This talk was given at Current25 London.
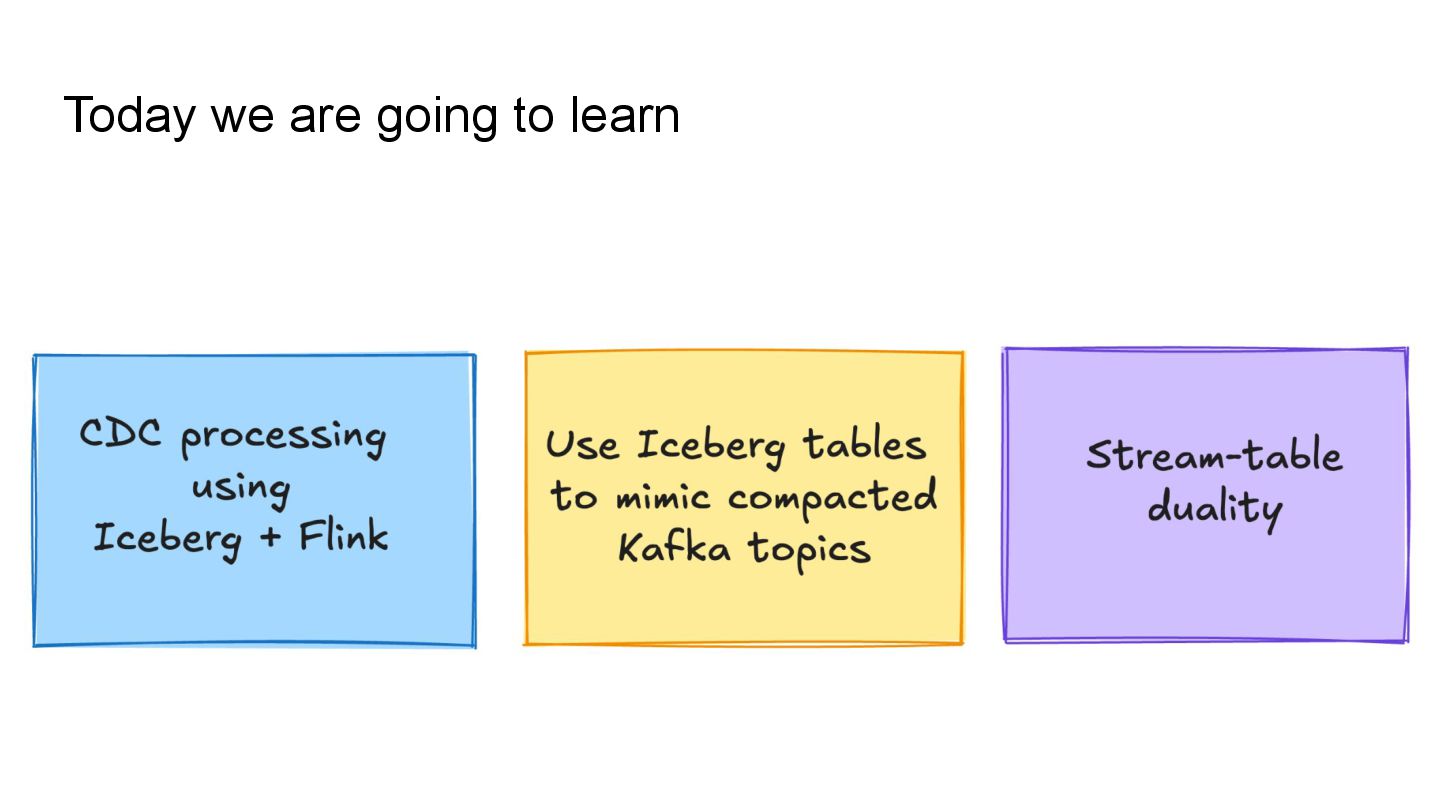
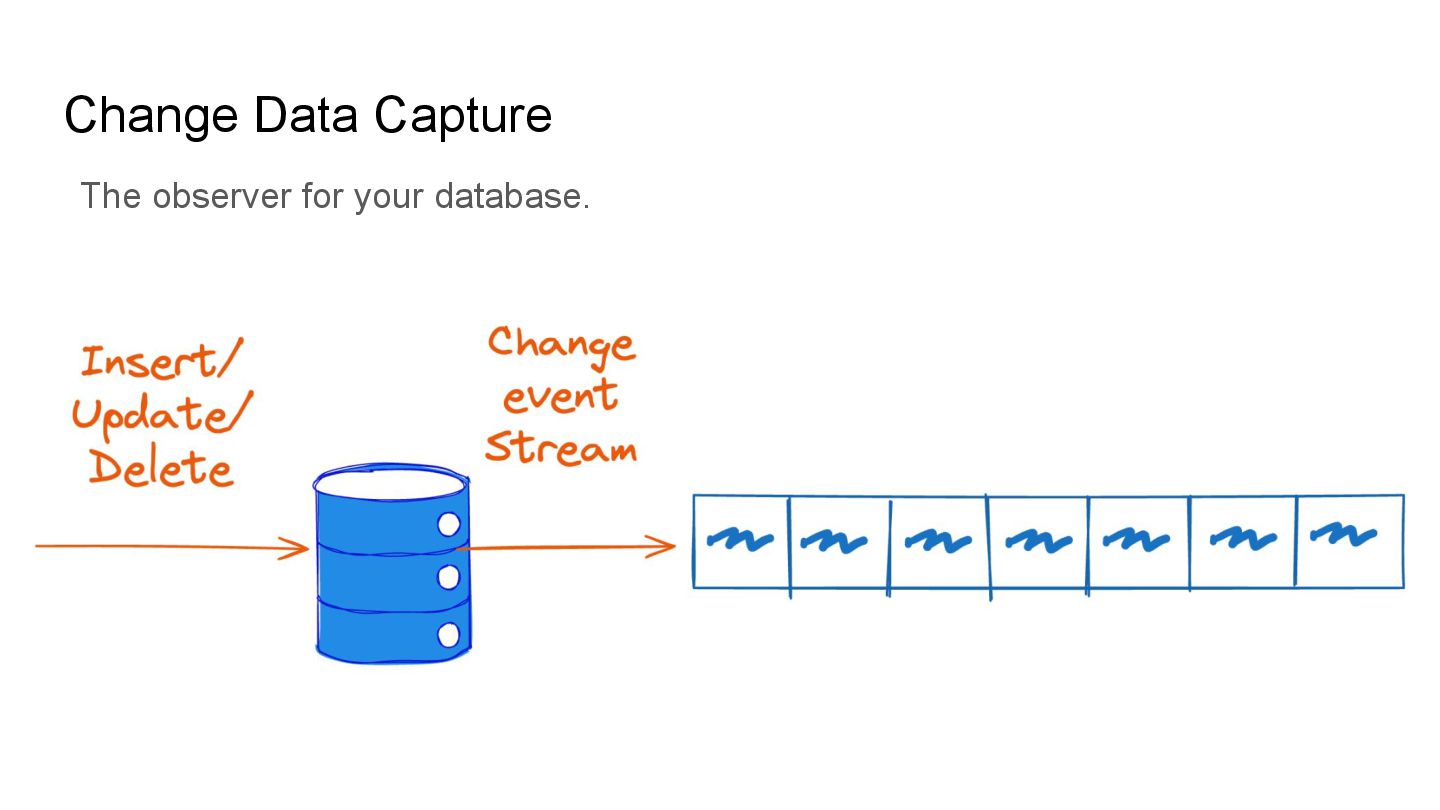
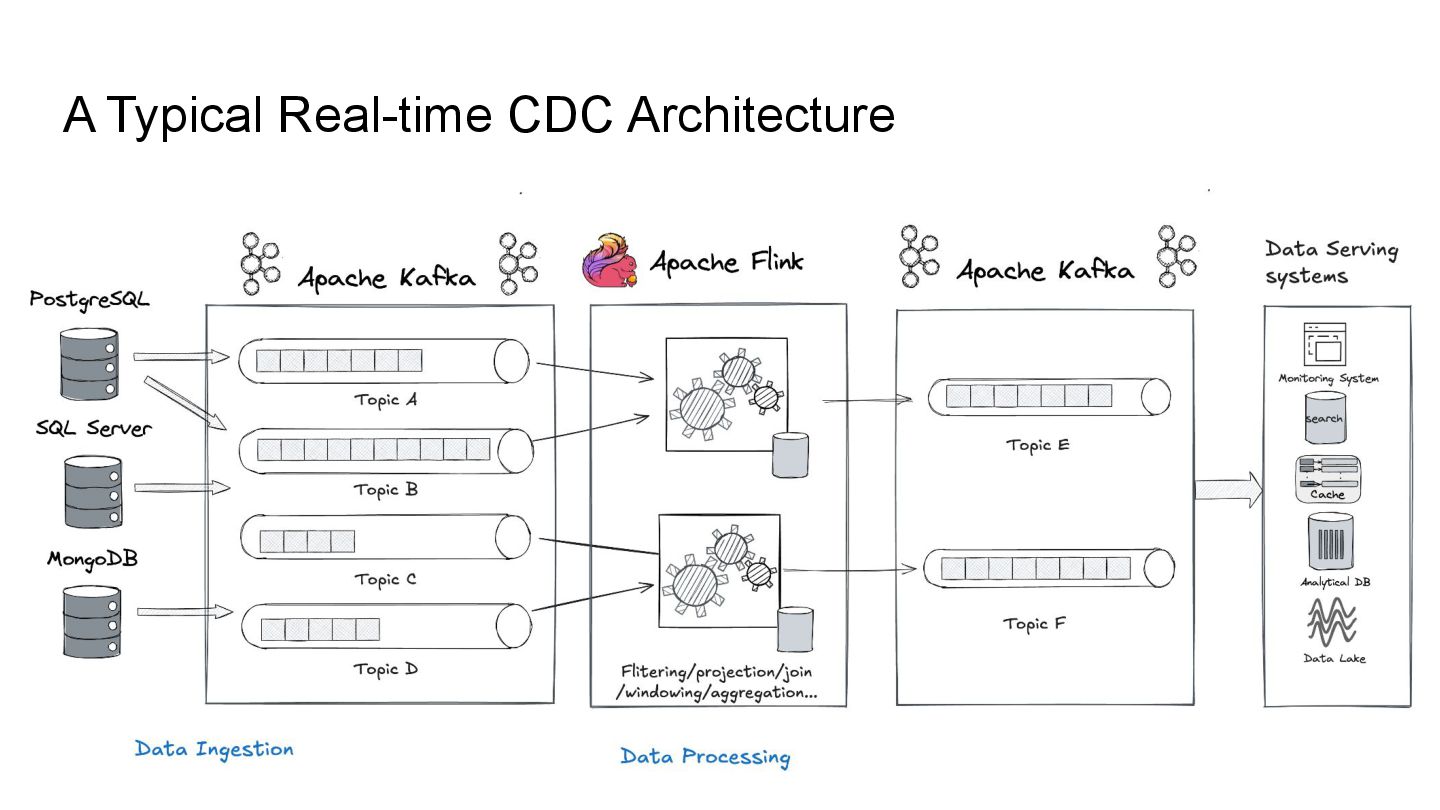
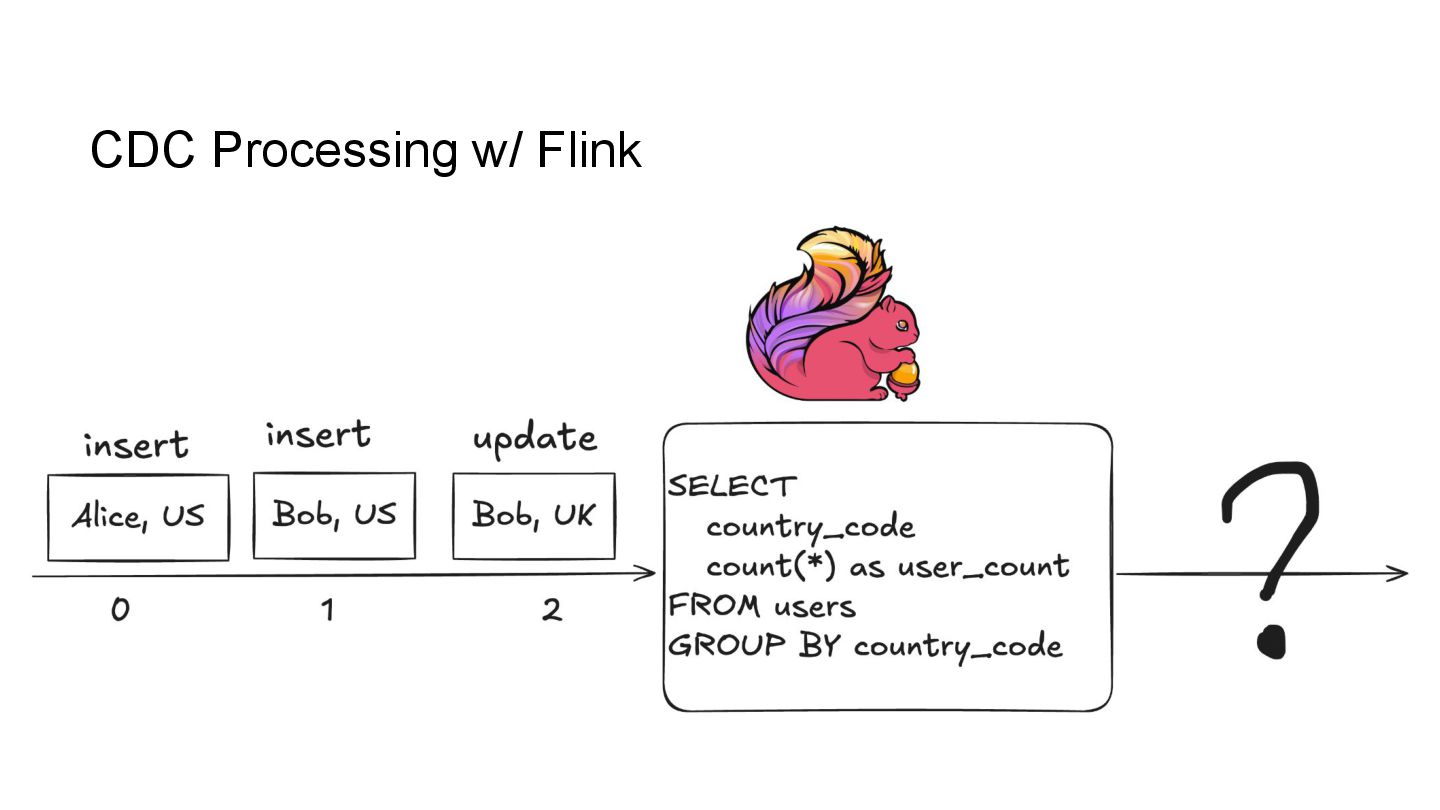
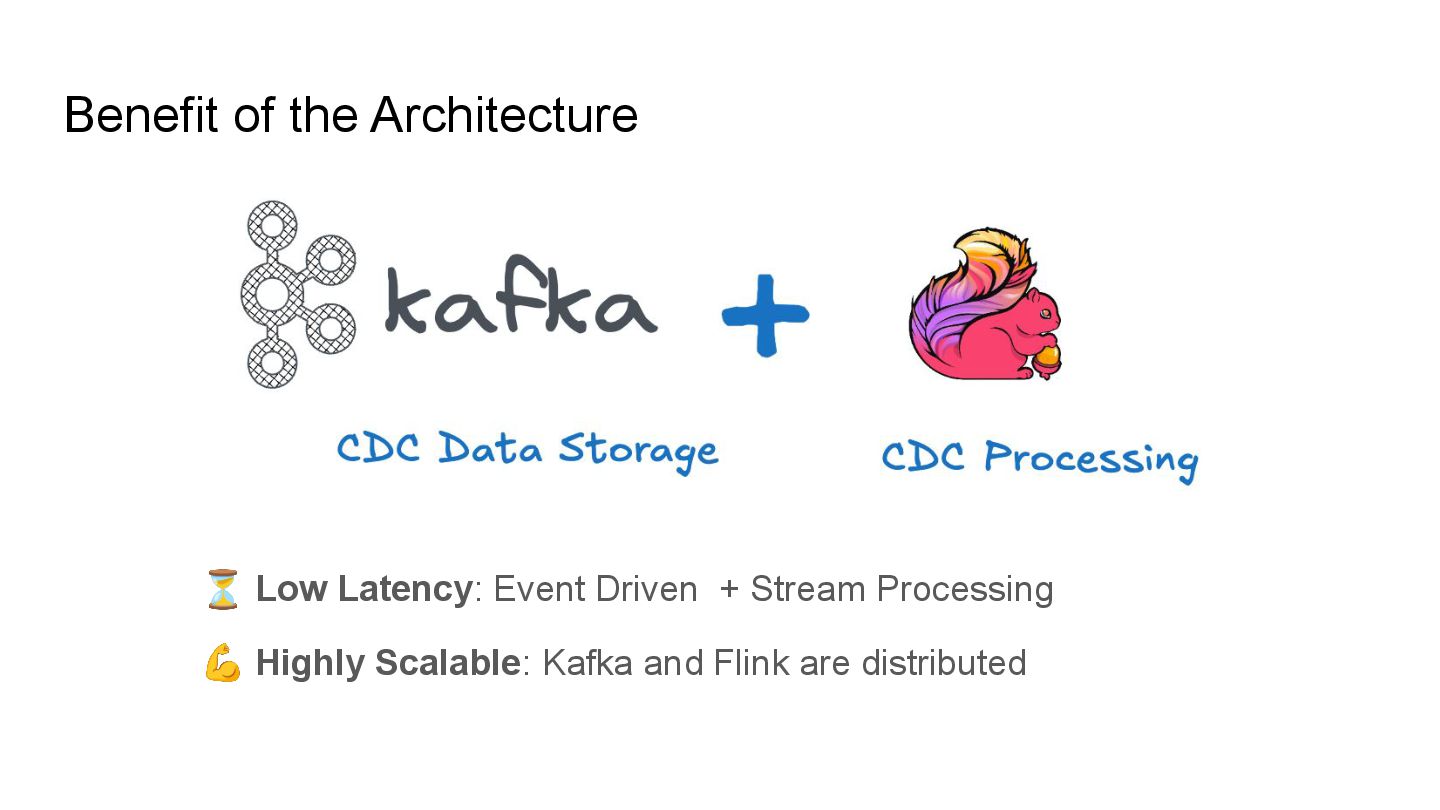
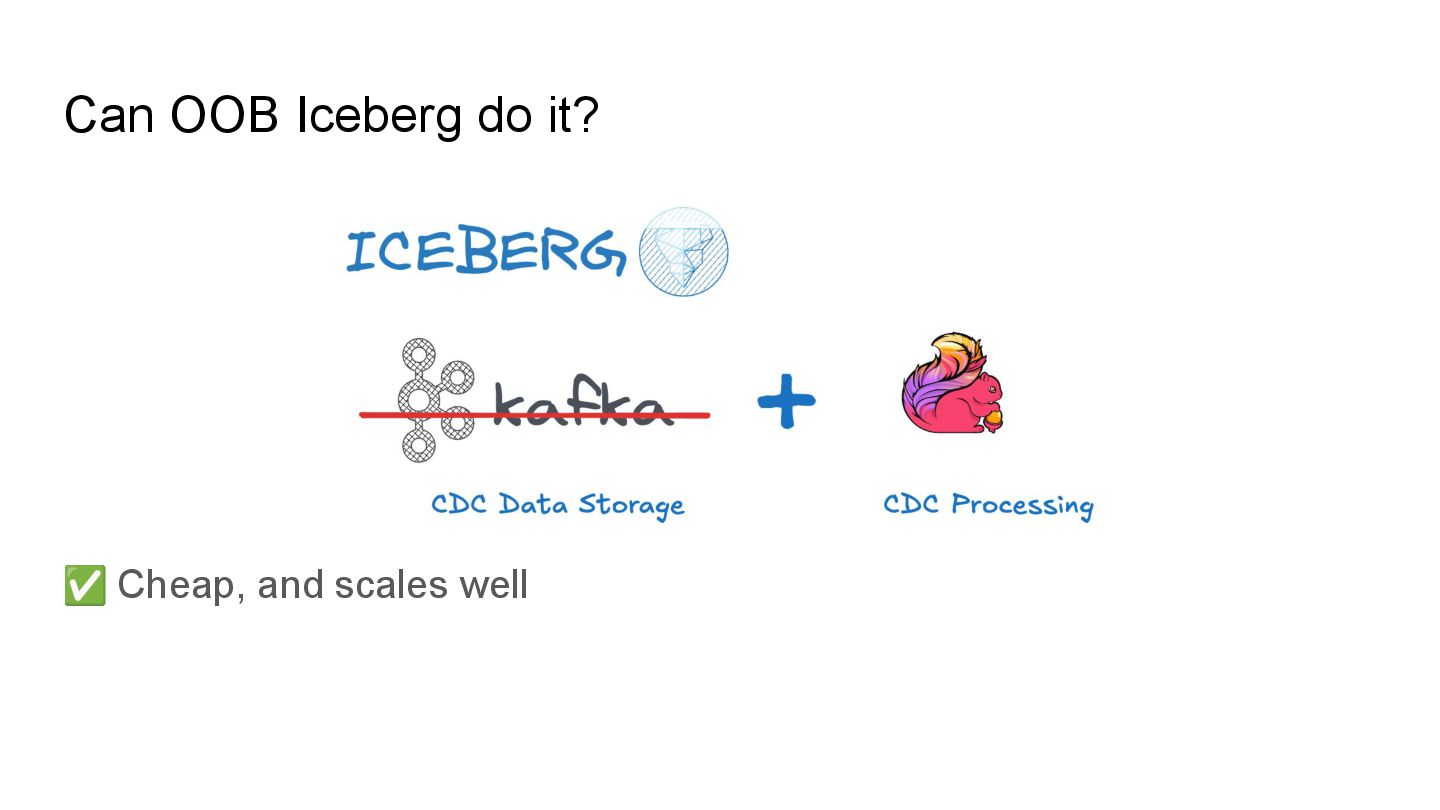
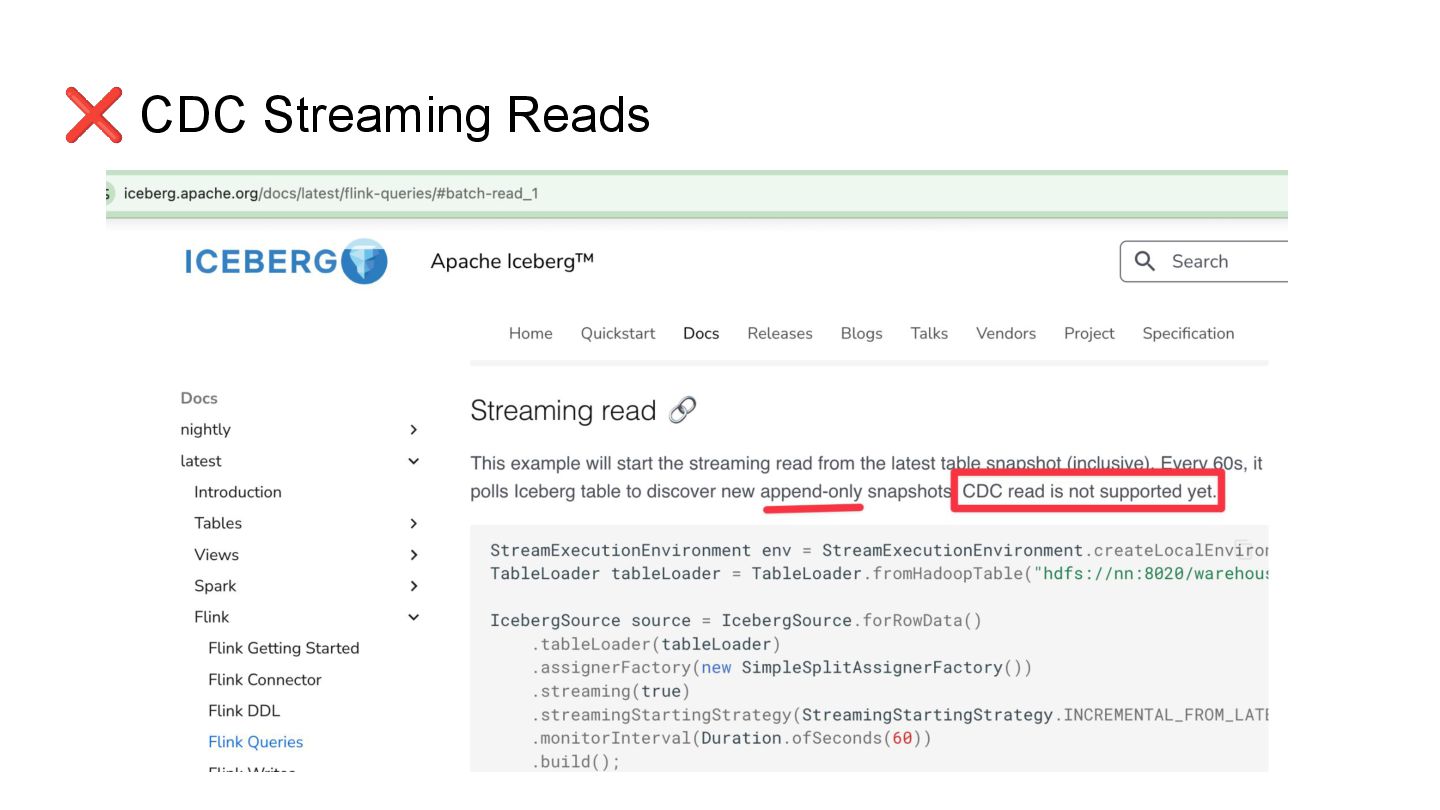
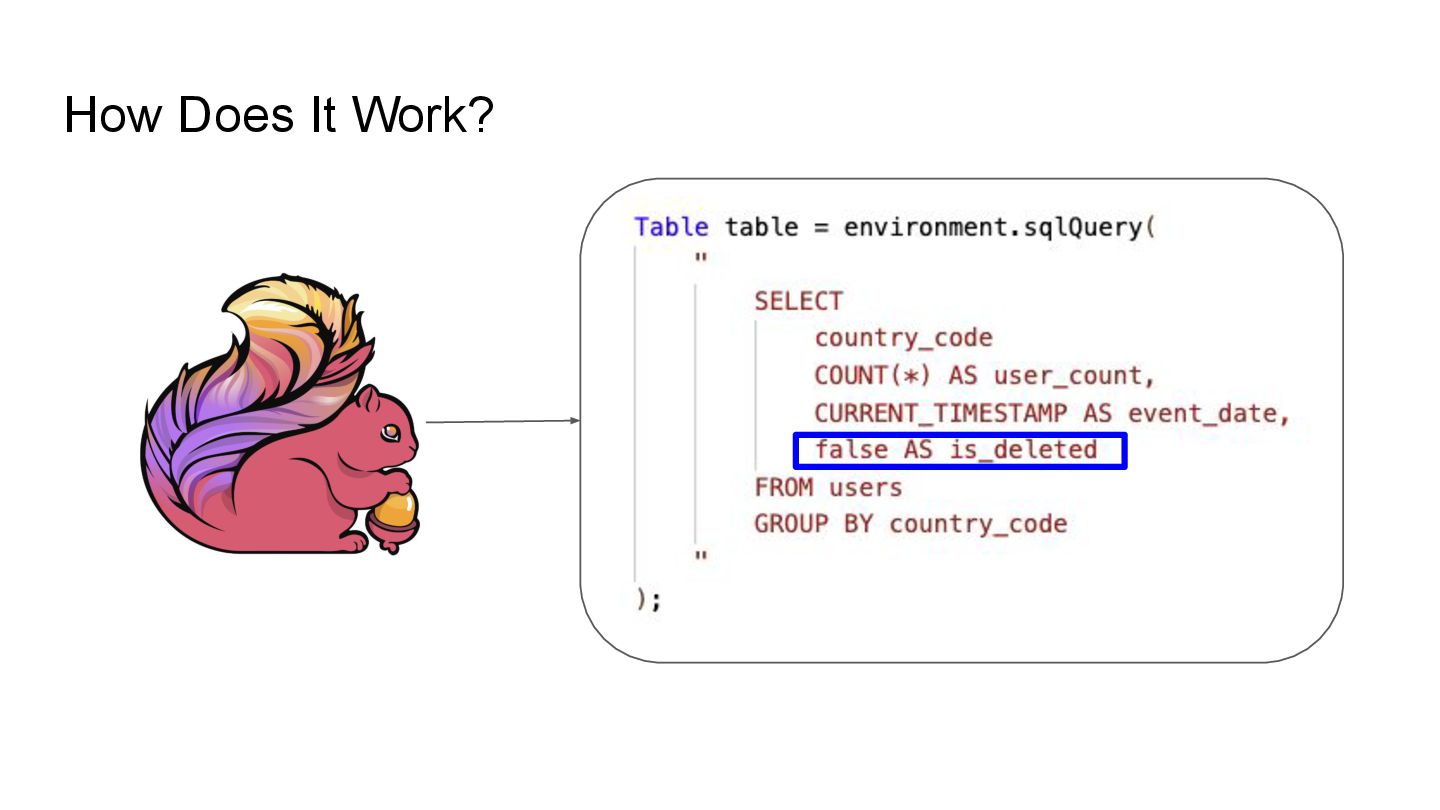
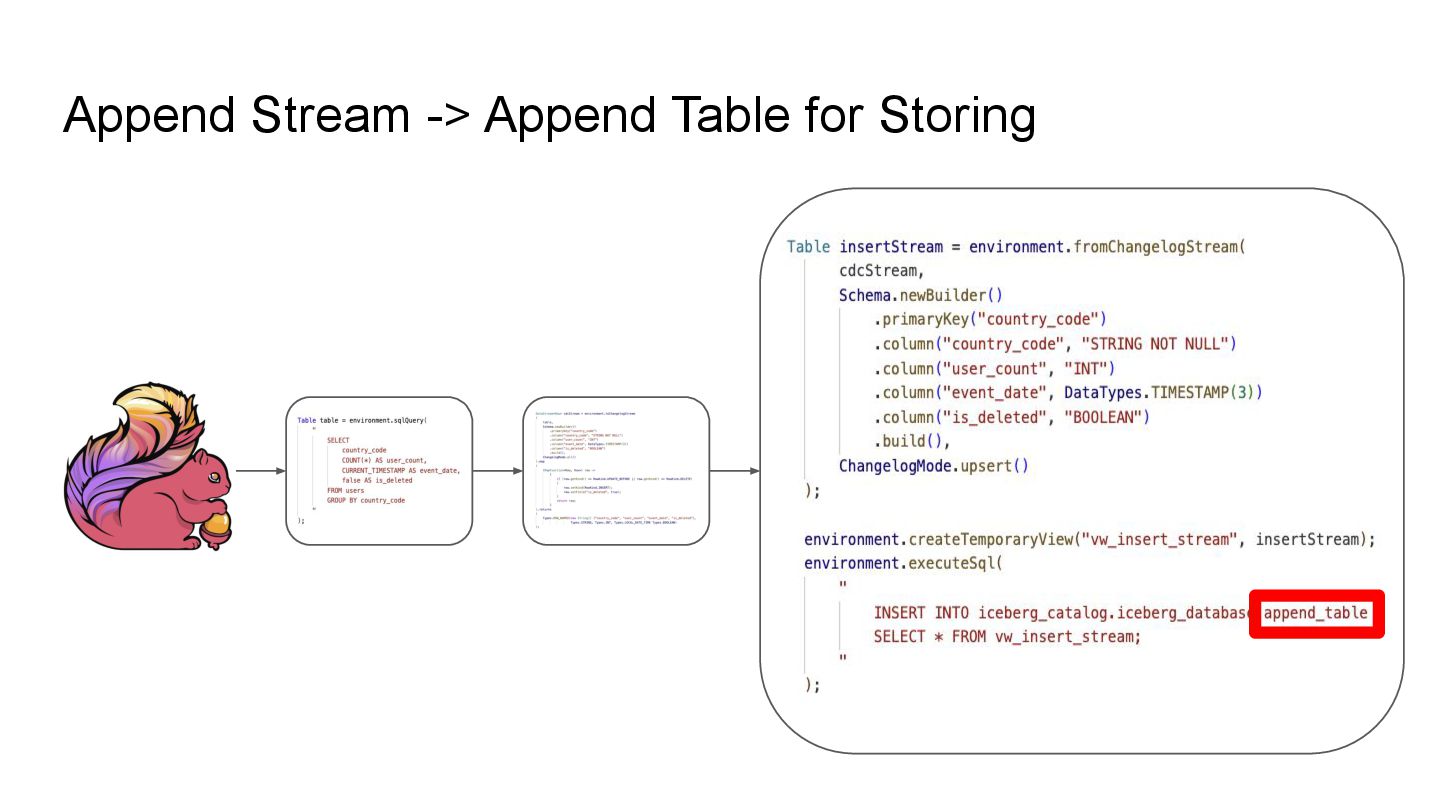
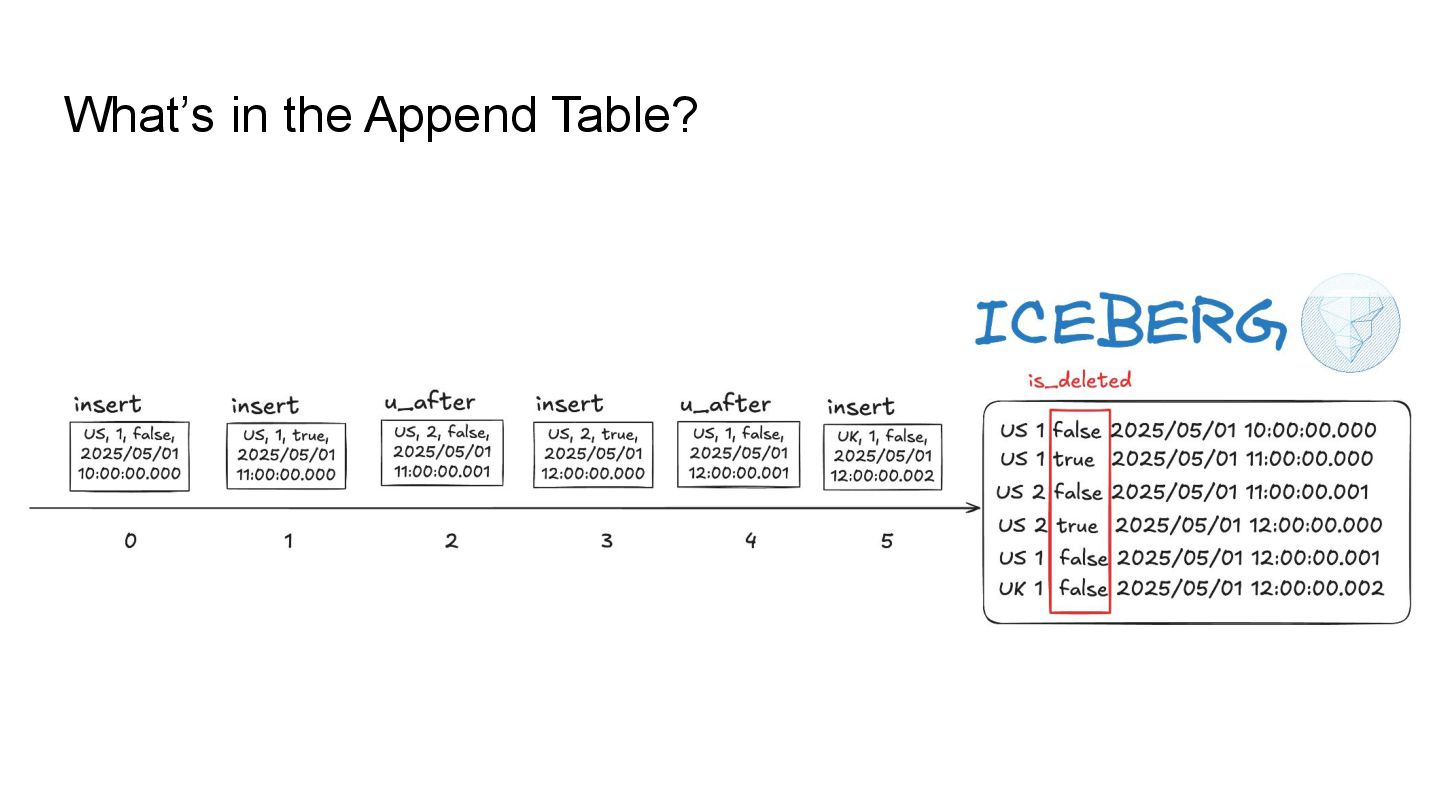
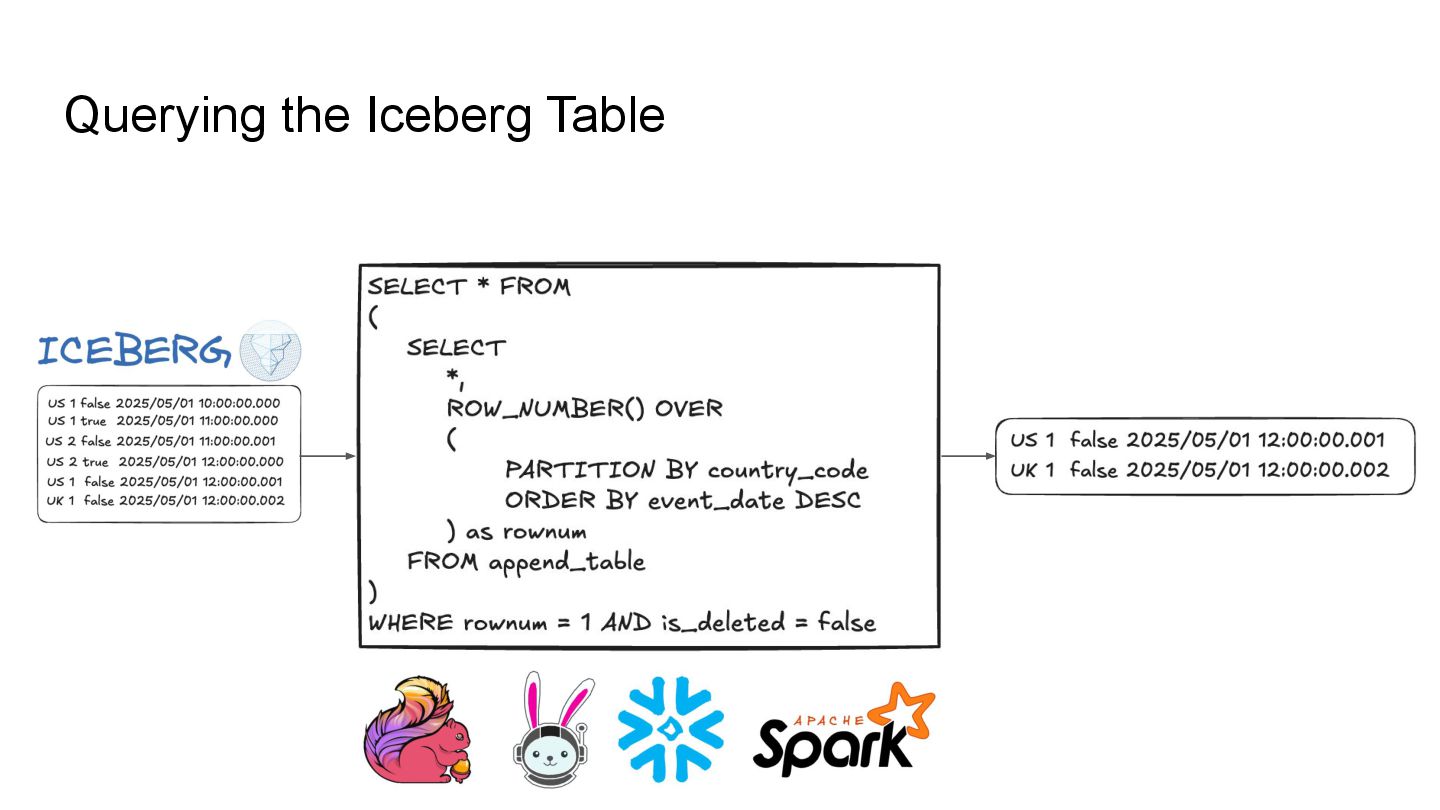
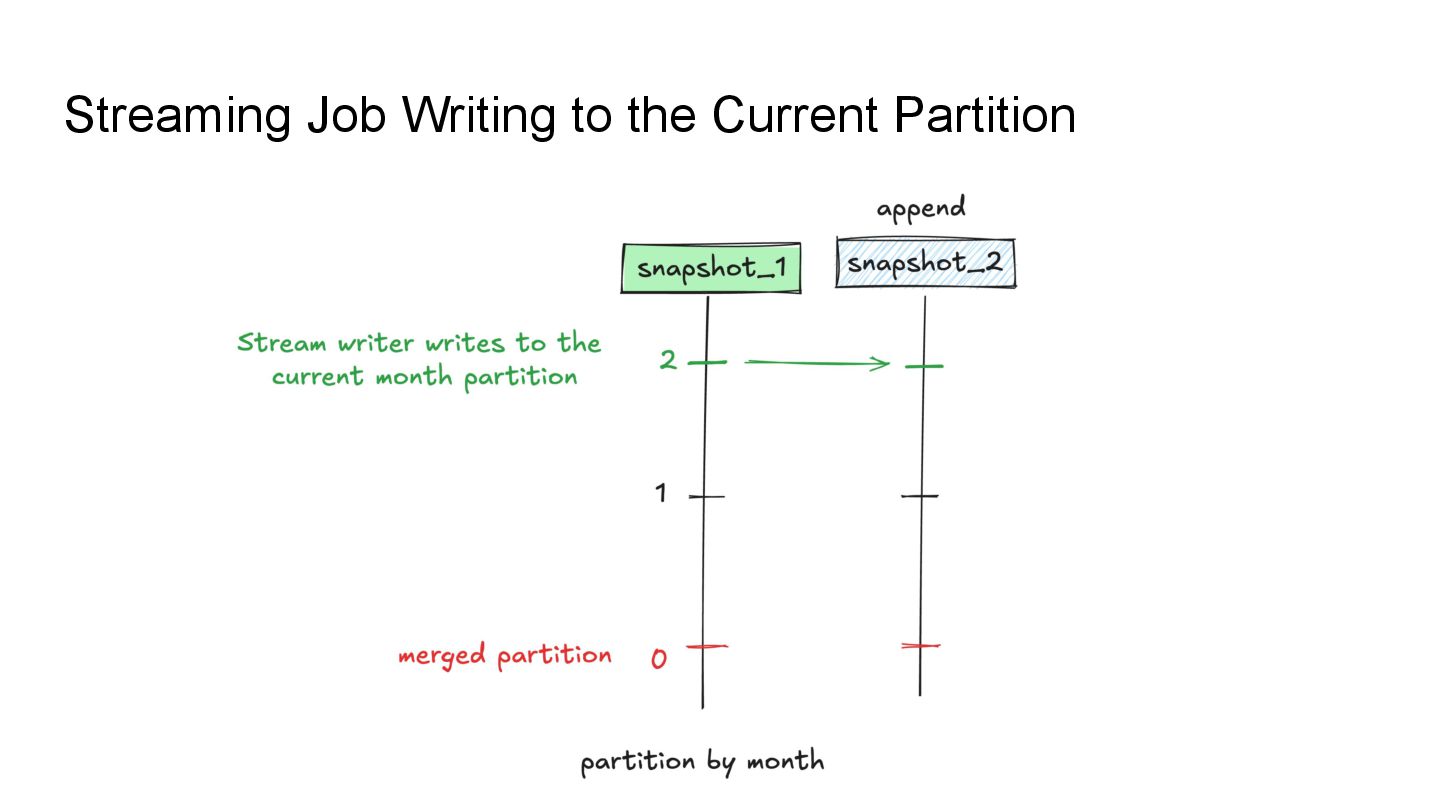
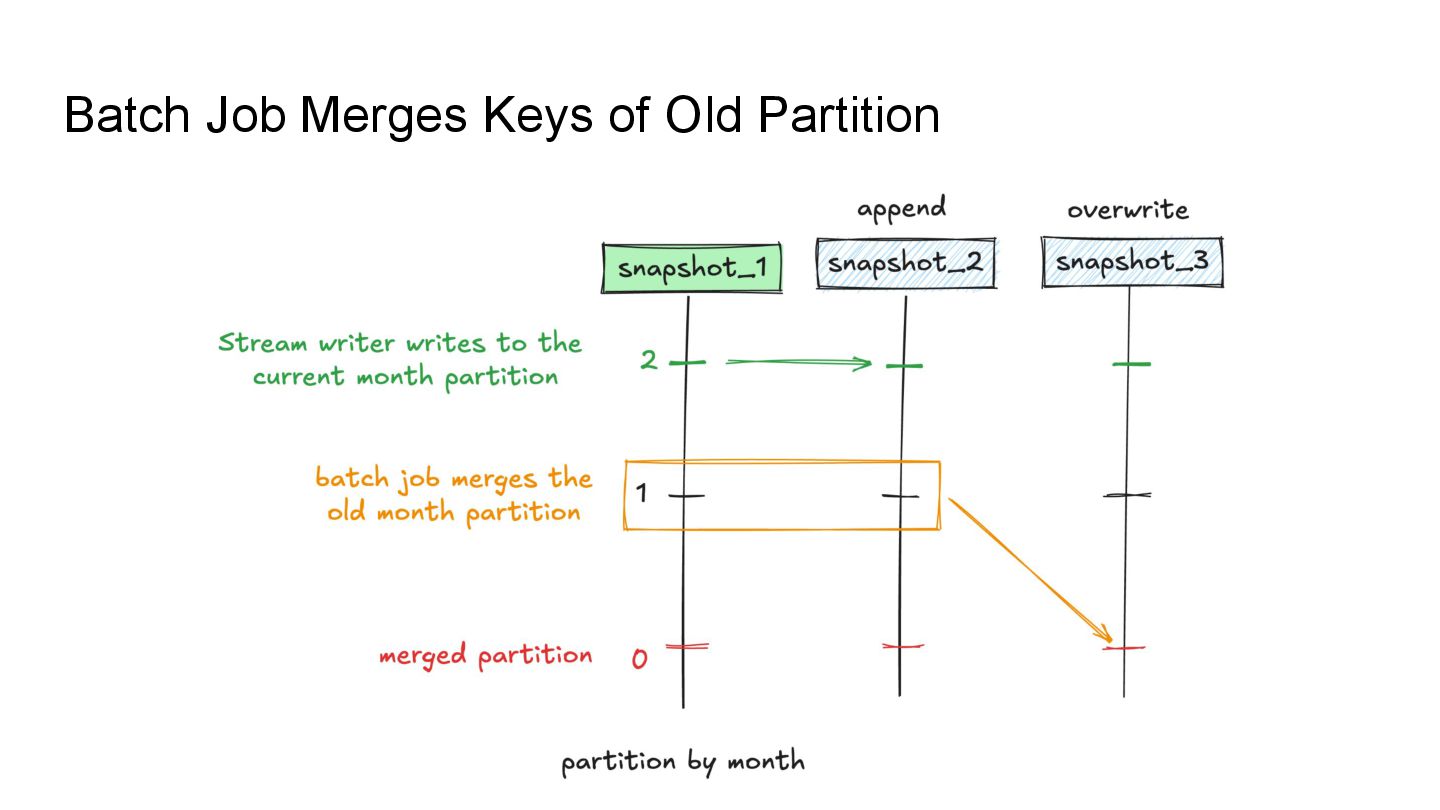
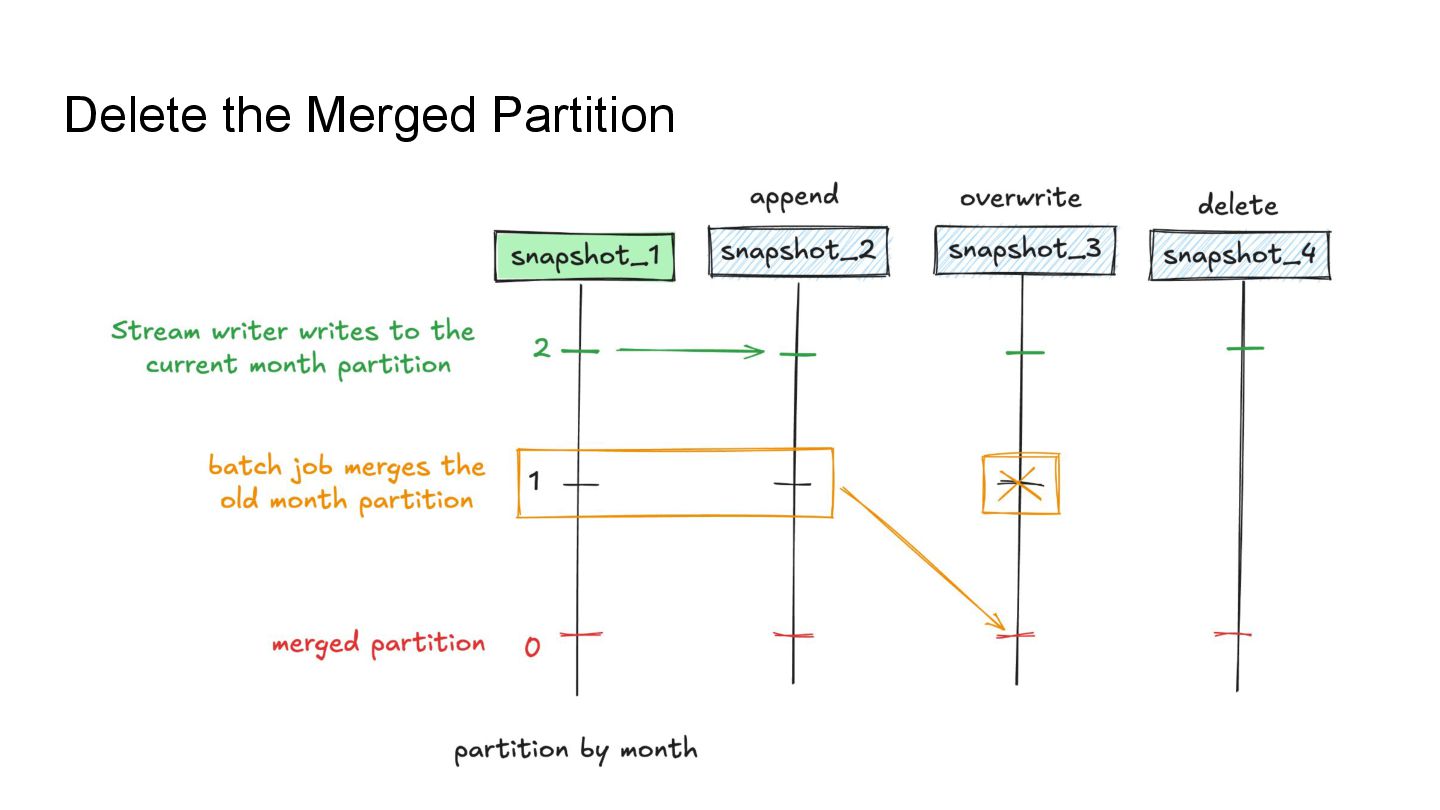
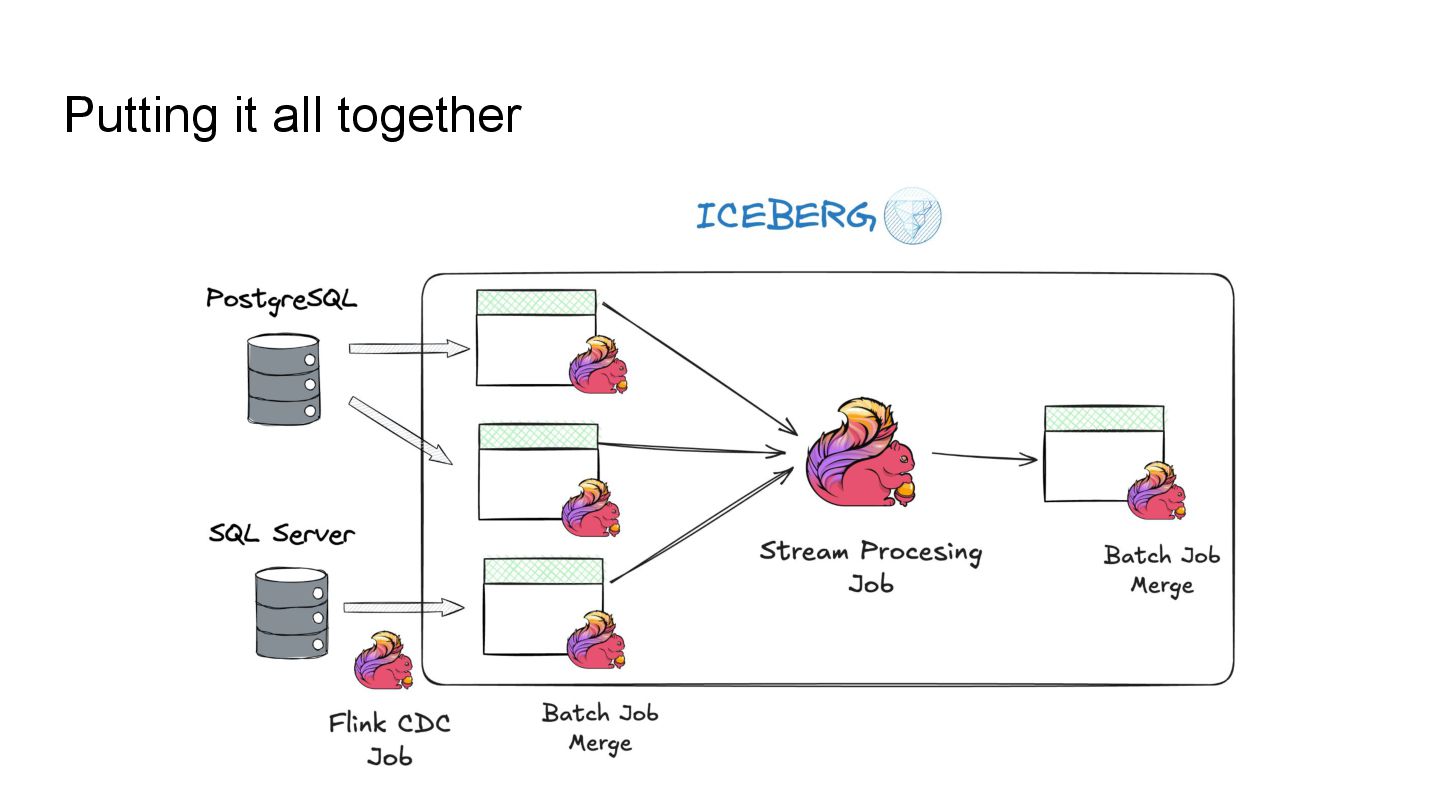
Apache Iceberg is a robust foundation for large-scale data lakehouses, yet its incremental processing model lacks native support for CDC, making updates and deletes challenging. While many teams turn to Kafka and Flink for CDC processing, this comes with high infrastructure costs and operational complexity. We needed a cost-effective solution with minute-level latency that supports dozens of terabytes of CDC data processing per day. Since we were already using Flink for Iceberg ingestion, we set out to extend it for CDC processing as well. In this session, we’ll share how we tackled this challenge by writing change data streams as append tables and reading append tables as change streams. This approach makes Iceberg tables function like Kafka topics, with two added benefits: Iceberg tables remain directly queryable, making troubleshooting and application integration more approachable and streamlined. Similar to Kafka consumers, multiple engines can independently process Iceberg tables. However, unlike Kafka clusters, there is no need to scale infrastructure. We will also explore optimization opportunities with Iceberg and Flink, including when to materialize tables and how to choose between append and upsert modes to enhance integration. If you’re working on data processing over Iceberg, this session will provide practical, battle-tested strategies to overcome limitations and scale efficiently while keeping the infrastructure simple.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}