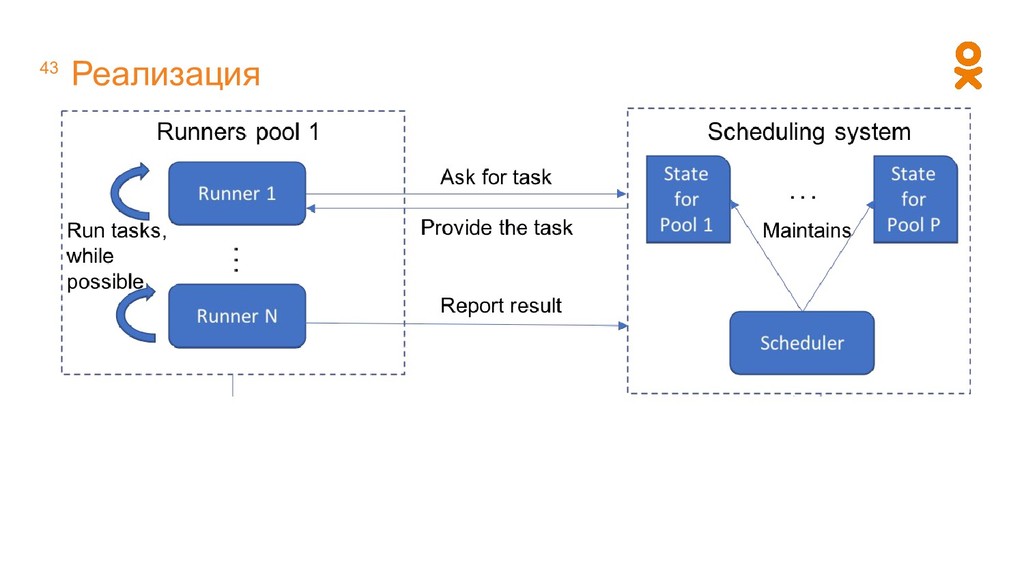
Hive или Spark. Воркер - программа, которая запускает расчет. Воркер запускает расчеты последовательно. Параллельный запуск расчетов требует n воркеров.
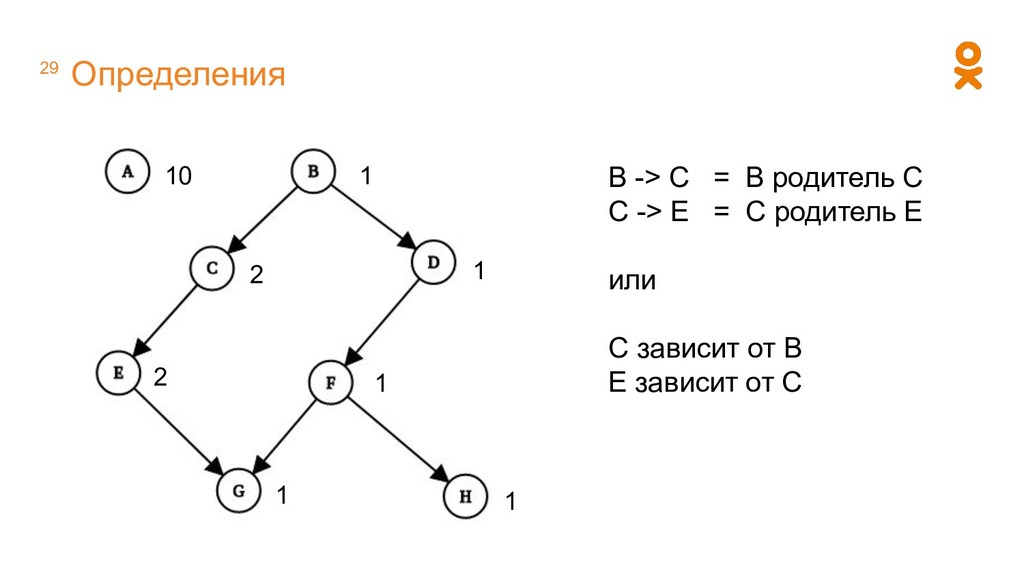
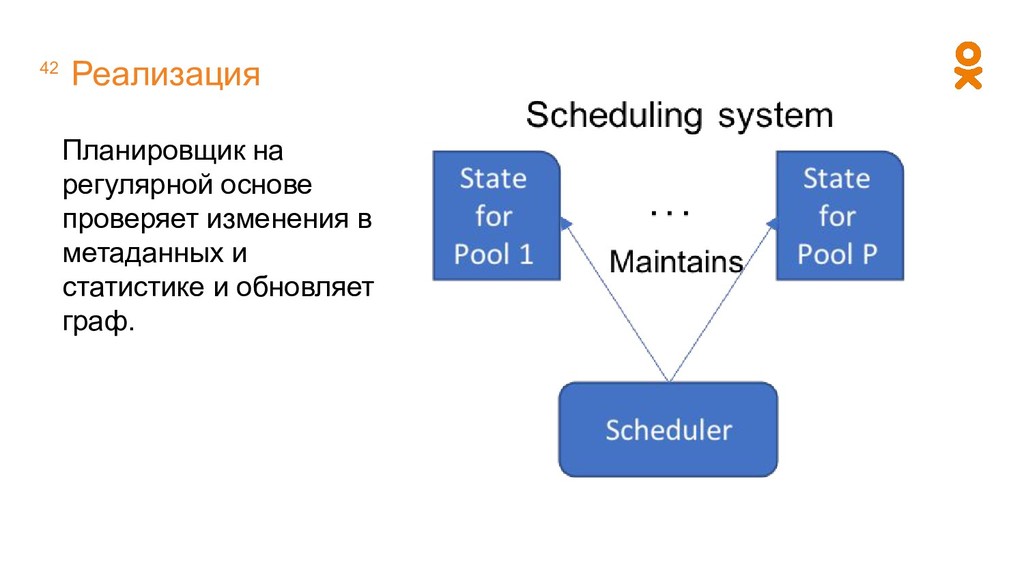
регулярных расчетов, можно поддерживать граф вычислений вручную. У нас было именно так. К каждому воркеру статически были привязаны конкретные расчеты.
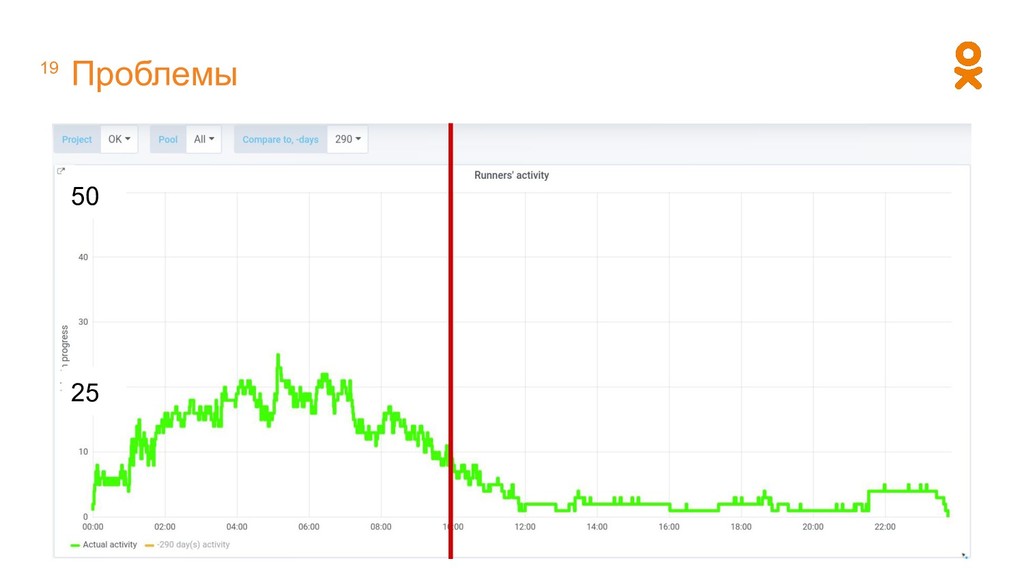
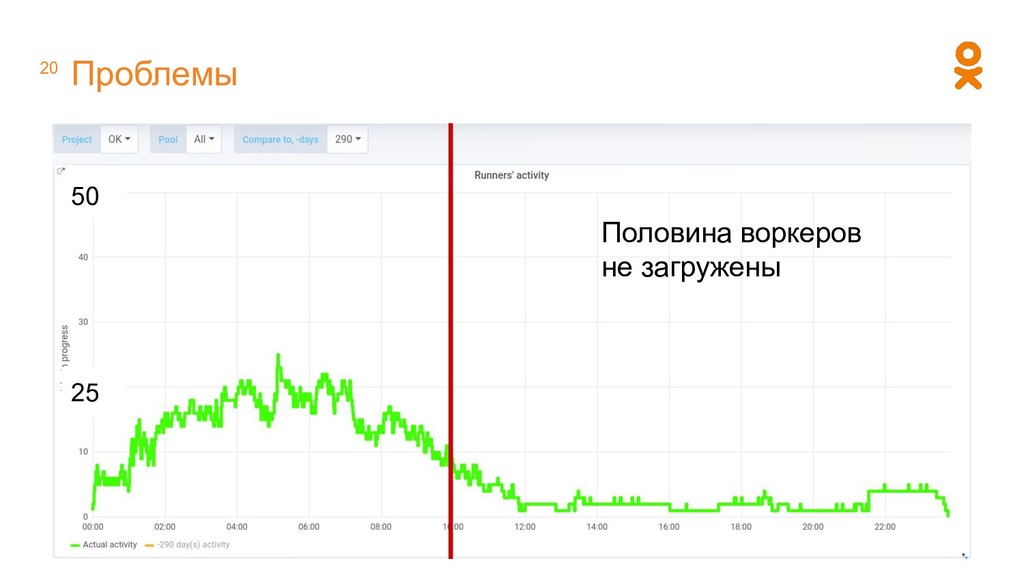
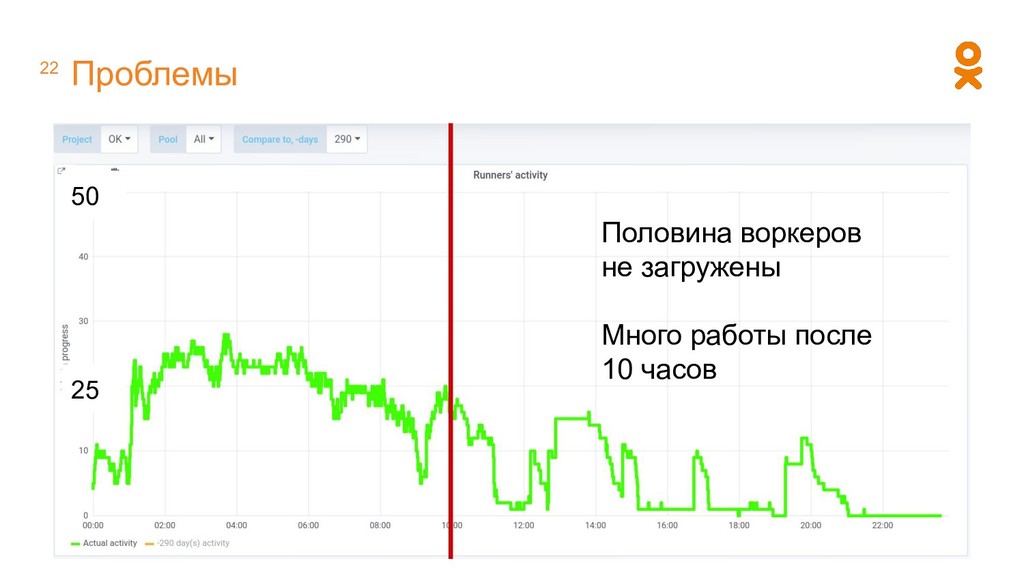
• При добавлении расчета надо руками определять, где он будет запускаться • Разные системы имеют свой механизм распределения задач • Кластер используется неэффективно
(лучше раньше) • Быстрое восстановление после аварий и инцидентов • Совместимость со всеми системами расчетов (Spark, HIVE, custom) • Простое масштабирование системы
внедрение • Контроль над алгоритмом обхода графа (topsort) • На первом этапе достаточно библиотеки для клиента, и не нужна сложная инфраструктура в виде сервисов • Python, а у нас все на Java
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}