позицией его работодателя, начальника, коллег или других специалистов. Все представленные в докладе сведения, примеры, выводы и другую информацию вы можете использовать на свой страх и риск. За все ваши действия ответственность несёте только вы сами.
хороший визуальный мониторинг (Grafana + ClickHouse) • Старались не просто закрывать инцидент, а находить root cause и закрывать его ◦ Десятки major патчей и рефакторингов ◦ Иногда полностью переписывали компоненты • Стали считать быстрее, появился запас по времени
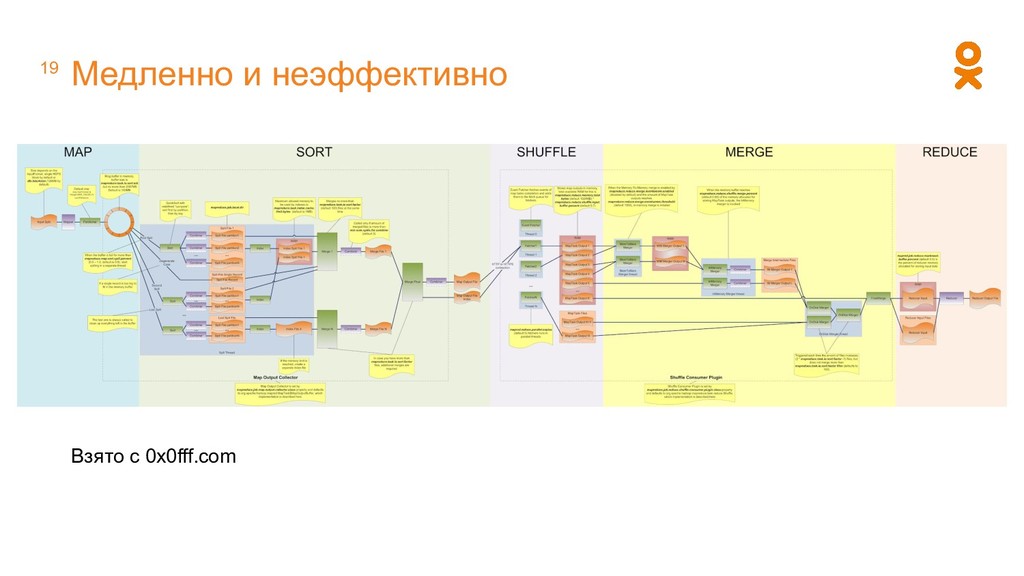
регулярных расчетах провоцирует дублировать код? • Не было хороших практик из software development (automatic tests, code review, etc) • Много разных проектов, которые делались, как правило, одним человеком • Дублирование функций и кода
Количество расчетов готовых/неготовых поминутно ◦ Время “в ошибках”, кол-во ошибок ◦ Топы по времени, кол-ву ошибок ◦ Можно смотреть статистику по любому расчету отдельно • Картина по воркерам
◦ Надо ставить четкую цель ◦ Декларировать средства ее достижения • Разделение команды на инженеров и аналитиков ◦ Не надо запрещать брать задачи из обоих пулов ◦ Но должен быть системный подход и единые требования • Могут быть конфликты, будут недовольные • Разработчикам нравится • Аналитикам тяжелее ◦ Если не хотят программировать, пусть работают с готовыми витринами
• Чтобы правильно приготовить Hadoop нужны Software Engineers/Devops ◦ Нужна общая экспертиза в JVM • Data Engineering это код + инфраструктура • Команда должна быть готова • Изменения нужно делать постепенно, но последовательно
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}