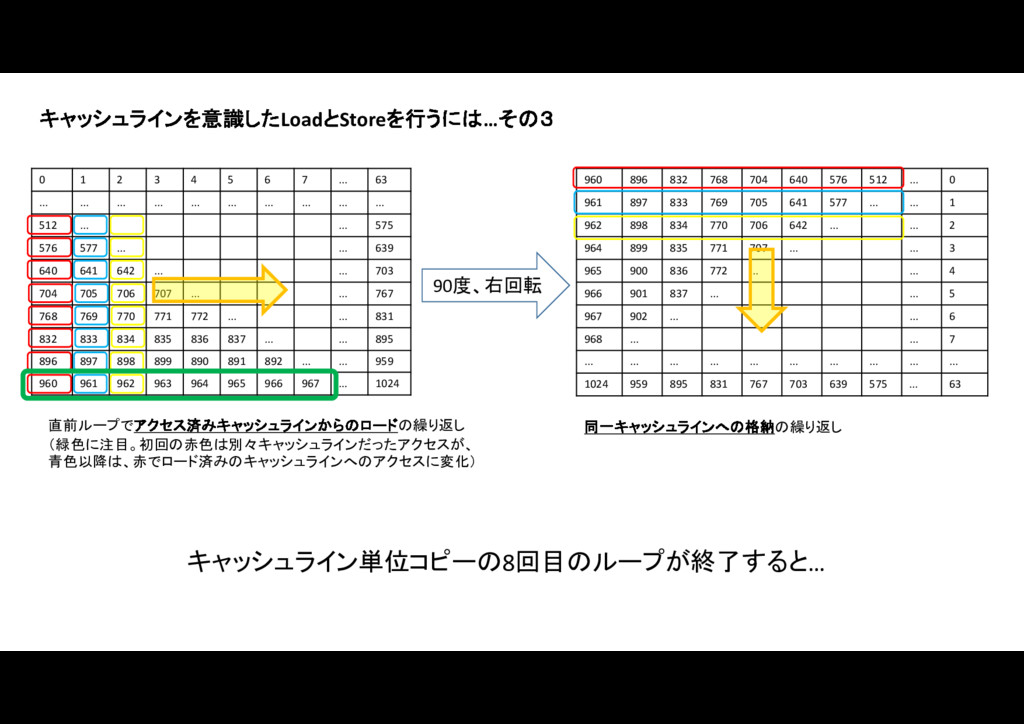
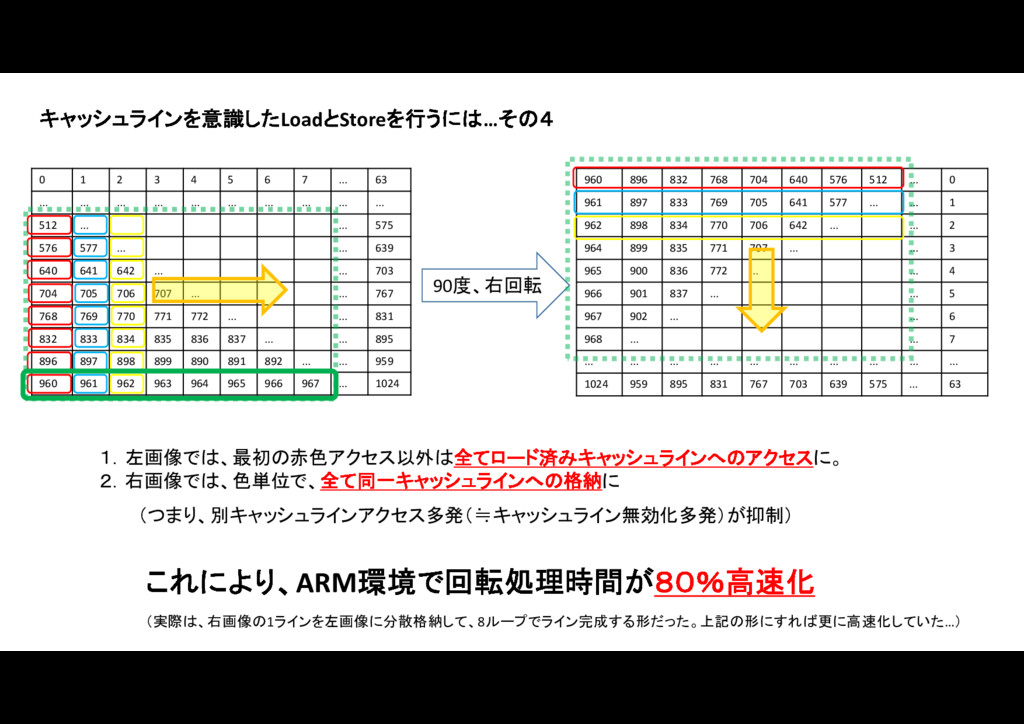
キャッシュラインを意識したコードにすることで、スマートフォンカメラ画像の90度回転を80%高速化した話です。
(さらに、i5で計測し直してみると7倍高速化)
また、AVX2 gather I/O での実験コードも追加してみました。
付記(2018/2/26)
(初版のscatter I/Oベースから、gather I/Oベースに更新しました。このあたりの経緯は https://twitter.com/shirouzu/status/967054027048419328 に書いてありますので、興味のある方は参照下さい)
計測用テストコードは下記にあります。
https://github.com/shirouzu/samples/tree/master/fast_rotate
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}