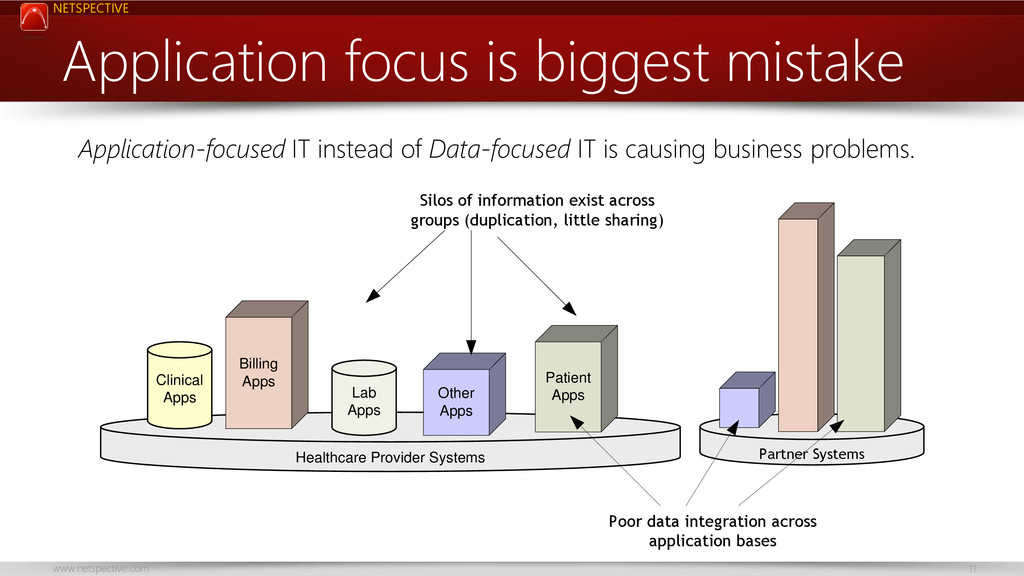
Centralized, monolithic databases primarily built using relational approaches have ruled for decades; they’ve given us tremendous advances such as vertically scaled business-critical transactional systems and web applications. The next generation of microapps, microservices, and web widgets demand a scale that vertical scale application-centric relational databases are having difficulty with so we need to move to a more service-oriented database approach in which even small services like those that service patients in a patient portal or specific modules of EHRs can and should have their own databases.
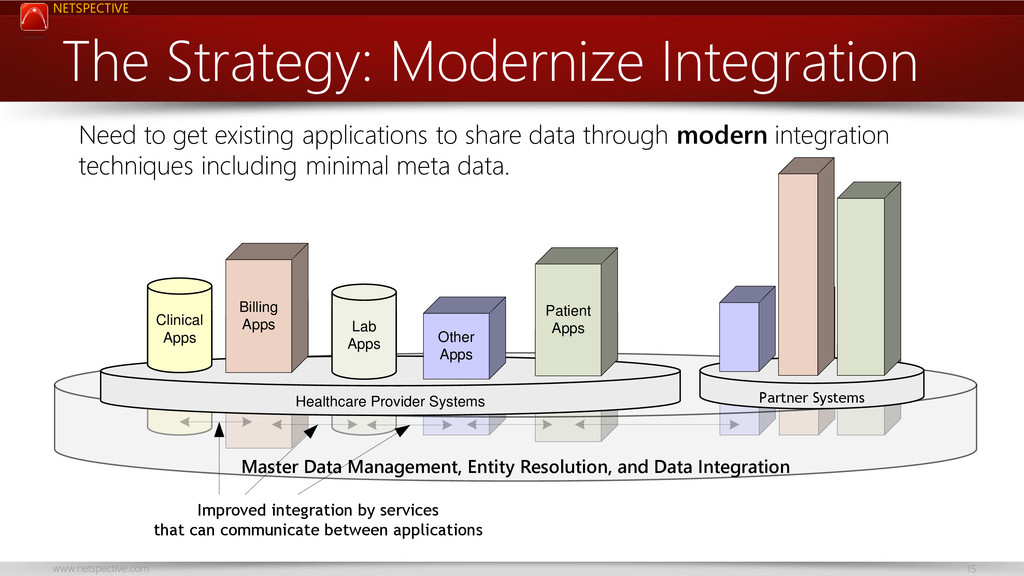
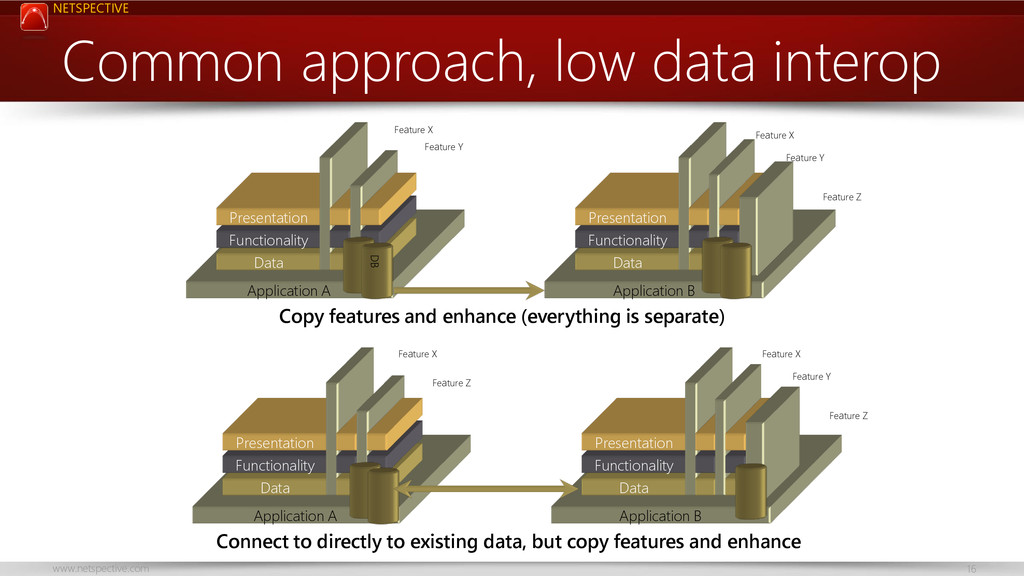
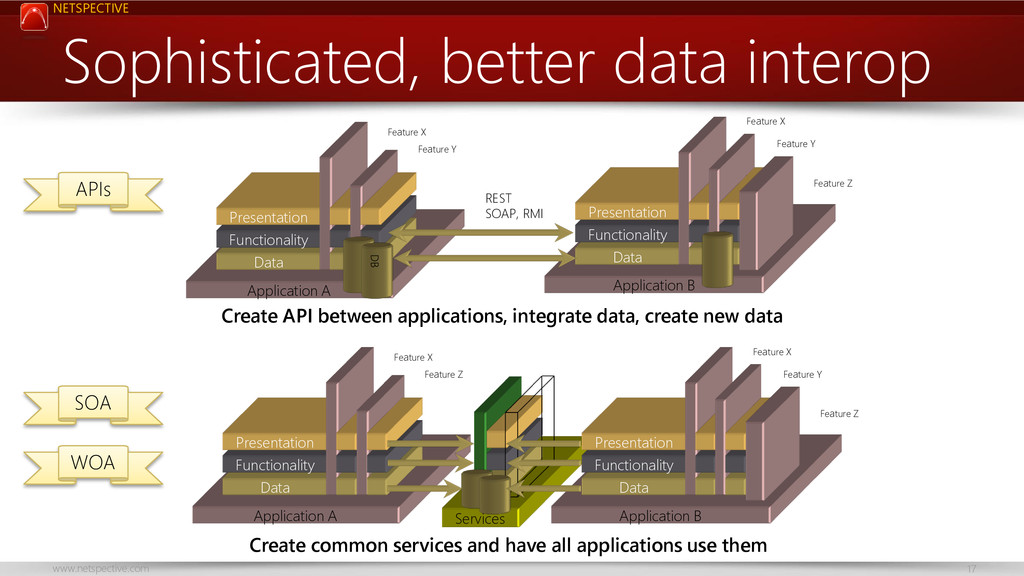
This talk encourages the idea of service-focused databases and how they differ from application-centric databases; using this new approach allows faster delivery of applications, less coupling, and better scalability. Healthcare and biomedical databases are notoriously complex and no single database technology can serve its needs so we need a more service-oriented approach to database design.
You’ll learn how to choose the right database technology for each service, how to model service-oriented databases differently than application-oriented ones, and how to keep service databases running smoothly.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
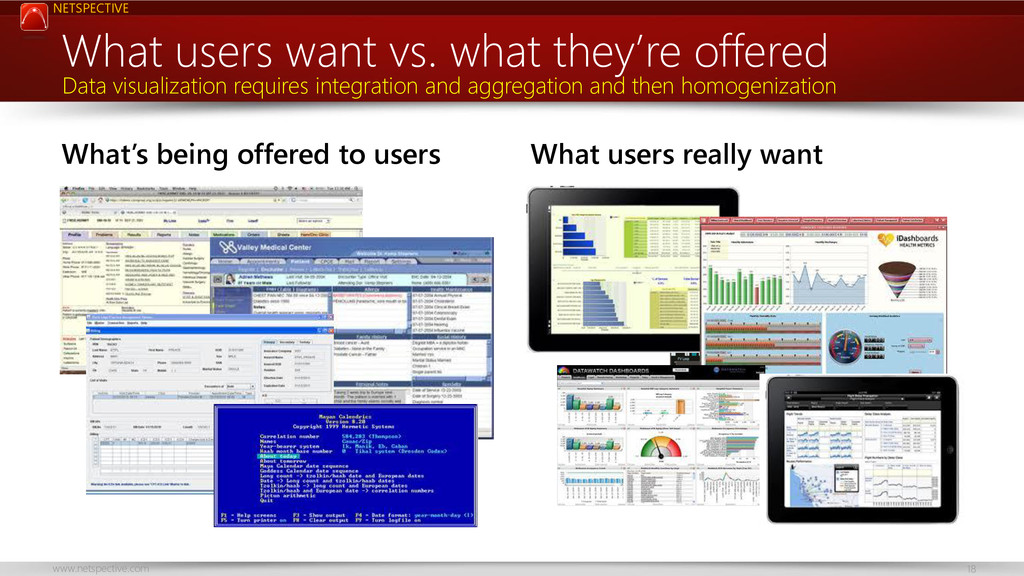{kind=link}
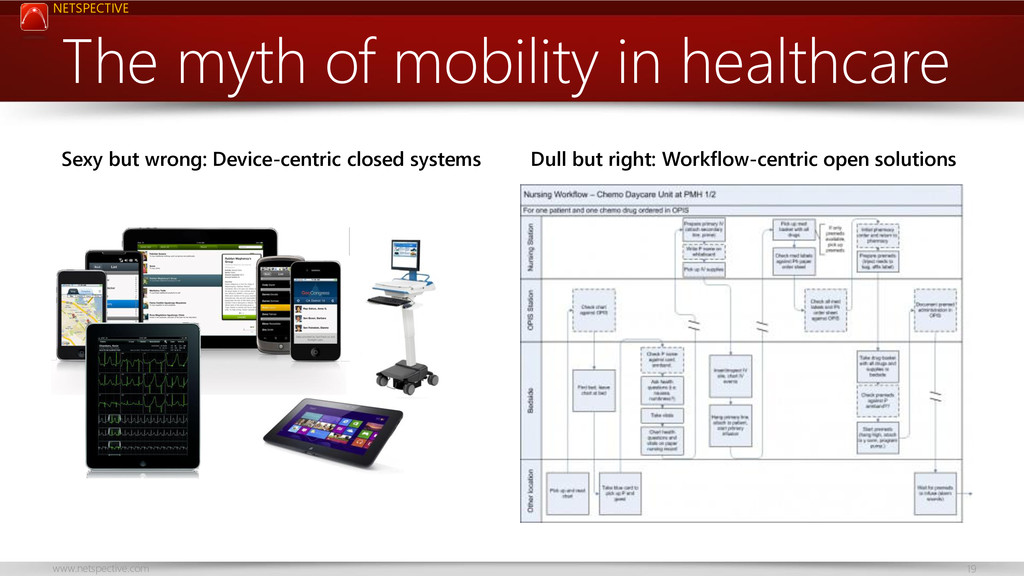{kind=link}
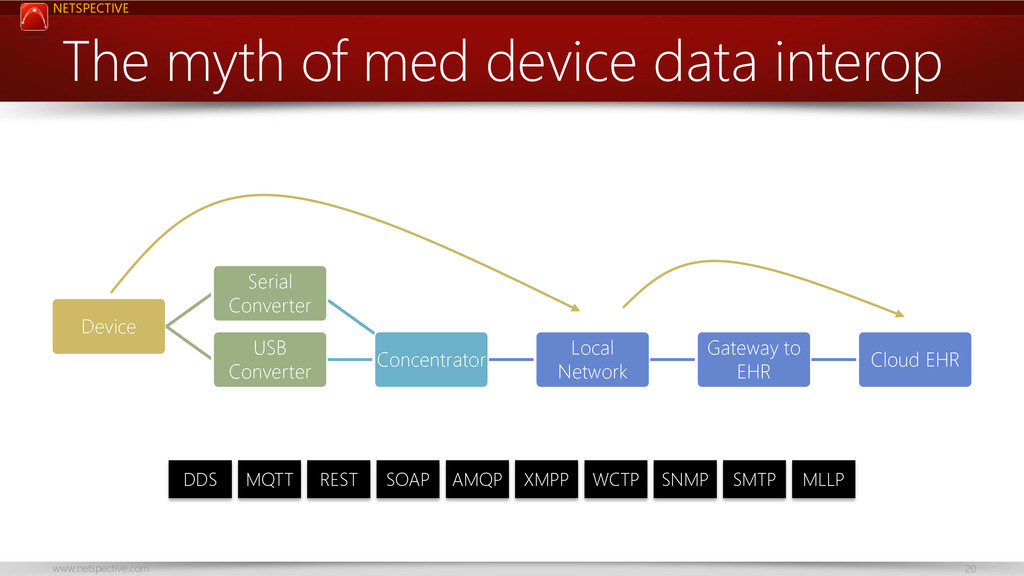{kind=link}
{kind=link}
{kind=link}
{kind=link}
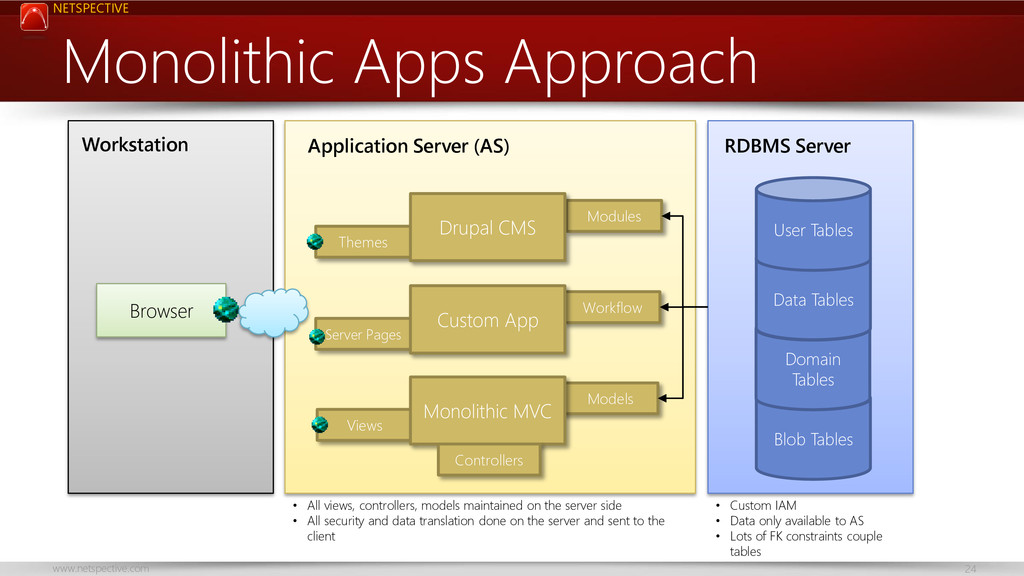{kind=link}
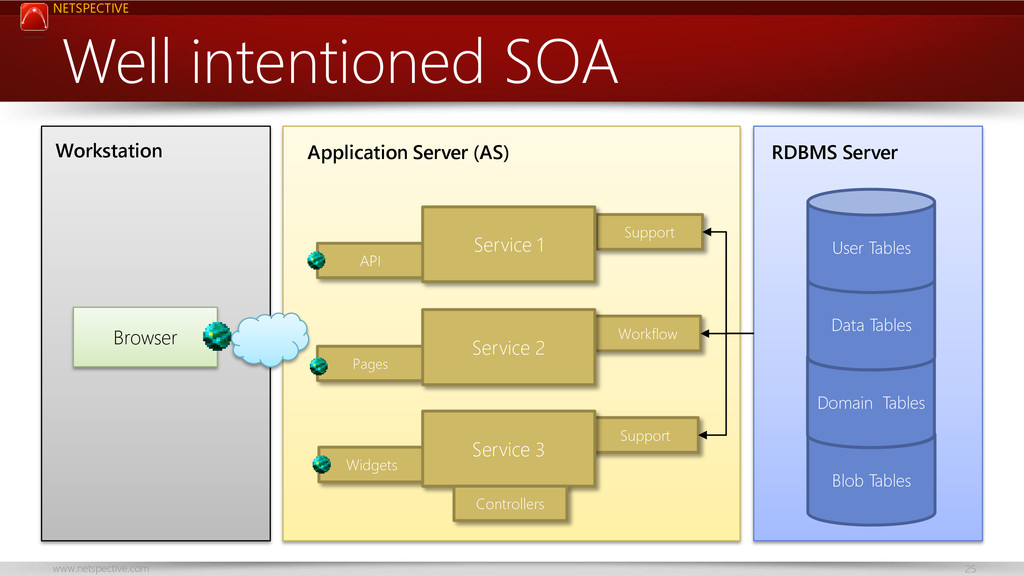{kind=link}
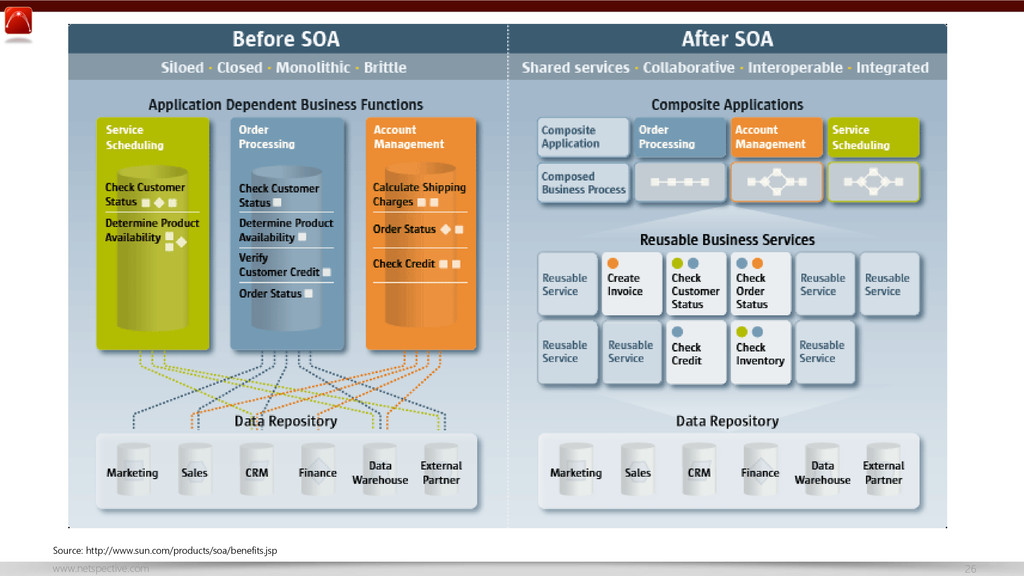{kind=link}
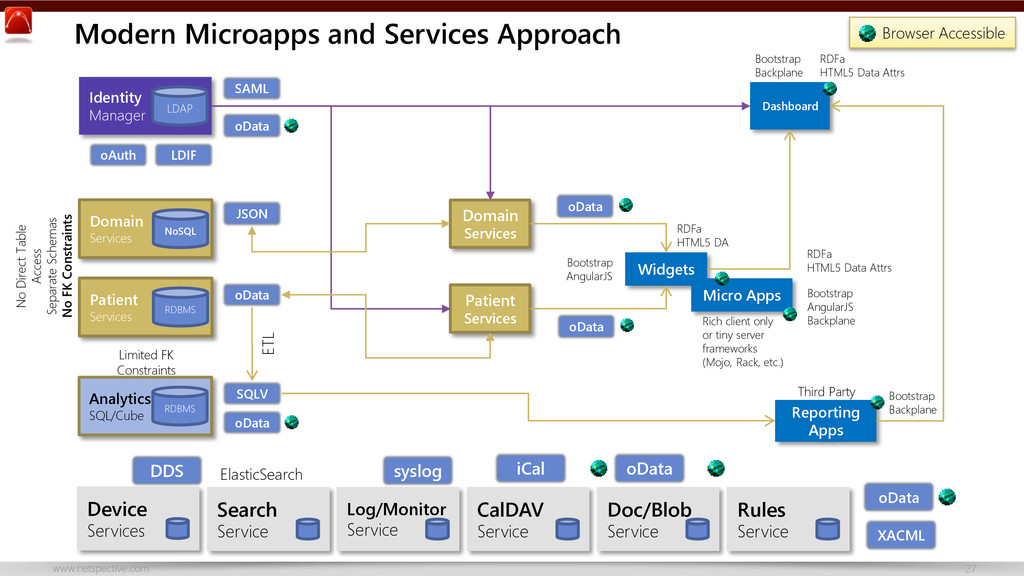{kind=link}
{kind=link}
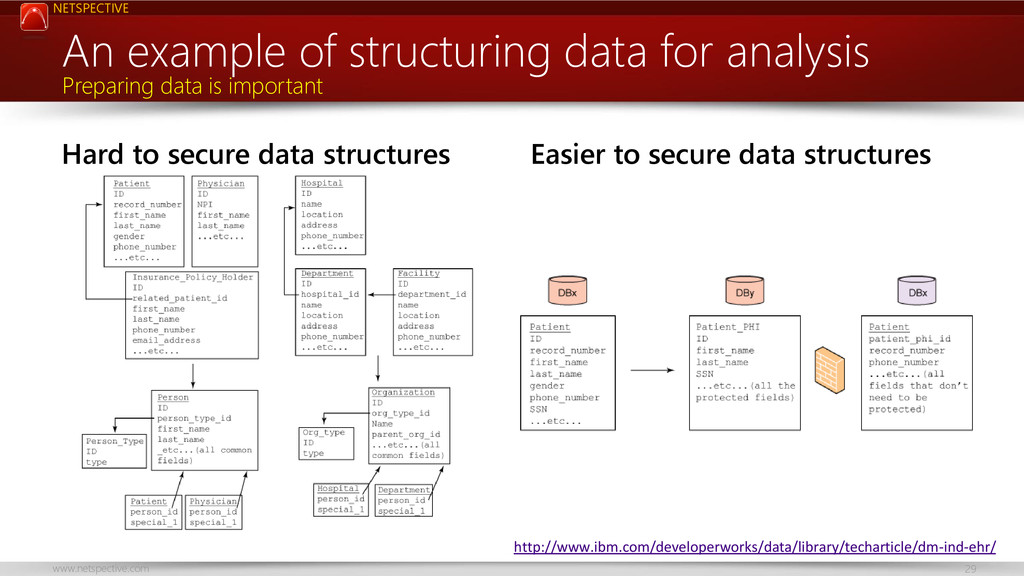{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You Visit http://www.netspective.com http://www.healthcareguy.com E-mail [email protected] Follow @ShahidNShah Call](https://files.speakerdeck.com/presentations/a04b70f009cb0131816d2ee45ae48804/slide_38.jpg){kind=link}
{kind=link}