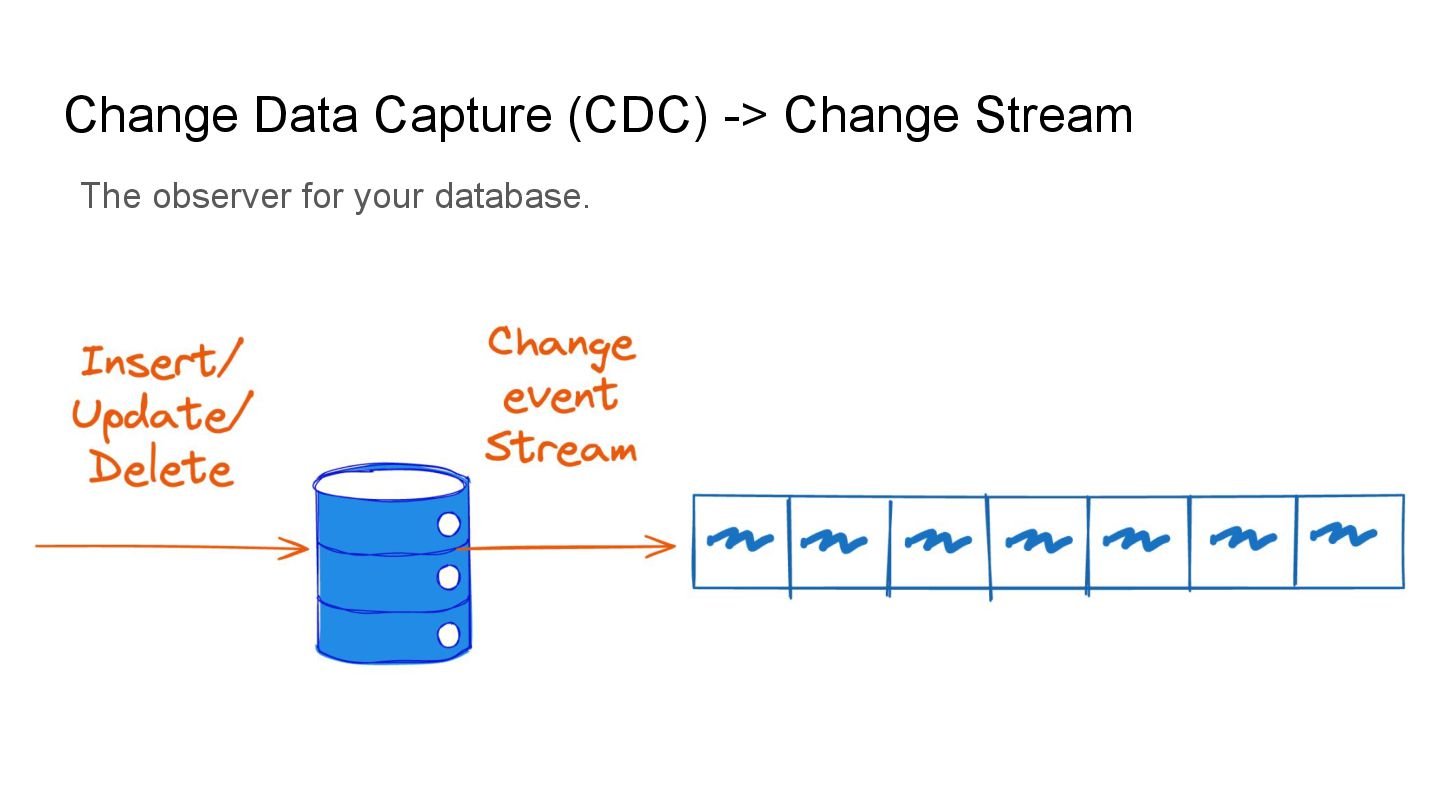
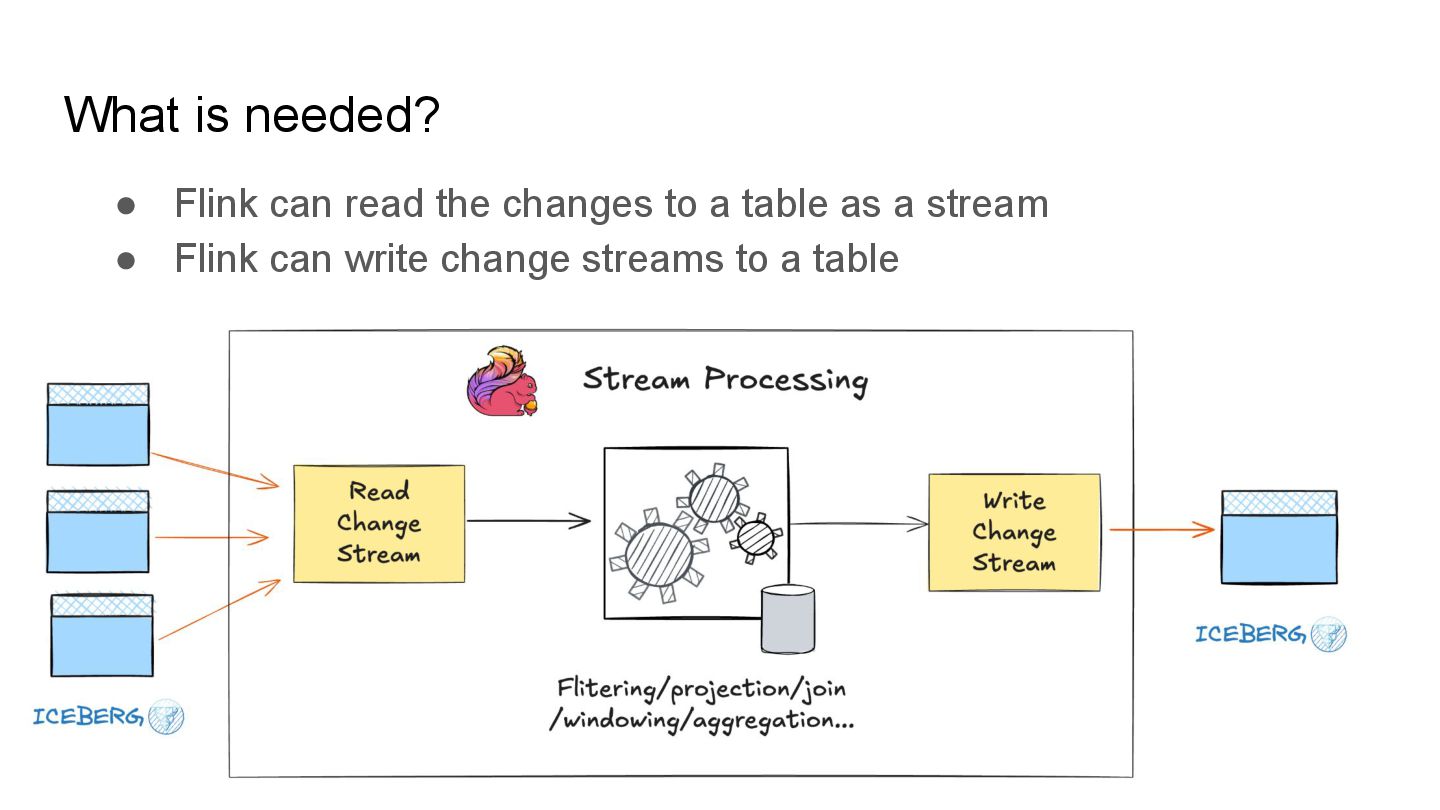
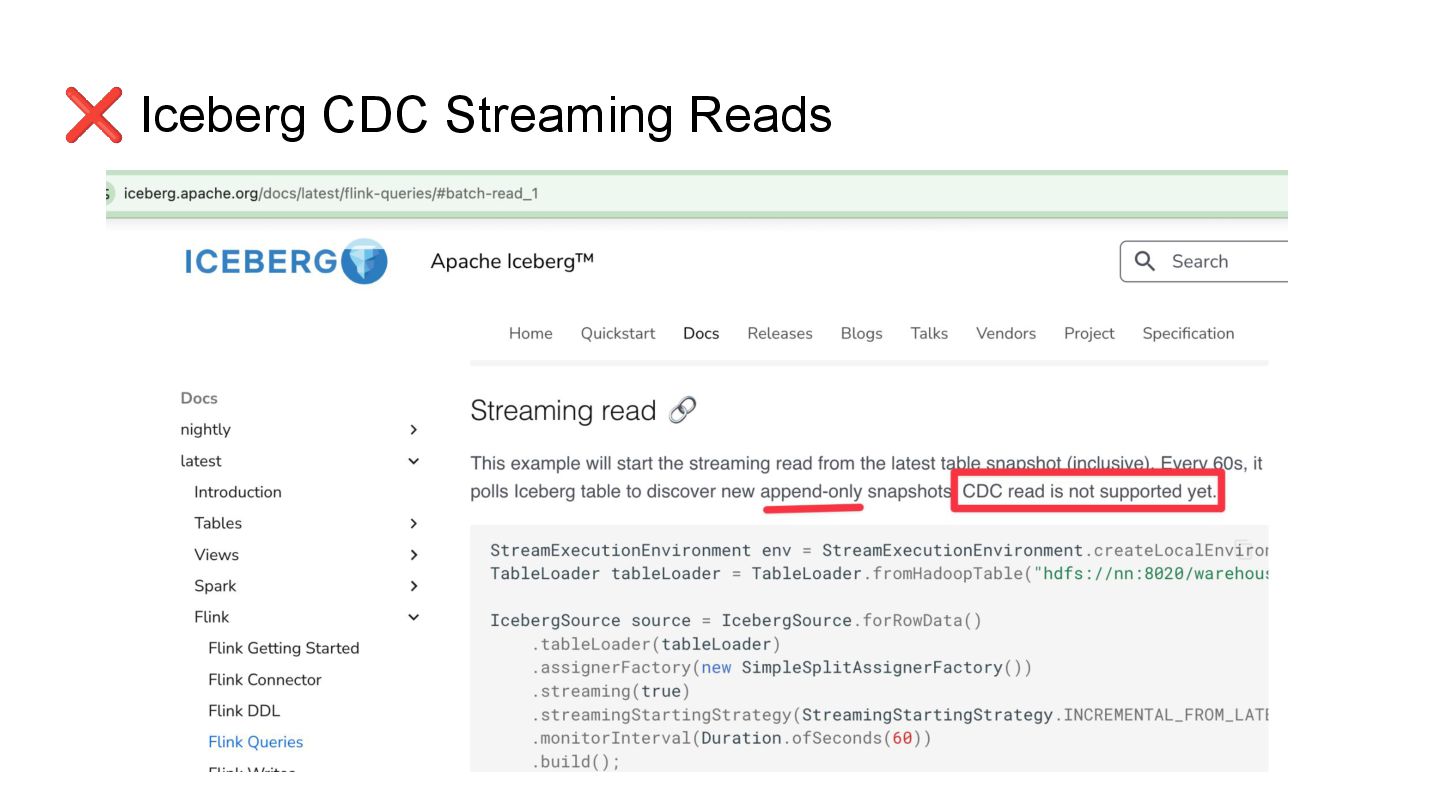
Apache Iceberg is a robust foundation for large-scale data lakehouses, yet its current support for change data capture (CDC) is limited, making updates and deletes challenging for incremental processing. While the unreleased Iceberg V3 will introduce native CDC support, many production environments still run on V2 and require pragmatic workarounds.
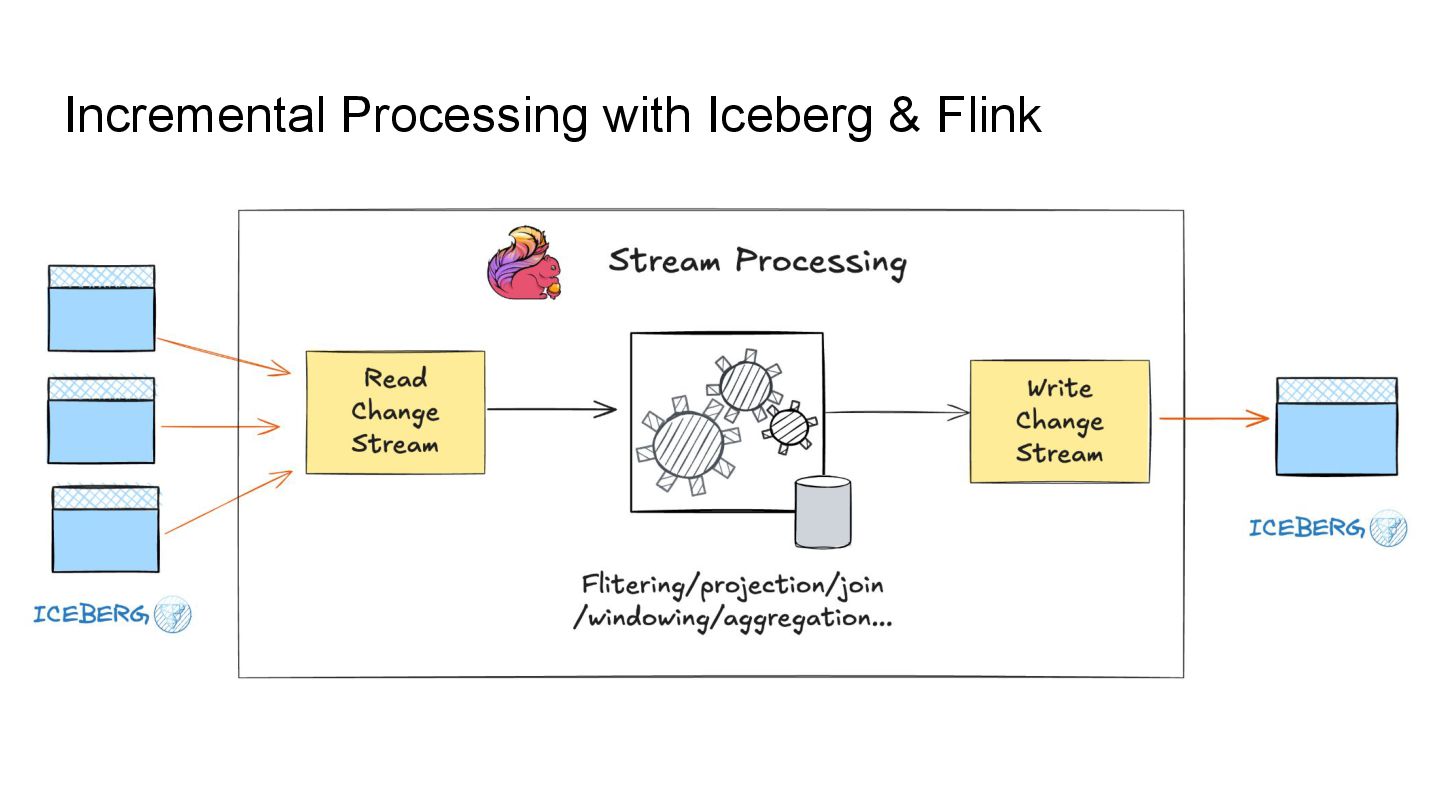
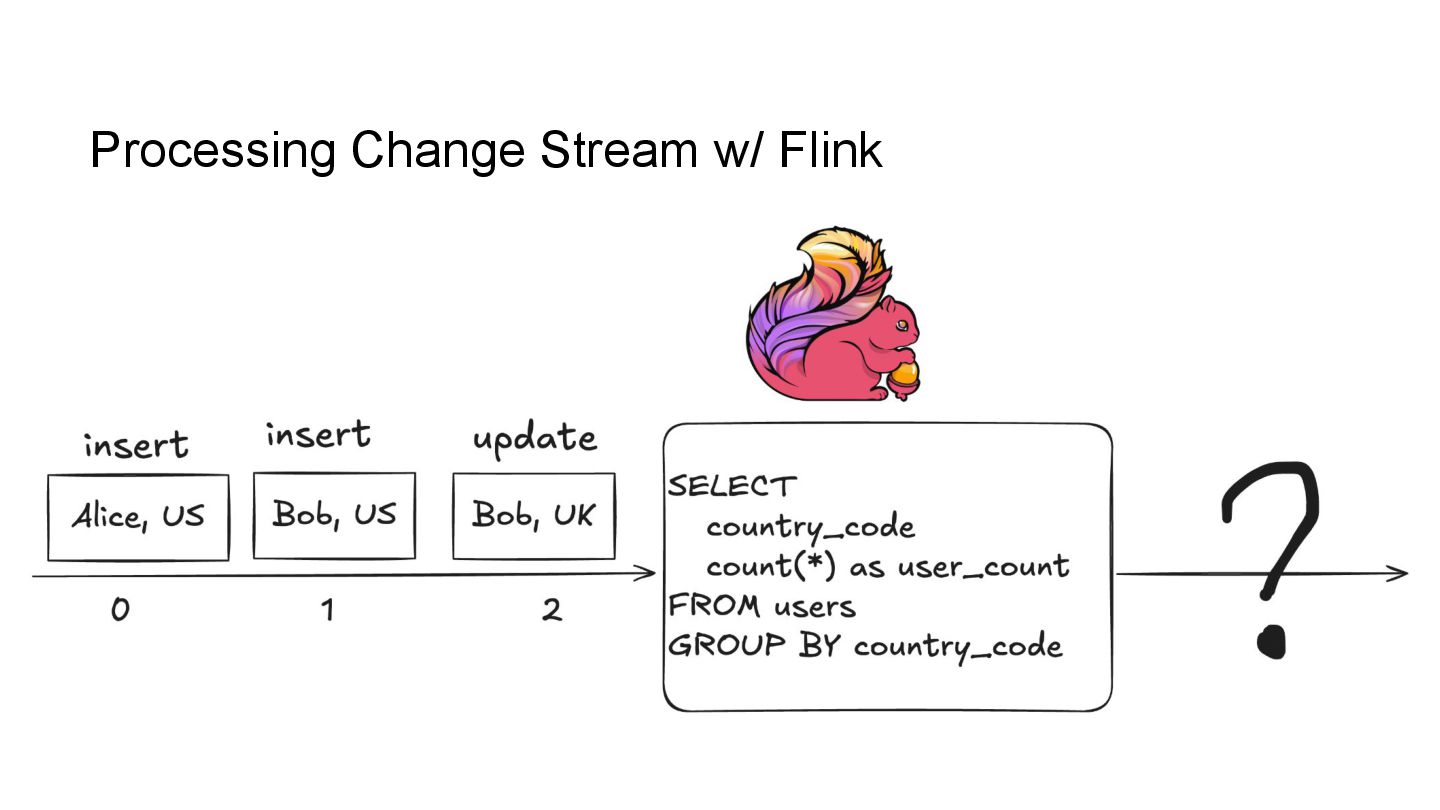
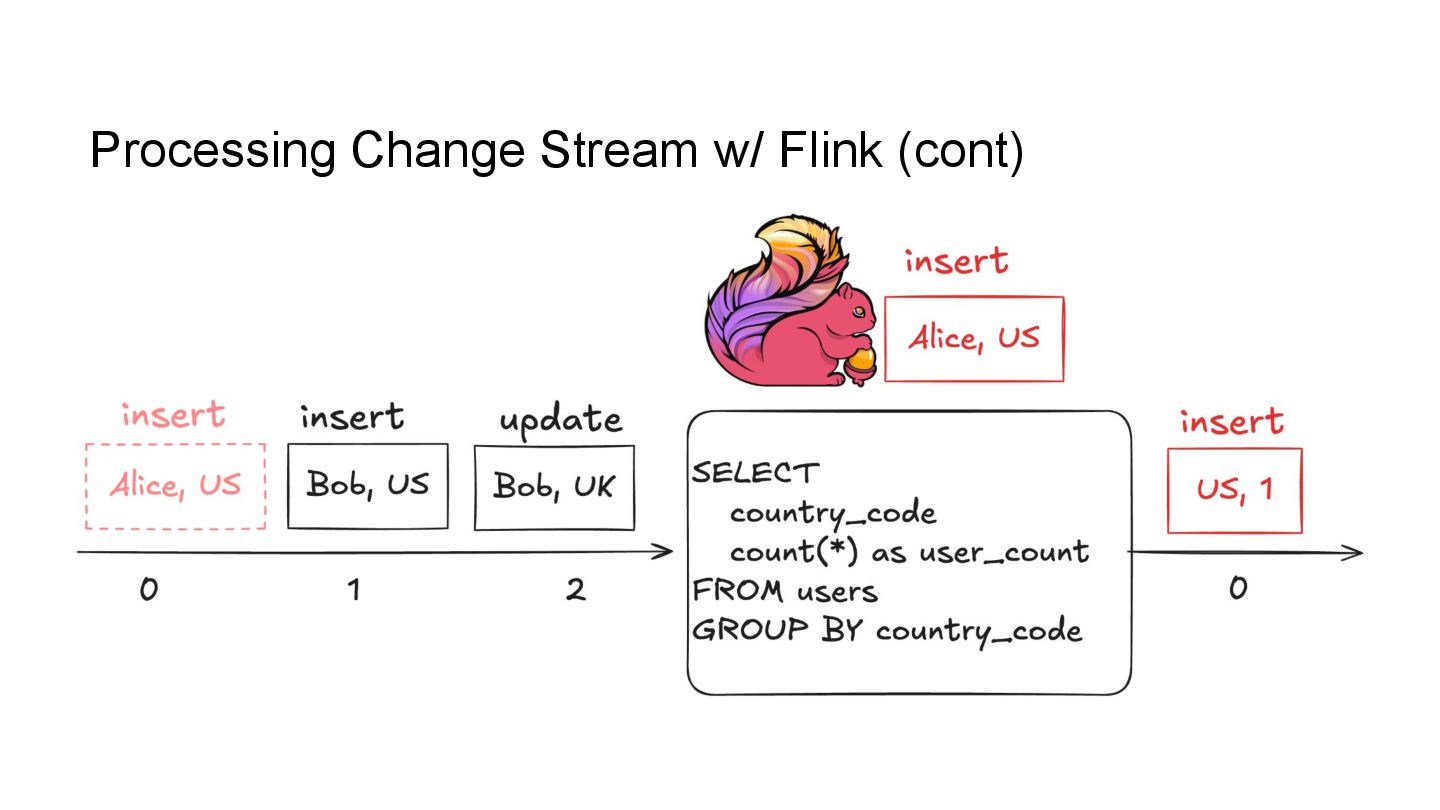
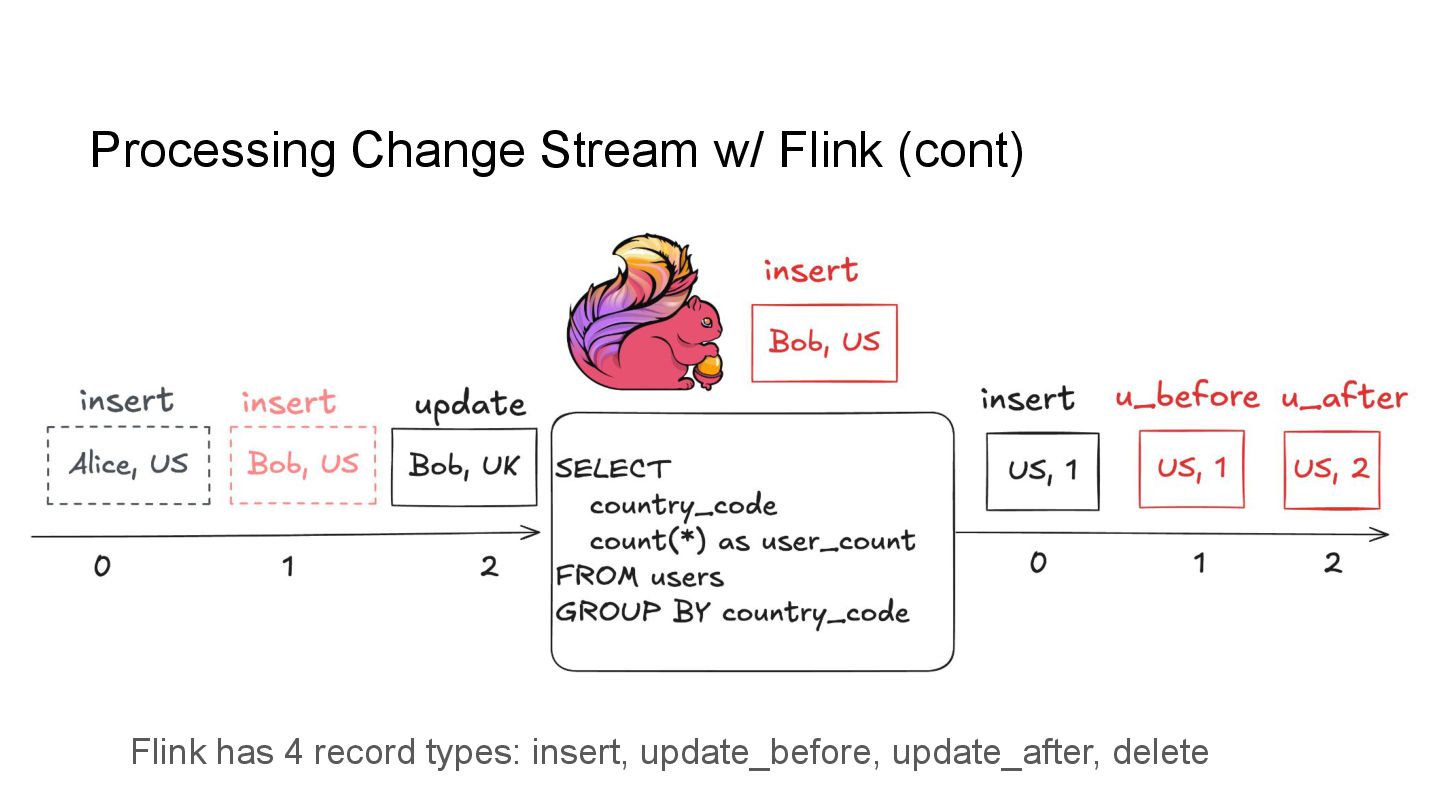
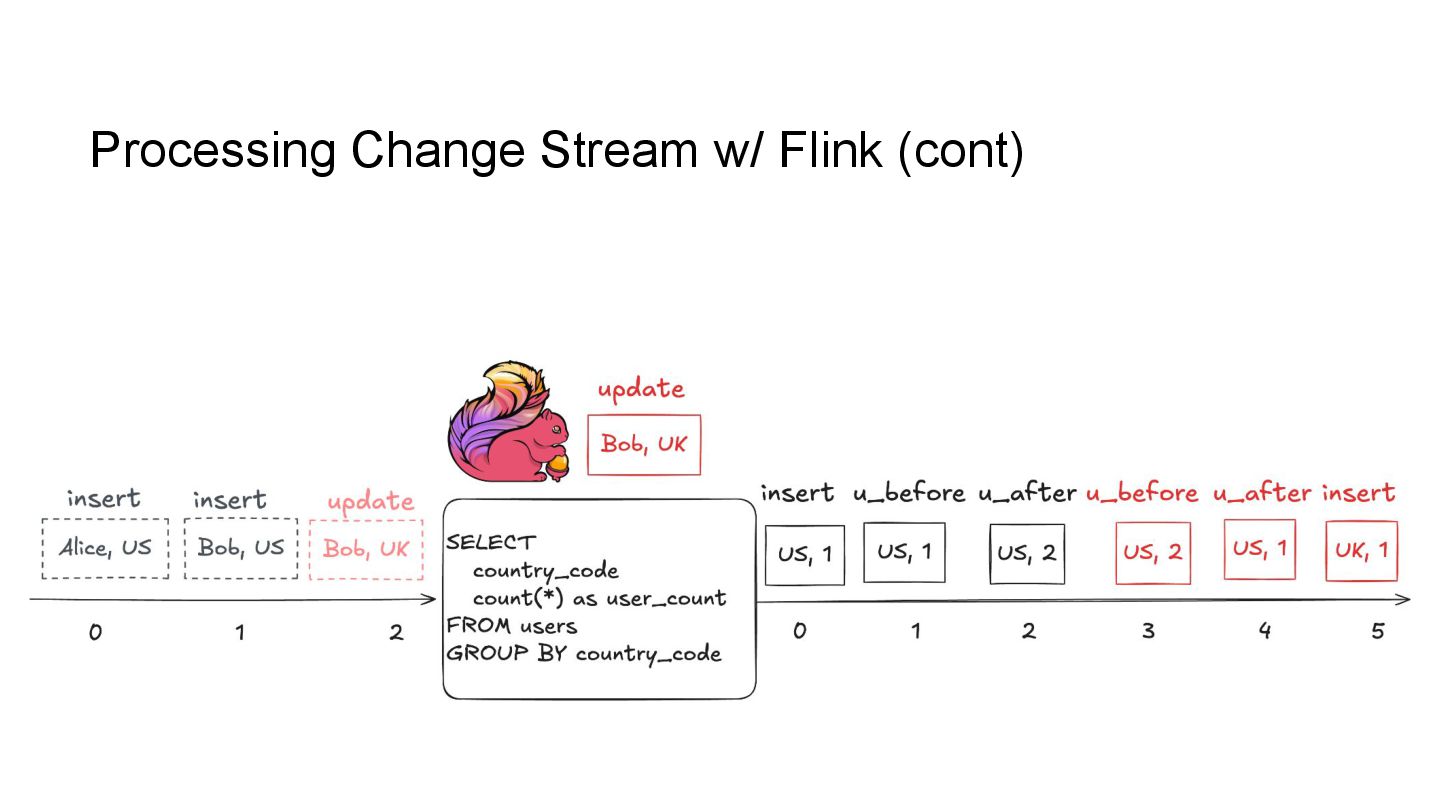
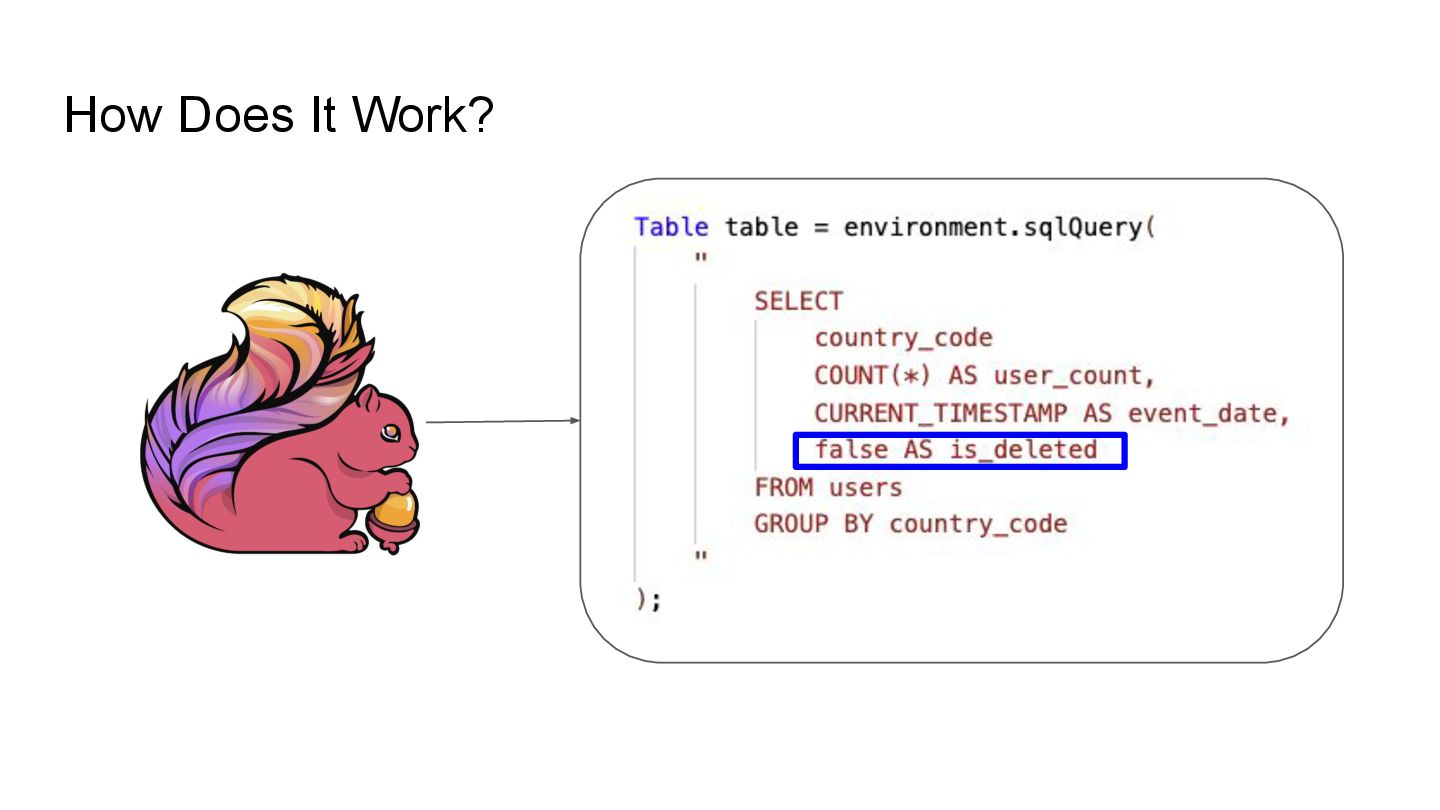
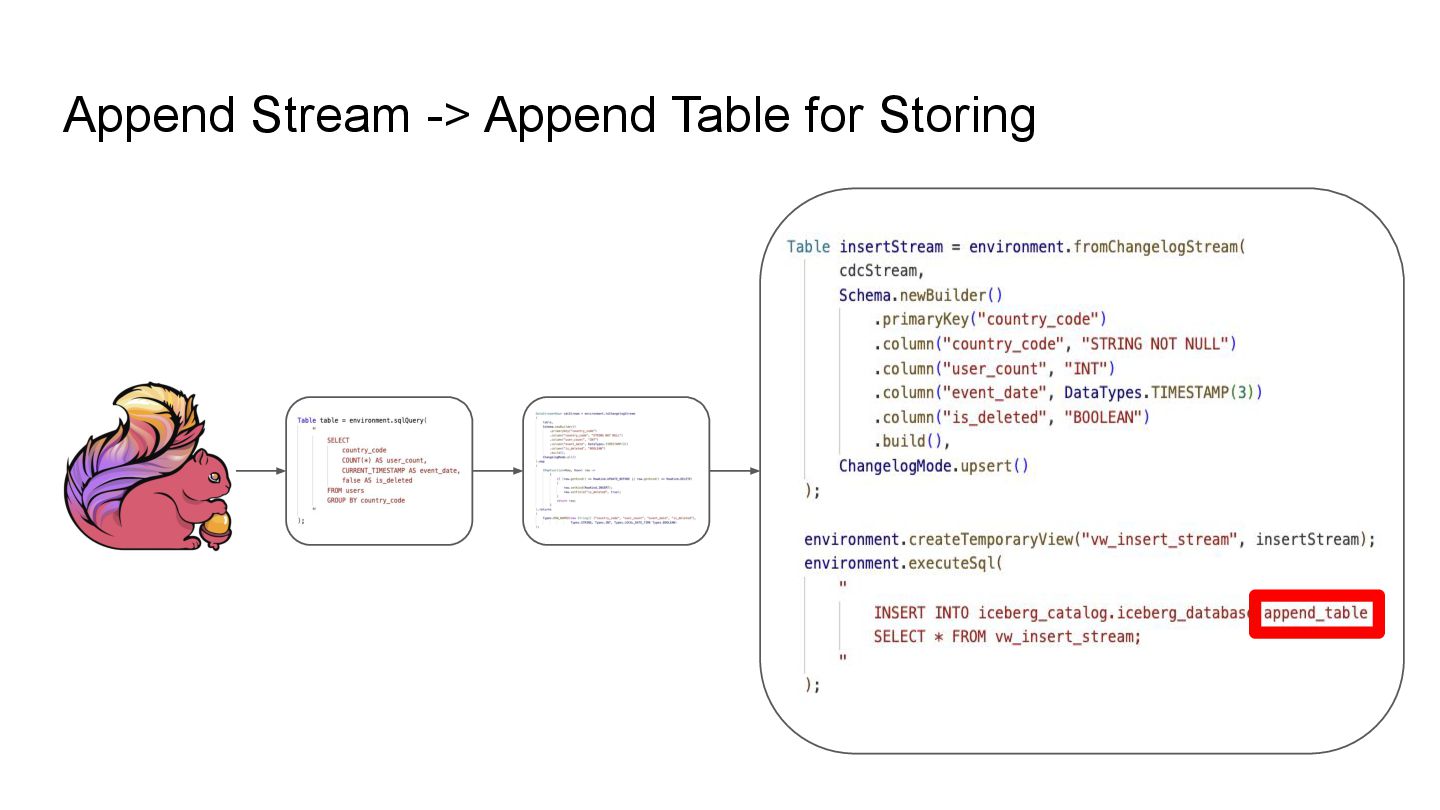
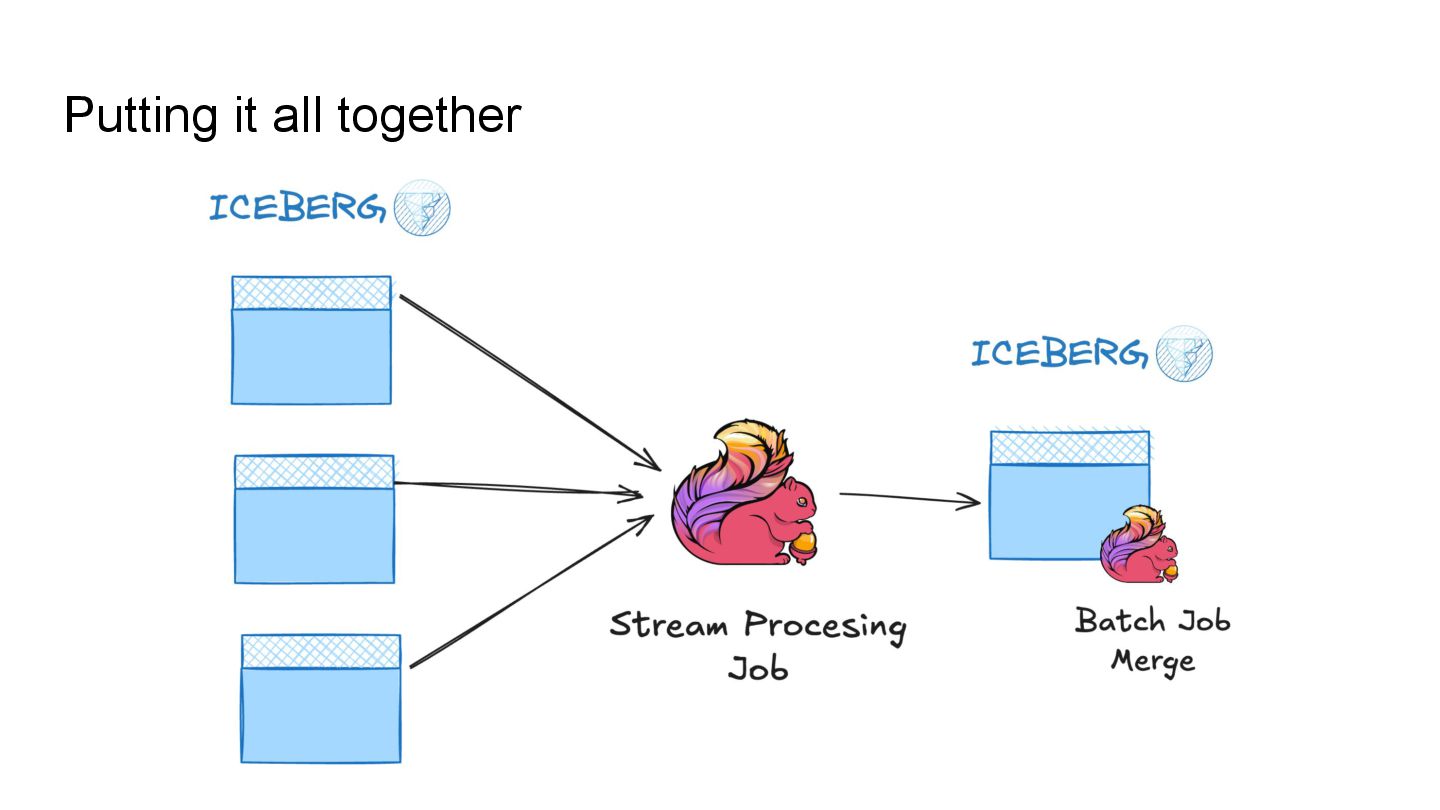
In this talk, we’ll explore how to implement incremental change processing over Iceberg V2 using Apache Flink, by writing change data streams as append tables and reading append tables as change streams. We’ll also walk through trade-offs between append and upsert modes, and how to choose the right one for your workload.
Finally, we’ll preview what Iceberg V3 brings to the table with native CDC support, and how it shifts the design landscape for real-time pipelines. If you're building data pipelines on Iceberg, this session will provide you with pragmatic strategies to overcome existing limitations and scale efficiently while keeping the infrastructure simple.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}