Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
仮想マシンを用いた分散システムの耐故障性評価環境
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ryo Kanbayashi
September 30, 2024
0
6
仮想マシンを用いた分散システムの耐故障性評価環境
みんなで各自の卒研の内容を発表しようという謎の会があって、その時に使ったスライドのはず
Ryo Kanbayashi
September 30, 2024
Tweet
Share
More Decks by Ryo Kanbayashi
See All by Ryo Kanbayashi
誰でも情報通になれる人力情報収集プラットフォームGrapevinet
ryo_grid
0
26
私がチャレンジしたSBMデータマイニング
ryo_grid
0
6
SS2PLを採用しているSamehadaDBでのPhantom Read抑止ロジックの検討
ryo_grid
0
9
Featured
See All Featured
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
440
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
120
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Ethics towards AI in product and experience design
skipperchong
2
220
Imperfection Machines: The Place of Print at Facebook
scottboms
269
14k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
1
320
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
380
4 Signs Your Business is Dying
shpigford
187
22k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.2k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
0
450
Transcript
@ryo_gridの自己紹介 -- ぷろろーぐ -- 神林 亮 筑波大学第三学群情報学類4年
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 2
自己紹介 ◼筑波大学にAC入試で入学した学部4年生(新M1) ◼専門はハイパフォーマンスコンピューティング ◼物作りが大好き!! TOFU-G(グリッドミドルウェア) 高校時代の分散コンピューティングのプロジェクト
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 3
Webマイニング系もいろいろやってみた Kikker はてブおせっかい kookle はてブまわりのひと
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 4
Twitter系とか ひらめいったー
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 5
こんなブログも書いてます 見てね♪
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 6
今回の参加者との関係性 僕 @hayamizu 大学入学前ぐらい からの知り合い @yuyarin @gomi-box @skylab13 @Chiba_ken_min 東大クラスタ @hogelog T大忘年会 @daftbeats @syou6162 @blanc_et_noir 筑波クラスタ リア知り合い ネト〃 初めまして ・・・・・ 初めまして Disる
仮想マシンを用いた分散システムの 耐故障性評価環境 神林 亮 筑波大学第三学群情報学類 佐藤 三久 筑波大学大学院システム情報工学研究科 -- 本編
--
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 8
耐故障性評価の必要性 ◼ 分散システムへの耐故障性の要求 証券取引や銀行のトランザクション処理 高性能並列計算における計算処理の長時間化 システムを構成するソフトウェアはハードウェア故障が 発生しても動作を継続できる必要がある 実際に十分な耐故障性があるか評価する必要がある 耐故障性を高める手法が実装される ・宇宙線によるメモリ内容 やプロセッサ内情報の破壊 ・ハードディスク故障 ・ネットワーク故障 etc.
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 9
耐故障性評価における問題 ◼ 分散システムの耐故障性テストの困難さ ・故障を想定したテストコードを書く事は労力を要す ・分散システムなどでは故障の発生パターンも複雑化 適切なツールが存在しない
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 10
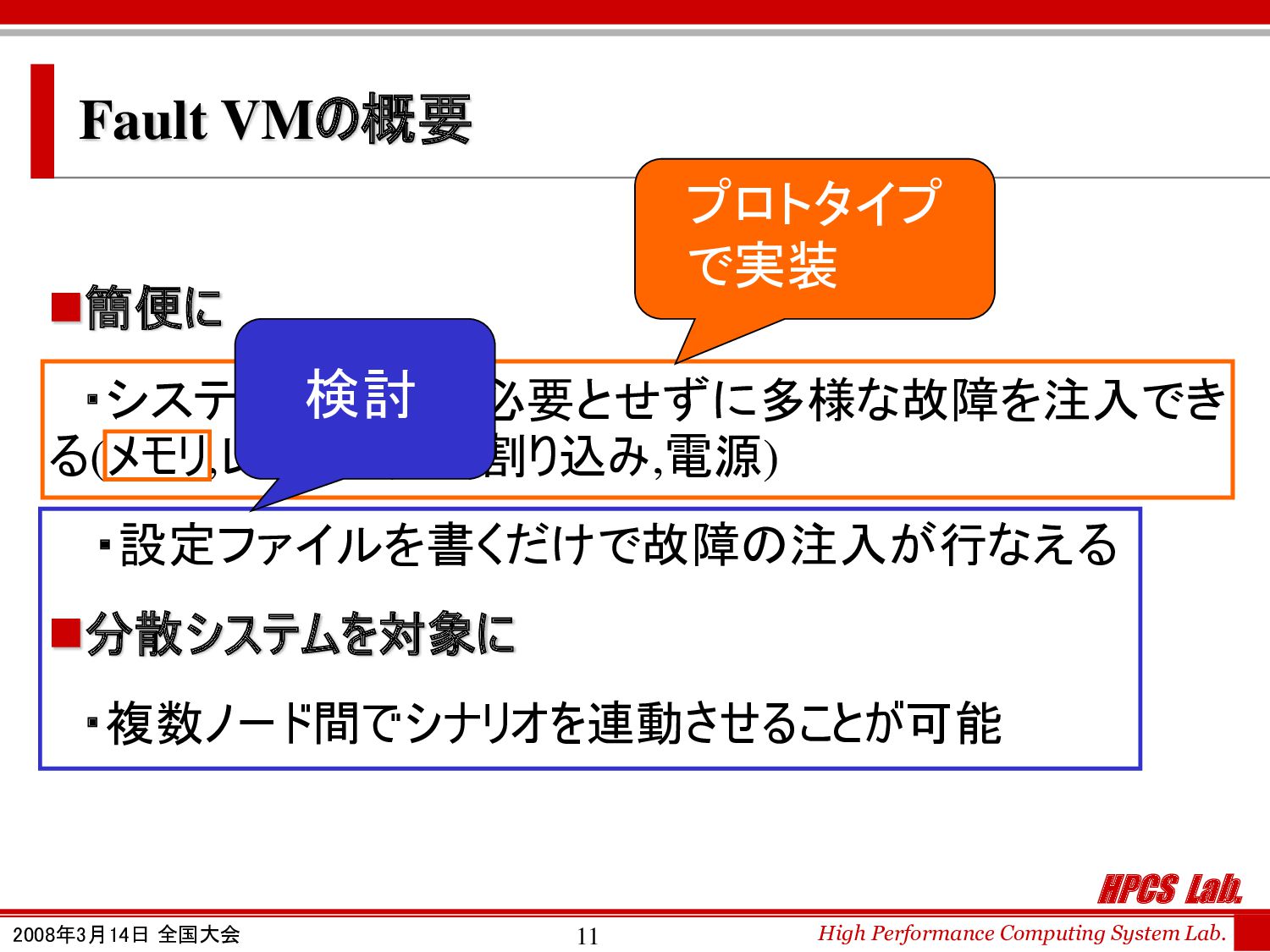
◼簡便に分散システムの耐故障性をテストするため のツールを設計・提案し,Fault VMを開発する. 研究の目的
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 11
Fault VMの概要 ◼簡便に ・システムの改変を必要とせずに多様な故障を注入でき る(メモリ,レジスタ,I/O,割り込み,電源) ・設定ファイルを書くだけで故障の注入が行なえる ◼分散システムを対象に ・複数ノード間でシナリオを連動させることが可能 プロトタイプ で実装 検討
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 12
・実ハードウェアの故障に見える ・故障後の状態観察が可能 ・システムのコードを改変せず に故障の注入が可能 ◼仮想マシンを用いてソフトウェア的に故障をエミュレートし挙動を観察 = フォルトインジェクタ Fault VMで用いる手法 Real Machine Fault VM OS Applications Applications Fault 概念図 簡便 OS
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 13
メモリ故障注入の概要 ◼ 評価作業用システムから評価対象システムにメモリ故障 を注入 ・メモリ内容のビットフリップをメモリ故障と定義 ・Xenを使用 ・評価作業用システムから評価対象 システムの仮想的な物理メモリを マップし書き込みを行う メモリ故障注入の様子
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 14
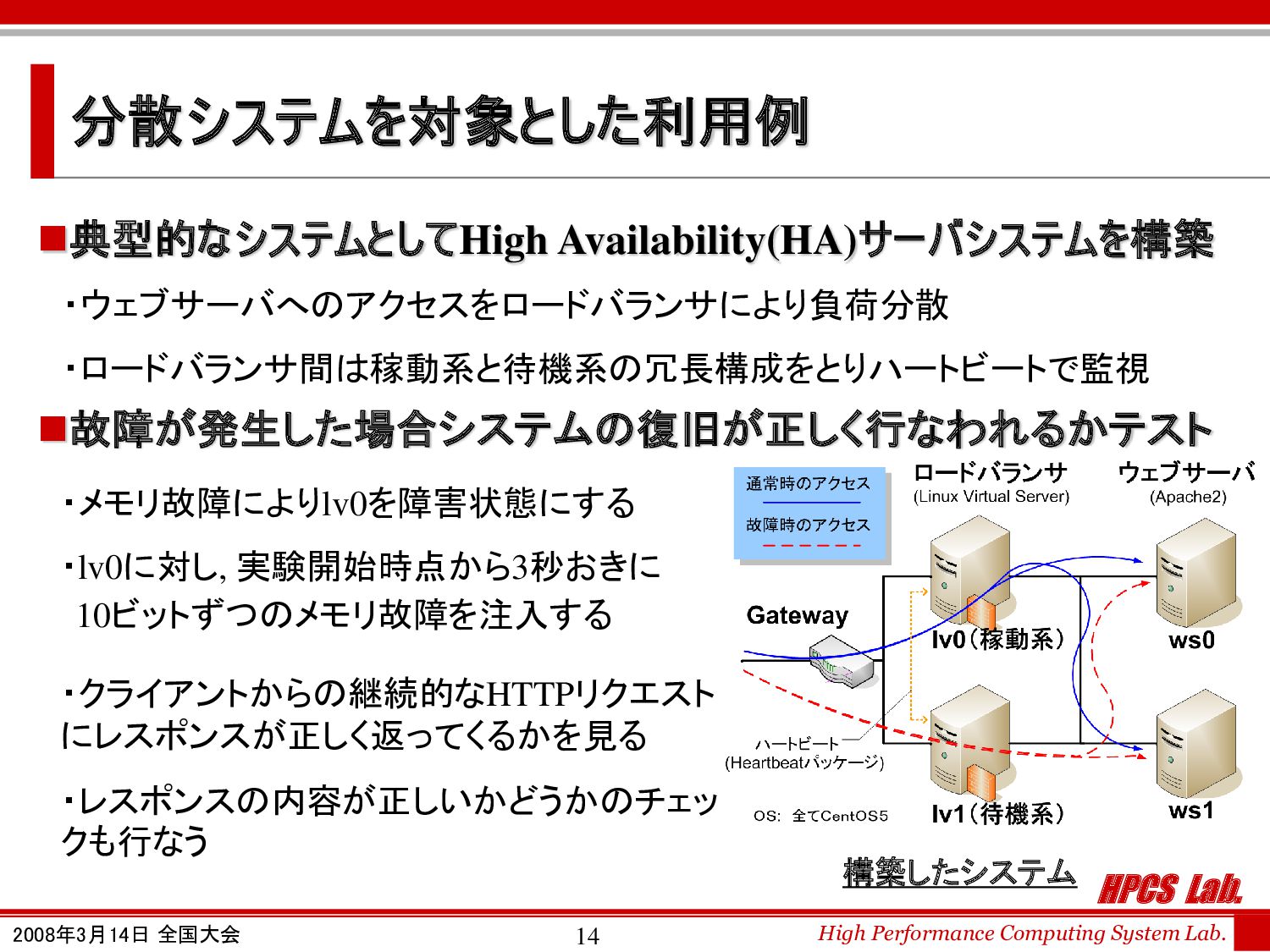
分散システムを対象とした利用例 ◼典型的なシステムとしてHigh Availability(HA)サーバシステムを構築 ・メモリ故障によりlv0を障害状態にする ・lv0に対し, 実験開始時点から3秒おきに ・クライアントからの継続的なHTTPリクエスト にレスポンスが正しく返ってくるかを見る ・レスポンスの内容が正しいかどうかのチェッ クも行なう ・ウェブサーバへのアクセスをロードバランサにより負荷分散 ・ロードバランサ間は稼動系と待機系の冗長構成をとりハートビートで監視 ◼故障が発生した場合システムの復旧が正しく行なわれるかテスト 10ビットずつのメモリ故障を注入する 構築したシステム
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 15
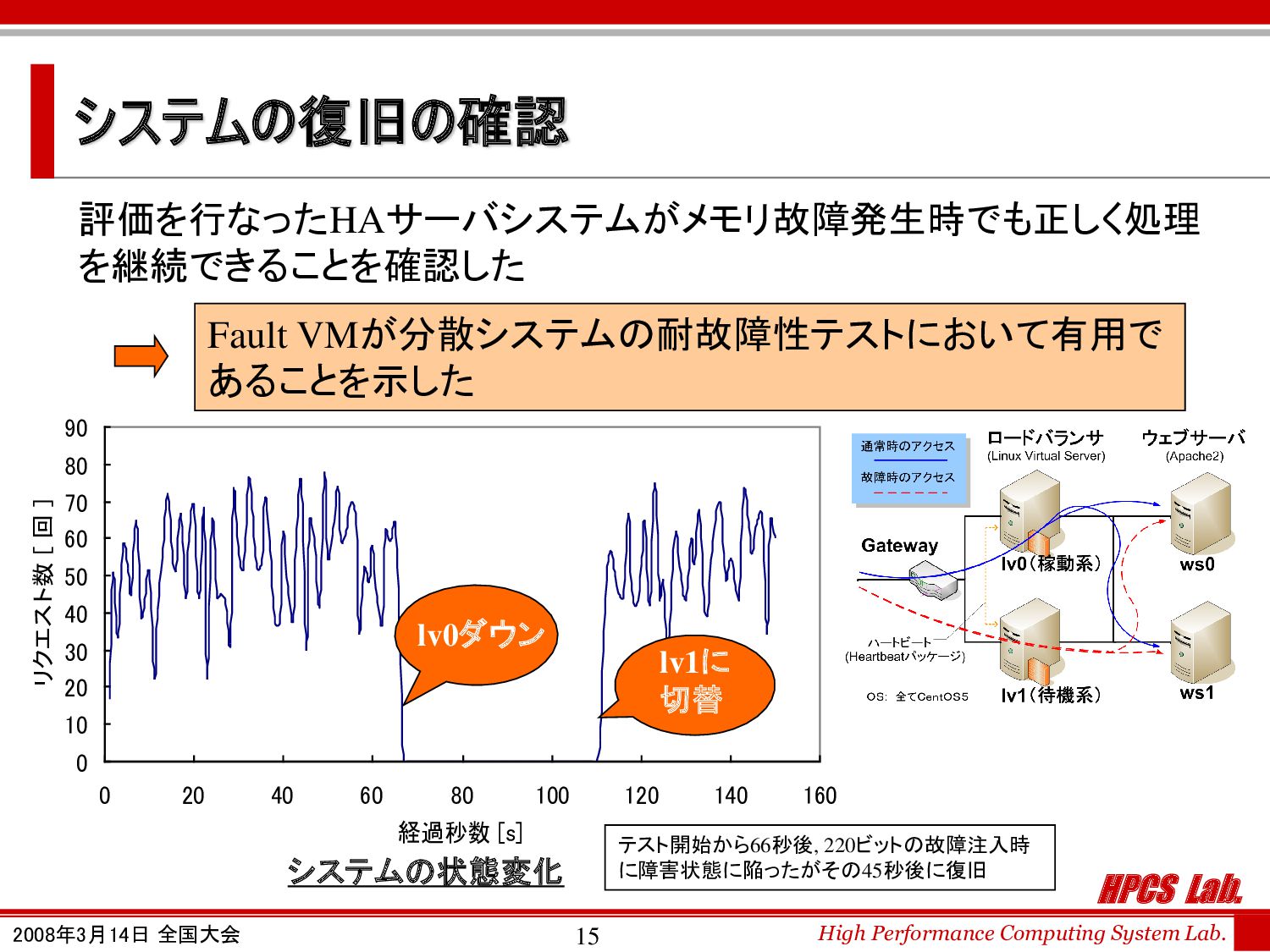
0 10 20 30 40 50 60 70 80 90 0 20 40 60 80 100 120 140 160 経過秒数 [s] リクエスト数 [ 回 ] システムの復旧の確認 評価を行なったHAサーバシステムがメモリ故障発生時でも正しく処理 を継続できることを確認した lv1に 切替 lv0ダウン システムの状態変化 テスト開始から66秒後, 220ビットの故障注入時 に障害状態に陥ったがその45秒後に復旧 Fault VMが分散システムの耐故障性テストにおいて有用で あることを示した
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 16
汎用的な評価手法の実現に向けて 耐故障性評価のステップ 状態の認識 集計 特定のモデルでの評価値算出 ◼ Fault VMの優位性 ・評価のためには十分な回数の試行が必要 可能 ◼ 評価対象システムの状態の定義 ・対象システムが正常状態か障害状態か否か, またどの程度の障害 状態であるかを認識する必要がある ・しかし, 状態の定義は対象システムにより異なる ユーザが比較的少ない労力で状態の定義を行なえる枠組 みを検討する必要がある
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 17
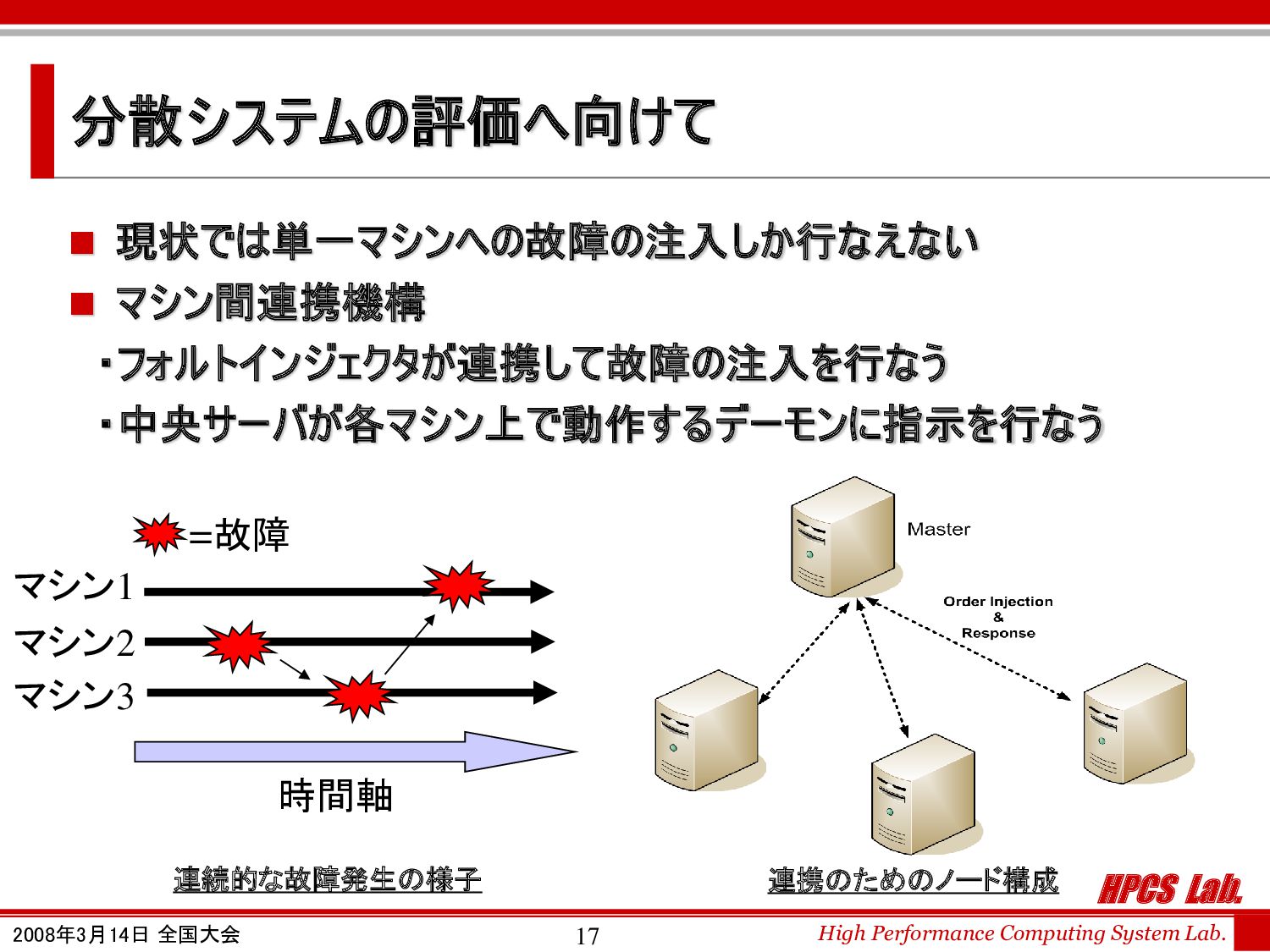
分散システムの評価へ向けて ◼ 現状では単一マシンへの故障の注入しか行なえない ◼ マシン間連携機構 ・フォルトインジェクタが連携して故障の注入を行なう ・中央サーバが各マシン上で動作するデーモンに指示を行なう 時間軸 マシン1 マシン2 マシン3 =故障 連続的な故障発生の様子 連携のためのノード構成
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 18
関連研究 ◼ コード書き換えによるフォルトインジェクタ ・システムのコードに故障を発生させるコードを追加する ・柔軟性は高いが, コードが必要になる. また利用するためにかかる労力が大きい. ・ WS-FIT[Nik Lookerら 2005]など ◼ カーネル層でのフォルトインジェクタ ・カーネル自身やドライバに故障を発生させる仕組みを実装. ・利用するために必要な労力は少ないが, OSに依存. また, カーネルごと障害状態 に陥った場合に内部状態の観測が不可能. ・FTAPE[Nik Lookerら 1995]など ◼ 仮想マシンを用いたフォルトインジェクタ ・分散システムを対象とした評価は行っていない ・FAUMachine[S.Potyraら 2007]
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 19
◼ 簡便に分散システムの耐故障性評価を行なうシステム、 Fault VMを提案し設計・試作を行なった. ・プロトタイプでは, 第一段階として仮想マシンによるメモリ故障の注 入を実装した ・分散システムの評価のための設計も行なった ◼ Fault VMを利用してHAサーバシステムの耐故障性評価 を行い , Fault VMの有用性を示した ・汎用的な評価に向けて必要な課題を明確にした 今後は機能の拡張を進め,汎用的に利用できる評価環境を目指す まとめ
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 20
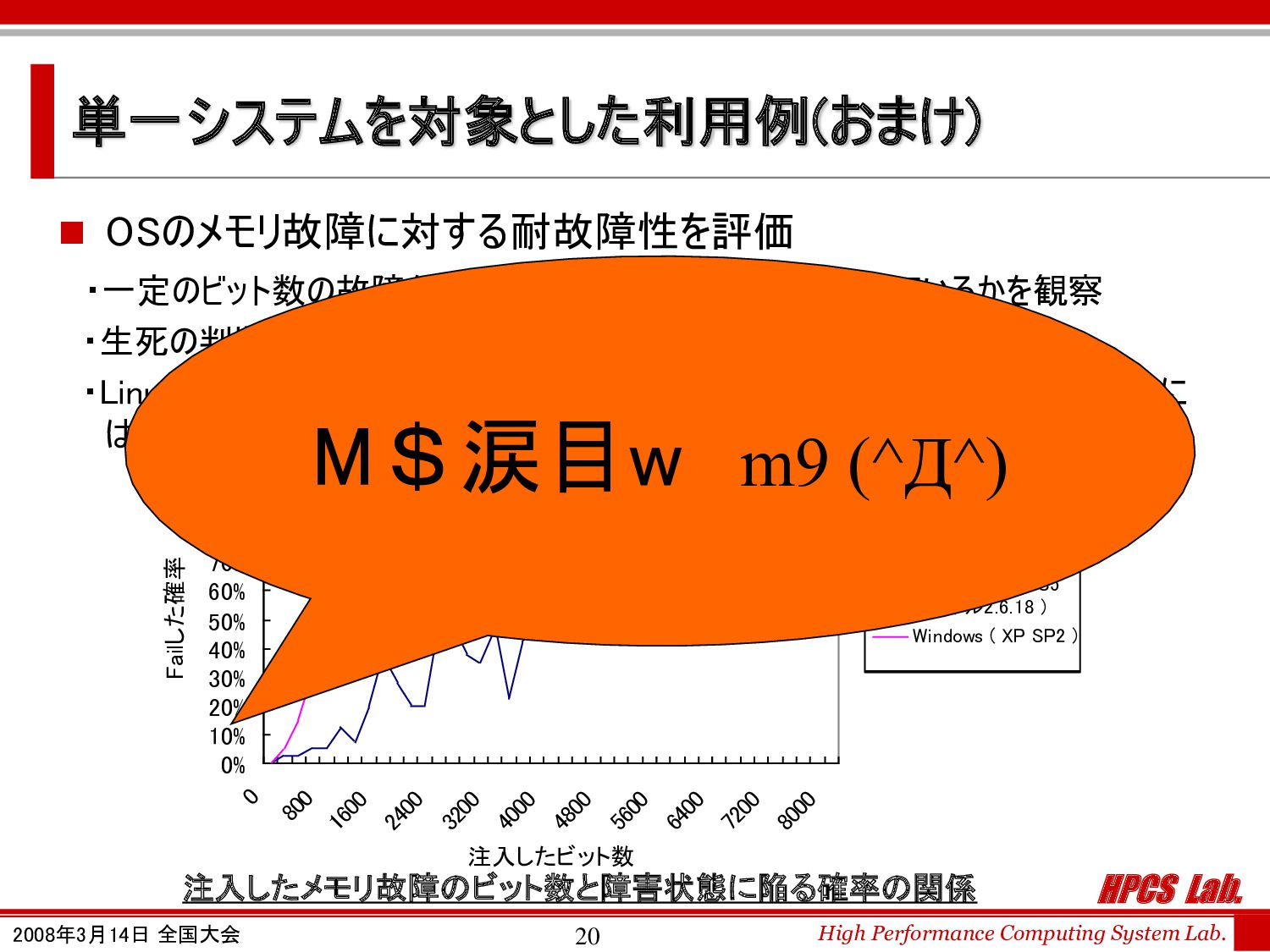
単一システムを対象とした利用例(おまけ) 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 0 800 1600 2400 3200 4000 4800 5600 6400 7200 8000 注入したビット数 Failした確率 Linux ( Cent OS5 カーネル2.6.18 ) Windows ( XP SP2 ) 注入したメモリ故障のビット数と障害状態に陥る確率の関係 ◼ OSのメモリ故障に対する耐故障性を評価 ・一定のビット数の故障を注入した段階でシステムが生存しているかを観察 ・生死の判断にはハートビートを使用 ・LinuxがWindowsより高い耐故障性を持つという結果. しかし、結論を出すために はより詳細な検討が必要 30% ~ 40% M$涙目w m9 (^Д^)
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 21
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 22
DomainU Application (full-virtualization) HW Xen kernel Domain0 DomainU Admin tools Application (para-virtualization) Linux Free BSD Windows XP 仮想マシンXen ◼ ホストOSを必要としないタイプの仮想マシン ・実マシンの上にXenカーネルが位置 ・Xenカーネルがコンテキストスイッチを行い複数のOSを動作させる ◼ 特権を持つDomain0とその他のDomainUが存在 ・Domain0のみ各DomainやXenの管理が可能 ◼ 他の仮想マシンと比べ ・準仮想化とHW支援による完全仮想化により 高速に動作 ・完全仮想化を利用するとシステムへの改変が 不要 また,他のDomainUの状態の操作も可能
HPCS Lab. High Performance Computing System Lab. 2008年3月14日 全国大会 23
手法 ◼ 設定ファイルによるシナリオベースでの故障注入 ・設定ファイルを記述するだけの少ない労力でテストが可能 ・ノード間で複合的に故障が起きるようなシナリオも記述可能 nodes: dennis01 192.168.1.1 dennis02 192.168.1.2 dennis03 192.168.1.3 faults: memory,random,0x1000-0x2000,100bits,dennis01 power,down,dennis02 wait,10sec communication,100sec,10bits,dennis01-dennis03 ノードの列挙 dennis01の0x1000から 0x2000番地に100ビットの ランダムなメモリ故障を発生 dennis01とdennis03の通信に 対し,100秒に10ビットずつ 通信異常を発生
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}