Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データアナリストが行うDatabricksを活用したETLの自動化事例
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Shinoa Nishikawa
April 05, 2024
Programming
790
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データアナリストが行うDatabricksを活用したETLの自動化事例
Shinoa Nishikawa
April 05, 2024
Other Decks in Programming
See All in Programming
OpenSpecのproposalにbrainstormingを持たせてみた
tigertora7571
1
160
5分で問診!Composer セキュリティ健康診断
codmoninc
0
730
Augmenting AI with the Power of Jakarta EE
ivargrimstad
0
340
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
180
生成AIで帳票OCRが「簡単に」作れる時代になった?
kon_shou
0
100
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
630
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
120
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
190
komatsuna「分散システムにおけるバグ分析手法」
komatsunaqa
0
140
yield再入門 #phpcon
o0h
PRO
0
840
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
1.5k
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
200
Featured
See All Featured
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
440
We Are The Robots
honzajavorek
0
290
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
400
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
Done Done
chrislema
186
16k
How GitHub (no longer) Works
holman
316
150k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
410
Agile that works and the tools we love
rasmusluckow
331
22k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Designing for Timeless Needs
cassininazir
1
420
We Have a Design System, Now What?
morganepeng
55
8.2k
Transcript
データアナリストが行う Databricksを活用したETLの自動化事例 2024.4.5
西川 史乃亜 2 所属:株式会社BuySell Technologies テクノロジー戦略本部データサイエンス部 略歴:2022年6月に株式会社Buysell Technologiesに入社。 データアナリストとして、データ分析・効果検証・データの可視化、
アナリティクスエンジニアリング( Databricks)を担当。 前職もBuySell Technologiesと同じリユース系の会社で、 デジタルマーケティング・事業企画・新規事業企画などを経験。 趣味:飼っている猫たちと遊ぶ、筋トレ、よさこい(旗士)
02 03 01 アジェンダ バイセルの事業紹介とデータ事情 3 Databricksの活用事例 まとめ
01 バイセルの事業紹介とデータ事情
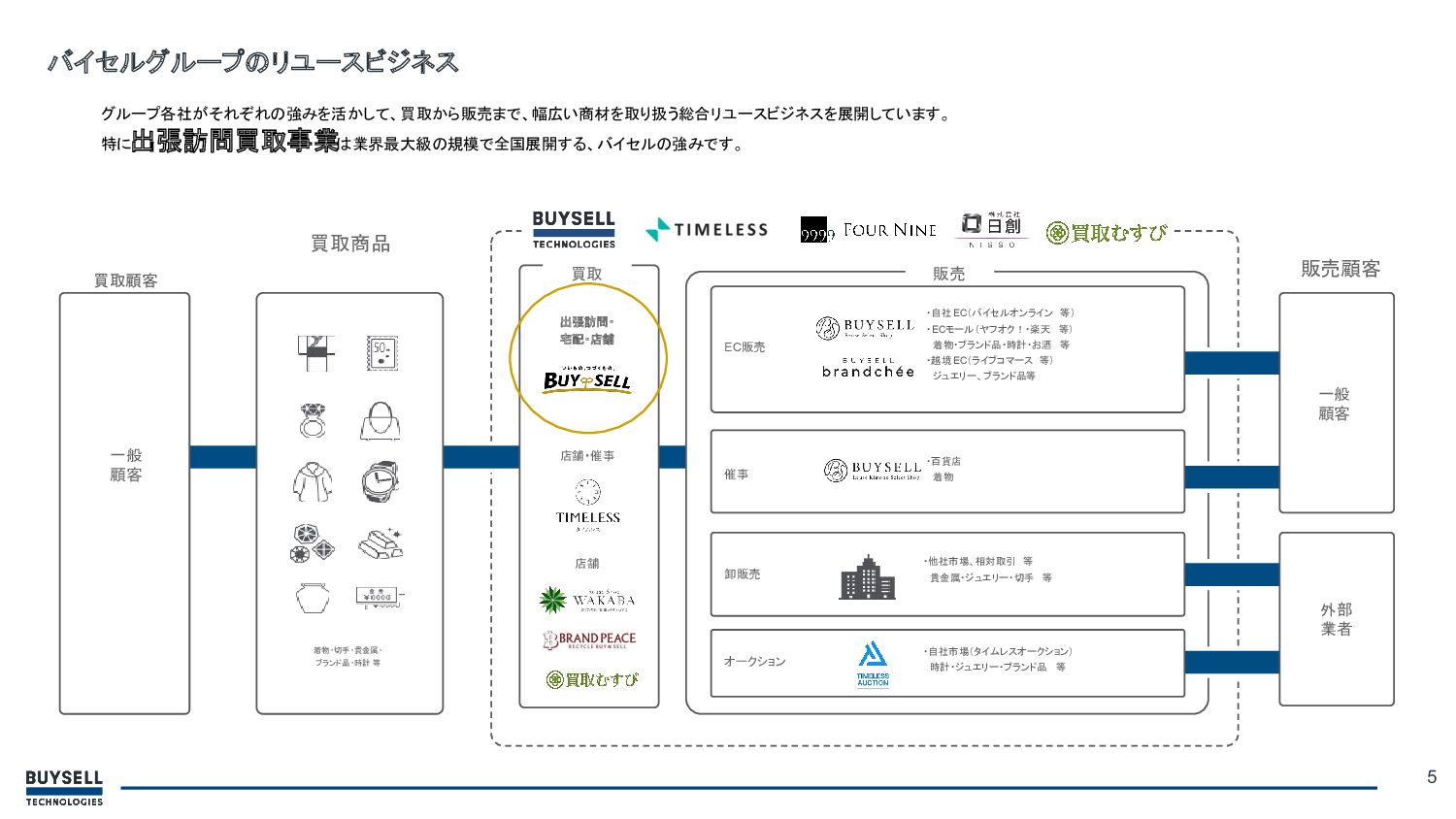
5 バイセルグループのリユースビジネス グループ各社がそれぞれの強みを活かして、買取から販売まで、幅広い商材を取り扱う総合リユースビジネスを展開しています。 特に出張訪問買取事業は業界最大級の規模で全国展開する、バイセルの強みです。 着物・切手・貴金属・ ブランド品・時計 等 買取 店舗・催事 店舗
販売 一般 顧客 外部 業者 EC販売 催事 卸販売 オークション ・自社EC(バイセルオンライン 等) ・ECモール(ヤフオク!・楽天 等) 着物・ブランド品・時計・お酒 等 ・越境EC(ライブコマース 等) ジュエリー、ブランド品等 ・百貨店 着物 ・他社市場、相対取引 等 貴金属・ジュエリー・切手 等 ・自社市場(タイムレスオークション) 時計・ジュエリー・ブランド品 等 一般 顧客 出張訪問・ 宅配・店舗 販売顧客 買取顧客 買取商品
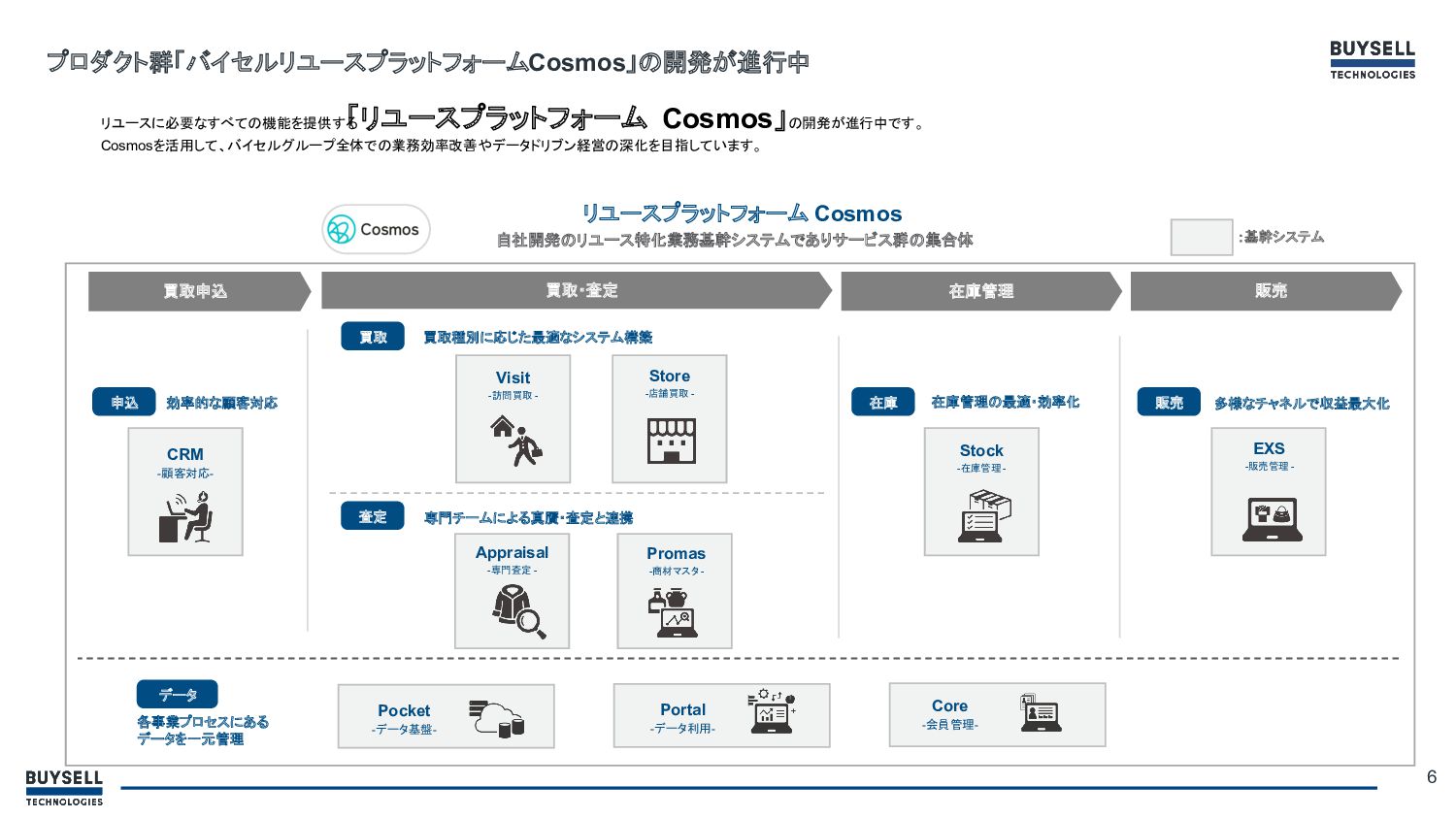
6 プロダクト群「バイセルリユースプラットフォーム Cosmos」の開発が進行中 リユースに必要なすべての機能を提供する 「リユースプラットフォーム Cosmos」の開発が進行中です。 Cosmosを活用して、バイセルグループ全体での業務効率改善やデータドリブン経営の深化を目指しています。 リユースプラットフォーム Cosmos 自社開発のリユース特化業務基幹システムでありサービス群の集合体
買取申込 買取・査定 在庫管理 販売 多様なチャネルで収益最大化 CRM -顧客対応- 買取種別に応じた最適なシステム構築 Visit -訪問買取 - Store -店舗買取 - Promas -商材マスタ - Appraisal -専門査定 - Stock -在庫管理 - EXS -販売管理 - Core -会員管理- Portal -データ利用- Pocket -データ基盤- 買取 専門チームによる真贋・査定と連携 査定 申込 効率的な顧客対応 在庫 在庫管理の最適・効率化 販売 データ 各事業プロセスにある データを一元管理 :基幹システム
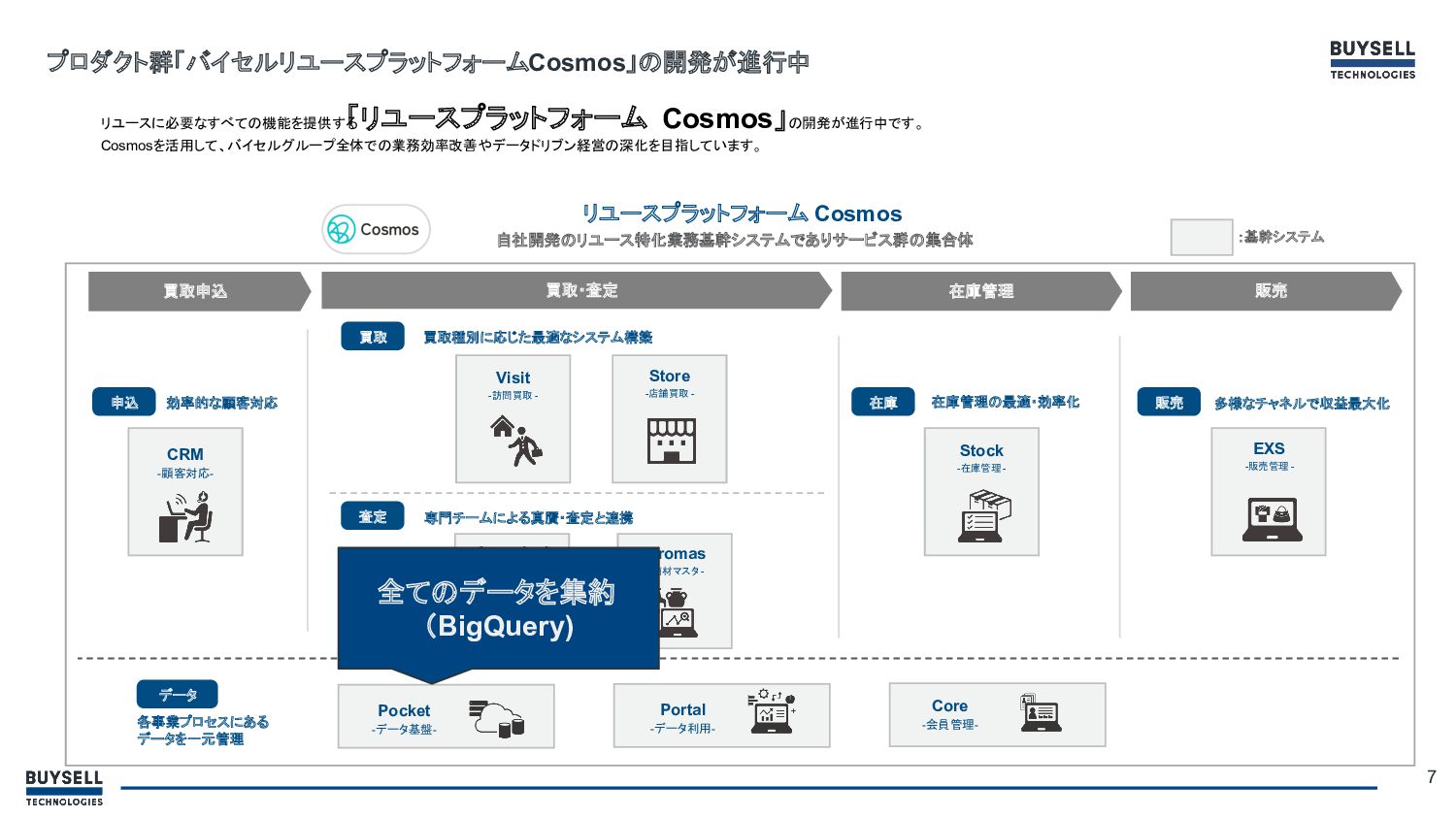
7 プロダクト群「バイセルリユースプラットフォーム Cosmos」の開発が進行中 リユースに必要なすべての機能を提供する 「リユースプラットフォーム Cosmos」の開発が進行中です。 Cosmosを活用して、バイセルグループ全体での業務効率改善やデータドリブン経営の深化を目指しています。 リユースプラットフォーム Cosmos 自社開発のリユース特化業務基幹システムでありサービス群の集合体
買取申込 買取・査定 在庫管理 販売 多様なチャネルで収益最大化 CRM -顧客対応- 買取種別に応じた最適なシステム構築 Visit -訪問買取 - Store -店舗買取 - Promas -商材マスタ - Appraisal -専門査定 - Stock -在庫管理 - EXS -販売管理 - Core -会員管理- Portal -データ利用- Pocket -データ基盤- 買取 専門チームによる真贋・査定と連携 査定 申込 効率的な顧客対応 在庫 在庫管理の最適・効率化 販売 データ 各事業プロセスにある データを一元管理 :基幹システム 全てのデータを集約 (BigQuery)
• 前提:各プロダクトのRDBはBigQueryに同期している • 課題:ExcelやCSV、Googleスプレッドシートのデータや外部ツールのデータが RDB、 BigQueryに格納されていない ◦ 手元で集計しているデータ / 独自で管理しているマスタ
/ 外部サービスのデータ( Google、Kintoneなど)/ パブリック データ(統計データ、気象データなど) • 影響:事業部サイドでデータ分析が進めにくい 8 Databricks導入前の背景と課題
• 前提:各プロダクトのRDBはBigQueryに同期している • 課題:ExcelやCSV、Googleスプレッドシートのデータや外部ツールのデータが RDB、 BigQueryに格納されていない ◦ 手元で集計しているデータ / 独自で管理しているマスタ
/ 外部サービスのデータ( Google、Kintoneなど)/ パブリック データ(統計データ、気象データなど) • 影響:事業部サイドでデータ分析が進めにくい 9 Databricks導入前の背景と課題 「RDBのデータと独自で集めたデータを組み合わせてデータ分析が行える環境」を 整備することが必要
02 Databricksの活用事例
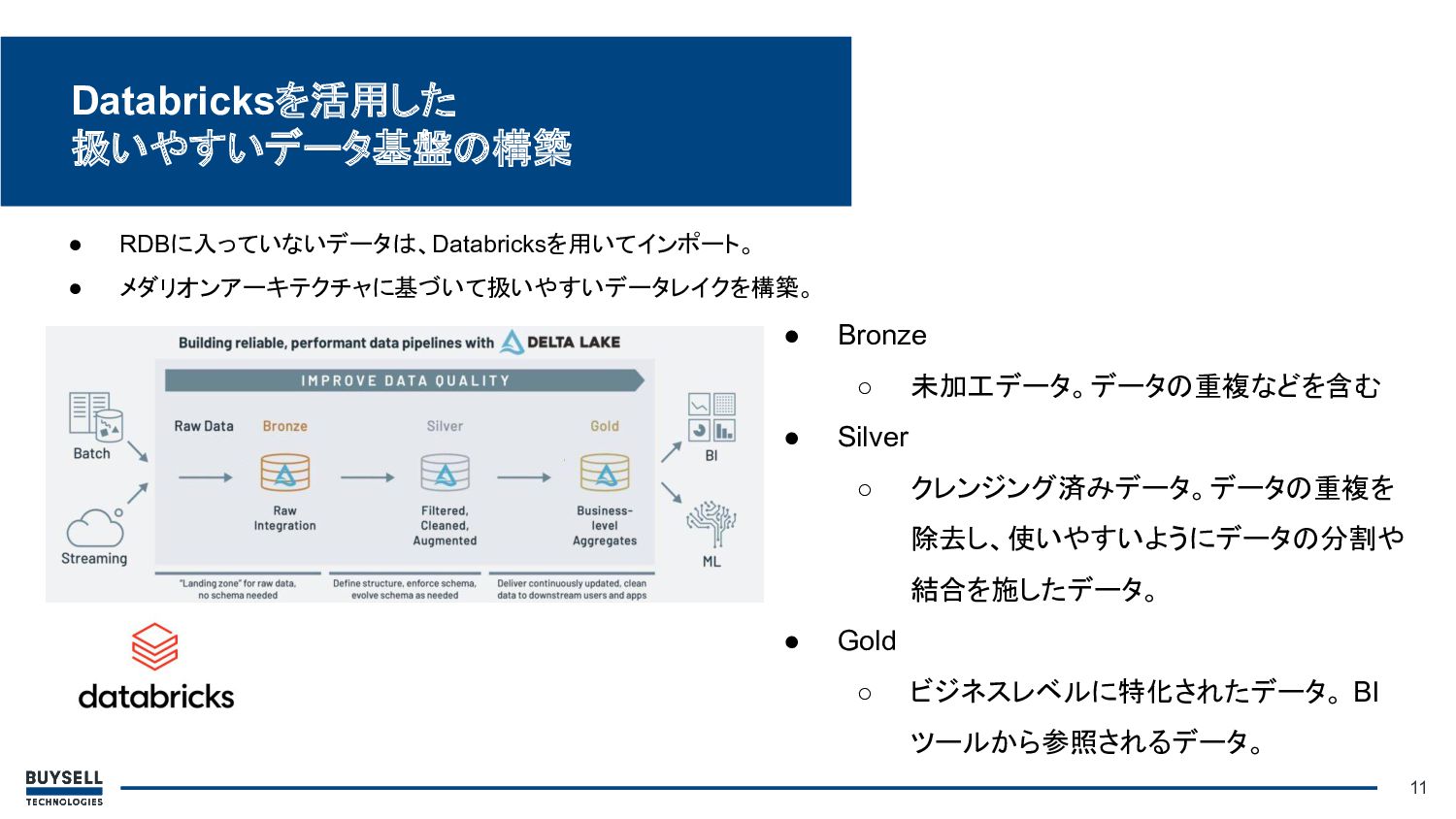
11 Databricksを活用した 扱いやすいデータ基盤の構築 • RDBに入っていないデータは、Databricksを用いてインポート。 • メダリオンアーキテクチャに基づいて扱いやすいデータレイクを構築。 • Bronze ◦
未加工データ。データの重複などを含む • Silver ◦ クレンジング済みデータ。データの重複を 除去し、使いやすいようにデータの分割や 結合を施したデータ。 • Gold ◦ ビジネスレベルに特化されたデータ。 BI ツールから参照されるデータ。
• 業務効率化 • データガバナンス強化 12 Databricksを活用するメリット
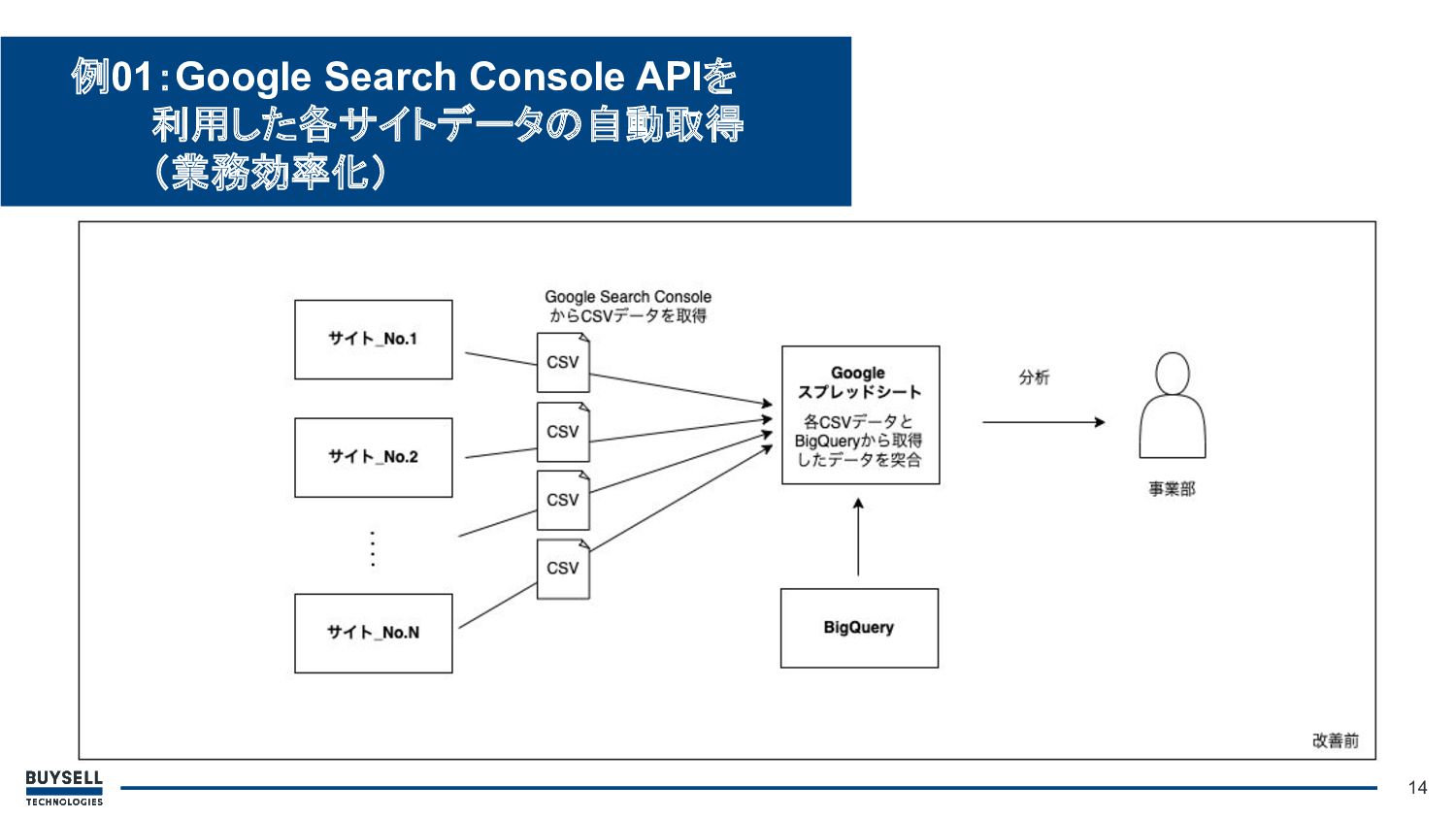
• 背景・課題: ◦ Search ConsoleのデータがRDBやBigQueryに未格納 ◦ Search Consoleからデータを手動でエクスポートし、 ExcelやGoogleスプレッド シート上でBigQueryから取得したデータと突合する必要があった
◦ 多くのサイトの分析を日々行なっているため、データ処理が煩雑化していた 13 例01:Google Search Console APIを 利用した各サイトデータの自動取得 (業務効率化)
14 例01:Google Search Console APIを 利用した各サイトデータの自動取得 (業務効率化)
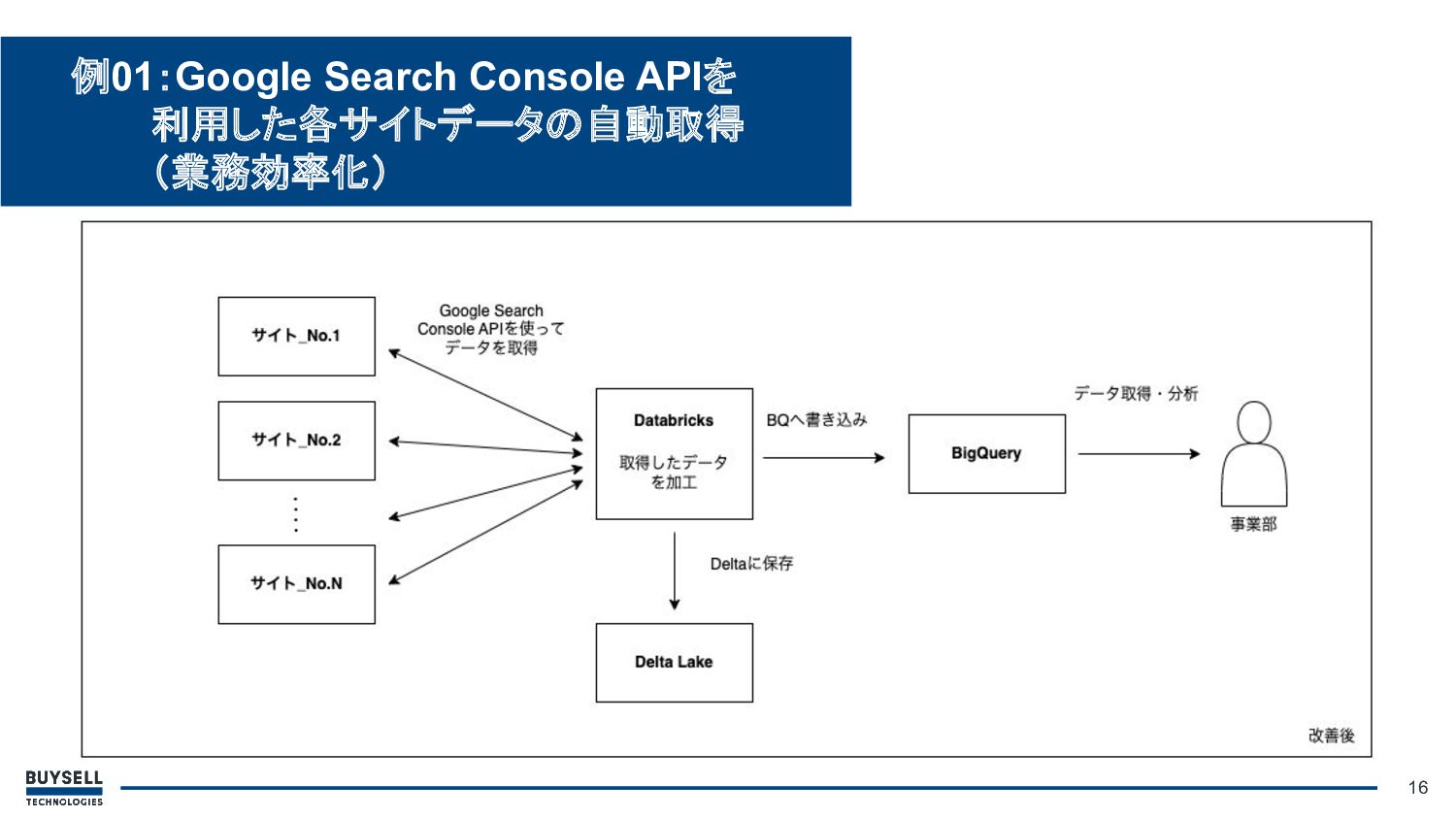
• 解決方法: ◦ Databricks上でGoogle Search Console APIを実行 ◦ 分析に必要なデータを取得、整形 しBigQueryに格納
◦ 毎日指定時間にジョブが実行さ れ、取得可能な最新データが蓄積 されていく 15 例01:Google Search Console APIを 利用した各サイトデータの自動取得 (業務効率化)
16 例01:Google Search Console APIを 利用した各サイトデータの自動取得 (業務効率化)
• ポイント: ◦ リクエスト時に渡すパラメータはデータ利用者と相談して決める ◦ Google側のデータ遅延等によりデータが上手く取得できない場合もあるため、開 発者側でエラーを認知できるようにしておく 17 例01:Google Search
Console APIを 利用した各サイトデータの自動取得 (業務効率化)
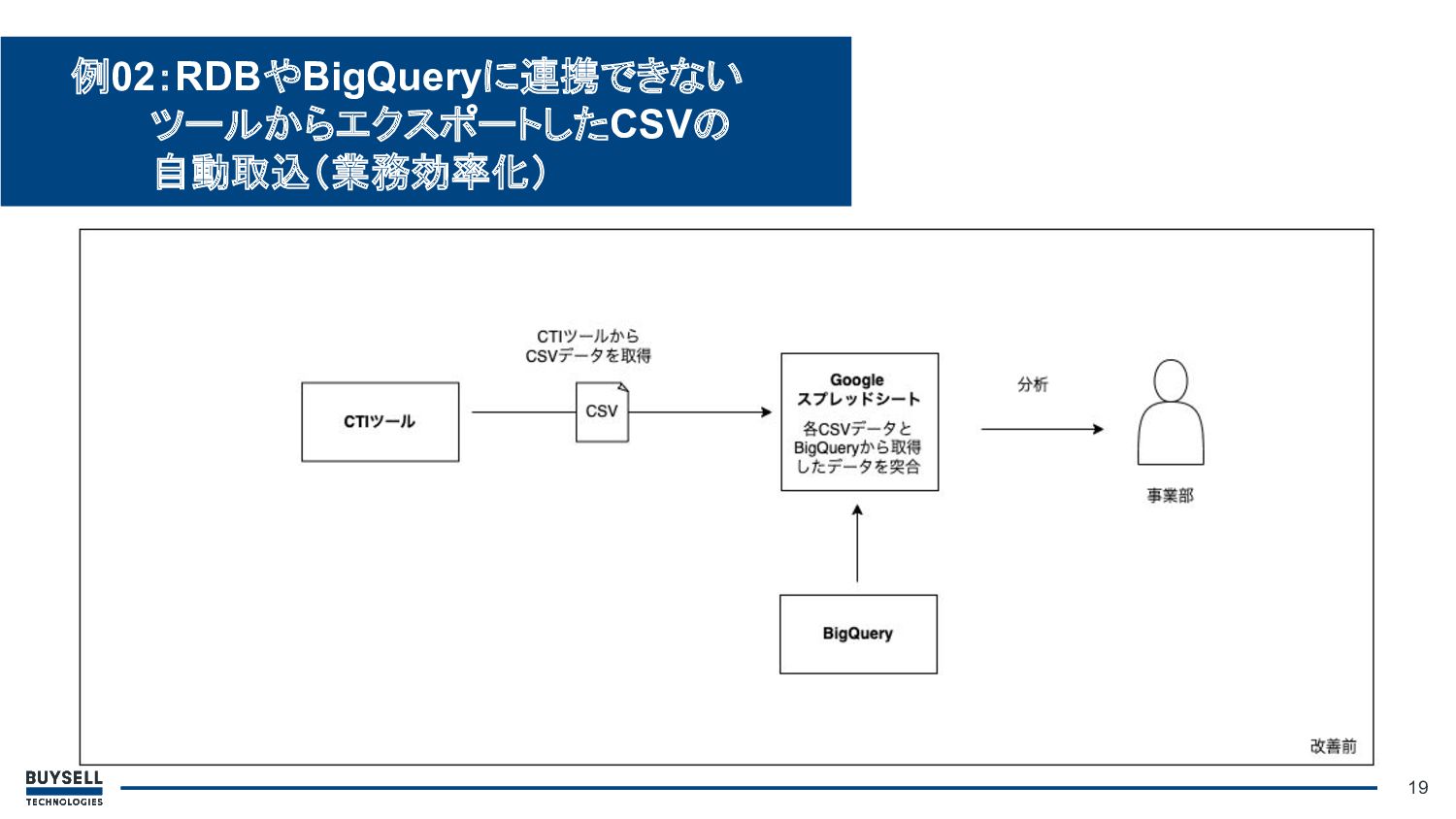
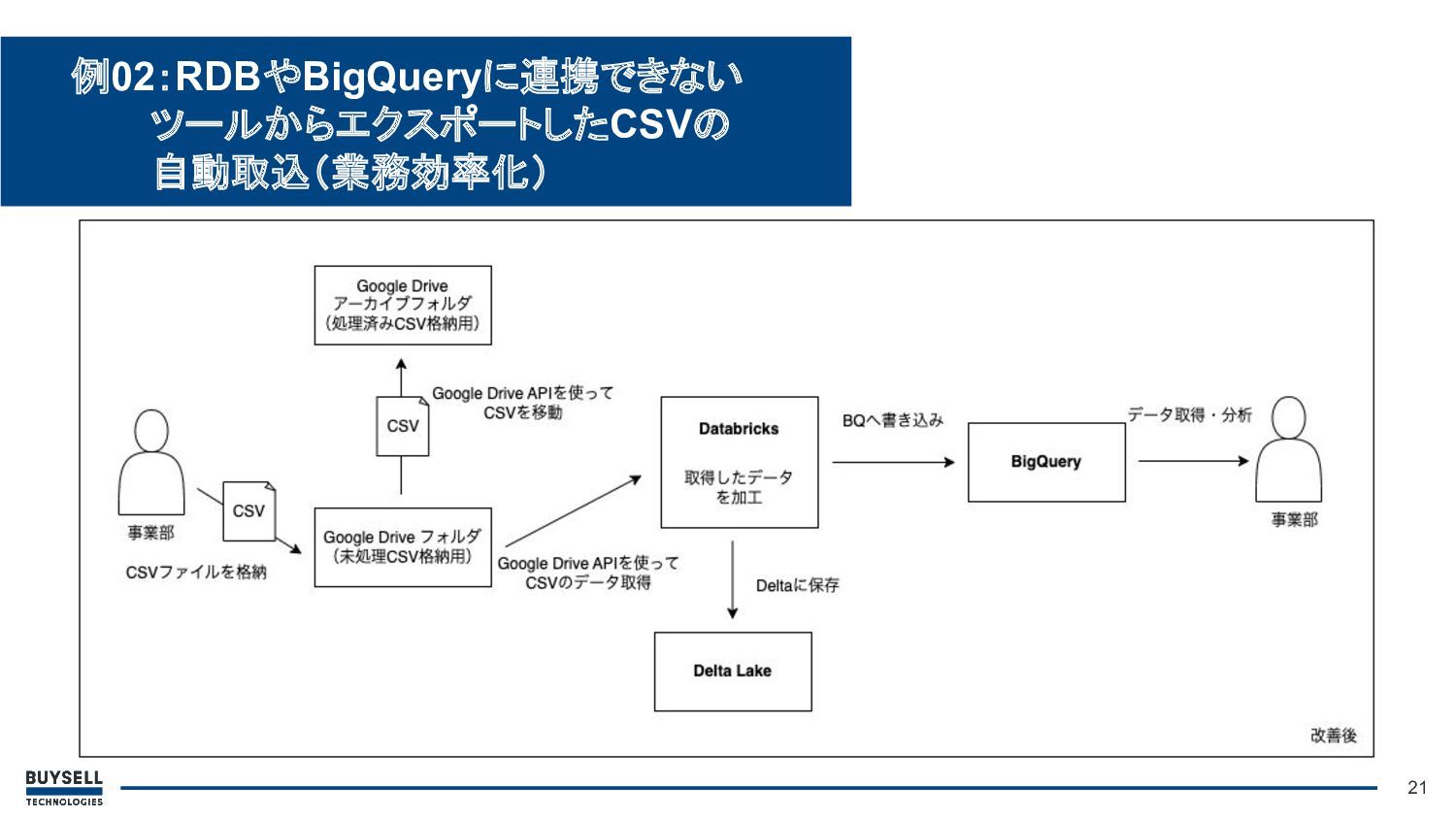
• 背景・課題: ◦ 使用しているCTIツールとBigQueryが未連携 ◦ ツールからCSVを手動でエクスポートし、Googleスプレッドシート上でデータを加 工し、データ集計や分析を行っていた 18 例02:RDBやBigQueryに連携できない ツールからエクスポートしたCSVの
自動取込(業務効率化)
19 例02:RDBやBigQueryに連携できない ツールからエクスポートしたCSVの 自動取込(業務効率化)
• 解決方法: ◦ CTIツールからCSVをエクスポートする 部分は引続き手動で実施 ◦ エクスポートしたCSVを指定のGoogleド ライブに格納 ◦ Databricks上でGoogle
Drive APIを利 用しCSVデータを取得 ◦ データ加工後、BigQueryに格納 20 例02:RDBやBigQueryに連携できない ツールからエクスポートしたCSVの 自動取込(業務効率化)
21 例02:RDBやBigQueryに連携できない ツールからエクスポートしたCSVの 自動取込(業務効率化)
• ポイント: ◦ BigQueryに格納されたCSVを処理中にアーカイブフォルダに移動させる ◦ 未格納のCSVがあるかどうか検知する処理を定期実行し、 CSVデータの格納漏 れがあれば関係者に通知する 22 例02:RDBやBigQueryに連携できない
ツールからエクスポートしたCSVの 自動取込(業務効率化)
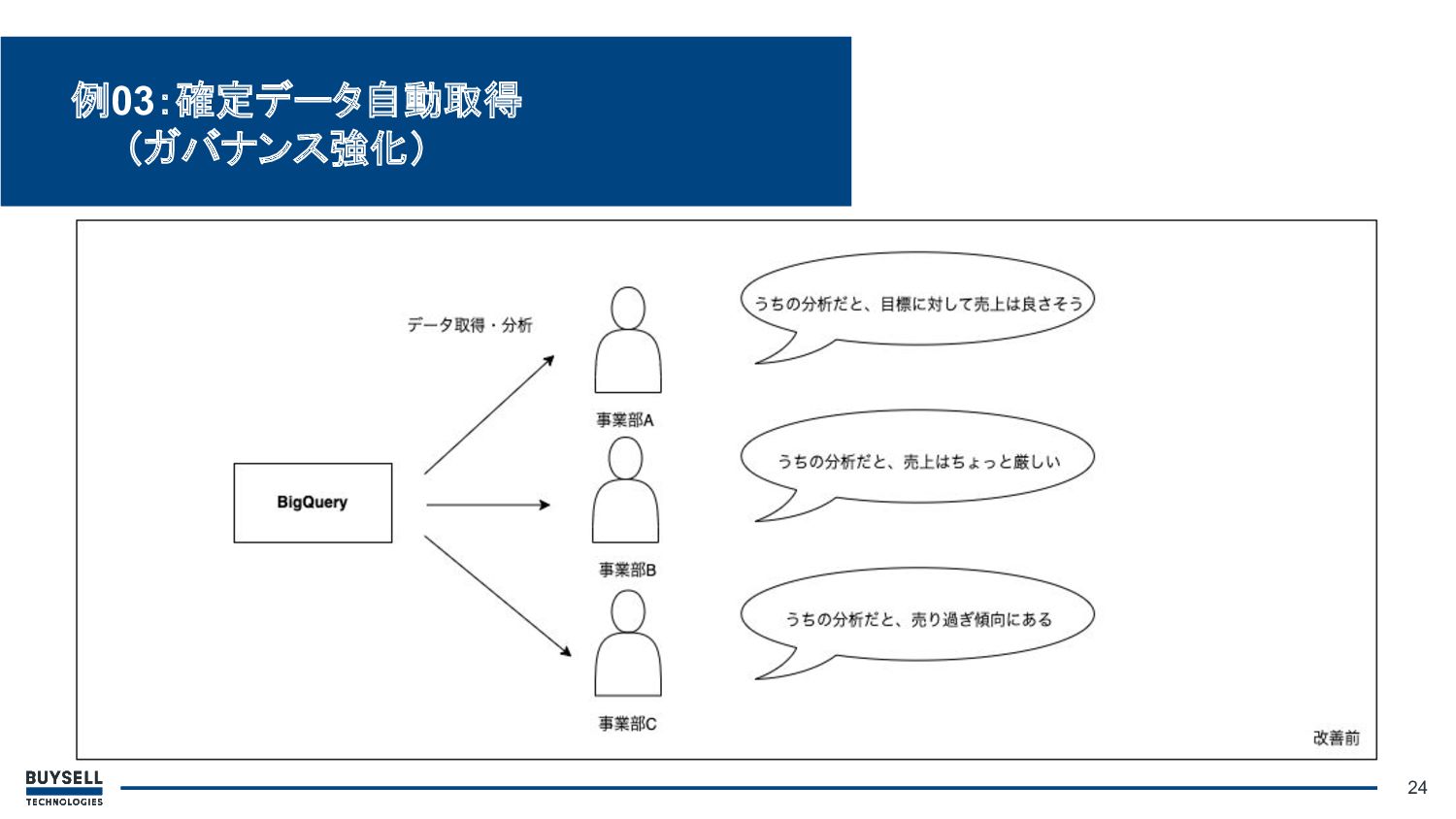
• 背景・課題: ◦ データは取得するタイミングによって値が異なっている、且つ事業部ごとにデータ の粒度やSQLのロジックもバラバラ ◦ 事業部間で「正しい数値」の認識にズレが生じていた ◦ データ量の関係でプロダクトのRDBに確定データを蓄積していくのは難しい( 15万
~900万件レコードが入っているCSVファイルが数ファイル分) 23 例03:確定データ自動取得 (ガバナンス強化)
24 例03:確定データ自動取得 (ガバナンス強化)
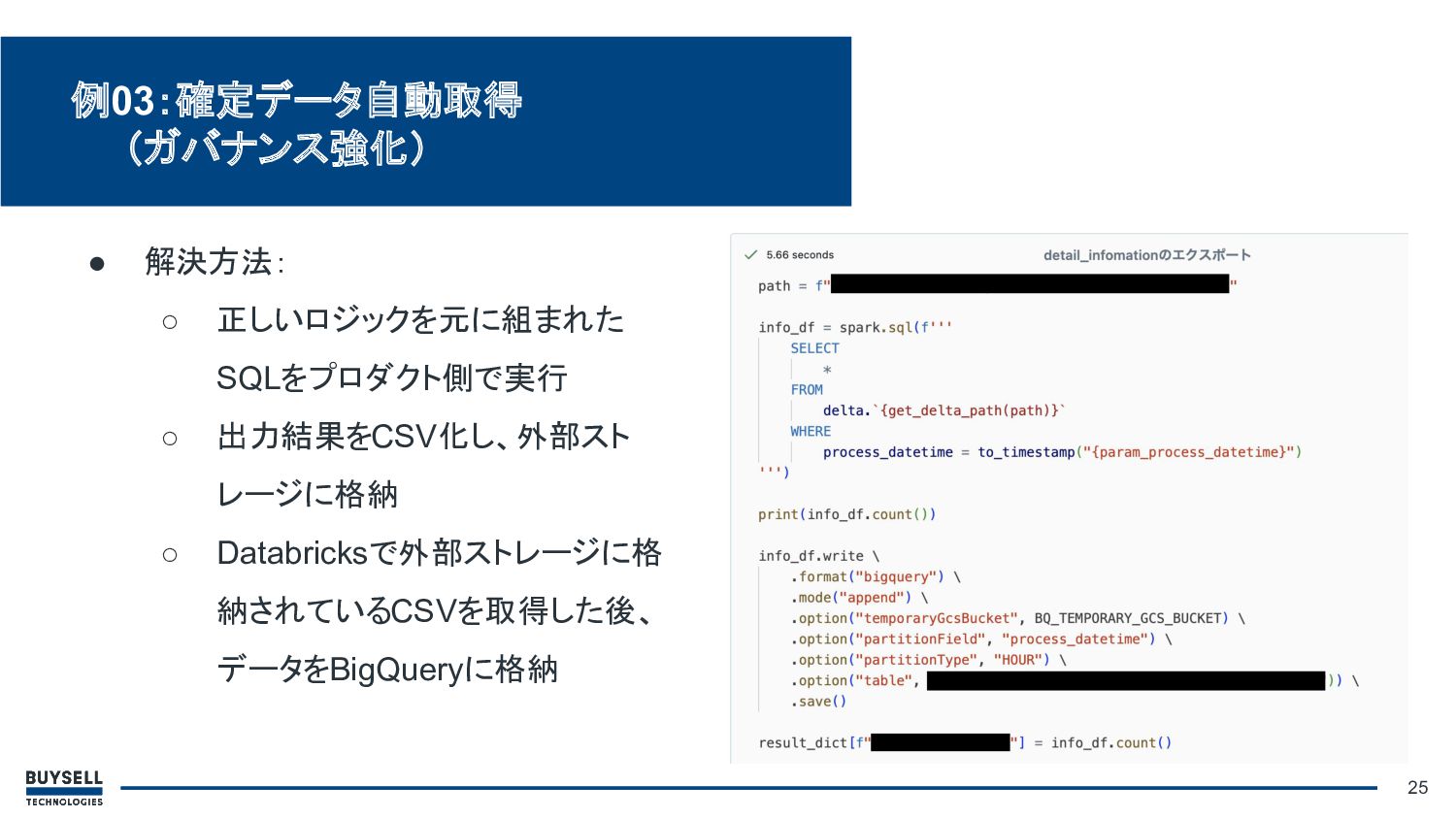
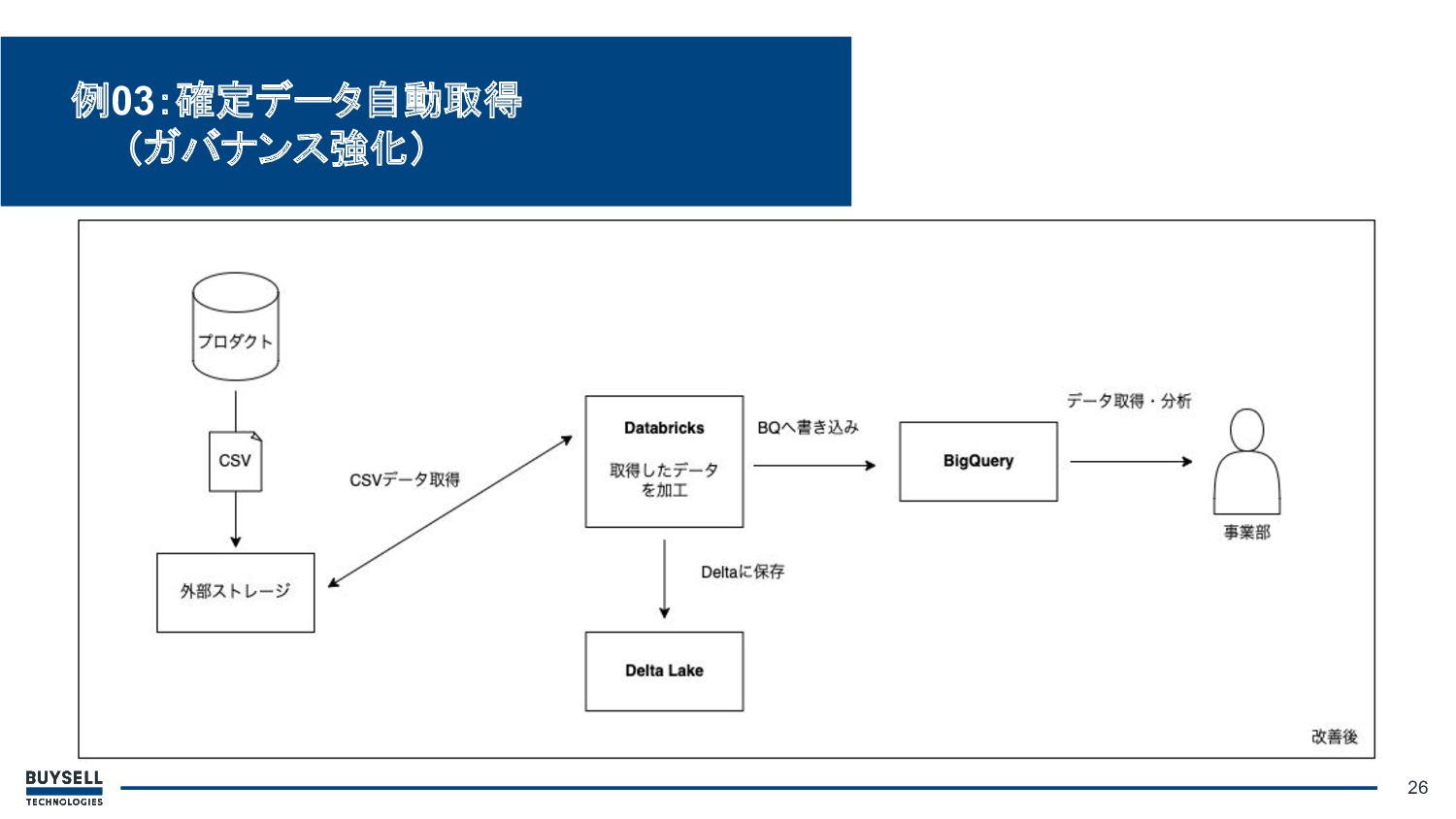
• 解決方法: ◦ 正しいロジックを元に組まれた SQLをプロダクト側で実行 ◦ 出力結果をCSV化し、外部スト レージに格納 ◦ Databricksで外部ストレージに格
納されているCSVを取得した後、 データをBigQueryに格納 25 例03:確定データ自動取得 (ガバナンス強化)
26 例03:確定データ自動取得 (ガバナンス強化)
• ポイント: ◦ 外部ストレージに格納されたCSVデータとBigQueryに格納されたデータに欠損が ないかチェック(レコード件数で比較) ◦ BigQueryに格納されたデータをデータソースとして、 LookerStudio上でダッシュ ボードを作成(複雑なSQLを事業部側で構築する必要も無くなった) 27
例03:確定データ自動取得 (ガバナンス強化)
03 まとめ
• 事業部が独占していたデータが自由に取れるようになり、他部署の業務理解が進んだ • 手動で行っていた集計の工数が削減され、分析業務に集中できるようになった • 使用しているツールの仕様上、閲覧できる期間や表示件数に制限があったが、必要な データが全てBigQueryに取り込まれているため、データ分析作業が捗るようになった 29 データ利用者の反応
• Databricksは柔軟性が高く、エンジニアではないアナリストでも簡単にデータを集めるこ とができる • データを集める中で業務効率化やデータガバナンス強化も実現可能 • 事業部が独占していたデータが民主化され、全社でのデータ活用が促進された 30 まとめ
バイセルでは今後もDatabricksを活用し、グループ全体のデータ活用を 促進していきます 31 まとめ
THANK YOU 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}