Лекция курса "Большие данные и машинное обучение" (v2.0-МОТ)
Лекция-7: построение предсказательной модели регрессии
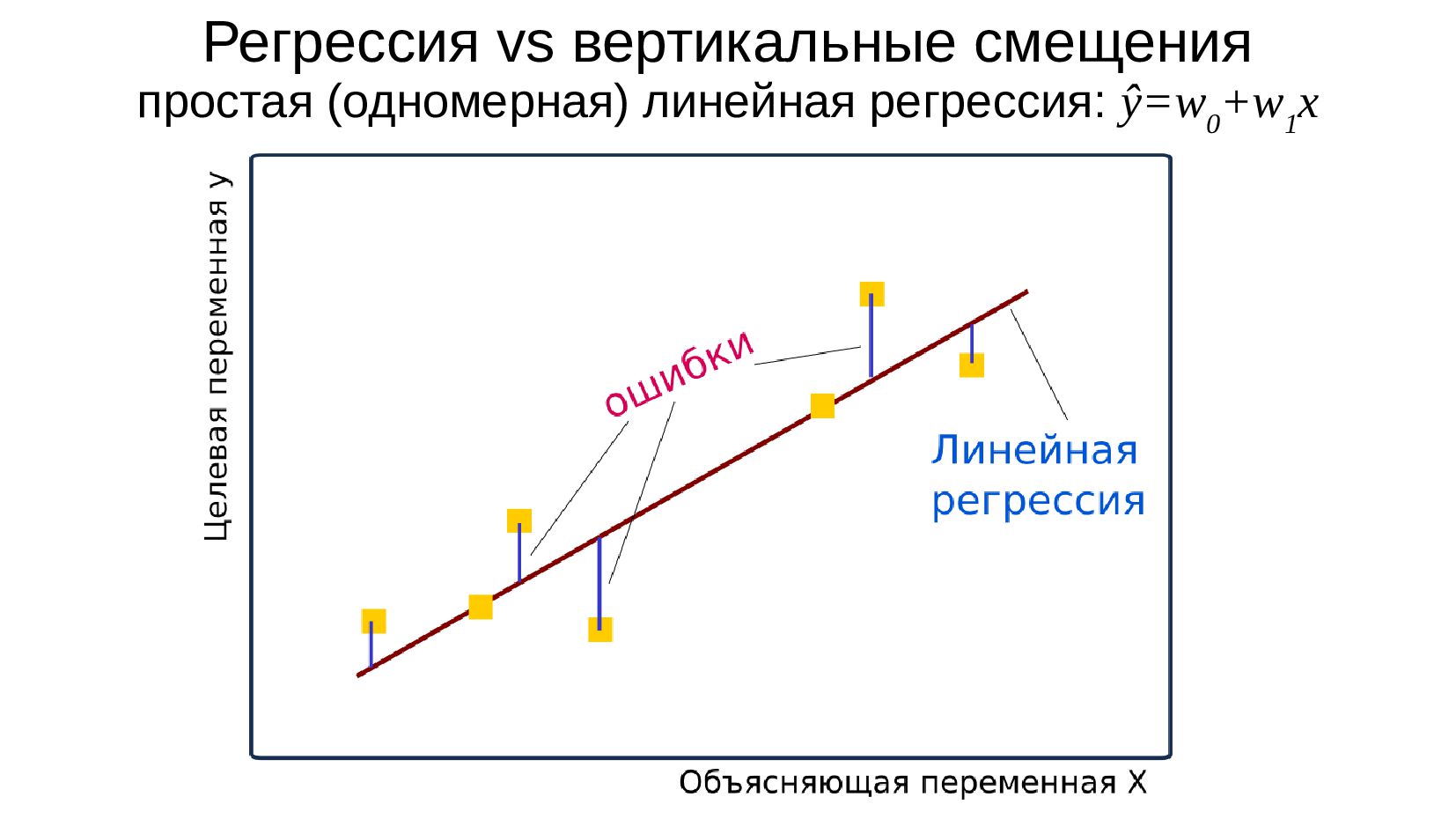
Регрессия, регрессионная модель — модель предсказания целевой переменной на непрерывной шкале
Часть 2: построение модели предсказания: линейная модель, криволинейные модели, выбросы, подгонка, оценка качества
- Простая (одномерная) регрессионная модель
- Регрессионные модели
- Признаковое описание объекта
- Предсказательная модель
- Параметрическое семейство функций
- Функция потерь
- Градиентный спуск
- Обобщающая способность модели
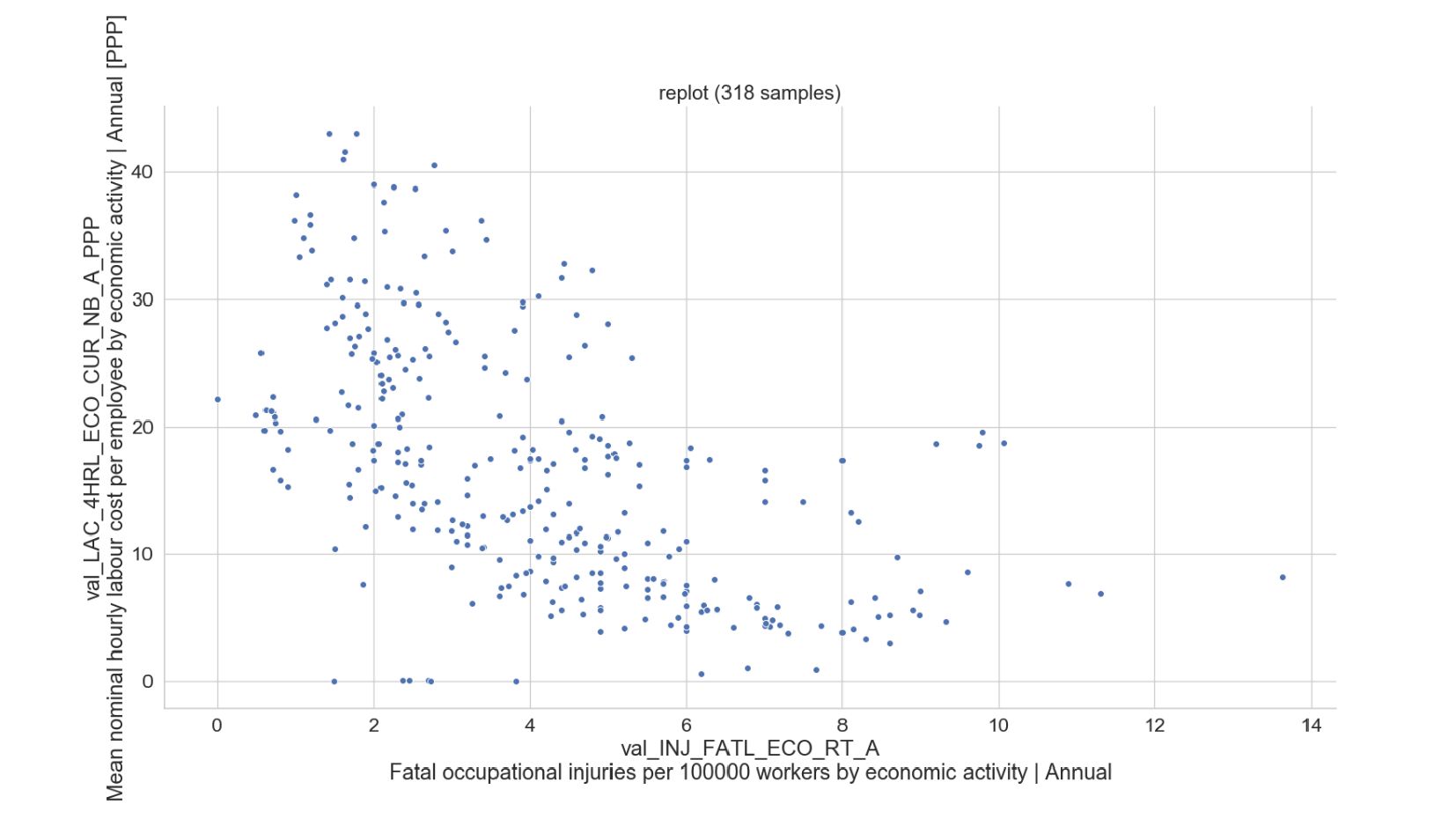
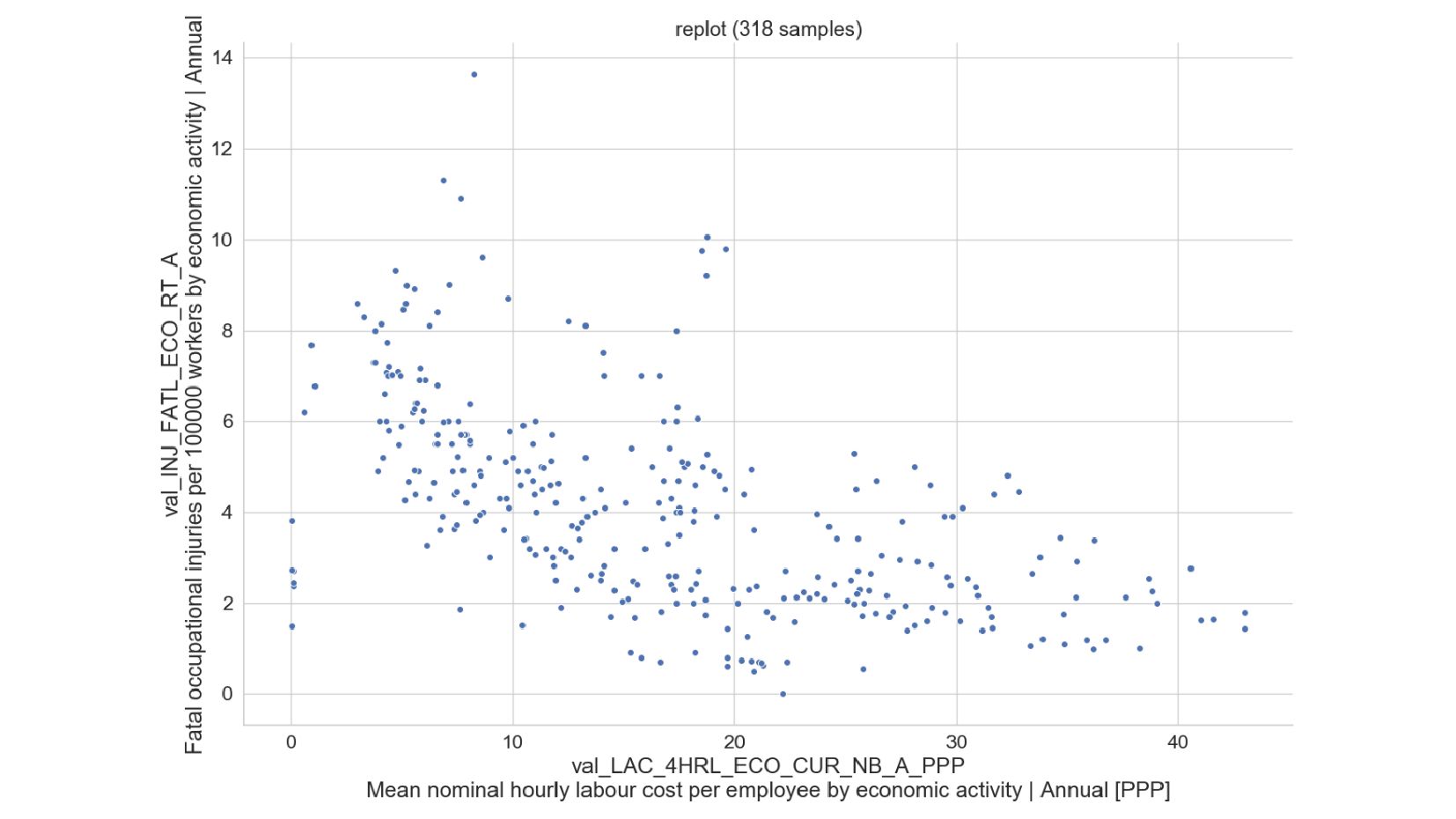
- Точечный график: Matplotlib:Scatter, Seaborn:Relplot
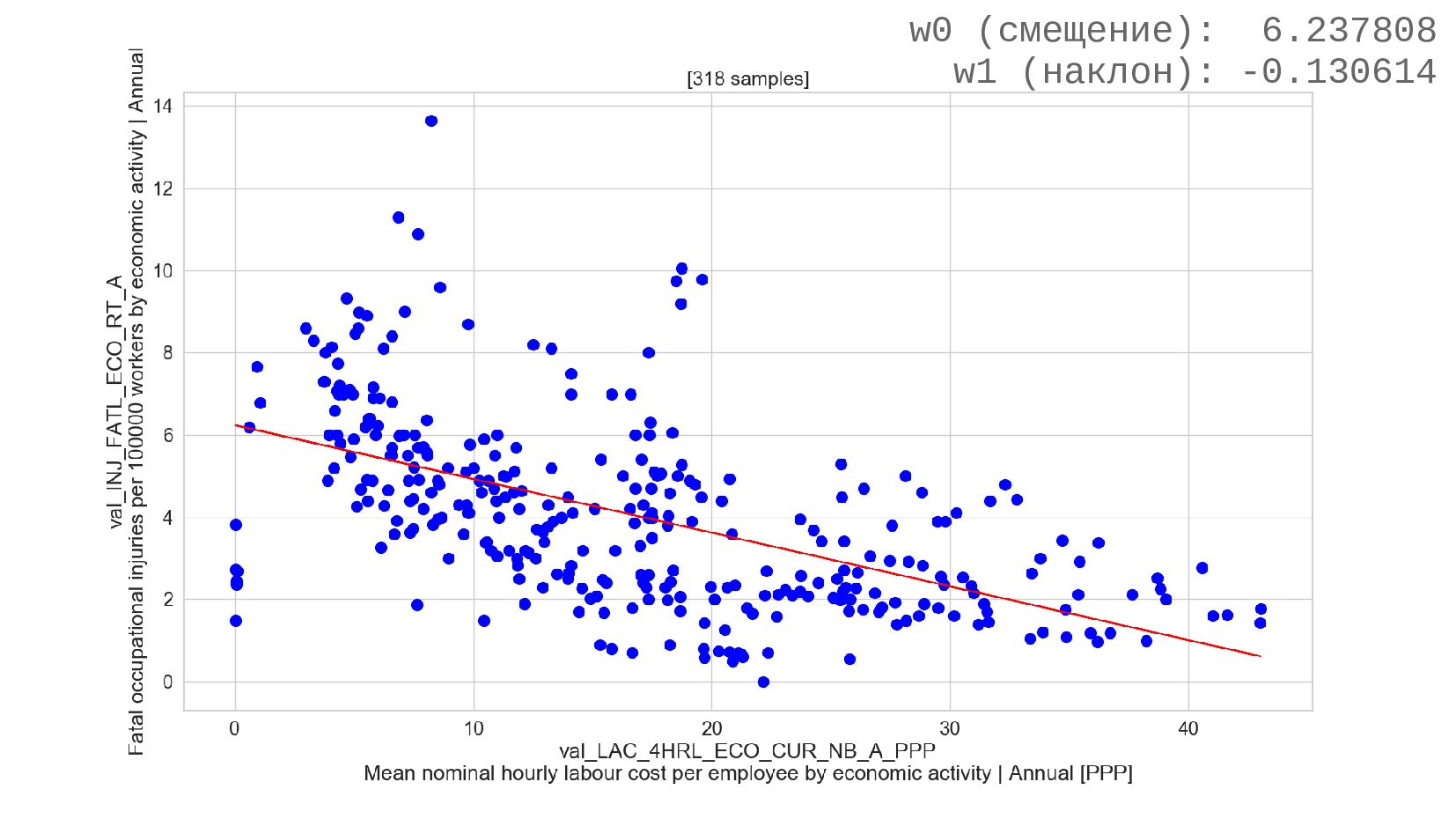
- Построение модели линейной регрессии: Sklearn: LinearRegression
- Пример: построение моделей регрессии в датасете ILO (МОТ - Международная организация труда) ilostat.ilo.org
- Объединение множества специализированных таблиц в одну таблицу объектов с целевыми признаками
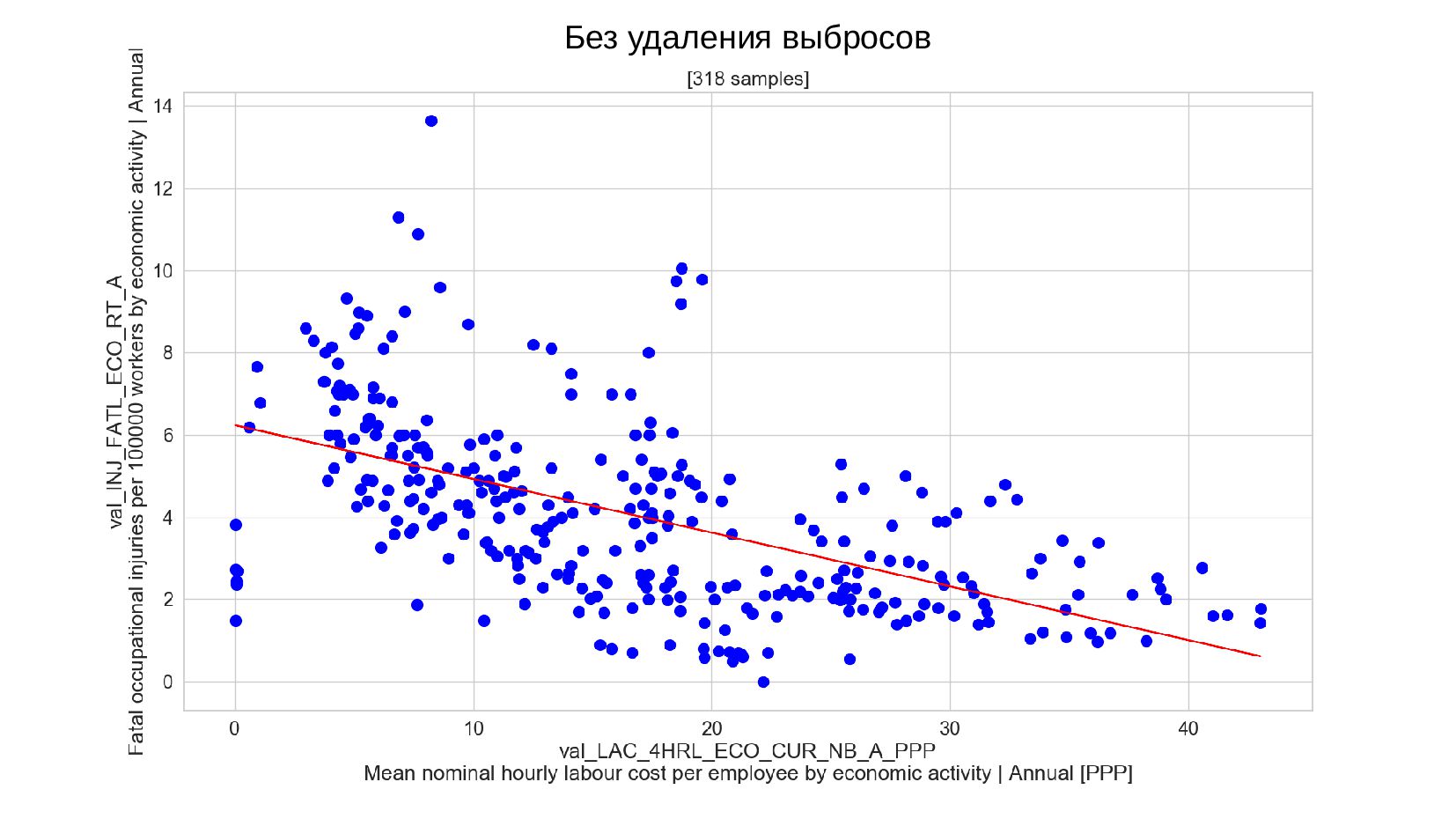
- Построение точечного графика для пары выбранных признаков
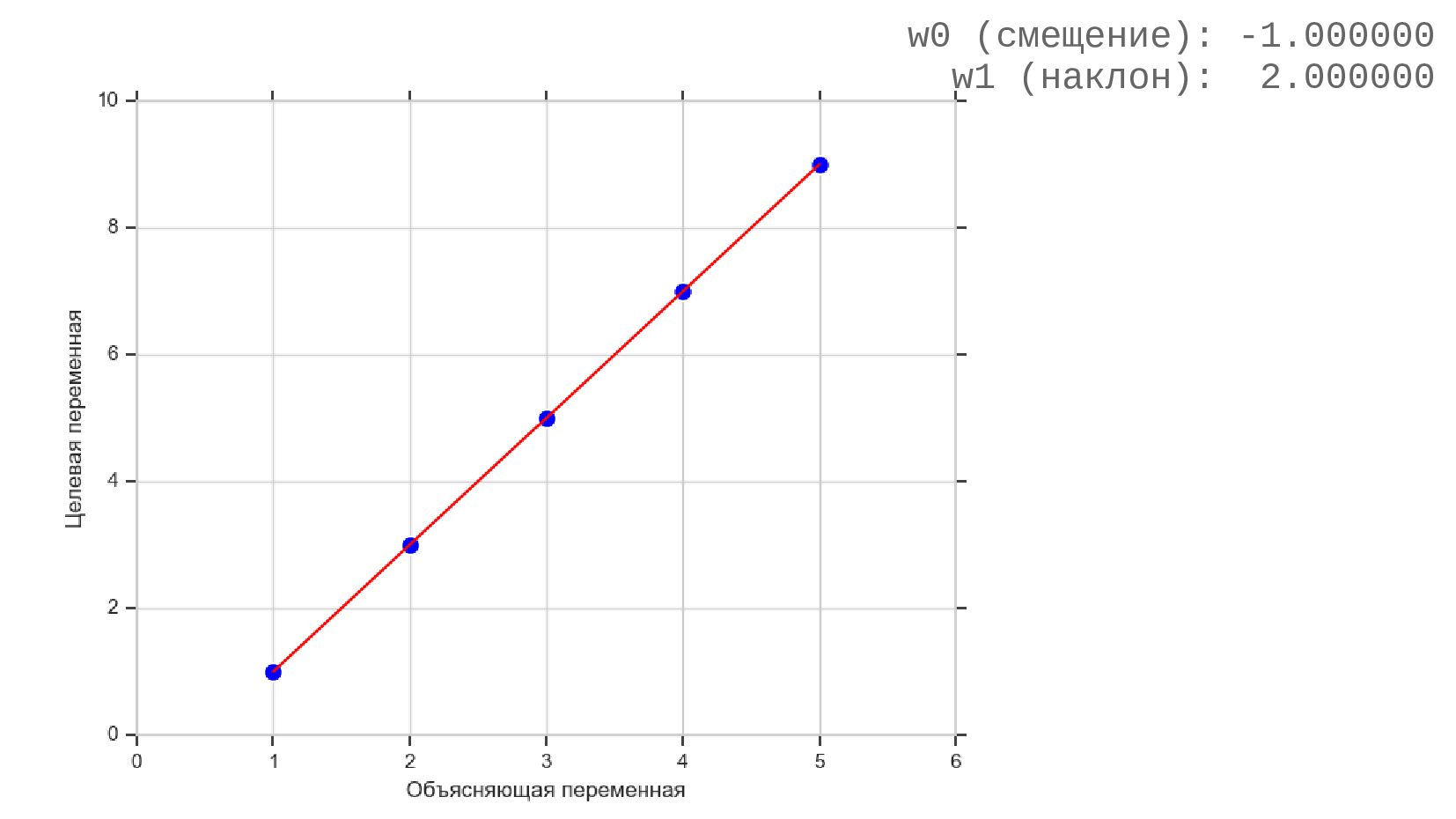
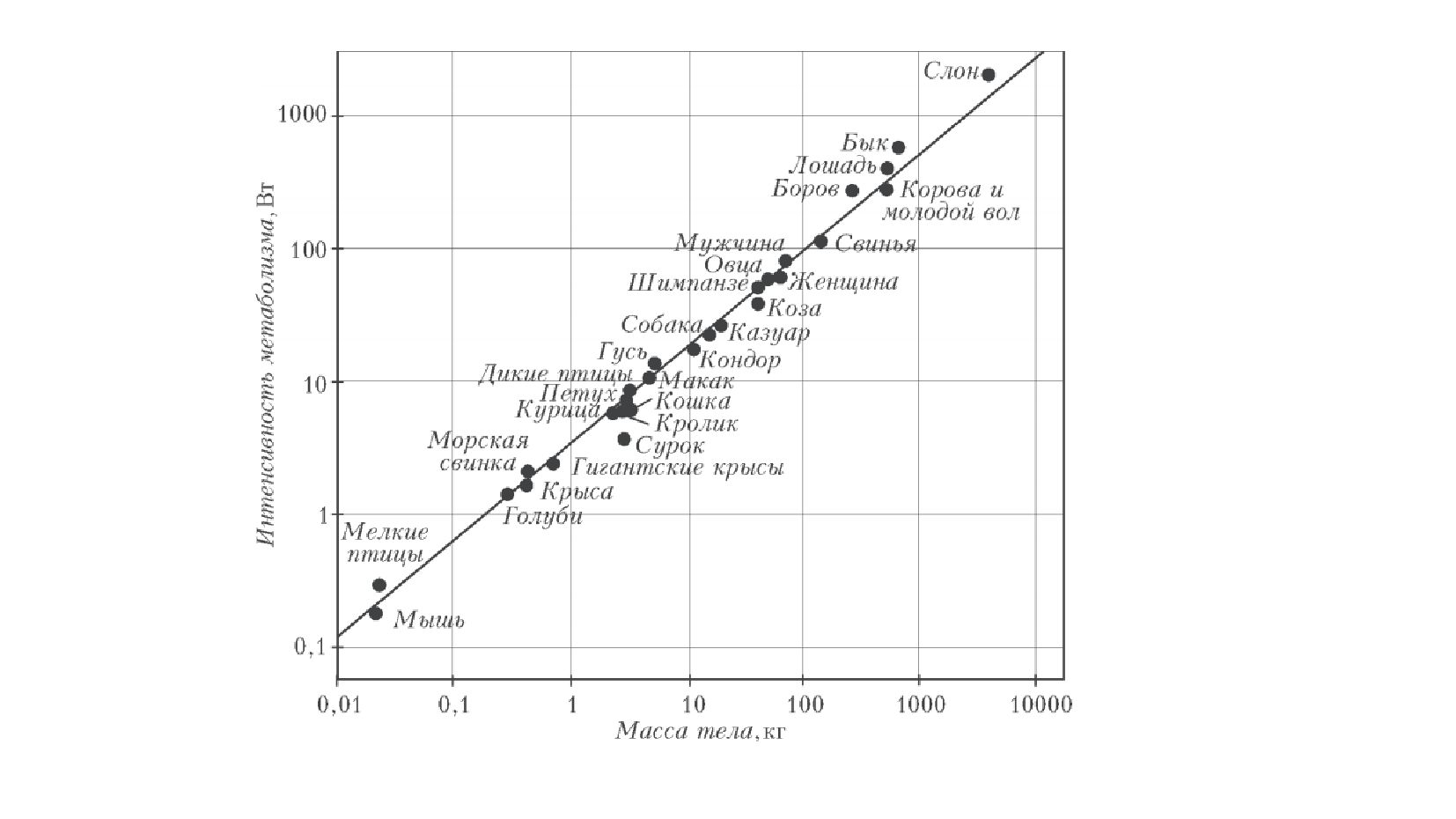
- Модель одномерной линейной регрессии для пары признаков
- Смысл предсказания
- Стандартизация переменных
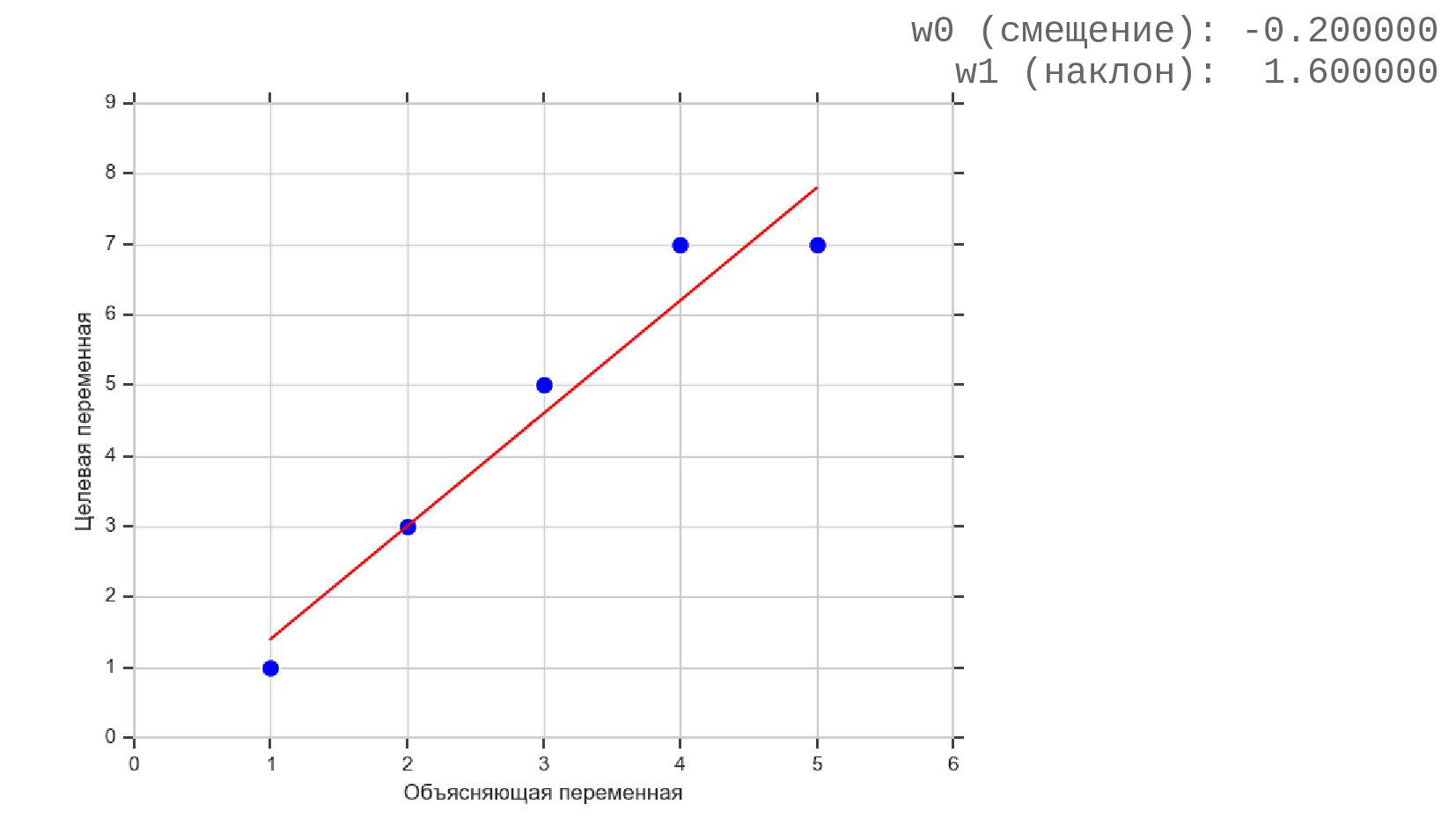
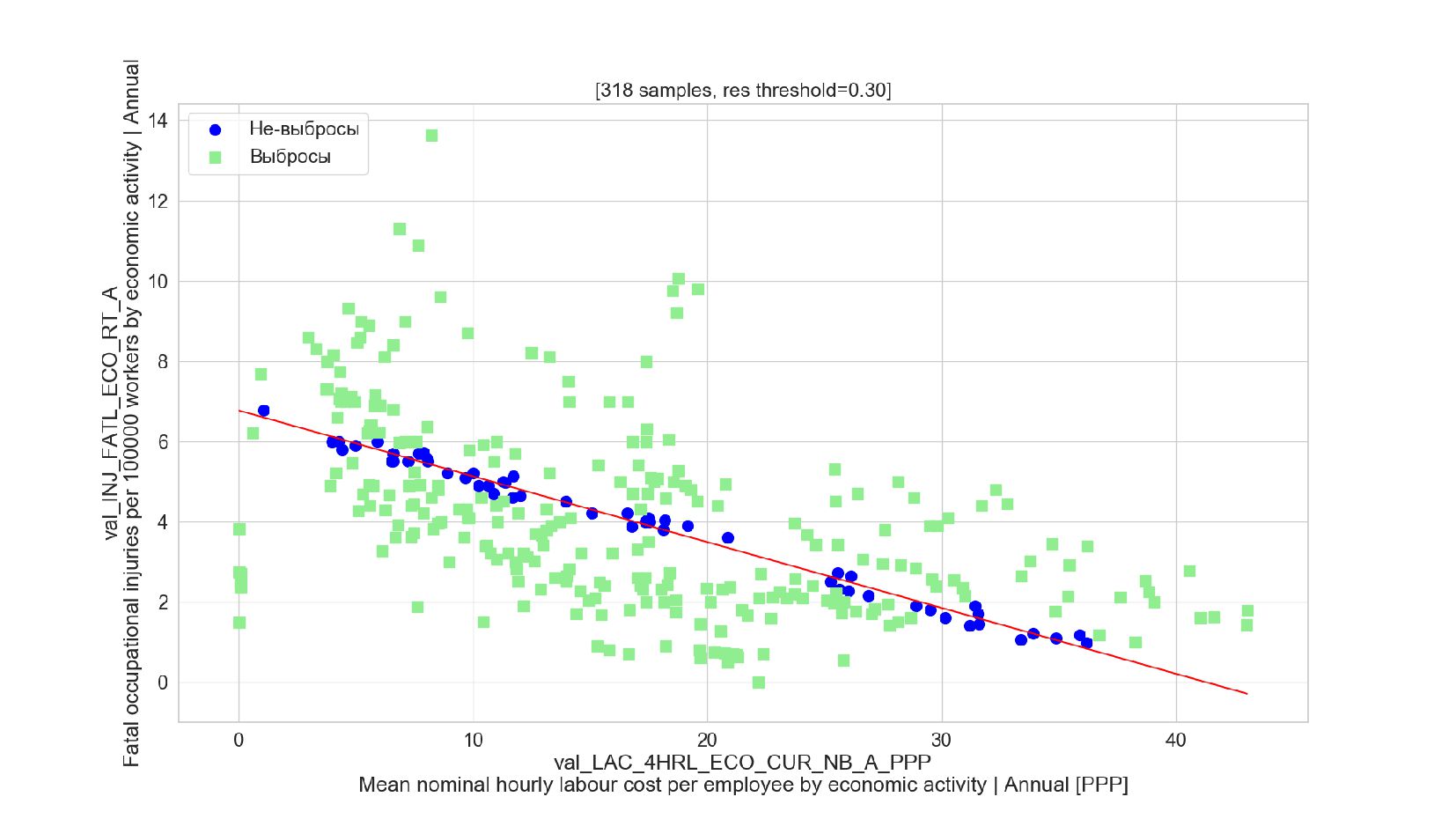
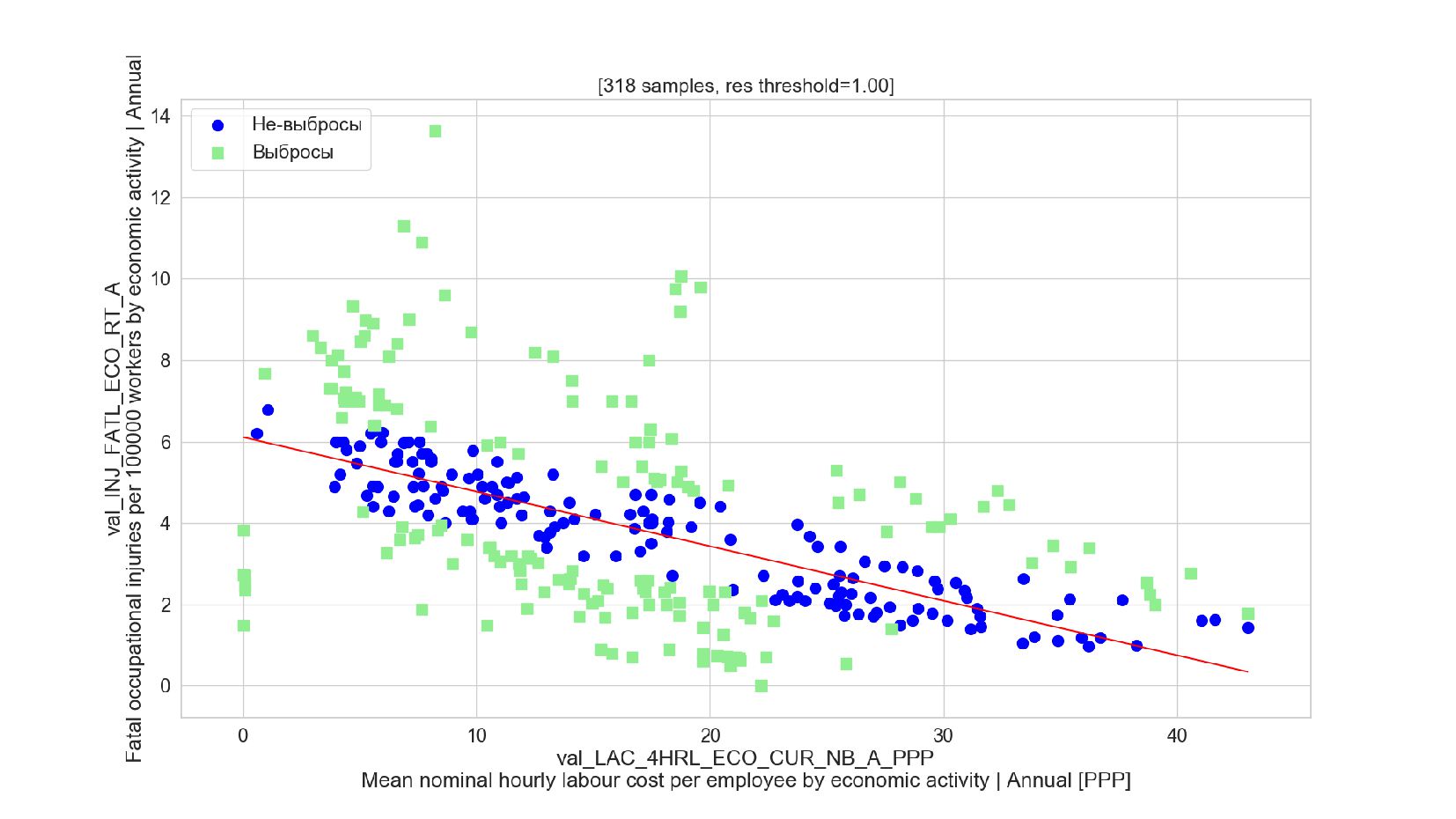
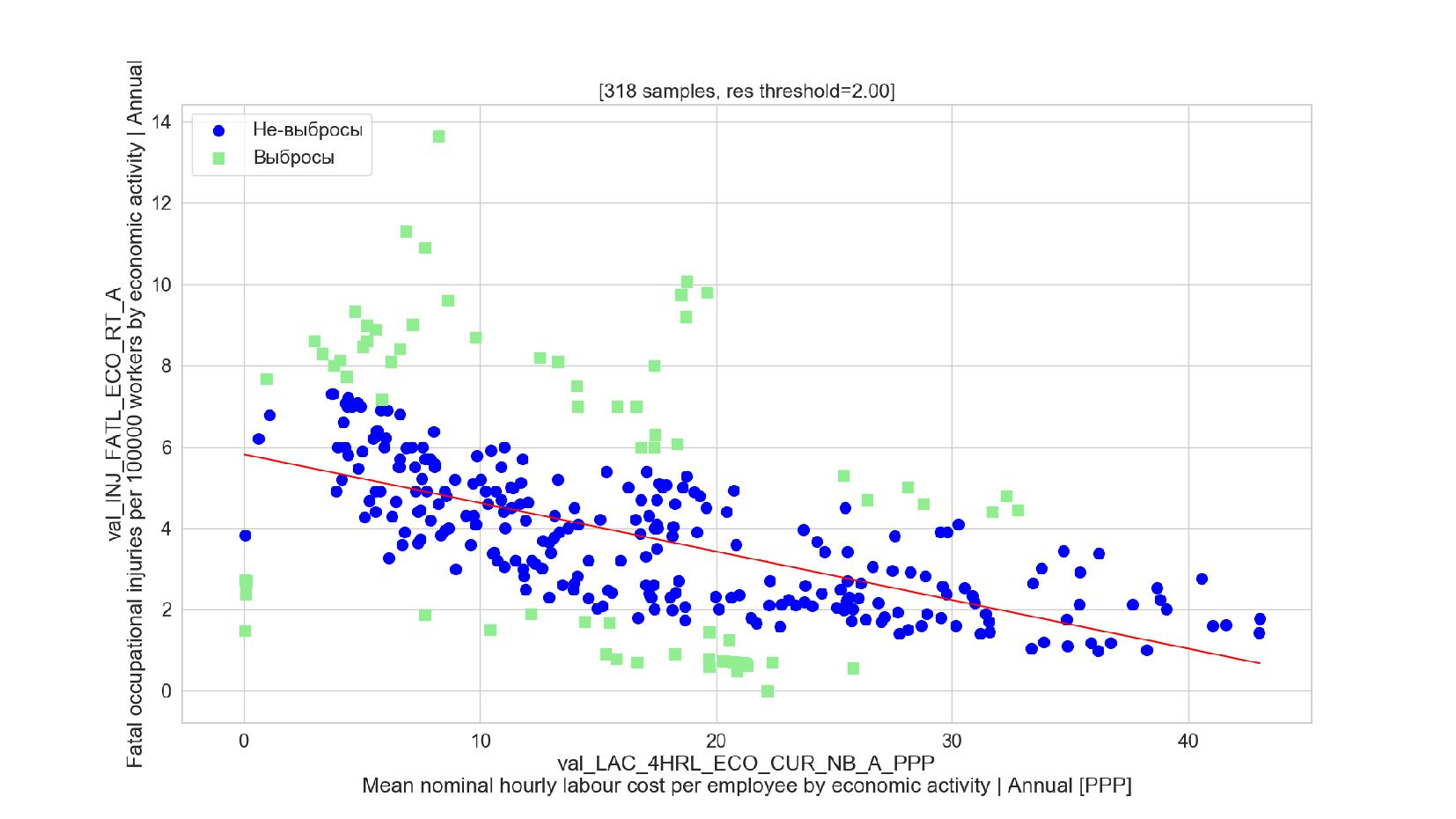
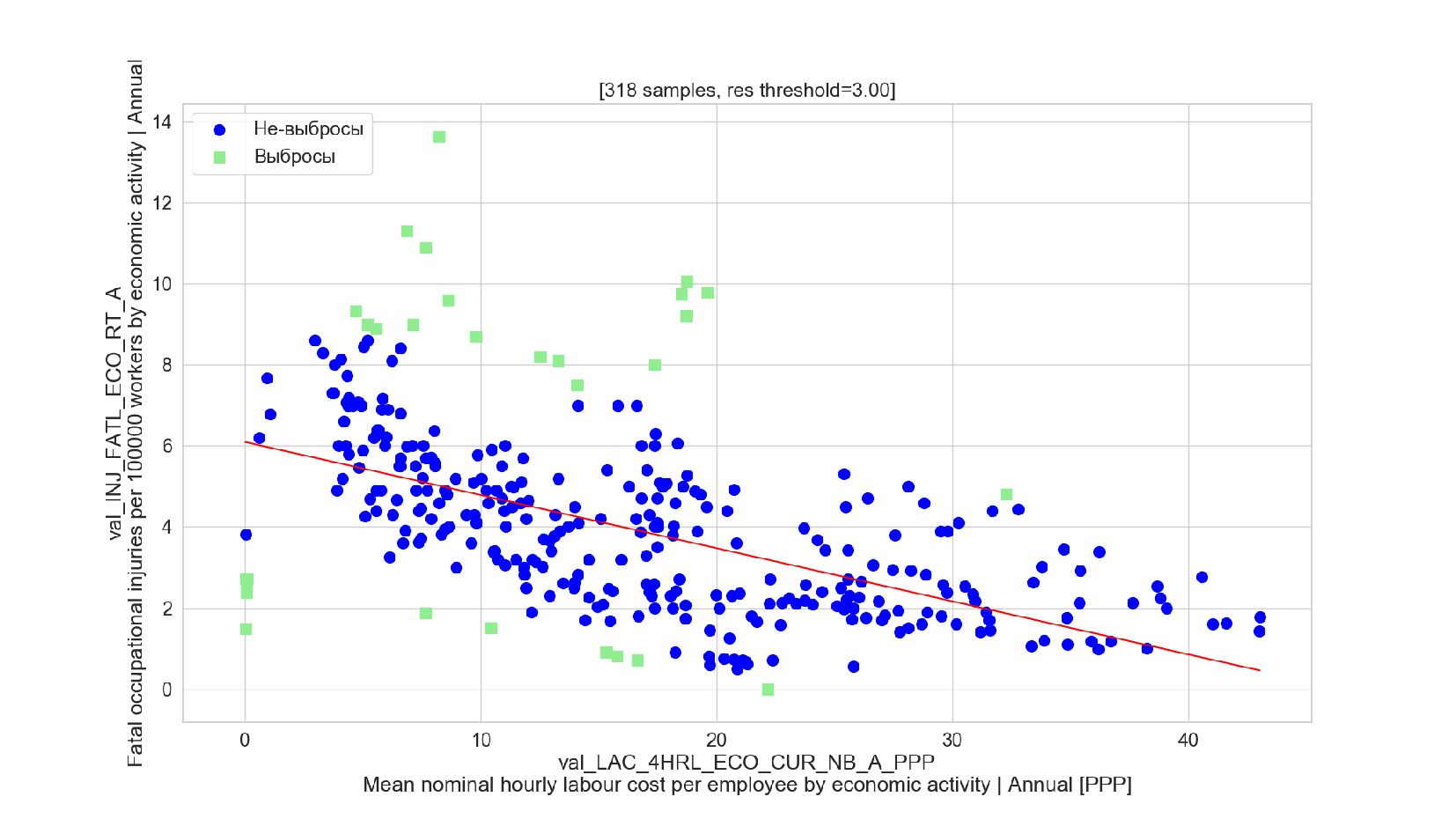
- Подгонка модели: удаление выбросов, алгоритм RANSAC
- Sklearn: RANSACRegressor
- Оценка качества модели
- Оценка качества: средневзвешенная квадратичная ошибка (MSE)
- Оценка качества: коэффициент детерминации R^2
- График остатков
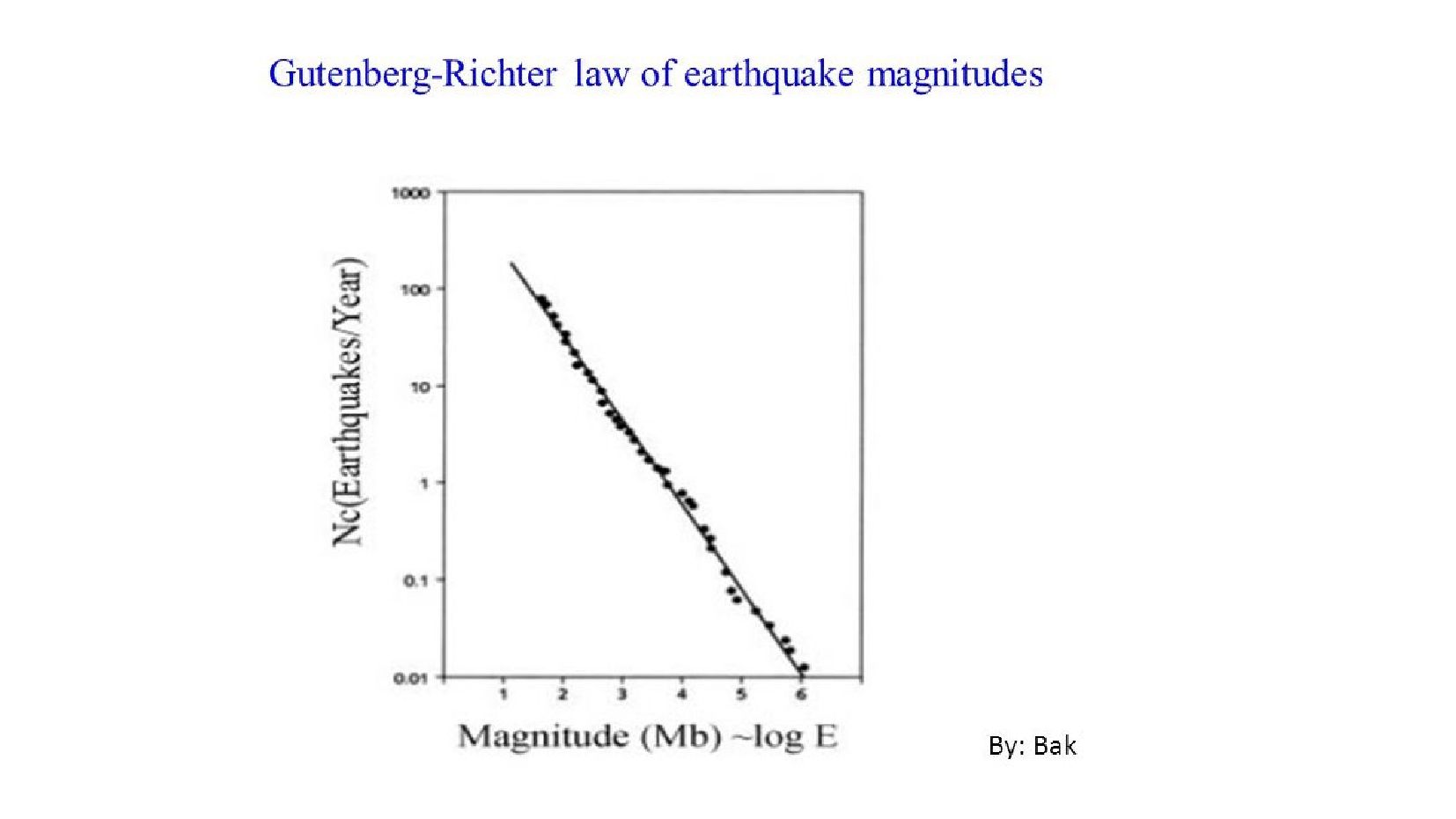
- Полиномиальная модель регрессии
- Sklearn: LinearRegression + PolynomialFeatures
- Многомерная линейная регрессия: модель регресси для нескольких параметров
- Пример: две объясняющие колонки и одна целевая - модель, график (3Д)
лекция с данными ILO: 20.05.2021
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[[9.200e-01] [1.050e+00] [7.640e+00] [8.220e+00] [2.012e+01] ... [1.178e+01] [1.408e+01] [8.040e+00] [9.710e+00]](https://files.speakerdeck.com/presentations/16a0ef9b6a30458e8b6756e381a3711a/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
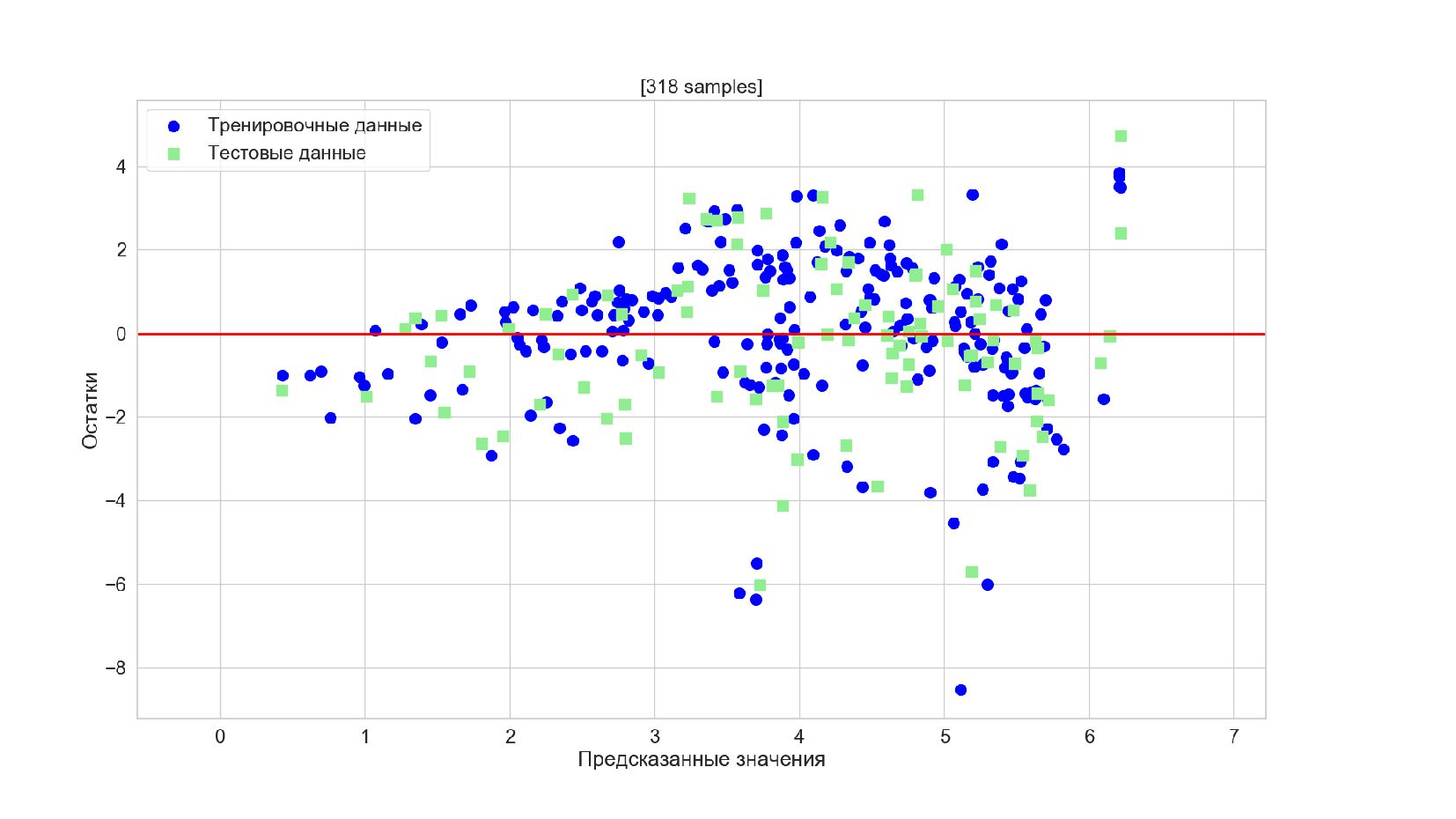{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
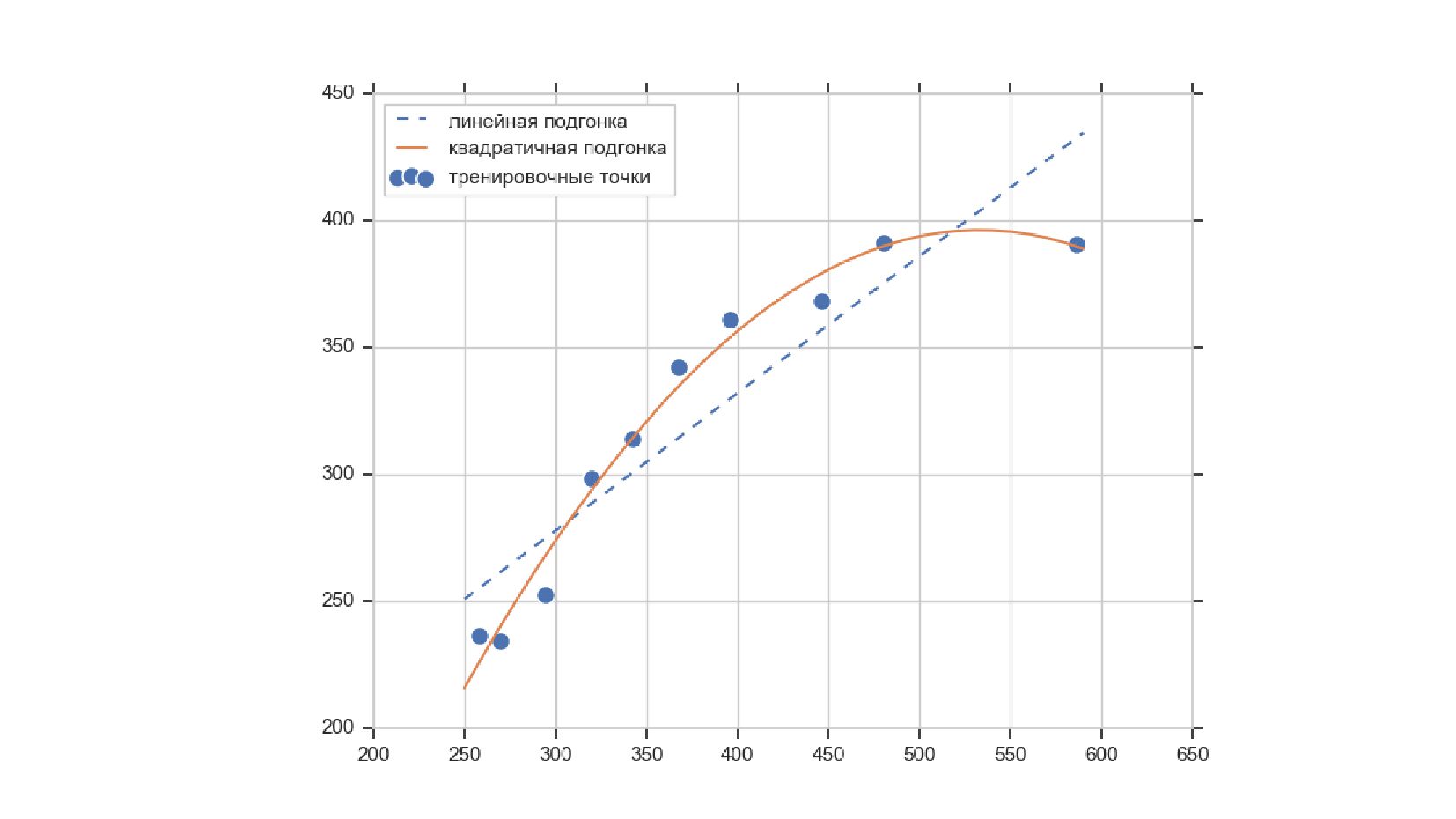{kind=link}
{kind=link}
![regr = LinearRegression() X_fit = np.arange(X.min(), X.max())[:, np.newaxis] # линейная](https://files.speakerdeck.com/presentations/16a0ef9b6a30458e8b6756e381a3711a/slide_66.jpg){kind=link}
{kind=link}
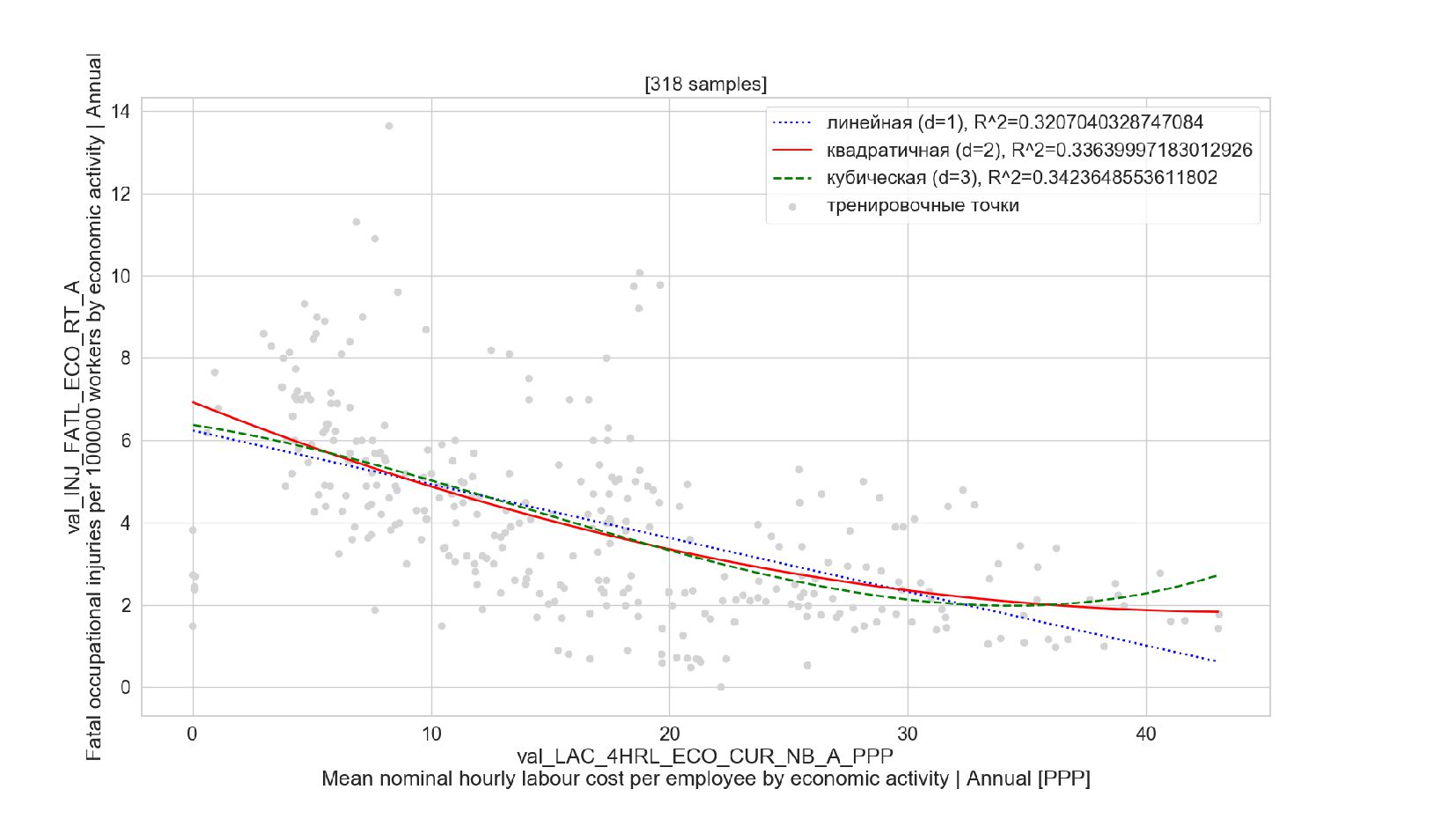{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
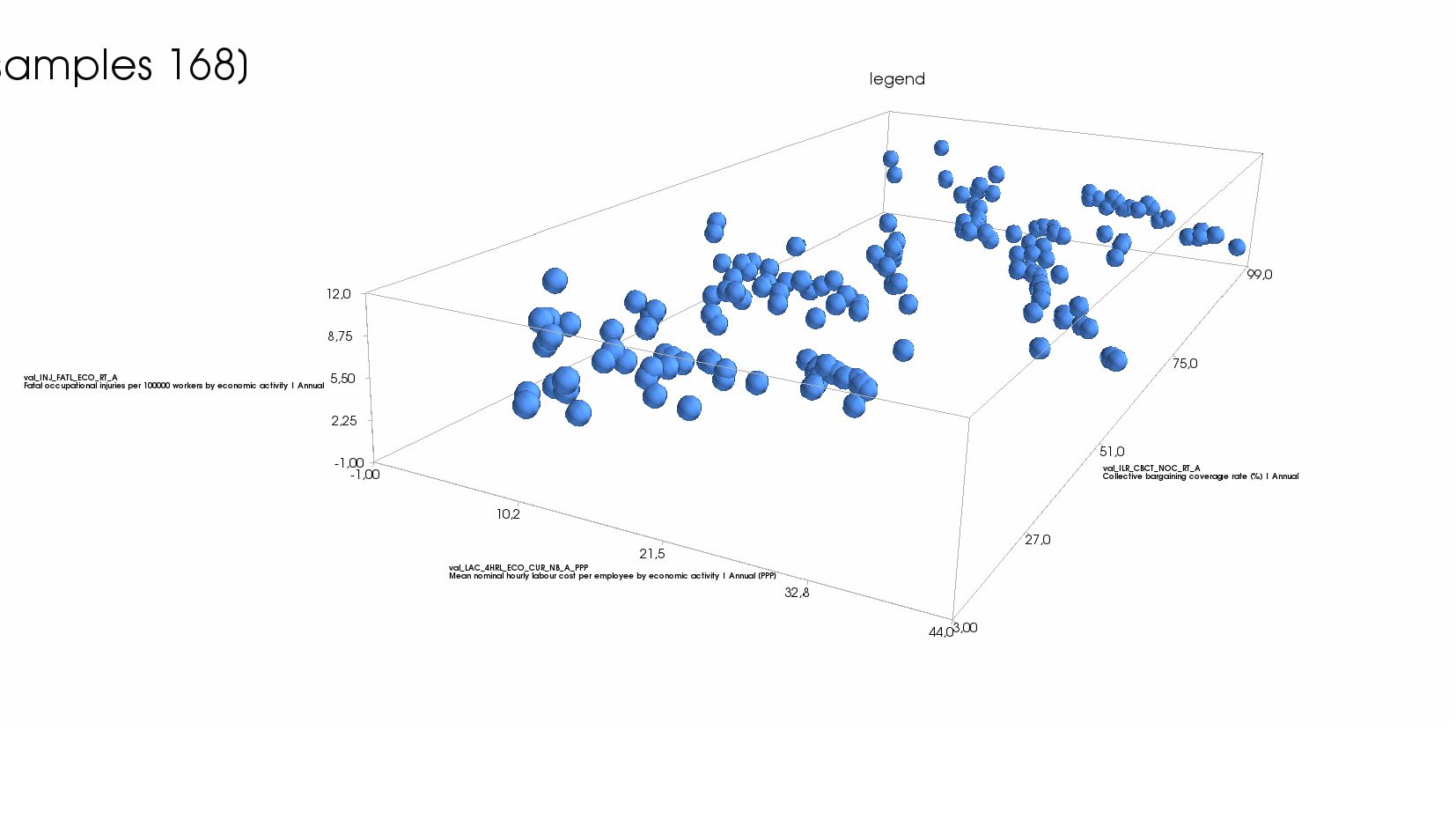{kind=link}
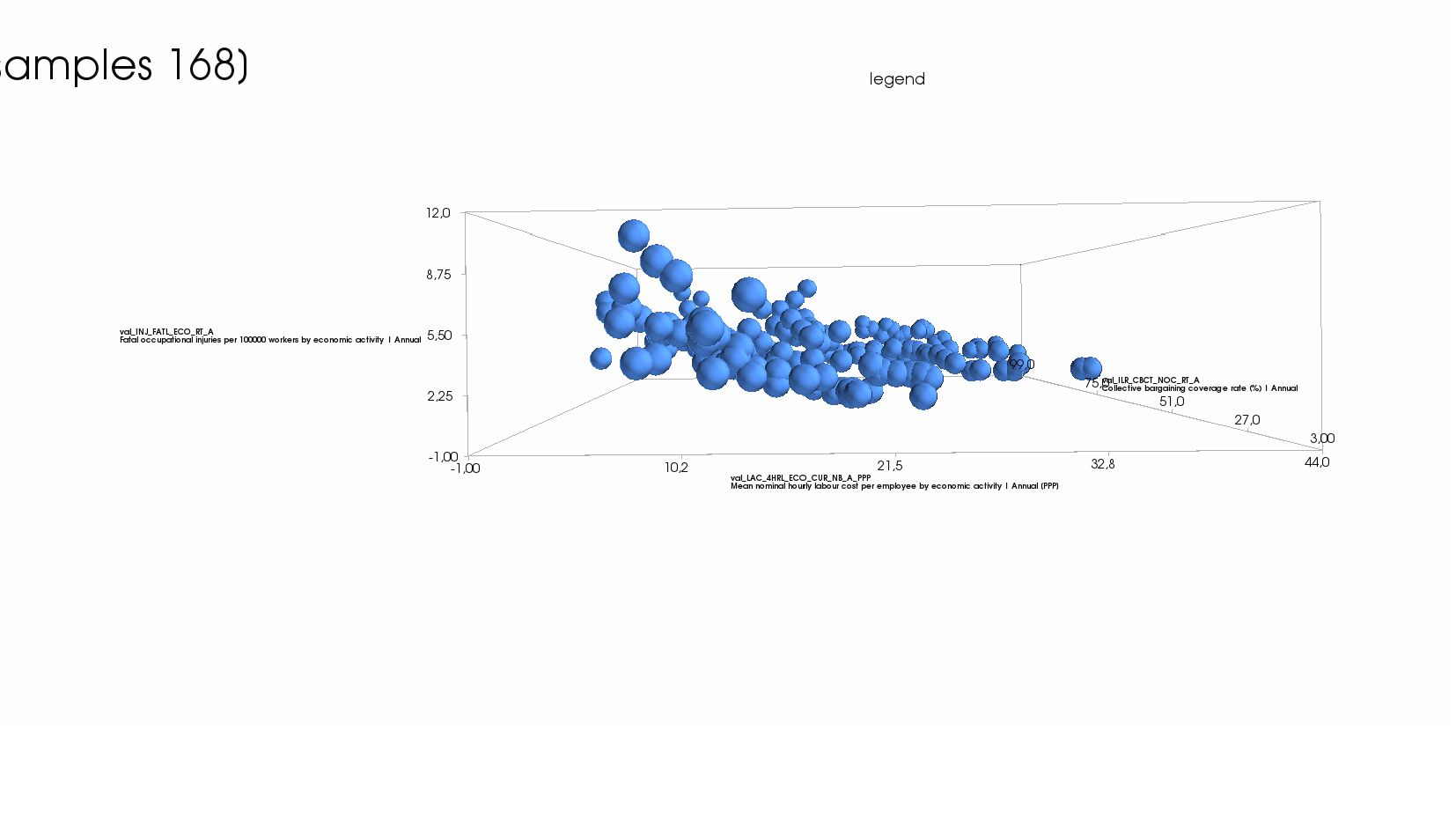{kind=link}
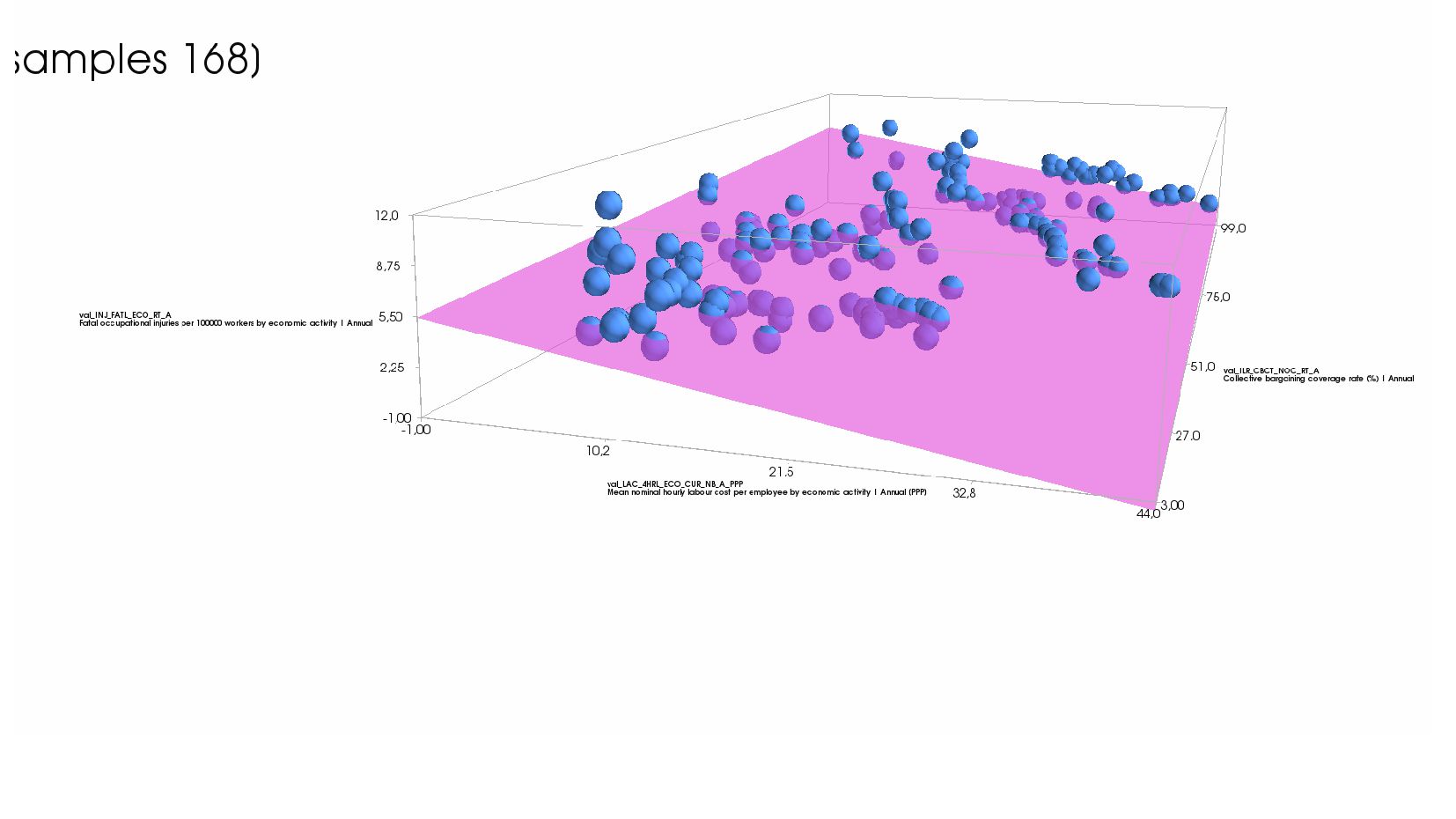{kind=link}
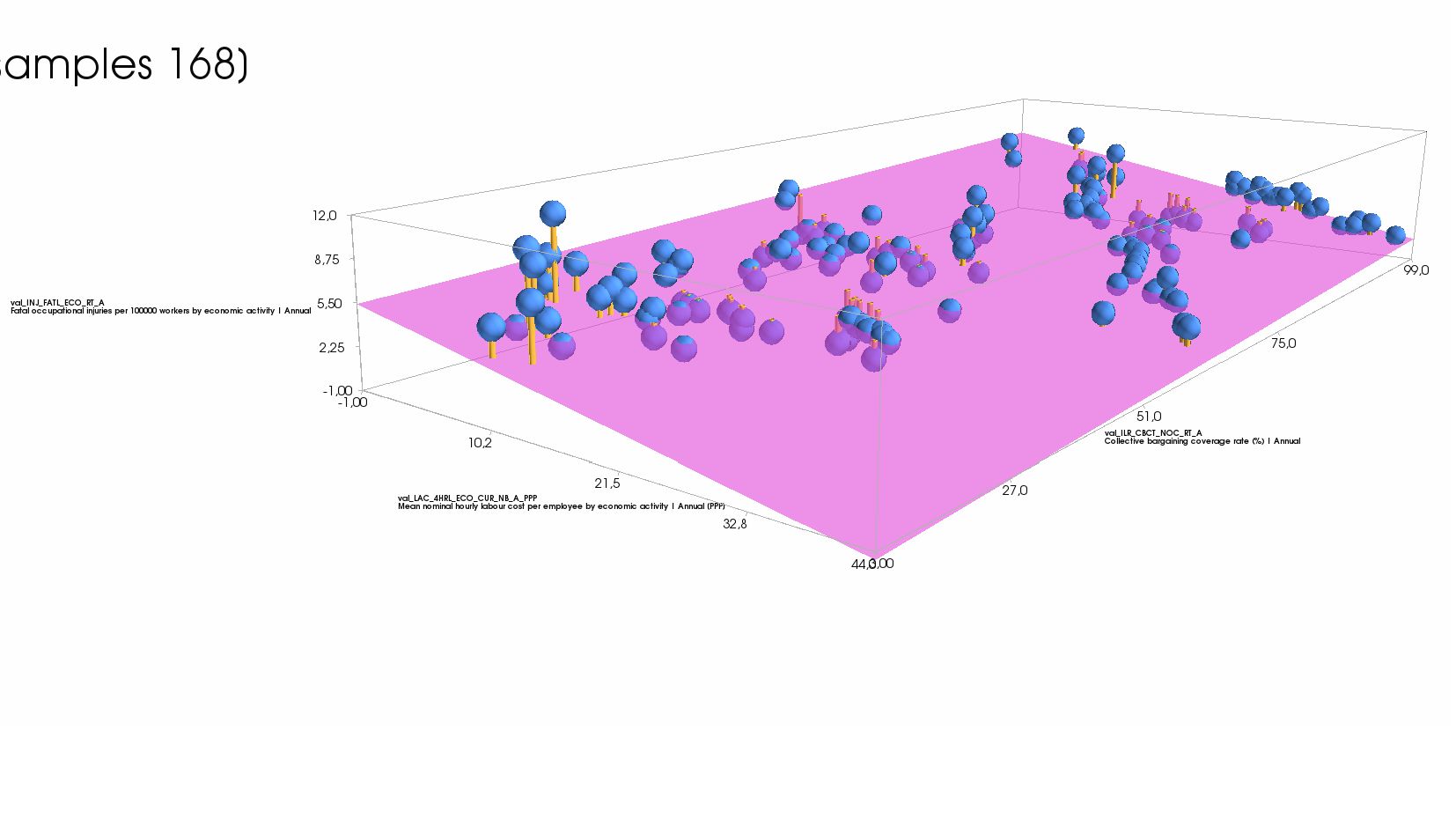{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
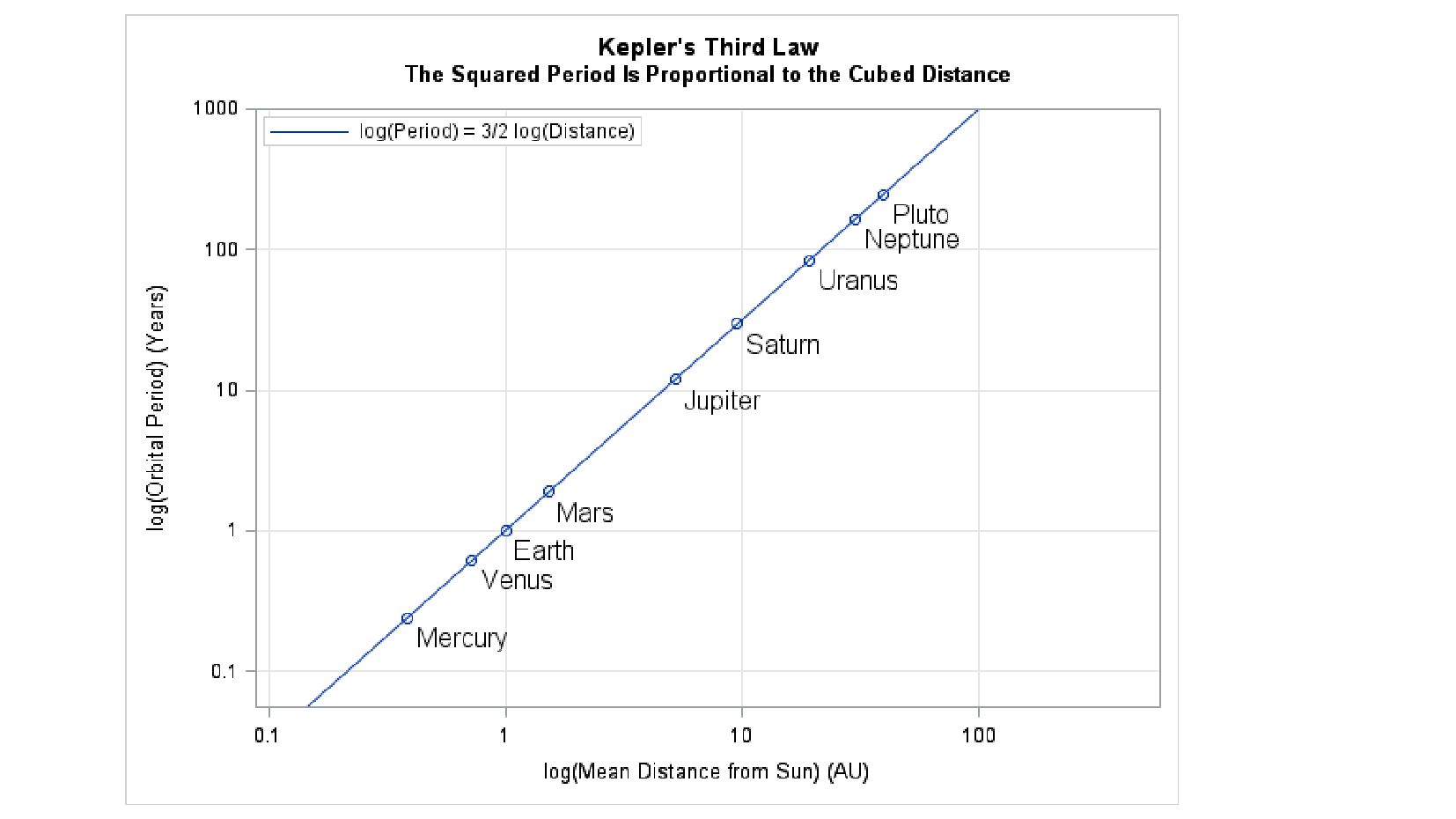{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}