timeuuid, type_id int, ..... PRIMARY KEY ((user_id, shard_part), id) ) WITH CLUSTERING ORDER BY (id DESC); CREATE TABLE NotificationByUserAndType ( ..... PRIMARY KEY ((user_id, type_id, shard_part), id) ) WITH CLUSTERING ORDER BY (id DESC); CREATE TABLE NotificationSeen ( user_id bigint, id timeuuid, value boolean, PRIMARY KEY (user_id, id) ) WITH CLUSTERING ORDER BY (id DESC);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
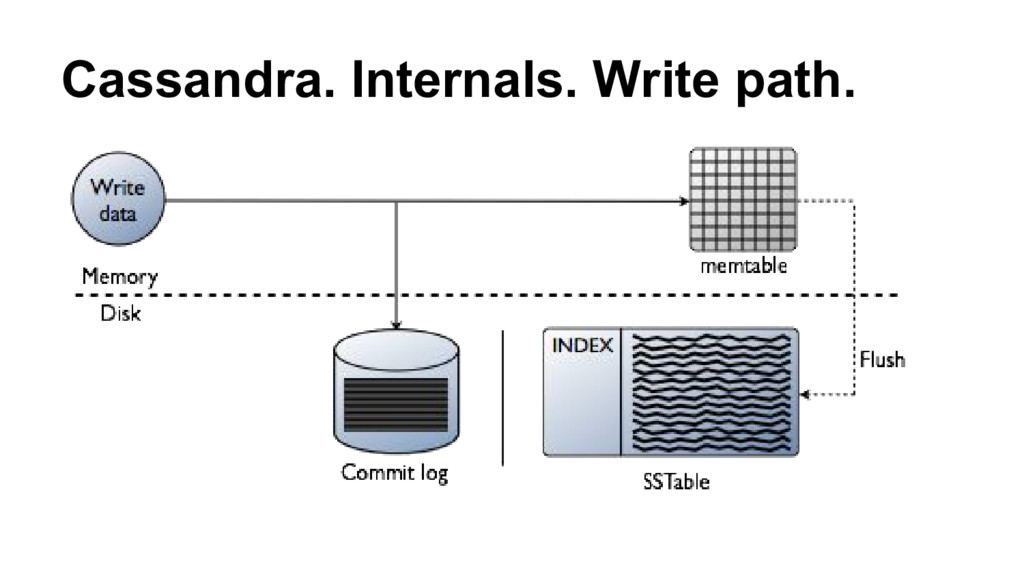{kind=link}
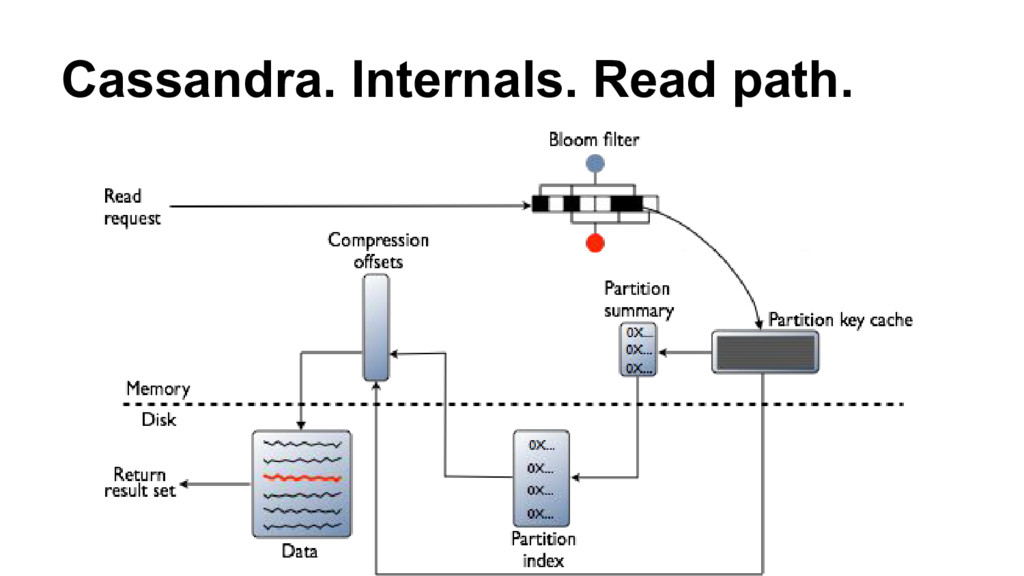{kind=link}
{kind=link}
{kind=link}
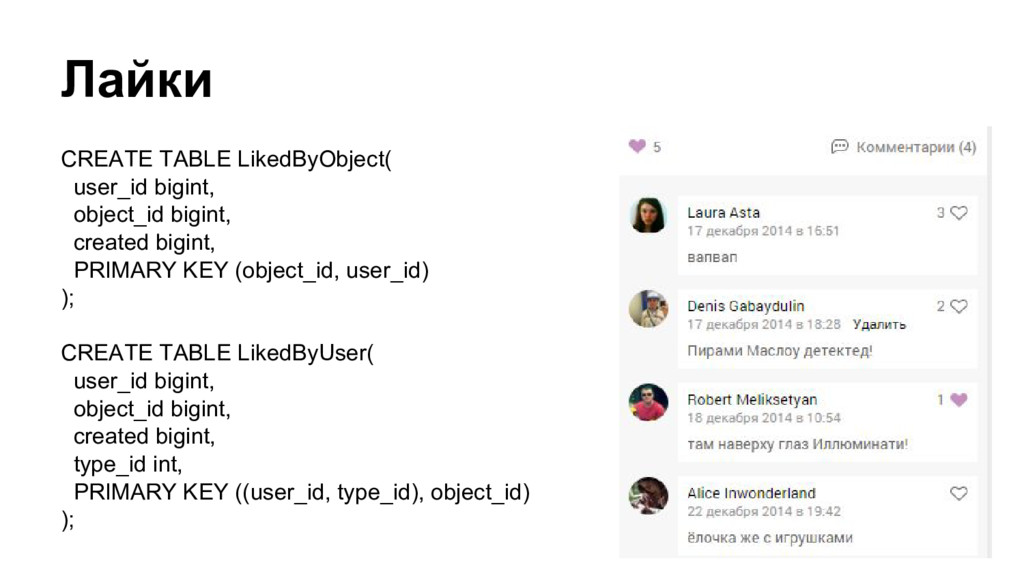{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы https://facebook.com/denis.gabaydulin (messanger) [email protected]](https://files.speakerdeck.com/presentations/8e378035d7b64b8e8b39370b789296b9/slide_31.jpg){kind=link}