Ø Japanese morphological analysis Ø Text classification • Big Data Processing Ø In-‐‑‒memory aggregation engine for BI Ø Big Data Processing for global social game About Me 2
Subsidiary company of NTT DOCOMO INC. (mobile carrier) • Our Services are Ø D2C Listing/Display Ads Ø D2C PLA Ø Mail Push Ads Ø Etc. About Our Company – D2C h"p://smt.docomo.ne.jp/ 3
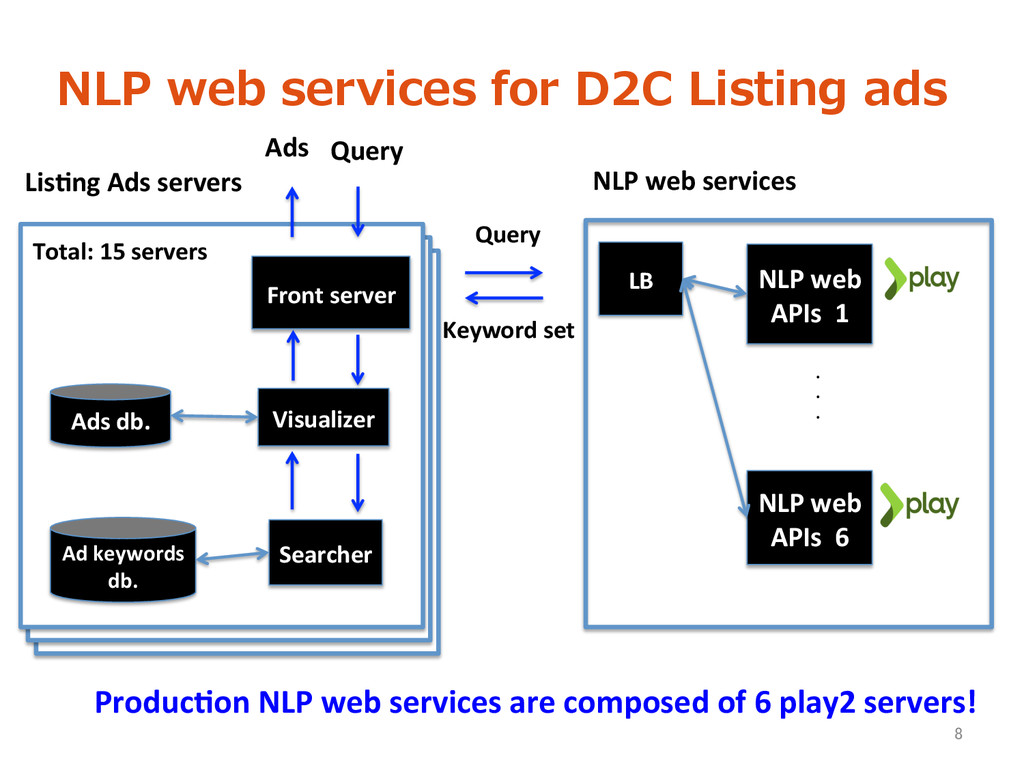
db. Front server Visualizer Searcher NLP web APIs 1 Query Ads db. Lis>ng Ads servers NLP web services . . . LB Query Ads Keyword set NLP web APIs 6 Total: 15 servers Produc>on NLP web services are composed of 6 play2 servers! 8
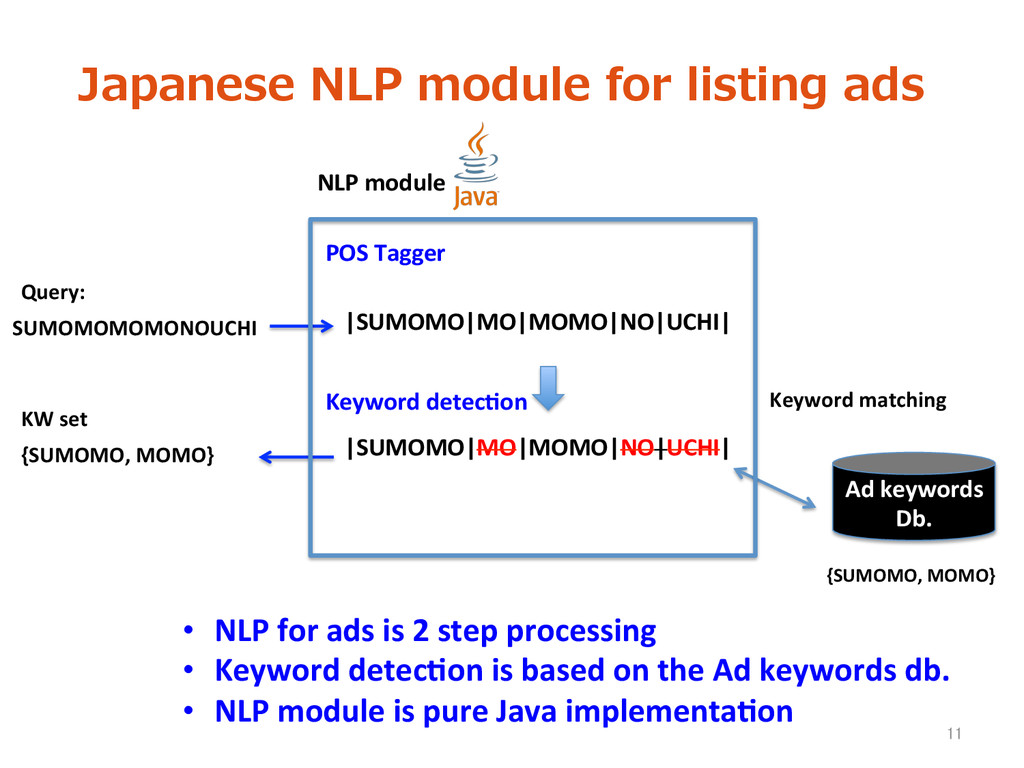
Plums are part of peaches Japanese text is not split by space between characters! 10 We need to split text into words SUMOMO(plum) noun MO par>cle MOMO(peach) noun NO par>cle UCHI noun POS Tagger
{SUMOMO, MOMO} |SUMOMO|MO|MOMO|NO|UCHI| Ad keywords Db. Keyword matching • NLP for ads is 2 step processing • Keyword detec>on is based on the Ad keywords db. • NLP module is pure Java implementa>on Keyword detec>on NLP module 11 |SUMOMO|MO|MOMO|NO|UCHI| {SUMOMO, MOMO} Query: KW set
Only 6 play2 servers! Ø Covers en>re DOCOMO portal for mobile • Only One person developed Ø Our NLP java module was embedded in play2 scala smoothly. 12
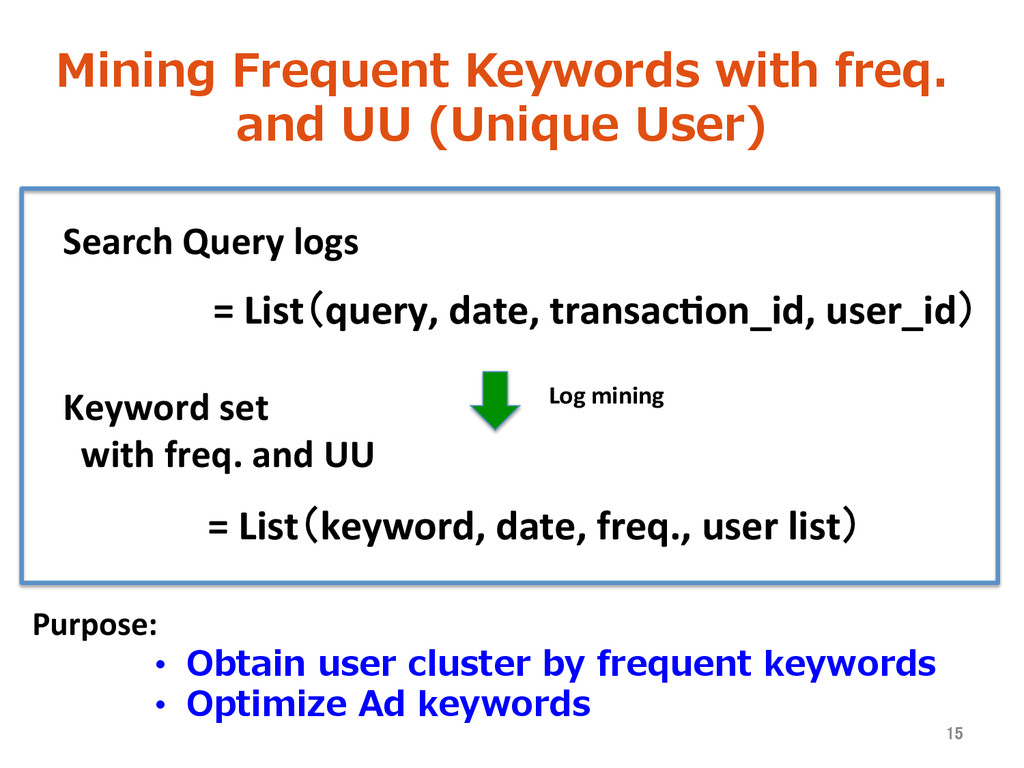
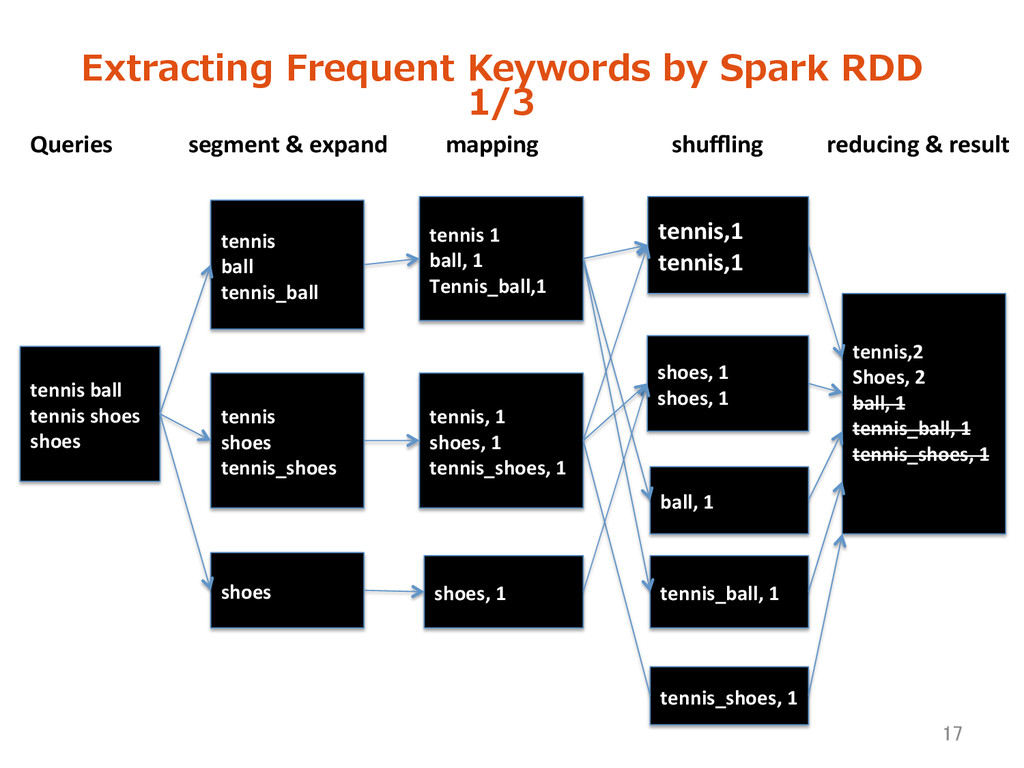
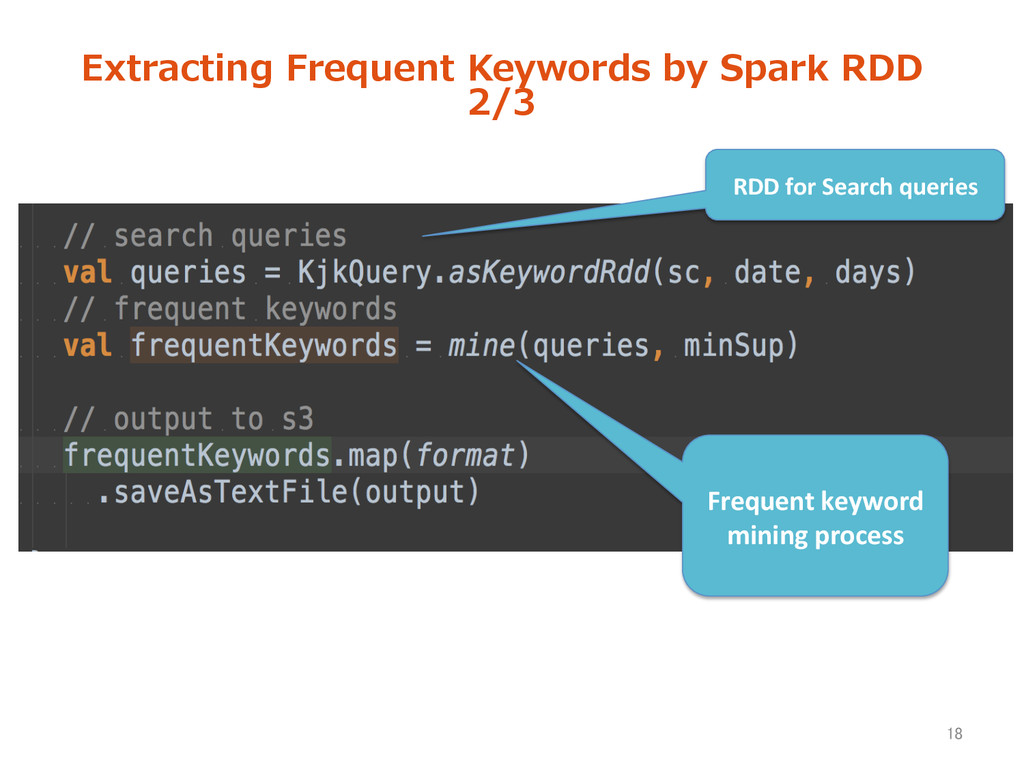
logs for over 2 years. • The number of queries increase day after day • Represents individual interests and likes. Extracting variable information 14 Query logs are our treasure!
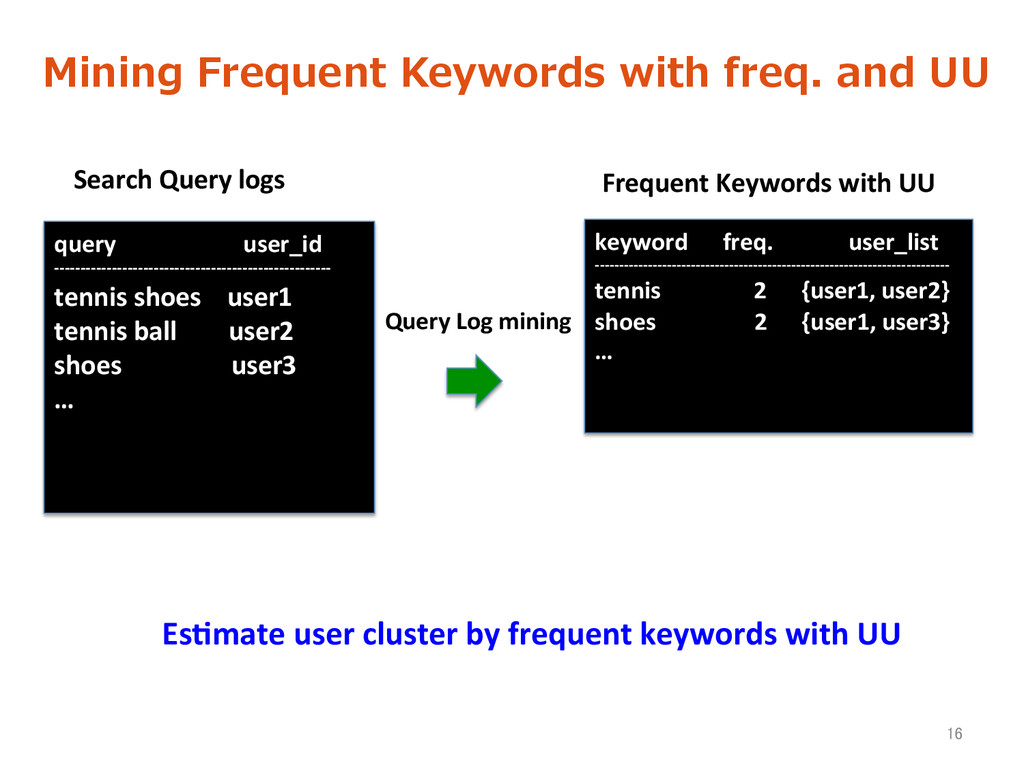
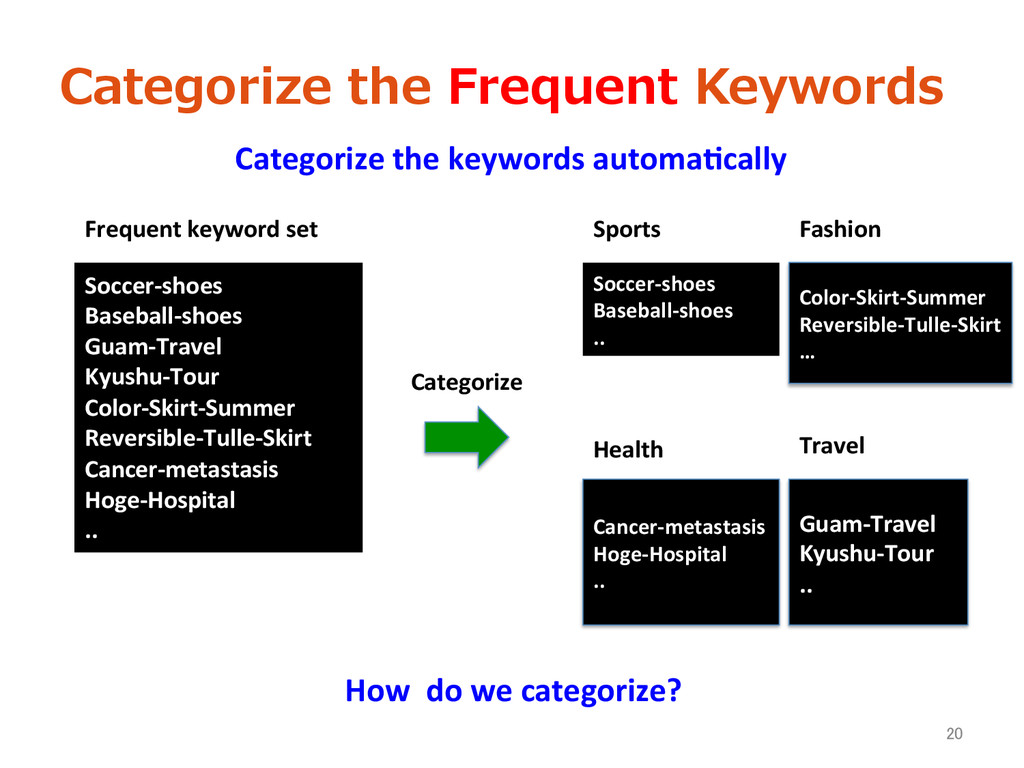
Search Query logs = List(query, date, transac>on_id, user_id) = List(keyword, date, freq., user list) Keyword set with freq. and UU • Obtain user cluster by frequent keywords • Optimize Ad keywords 15 Log mining Purpose:
(NB) 2. Support Vector Machine 3. Logis>c Regression 4. Decision Tree 5. Random Forest 6. Gradient Boosted Tree 1. K-‐means 2. Gaussian Mixture 21 There are no semi-‐supervised learning algorithms yet. So we made it !
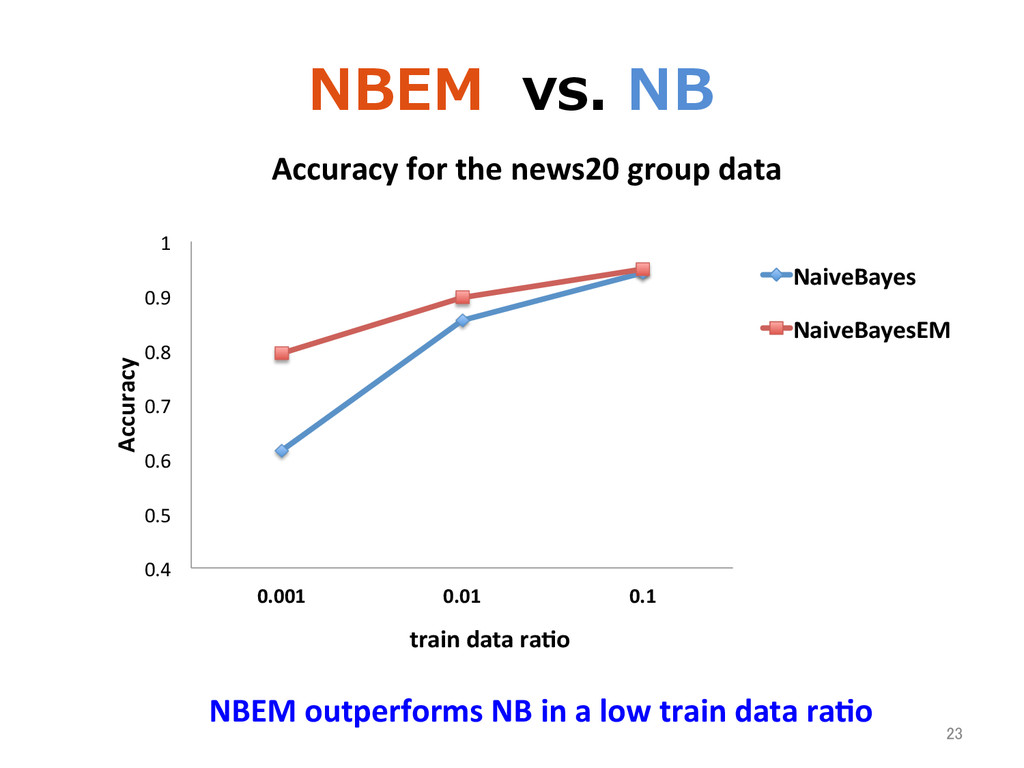
0.7 0.8 0.9 1 0.001 0.01 0.1 Accuracy train data ra>o Accuracy for the news20 group data NaiveBayes NaiveBayesEM 23 NBEM outperforms NB in a low train data ra>o
log mining Ø Obtained frequent keyword set for user interests targe>ng • Semi-‐supervised extension of the spark Naive Bayes classifier was proposed. Ø NBEM outperforms NB in case of small train data Ø NBEM is used for categorizing Keywords. 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}