Dongyan Zhao, and Rui Yan. 2022. Learning to Express in Knowledge-Grounded Conversation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2258–2273, Seattle, United States. Association for Computational Linguistics. n 選んだ理由 l応答表現を多様化する?みたいな論文が読みたかった lタイムステップごとに生成方法を変えるのが面白そうだった 2
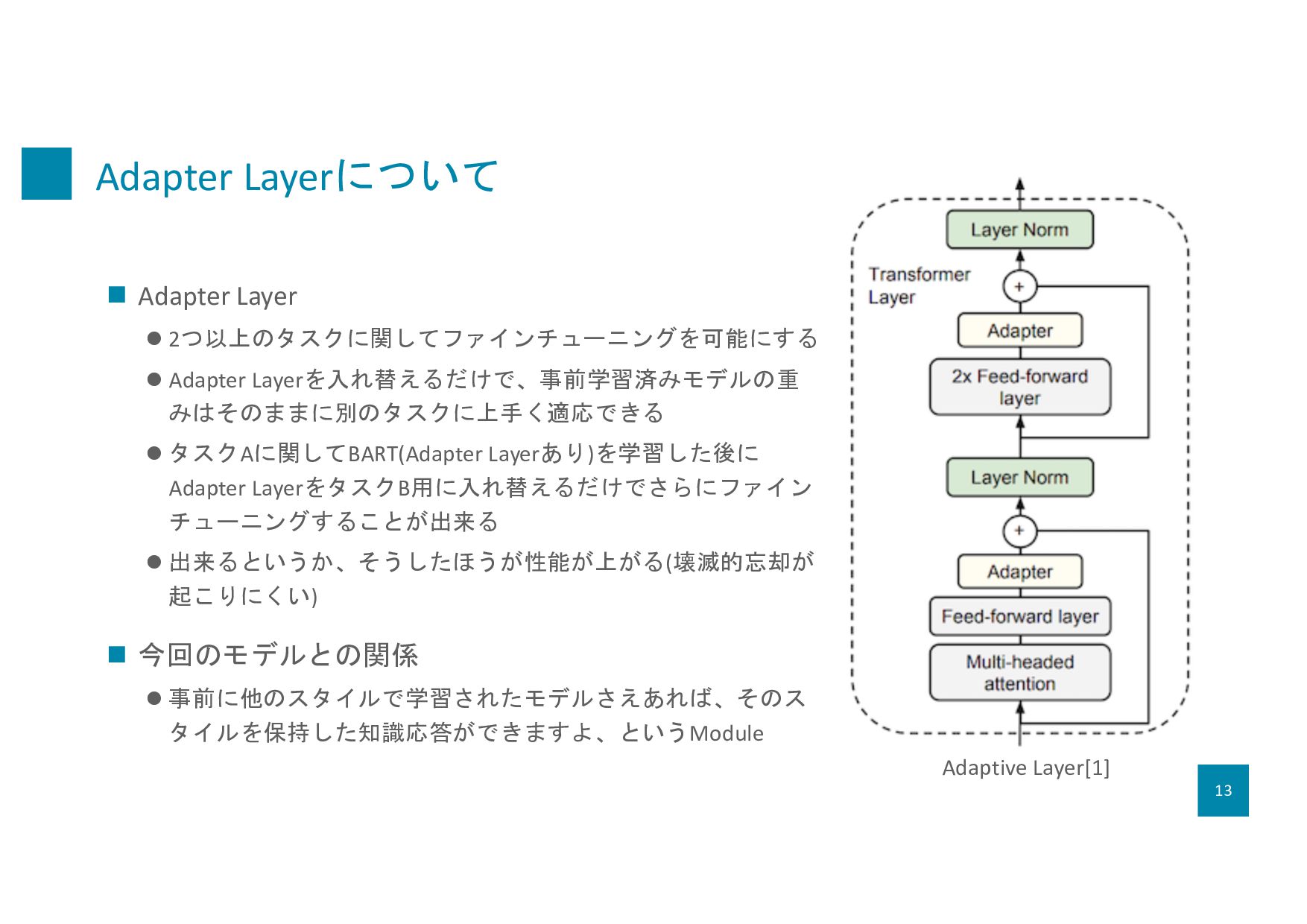
みはそのままに別のタスクに上手く適応できる l タスクAに関してBART(Adapter Layerあり)を学習した後に Adapter LayerをタスクB用に入れ替えるだけでさらにファイン チューニングすることが出来る l 出来るというか、そうしたほうが性能が上がる(壊滅的忘却が 起こりにくい) n 今回のモデルとの関係 l 事前に他のスタイルで学習されたモデルさえあれば、そのス タイルを保持した知識応答ができますよ、というModule Adaptive Layer[1] 13
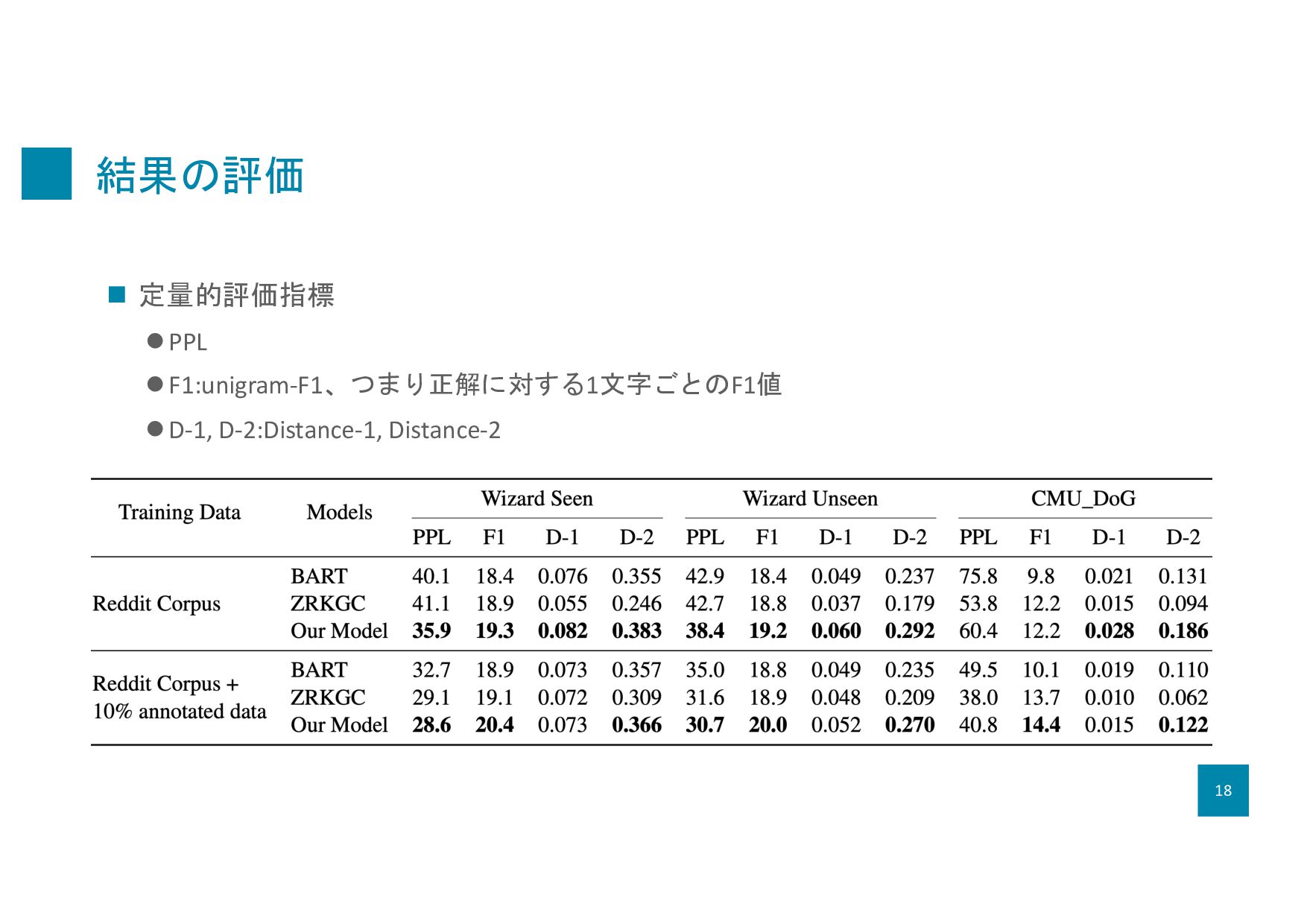
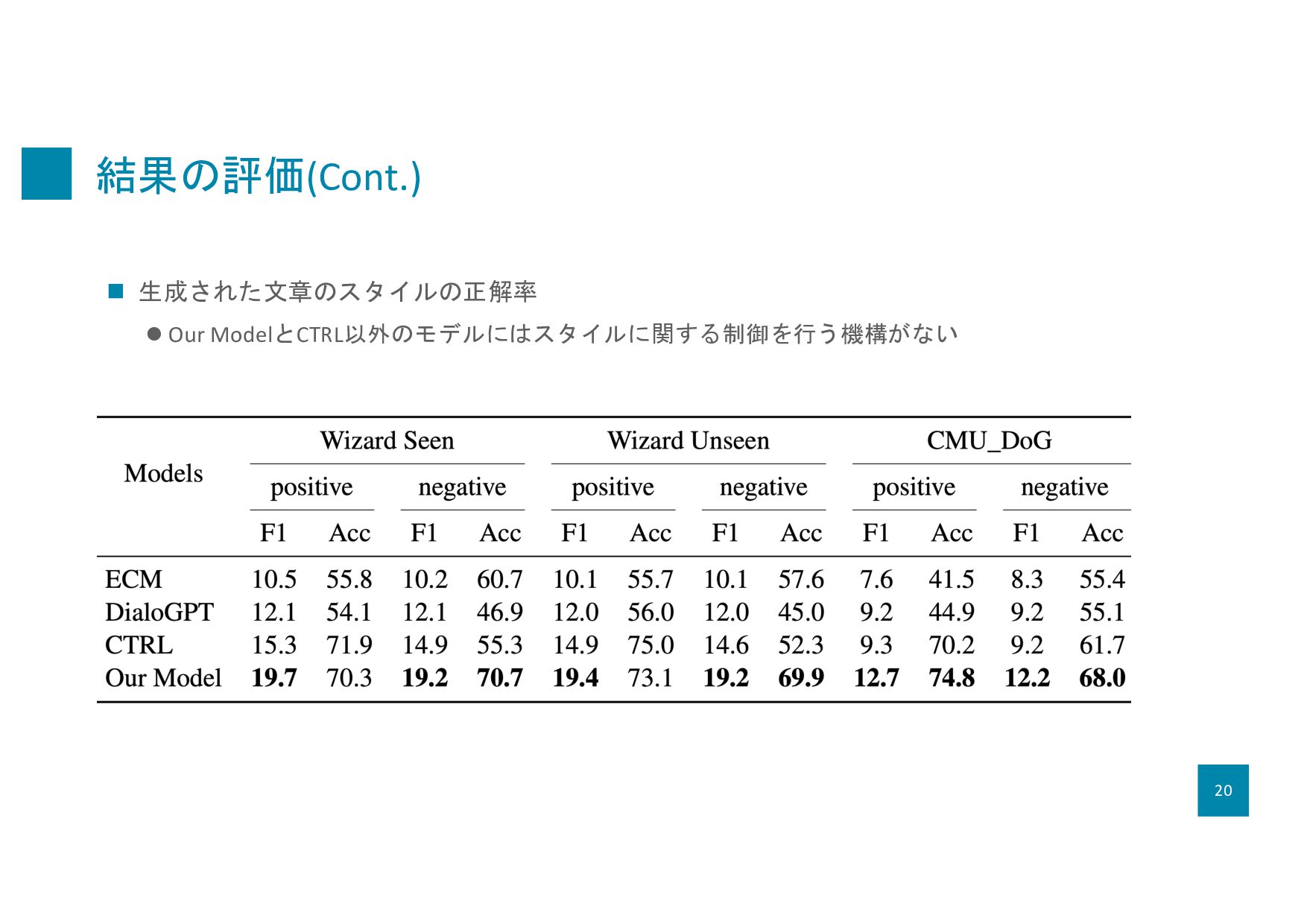
2019) l CMU Document Grounded Conversations (CMU_DoG) (Zhou et al., 2018c) n ベースライン lBART (Lewis et al., 2020) l Zero-resource Knowledge-grounded Conversation (ZRKGC) (Li et al., 2020) l Emotional Chatting Machine (ECM) (Zhou et al., 2018a) l variant of DialoGPT (Zhang et al..., 2019b):感情の制御コードを用いたモデル l CTRL(Keskar et al.,2019):スタイルを制御するコードを用いてスタイル付き応答を生成する大 規模モデル 16
Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly. ” Parameter-Efficient Transfer Learning for NLP.” Proceedings of the 36th International Conference on Machine Learning, PMLR 97:2790-2799, 2019. 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![結果の評価(Cont.) n 人間による評価 l [0, 1, 2]で評価 l Fluency l](https://files.speakerdeck.com/presentations/097a7f1638424f1b88e6818d853d8432/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
![補足資料 n [1] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna](https://files.speakerdeck.com/presentations/097a7f1638424f1b88e6818d853d8432/slide_19.jpg){kind=link}