Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Data at the Speed of your Users
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Rustam Aliyev
September 26, 2014
Technology
80
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Data at the Speed of your Users
Apache Cassandra and Spark for simple, distributed, near real-time stream processing.
Rustam Aliyev
September 26, 2014
More Decks by Rustam Aliyev
See All by Rustam Aliyev
From monolith web app to micro-frontends
rstml
0
960
Lightning Fast Analytics with Spark and Cassandra
rstml
2
320
Deep dive into CQL
rstml
1
69
Other Decks in Technology
See All in Technology
Kiro Ambassador を目指す話
k_adachi_01
0
130
新しいUbuntu/GNOMEが使いたいからXからWaylandへ移行頑張ってるの巻 2026-06-20
nobutomurata
0
160
Deep Data Security 機能解説
oracle4engineer
PRO
2
110
Bucharest Tech Week 2026 - Guardians of the Cloud-Native Galaxy
edeandrea
PRO
0
140
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
1
1.1k
Claude Codeをどのように キャッチアップしているか
oikon48
13
8.8k
入門!AWS Blocks
ysuzuki
1
190
SteampipeとExcel Power QueryでAWS構成定義書の作成を自動化する
jhashimoto
0
180
Microsoft のサポートとフィードバック総まとめ
murachiakira
PRO
0
110
WebGIS AI Agentの紹介
_shimizu
0
560
AIチャットの改善から見えた、良いAI体験とは / What Constitutes a Good AI Experience: Insights from Improving AI Chat
kubode
0
120
FPC(フレキシブル)基板にZephyr実装してみた。
iotengineer22
0
170
Featured
See All Featured
BBQ
matthewcrist
89
10k
The agentic SEO stack - context over prompts
schlessera
0
820
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
GraphQLとの向き合い方2022年版
quramy
50
15k
Leo the Paperboy
mayatellez
7
1.9k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
560
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Believing is Seeing
oripsolob
1
150
Six Lessons from altMBA
skipperchong
29
4.3k
Mobile First: as difficult as doing things right
swwweet
225
10k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
180
Transcript
Data at the Speed of your Users Apache Cassandra and
Spark for simple, distributed, near real-time stream processing. GOTO Copenhagen 2014
Rustam Aliyev Solution Architect at . ! ! @rstml
Big Data? Photo: Flickr / Watches En Masse
" Volume # Variety $ Velocity
Velocity = Near Real Time
Near Real Time?
0.5 sec ≤ ≤ 60 sec Near Real Time
Use Cases Photo: Flickr / Swiss Army / Jim Pennucci
Web Analytics Dynamic Pricing Recommendation Fraud Detection
Architecture Photo: Ilkin Kangarli / Baku Haydar Aliyev Center
Architecture Goals Low Latency High Availability Horizontal Scalability Simplicity
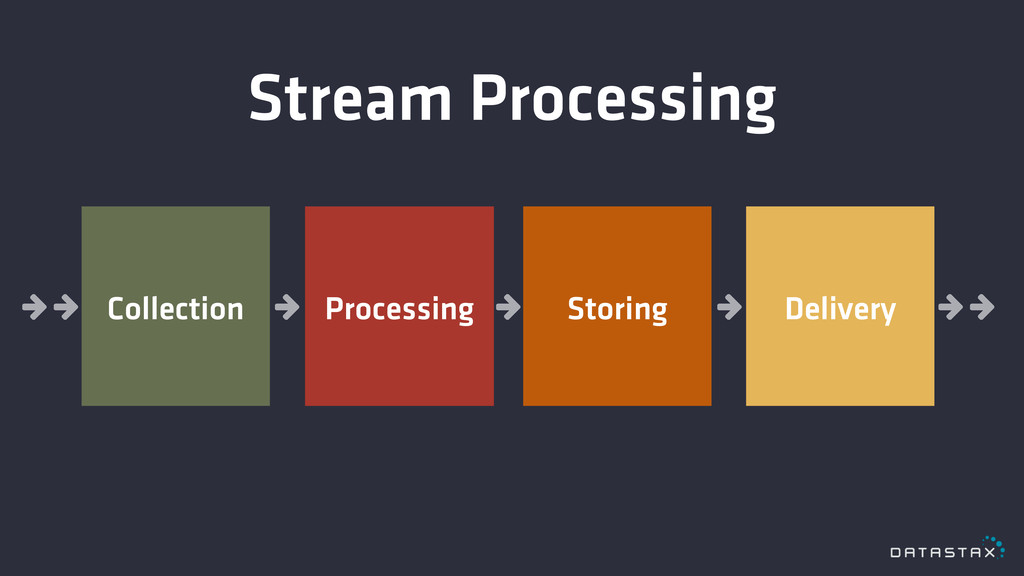
Stream Processing % % % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % Collection Processing Storing Delivery
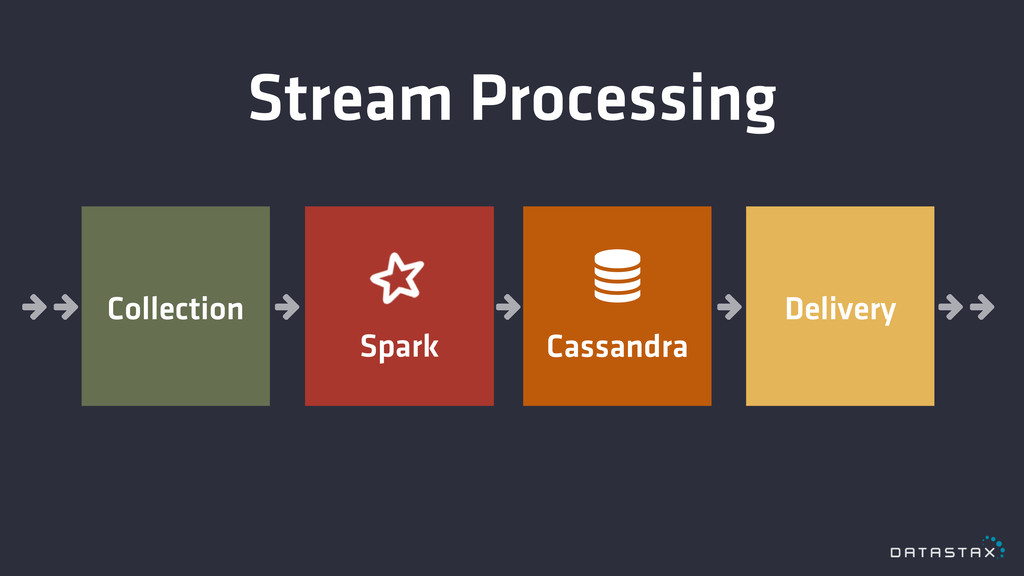
Stream Processing % % % % % % % %
% % % % % % % % % % % % % % % % % % % % % % % Collection ! ! Spark ! Cassandra Delivery
Cassandra Distributed Database Photo: Flickr / Hypostyle Hall / Jorge
Láscar
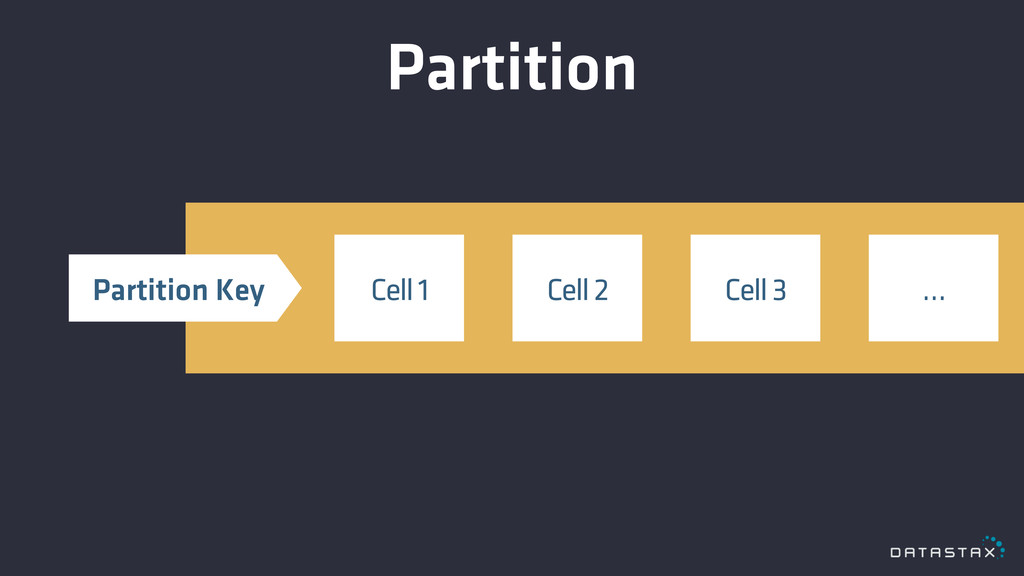
Data Model
Partition Cell 1 Cell 2 … Cell 3 Partition Key
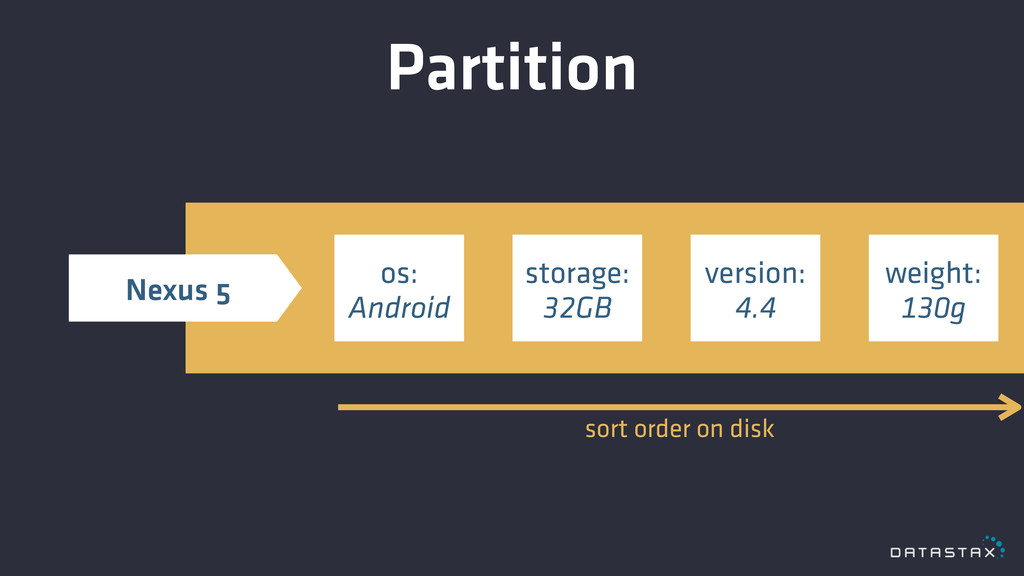
Partition os: Android storage: 32GB version: 4.4 weight: 130g sort
order on disk Nexus 5
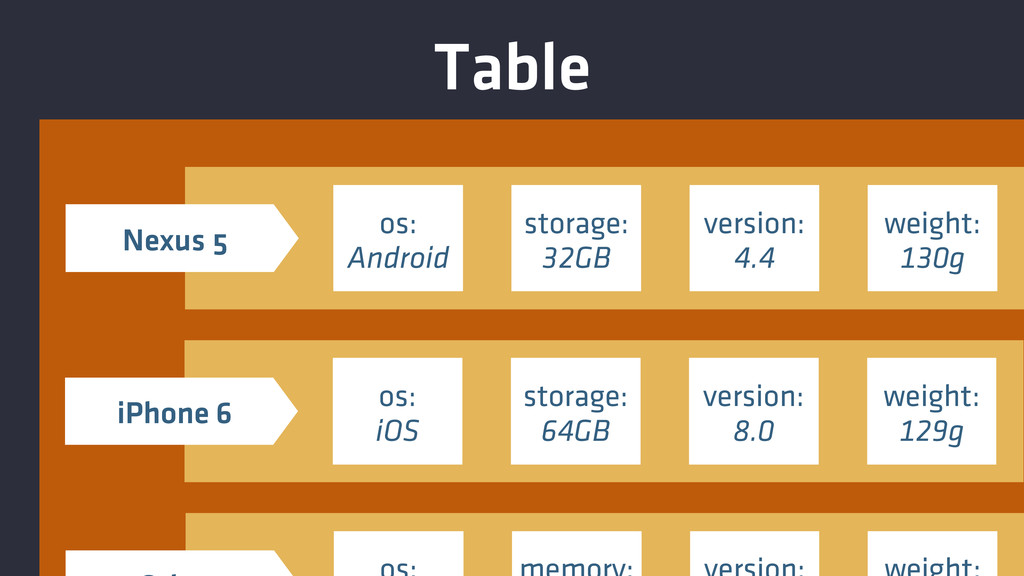
Table os: Android storage: 32GB version: 4.4 weight: 130g Nexus
5 os: iOS storage: 64GB version: 8.0 weight: 129g iPhone 6
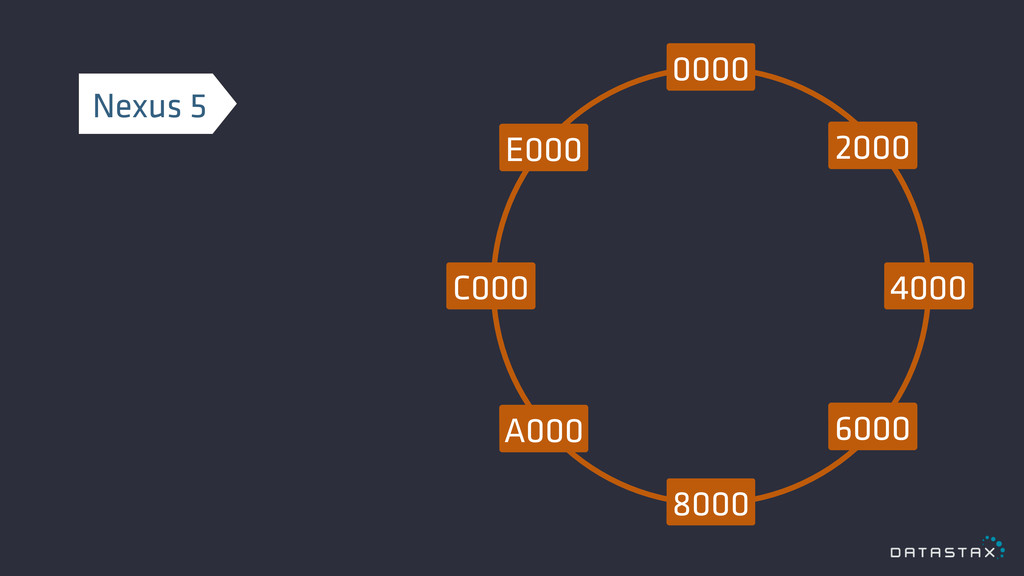
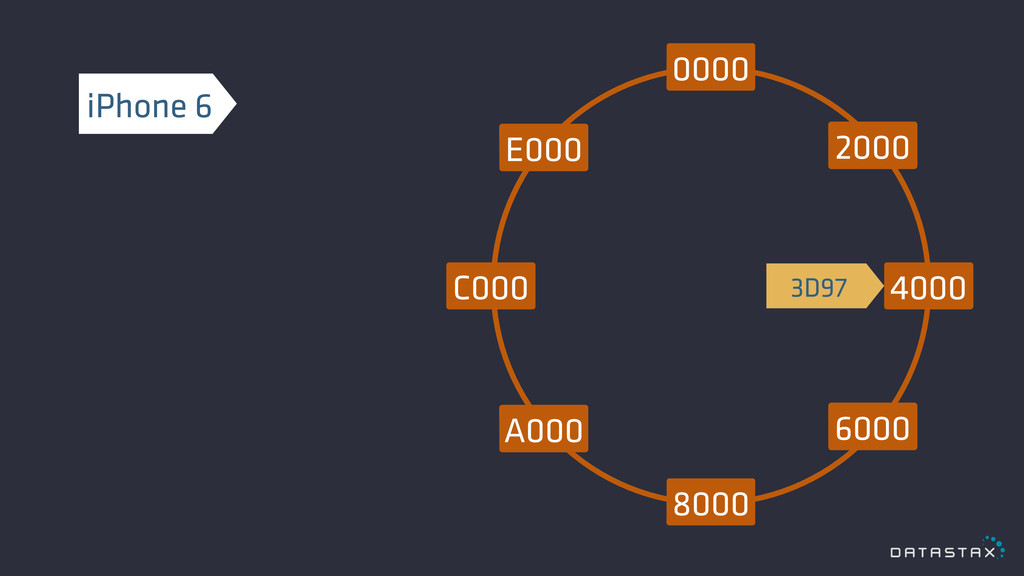
Distribution
0000 8000 4000 C000 2000 6000 E000 A000 3D97 Nexus
5
0000 8000 4000 C000 2000 6000 E000 A000 9C4F iPhone
6 3D97
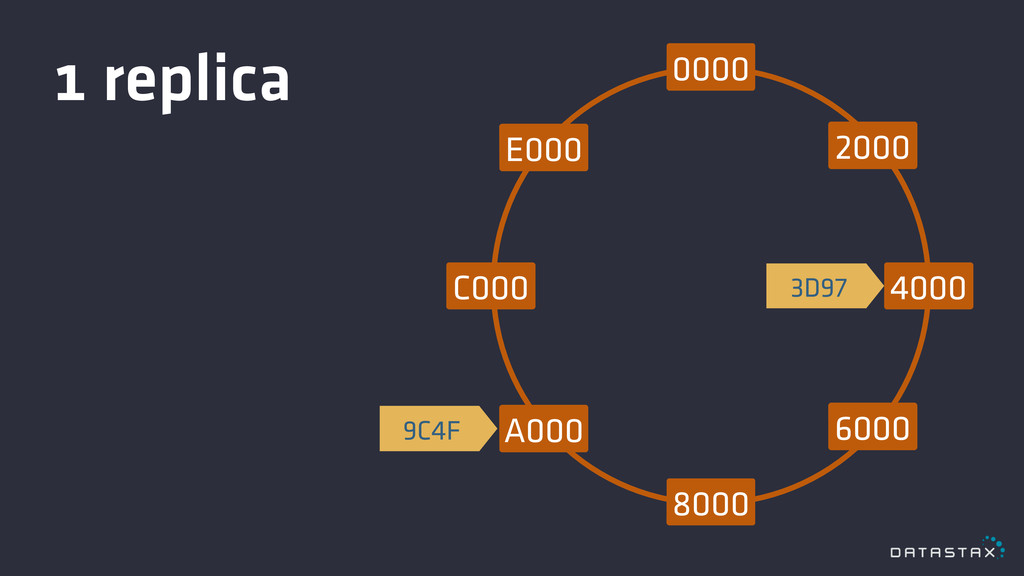
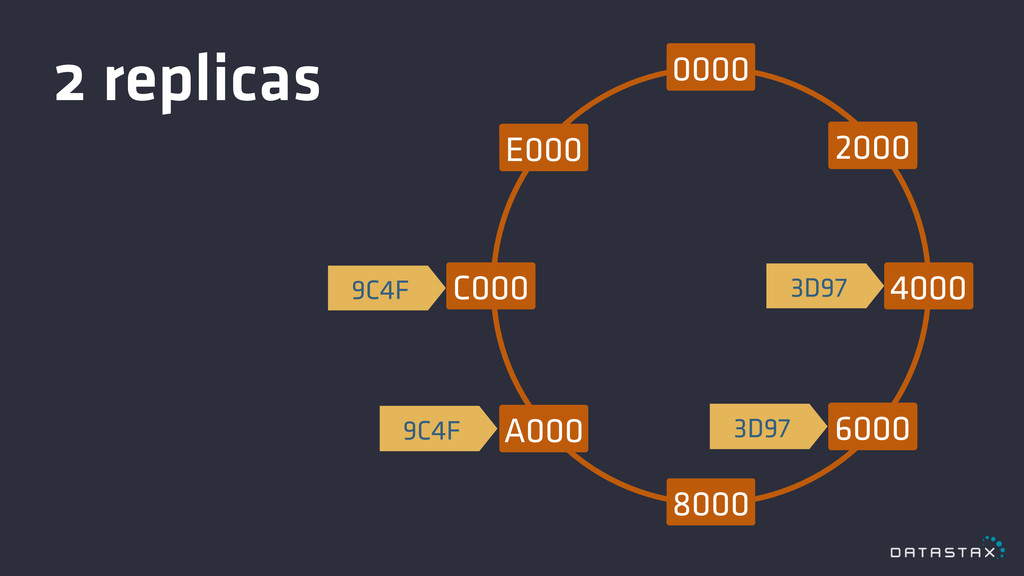
Replication
0000 8000 4000 C000 2000 6000 E000 A000 3D97 9C4F
1 replica
0000 8000 4000 C000 2000 6000 E000 A000 3D97 9C4F
9C4F 3D97 2 replicas
Spark Distributed Data Processing Engine Photo: Flickr / Sparklers /
Alexandra Compo / CreativeCommons
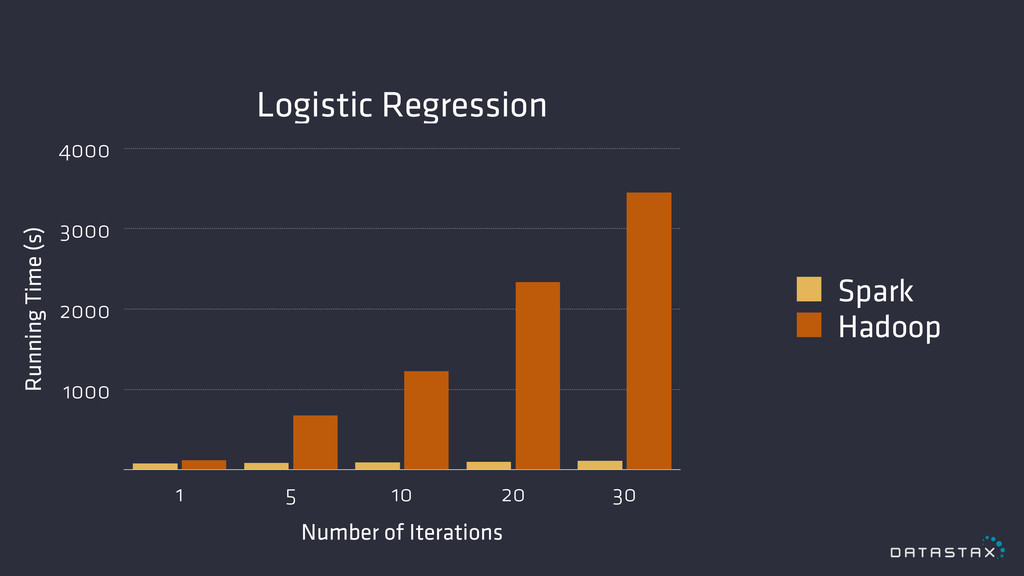
Fast In-memory
Logistic Regression Running Time (s) 1000 2000 3000 4000 Number
of Iterations 1 5 10 20 30 Spark Hadoop
Easy
map ! reduce
map filter groupBy sort union join leftOuterJoin rightOuterJoin reduce count
fold reduceByKey groupByKey cogroup cross zip sample take first partitionBy mapWith pipe save ...
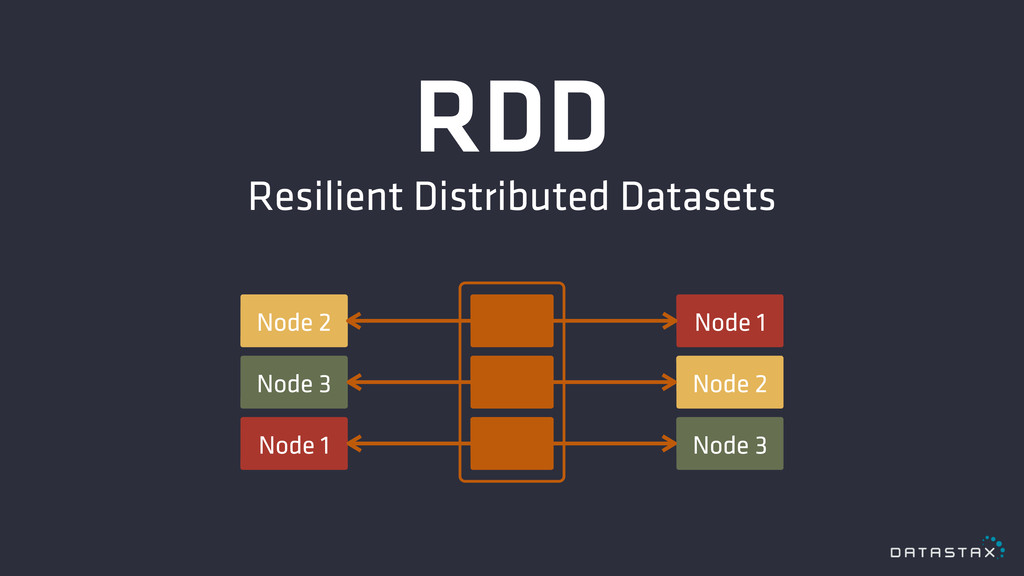
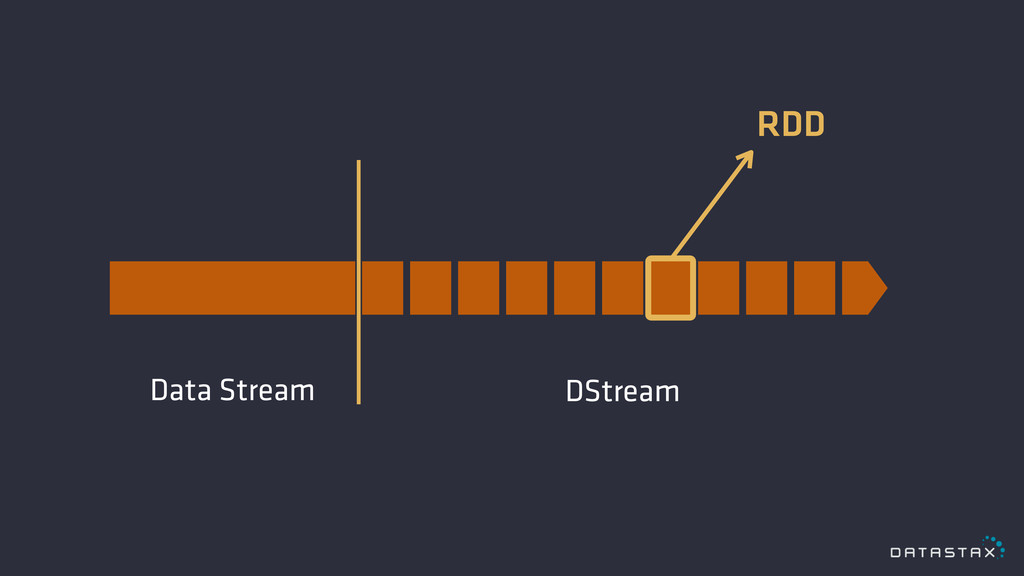
RDD Resilient Distributed Datasets Node 1 Node 2 Node 3
Node 1 Node 2 Node 3
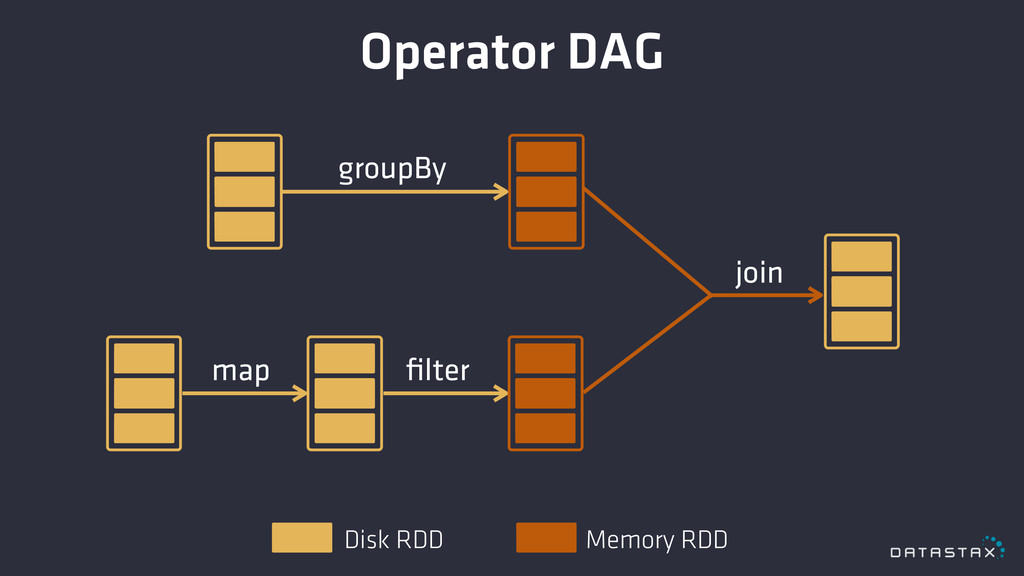
Operator DAG groupBy join filter map Disk RDD Memory RDD
Spark Streaming Micro-batching
RDD DStream Data Stream
Spark + Cassandra DataStax Spark Cassandra Connector
https://github.com/datastax/spark-cassandra-connector
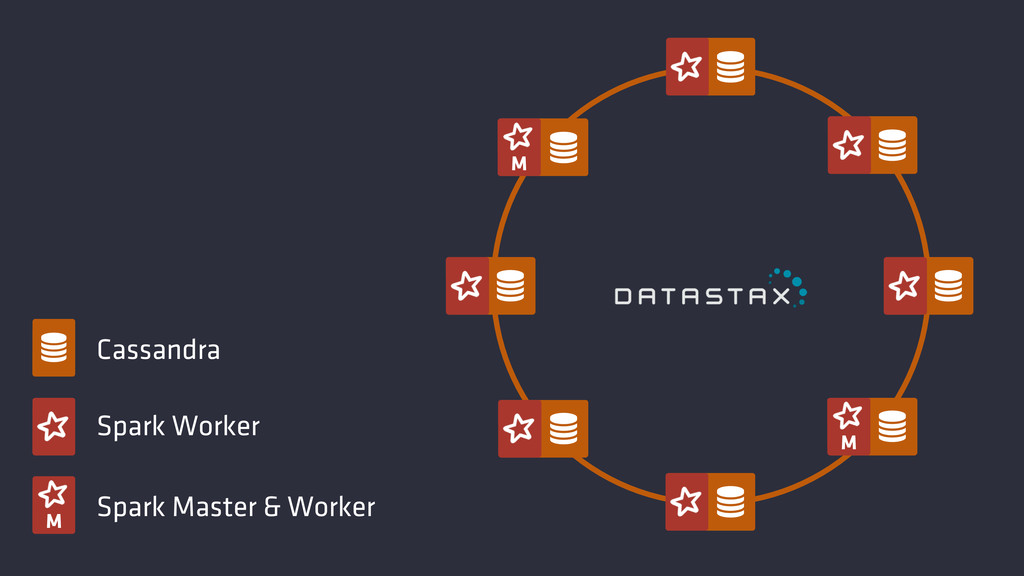
M M
M Cassandra Spark Worker Spark Master & Worker
Demo ! ! Twitter Analytics
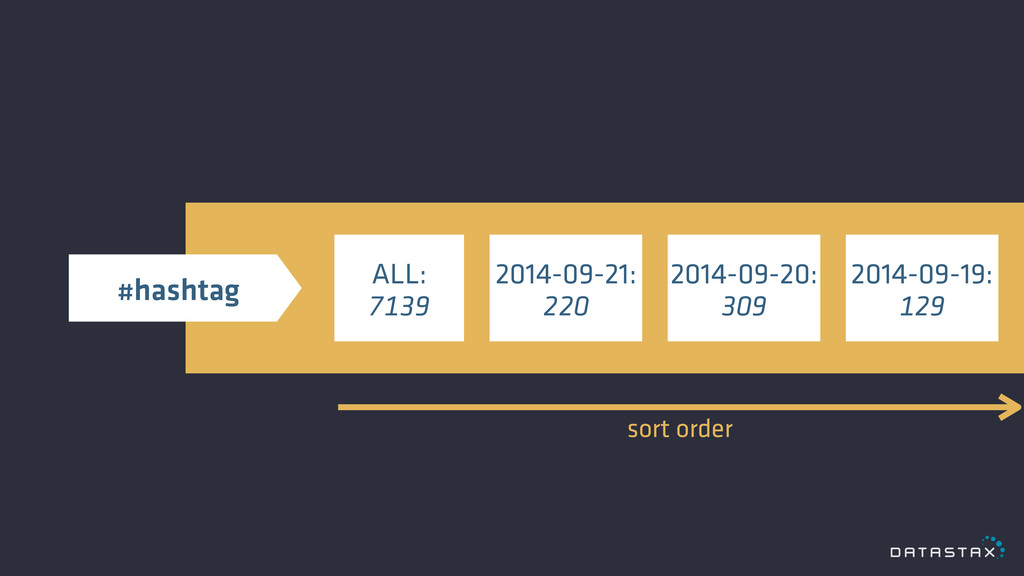
Cassandra Data Model
ALL: 7139 2014-09-21: 220 2014-09-20: 309 2014-09-19: 129 sort order
#hashtag
CREATE TABLE hashtags ( hashtag text,
interval text, mentions counter, PRIMARY KEY((hashtag), interval) ) WITH CLUSTERING ORDER BY (interval DESC);
Processing Data Stream
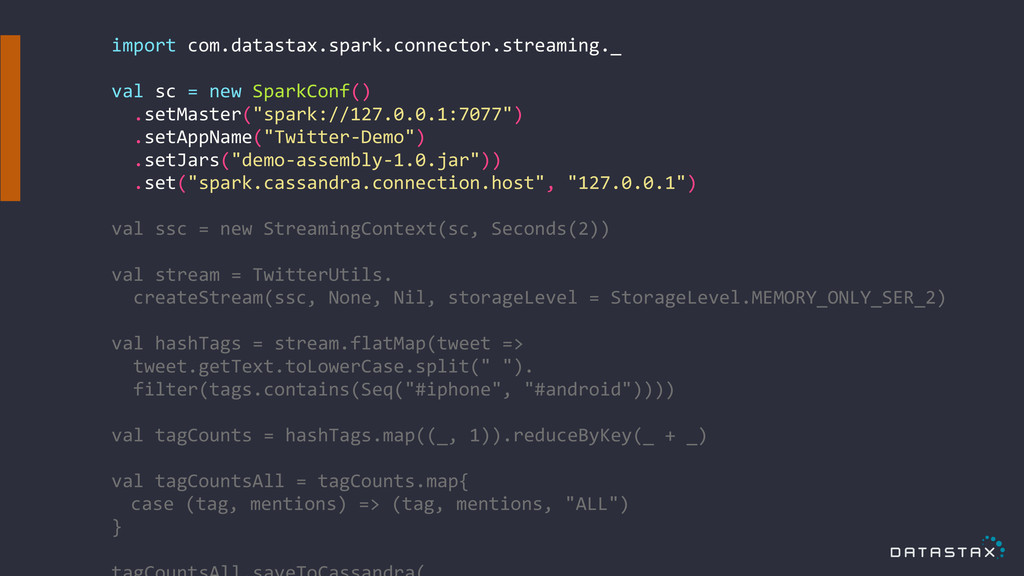
import com.datastax.spark.connector.streaming._ ! val sc = new SparkConf()
.setMaster("spark://127.0.0.1:7077") .setAppName("Twitter-‐Demo") .setJars("demo-‐assembly-‐1.0.jar")) .set("spark.cassandra.connection.host", "127.0.0.1") ! val ssc = new StreamingContext(sc, Seconds(2)) ! val stream = TwitterUtils. createStream(ssc, None, Nil, storageLevel = StorageLevel.MEMORY_ONLY_SER_2) ! val hashTags = stream.flatMap(tweet => tweet.getText.toLowerCase.split(" "). filter(tags.contains(Seq("#iphone", "#android")))) ! val tagCounts = hashTags.map((_, 1)).reduceByKey(_ + _) ! val tagCountsAll = tagCounts.map{ case (tag, mentions) => (tag, mentions, "ALL") } !
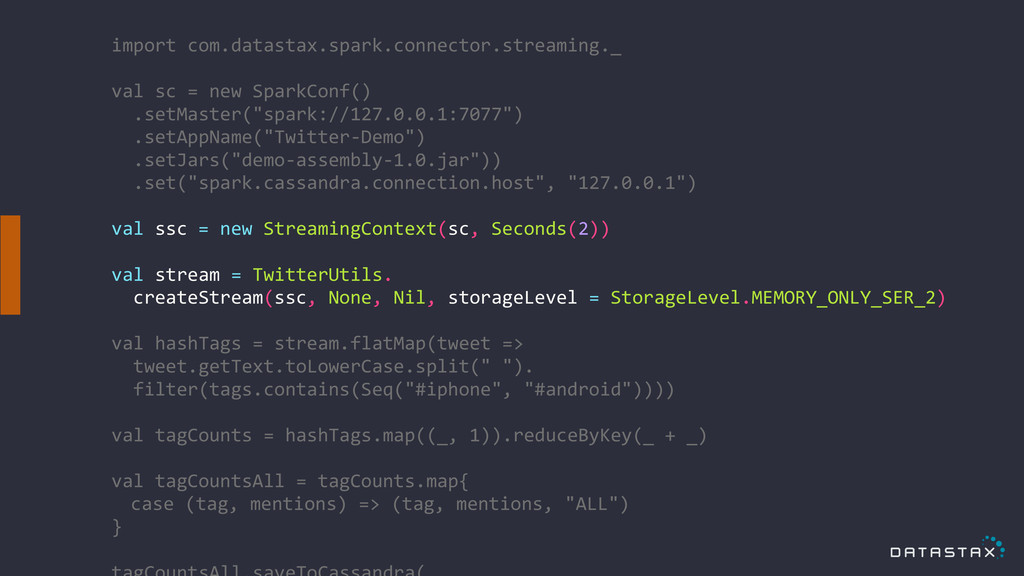
import com.datastax.spark.connector.streaming._ ! val sc = new SparkConf()
.setMaster("spark://127.0.0.1:7077") .setAppName("Twitter-‐Demo") .setJars("demo-‐assembly-‐1.0.jar")) .set("spark.cassandra.connection.host", "127.0.0.1") ! val ssc = new StreamingContext(sc, Seconds(2)) ! val stream = TwitterUtils. createStream(ssc, None, Nil, storageLevel = StorageLevel.MEMORY_ONLY_SER_2) ! val hashTags = stream.flatMap(tweet => tweet.getText.toLowerCase.split(" "). filter(tags.contains(Seq("#iphone", "#android")))) ! val tagCounts = hashTags.map((_, 1)).reduceByKey(_ + _) ! val tagCountsAll = tagCounts.map{ case (tag, mentions) => (tag, mentions, "ALL") } !
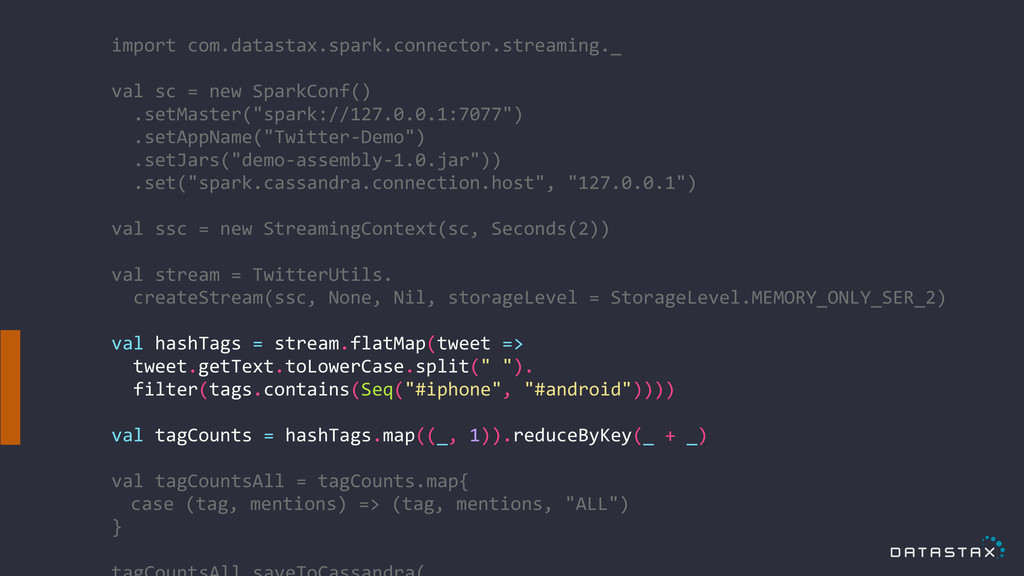
import com.datastax.spark.connector.streaming._ ! val sc = new SparkConf()
.setMaster("spark://127.0.0.1:7077") .setAppName("Twitter-‐Demo") .setJars("demo-‐assembly-‐1.0.jar")) .set("spark.cassandra.connection.host", "127.0.0.1") ! val ssc = new StreamingContext(sc, Seconds(2)) ! val stream = TwitterUtils. createStream(ssc, None, Nil, storageLevel = StorageLevel.MEMORY_ONLY_SER_2) ! val hashTags = stream.flatMap(tweet => tweet.getText.toLowerCase.split(" "). filter(tags.contains(Seq("#iphone", "#android")))) ! val tagCounts = hashTags.map((_, 1)).reduceByKey(_ + _) ! val tagCountsAll = tagCounts.map{ case (tag, mentions) => (tag, mentions, "ALL") } !
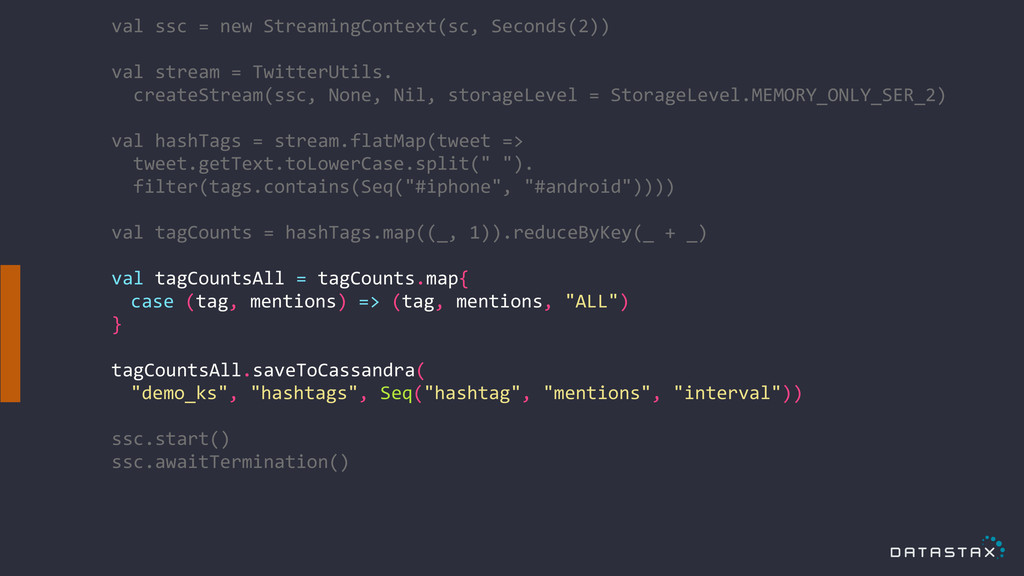
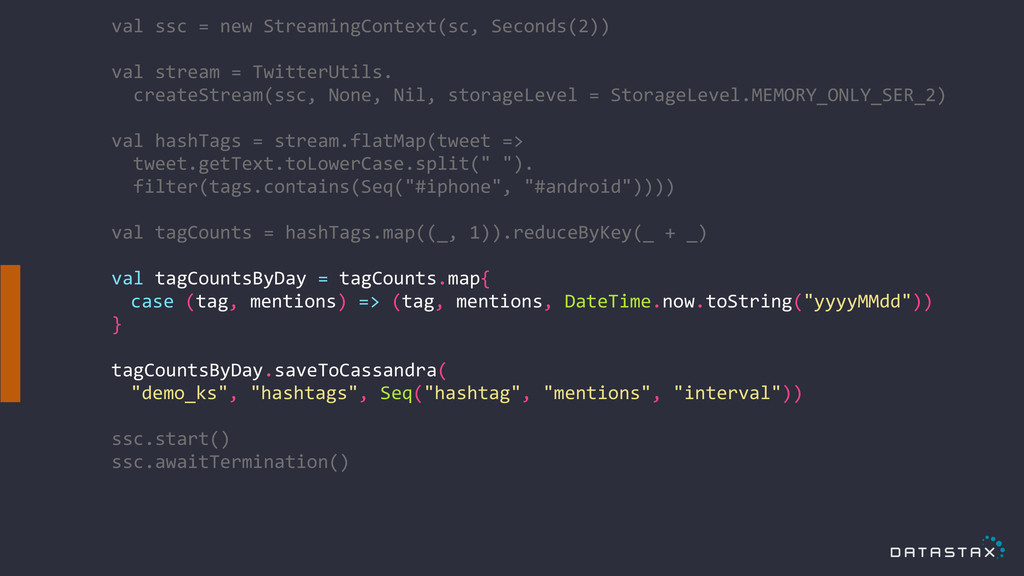
! val ssc = new StreamingContext(sc, Seconds(2)) ! val
stream = TwitterUtils. createStream(ssc, None, Nil, storageLevel = StorageLevel.MEMORY_ONLY_SER_2) ! val hashTags = stream.flatMap(tweet => tweet.getText.toLowerCase.split(" "). filter(tags.contains(Seq("#iphone", "#android")))) ! val tagCounts = hashTags.map((_, 1)).reduceByKey(_ + _) ! val tagCountsAll = tagCounts.map{ case (tag, mentions) => (tag, mentions, "ALL") } ! tagCountsAll.saveToCassandra( "demo_ks", "hashtags", Seq("hashtag", "mentions", "interval")) ! ssc.start() ssc.awaitTermination()
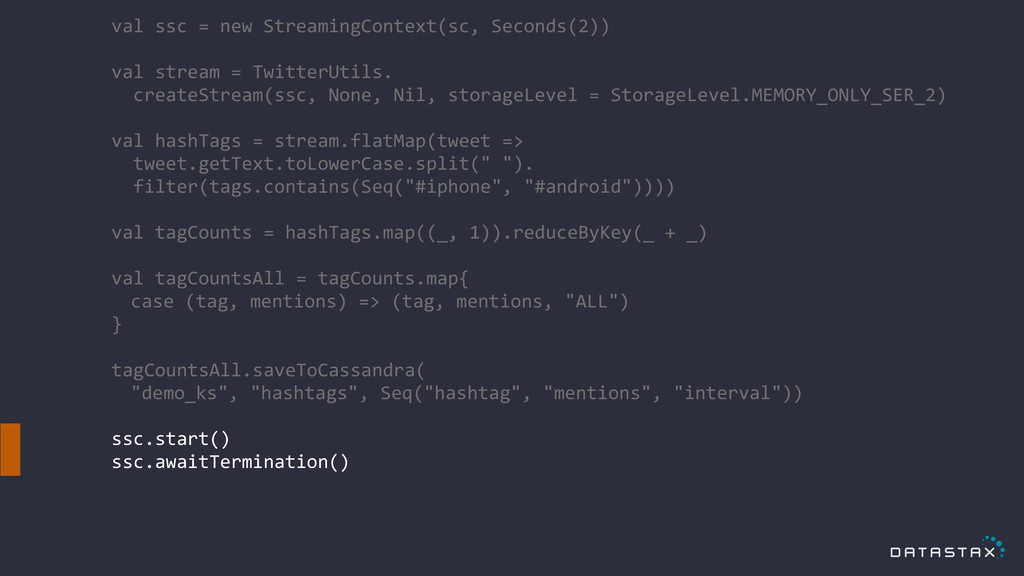
! val ssc = new StreamingContext(sc, Seconds(2)) ! val
stream = TwitterUtils. createStream(ssc, None, Nil, storageLevel = StorageLevel.MEMORY_ONLY_SER_2) ! val hashTags = stream.flatMap(tweet => tweet.getText.toLowerCase.split(" "). filter(tags.contains(Seq("#iphone", "#android")))) ! val tagCounts = hashTags.map((_, 1)).reduceByKey(_ + _) ! val tagCountsByDay = tagCounts.map{ case (tag, mentions) => (tag, mentions, DateTime.now.toString("yyyyMMdd")) } ! tagCountsByDay.saveToCassandra( "demo_ks", "hashtags", Seq("hashtag", "mentions", "interval")) ! ssc.start() ssc.awaitTermination()
! val ssc = new StreamingContext(sc, Seconds(2)) ! val
stream = TwitterUtils. createStream(ssc, None, Nil, storageLevel = StorageLevel.MEMORY_ONLY_SER_2) ! val hashTags = stream.flatMap(tweet => tweet.getText.toLowerCase.split(" "). filter(tags.contains(Seq("#iphone", "#android")))) ! val tagCounts = hashTags.map((_, 1)).reduceByKey(_ + _) ! val tagCountsAll = tagCounts.map{ case (tag, mentions) => (tag, mentions, "ALL") } ! tagCountsAll.saveToCassandra( "demo_ks", "hashtags", Seq("hashtag", "mentions", "interval")) ! ssc.start() ssc.awaitTermination()
Questions ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}