practically unlimited Bandwidth 4. It is homogenous 5. Nobody can break into our LAN 6. Topology changes are unnoticeable 7. All managed by single genius admin 8. So data transport cost is zero now 2 OK.ru has come to:
practically unlimited Bandwidth 4. It is homogenous (same HW and hop cnt to every server) 5. Nobody can break into our LAN 6. Topology changes are unnoticeable 7. All managed by single genius admin 8. So data transport cost is zero now 3 Fallacies of distributed computing https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing [Peter Deutsch, 1994; James Gosling 1997]
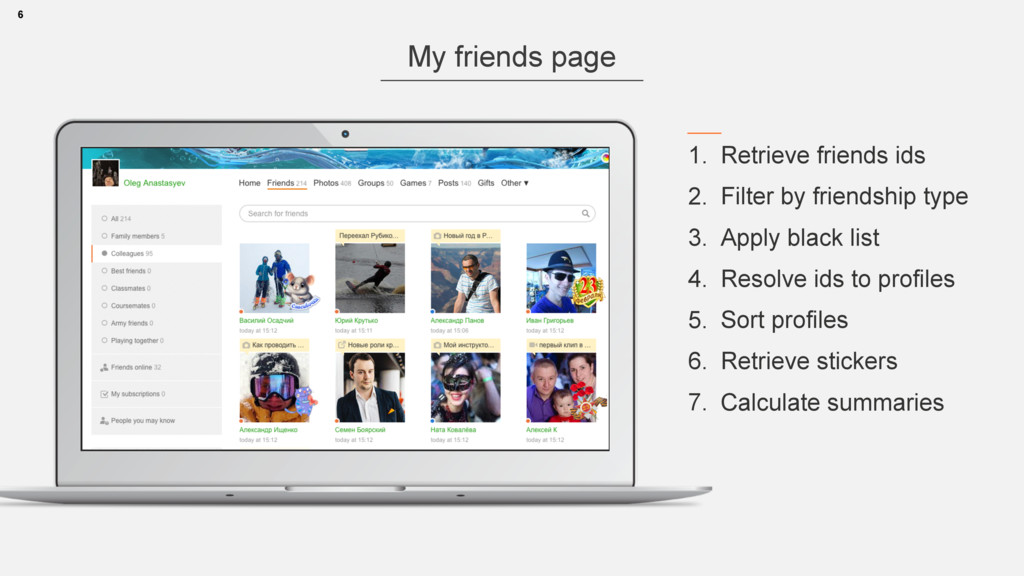
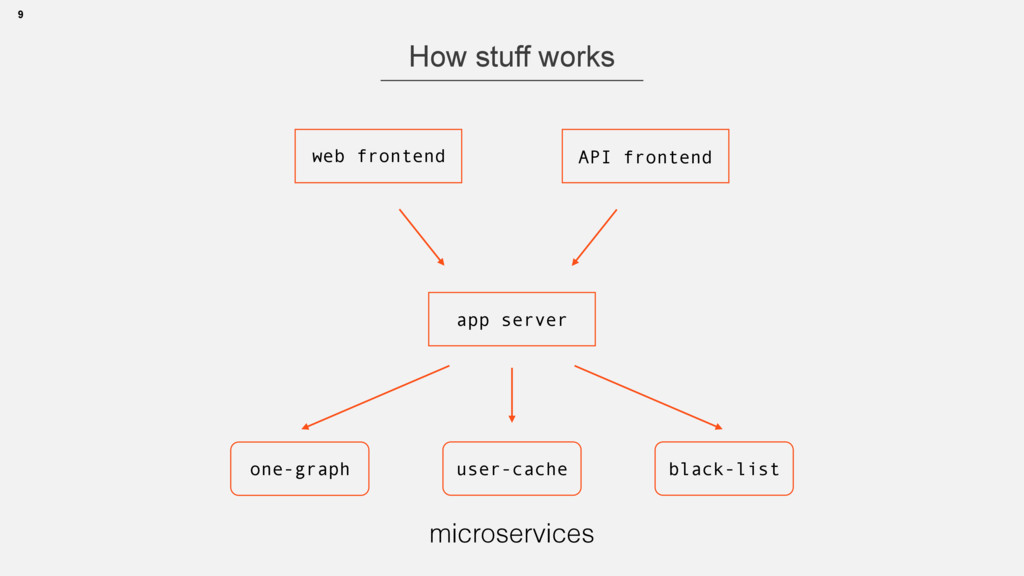
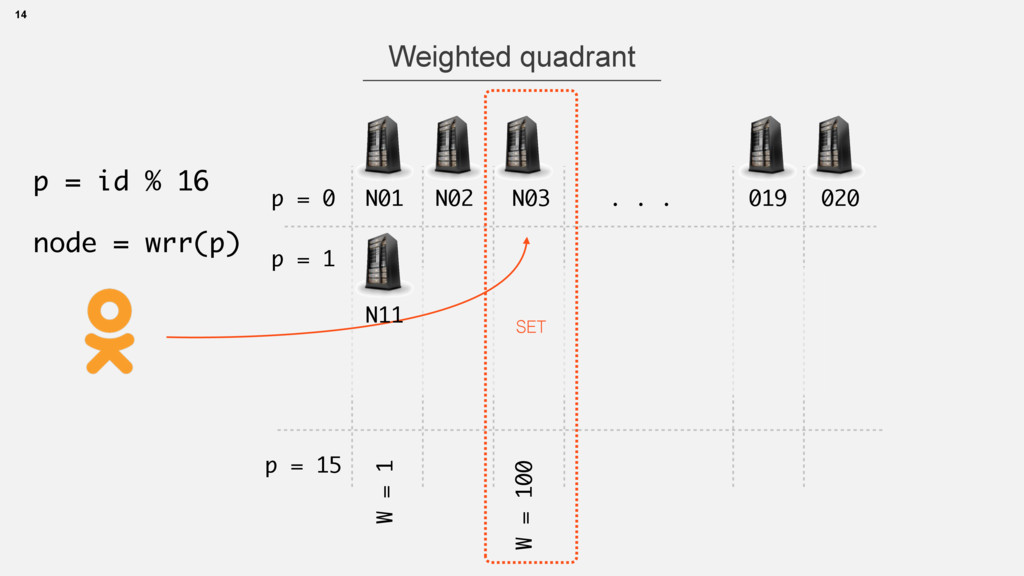
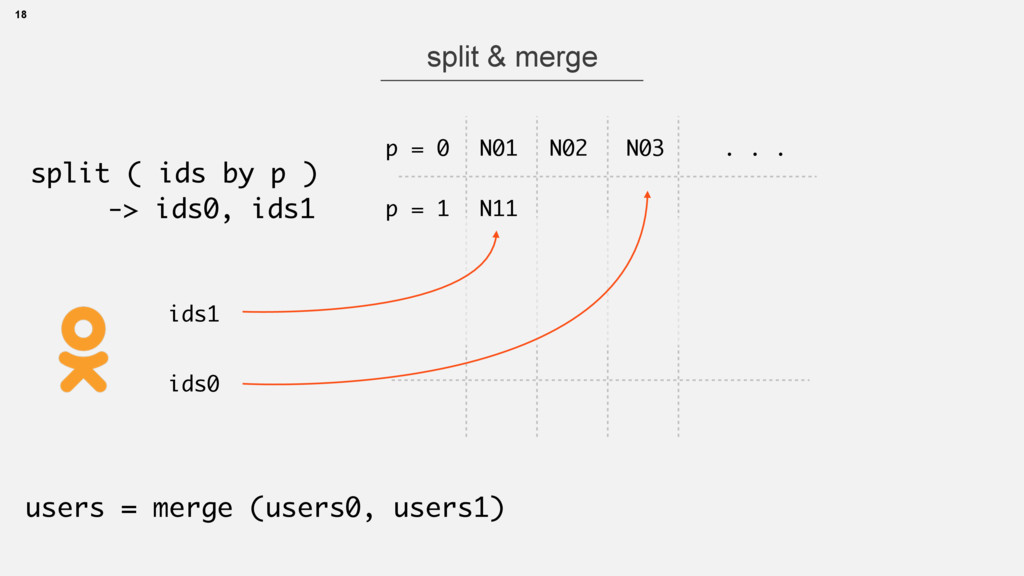
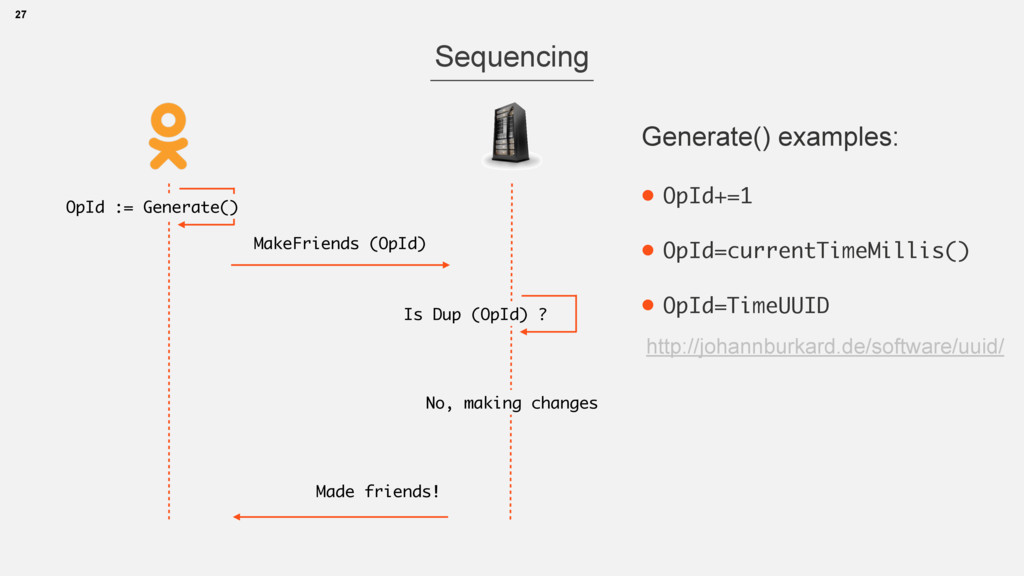
• long id -> int partitionId(id) -> node1,node2,… • Strategies can be different • Cassandra ring, Voldemort partitions • or … 13 interface GraphService extends RemoteService { @RemoteMethod long[] getFriendsByFilter(@Partition long vertexId, long relationMask); }
friends = 400 ms A roundtrip price 0.1-0.3 ms 0.7-1.0 ms remote datacenter * this price is tightly coupled with the specific infrastructure and frameworks 10k friends latency = 20 seconds
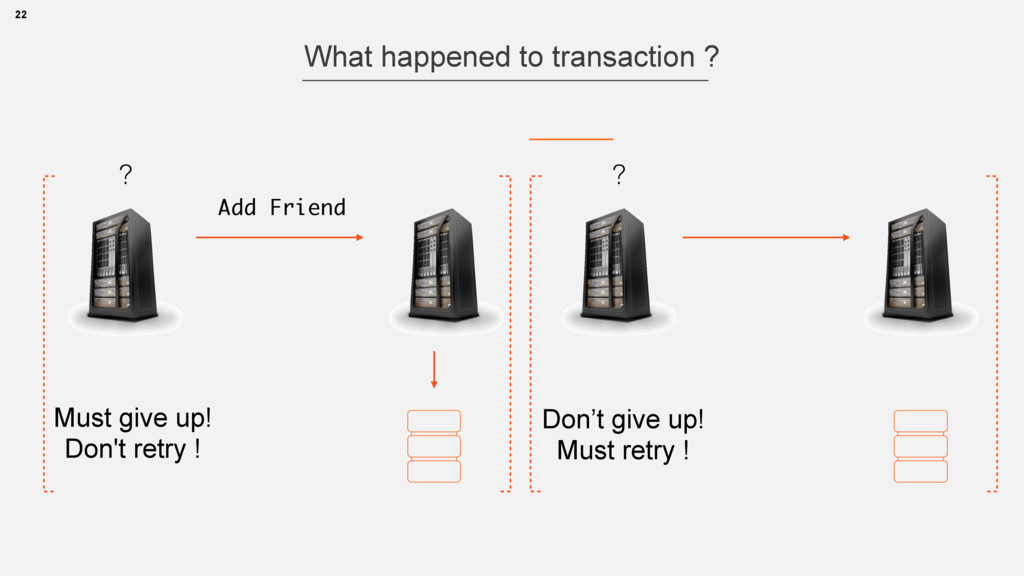
• If a Failure can occur it will occur • Redundancy is a must to mask failures • Information ( error correction codes ) • Hardware (replicas, substitute hardware) • Time (transactions, retries) 21 What to do with failures ?
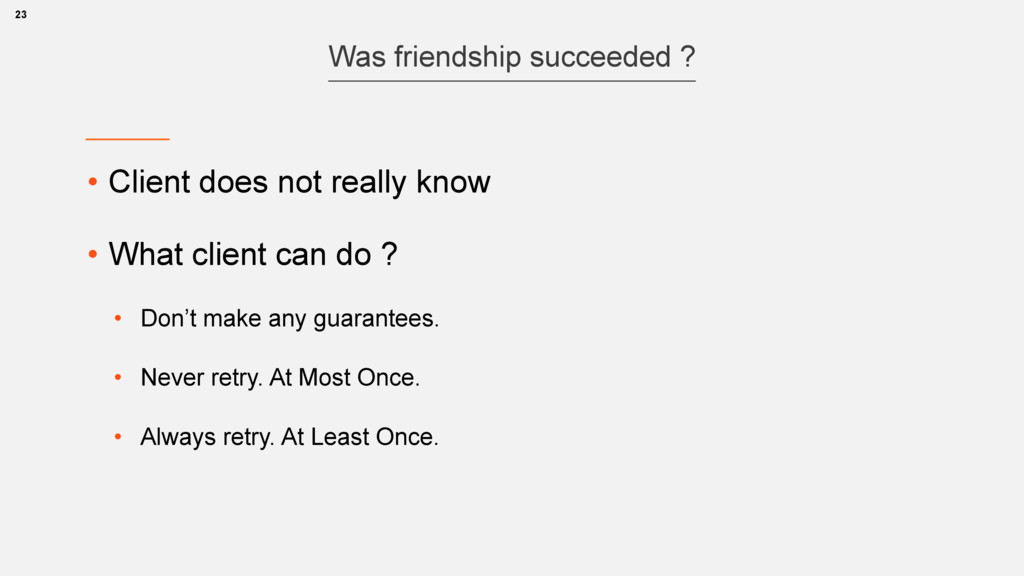
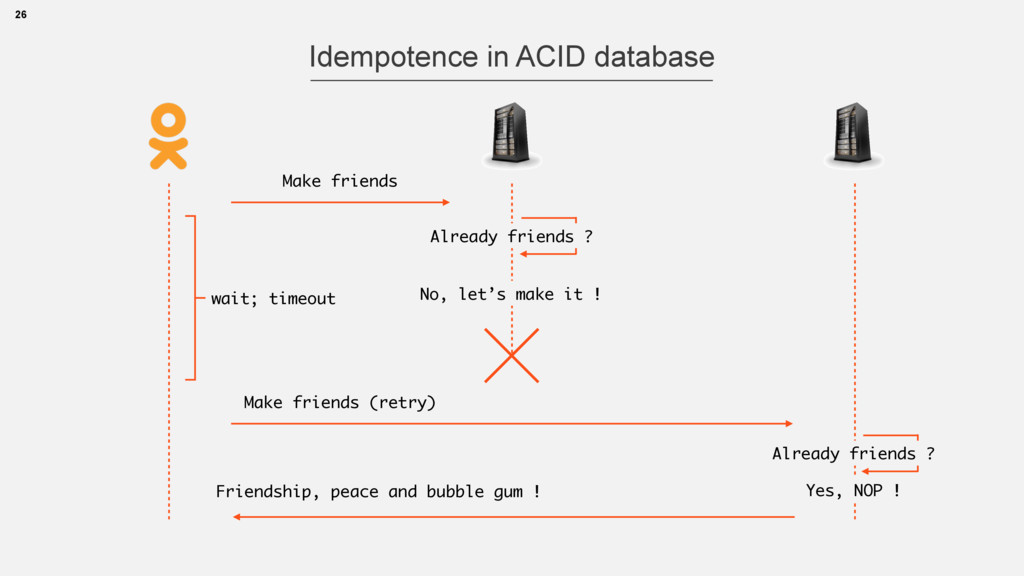
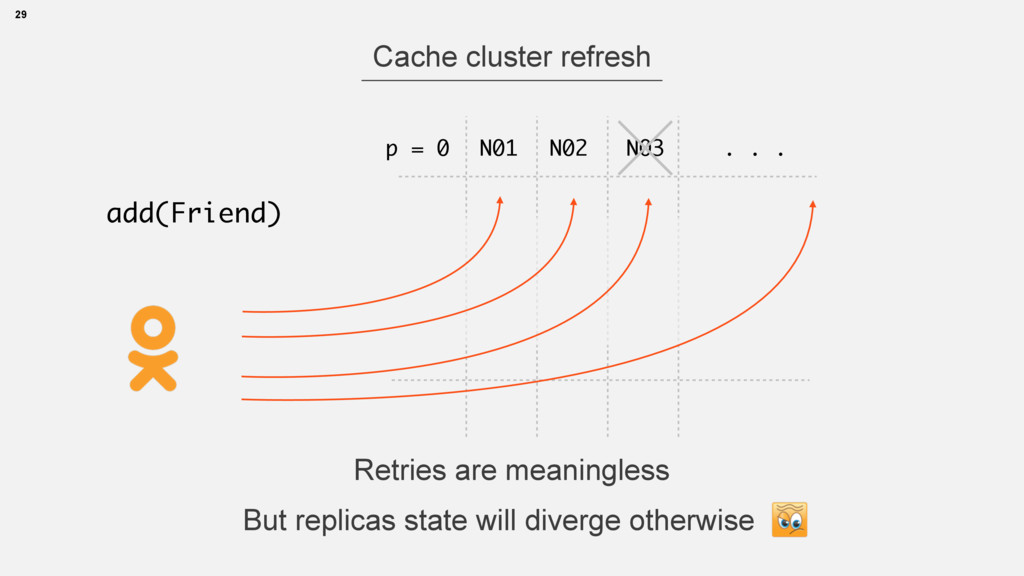
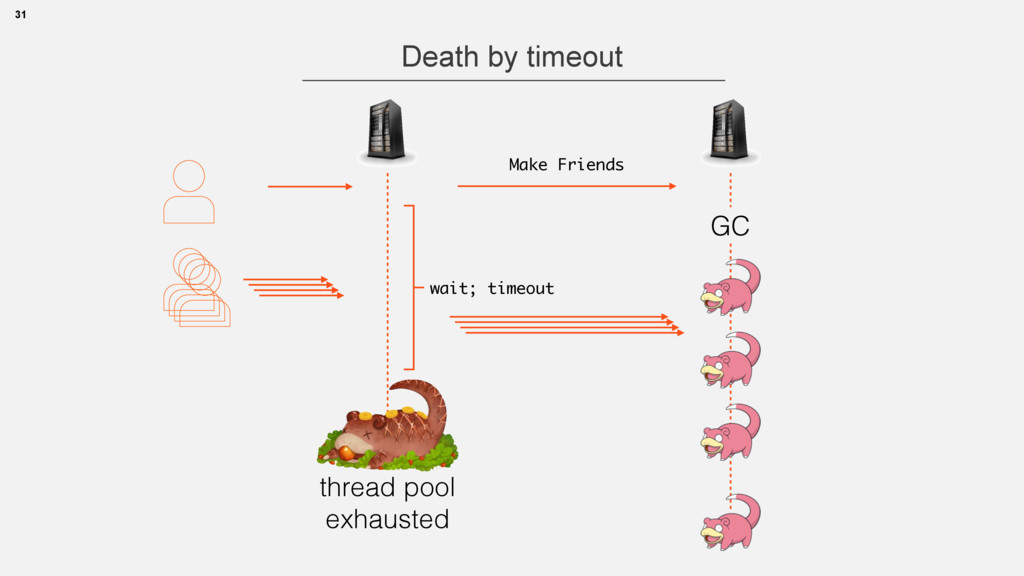
atomic (either yes or no) • atomic rollback is possible 2. Cache cluster refresh • many replicas, no master • no rollback, partial failures are possible 24 Making new friendship
• e.g.: read, Set.add(), Math.max(x,y) • Atomic change with order and dup control 25 Idempotence “Always retry” policy can be applied only on Idempotent Operations https://en.wikipedia.org/wiki/Idempotence
atomic (either yes or no) • atomic rollback is possible 2. Cache cluster refresh • many replicas, no master • no rollback, partial failures are possible 28 Making new friendship
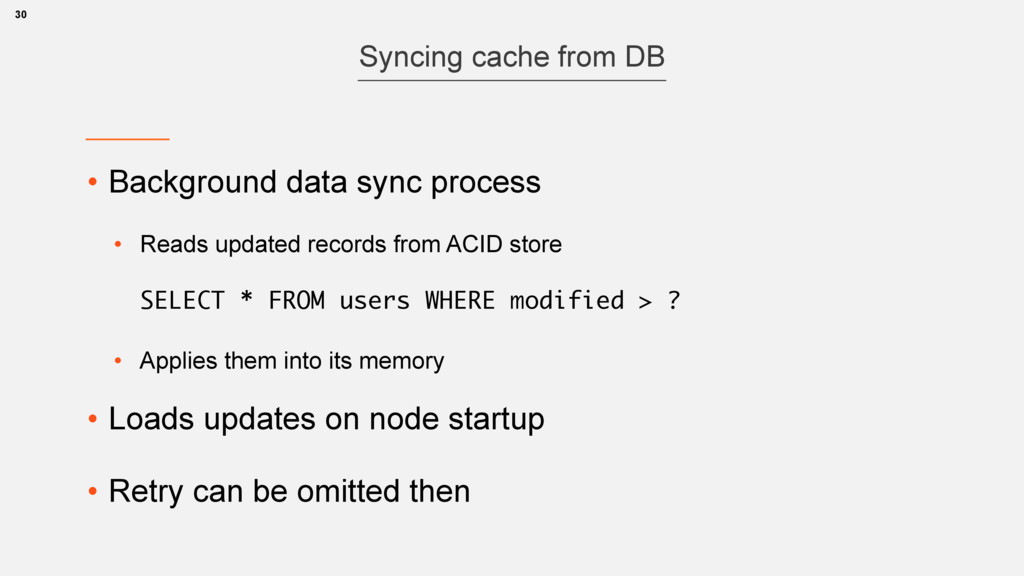
ACID store SELECT * FROM users WHERE modified > ? • Applies them into its memory • Loads updates on node startup • Retry can be omitted then 30 Syncing cache from DB
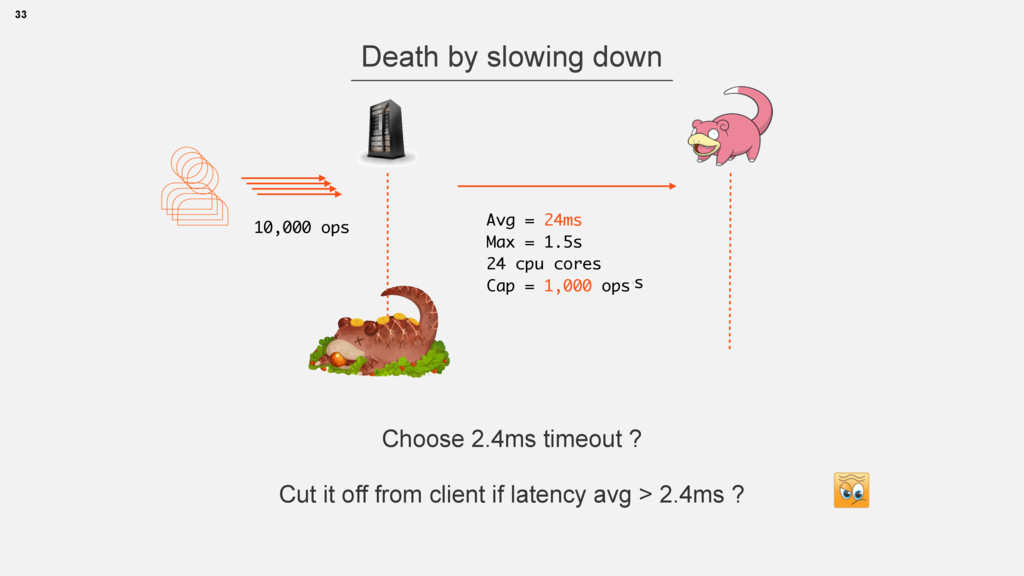
1.5c 24 cpu cores Cap = 24,000 ops Choose 2.4ms timeout ? Cut it off from client if latency avg > 2.4ms ? Avg = 24ms Max = 1.5s 24 cpu cores Cap = 1,000 ops 10,000 ops
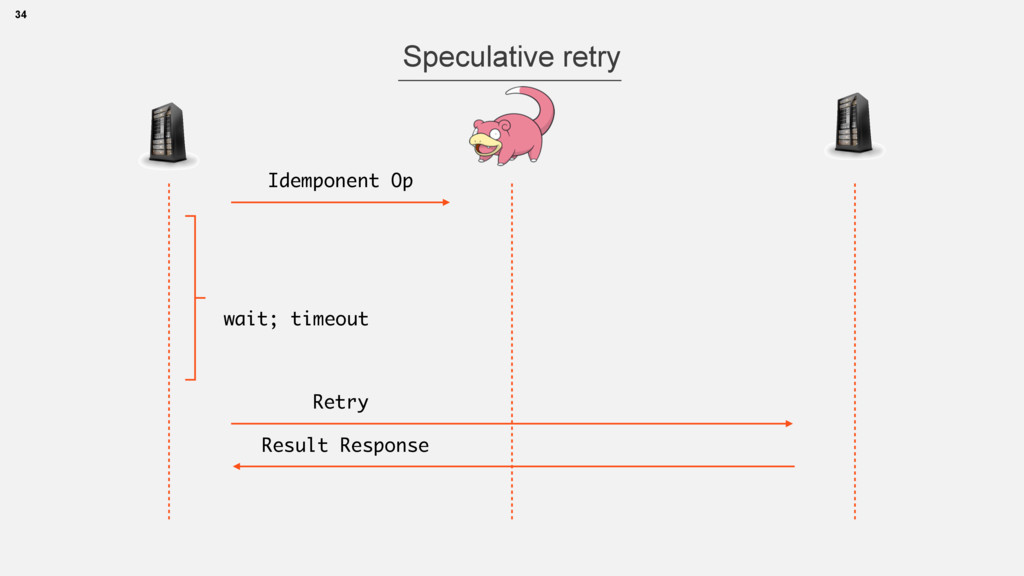
even average latencies • More stable system • Not always applicable: • Idempotent ops, additional load, traffic (to consider) • Can be balanced: always, >avg, >99p 35 Speculative retry
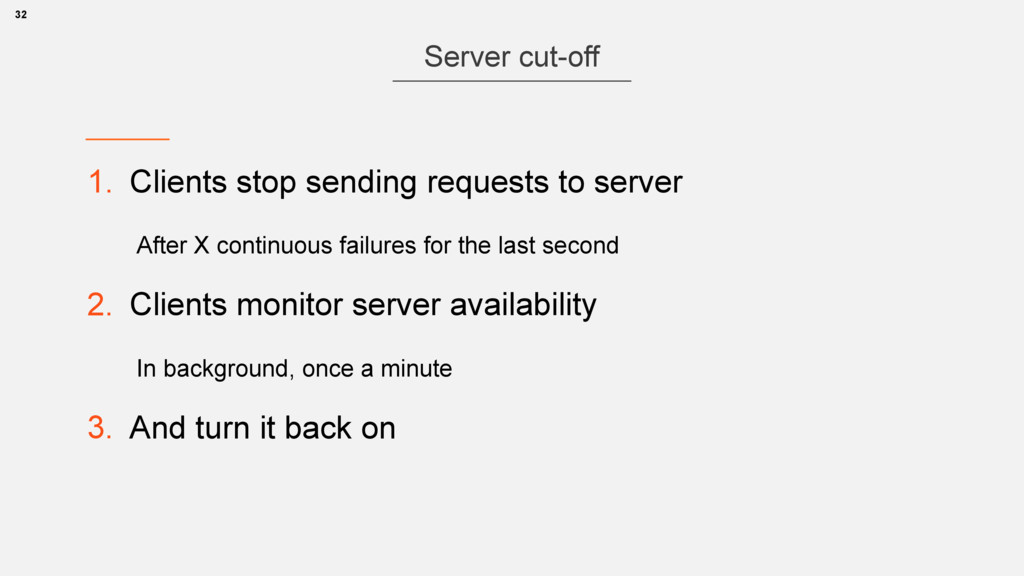
• Disables them (iptables drop) • Runs auto tests • What we check • No crashes, nice UI messages are rendered • Server does start and can serve requests 42 The product we make : “Guerrilla”
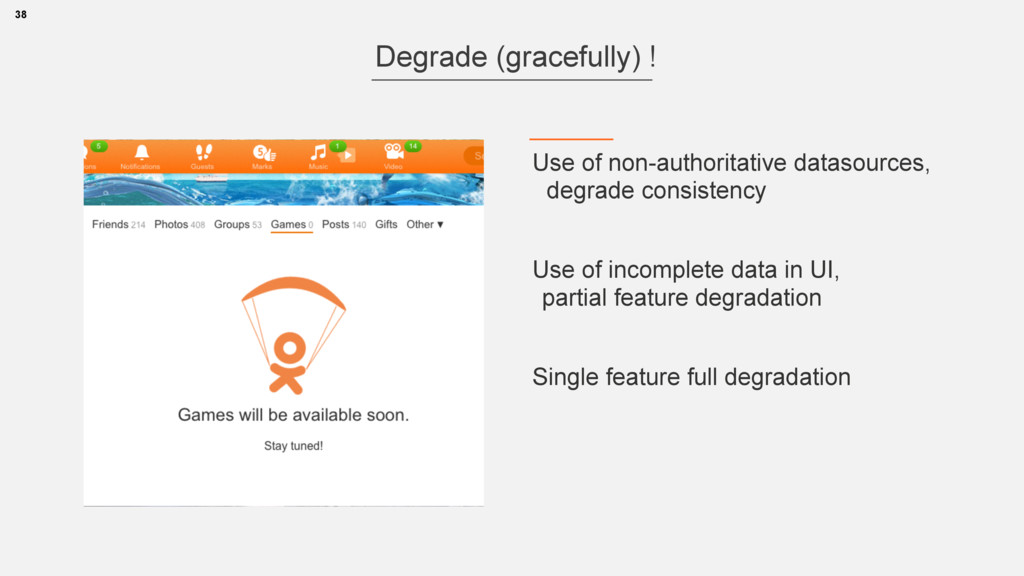
• Don't “prevent”, but mask failures through redundancy • Degrade gracefully on unmask-able failure • Test failures • Production diagnostics are key to failure detection and prevention 49 Short summary
![Distributed Systems @ OK.RU Oleg Anastasyev @m0nstermind [email protected]](https://files.speakerdeck.com/presentations/c3fa688b52c1409abf50ff7a2c69f423/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![12 App Server code https://github.com/odnoklassniki/one-nio long []friendsIds = graphService.getFriendsByFilter(userId, mask);](https://files.speakerdeck.com/presentations/c3fa688b52c1409abf50ff7a2c69f423/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![15 A coding issue https://github.com/odnoklassniki/one-nio long []friendsIds = graphService.getFriendsByFilter(userId, mask);](https://files.speakerdeck.com/presentations/c3fa688b52c1409abf50ff7a2c69f423/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![39 The code interface UserCache { @RemoteMethod Distributed<Collection<User>> getUsersByIds(long[] keys);](https://files.speakerdeck.com/presentations/c3fa688b52c1409abf50ff7a2c69f423/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}