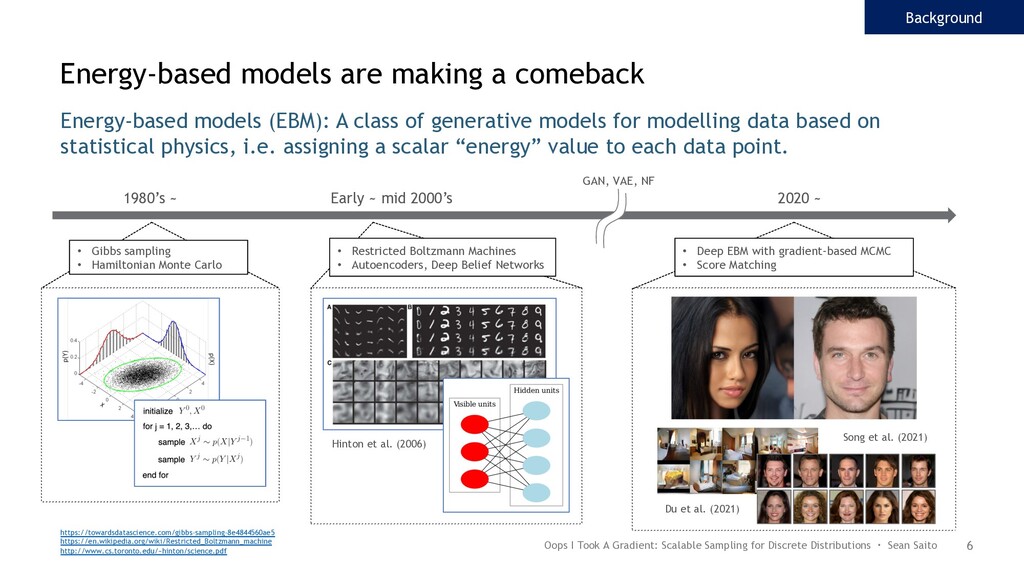
of energy based models." arXiv preprint arXiv:2012.01316 (2020). • Grathwohl, Will, et al. "Oops I Took A Gradient: Scalable Sampling for Discrete Distributions." arXiv preprint arXiv:2102.04509 (2021). • Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. "Reducing the dimensionality of data with neural networks." science 313.5786 (2006): 504-507. • Larochelle, Hugo, and Yoshua Bengio. "Classification using discriminative restricted Boltzmann machines." Proceedings of the 25th international conference on Machine learning. 2008. • Song, Yang, and Diederik P. Kingma. "How to train your energy-based models." arXiv preprint arXiv:2101.03288 (2021). Oops I Took A Gradient: Scalable Sampling for Discrete Distributions ・ Sean Saito 22 References
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
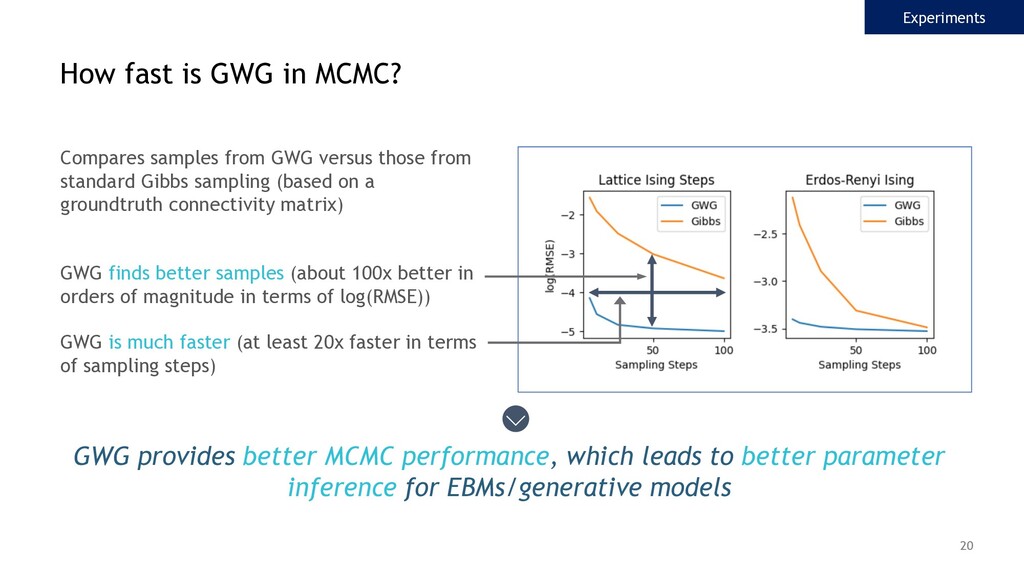{kind=link}
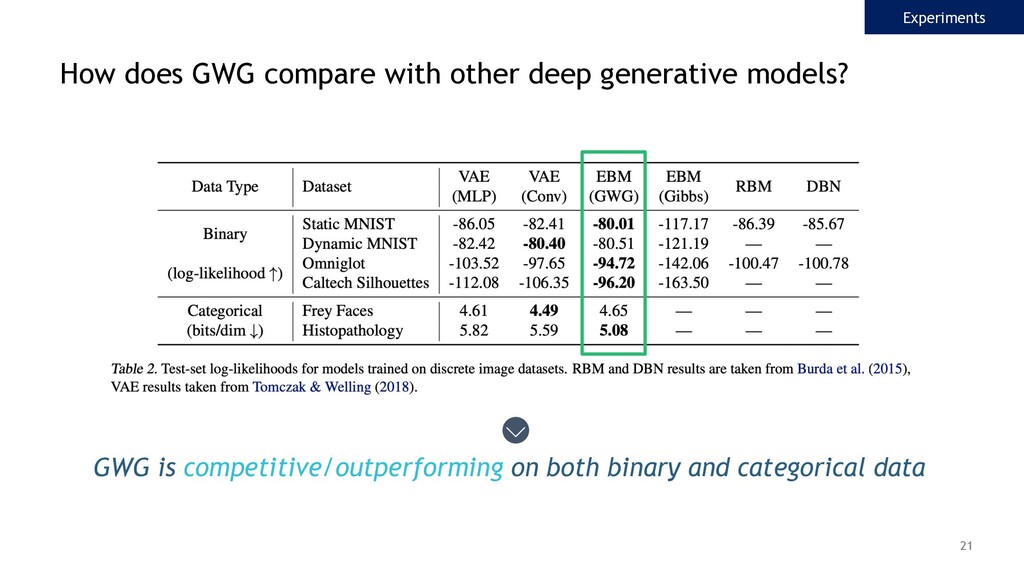{kind=link}
{kind=link}