Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Lets start mlops
Search
shibuiwilliam
March 17, 2022
Technology
120
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Lets start mlops
https://tier4.connpass.com/event/217726/
shibuiwilliam
March 17, 2022
More Decks by shibuiwilliam
See All by shibuiwilliam
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
2
440
From Prompt Engineering to Loop Engineering
shibuiwilliam
1
370
OntologyとLLMOps
shibuiwilliam
3
86
Rule repository
shibuiwilliam
3
65
LLM時代の検索アーキテクチャと技術的意思決定
shibuiwilliam
5
2.5k
Why Open Dataspacesのまとめ
shibuiwilliam
2
100
マルチモーダル非構造データとの闘い
shibuiwilliam
2
680
飽くなき自動生成への挑戦
shibuiwilliam
1
94
AIエージェントのメモリについて
shibuiwilliam
2
800
Other Decks in Technology
See All in Technology
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
490
穢れた技術選定について
watany
19
6.2k
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
790
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.5k
Jitera Company Deck
jitera
0
280
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
530
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
490
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
1
270
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
reFACToring
moznion
0
200
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
330
Featured
See All Featured
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
380
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
How to make the Groovebox
asonas
2
2.3k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
A better future with KSS
kneath
240
18k
Navigating Team Friction
lara
192
16k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Transcript
今日から始める MLOps 2021/07/29 shibui yusuke 1
自己紹介 shibui yusuke • ティアフォーでよろず屋兼イベント係 • MLOpsコミュニティのオーガナイザー • もともとクラウド基盤の開発、運用。 •
ここ5年くらいMLOpsで仕事。 • Github: @shibuiwilliam • Qiita: @cvusk • FB: yusuke.shibui • 最近やってること: Golangとデータ分析とBI cat : 0.55 dog: 0.45 human : 0.70 gorilla : 0.30 物体検知 2
今日話すこと • 最近よく聞く「MLOps」について説明します。 • ティアフォーで取り組んでいる事例とともに、 MLOpsの進め方を紹介します。 3
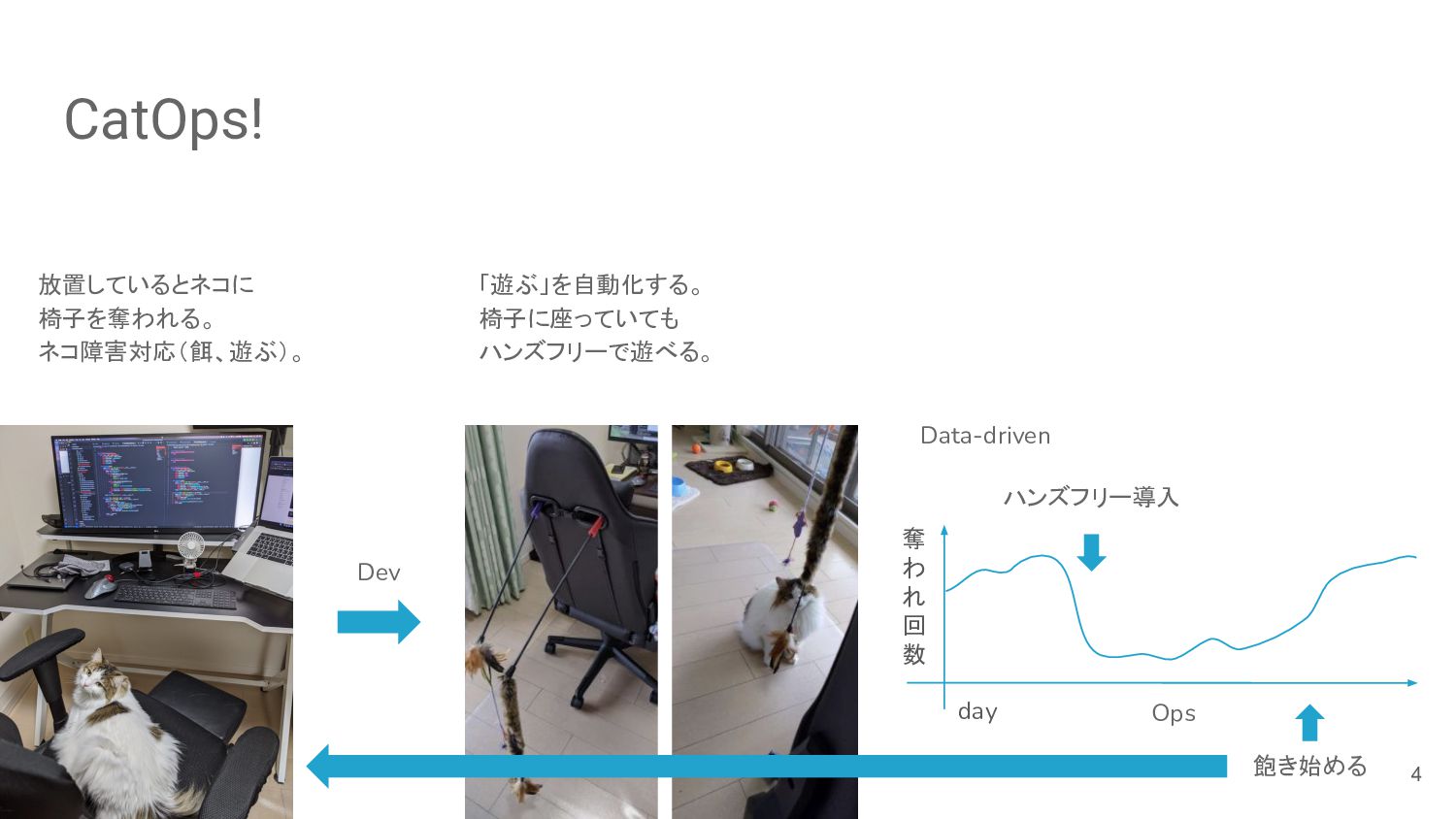
CatOps! 放置しているとネコに 椅子を奪われる。 ネコ障害対応(餌、遊ぶ)。 「遊ぶ」を自動化する。 椅子に座っていても ハンズフリーで遊べる。 day 奪 わ
れ 回 数 ハンズフリー導入 飽き始める Dev Data-driven 4 Ops
なぜ機械学習に DevOpsが必要か 5
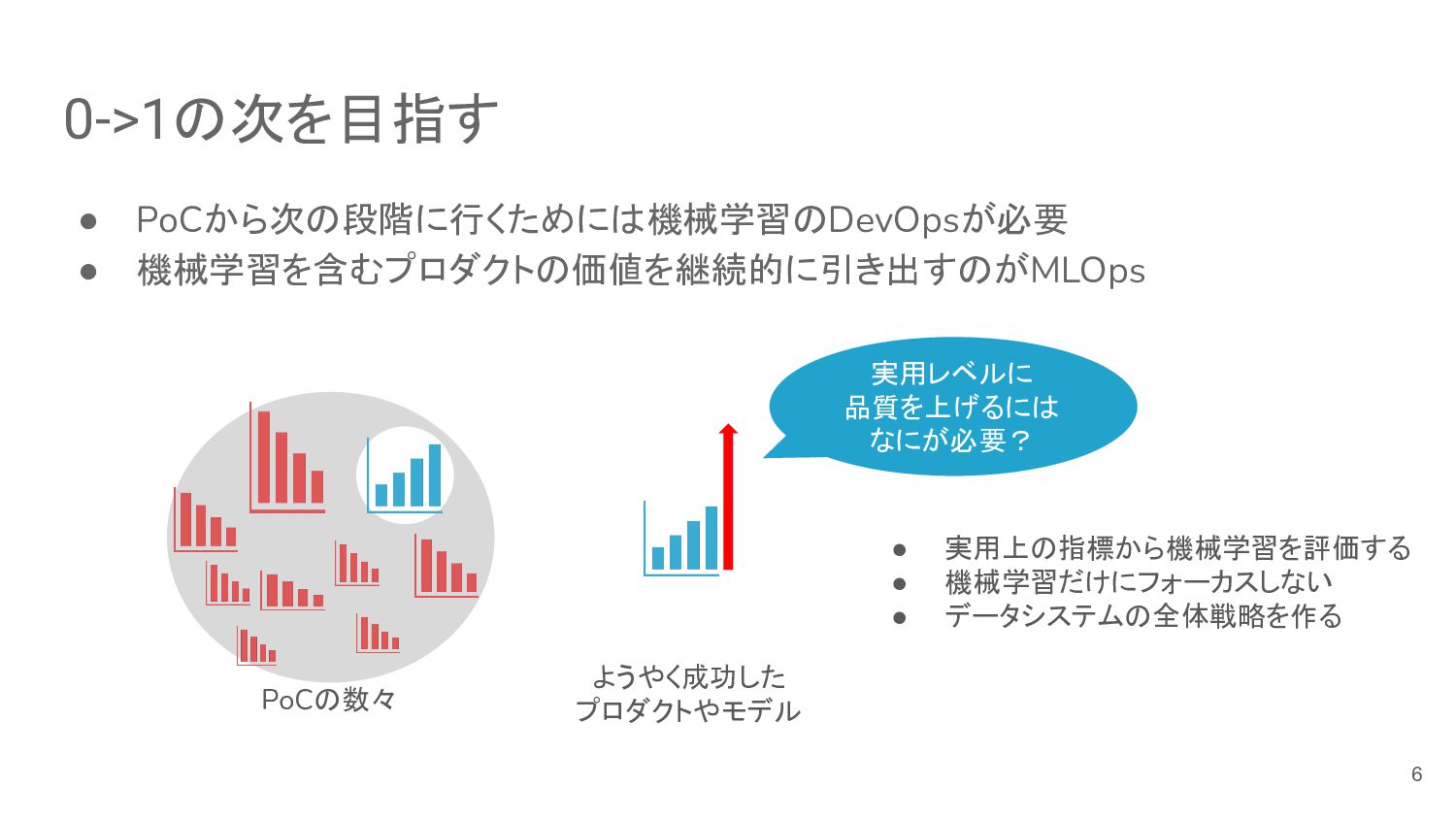
• PoCから次の段階に行くためには機械学習のDevOpsが必要 • 機械学習を含むプロダクトの価値を継続的に引き出すのがMLOps 0->1の次を目指す PoCの数々 ようやく成功した プロダクトやモデル 実用レベルに 品質を上げるには
なにが必要? • 実用上の指標から機械学習を評価する • 機械学習だけにフォーカスしない • データシステムの全体戦略を作る 6
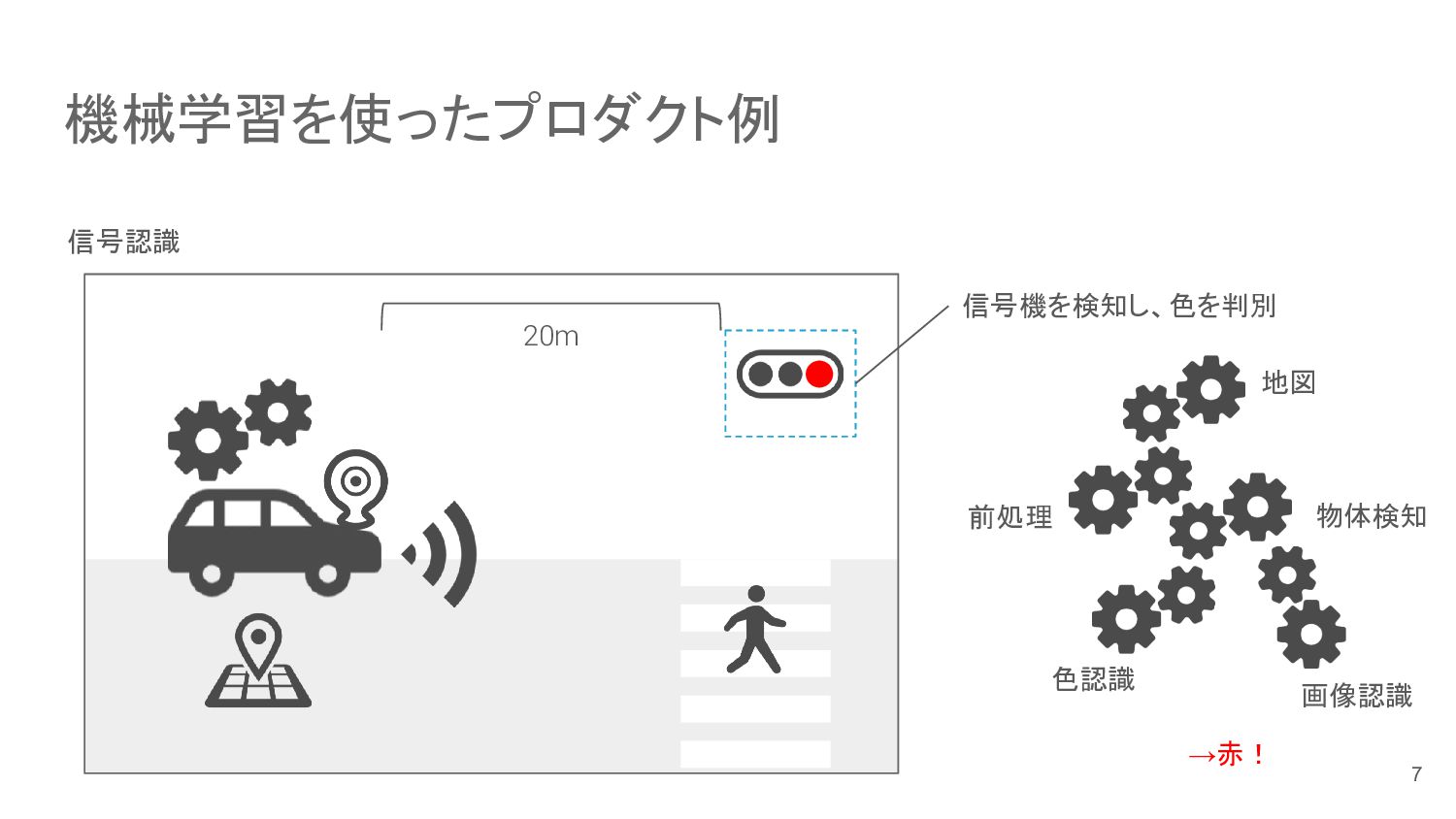
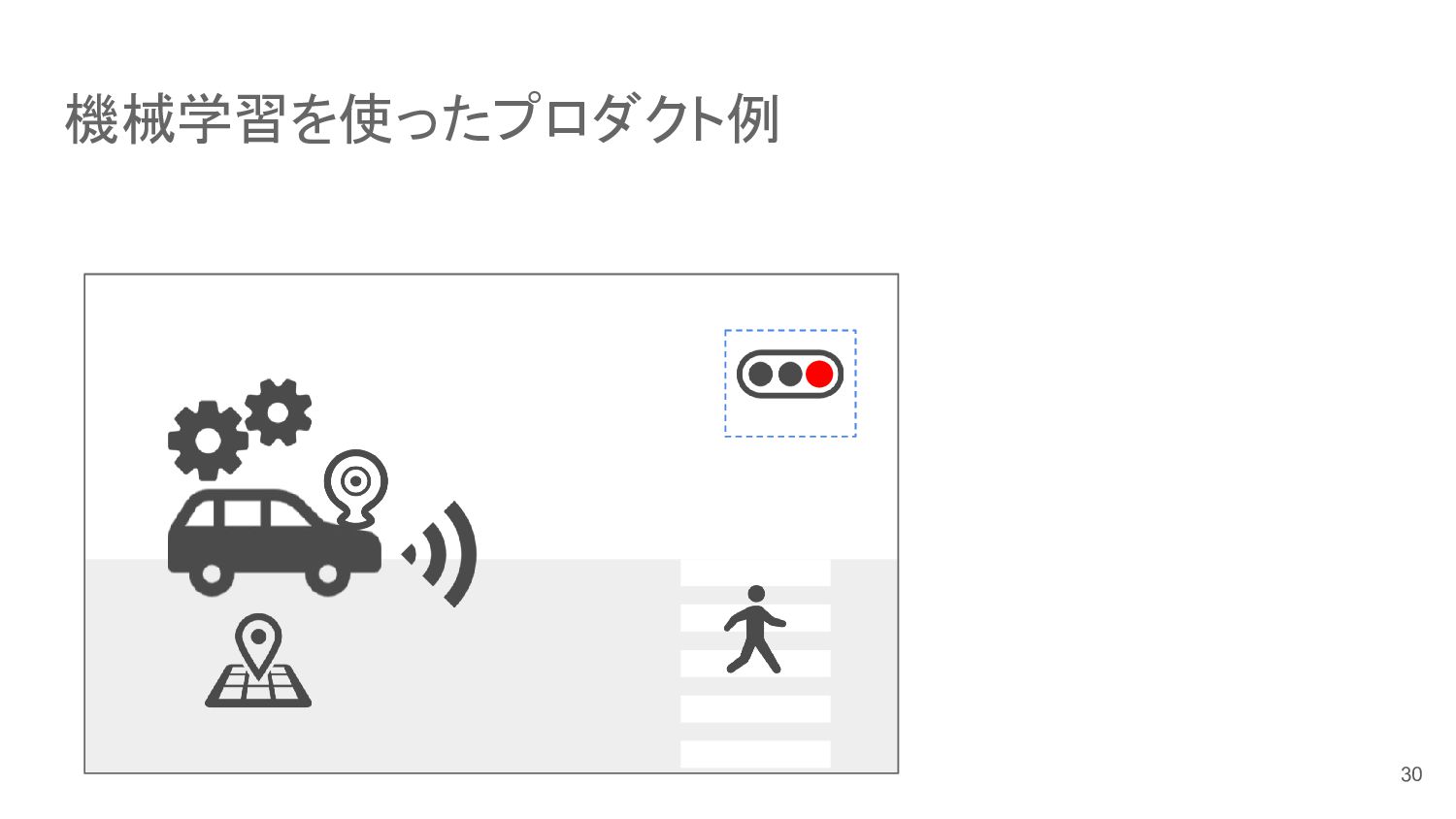
機械学習を使ったプロダクト例 信号認識 信号機を検知し、色を判別 20m 物体検知 画像認識 色認識 前処理 地図 →赤!
7
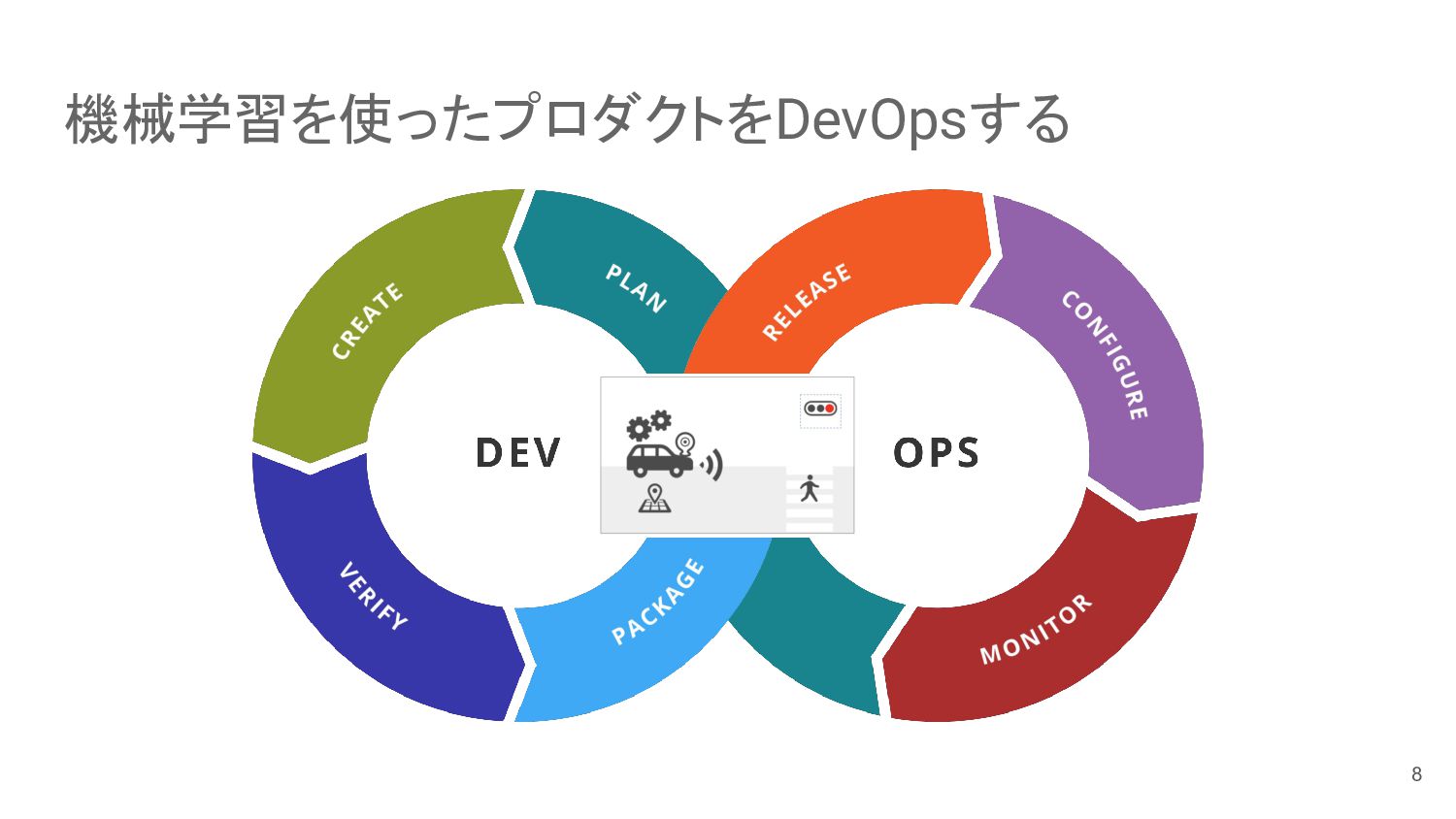
機械学習を使ったプロダクトをDevOpsする 8
MLOpsの始め方 9
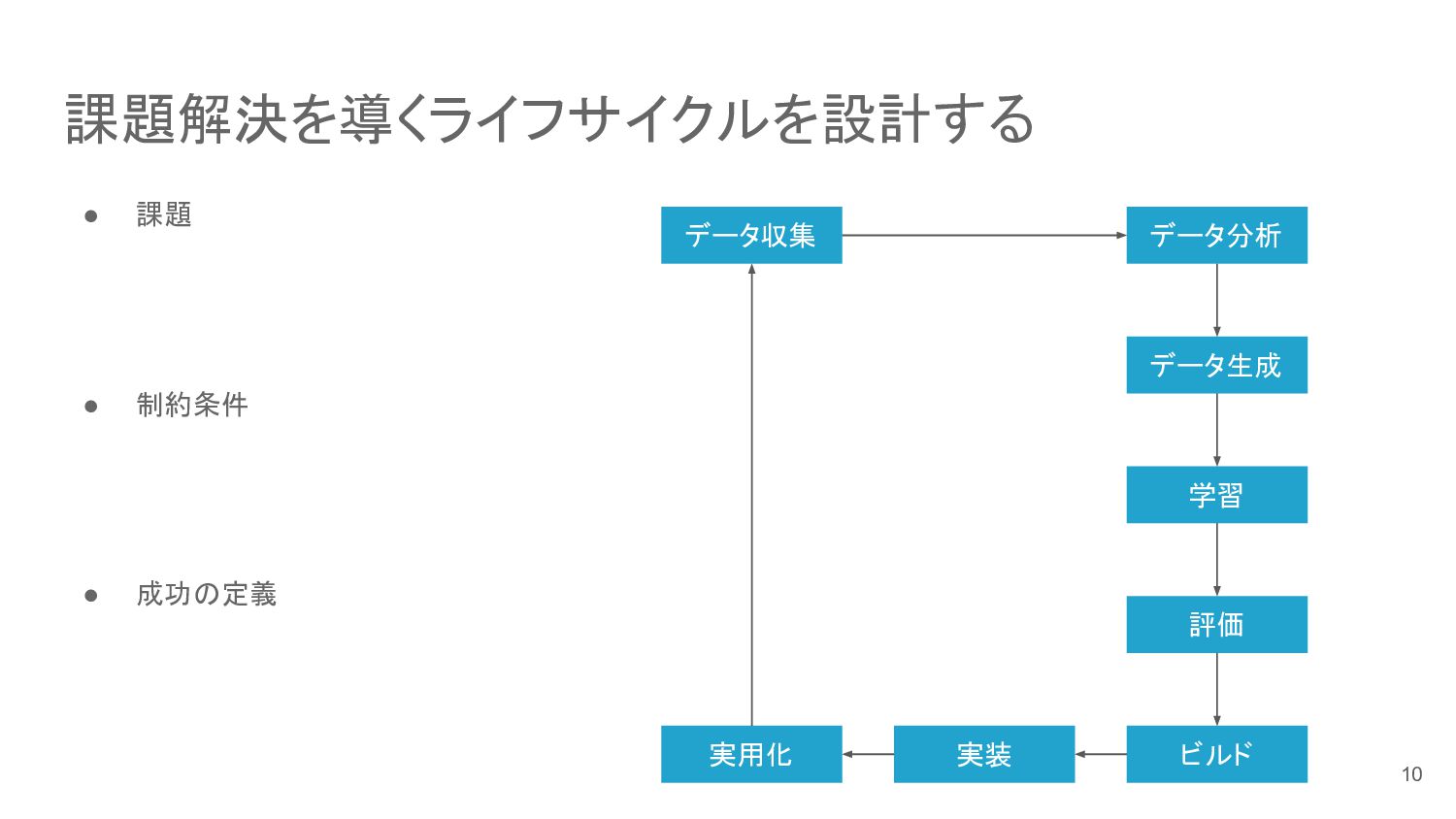
課題解決を導くライフサイクルを設計する • 課題 • 制約条件 • 成功の定義 データ収集 データ分析 データ生成
学習 評価 実用化 ビルド 実装 10
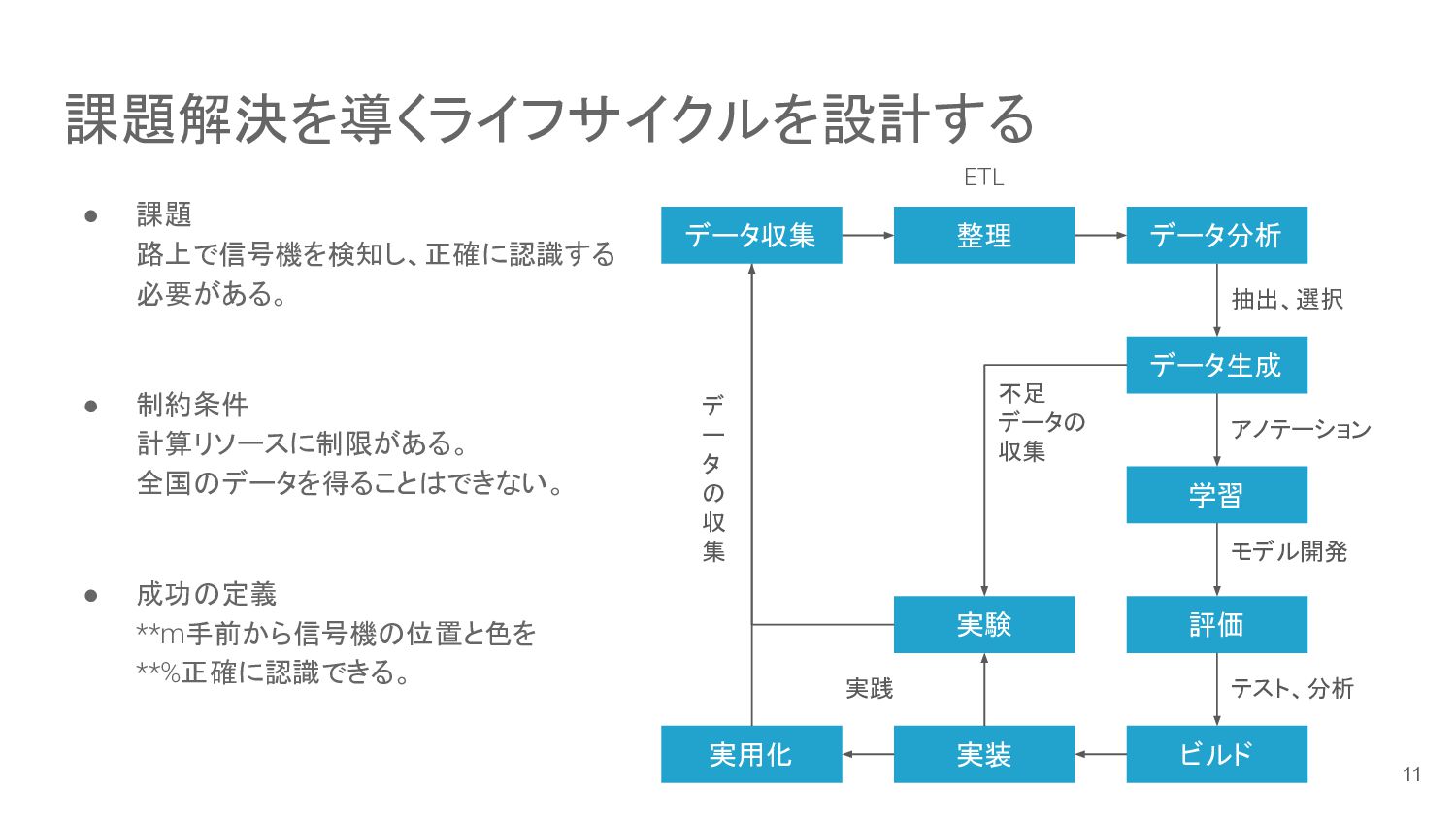
課題解決を導くライフサイクルを設計する • 課題 路上で信号機を検知し、正確に認識する 必要がある。 • 制約条件 計算リソースに制限がある。 全国のデータを得ることはできない。 •
成功の定義 **m手前から信号機の位置と色を **%正確に認識できる。 データ収集 データ分析 データ生成 学習 評価 実用化 ビルド 実装 デ ー タ の 収 集 アノテーション 実験 抽出、選択 整理 ETL モデル開発 テスト、分析 不足 データの 収集 実践 11
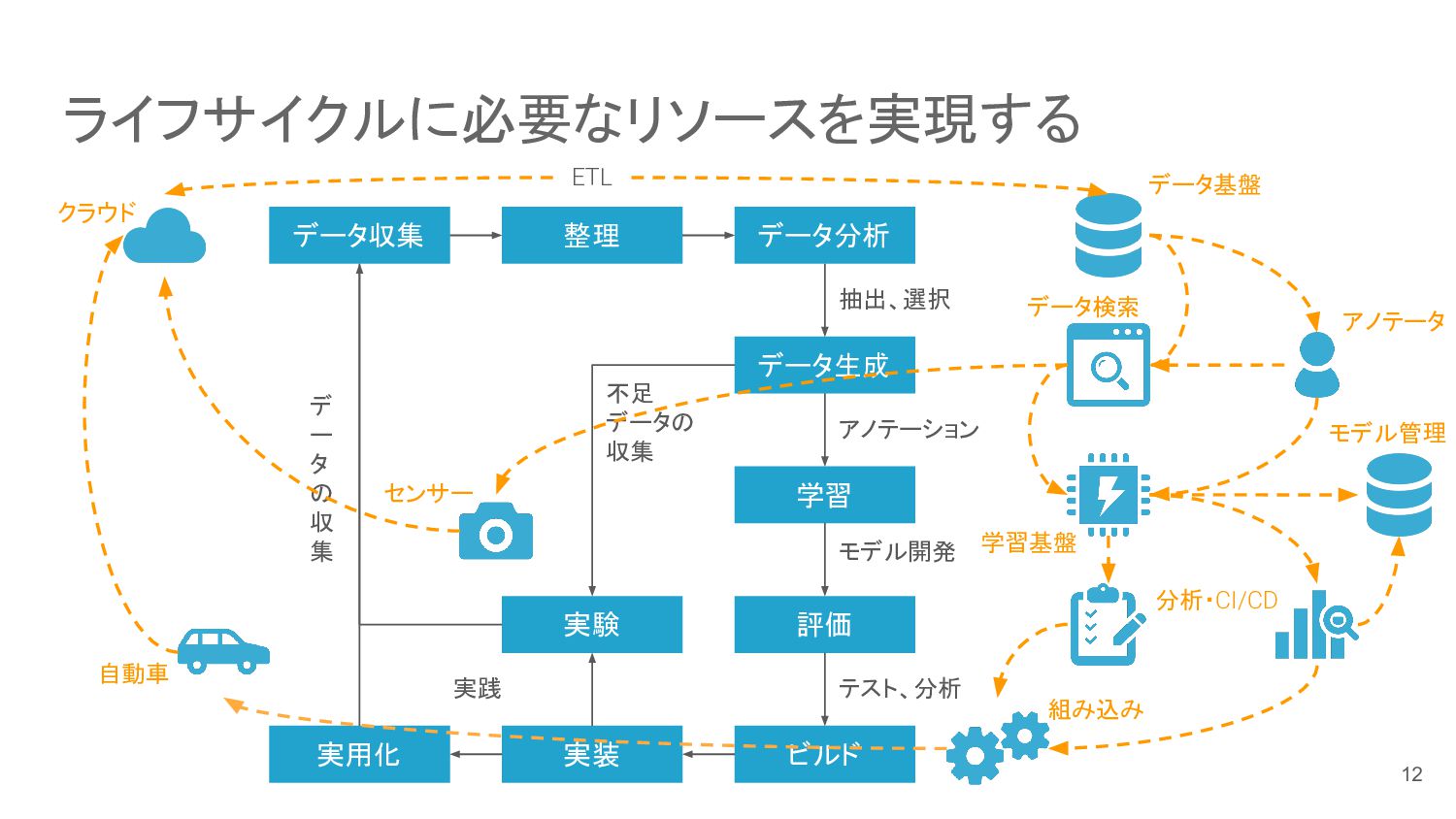
ライフサイクルに必要なリソースを実現する データ収集 データ分析 データ生成 学習 評価 実用化 ビルド 実装 デ
ー タ の 収 集 アノテーション 実験 抽出、選択 整理 ETL モデル開発 テスト、分析 不足 データの 収集 実践 クラウド データ基盤 データ検索 アノテータ 学習基盤 分析・CI/CD 組み込み センサー 自動車 モデル管理 12
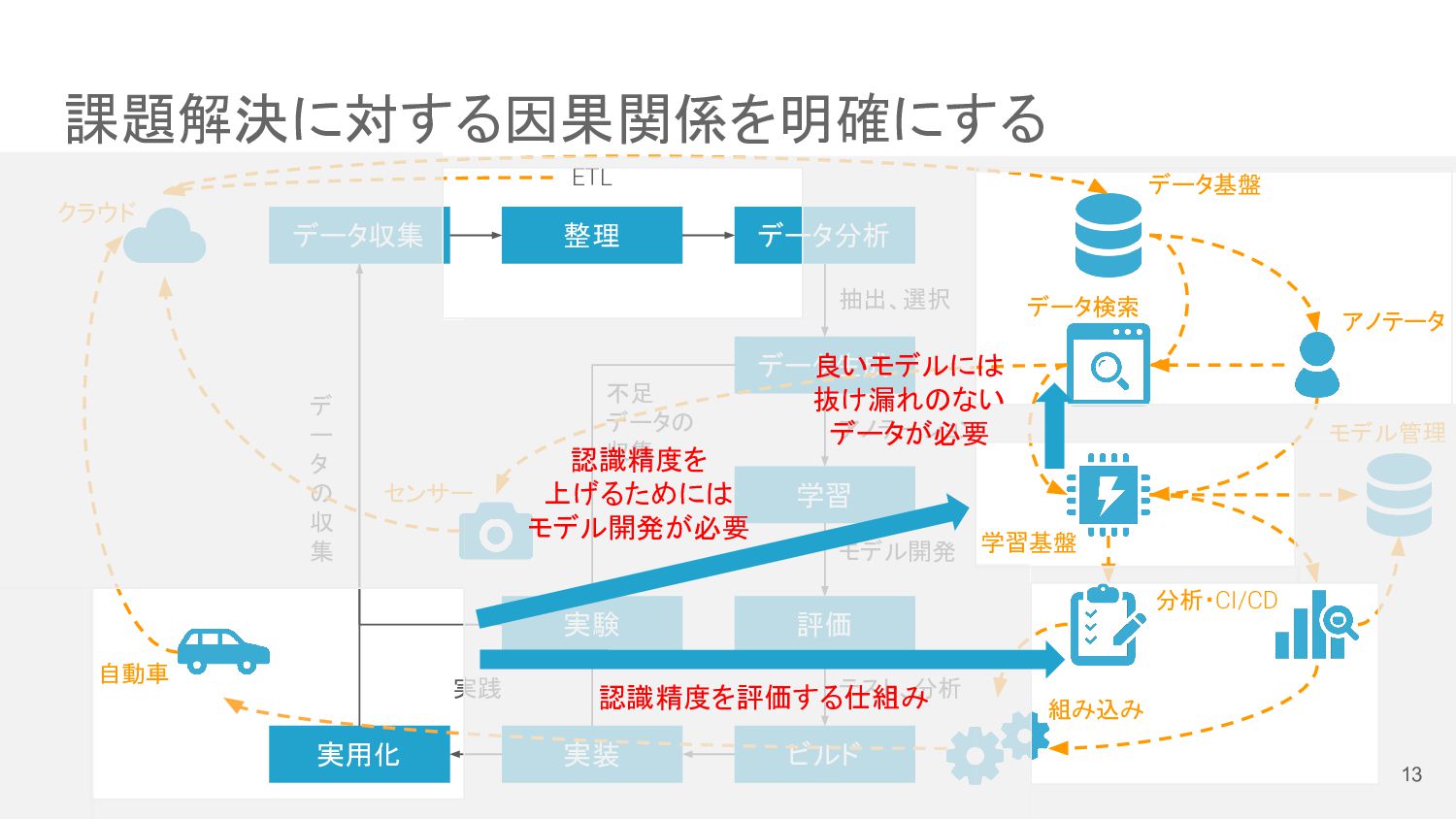
課題解決に対する因果関係を明確にする データ収集 データ分析 データ生成 学習 評価 実用化 ビルド 実装 デ
ー タ の 収 集 アノテーション 実験 抽出、選択 整理 ETL モデル開発 テスト、分析 不足 データの 収集 実践 クラウド データ基盤 データ検索 アノテータ 学習基盤 分析・CI/CD 組み込み センサー 自動車 モデル管理 認識精度を 上げるためには モデル開発が必要 認識精度を評価する仕組み 良いモデルには 抜け漏れのない データが必要 13
データ検索、コードテスト、モデル管理 14
データ検索 15
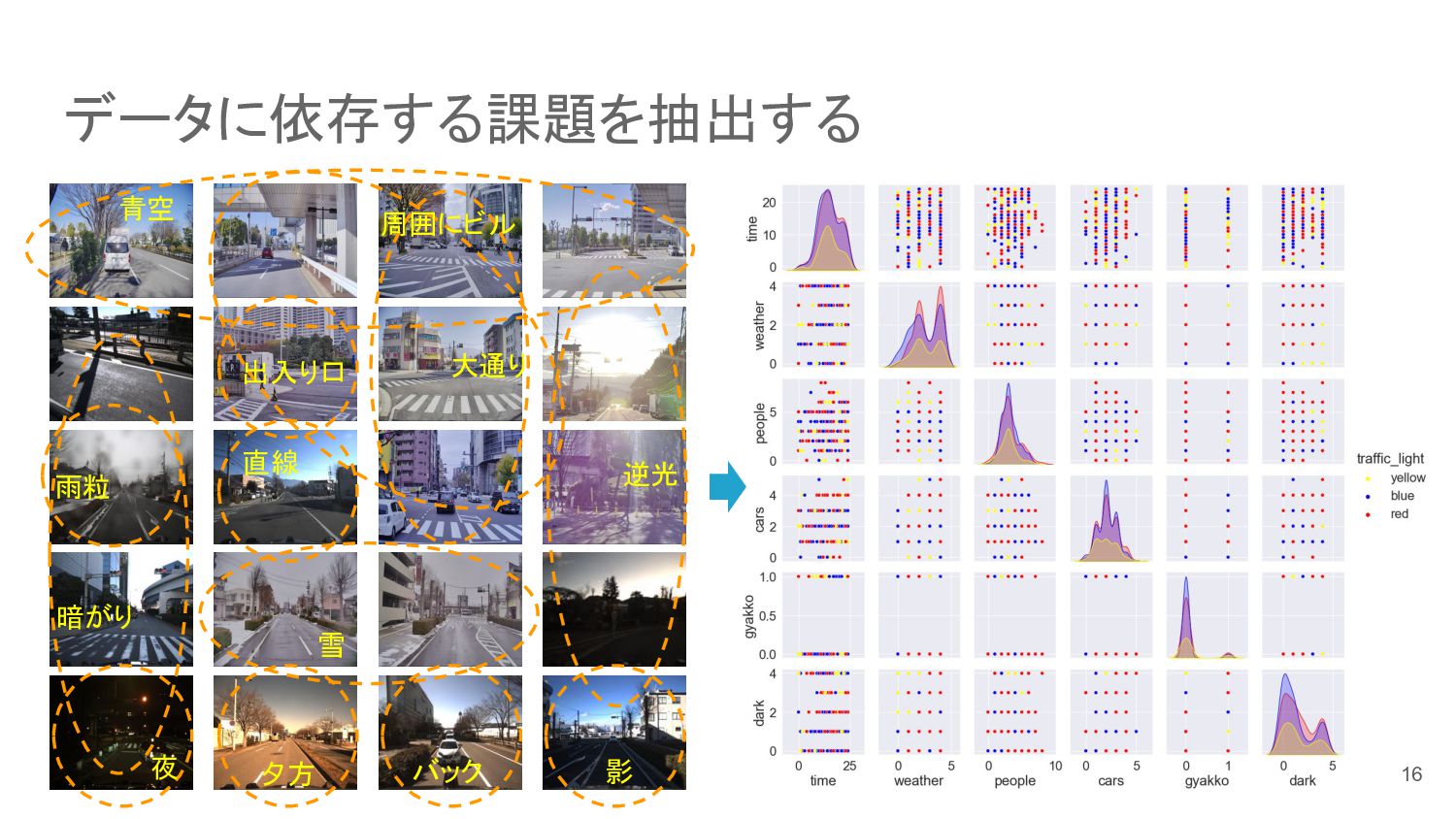
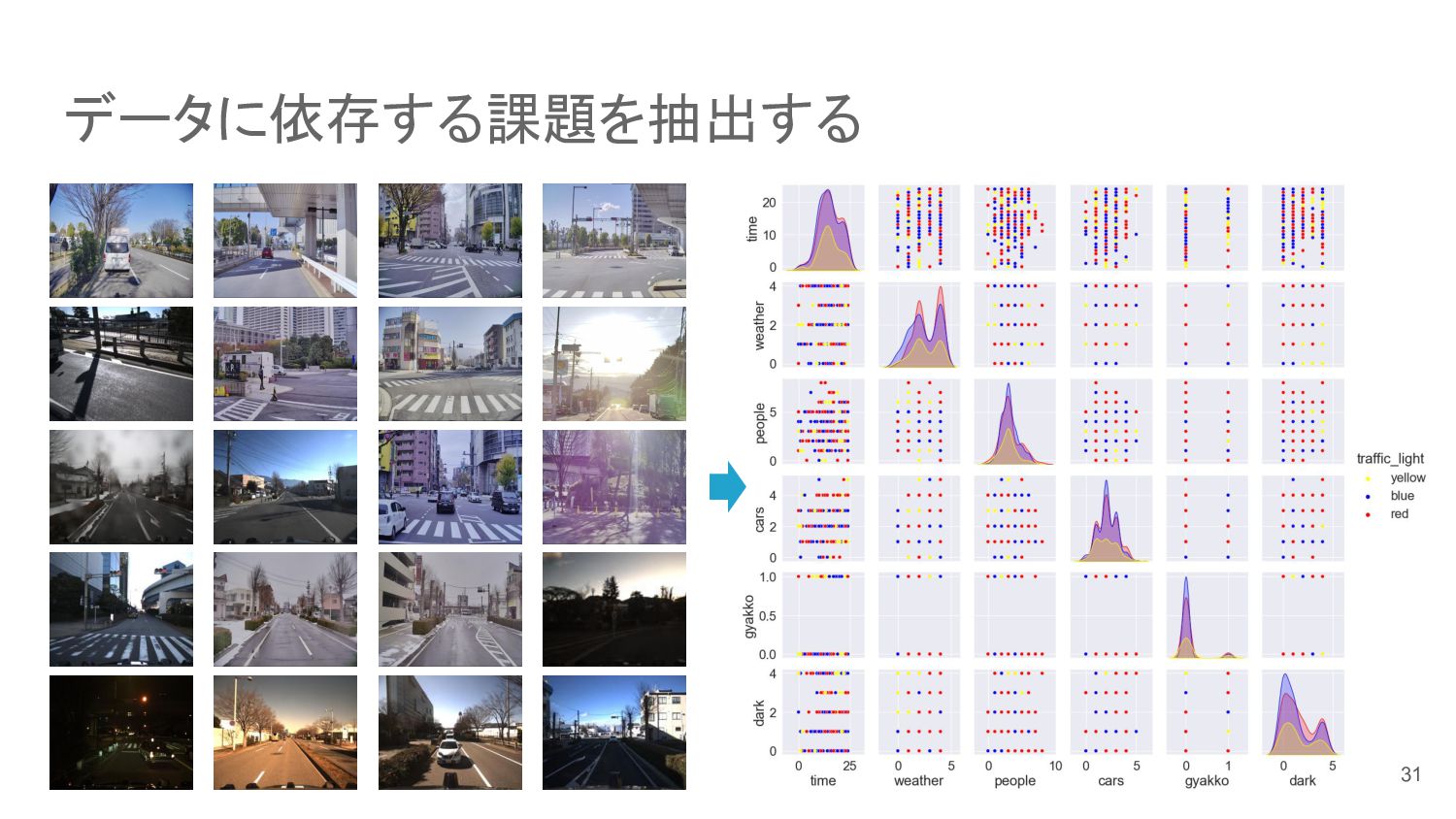
データに依存する課題を抽出する 夜 夕方 逆光 影 バック 雨粒 暗がり 雪 大通り
周囲にビル 出入り口 青空 直線 16
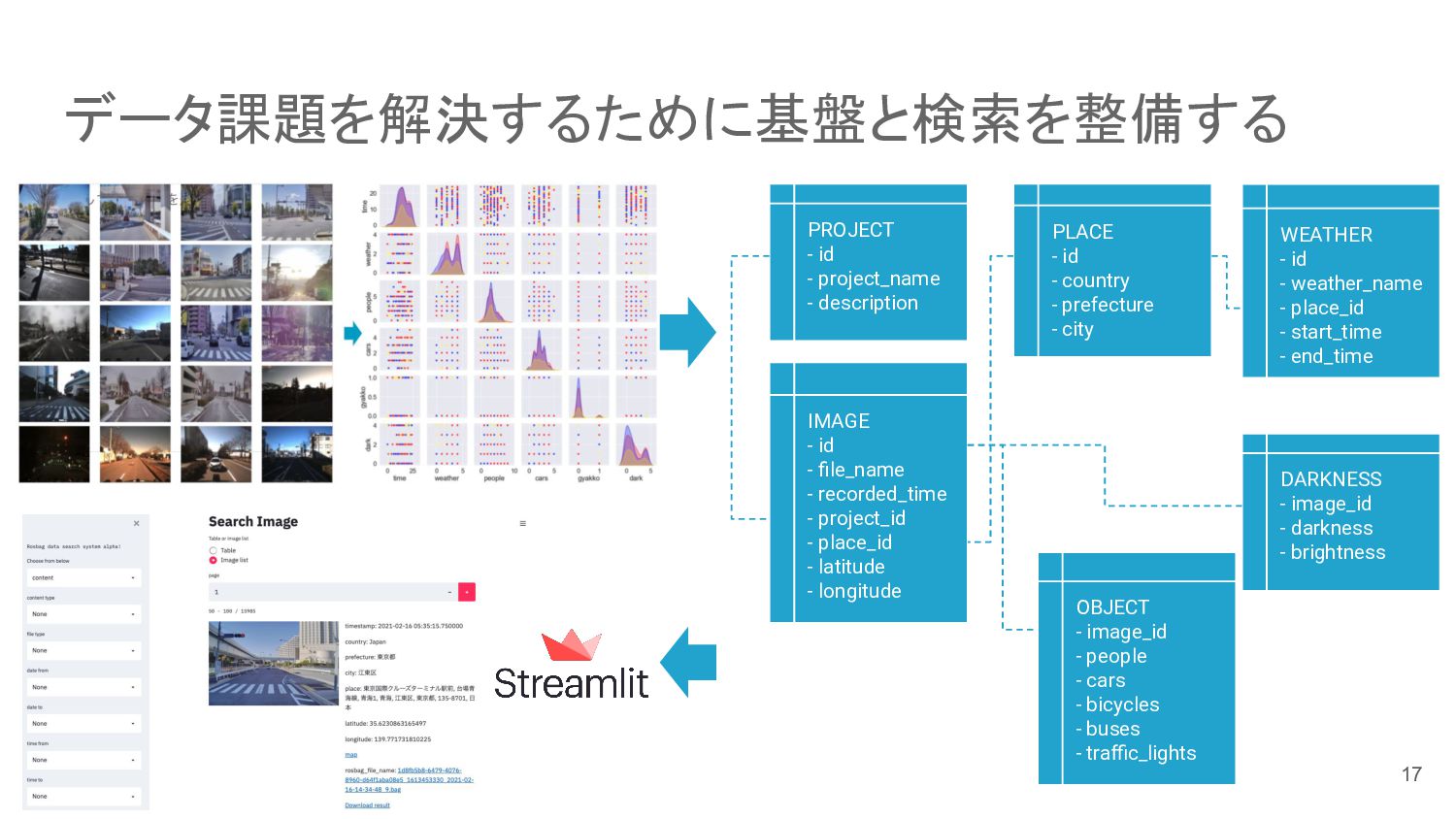
データ課題を解決するために基盤と検索を整備する PROJECT - id - project_name - description PLACE -
id - country - prefecture - city WEATHER - id - weather_name - place_id - start_time - end_time IMAGE - id - file_name - recorded_time - project_id - place_id - latitude - longitude OBJECT - image_id - people - cars - bicycles - buses - traffic_lights DARKNESS - image_id - darkness - brightness 17
検索 18
コードテスト 19
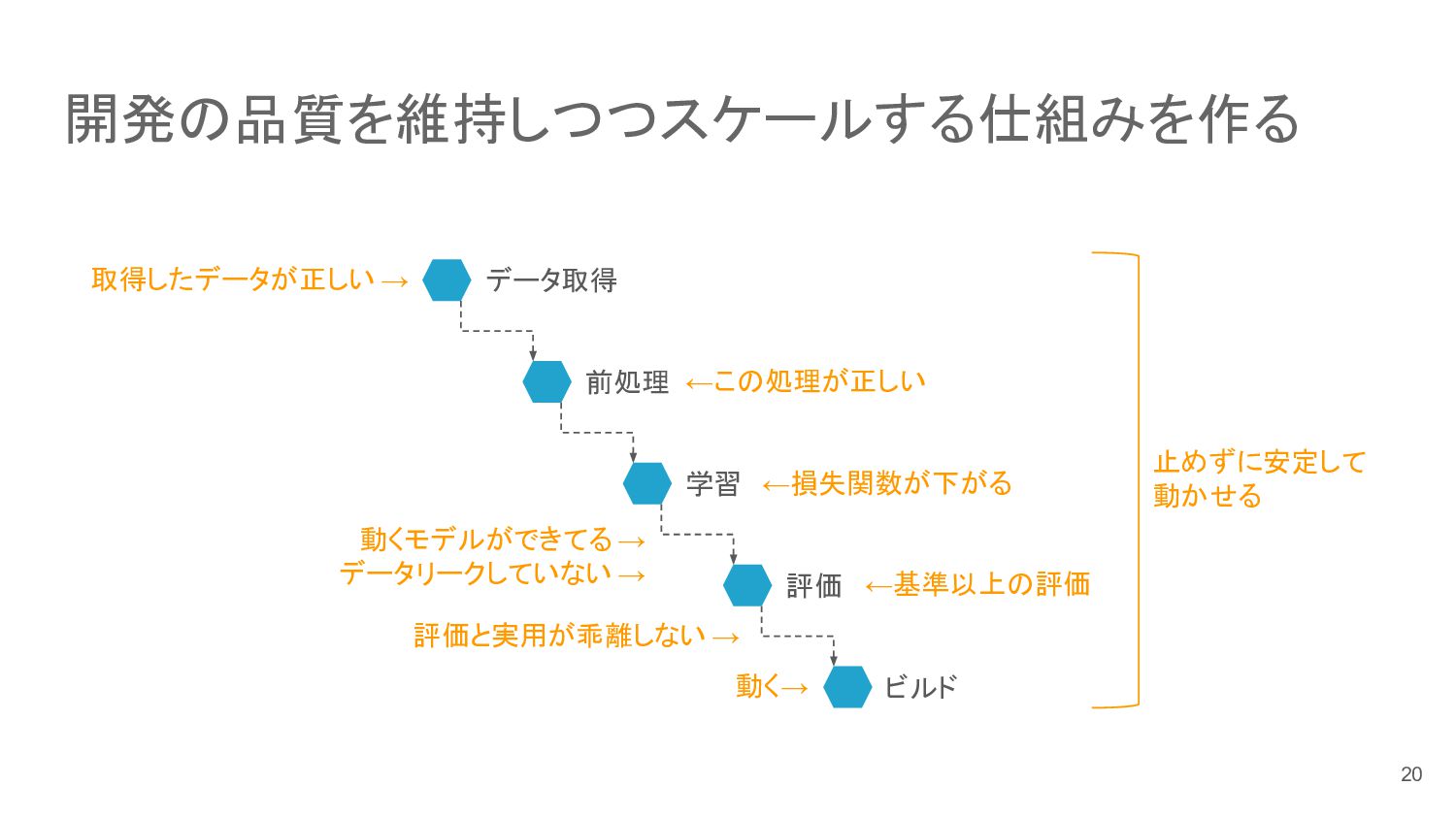
開発の品質を維持しつつスケールする仕組みを作る 取得したデータが正しい → ←この処理が正しい 動くモデルができてる → データリークしていない → ←基準以上の評価 評価と実用が乖離しない
→ 止めずに安定して 動かせる データ取得 前処理 学習 評価 ビルド ←損失関数が下がる 動く→ 20
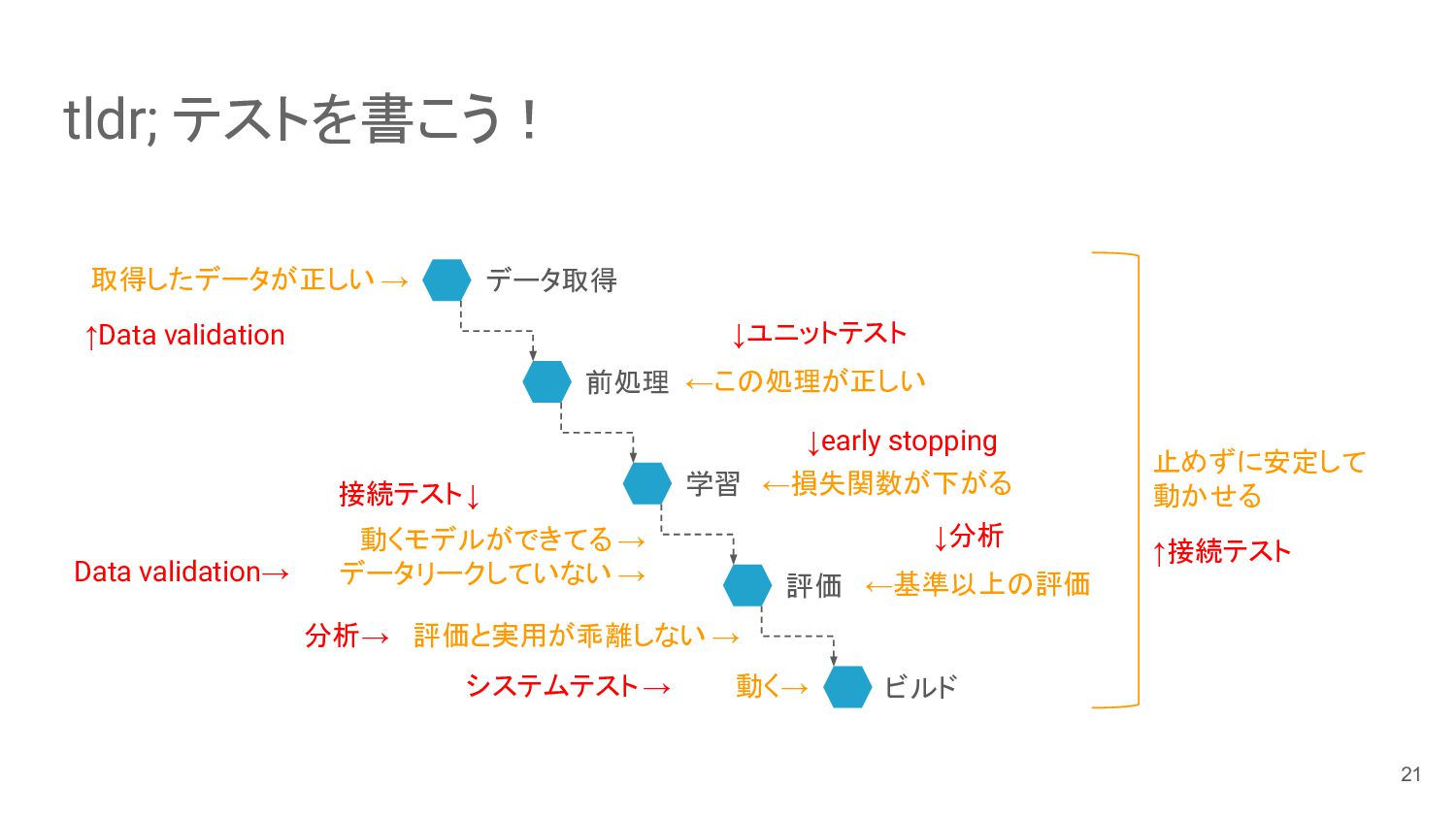
tldr; テストを書こう! 取得したデータが正しい → ←この処理が正しい 動くモデルができてる → データリークしていない → ←基準以上の評価
評価と実用が乖離しない → 止めずに安定して 動かせる データ取得 前処理 学習 評価 ビルド ←損失関数が下がる 動く→ ↑Data validation ↓ユニットテスト ↓early stopping ↓分析 システムテスト→ ↑接続テスト Data validation→ 接続テスト↓ 分析→ 21
• ソフトウェア開発ではプログラムを通してロジックをテストする • 機械学習ではコードを通してデータで確率をテストする データ モデル以外もテストする YES or NO 0
~ 1 ソフトウェア開発のテスト 機械学習のテスト 入力 正解 出力 assert 関数 指標 推論 evaluate モデル 関数 テスト通過率:95/100 Accuracy:0.99 Precision:0.95 Recall:0.60 22
テストのイメージ # 仮のコードです def make_dataloader(data_path: str) -> DataLoader: return dataloader(data_path)
def train(model: nn.Module, epochs: int, trainloader: DataLoader) -> List[float]: losses = [] for epoch in range(epochs): average_loss = train_once(model, trainloader) losses.append(average_loss) model.save() return losses def evaluate(model_path: str, testloader: DataLoader) -> List[float]: predictor = Model(model_path) evaluations = predictor.evaluate(testloader) return evaluations • 少量データで普通のテストを動かす。 @pytest.mark.parametrize( (“model”, “train_path”, “test_path” “epochs”), [(model, “/tmp/small_train/”, “/tmp/small_test/”, 10)], ) def test_train( model: nn.Module, train_path: str, test_path: str, epochs: int, ): trainloader = make_dataloader(train_path) testloader = make_dataloader(test_path) init_accuracy = evaluate(model, testloader) losses = train(model, epochs, trainloader) assert losses[0] > losses[-1] trained_accuracy = evaluate(model, testdata) assert init_accuracy < trained_accuracy 23
モデル管理 24
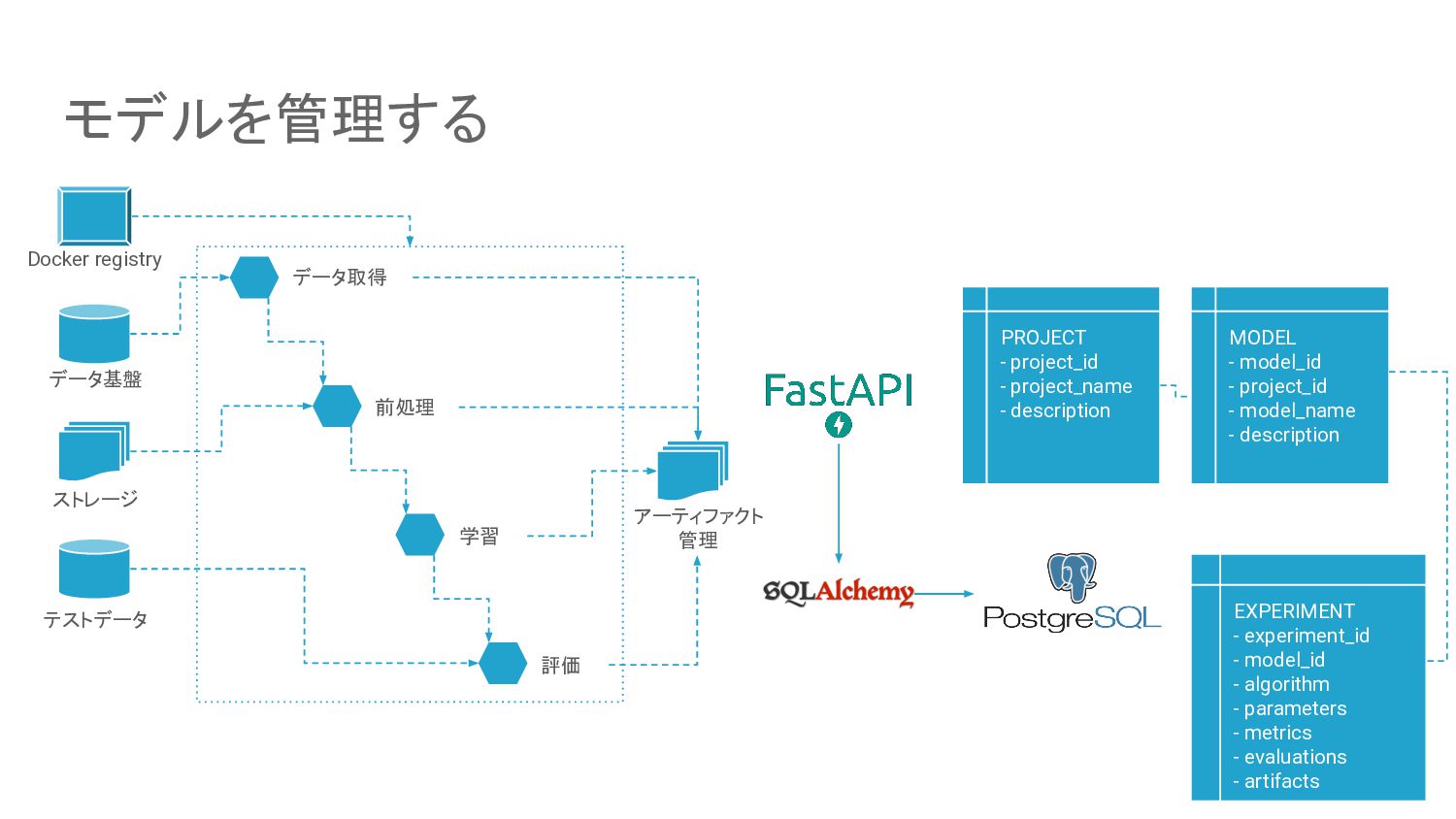
モデルを管理する 25 データ取得 前処理 学習 評価 データ基盤 ストレージ テストデータ アーティファクト
管理 Docker registry 25 PROJECT - project_id - project_name - description MODEL - model_id - project_id - model_name - description EXPERIMENT - experiment_id - model_id - algorithm - parameters - metrics - evaluations - artifacts
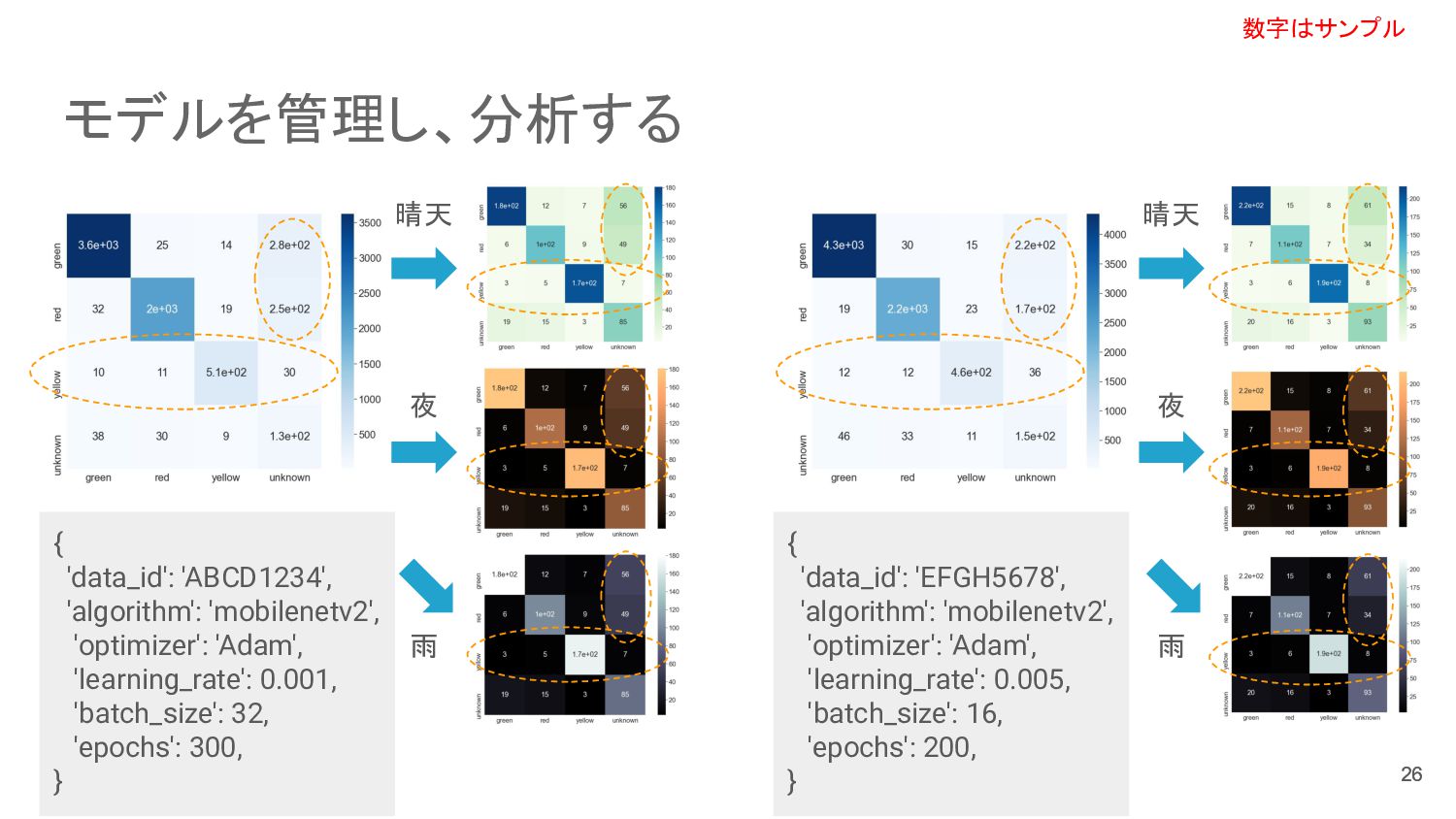
モデルを管理し、分析する 26 26 晴天 夜 雨 数字はサンプル 晴天 夜 雨
{ 'data_id': 'ABCD1234', 'algorithm': 'mobilenetv2', 'optimizer': 'Adam', 'learning_rate': 0.001, 'batch_size': 32, 'epochs': 300, } { 'data_id': 'EFGH5678', 'algorithm': 'mobilenetv2', 'optimizer': 'Adam', 'learning_rate': 0.005, 'batch_size': 16, 'epochs': 200, }
まとめ 27
ティアフォー MLOpsエンジニア募集中! https://herp.careers/v1/tier4/zHA-dVY6ORa4 • 2Dや3Dの物体検出モデル開発および基盤開発 • KubernetesおよびAWSインフラの構築、運用 • Deep Learningのモデル最適化および推論器開発 •
Deep LearningのためのシミュレーションとCI/CD • データパイプライン、データ基盤、検索 • 技術的に難しいことすべて 28
本を出版しました! • AIエンジニアのための機械学習システムデザインパターン • 2021年5月17日出版 • https://www.amazon.co.jp/dp/4798169447/ • Amazon.co.jp ◦
情報学・情報科学部門 1位! ◦ 人工知能部門 1位! ◦ 増刷決定! • 中国語版と韓国語訳も出るらしい! 29
機械学習を使ったプロダクト例 30
データに依存する課題を抽出する 31
機械学習を使ったプロダクトをOpsする データ収集と 整理、検索 フィードバックと ロジック開発 実装と実験 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}