• Стандартная библиотека re docs.python.org/2/library/re.html • Библиотека regex (совместима со стандартной, лучше поддерживает юникод) pypi.org/project/regex/
nltk • Содержит готовые наборы данных, в том числе корпусы (corpora) текстов, грамматики, натренированные модели, которые можно скачать командой: nltk.download() - графическое окно для выбора набора или nltk.download('dataset-name')
• Переработка документа в лексемы (разбивка на слова, словосочетания, предложения) • Выделение основы слов (удаление приставок, окончаний и суффиксов, определение корня) — стемминг
Знаки препинания (если не используются в дальнейшем анализе) • Смайлики (если не используются в дальнейшем анализе) • И т. п. • Инструменты: должно хватить регулярных выражений
делал это сам за нас (самостоятельно: посмотрите в документации, что за алгоритм): count = CountVectorizer() docs = np.array([ u'спят усталые игрушки, книжки спят', u'усталые игрушки усталые', u'книжки спят' ]) bag = count.fit_transform(docs)
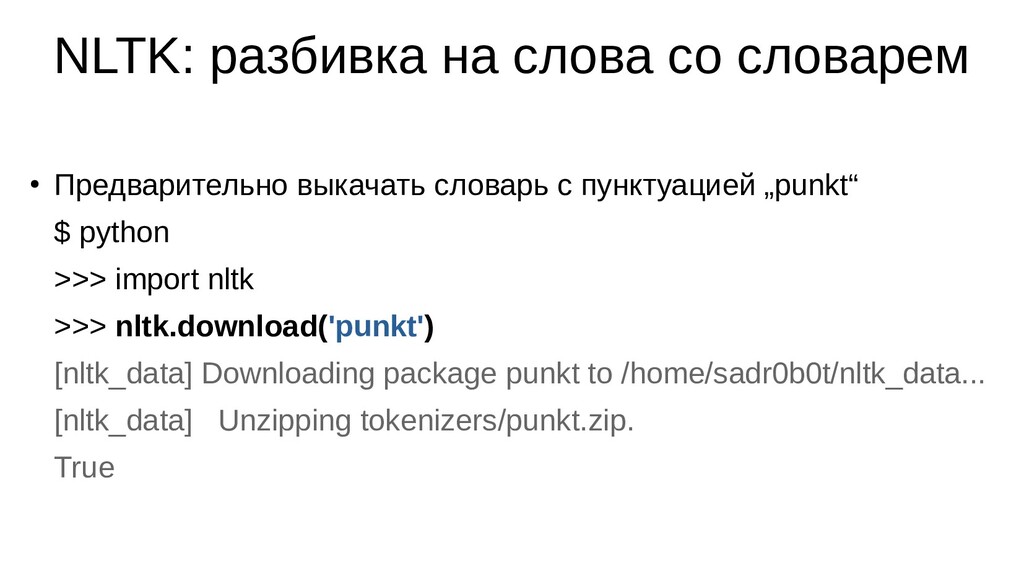
import nltk >>> nltk.download('punkt') [nltk_data] Downloading package punkt to /home/sadr0b0t/nltk_data... [nltk_data] Unzipping tokenizers/punkt.zip. True NLTK: разбивка на слова со словарем
Learning with Python machinelearningmastery.com/clean-text-machine- learning-python/ • How to get rid of punctuation using NLTK tokenizer? stackoverflow.com/questions/15547409/how-to-get- rid-of-punctuation-using-nltk-tokenizer • ...
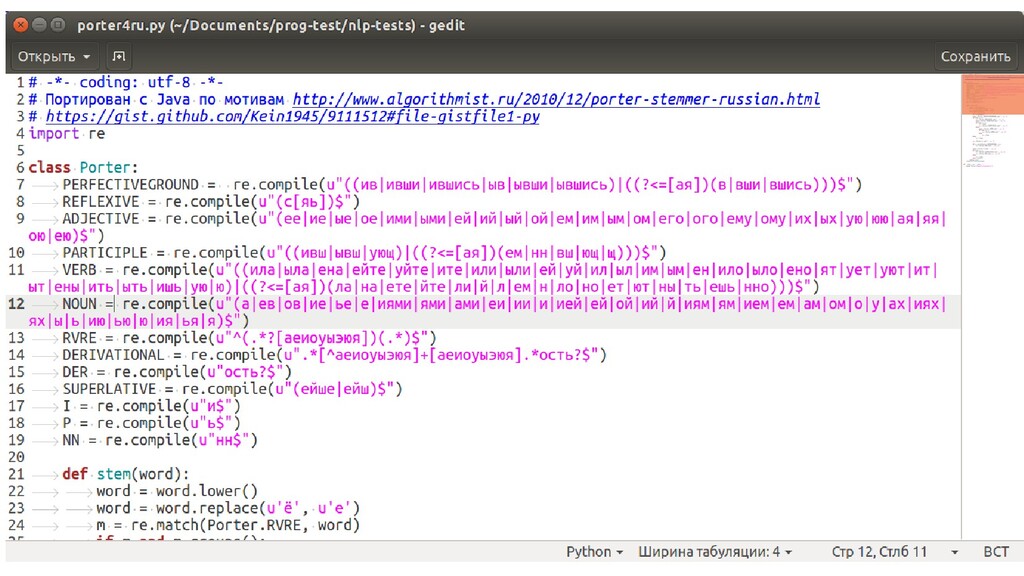
• Поиск по «стеммер Портера для русского языка на Python» выводит на gist.github.com/Kein1945/9111512 • Это порт другой реализации стеммера на Пайтон с Явы • Скачаем этот файл, переименуем в porter4ru.py, положим рядом с исходниками • В строке 24 исправить (чтобы не падал на английских словах): if m.groups(): на if m and m.groups():
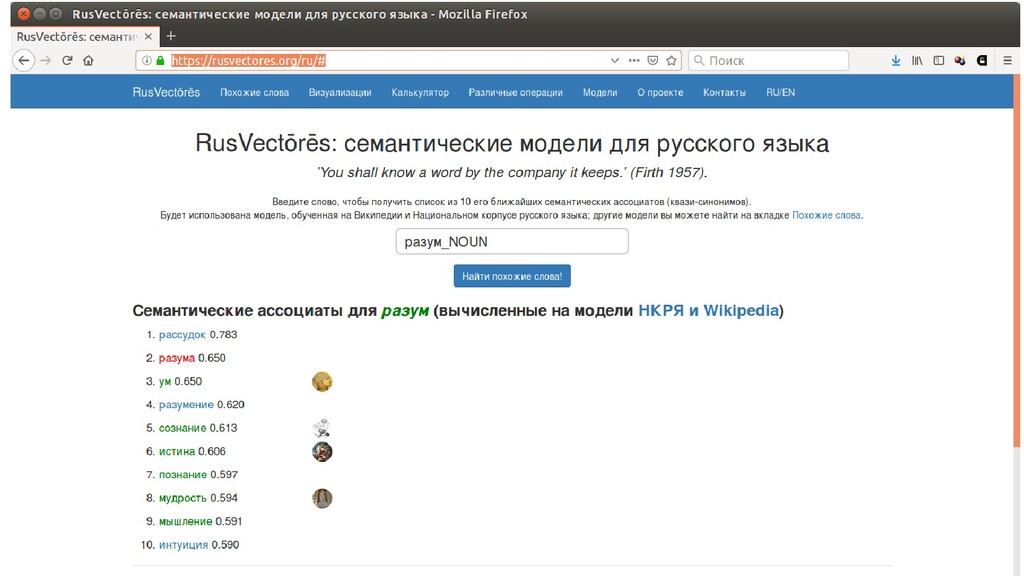
основываясь на контекстной близости этих слов. • Обучается на больших массивах текстов • Реализация на Python: radimrehurek.com/gensim/models/word2vec.html • Обученная модель для русского языка (обучена на Википедии и Национальном корпусе русского языка): rusvectores.org/ru/# github.com/akutuzov/webvectors/blob/master/preprocessing/rusvectores _tutorial.ipynb
интерфейсы самообслуживания и т. п. • (позволяют заменять живых сотрудников => экономят деньги => повышенный интерес, который может выражаться в живых деньгах) • Юридические тексты (январь 2017: «Сбербанк сократит 3тыс рабочих мест из- за робота-юриста»; февраль 2019: «Сбербанк потерял миллиарды из-за ИИ») • Анализ медиа • Деанон анонимусов (очередного Сатоши Накамото нашли анализом текстовых сообщений на форумах) • Автоматическое распознавание книг (разрешение спорных моментов: наиболее вероятный вариант исходя из контекста) (в мире всего ~120 млн книг, по оценке разработчиков Google Books) • ...
сервисы с отзывами и т. п.) — берите всё, что есть в интернете, современный интернет генерят пользователи • Википедия (регулярно применяется: IBM Watson + Jeopardy, Rusvectores и т. п.) • Онлайн-библиотеки: libgen.io (~2.7 млн. книг, 58 млн. научных статей, можно скачать базу на торентах) • Научные статьи: Sci-Hub (65.5 млн. научных статей, недавно выложили базу в открытый доступ, ~60терабайт), КиберЛенинка (~1.5 млн научных статей — выложены легально) • Патенты, Архивы, ... • ...
корпус современного русского языка общим объемом более 600 млн слов. • Корпус русского языка — это информационно-справочная система, основанная на собрании русских текстов в электронной форме. • Развивается и пополняется профессиональными исследователями, энтузиастами • Хостит Яндекс — на общественных началах
при помощи sklearn.feature_extraction.text.CountVectorizer Выведите: • топ 5 слов для комментариев с позитивным отзывом, • топ 5 слов для комментариев с негативным отзывом
при помощи sklearn.feature_extraction.text.TfIdfTransformer Выведите: • топ 5 слов (максимальный tf-idf) для комментариев с позитивным отзывом, • топ 5 слов для комментариев с негативным отзывом
о положительности или отрицательности отзыва? • Будет ли IDF выводить характерные для всего класса слова в топ? • Можно ли улучшить алгоритм? например: считать IDF для каждого позитивного отзыва отдельно в группе только с негативными Задание-3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}