modelin belirli bir görev için yeniden optimize edilmesi sürecidir. Genellikle büyük modellerin (örneğin, ResNet, BERT, GPT) öğrendiği temel özelliklerin korunarak son katmanlarının yeni bir göreve uyarlanmasını içerir.
(örneğin, kenar ve doku tespiti) korunmasıyla modelin belirli bir görevi daha iyi öğrenmesi sağlanır. Zaman ve Kaynak Tasarrufu: Büyük bir modeli sıfırdan eğitmek hem yüksek işlem gücü hem de uzun zaman gerektirir. Önceden eğitilmiş modeli temel alarak, eğitim süreci önemli ölçüde kısalır. Sınırlı Veriyle Yüksek Performans: Yeni bir görev için az veriye sahip olduğunuzda, fine tuning mevcut modelin genel özelliklerini kullanarak verimli bir şekilde öğrenmeyi sağlar. Göreve Özel Optimizasyon:
geniş veri kümelerinde öğrendiği özellikler yeni görevlere taşınarak daha hızlı ve yüksek doğruluk elde edilir. Esneklik: Modelin son katmanları (veya seçilen ara katmanlar) kolayca değiştirilerek farklı problemlere uyarlanabilir. Düşük Maliyet: Sıfırdan eğitime göre daha az donanım ve zaman gerektirir.
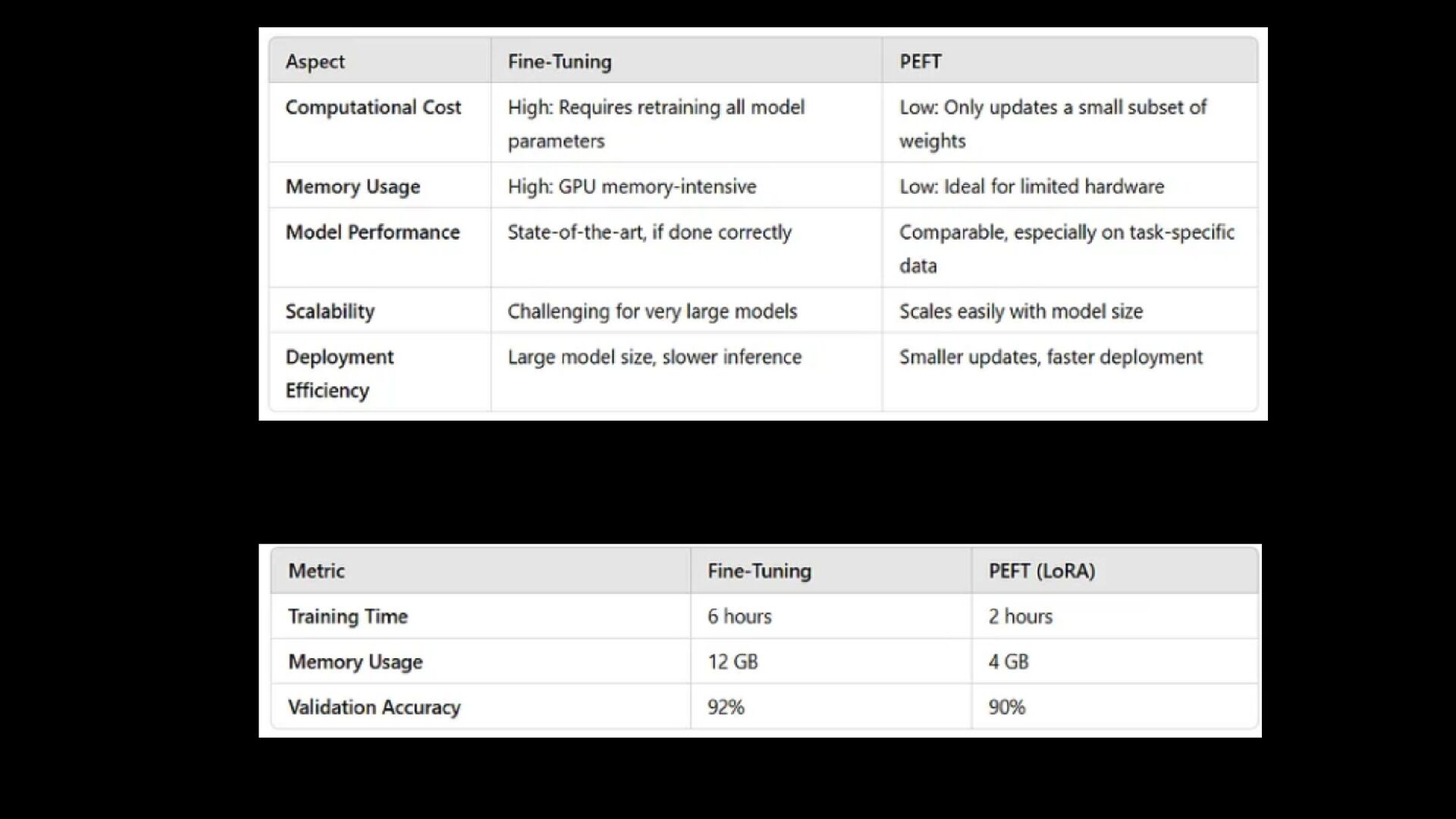
güncellenmesi aşırı uyuma yol açabilir. Hesaplama Maliyeti: Çok büyük modeller (örneğin, GPT-3) bile fine tuning için yüksek bellek ve GPU kullanımı gerektirebilir.
için güncellenmesi işlemidir. Bu, modelin tüm katmanlarının yeni veri üzerinde eğitilmesi anlamına gelir. Avantajları: En yüksek potansiyel doğruluğu sağlayabilir, çünkü model tamamen yeni göreve adapte olur. Eğer yeterli miktarda veri varsa, en iyi sonuçları verir. Dezavantajları: Hesaplama açısından maliyetlidir, özellikle büyük modellerde. Çok fazla GPU belleği ve zaman gerektirebilir. Overfitting riski yüksektir, özellikle küçük veri setlerinde. Büyük modellerde, ince fine-tuning)yapmak pratik olmayabilir. Full Fine Tuning
küçük bir parametre alt kümesini eğiterek, bellek ve işlem maliyetlerini düşürmeyi hedefler. Bu yöntemler, büyük dil modellerini (LLM'ler) daha erişilebilir hale getirmek için tasarlanmıştır.
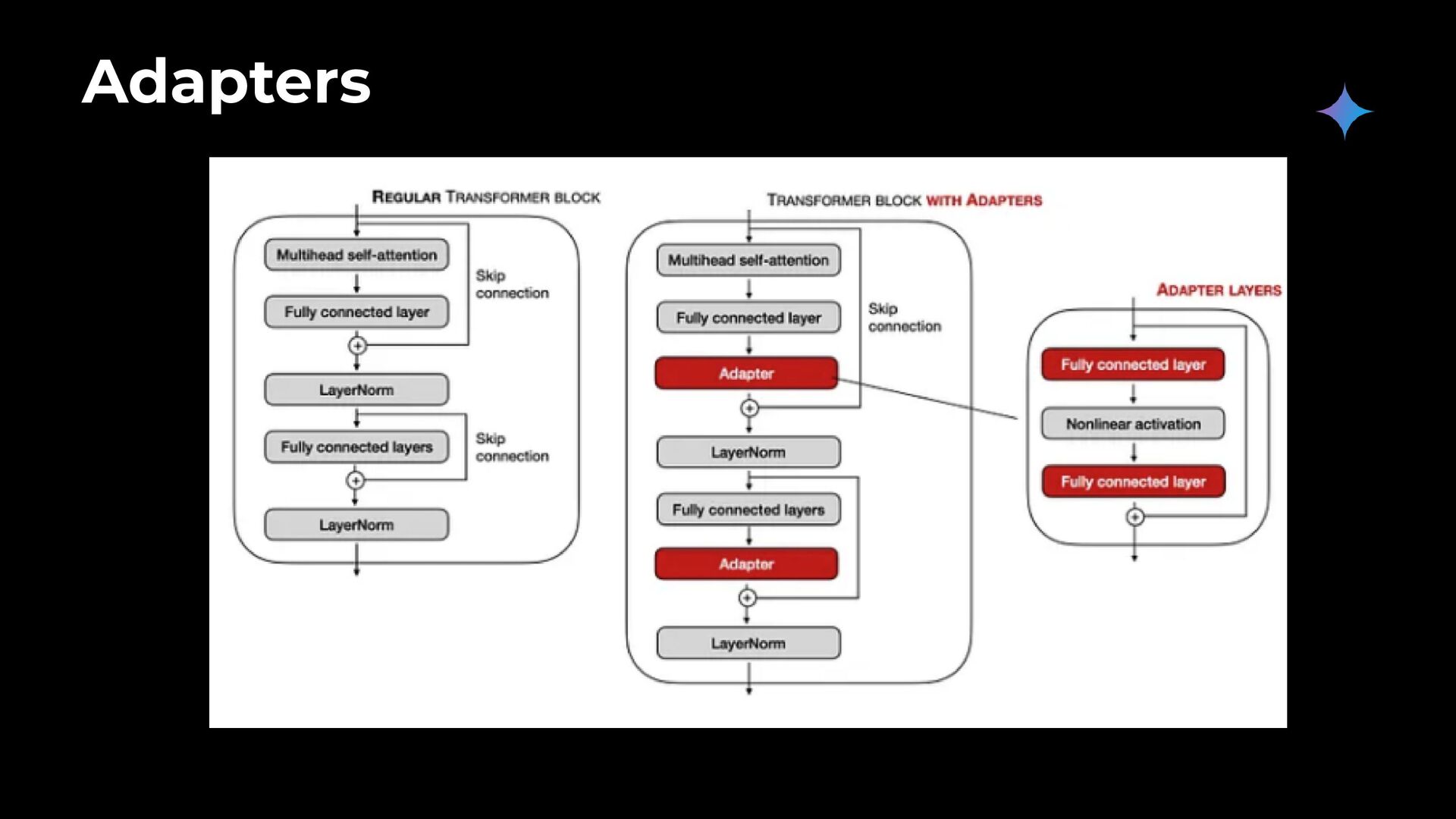
modüllerdir. Modelin orijinal parametreleri dondurulur ve sadece adapter modüllerinin parametreleri güncellenir. Avantajları: fine tuning maliyetini düşürür. Farklı görevler için farklı adapter'ler kullanılabilir, bu da modelin farklı görevlere adapte olmasını kolaylaştırır. Dezavantajları: Eklenen adapter modülleri, modelin karmaşıklığını artırabilir.
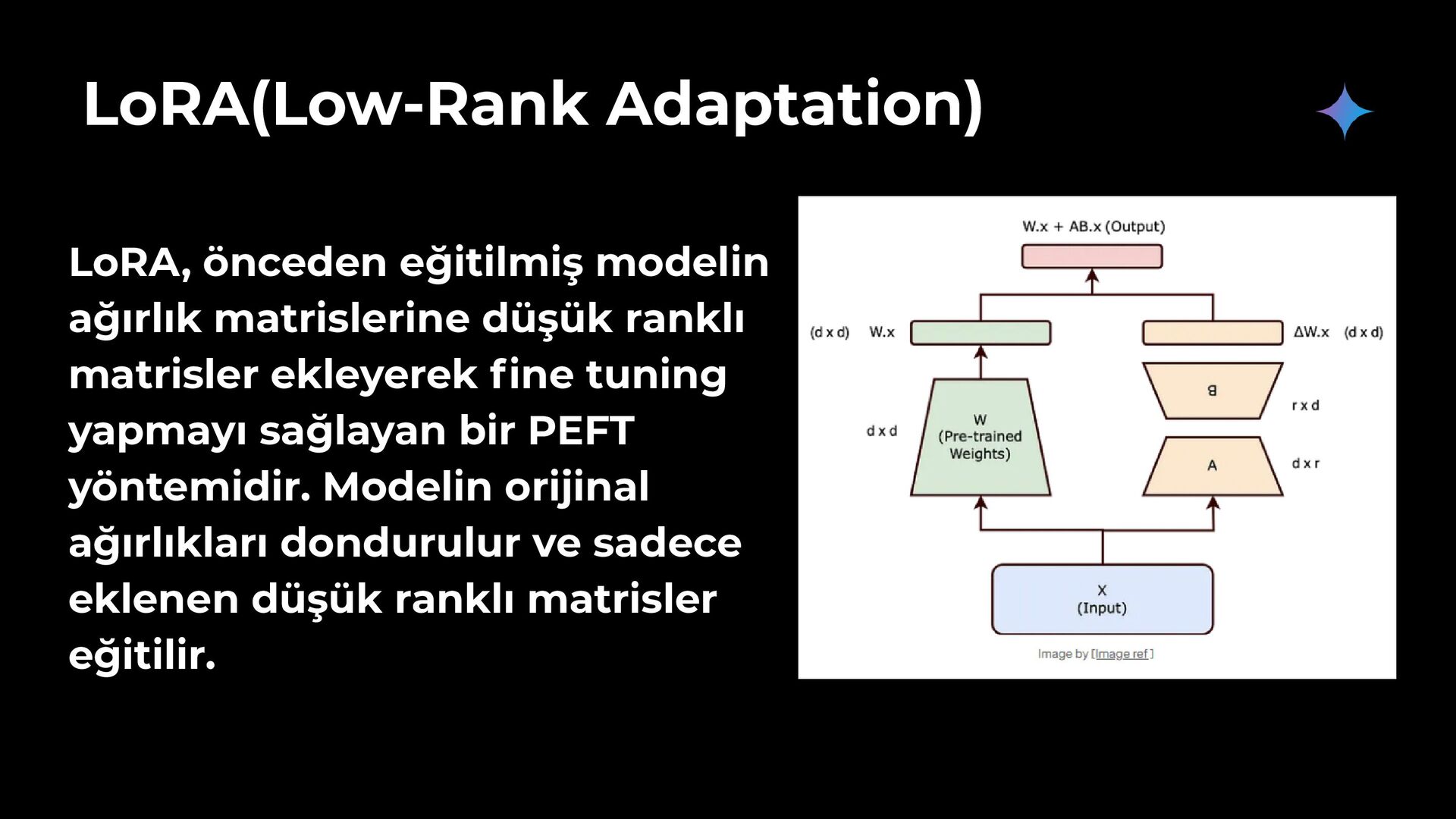
matrisler ekleyerek fine tuning yapmayı sağlayan bir PEFT yöntemidir. Modelin orijinal ağırlıkları dondurulur ve sadece eklenen düşük ranklı matrisler eğitilir.
fine tuning süreleri sağlar. Dezavantajları: Full fine tuning kadar yüksek doğruluk sağlamayabilir. Düşük ranklı matrislerin boyutu, performansı etkileyebilir.
fine tuning yapmayı sağlayan bir PEFT yöntemidir. Bu, bellek gereksinimlerini önemli ölçüde azaltır ve daha küçük GPU'larda bile büyük modellerin fine tune edilmesini mümkün kılar. QLoRA, düşük ranklı adaptasyon (LoRA) tekniğini kullanır. Avantajları: Çok düşük bellek kullanımı sağlar. Büyük modellerin daha erişilebilir donanımlarda fine tuning yapmayı mümkün kılar. Dezavantajları: Kuantizasyon nedeniyle bir miktar doğruluk kaybı olabilir.
içeren bir sıkıştırma tekniğidir. LLM'ler genellikle float32 veya float16 kayan nokta sayıları ile eğitilir. Kuantizasyon, FP32 ağırlık değerlerinin aralığını FP16 veya hatta INT4 (Integer 4 bit) veri türleri gibi daha düşük hassasiyetli değerlere temsil etmenin bir yolunu bulmaya çalışır. Kuantizasyon - Quantization
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}