_word = word #output the last word if current_word == word: print '%s\t%s' % (current_word, current_count) def main(): reduce_lines(sys.stdin)
files into the HDFS • Snakebite - Python HDFS Client 2. Run the multi-step job (use a runner script) • Use a runner script 3. Retrieve and parse output files from the HDFS 4. Assert!
Job001 workflow When I add test1_input file into HDFS And I run the task Job001 on that file Then the task must complete with status Success And job output must match test1_output file Scenario: navigate to DFS-Home and check the status of any directory When I go to "http://your-namenode:50070/dfshealth.jsp" Then the request should succeed And the directories should be "Active"
times for different data sets. • File type agnostic • store, process all types of Files - Don't need to specify out schema on load • Transparent Parallelism HDFS and Map Reduce STRENGTHS
into a single MR job find the MR model of chaining very restrictive. • Lack of flexibility inhibits optimisations • Full dump to disk between jobs - too much of disk IO • Only one mapper and reducer per MR job Map Reduce - one size fits all? MAYBE NOT… M1 R1 HDFS HDFS M2 R2 HDFS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15/06/18 00:47:20 INFO streaming.PipeMapRed: PipeMapRed exec [/Users/rahul/workspace/hadoop/./reducer.py] 15/06/18 00:47:20 INFO](https://files.speakerdeck.com/presentations/29c1b75562b943eabd279e6e6d3cad0e/slide_23.jpg){kind=link}
{kind=link}
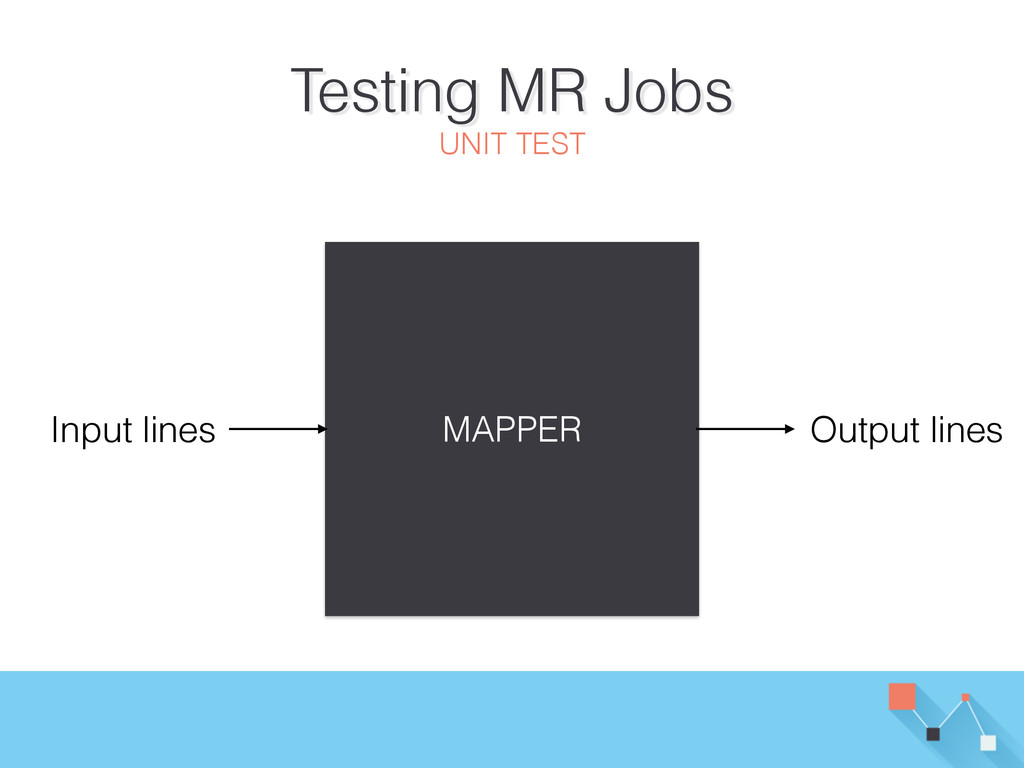{kind=link}
![class TestMapper(object): def test_one_line(self, capsys): expected_output = self._format_output([ [“Hello", “1"],](https://files.speakerdeck.com/presentations/29c1b75562b943eabd279e6e6d3cad0e/slide_26.jpg){kind=link}
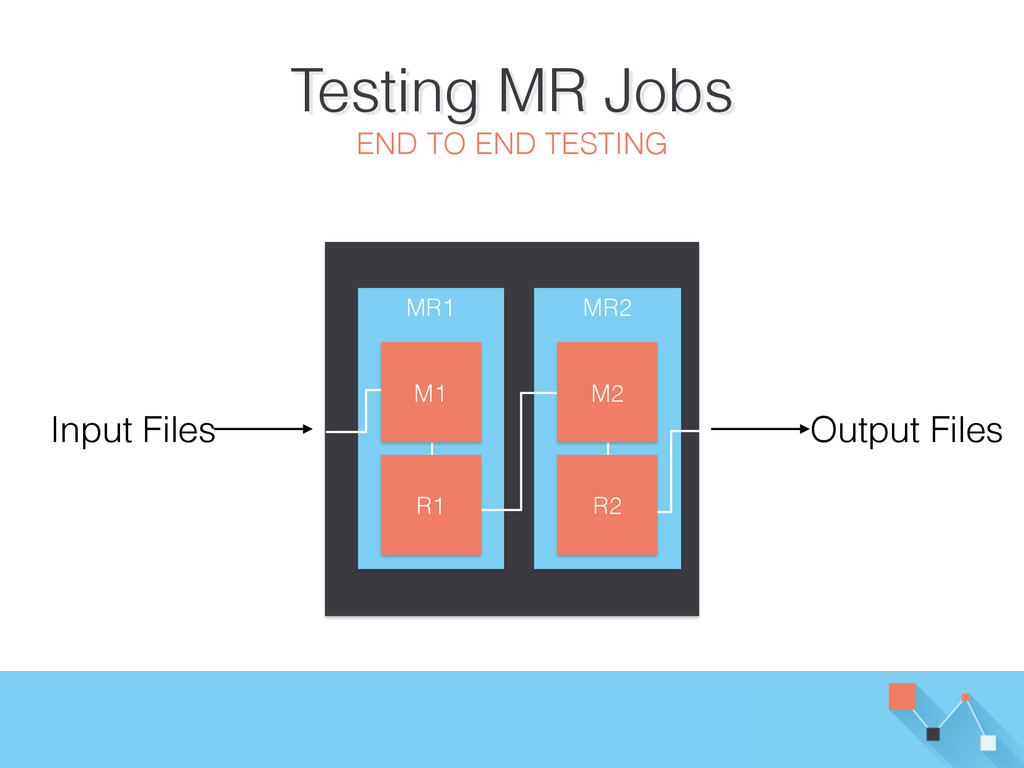{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
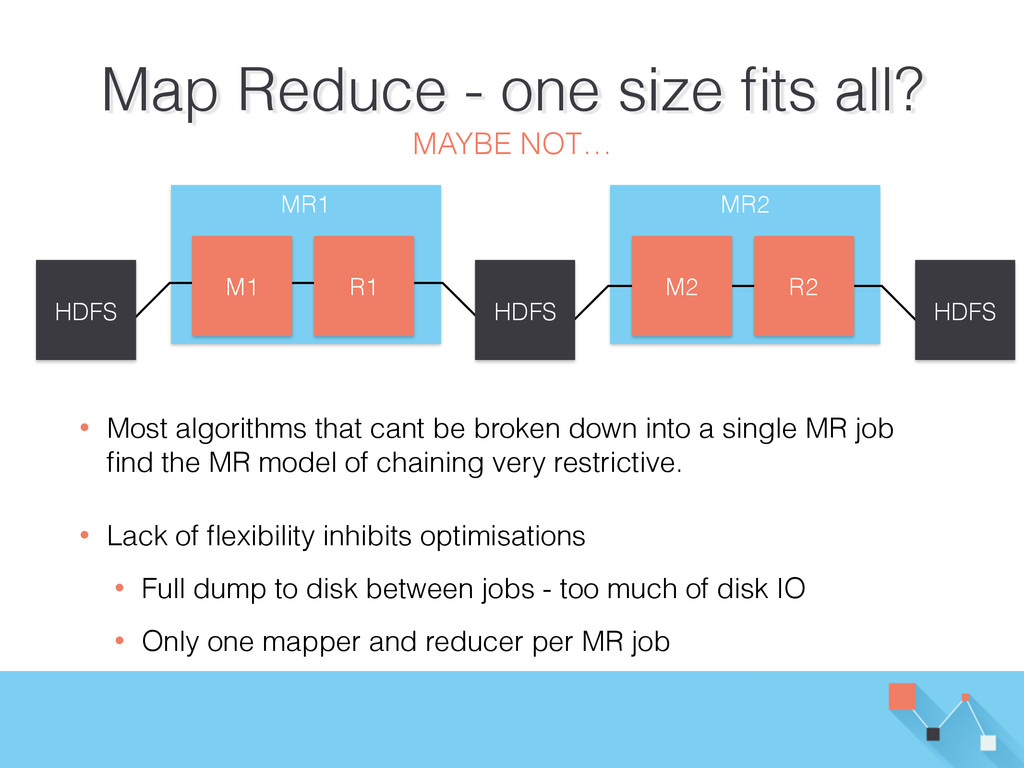{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}