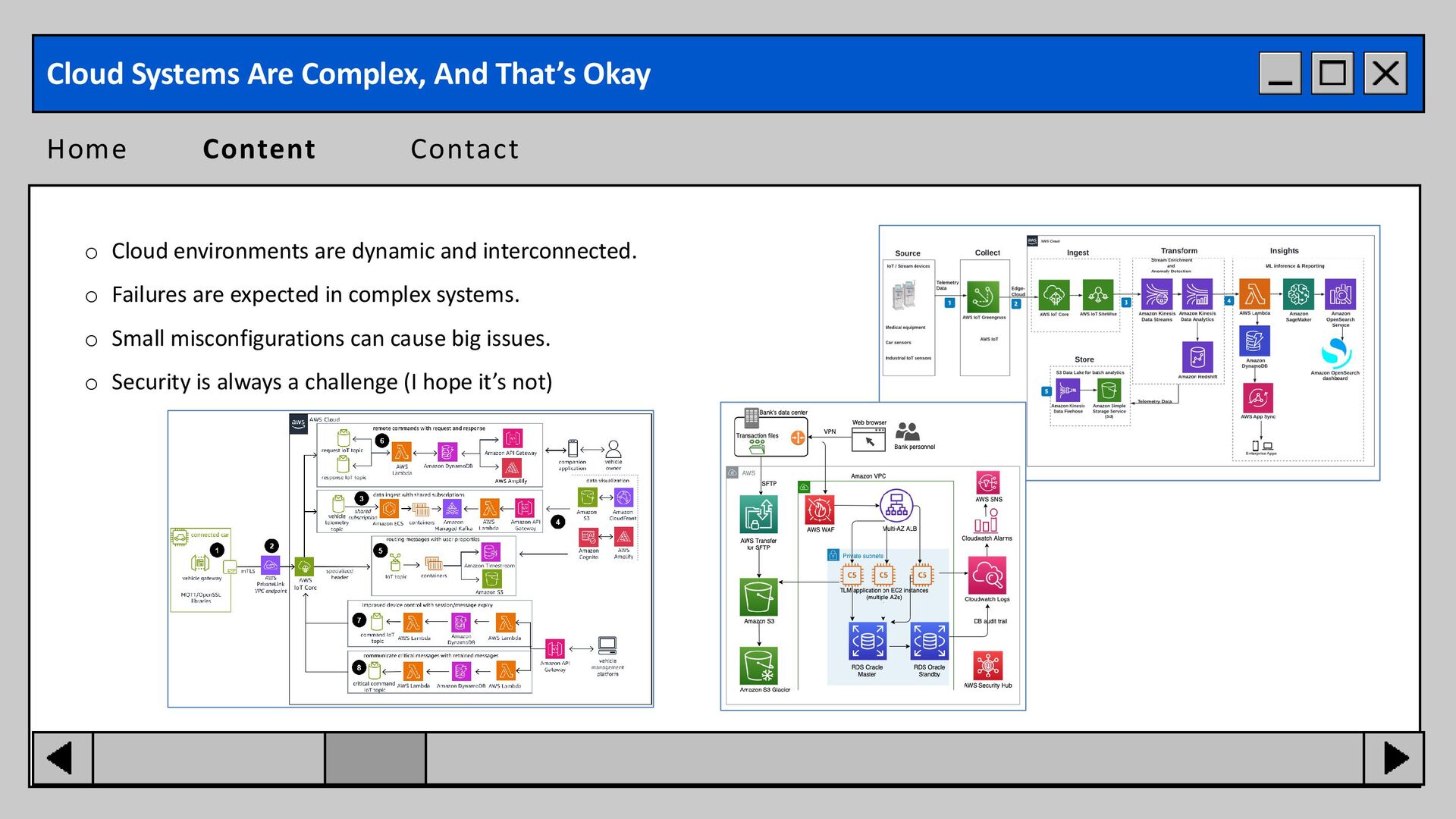
expected in complex systems. o Small misconfigurations can cause big issues. o Security is always a challenge (I hope it’s not) Home Content Contact Cloud Systems Are Complex, And That’s Okay
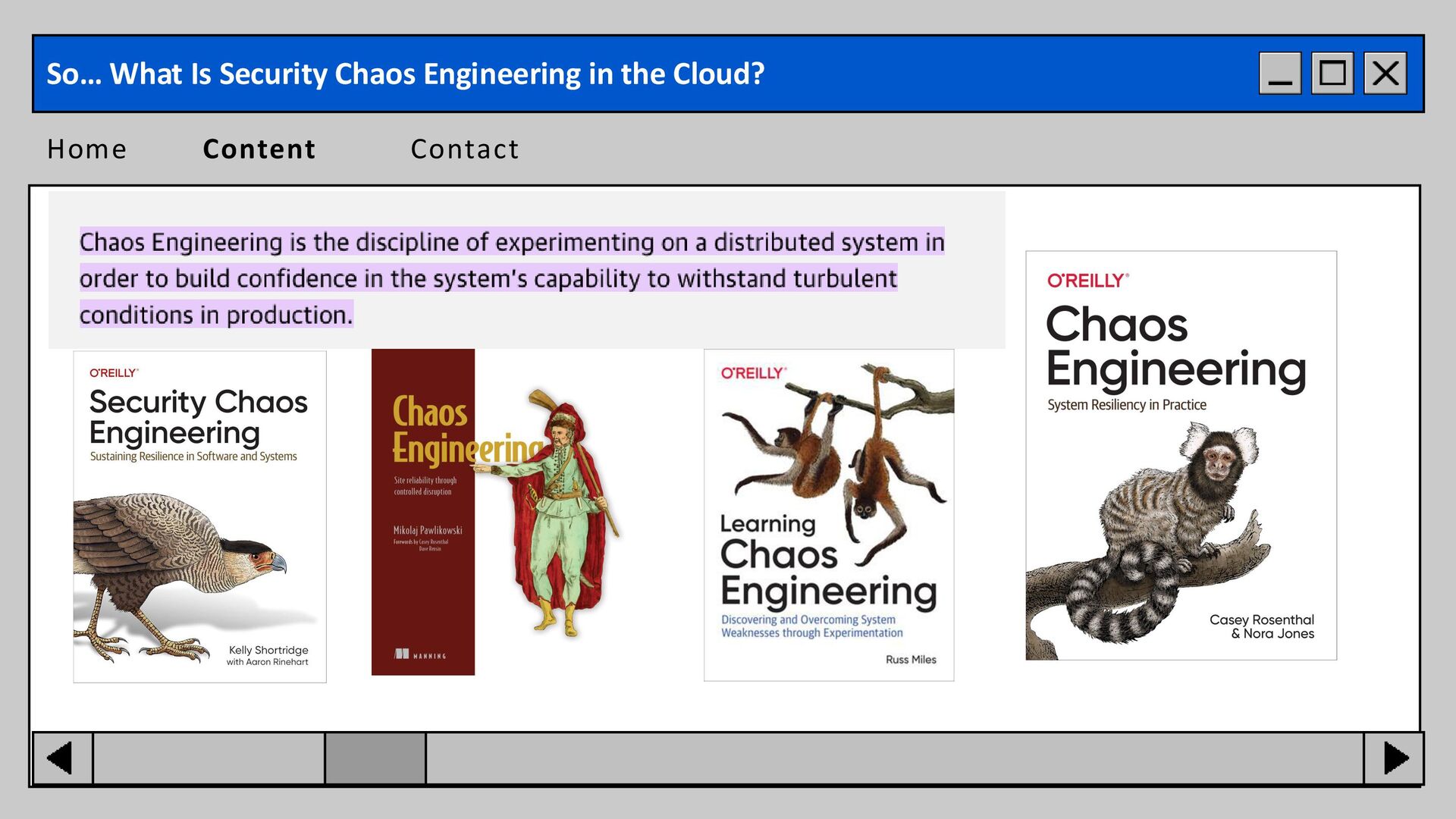
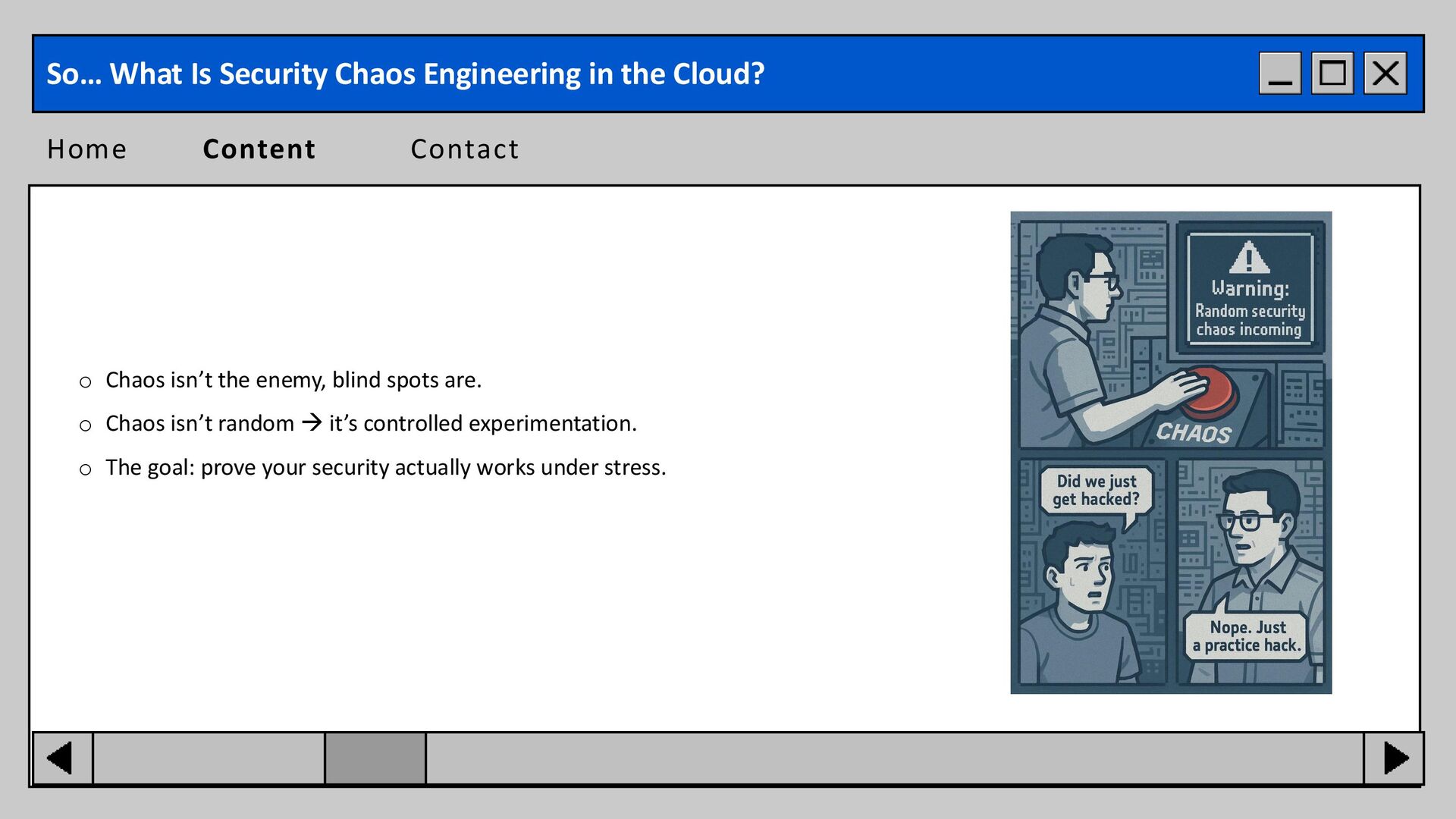
isn’t random → it’s controlled experimentation. o The goal: prove your security actually works under stress. Home Content Contact So… What Is Security Chaos Engineering in the Cloud?
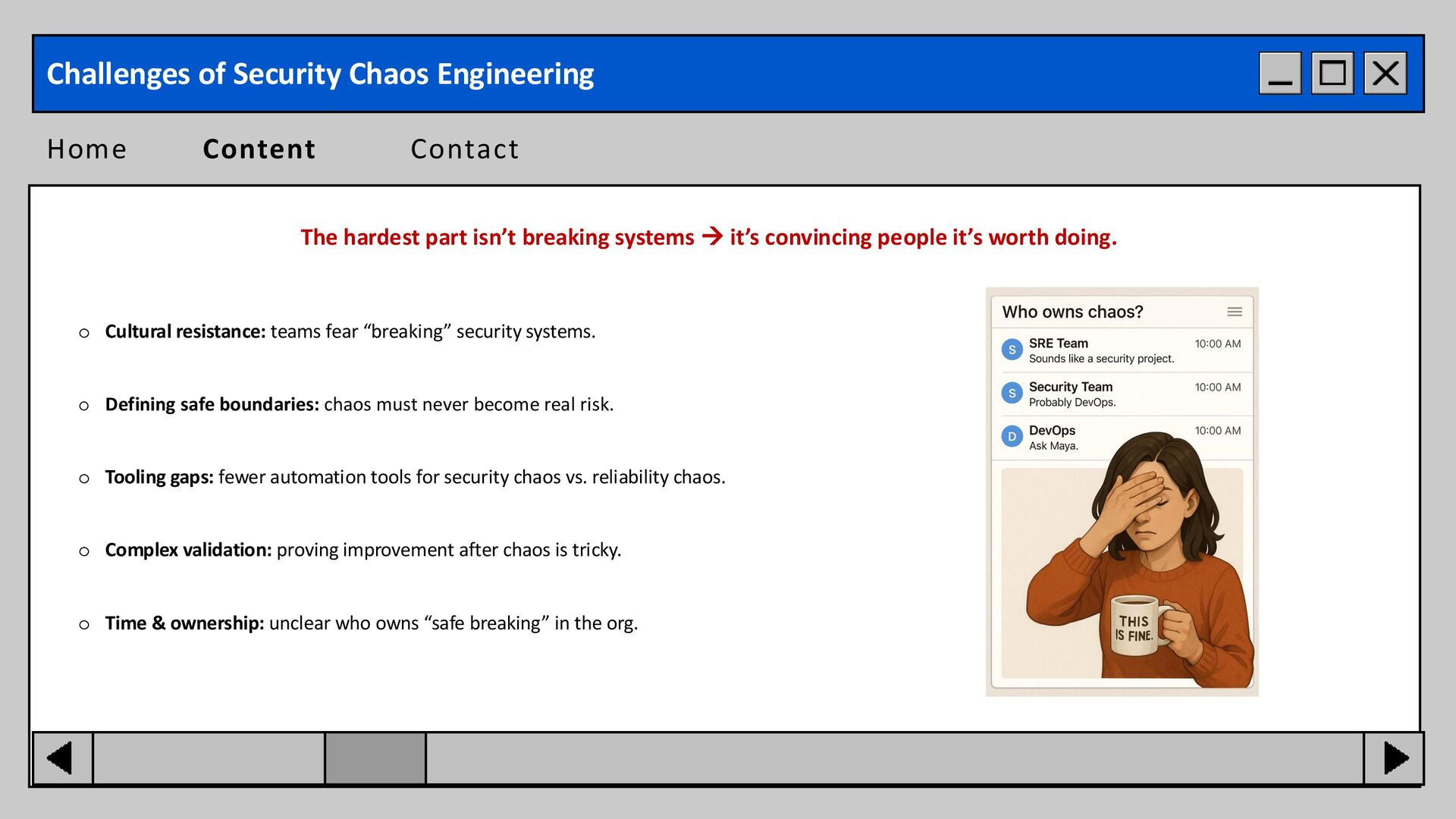
resistance: teams fear “breaking” security systems. o Defining safe boundaries: chaos must never become real risk. o Tooling gaps: fewer automation tools for security chaos vs. reliability chaos. o Complex validation: proving improvement after chaos is tricky. o Time & ownership: unclear who owns “safe breaking” in the org. The hardest part isn’t breaking systems → it’s convincing people it’s worth doing.
safe → test in staging or an identical prod environment, not real production. o Use automation and stop conditions to control chaos safely. o Make it cross-team → involve DevSecOps, SREs, and Security together. o Treat experiments as learning, not blame.
cloud team wants to ensure that their security incident detection pipeline: Security logs → security alerts → remediations truly works when something goes wrong. They decide to run a security chaos experiment to simulate a failure.
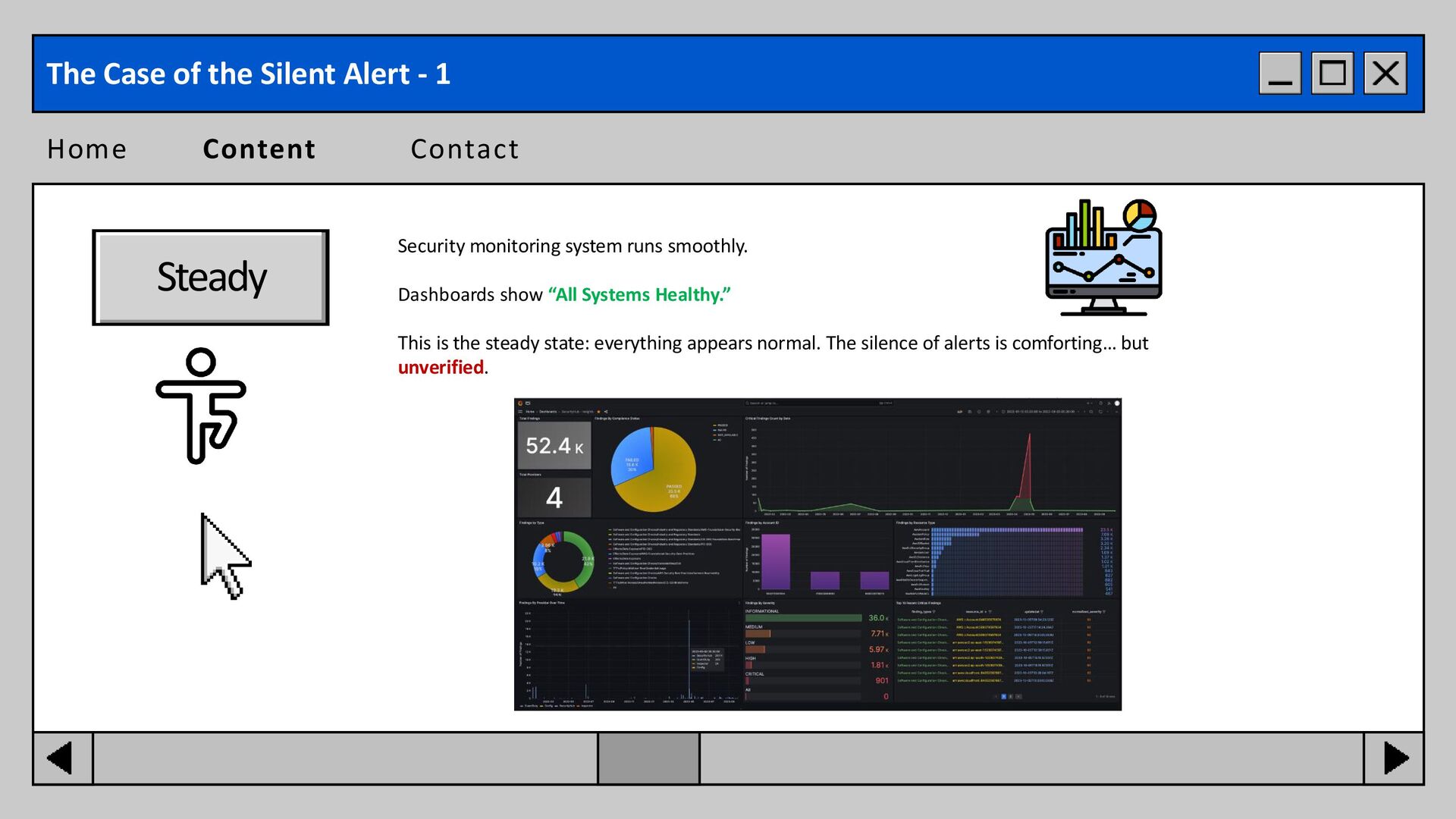
show “All Systems Healthy.” This is the steady state: everything appears normal. The silence of alerts is comforting… but unverified. The Case of the Silent Alert - 1
2 Hypothesis When _________ happens, ________ system will notify the team within _______ and the application’s metric _________ will remain at ________. o Brainstorming o Threat modeling o Think all the security-based scenarios o ”What if?”
2 Hypothesis 1. WAF Alerting When malicious requests (e.g., SQLi or bot traffic) happens, the WAF and CloudWatch system will notify the team within 1 minute, and the application’s metric AllowedRequests/BlockedRequests ratio will remain at safe threshold (<10% malicious allowed).
2 Hypothesis 2. GuardDuty + Remediation (Malware) When GuardDuty detects malware or a compromised instance, the automated remediation Lambda will notify the team within 2 minutes, and the application’s metric instance network connections will remain at zero (isolated state).
3 Run Exp 1. WAF Alerting Test o Send simulated SQLi/bot traffic to test rules. o Watch BlockedRequests and alert timing. o Ensure app stays stable, alerts arrive in <1 min. o Stop test if latency spikes. Keep it safe, controlled, and well-logged. Chaos ≠ production outage!
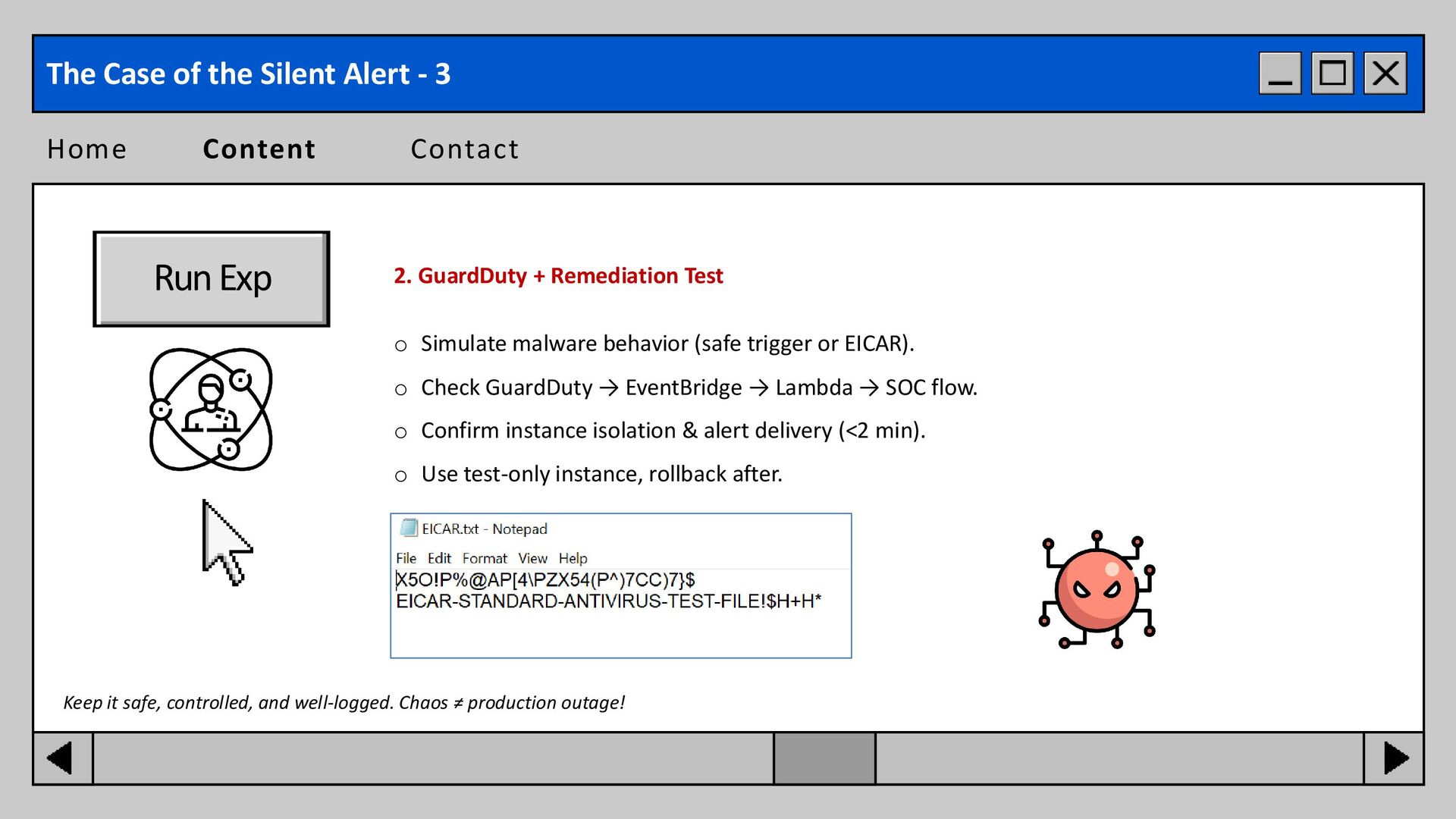
3 Run Exp 2. GuardDuty + Remediation Test o Simulate malware behavior (safe trigger or EICAR). o Check GuardDuty → EventBridge → Lambda → SOC flow. o Confirm instance isolation & alert delivery (<2 min). o Use test-only instance, rollback after. Keep it safe, controlled, and well-logged. Chaos ≠ production outage!
4 Verify 1. WAF Alerting o After a burst of SQL injection traffic, the WAF detected and blocked 95% of malicious requests within 1 minute. o However, the CloudWatch alarm for “BlockedRequests > Threshold” didn’t trigger because the metric filter name was outdated. o During the test, the application stayed healthy → no user-facing downtime. Analyze, document, collect lessons learned.
4 Verify 2. GuardDuty + Remediation (Malware) o After a simulated malware file was placed on an EC2 instance, GuardDuty generated a finding within 2 minutes and triggered the remediation Lambda. o Network activity dropped to zero, confirming isolation worked. o But isolation causes performance issues. Analyze, document, collect lessons learned.
5 Improve o Summarize what broke, what worked, and who felt it. o Fix gaps: alerts, permissions, automation. o Re-run experiments after improvements. o Apply lessons across other systems. o Automate where humans slowed down. o Turn chaos reports into new playbooks. AWS Incident Response Playbook Samples Forming a Chaos Engineering Team
Fun o Chaos isn’t scary when you own the experiment. o Every “oops” in testing saves a “WTF” in production. o Build chaos muscles. Laugh at your alerts. o If your system never breaks… are you sure it’s running?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}