▪ フレーム間で結合したポイントマップの損失を強めて、マスク損失を弱めるのが有効だった R. Wang et al., “MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision”, CVPR’25. R. Rantftl et al., “Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer”, TPAMI’20. L. Yang et al., “Depth anythingV2”, NeurIPS’24.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
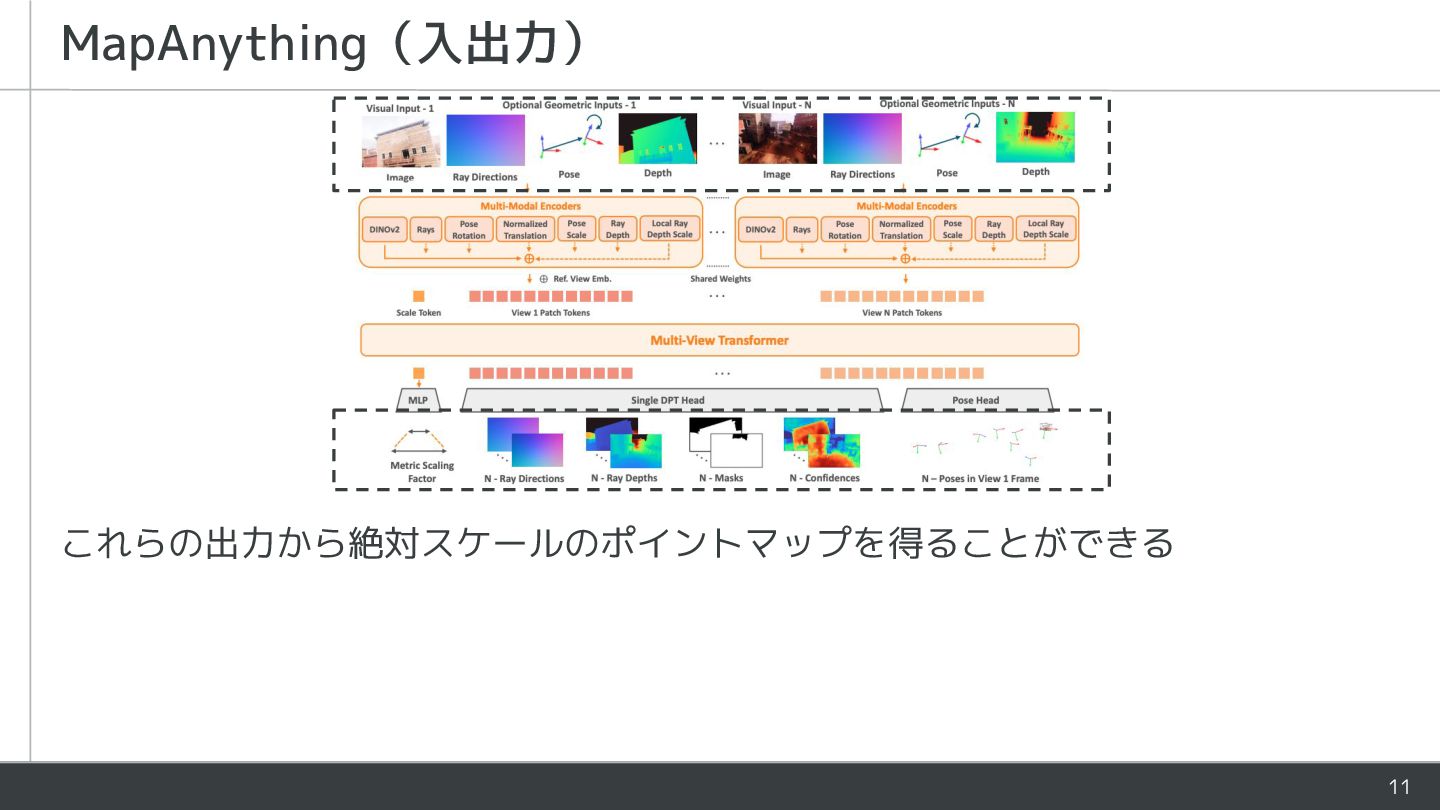{kind=link}
{kind=link}
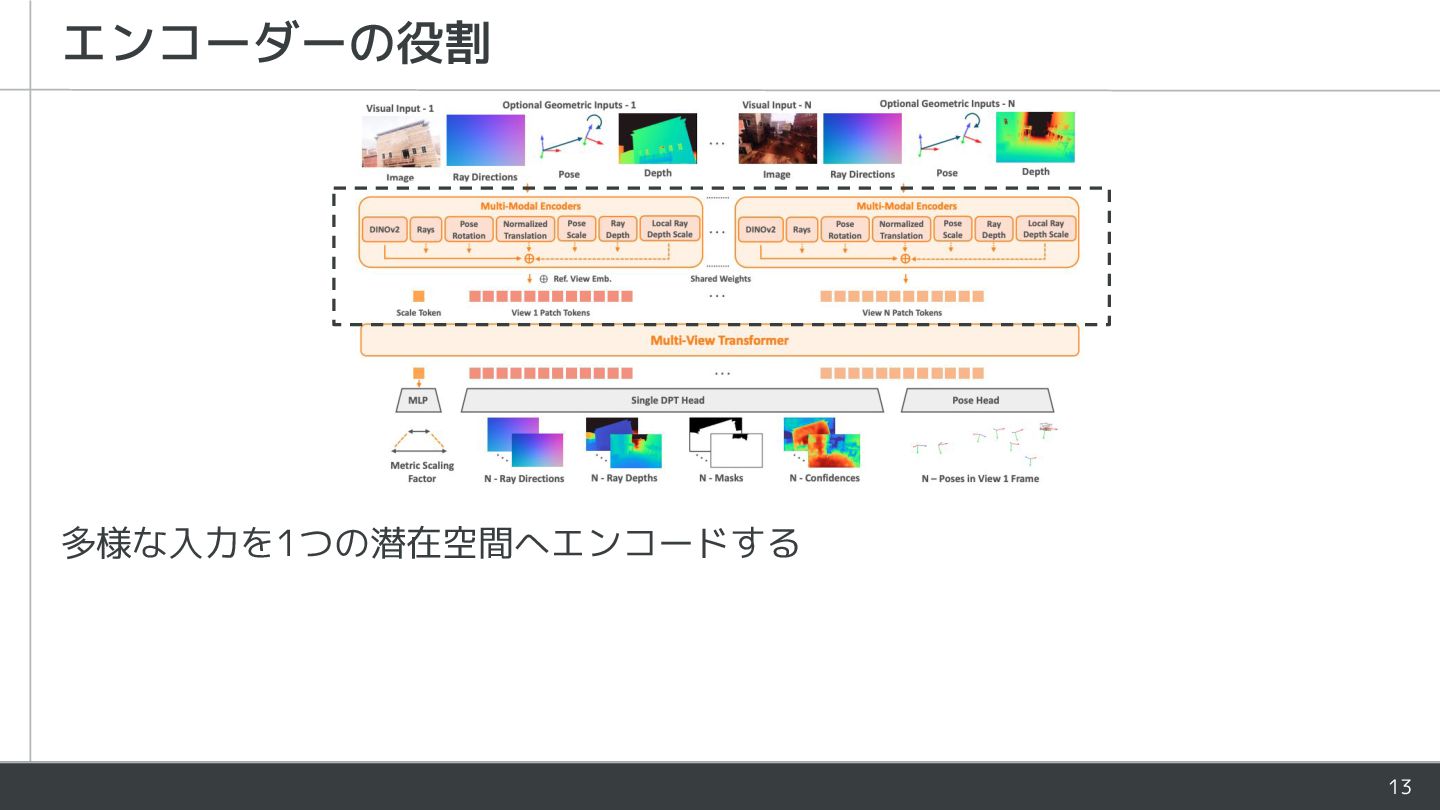{kind=link}
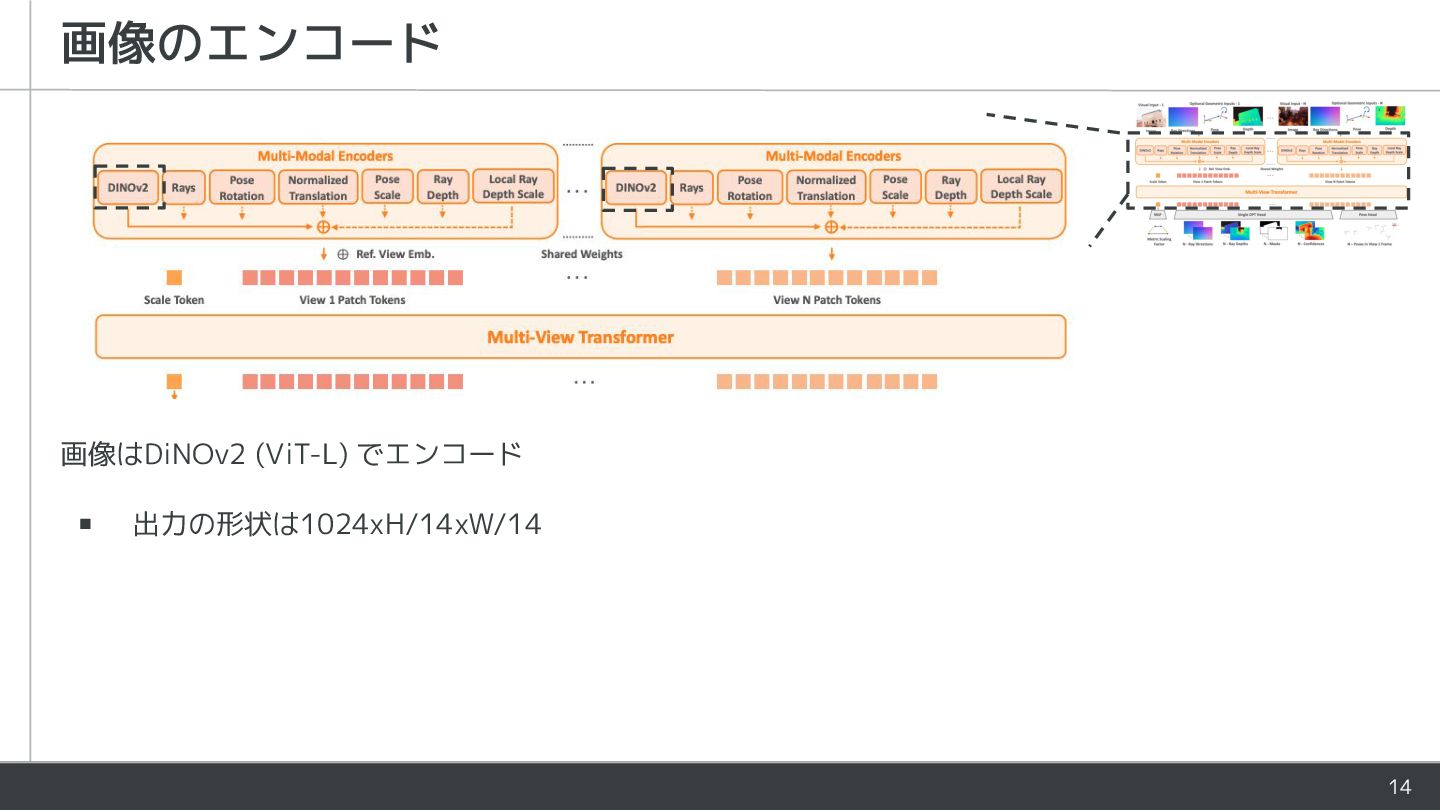{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
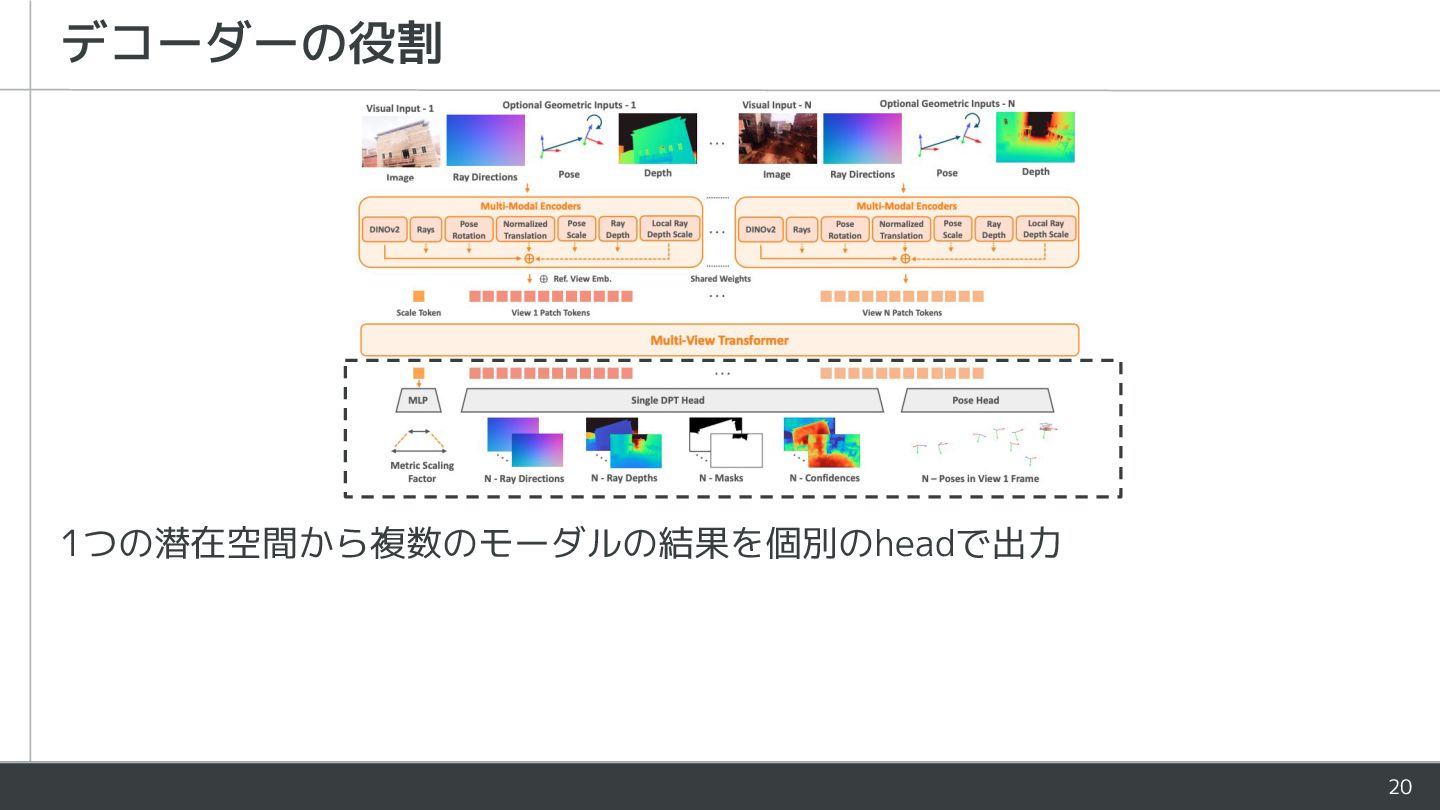{kind=link}
{kind=link}
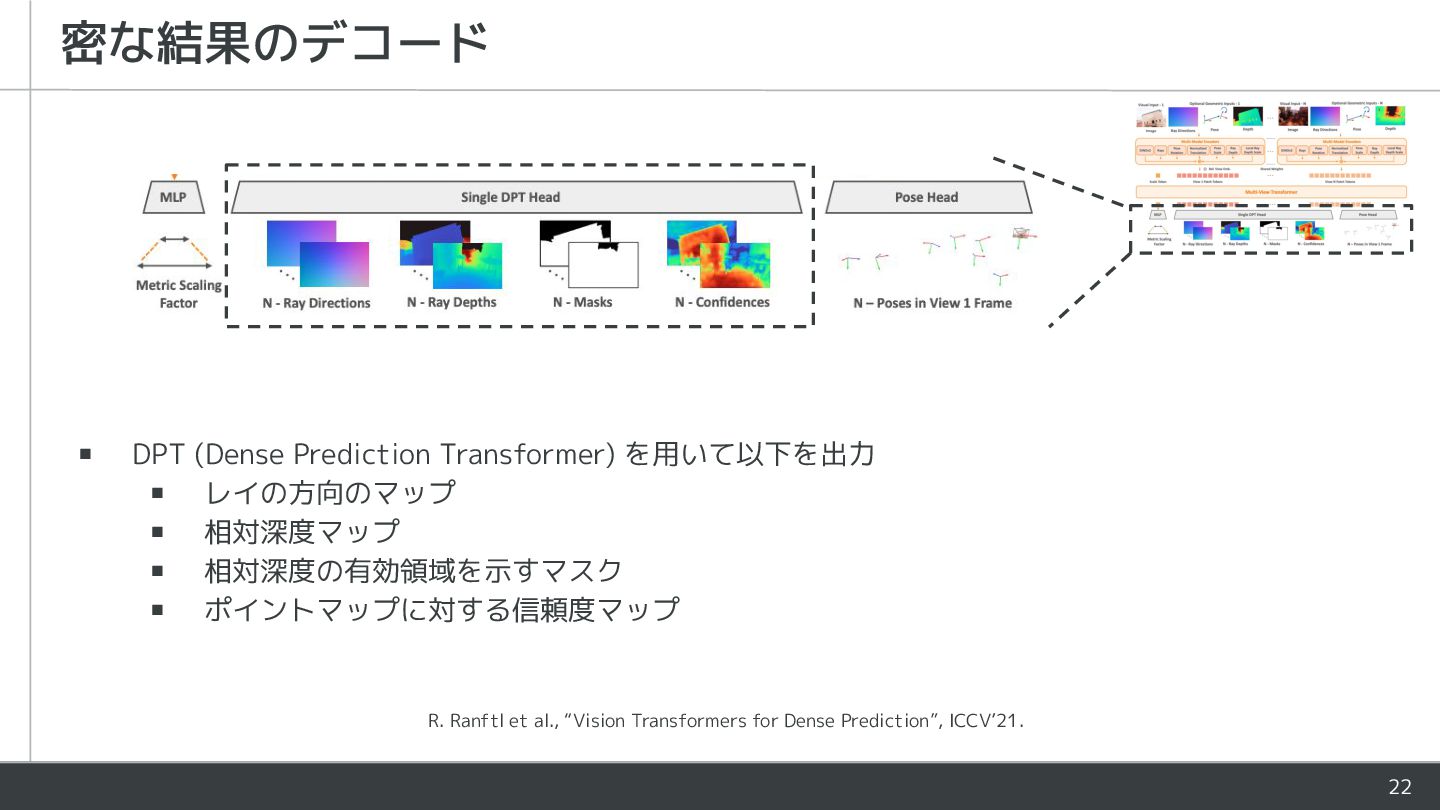{kind=link}
{kind=link}
{kind=link}
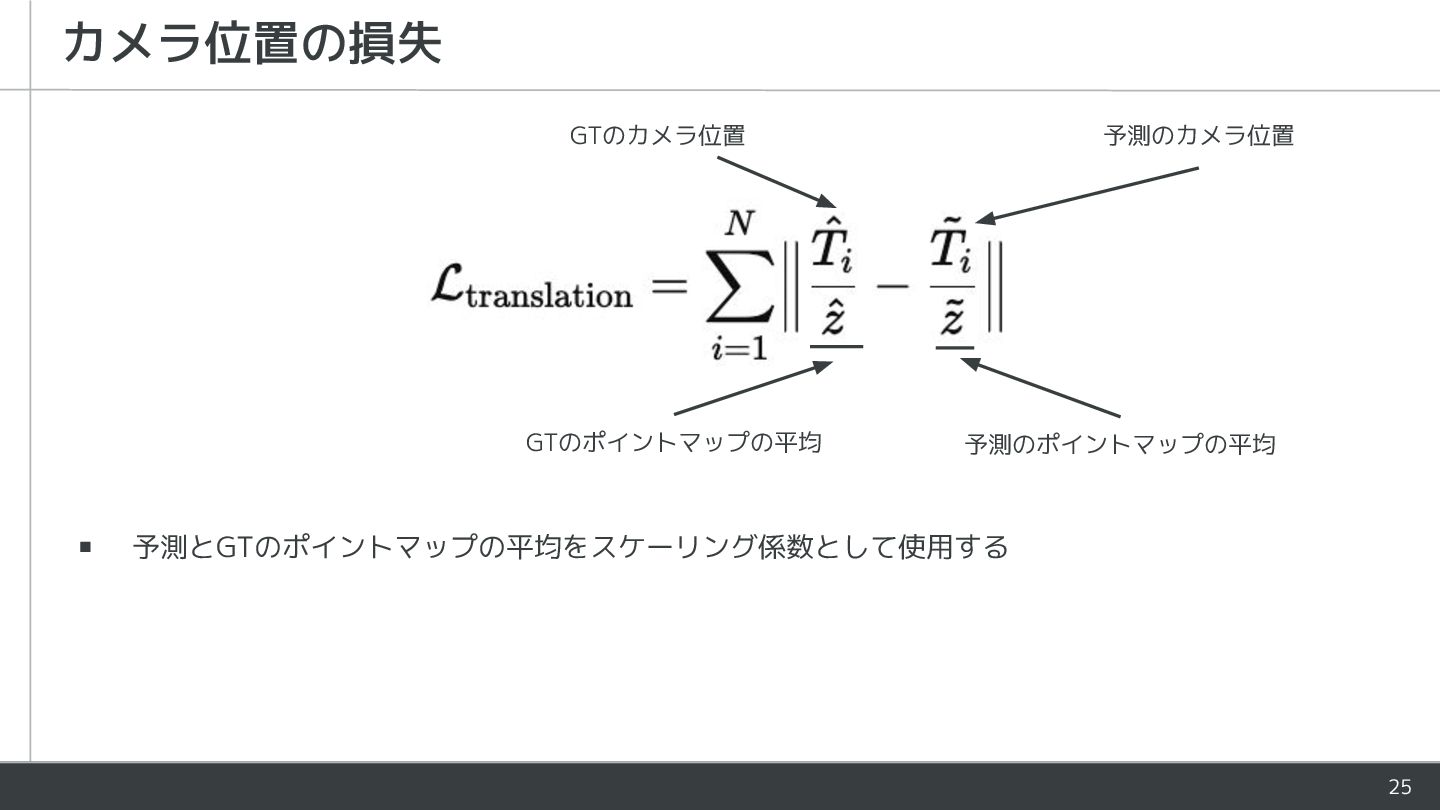{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
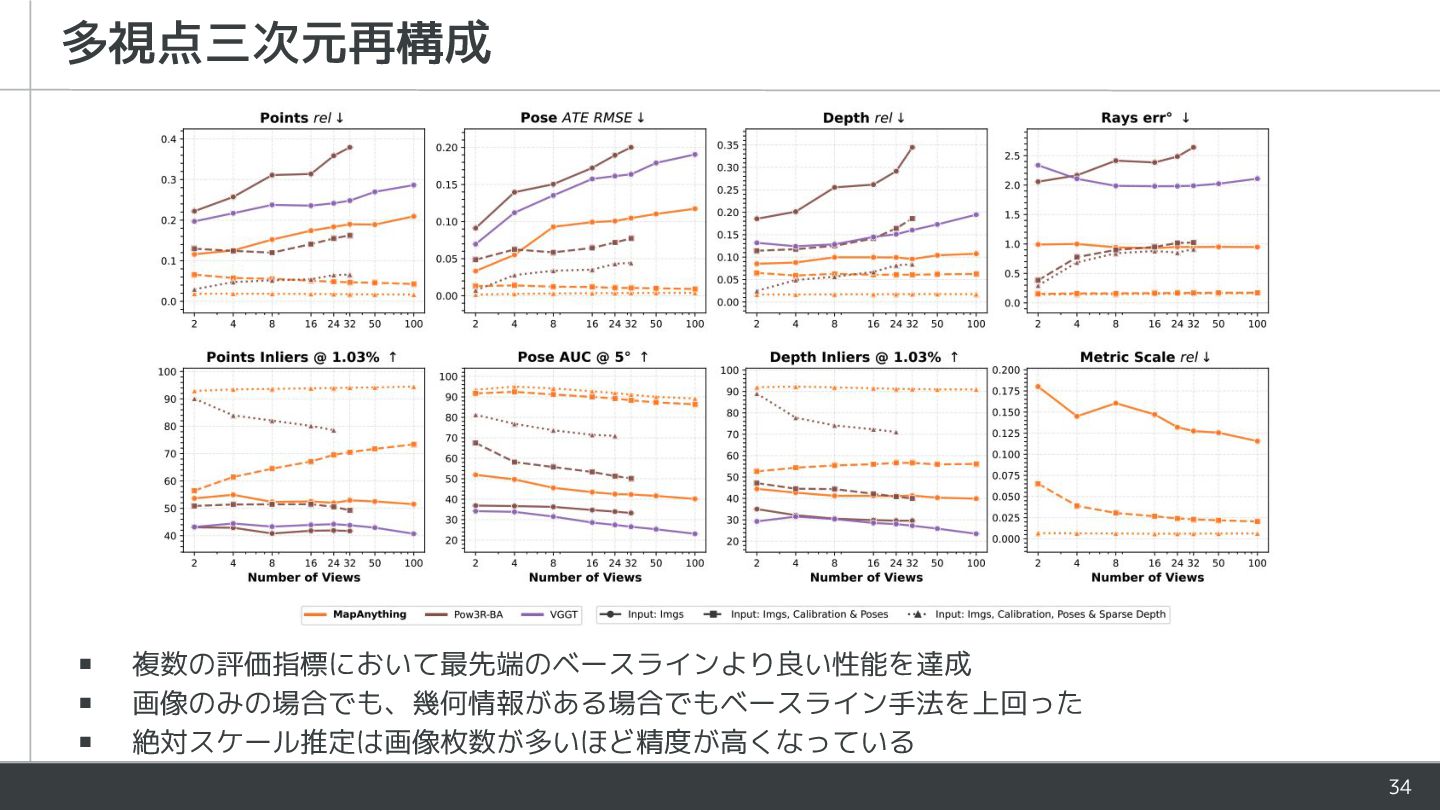{kind=link}
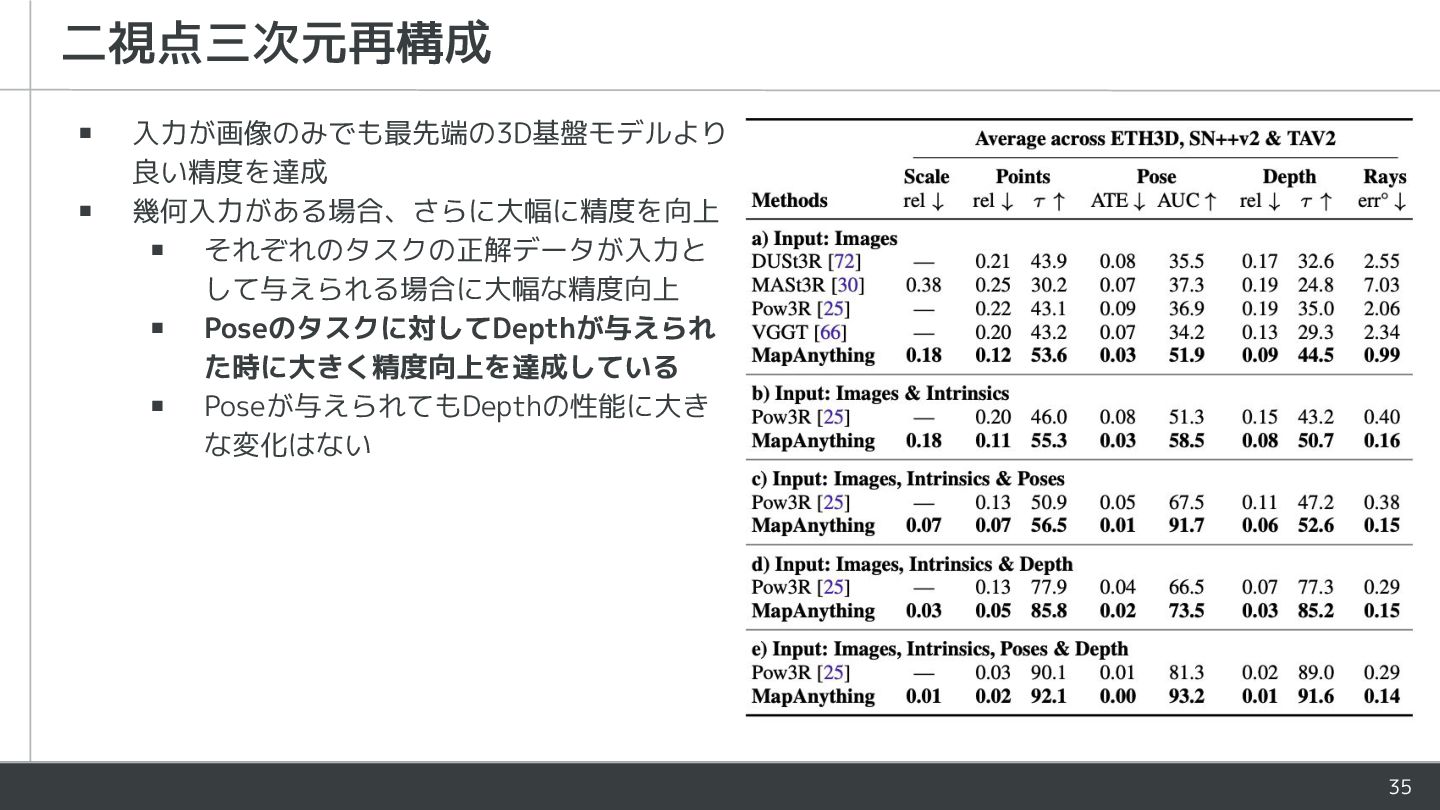{kind=link}
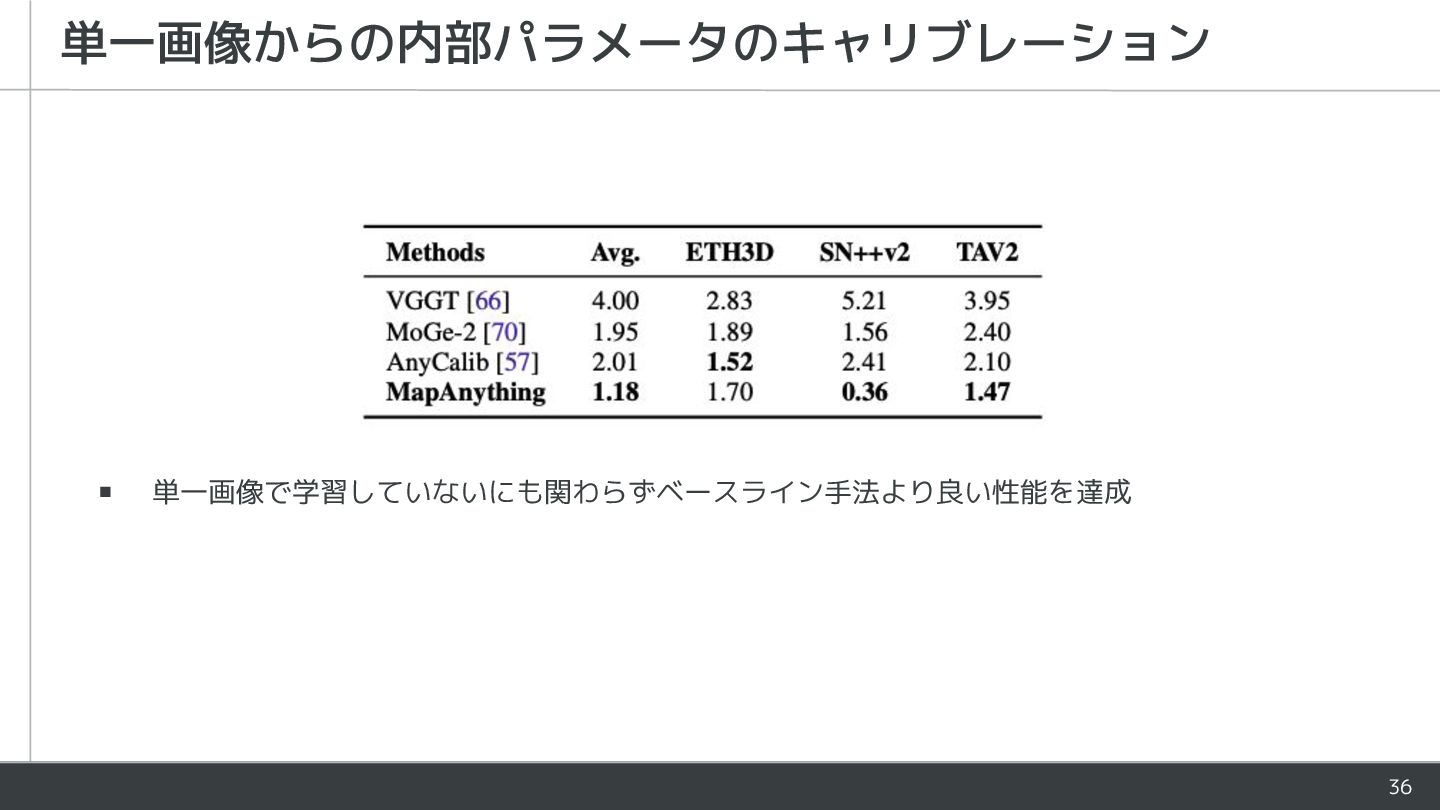{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}