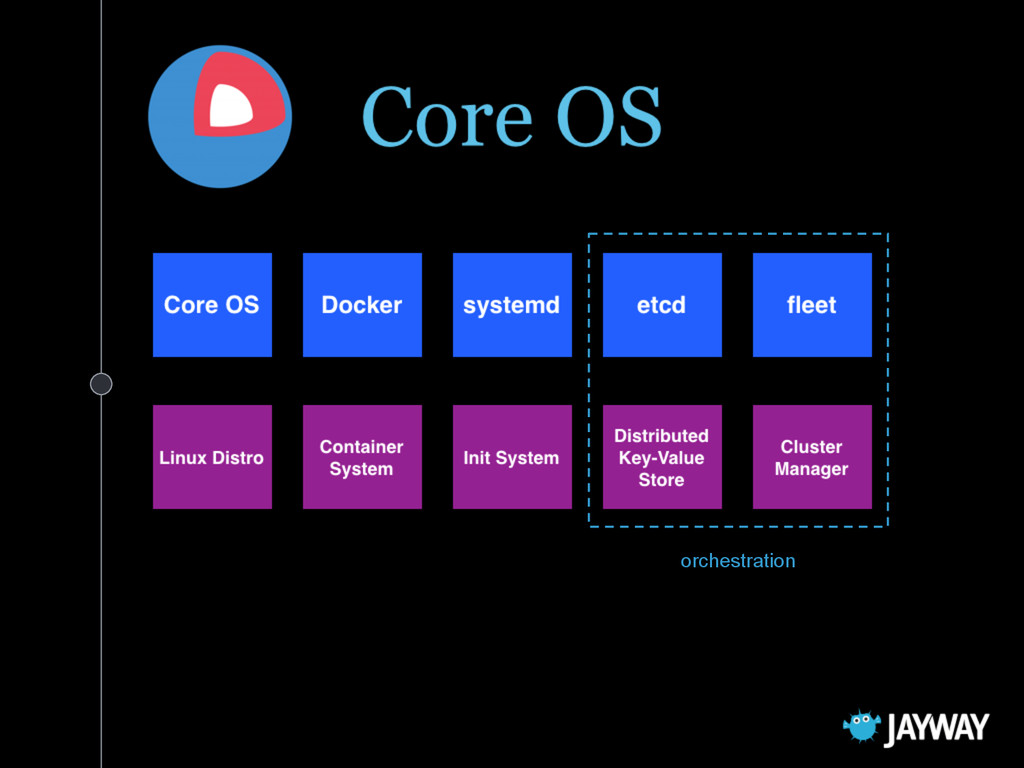
docker pull, start, stop, rm ◦ set environment variables ◦ restart policies ◦ capture output And an OS that can update itself in a sane way. And some orchestration …
magic. * By default one host per cluster can hold a reboot lock. Can turn off reboots. Define strategy in cloud-config: #cloud-config coreos: update: group: stable reboot-strategy: off * not actual magic
software tested in alpha and beta first. Beta Promoted alpha releases. Run a few beta hosts to catch problems early. Alpha Tracks dev and gets newest docker, etcd and fleet. Frequent releases. https://coreos.com/releases/
• This cluster is finished. You must create a new one. • This is not cool. etcd gotchas Use an odd number of hosts. • Adding one to make an even number does not increase redundancy. Use Elastic IPs. • If an instance reboots with a new IP it may fail to rejoin the cluster.
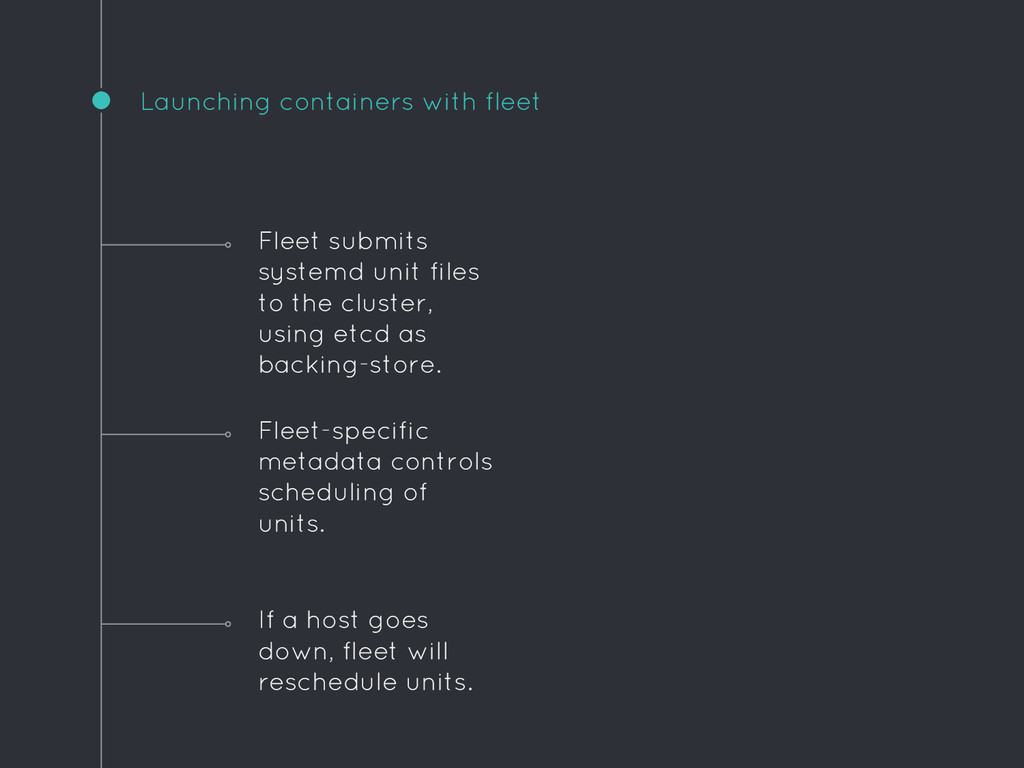
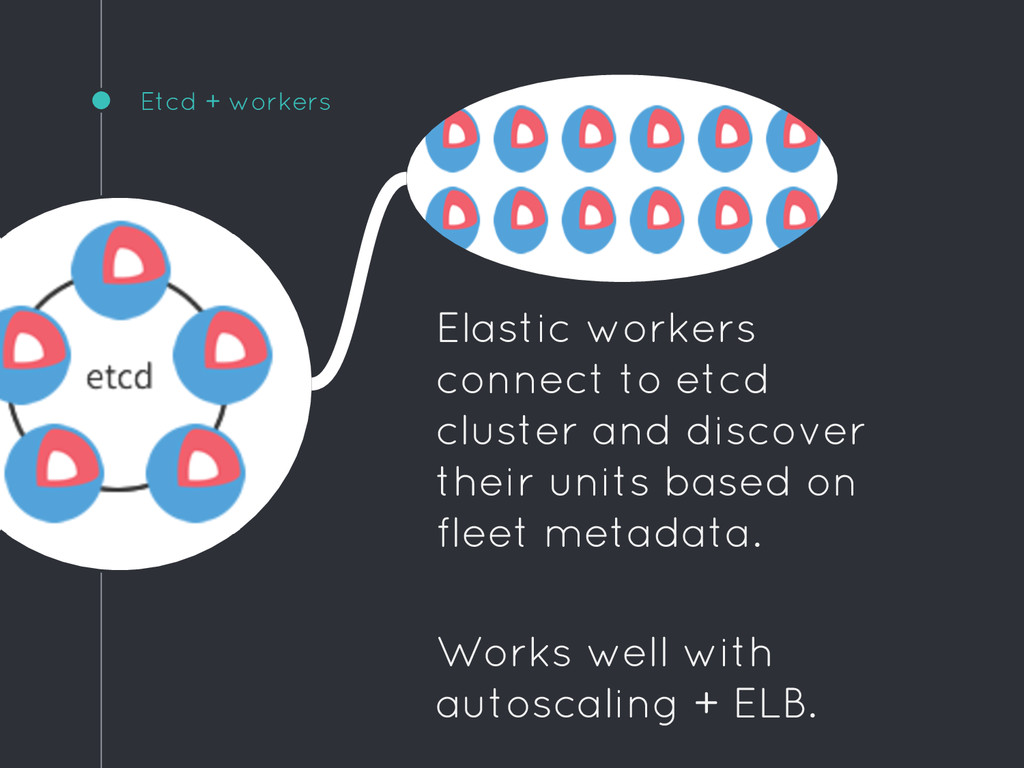
will reschedule units. Fleet submits systemd unit files to the cluster, using etcd as backing-store. Fleet-specific metadata controls scheduling of units.
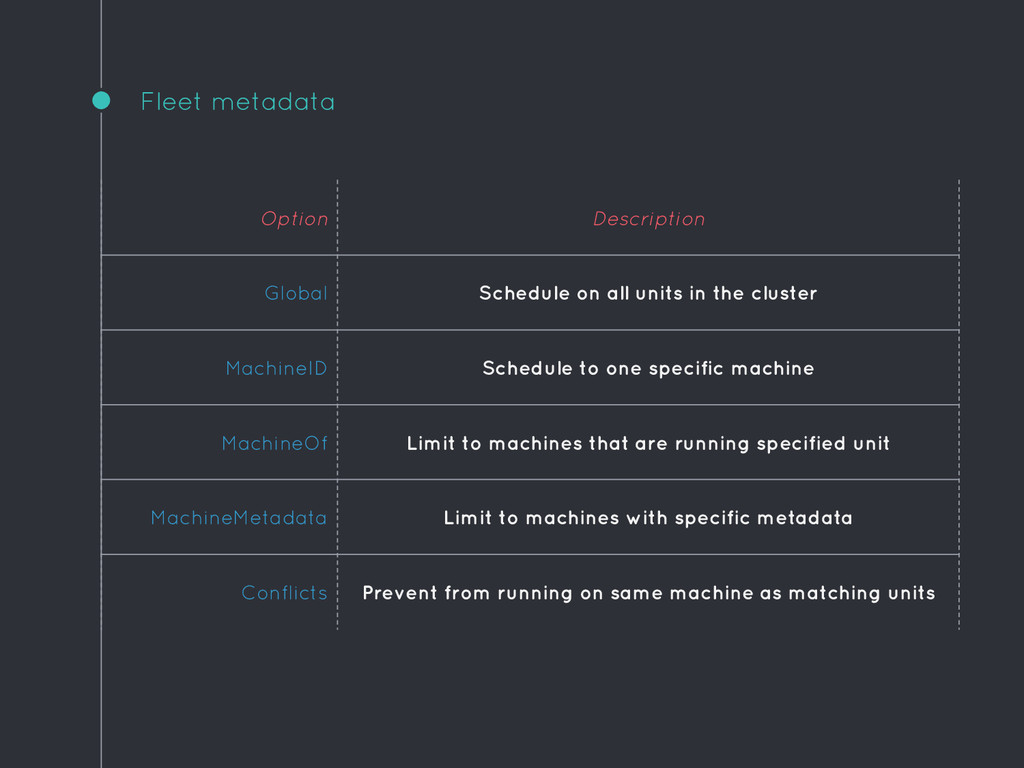
the cluster MachineID Schedule to one specific machine MachineOf Limit to machines that are running specified unit MachineMetadata Limit to machines with specific metadata Conflicts Prevent from running on same machine as matching units
ExecStartPre=-/usr/bin/docker rm hello ExecStartPre=/usr/bin/docker pull busybox ExecStart=/usr/bin/docker run --name hello busybox /bin/sh -c "while true; do echo Hello World; sleep 1; done" ExecStop=/usr/bin/docker stop hello [X-Fleet] Conflicts=hello@* Ensure there is only one of these on each instance
it. • For global units this means the whole cluster. • Which means downtime. fleet gotchas Fleet does not do resource-based scheduling. • Intended as a low-level system to build more advanced systems on. When moving units around you must do discovery to route traffic. • For example sidekick patterns and etcd-aware proxies.
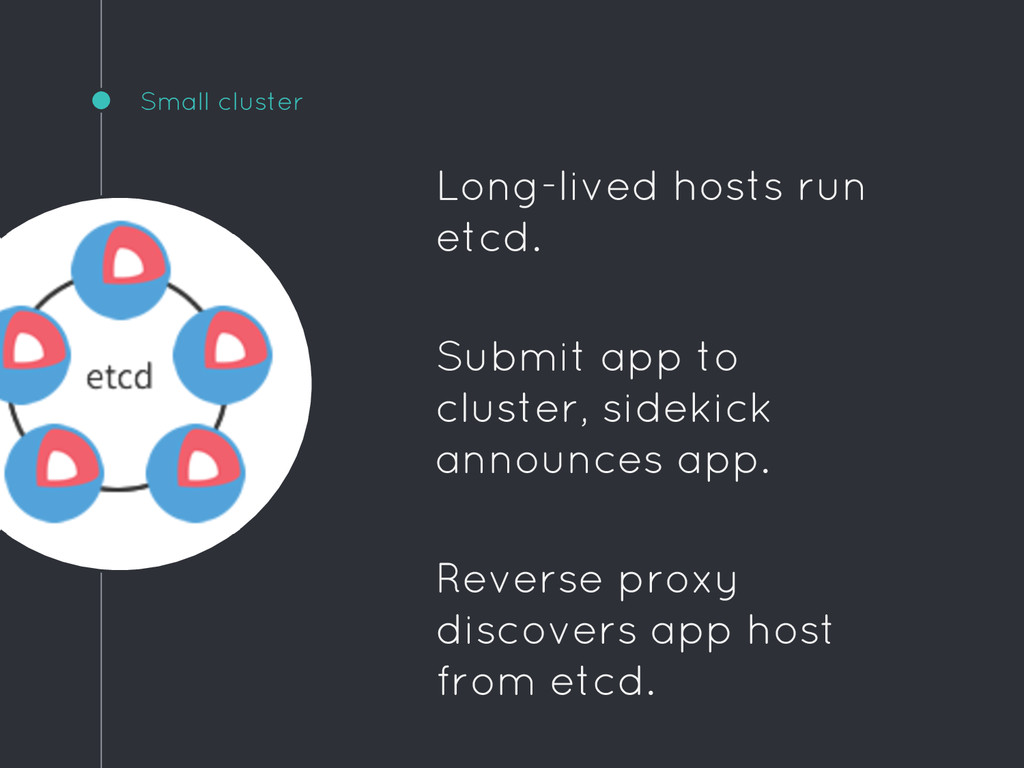
etcd. Sidekick unit sets etcd key for app container host:port when app starts. Write your own, calling etcdctl, or use something like github. com/gliderlabs/registrator Reverse proxy or load-balancer container listens for changes in etcd keys. Reconfigures to proxy to app host:port. Write config files with github. com/kelseyhightower/confd, or use etcd-specific proxy like github.com/mailgun/vulcand
high-traffic cluster of micro-services that demands very high availability and strict change control. Systemd units are hard-coded into cloud-config with user- data. Demands some orchestration such as autoscaling groups. 3
by changing launch config and replacing all hosts. Immutable servers with no etcd No etcd, no cluster. Workers spun up by autoscaling. Hard-code systemd units in launch config.
sophistication: ◦ Google’s Kubernetes ◦ Apache Mesos/Marathon ◦ paz.sh … PaaS based-on CoreOS ◦ Deis … private heroku-like on CoreOS It seems like something new pops up every day at the moment ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example unit [Unit] Description=Hello world After=docker.service Requires=docker.service [Service] TimeoutStartSec=0 ExecStartPre=-/usr/bin/docker](https://files.speakerdeck.com/presentations/a8024e1a816d4174bcb7984956685e9c/slide_24.jpg){kind=link}
{kind=link}
![Example global unit [Unit] Description=Hello world After=docker.service Requires=docker.service [Service] TimeoutStartSec=0](https://files.speakerdeck.com/presentations/a8024e1a816d4174bcb7984956685e9c/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example template unit [Unit] Description=Hello world After=docker.service Requires=docker.service [Service] TimeoutStartSec=0](https://files.speakerdeck.com/presentations/a8024e1a816d4174bcb7984956685e9c/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}