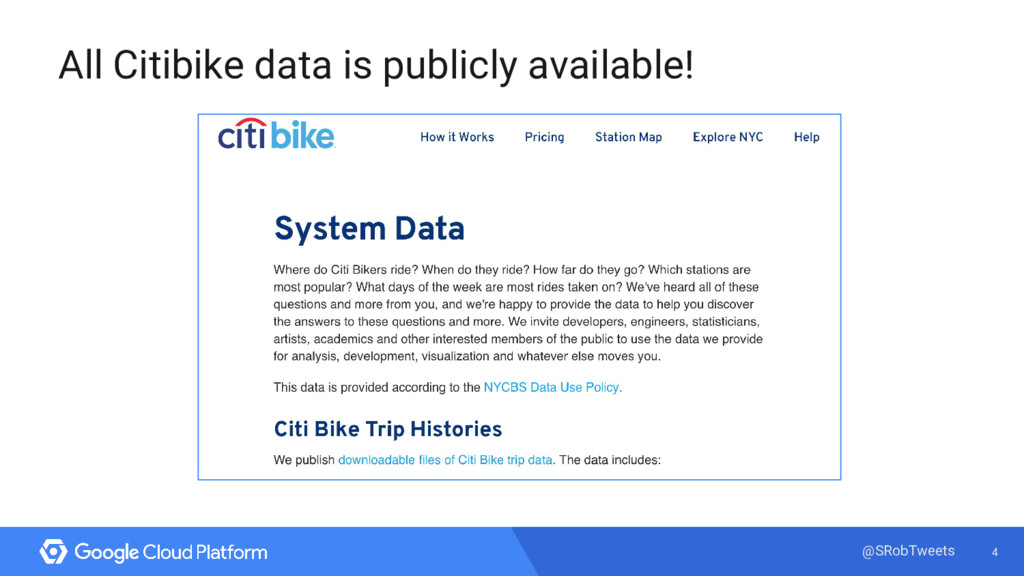
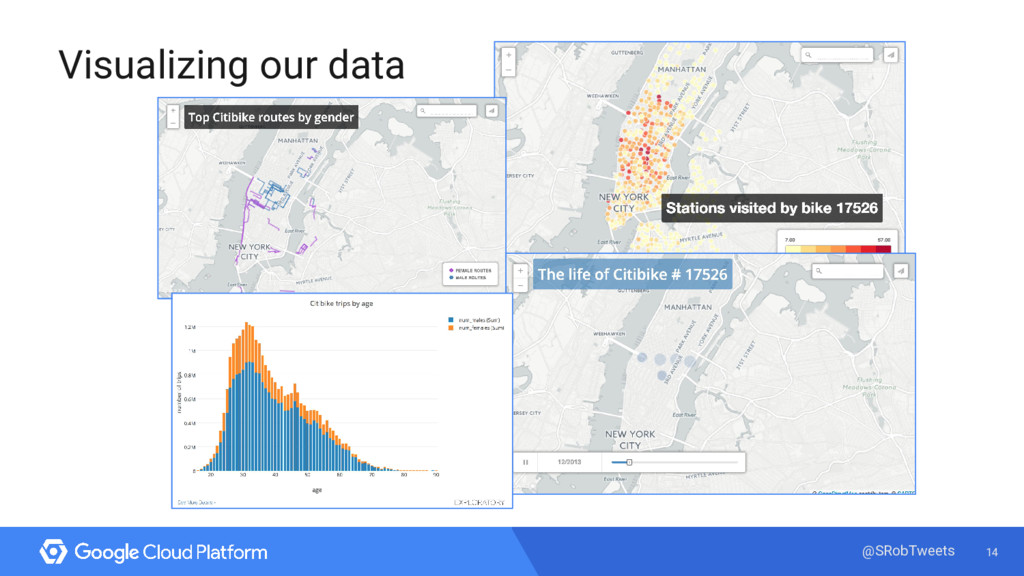
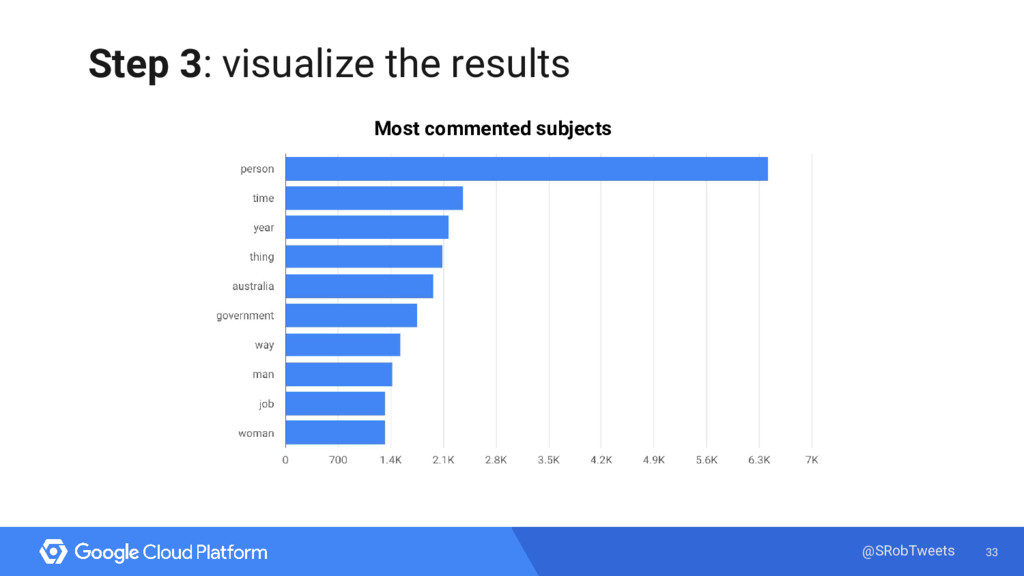
With so many people using NYC’s bike share program, I wanted to see if I could spot any trends in usage. But how did I go from observing bikers on the street to creating visualizations of popular routes based on different biker demographics?
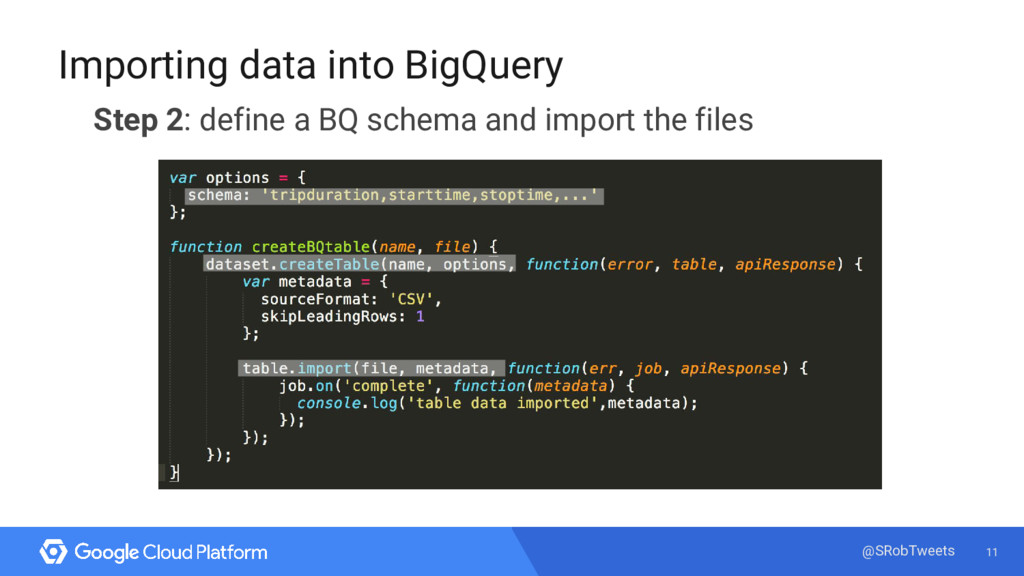
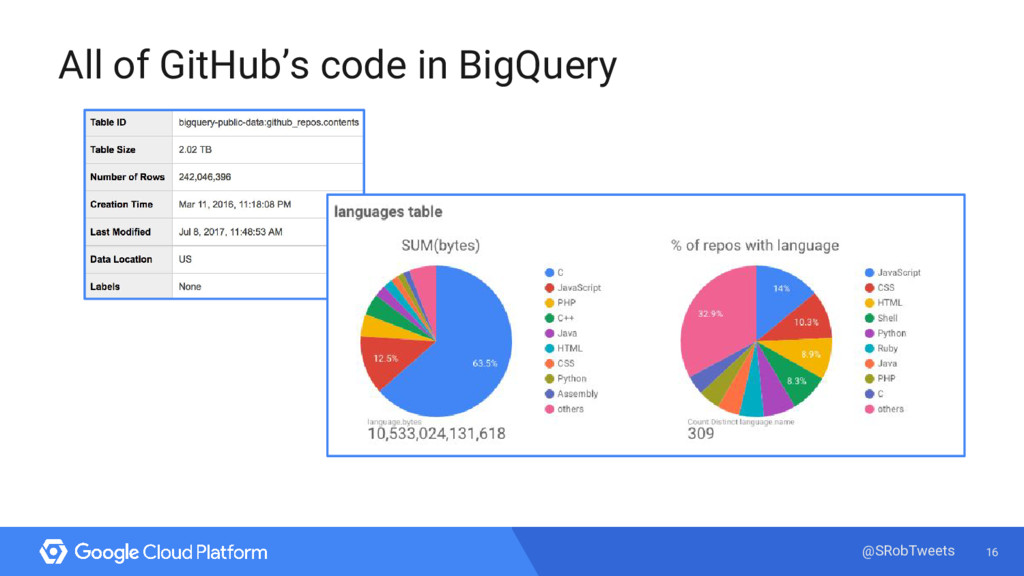
Enter Google’s managed big data analytics warehouse tool - BigQuery! Using BigQuery, I ran queries on 33 million bike trips and integrated my findings with a few visualization tools. I’ll explain my process, do some live queries, and show you how to do the same analysis with your own data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
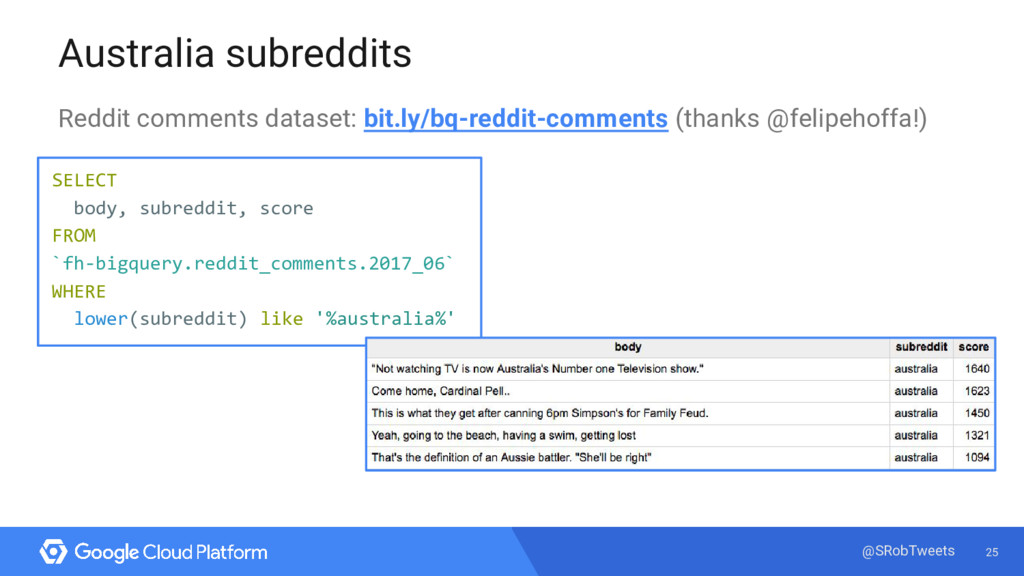{kind=link}
{kind=link}
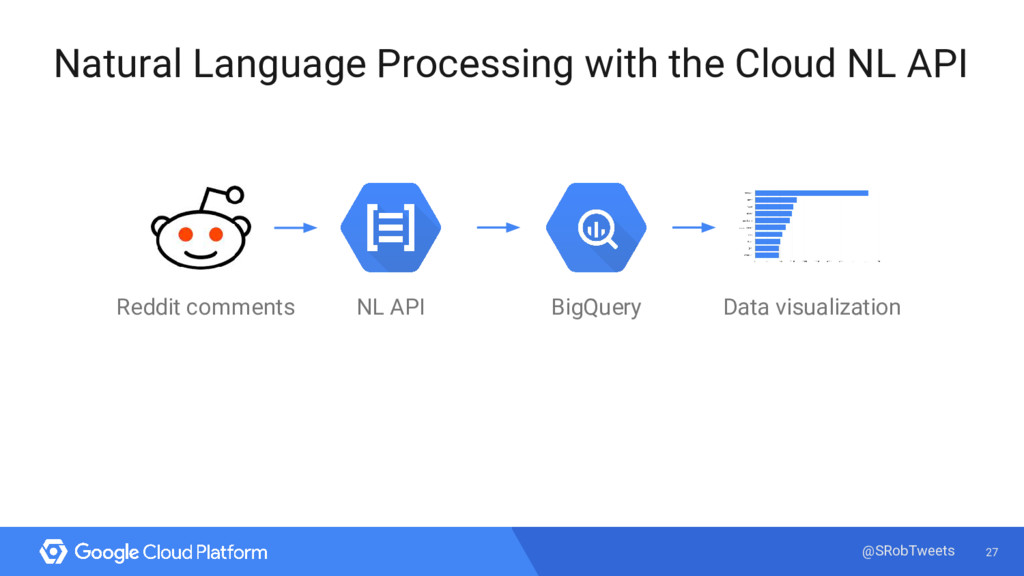{kind=link}
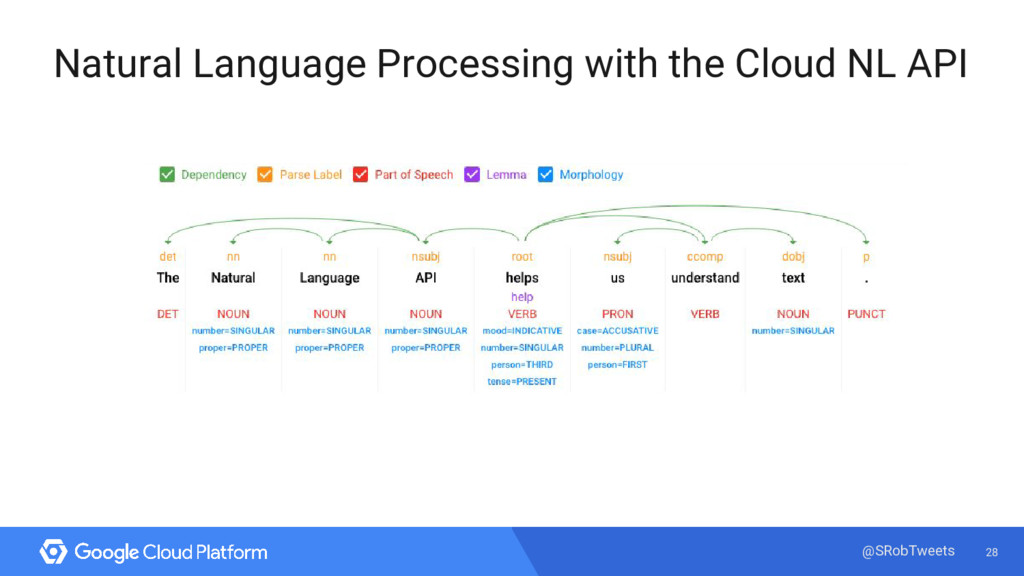{kind=link}
{kind=link}
{kind=link}
{kind=link}
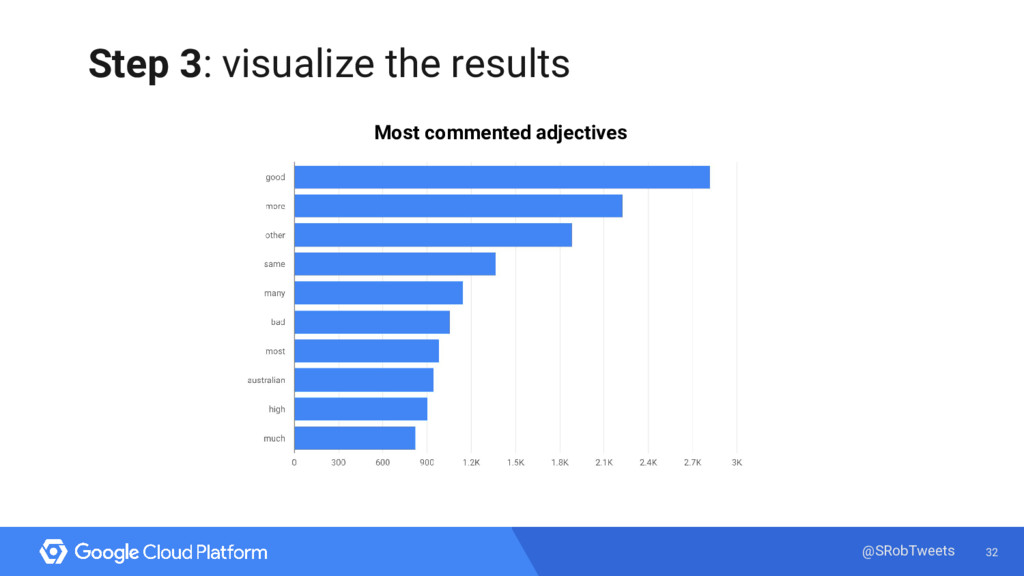{kind=link}
{kind=link}
{kind=link}
{kind=link}