• SQLなどのクエリのステート メント(INSERT, UPDATE, DELETE)をそのまま転送。 • NOW()などの非決定的な関 数は値に置き換える。 • 複数ステートメントの場合、 リーダーと完全に同じ順序 で実行する。 (INSERT→UPDATE WHEREなどの組み合わせ では適用順が大事) • エッジケースが多数存在す るので他のレプリケーション 方法が良い。 • 「ストレージエンジンでは全 ての書き込みはログに追記 されていく」ことを利用。 • リーダーはログを自身のディ スクに書き込みつつフォロワ ーに高速に転送。 • フォロワーは受信後高速に 適用していくことでデータを 複製できる。 • 低レベルなバイナリログで柔 軟性がないので、ストレージ エンジンの種類やバージョン を同一のものにする必要有。 • PostgreSQLやOracleで利 用。 • ストレージエンジン固有のロ グフォーマットではない論理 ログを利用、表現力が高い。 • 挿入された行、削除された 行、変更された行という様に 行でログレコードを作成。 • 表現力が高く、パースも容易 なのでCDC(Change Data Capture)に利用され、DWH 構築やインデックス構築など 外部ソース連携可能。 • DynamoDB Streamsなども これにあたる。 • RDBMSのトリガやストアド プロシージャを利用してレプ リケーションを行う。 • 異なるデータベース間での レプリケーション、限定的な 複製、複製ロジックなどアプ リケーションレイヤに上がっ てきた時に利用。 • データの変更時に実行され るカスタムアプリケーションコ ードを登録できる。 • DBMSによって実装されな いので柔軟性が高いが、オ ーバーヘッドが大きい、バグ が生じやすい、制約が大き いなどのデメリットもある。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
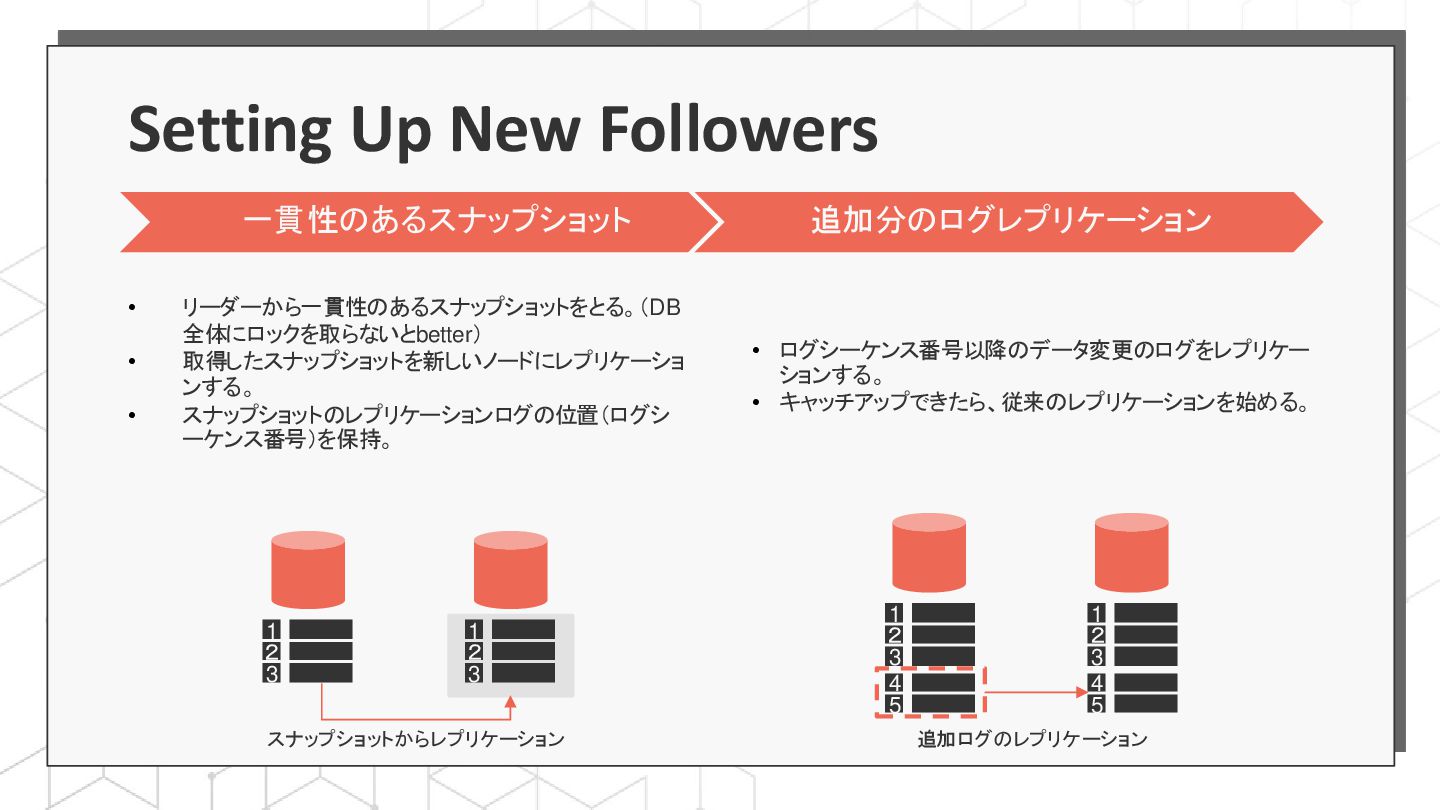{kind=link}
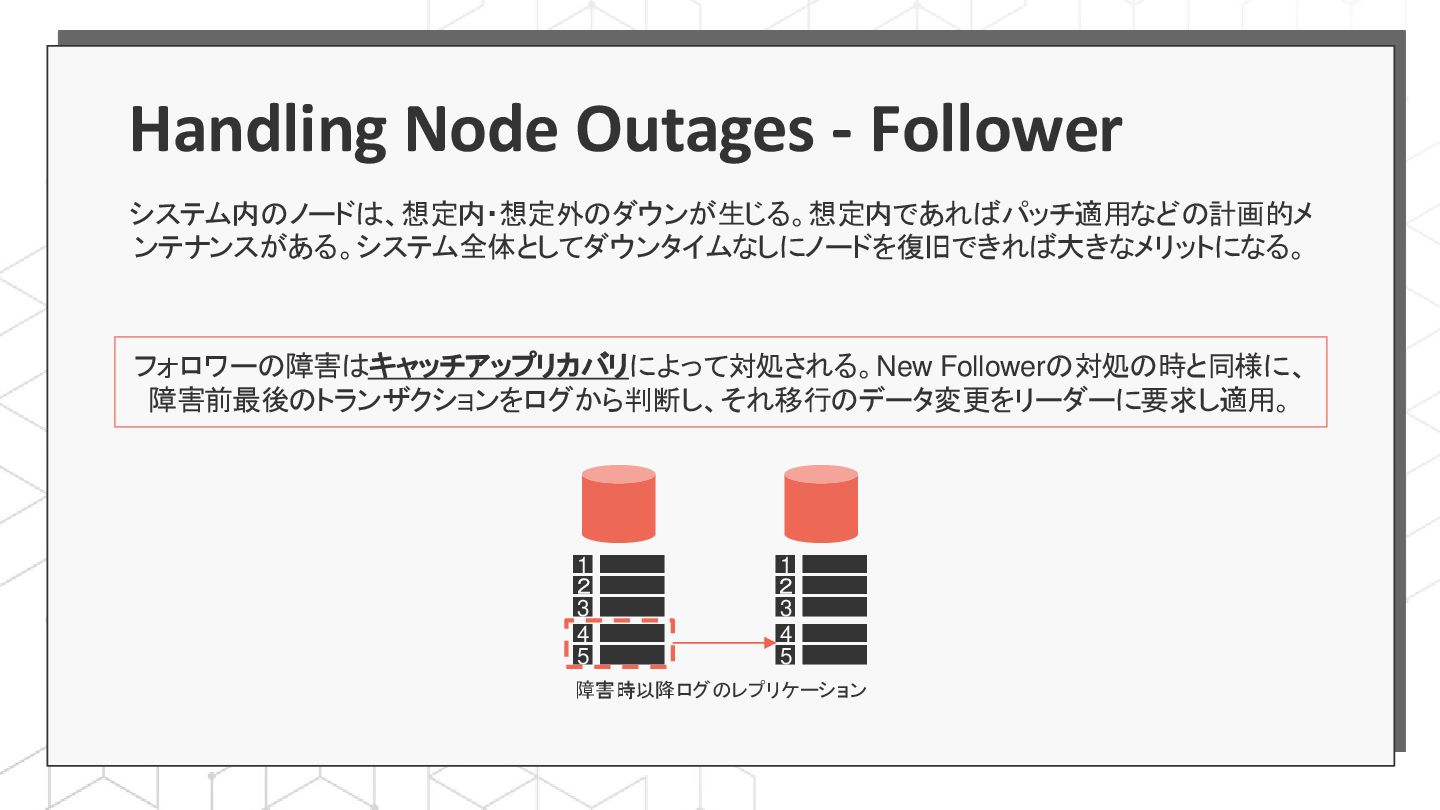{kind=link}
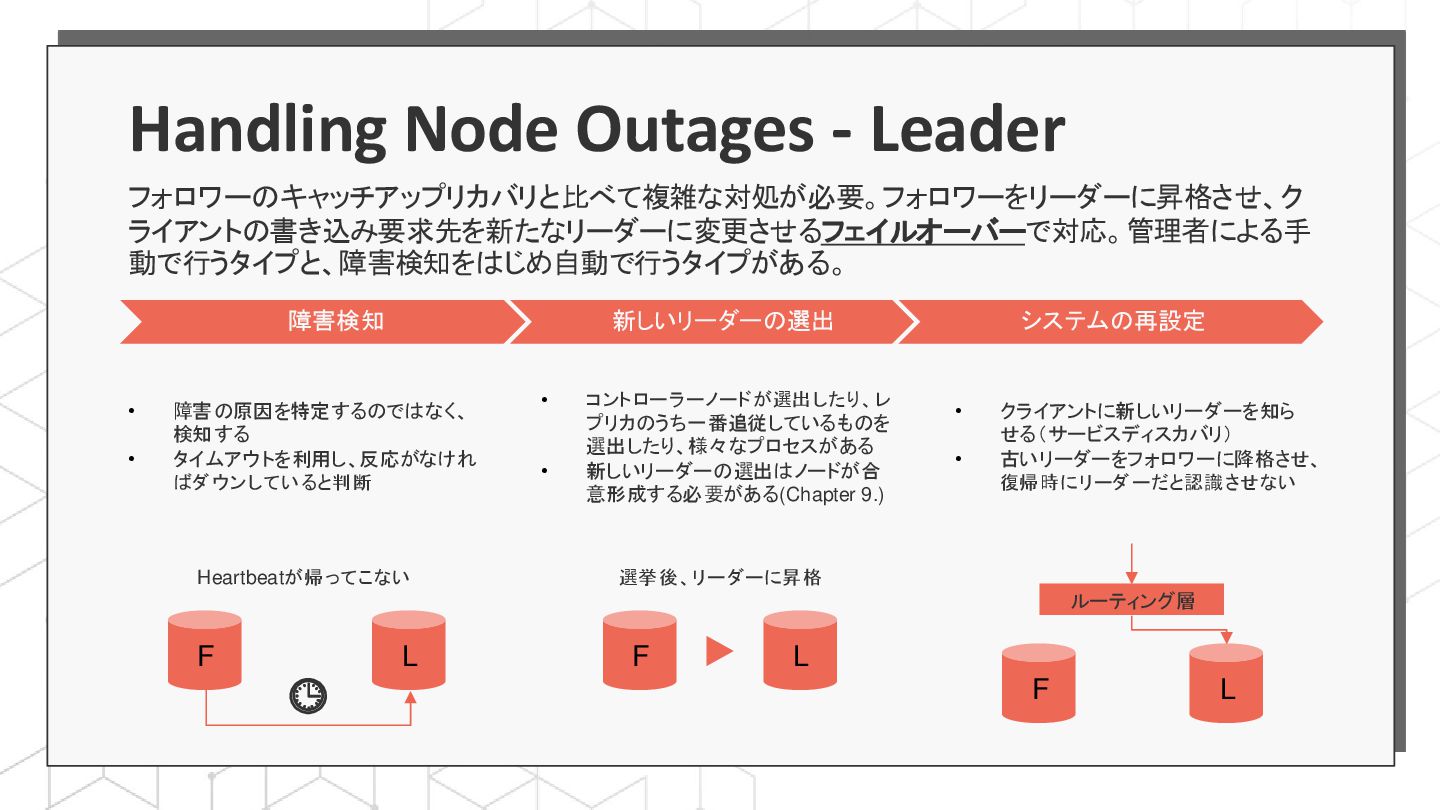{kind=link}
{kind=link}
{kind=link}
{kind=link}
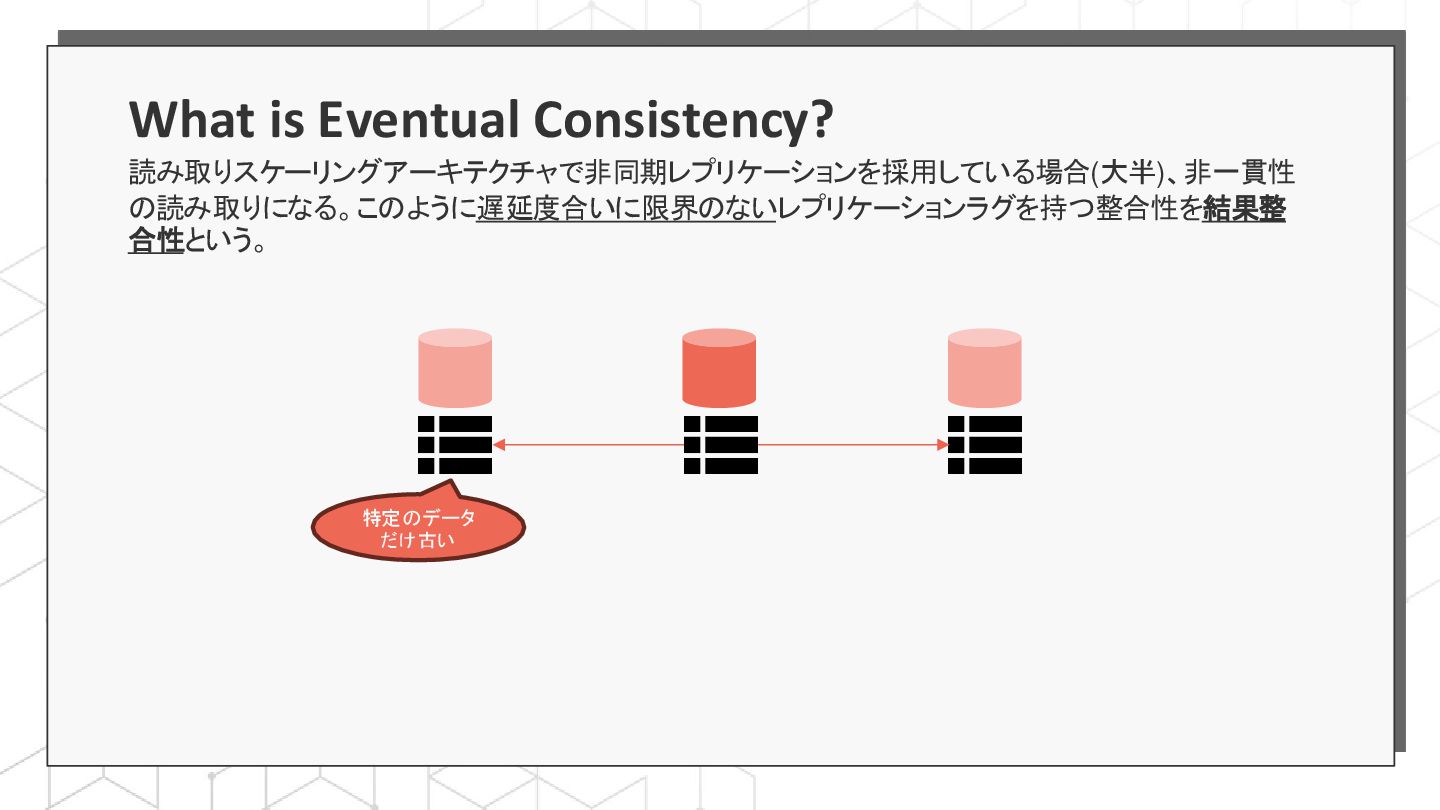{kind=link}
{kind=link}
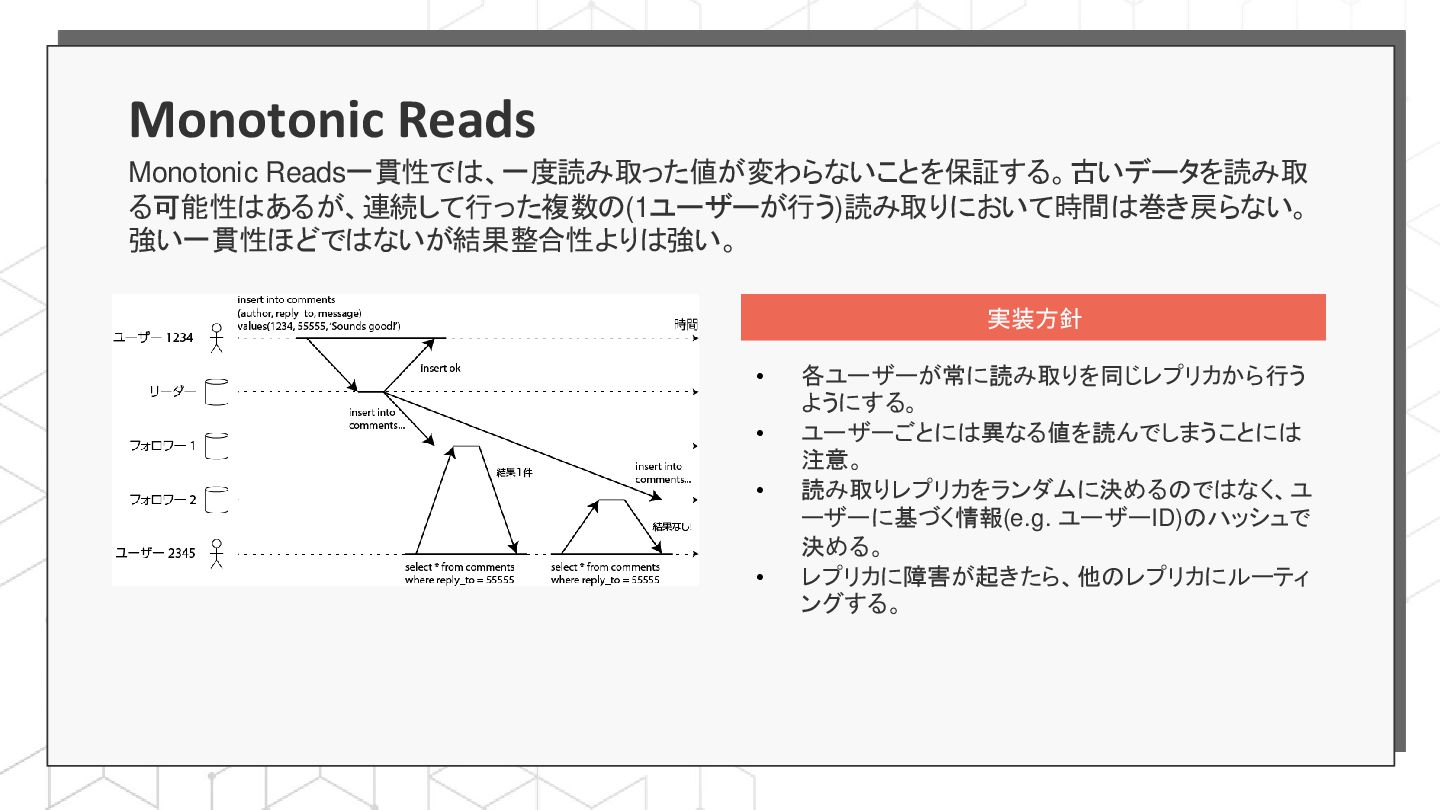{kind=link}
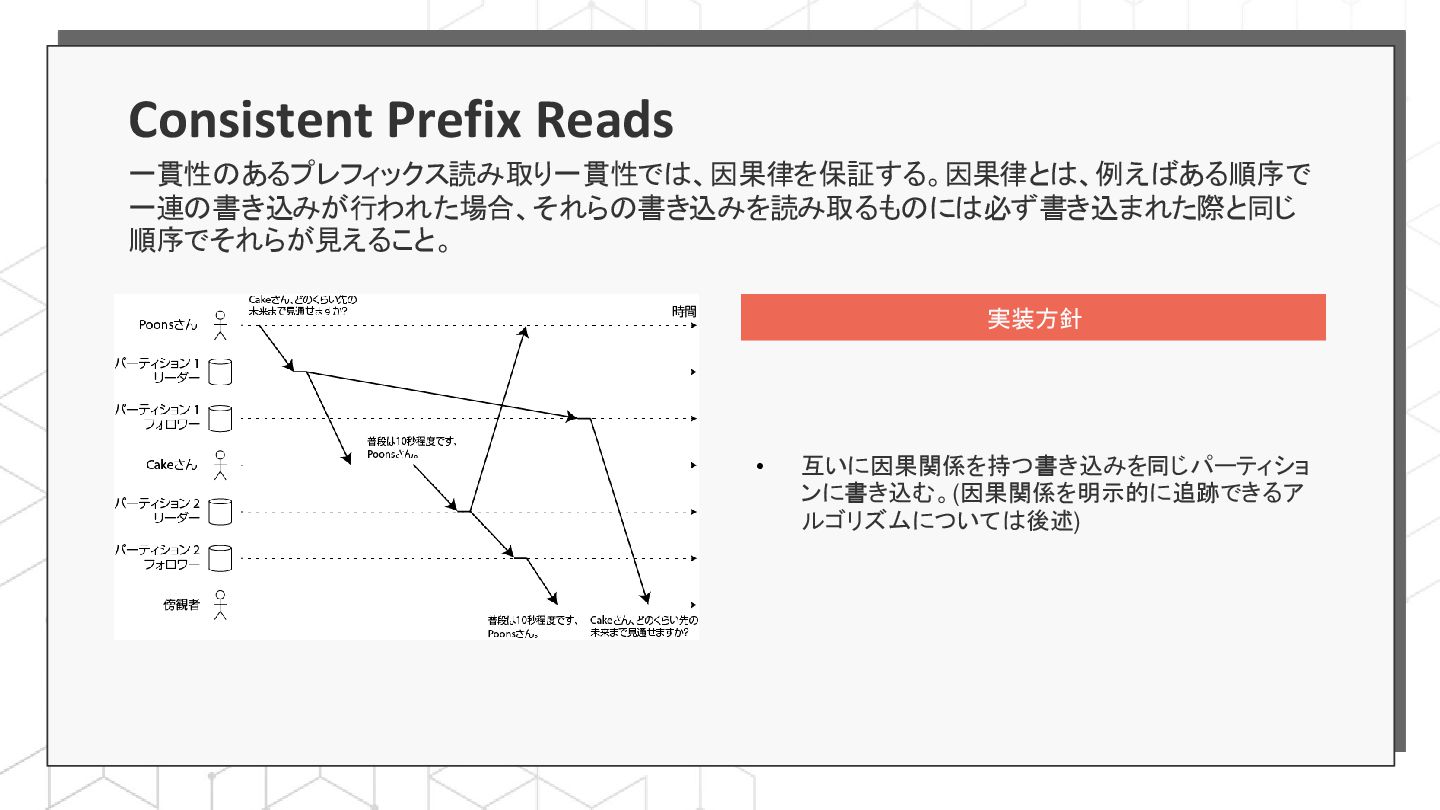{kind=link}
{kind=link}
{kind=link}
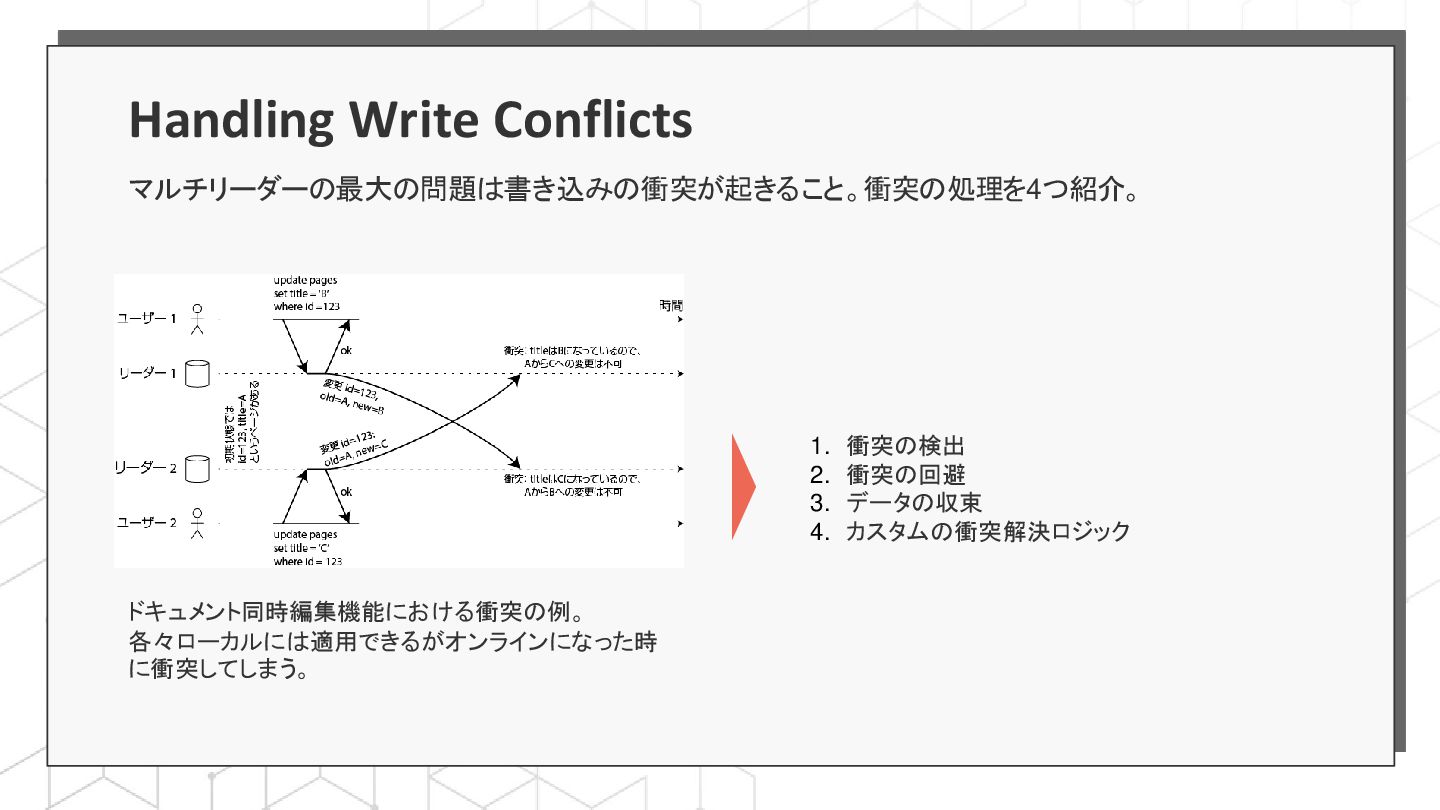{kind=link}
{kind=link}
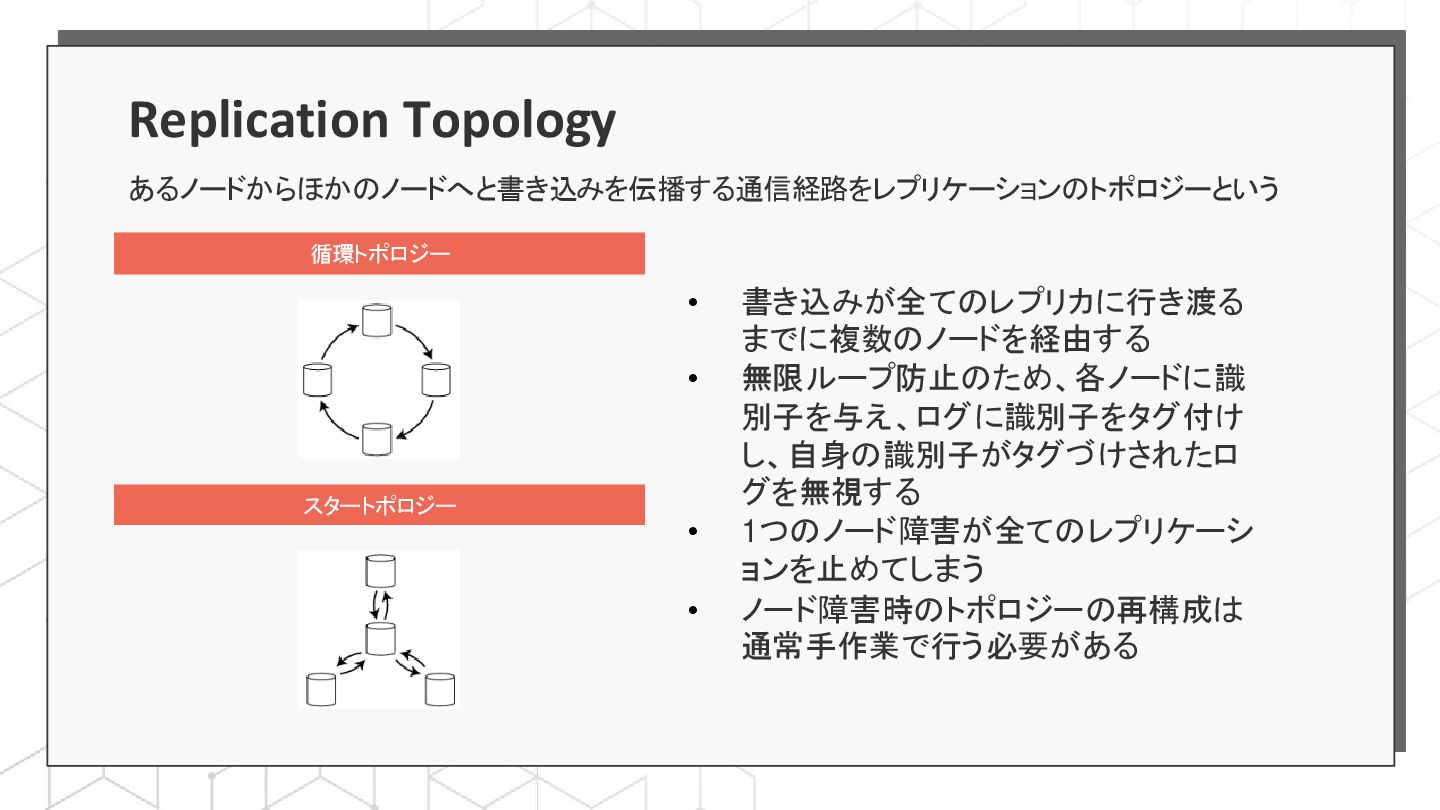{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}