REMOVING. ▸ SQL is equipped with data manipulation language (DML). DML modifies the database instance by inserting, updating and deleting its data. ▸ SQL contains the following set of commands in its DML section − ▸ SELECT/FROM/WHERE ▸ INSERT INTO/VALUES ▸ UPDATE/SET/WHERE ▸ DELETE FROM/WHERE
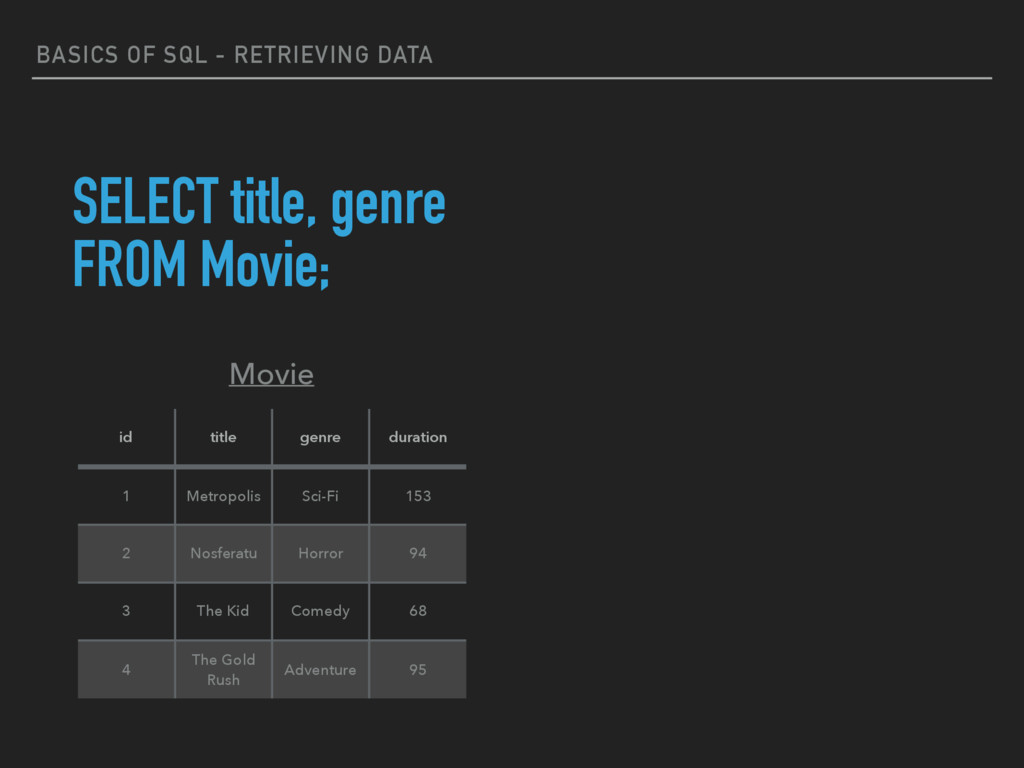
Fundamental query command of SQL. Selects columns based on the condition described by WHERE clause. ▸ FROM - This clause takes a table/relation name as an argument from which columns are to be selected. ▸ WHERE - This clause defines conditions which must match in order to qualify the columns to be selected.
1 Metropolis Sci-Fi 153 2 Nosferatu Horror 94 3 The Kid Comedy 68 4 The Gold Rush Adventure 95 title genre The Kid Comedy Movie SELECT title, genre FROM Movie WHERE id = 3;
1 Metropolis Sci-Fi 153 2 Nosferatu Horror 94 3 The Kid Comedy 68 4 The Gold Rush Adventure 95 id title genre duration 3 The Kid Comedy 68 Movie SELECT * FROM Movie WHERE id = 3;
for inserting values into the rows of a table (relation). ▸ INSERT INTO table (column1, column2, column3 ... ) VALUES (value1, value2, value3 …) ▸ INSERT INTO table VALUES (value1, value2, ... )
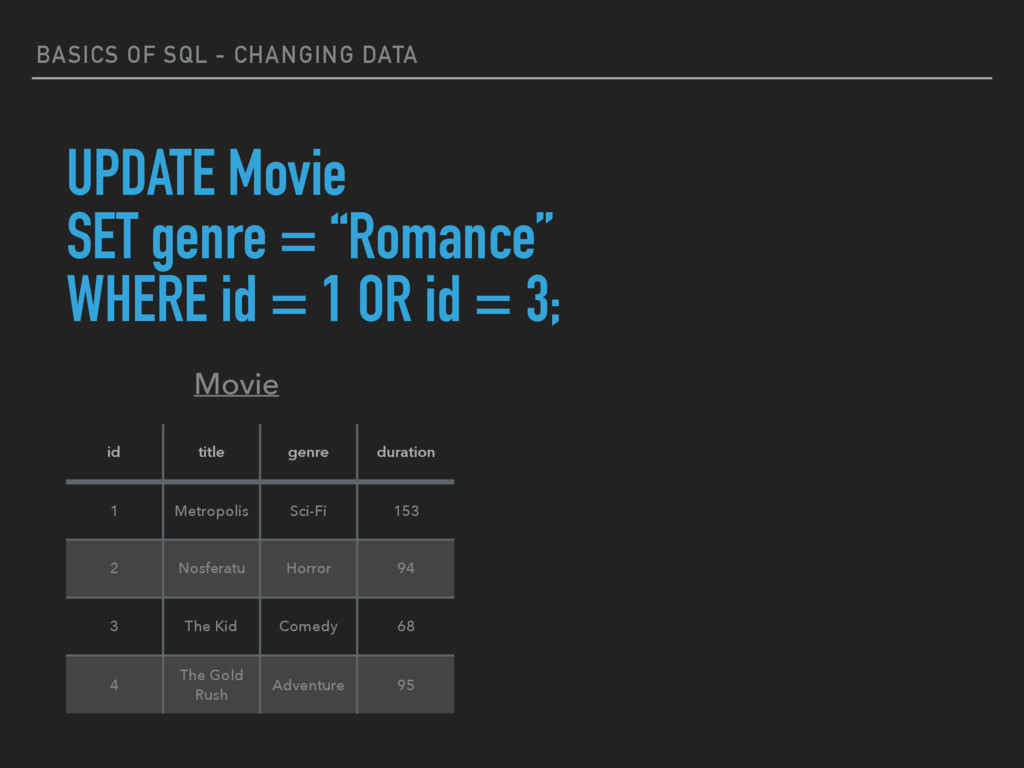
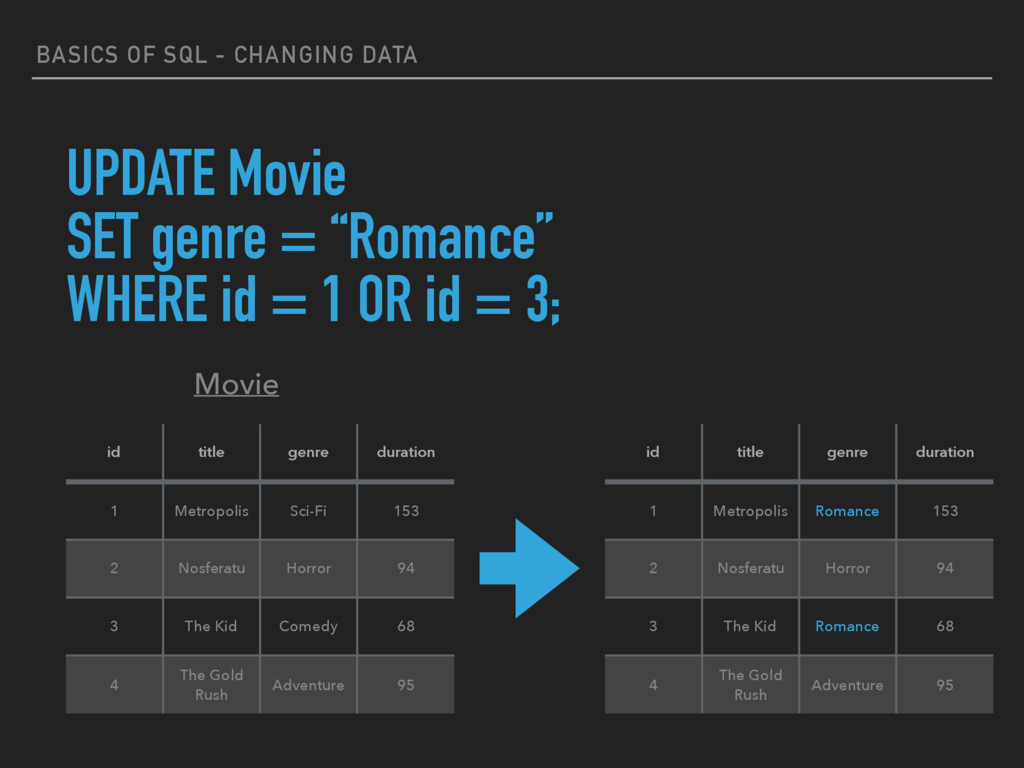
updating or modifying the values of columns in a table (relation). ▸ UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition]
genre = “Romance” WHERE id = 1 OR id = 3; id title genre duration 1 Metropolis Sci-Fi 153 2 Nosferatu Horror 94 3 The Kid Comedy 68 4 The Gold Rush Adventure 95
genre = “Romance” WHERE id = 1 OR id = 3; id title genre duration 1 Metropolis Romance 153 2 Nosferatu Horror 94 3 The Kid Romance 68 4 The Gold Rush Adventure 95 id title genre duration 1 Metropolis Sci-Fi 153 2 Nosferatu Horror 94 3 The Kid Comedy 68 4 The Gold Rush Adventure 95
WHERE id = 3; id title genre duration 1 Metropolis Sci-Fi 153 2 Nosferatu Horror 94 3 The Kid Comedy 68 4 The Gold Rush Adventure 95 id title genre duration 1 Metropolis Sci-Fi 153 2 Nosferatu Horror 94 4 The Gold Rush Adventure 95
Adds values on either side of the operator - Subtraction - Subtracts right hand operand from left hand operand * Multiplication - Multiplies values on either side of the operator / Division - Divides left hand operand by right hand operand % Modulus - Divides left hand operand by right hand operand and returns remainder
the values of two operands are equal or not, if yes then condition becomes true. != Checks if the values of two operands are equal or not, if values are not equal then condition becomes true. <> Checks if the values of two operands are equal or not, if values are not equal then condition becomes true. > Checks if the value of left operand is greater than the value of right operand, if yes then condition becomes true. < Checks if the value of left operand is less than the value of right operand, if yes then condition becomes true. >= Checks if the value of left operand is greater than or equal to the value of right operand, if yes then condition becomes true. <= Checks if the value of left operand is less than or equal to the value of
compare a value to all values in another value set. AND Allows the existence of multiple conditions in an SQL statement's WHERE clause. BETWEEN Used to search for values that are within a set of values, given the minimum value and the maximum value. IN Used to compare a value to a list of literal values that have been specified. LIKE Used to compare a value to similar values using wildcard operators. NOT Reverses the meaning of the logical operator with which it is used. Eg: NOT BETWEEN, NOT IN, etc. This is a negate operator. OR Used to combine multiple conditions in an SQL statement's WHERE clause. IS NULL Used to compare a value with a NULL value. UNIQUE Searches every row of a specified table for uniqueness (no duplicates).
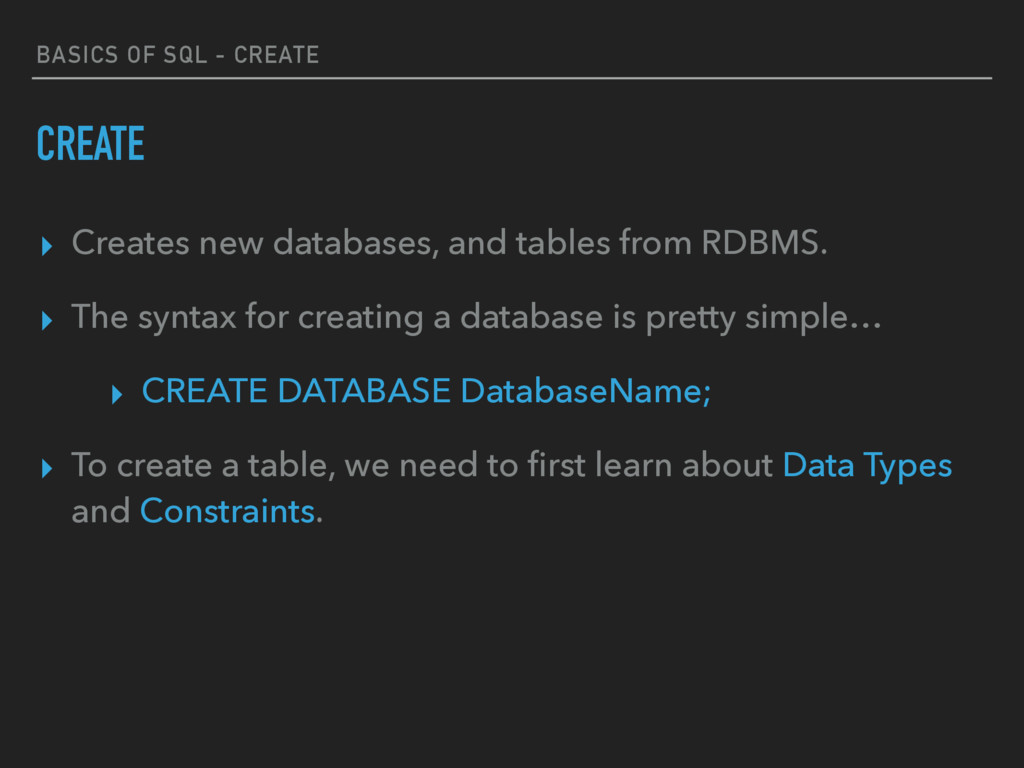
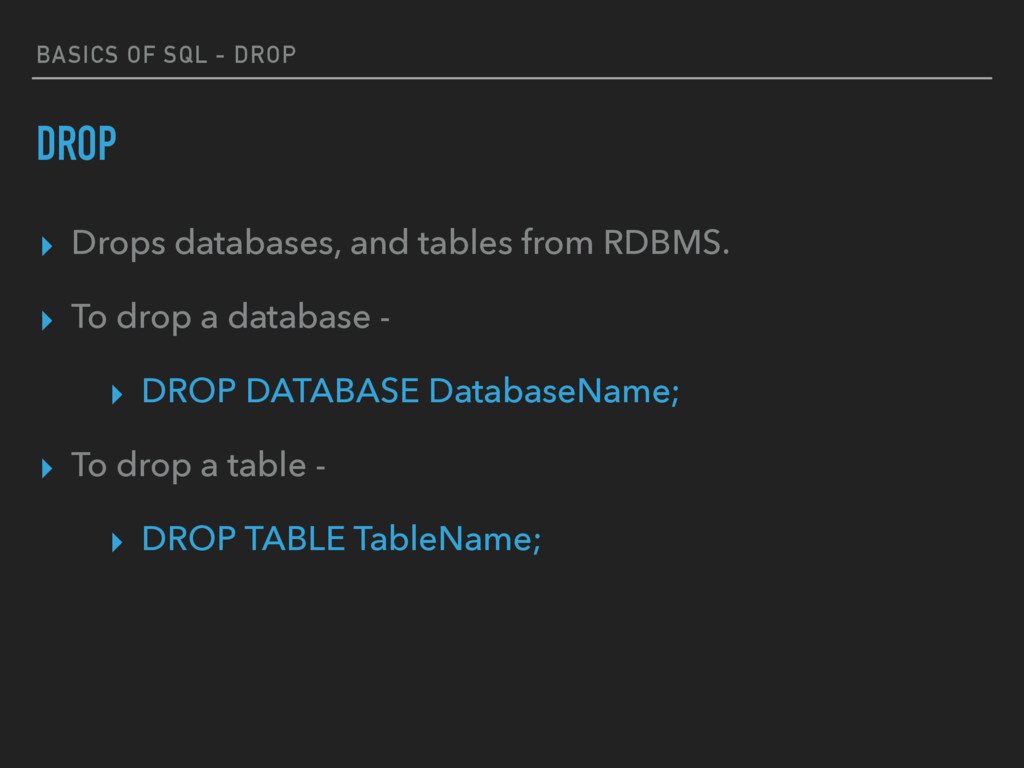
AND DROPPING. ▸ SQL is equipped with data definition language (DDL) to define database schema. SQL contains the following set of commands in its DDL section − ▸ CREATE ▸ DROP ▸ ALTER (We’ll skip this for now…)
and tables from RDBMS. ▸ The syntax for creating a database is pretty simple… ▸ CREATE DATABASE DatabaseName; ▸ To create a table, we need to first learn about Data Types and Constraints.
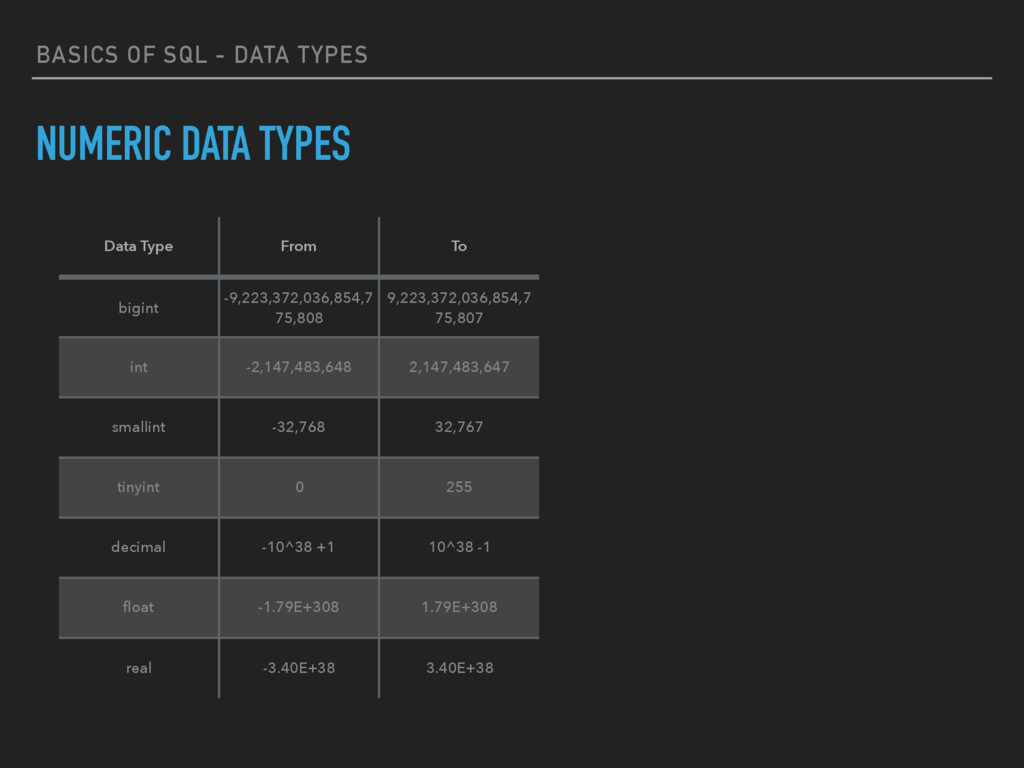
TYPES Data Type From To datetime Jan 1, 1753 Dec 31, 9999 smalldatetime Jan 1, 1900 Jun 6, 2079 date Stores a date like June 30, 1991 time Stores a time of day like 12:30 P.M.
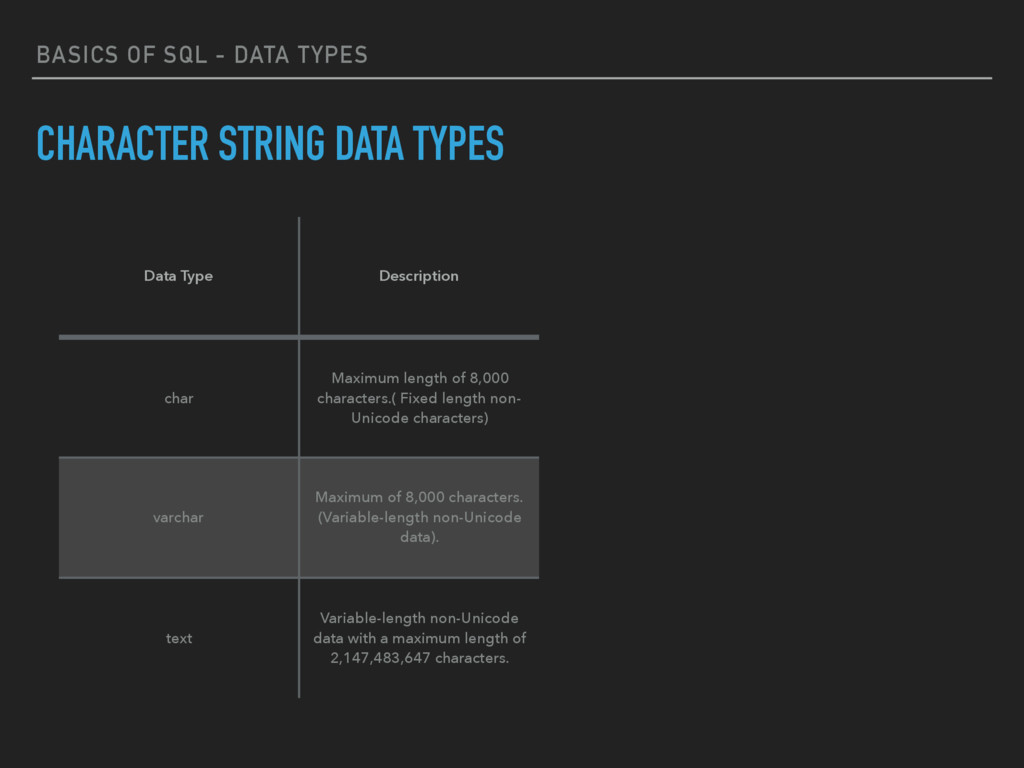
Data Type Description char Maximum length of 8,000 characters.( Fixed length non- Unicode characters) varchar Maximum of 8,000 characters. (Variable-length non-Unicode data). text Variable-length non-Unicode data with a maximum length of 2,147,483,647 characters.
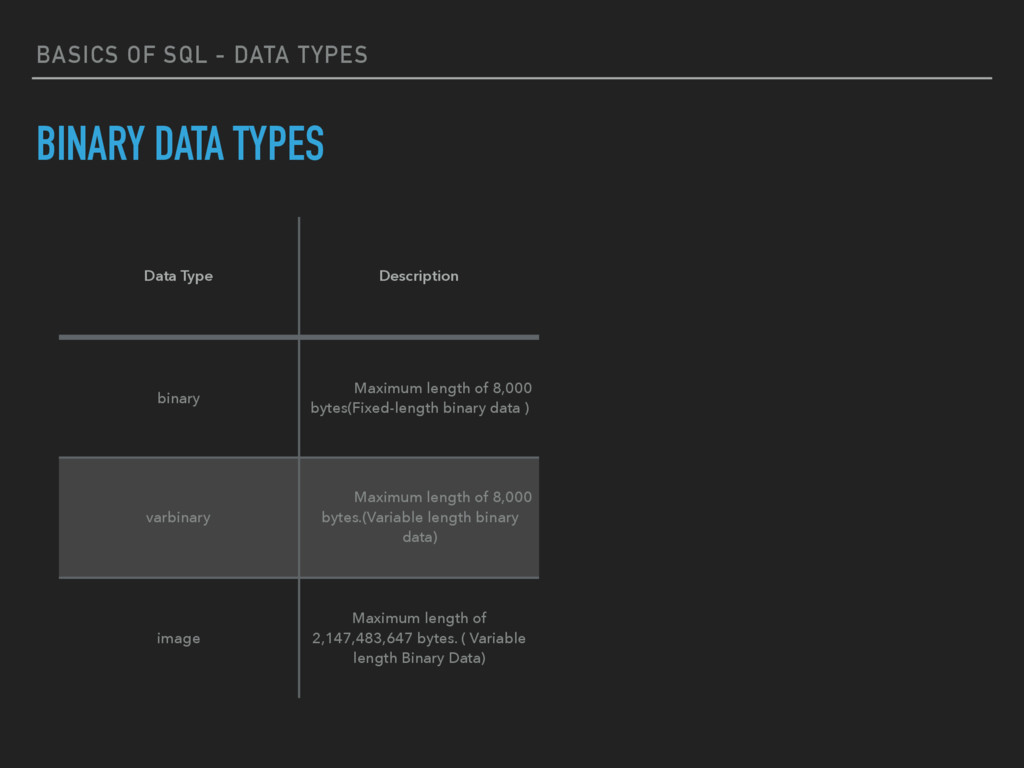
Type Description binary Maximum length of 8,000 bytes(Fixed-length binary data ) varbinary Maximum length of 8,000 bytes.(Variable length binary data) image Maximum length of 2,147,483,647 bytes. ( Variable length Binary Data)
the rules enforced on data columns on table. These are used to limit the type of data that can go into a table. This ensures the accuracy and reliability of the data in the database.
NOT NULL: Ensures that a column cannot have NULL value. ▸ DEFAULT: Provides a default value for a column when none is specified. ▸ UNIQUE: Ensures that all values in a column are different. ▸ PRIMARY Key: Uniquely identified each rows/records in a database table. ▸ FOREIGN Key: Uniquely identified a rows/records in any another database table. ▸ CHECK: Ensures that all values in a column satisfy certain conditions.
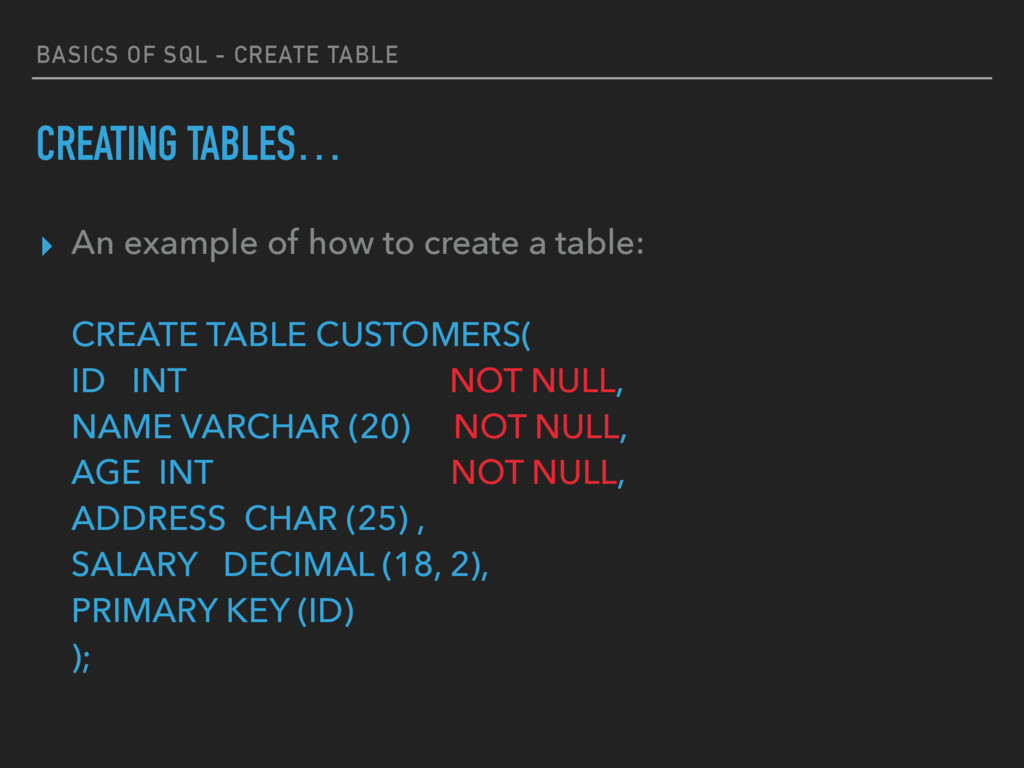
▸ The syntax for creating a table: CREATE TABLE table_name( column1 datatype, column2 datatype, column3 datatype, ..... columnN datatype, PRIMARY KEY( one or more columns ) );
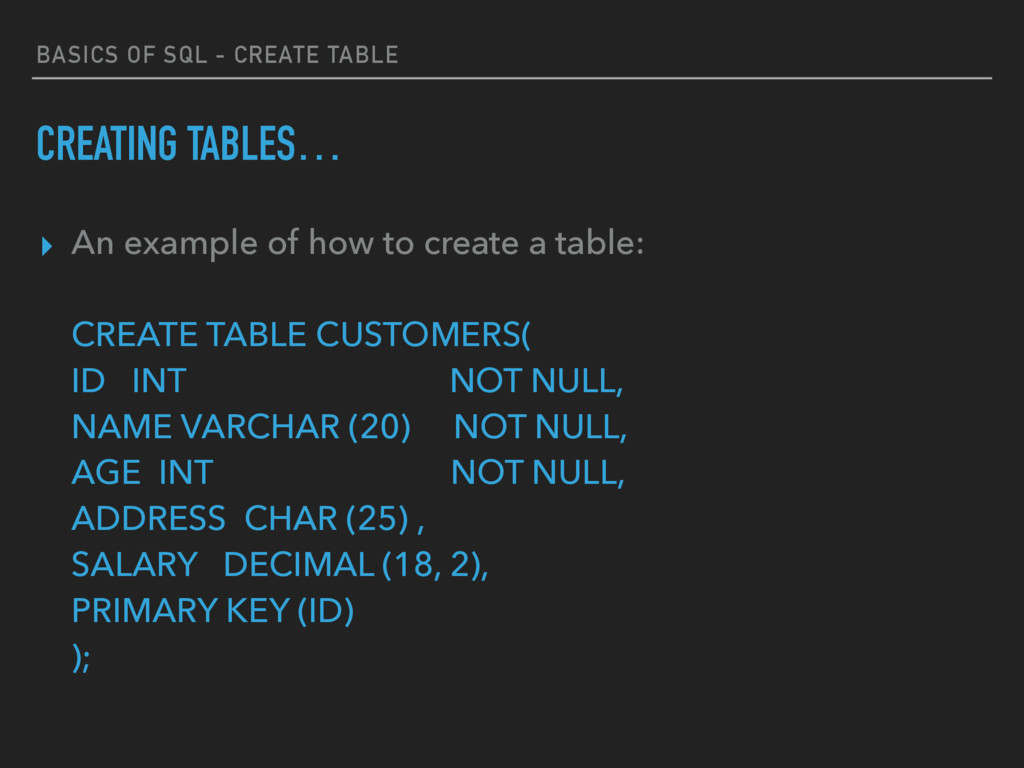
example of how to create a table: CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
example of how to create a table: CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
example of how to create a table: CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
example of how to create a table: CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25) , SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
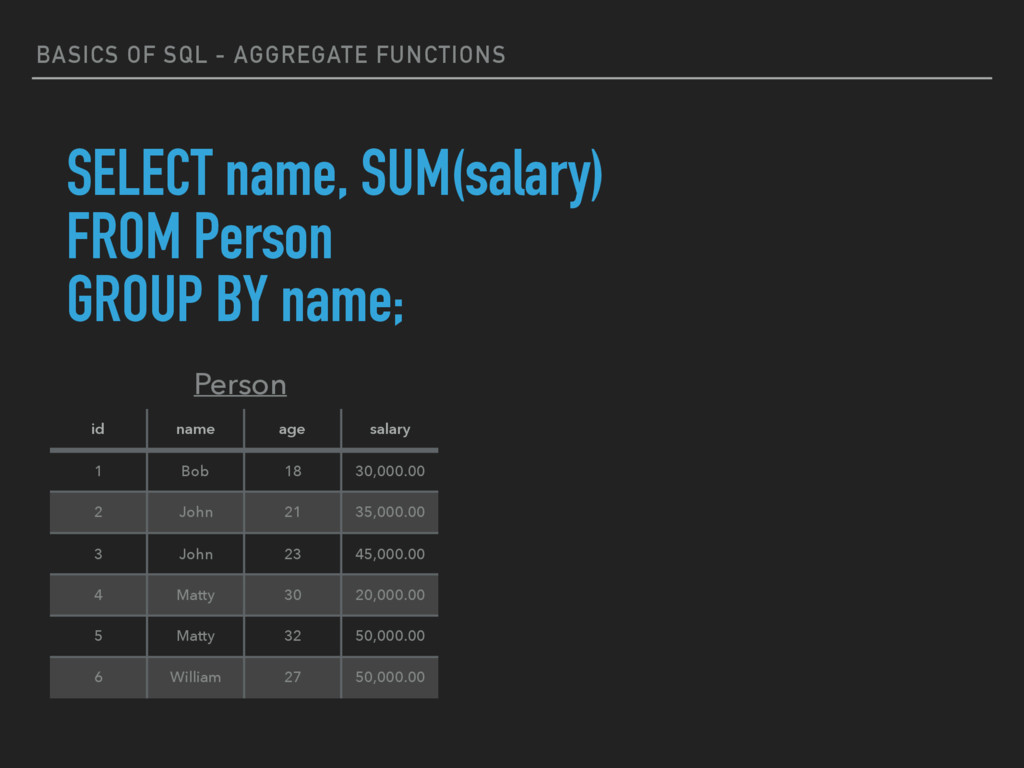
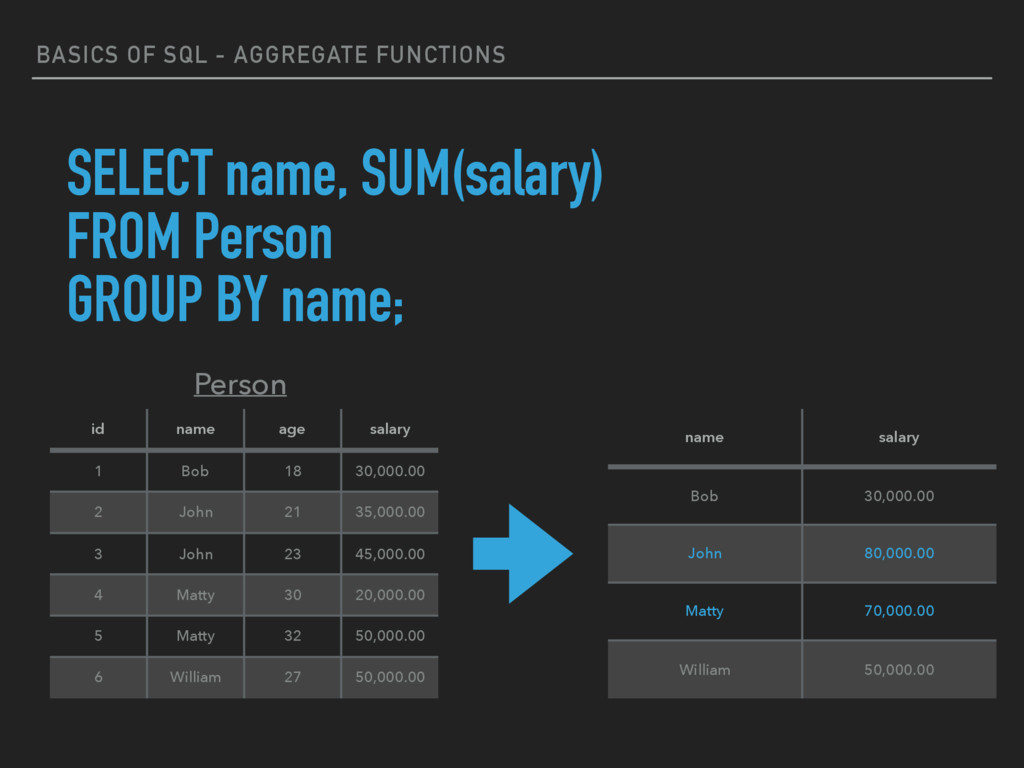
aggregate functions return a single value, calculated from values in a column. ▸ AVG() - Returns the average value ▸ COUNT() - Returns the number of rows ▸ FIRST() - Returns the first value ▸ LAST() - Returns the last value ▸ MAX() - Returns the largest value ▸ MIN() - Returns the smallest value ▸ SUM() - Returns the sum
aggregate functions return a single value, calculated from values in a column. ▸ AVG() - Returns the average value ▸ COUNT() - Returns the number of rows ▸ FIRST() - Returns the first value ▸ LAST() - Returns the last value ▸ MAX() - Returns the largest value ▸ MIN() - Returns the smallest value ▸ SUM() - Returns the sum
GROUP BY statement is used in conjunction with the aggregate functions to group the result-set by one or more columns. ▸ Example syntax - SELECT column_name, aggregate_function(column_name) FROM table_name GROUP BY column_name;
1 Bob 18 30,000.00 2 John 21 35,000.00 3 John 23 45,000.00 4 Matty 30 20,000.00 5 Matty 32 50,000.00 6 William 27 50,000.00 Person SELECT name, SUM(salary) FROM Person GROUP BY name;
1 Bob 18 30,000.00 2 John 21 35,000.00 3 John 23 45,000.00 4 Matty 30 20,000.00 5 Matty 32 50,000.00 6 William 27 50,000.00 Person SELECT name, SUM(salary) FROM Person GROUP BY name; name salary Bob 30,000.00 John 80,000.00 Matty 70,000.00 William 50,000.00
clause is used to combine records from two or more tables in a database. A JOIN is a means for combining fields from two tables by using values common to each.
returns rows when there is a match in both tables. ▸ LEFT JOIN: returns all rows from the left table, even if there are no matches in the right table. ▸ RIGHT JOIN: returns all rows from the right table, even if there are no matches in the left table. ▸ FULL JOIN: returns rows when there is a match in one of the tables. ▸ SELF JOIN: is used to join a table to itself as if the table were two tables, temporarily renaming at least one table in the SQL statement. ▸ CARTESIAN JOIN: returns the Cartesian product of the sets of records from the two or more joined tables.
returns rows when there is a match in both tables. ▸ LEFT JOIN: returns all rows from the left table, even if there are no matches in the right table. ▸ RIGHT JOIN: returns all rows from the right table, even if there are no matches in the left table. ▸ FULL JOIN: returns rows when there is a match in one of the tables. ▸ SELF JOIN: is used to join a table to itself as if the table were two tables, temporarily renaming at least one table in the SQL statement. ▸ CARTESIAN JOIN: returns the Cartesian product of the sets of records from the two or more joined tables.
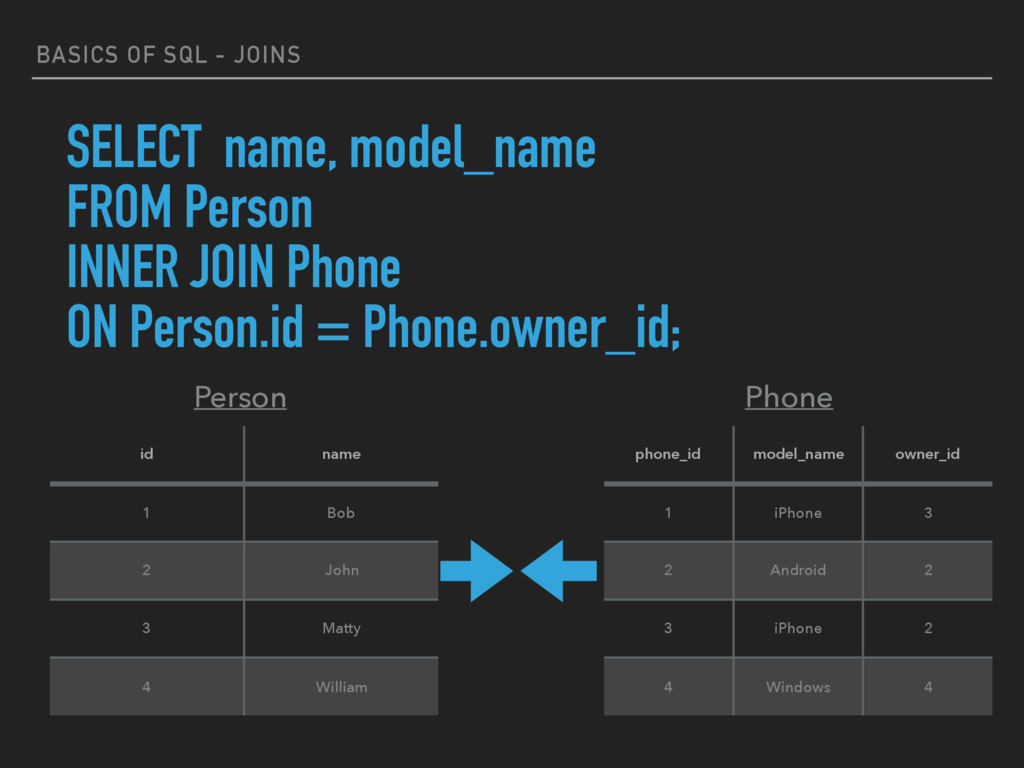
JOIN keyword selects all rows from both tables as long as there is a match between the columns in both tables. ▸ SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name=table2.column_name;
John 3 Matty 4 William Person SELECT name, model_name FROM Person INNER JOIN Phone ON Person.id = Phone.owner_id; phone_id model_name owner_id 1 iPhone 3 2 Android 2 3 iPhone 2 4 Windows 4 Phone
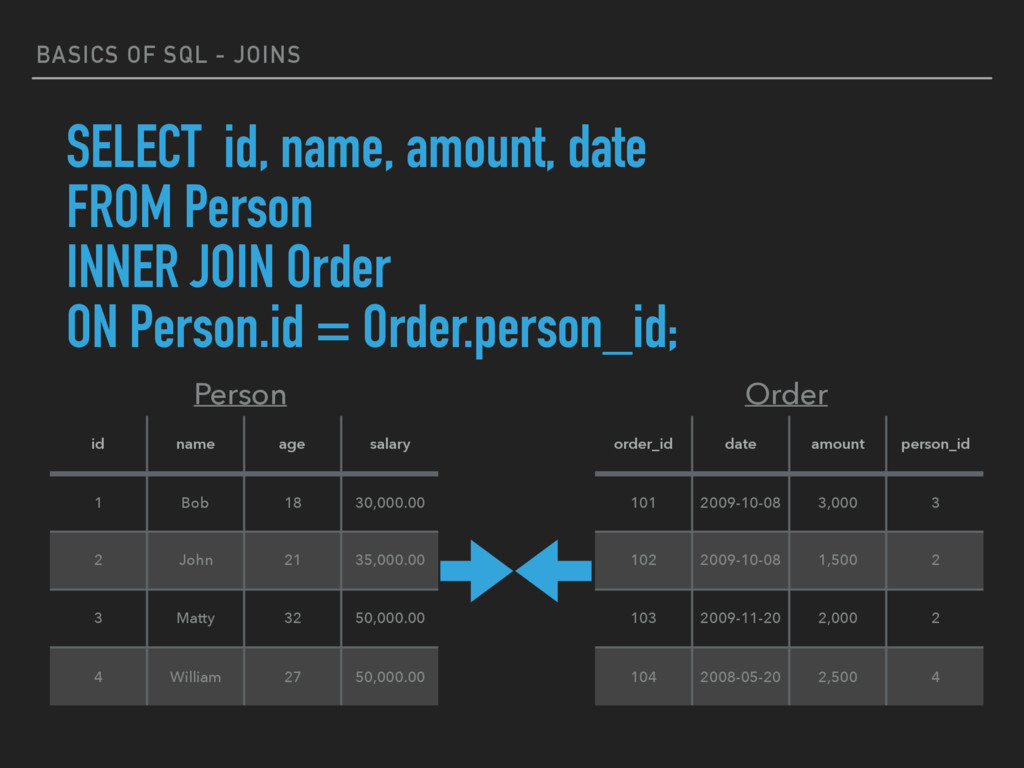
Bob 18 30,000.00 2 John 21 35,000.00 3 Matty 32 50,000.00 4 William 27 50,000.00 Person SELECT id, name, amount, date FROM Person INNER JOIN Order ON Person.id = Order.person_id; order_id date amount person_id 101 2009-10-08 3,000 3 102 2009-10-08 1,500 2 103 2009-11-20 2,000 2 104 2008-05-20 2,500 4 Order
FROM Person INNER JOIN Order ON Person.id = Order.person_id; id name amount date 3 Matty 3,000 2009-10-08 2 John 1,500 2009-10-08 2 John 2,000 2009-11-20 4 William 2,500 2008-05-20
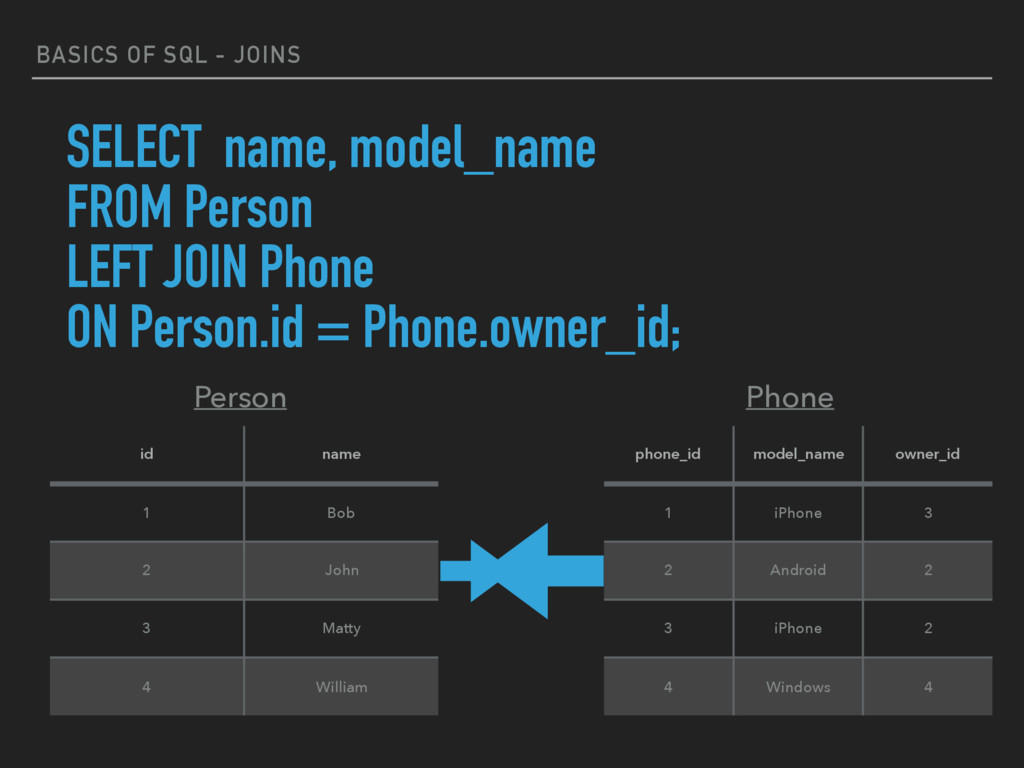
JOIN keyword returns all rows from the left table (table1), with the matching rows in the right table (table2). The result is NULL in the right side when there is no match. ▸ SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name=table2.column_name; ▸ *Note - In some databases, LEFT JOIN is called LEFT OUTER JOIN.
John 3 Matty 4 William Person SELECT name, model_name FROM Person LEFT JOIN Phone ON Person.id = Phone.owner_id; phone_id model_name owner_id 1 iPhone 3 2 Android 2 3 iPhone 2 4 Windows 4 Phone
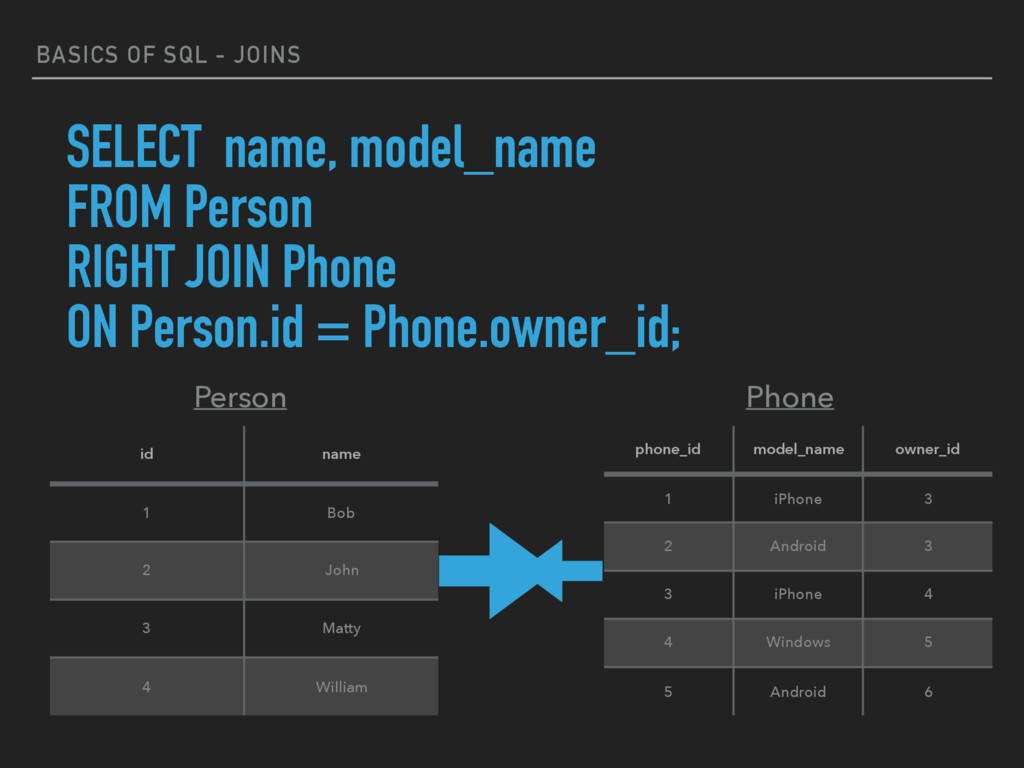
JOIN keyword returns all rows from the right table (table2), with the matching rows in the left table (table1). The result is NULL in the left side when there is no match. ▸ SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name=table2.column_name; ▸ *Note - In some databases, RIGHT JOIN is called RIGHT OUTER JOIN.
John 3 Matty 4 William Person SELECT name, model_name FROM Person RIGHT JOIN Phone ON Person.id = Phone.owner_id; phone_id model_name owner_id 1 iPhone 3 2 Android 3 3 iPhone 4 4 Windows 5 5 Android 6 Phone
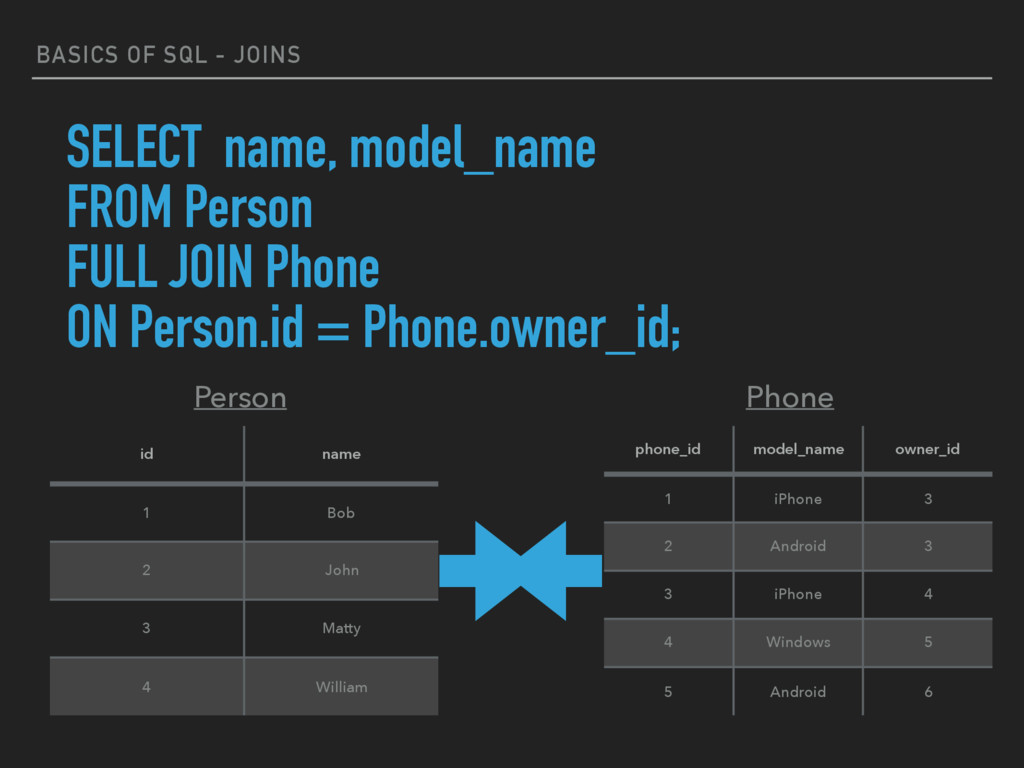
OUTER JOIN keyword returns all rows from the left table (table1) and from the right table (table2). ▸ The FULL OUTER JOIN keyword combines the result of both LEFT and RIGHT joins. ▸ SELECT column_name(s) FROM table1 FULL JOIN table2 ON table1.column_name=table2.column_name; ▸ *Note - In some databases, FULL JOIN is called FULL OUTER JOIN.
John 3 Matty 4 William Person SELECT name, model_name FROM Person FULL JOIN Phone ON Person.id = Phone.owner_id; phone_id model_name owner_id 1 iPhone 3 2 Android 3 3 iPhone 4 4 Windows 5 5 Android 6 Phone
in a database. This includes creating tables and establishing relationships between those tables according to rules designed both to protect the data and to make the database more flexible by eliminating redundancy and inconsistent dependency. ▸ Redundant data wastes disk space and creates maintenance problems. If data that exists in more than one place must be changed, the data must be changed in exactly the same way in all locations. A customer address change is much easier to implement if that data is stored only in the Customers table and nowhere else in the database.
it is intuitive for a user to look in the Customers table for the address of a particular customer, it may not make sense to look there for the salary of the employee who calls on that customer. The employee's salary is related to, or dependent on, the employee and thus should be moved to the Employees table. Inconsistent dependencies can make data difficult to access because the path to find the data may be missing or broken.
database normalization. Each rule is called a "normal form." If the first rule is observed, the database is said to be in "first normal form." If the first three rules are observed, the database is considered to be in "third normal form." Although other levels of normalization are possible, third normal form is considered the highest level necessary for most applications.
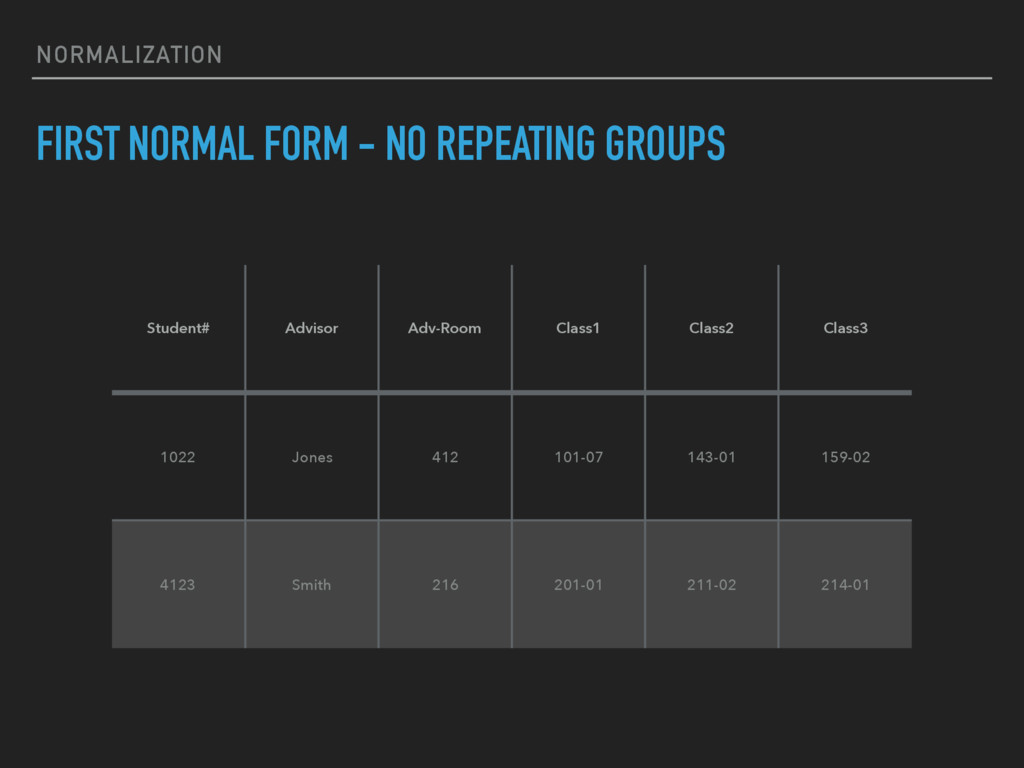
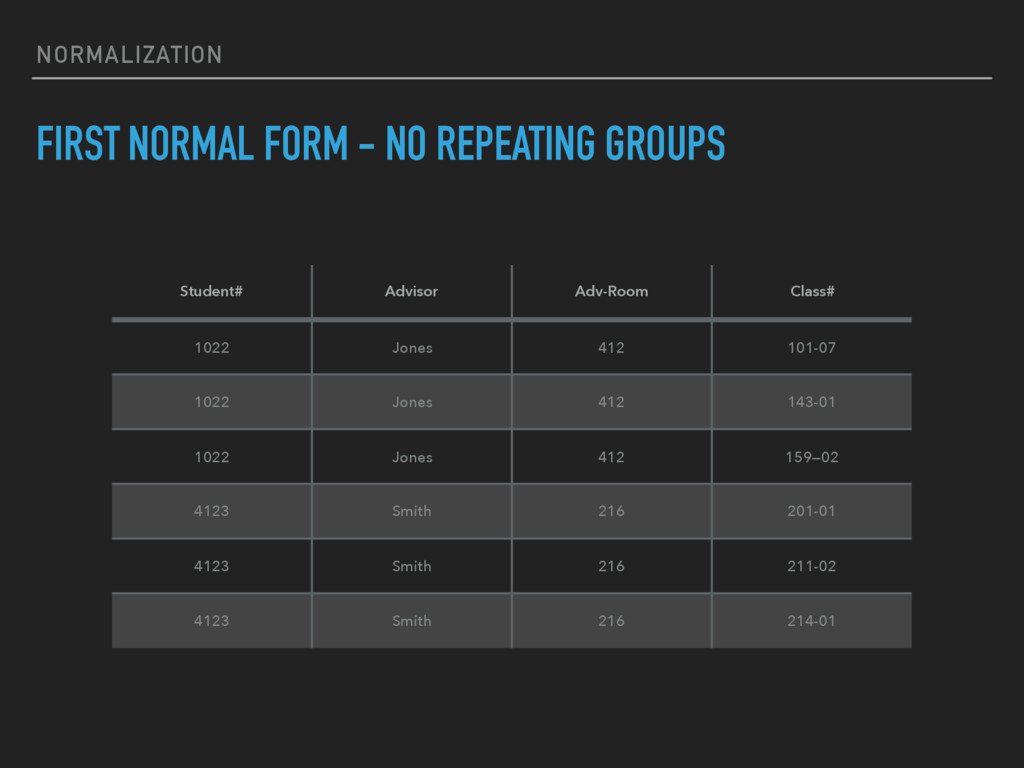
repeating groups in individual tables. ▸ Create a separate table for each set of related data. ▸ Identify each set of related data with a primary key. ▸ Do not use multiple fields in a single table to store similar data. ▸ Adding more fields is not the answer; it requires program and table modifications.
separate tables for sets of values that apply to multiple records. ▸ Relate these tables with a foreign key. ▸ Records should not depend on anything other than a table's primary key (a compound key, if necessary).
ON KEY ▸ Eliminate fields that do not depend on the key. ▸ Values in a record that are not part of that record's key do not belong in the table. ▸ In general, any time the contents of a group of fields may apply to more than a single record in the table, consider placing those fields in a separate table.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}