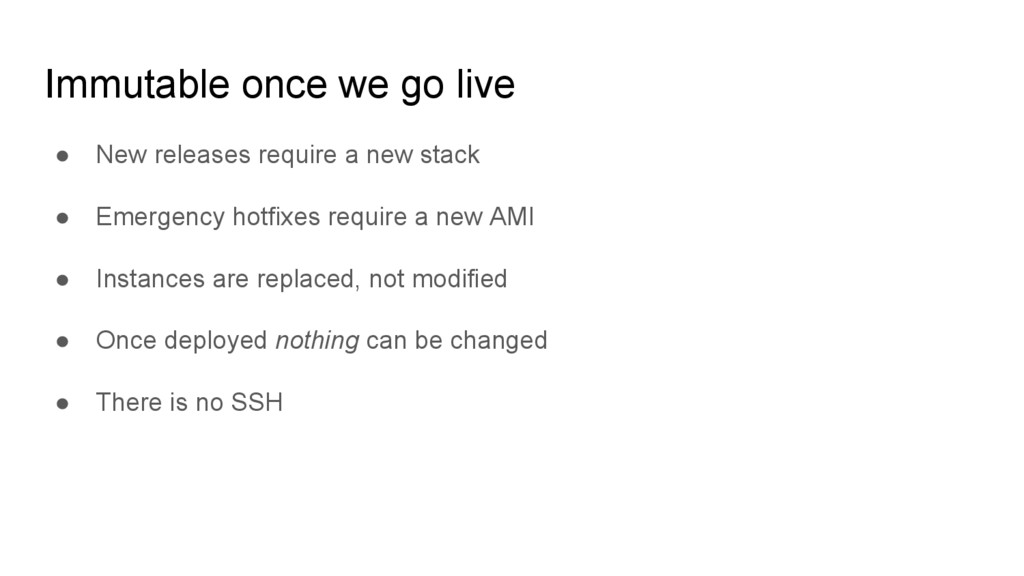
stability at the expense of speed ◦ Whatever solution we come up with it will just slow us down • Intervals between deployments ◦ The longer we go between deploys, the more worried we are about the next one ◦ Migrations are more likely to fail ◦ We’re only making the problem worse by delaying our deployments
from the “Real World” ◦ Application behavior ◦ User behavior • Let’s figure out a way to eliminate those differences • No more surprises when we deploy!
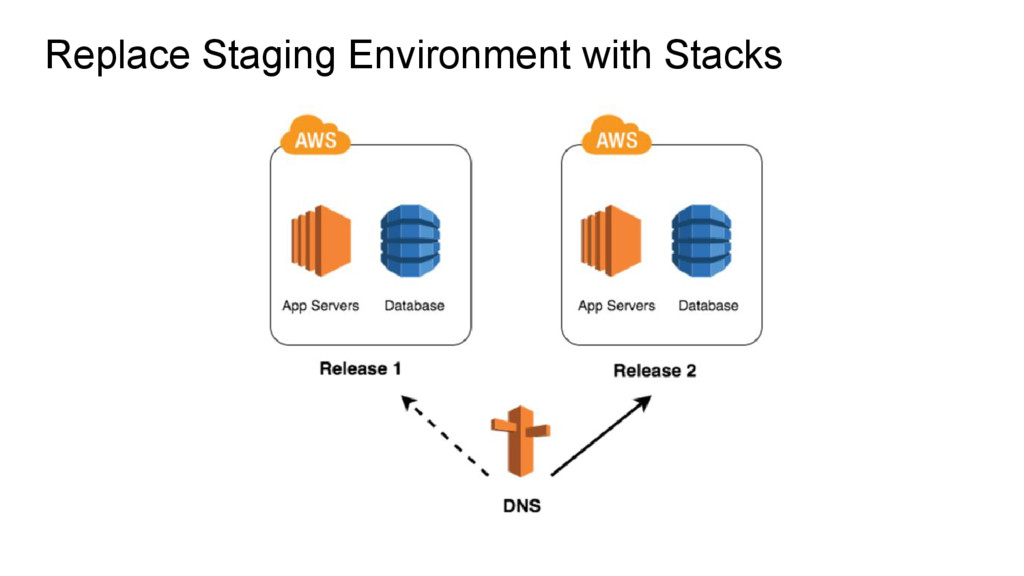
done as a self-contained “stack” • No more staging environment • No more RAILS_ENV • Think release candidate for your infrastructure • No more surprises based on real world data
massive amounts of data • Test data and live customer data can peacefully co-exist • Use a test attribute to identify our test records • Everything lives together in a single database!
Spree • Really slow when doing a lot of writes • Use Plain Old Ruby Objects (PORO) instead • All of our tables have the same structure ◦ store_id ◦ object_id ◦ object_value
for developers • Only the store owner change their own data • No super admin • Impossible for developers to change data while testing • Ensure no real world side effects whenever we write data
complete database copy • Migrations are performed at the same time as copy • Shoryuken workers for multi-threaded processing • We can copy 500,000 records in under ten minutes
bulk copy • DynamoDB streams to monitor these changes • New data is continuously migrated • Same migration logic as with bulk copy • No more migrations on release day!
change-controlled and repeatable • Operations source-code is in same git repo as application code • Every release is tracked as a single SHA in Github • Check out a SHA to get a fully self-contained ops+app setup • We use AWS Cloudformation templates to describe all resources
the underlying OS, which just provides: ◦ Kernel ◦ Docker daemon ◦ Systemd, to start containers • We are safer making OS updates ◦ Updates to system libraries do not affect application
◦ We get the same artifact every time • What if Docker repository goes down? ◦ Create AMI with packer and bake in all docker images ◦ We’re happy to trade AMI build time for stability • What if Github or rubygems are down? ◦ Instance needs no external information to start app
day - just not to production ◦ Devs get a stack for each feature branch, with a full copy of production data ◦ Go crazy, break things, it will be entirely deleted when done • Docker lets us build image fast ◦ We don’t want to wait for a brand new AMI with each commit ◦ Write Dockerfile to use caching in a smart way • Dev stacks can be deployed by just replacing docker image
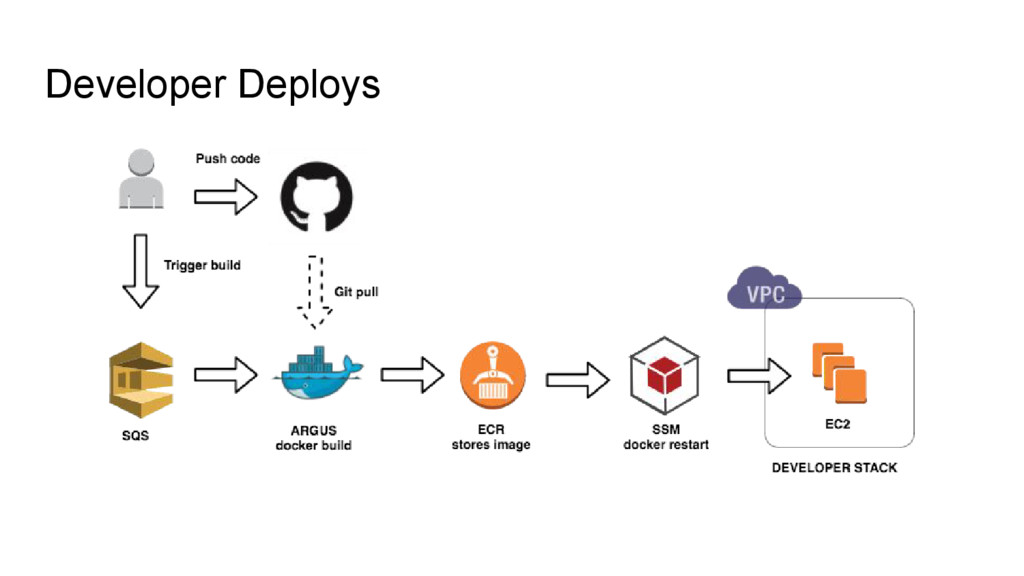
SQS • Distributed workers for fast builds • Workers pre-pull existing image layers • This means all workers can use docker cache • Pushes image to AWS EC2 Container Registry github.com/rlister/argus
docker build takes about 15 seconds • AWS SSM Run Command runs a canned script • Simply pulls latest docker image and restarts container • Access is controlled with IAM • Logs are in logstash
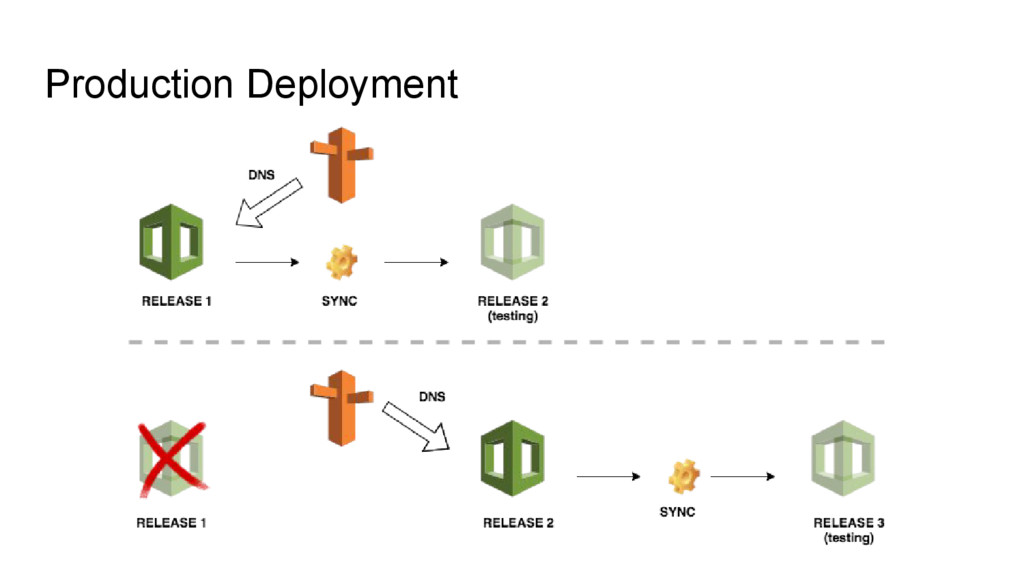
• The stack is immutable • We use stacks instead of a having a special staging environment • We use a complete copy of real world data in our stacks • We’re constantly deploying - just not to production • Production deploys are just updating the DNS to the new stack
- asynchronous Ruby workers with SQS • github.com/rlister/argus - fast Docker build and push to ECR • github.com/rlister/awful - Ruby library for common stack operations • github.com/seanedwards/cfer - Ruby DSL for Cloudformation templates • 12factor.net - guidelines for stateless software as a service
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}