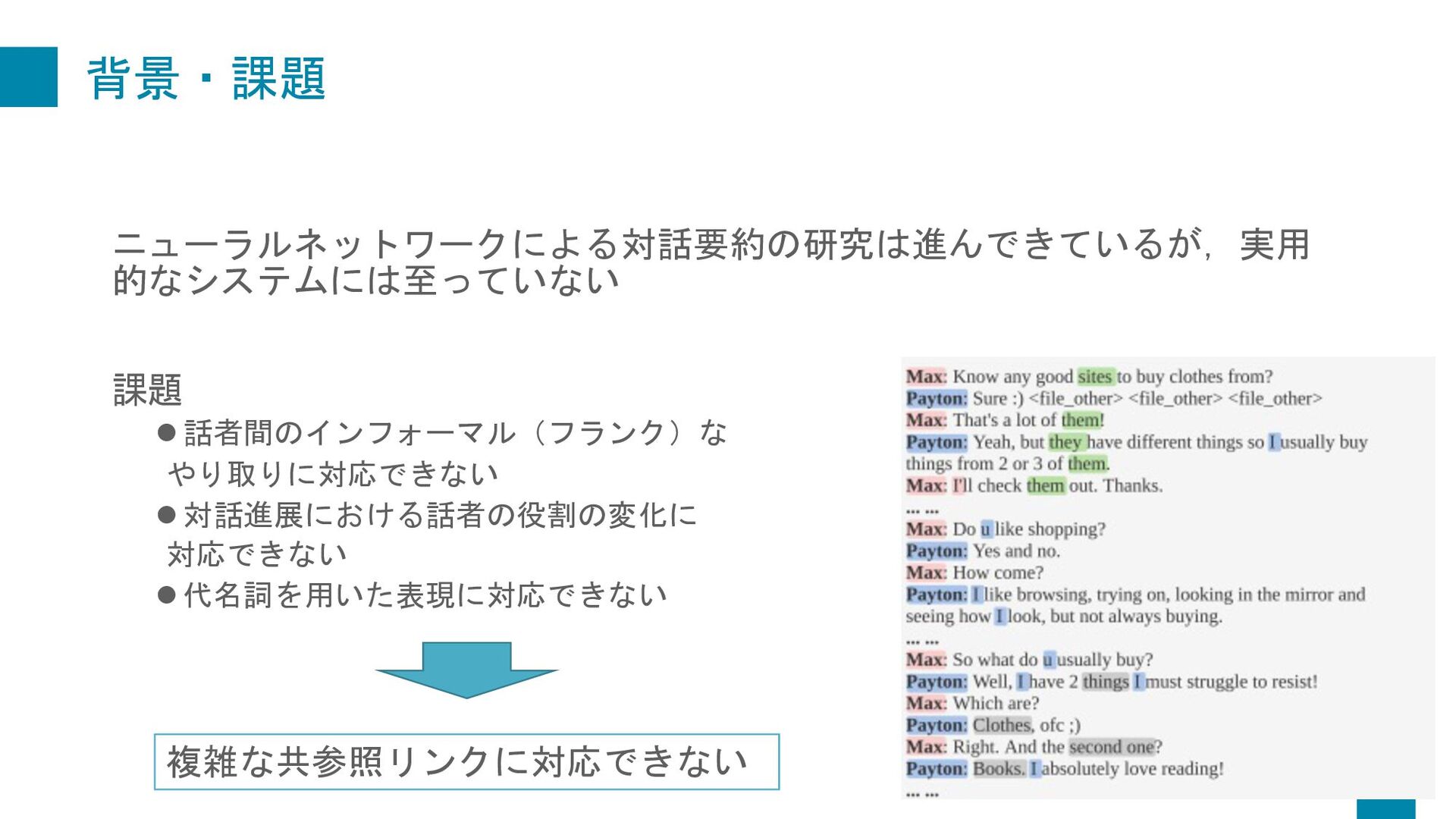
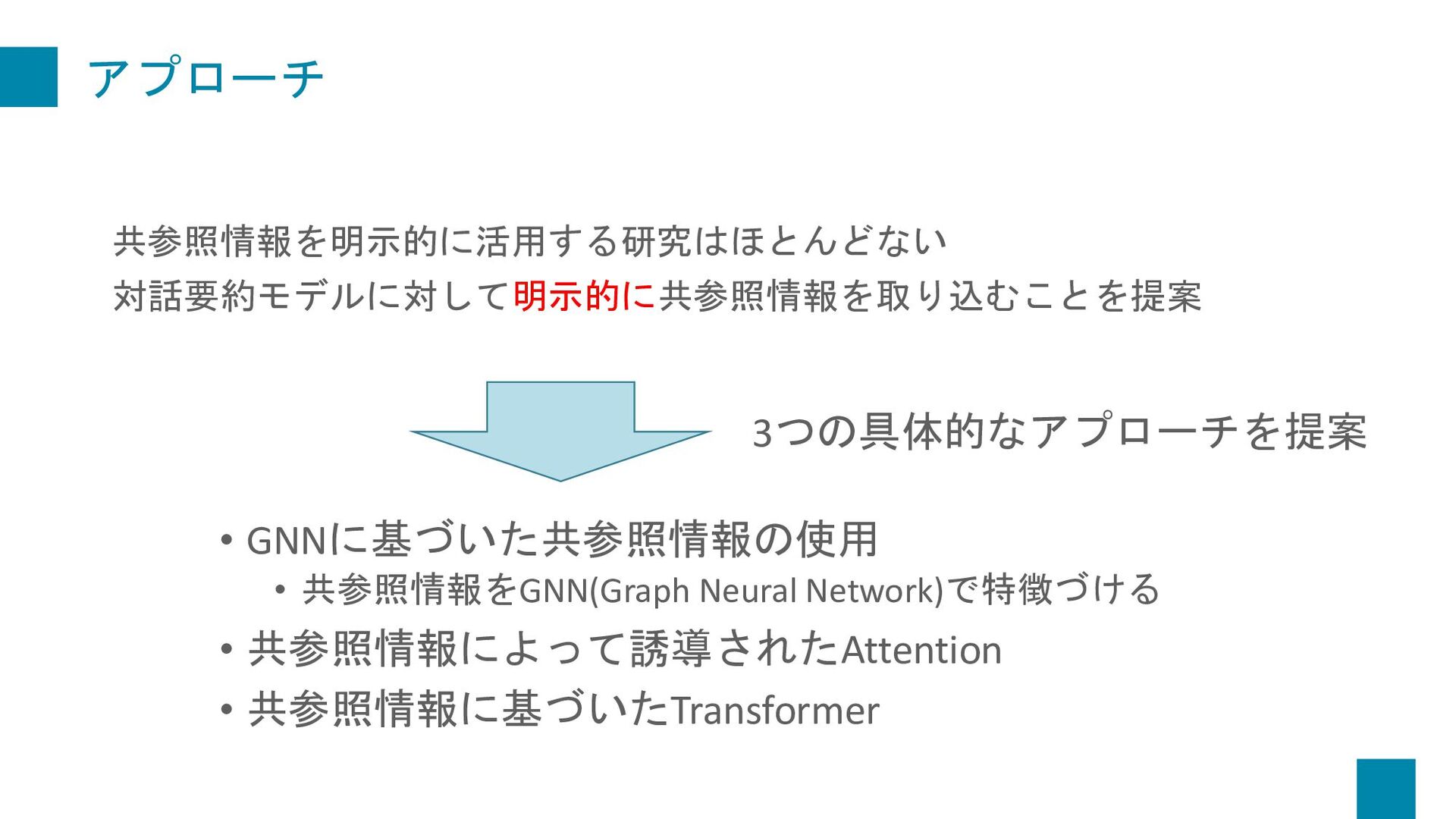
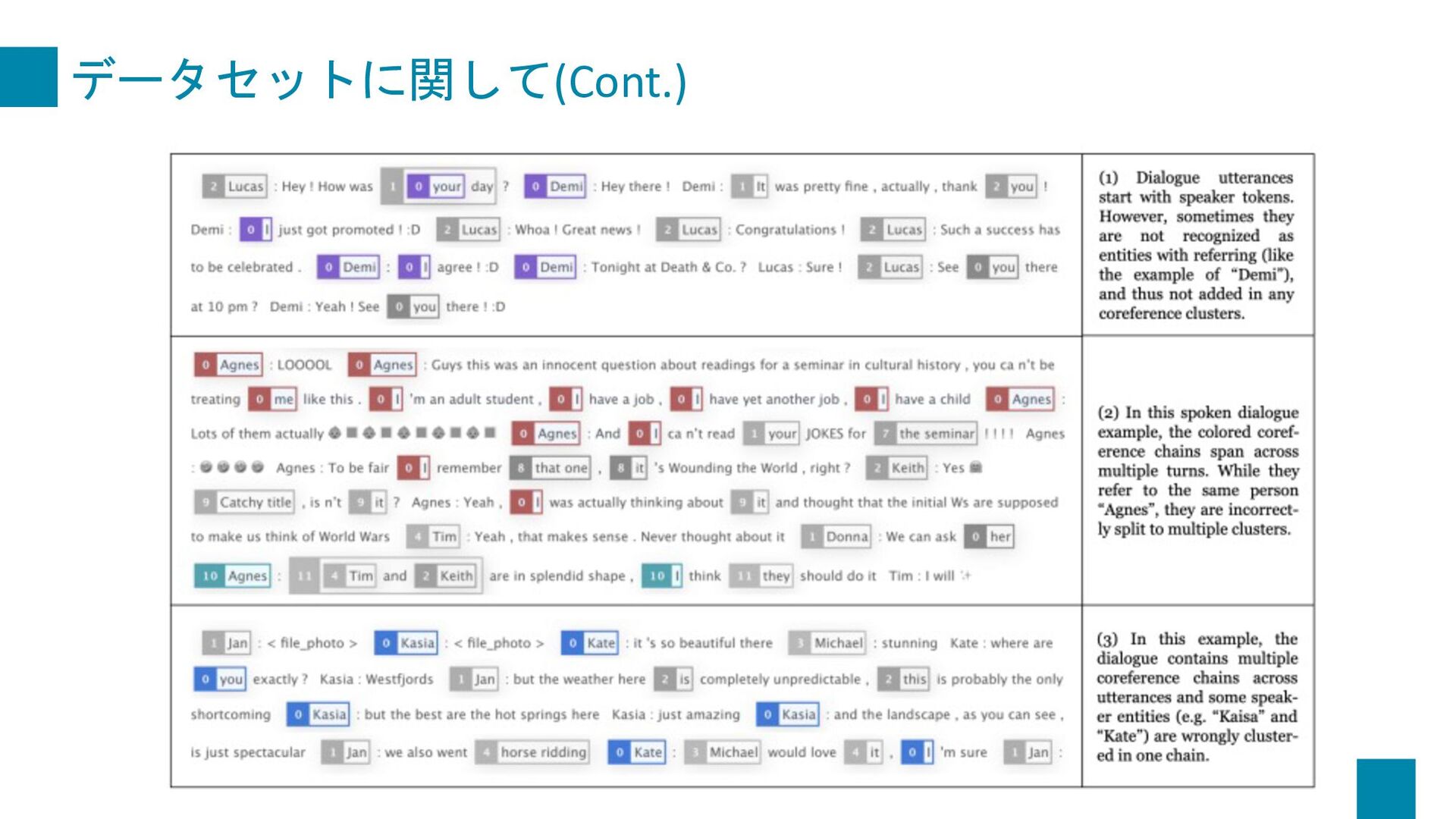
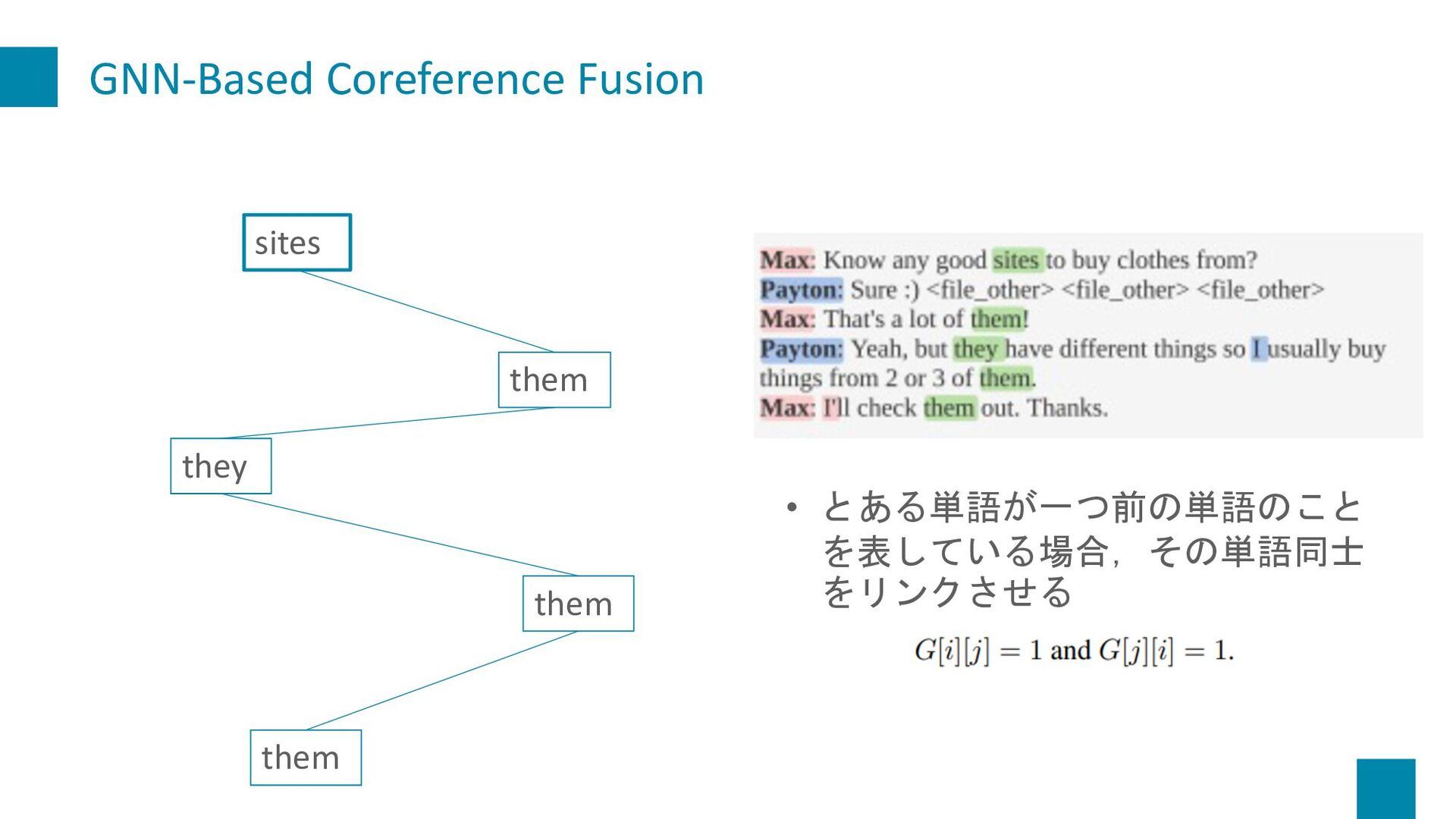
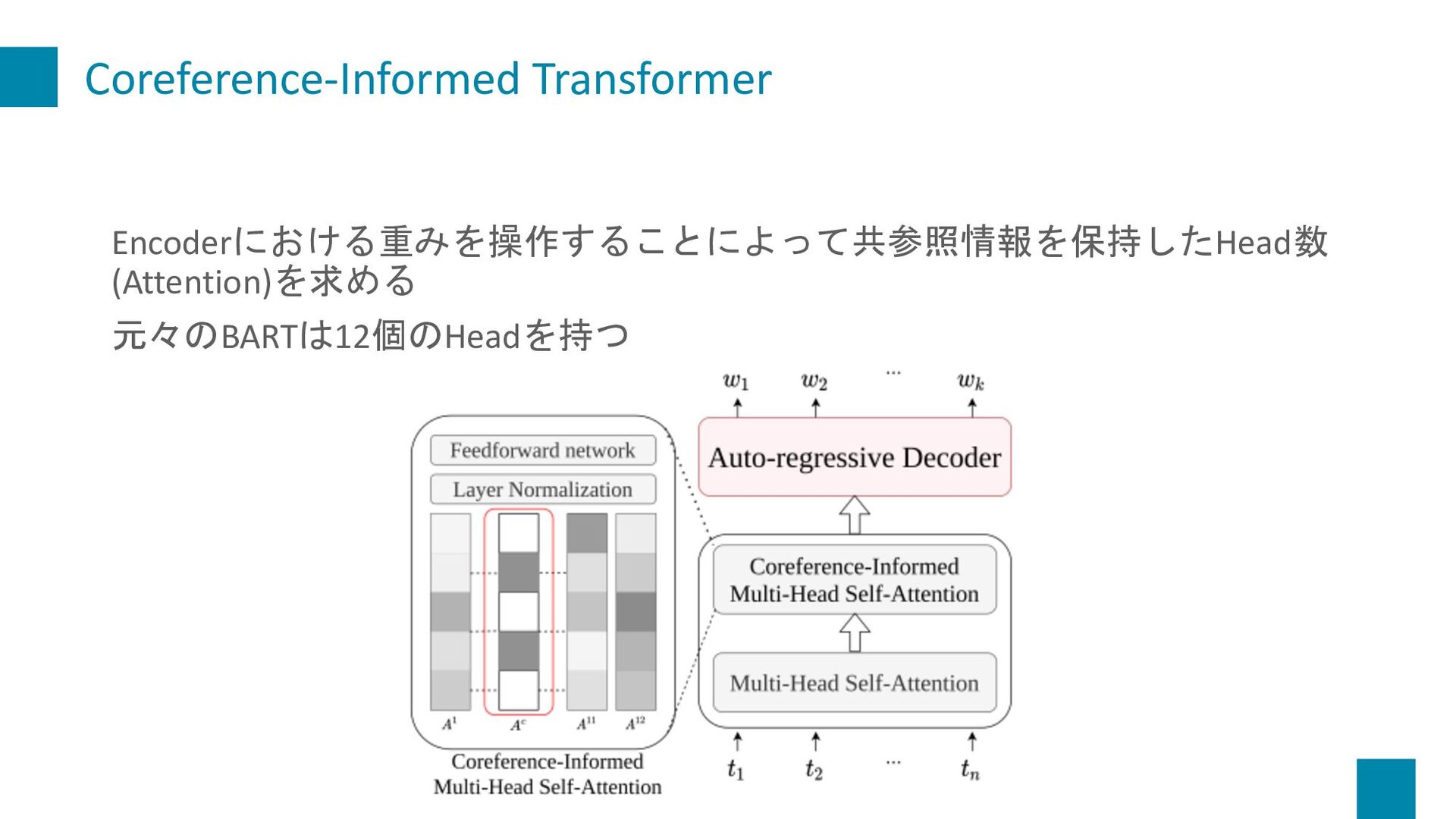
Dialogue Summarization. In Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 509–519, Singapore and Online. Association for Computational Linguistics. 紹介する理由 • 対話文における共参照関係をグラフ化して要約するというのが 面白そうだったから • 共参照情報をうまく保持したHead数(Attention)を求める手法を 提案している
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![人間による評価 • 人間による[-2, 0, 2]スケールでの評価 • -2は要約が間違った参照を行っている • 0は許容は出来るが情報が足りない •](https://files.speakerdeck.com/presentations/f90cba28130d430ba7813498f7ecbca5/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}