Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【第4回】関東Kaggler会「Kaggleは執筆に役立つ」
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Wataru Takahara
August 23, 2025
Programming
2.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【第4回】関東Kaggler会「Kaggleは執筆に役立つ」
Wataru Takahara
August 23, 2025
More Decks by Wataru Takahara
See All by Wataru Takahara
Kaggle-Vesuvius-Challenge-Ink-Detection-2nd-Solution
mipypf
1
3.6k
Other Decks in Programming
See All in Programming
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
270
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
変わらないものが、変わるものを決める — 意図駆動開発 × イベントソーシング × イミュータブル | What Doesn't Change Decides What Can — IDD × Event Sourcing × Immutability
tomohisa
0
140
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
160
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.9k
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
530
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
500
人間の目はかわらない、だからJPEGは30年もつ
yuzneri
1
250
FDEが実現するAI駆動経営の現在地
gonta
2
200
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
240
Hatena Engineer Seminar #37「言語モデルの活用に関する研究」
slashnephy
0
540
Featured
See All Featured
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Git: the NoSQL Database
bkeepers
PRO
432
67k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Design in an AI World
tapps
1
270
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Amusing Abliteration
ianozsvald
1
240
Thoughts on Productivity
jonyablonski
76
5.3k
Transcript
Kaggleは執筆に役立つ 2025/8/23 第4回 関東Kaggler会 ろん
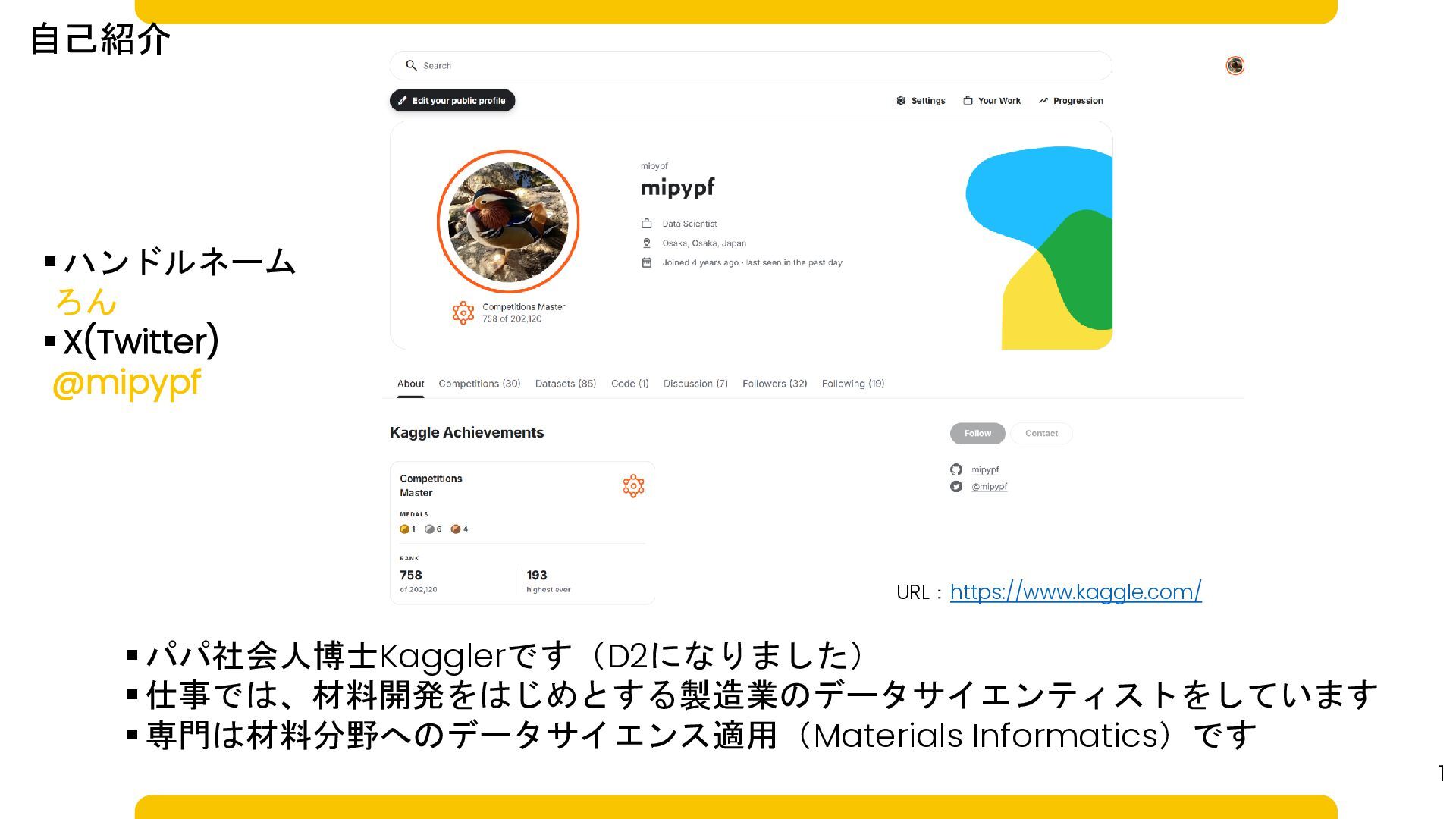
▪ パパ社会人博士Kagglerです(D2になりました) ▪ 仕事では、材料開発をはじめとする製造業のデータサイエンティストをしています ▪ 専門は材料分野へのデータサイエンス適用(Materials Informatics)です ▪ ハンドルネーム ろん
▪ X(Twitter) @mipypf 自己紹介 1 URL:https://www.kaggle.com/
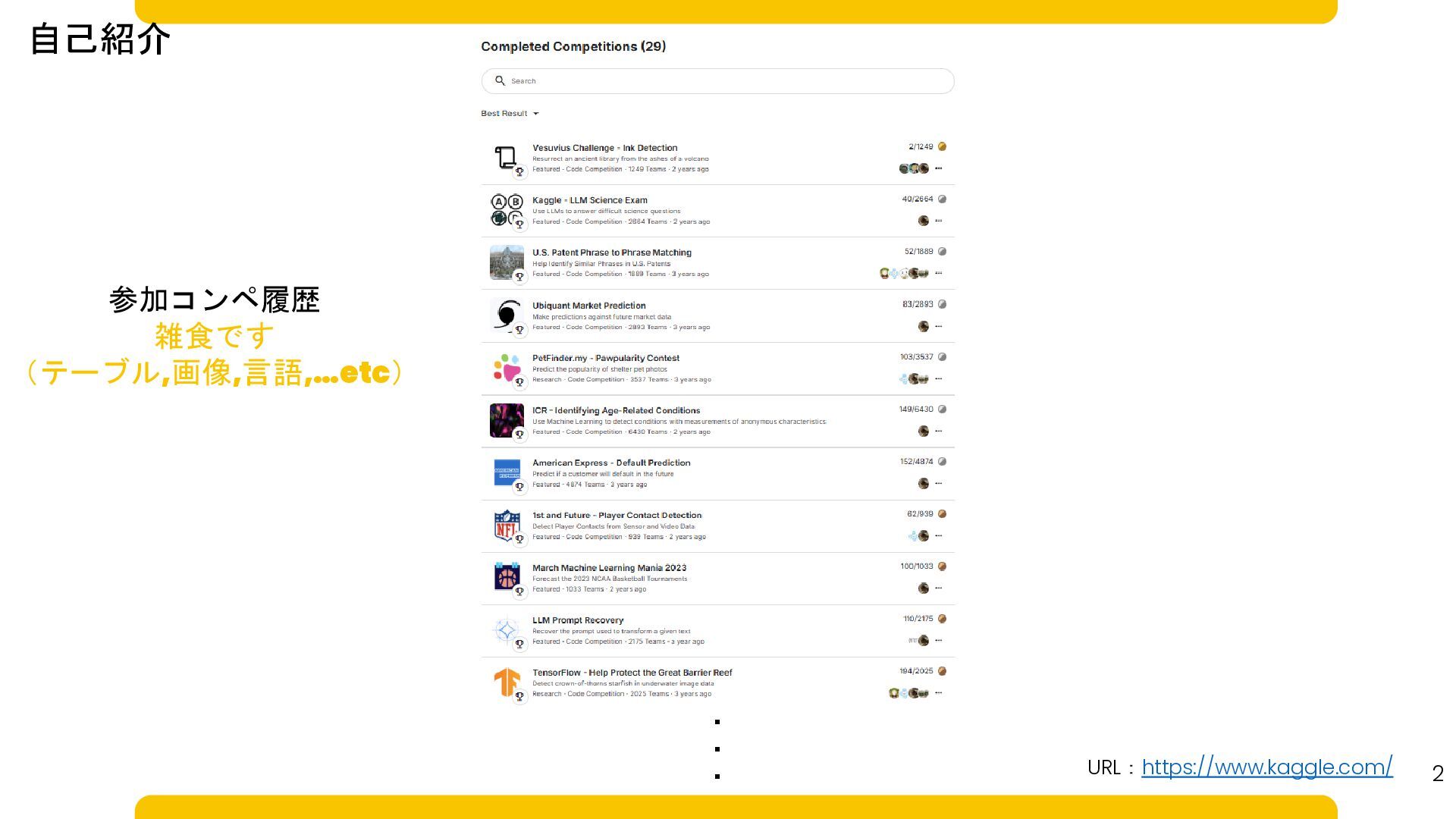
参加コンペ履歴 雑食です (テーブル,画像,言語,…etc) 自己紹介 2 ・・・ URL:https://www.kaggle.com/
出典:https://x.com/kakulin_real/status/1728691633196286055 Kaggleはxx に役立つ? はじめに 3
Kaggleは執筆にも役立つ! はじめに 4
5 製造業における仕事でデータ 分析コンペがどう役立ってい るか、執筆してもらえません か? 色々なタスクのコンペ に参加して得られた Kaggleでの学びを、 材料開発をはじめとす る製造業の現場に適用
してきた経験が今こそ 役立つのでは… 経緯 材料開発をはじめとした製造 業で、テーブルデータだけで はなく、画像データ・テキス トデータ(生成AI含む)・材 料構造など各種タスクを網羅 的に実務の傍らにおける書籍 を執筆してもらえませんか? 例1 例2
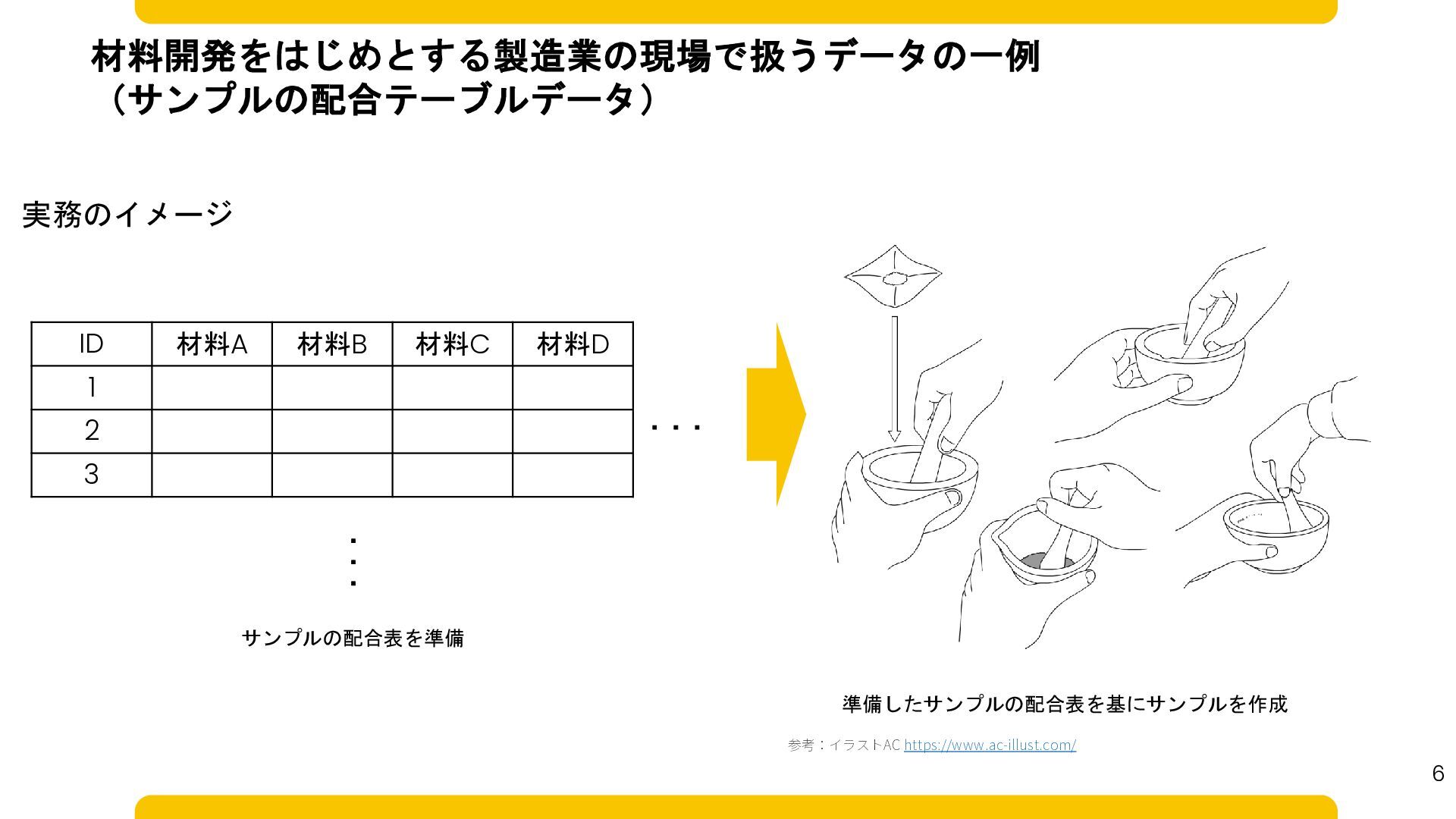
材料開発をはじめとする製造業の現場で扱うデータの一例 (サンプルの配合テーブルデータ) 実務のイメージ ID 材料A 材料B 材料C 材料D 1 2
3 ・・・ ・・・ サンプルの配合表を準備 準備したサンプルの配合表を基にサンプルを作成 参考:イラストAC https://www.ac-illust.com/ 6
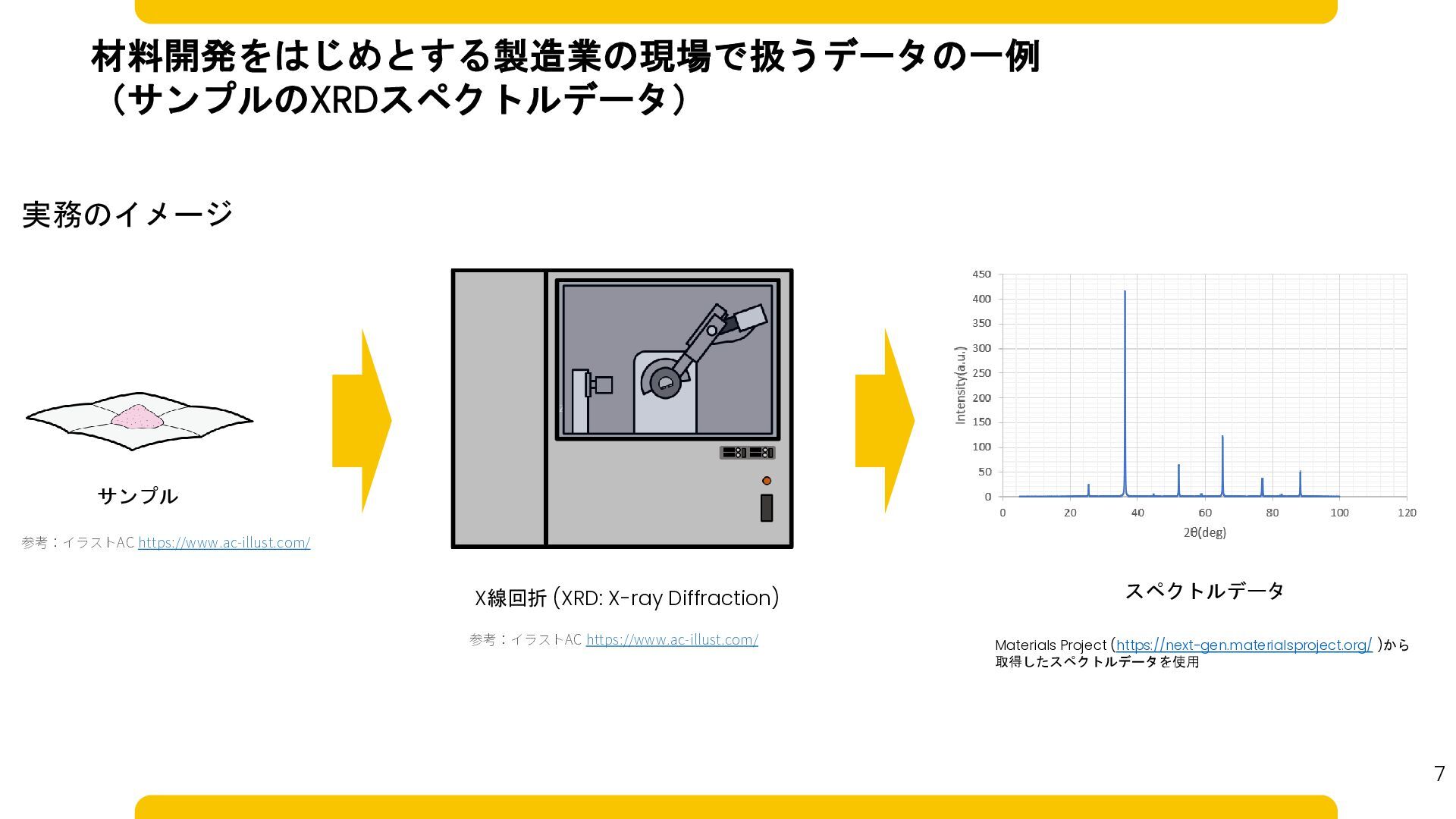
材料開発をはじめとする製造業の現場で扱うデータの一例 (サンプルのXRDスペクトルデータ) サンプル X線回折 (XRD: X-ray Diffraction) 実務のイメージ スペクトルデータ Materials
Project (https://next-gen.materialsproject.org/ )から 取得したスペクトルデータを使用 参考:イラストAC https://www.ac-illust.com/ 参考:イラストAC https://www.ac-illust.com/ 7
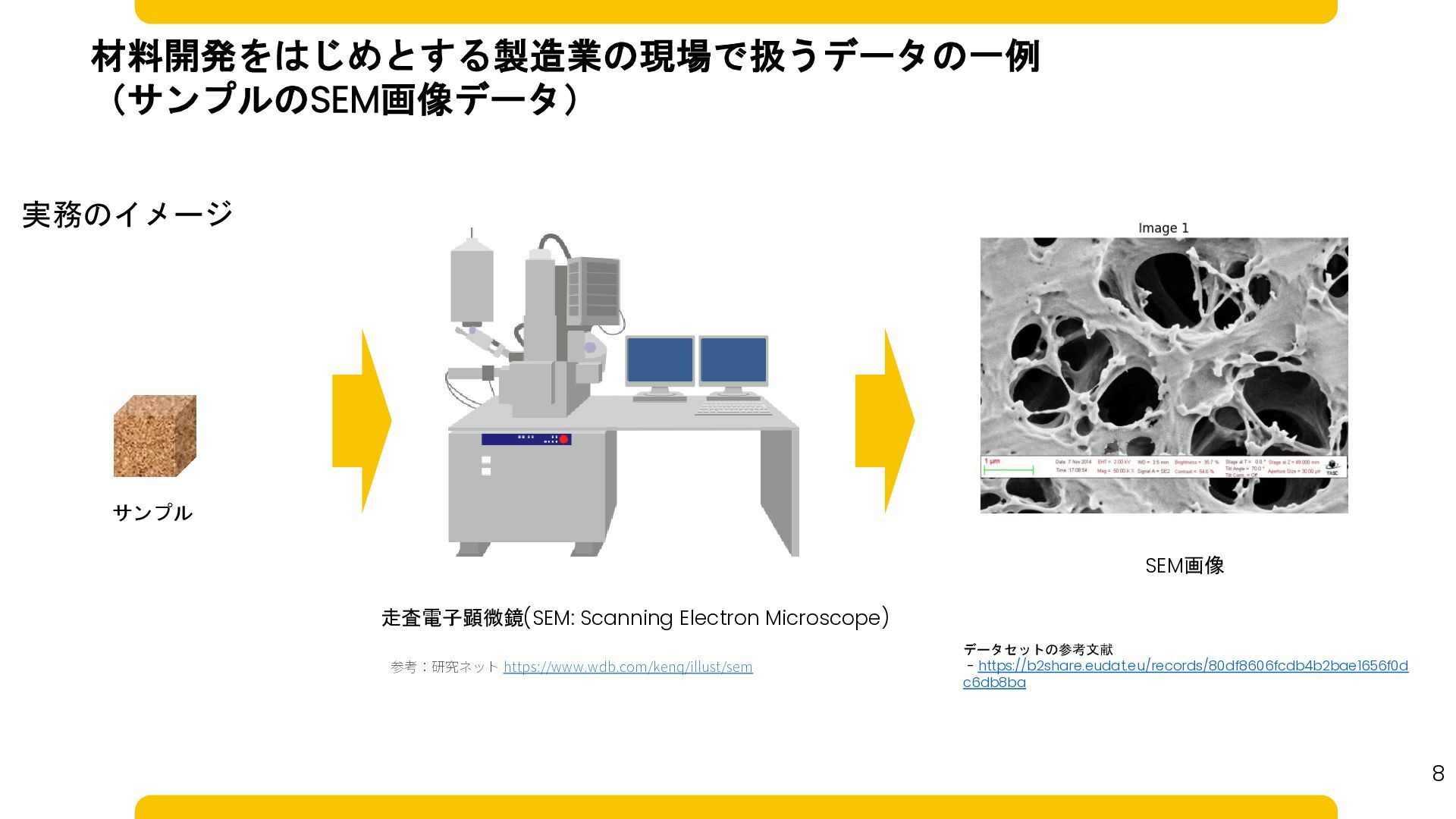
材料開発をはじめとする製造業の現場で扱うデータの一例 (サンプルのSEM画像データ) 実務のイメージ 走査電子顕微鏡(SEM: Scanning Electron Microscope) データセットの参考文献 - https://b2share.eudat.eu/records/80df8606fcdb4b2bae1656f0d
c6db8ba SEM画像 サンプル 参考:研究ネット https://www.wdb.com/kenq/illust/sem 8
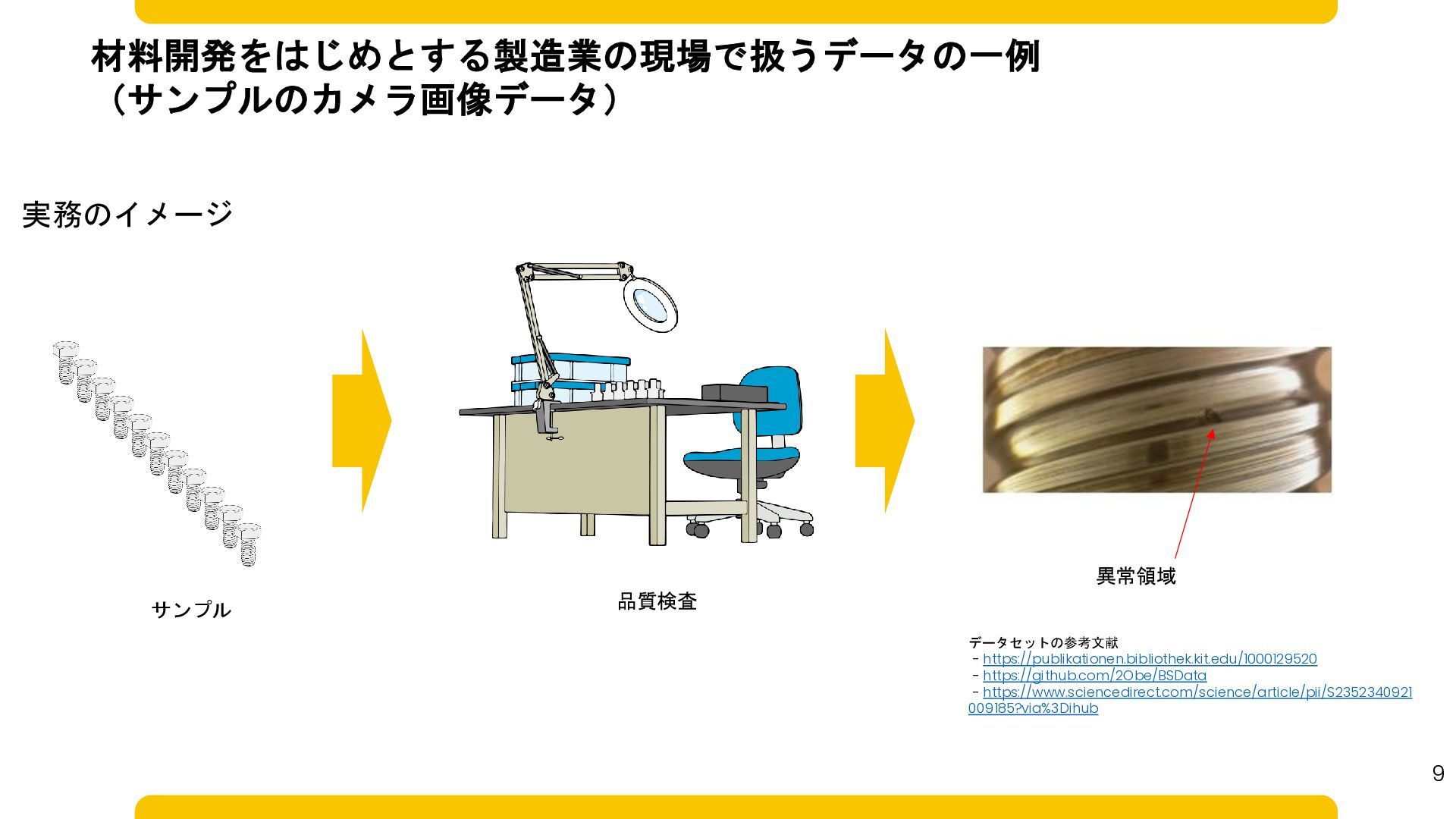
材料開発をはじめとする製造業の現場で扱うデータの一例 (サンプルのカメラ画像データ) 実務のイメージ データセットの参考文献 - https://publikationen.bibliothek.kit.edu/1000129520 - https://github.com/2Obe/BSData - https://www.sciencedirect.com/science/article/pii/S2352340921
009185?via%3Dihub 品質検査 異常領域 サンプル 9
材料開発をはじめとする製造業の現場で扱うデータの一例 (文書データ) 実務のイメージ xxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxx ABSTRACT xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxx INTRODUCTION
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxx Aaaaa, Bbbbbb, Ccccccc, and Dddddd xxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxx ABSTRACT xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxx INTRODUCTION xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxx Aaaaa, Bbbbbb, Ccccccc, and Dddddd xxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxx ABSTRACT xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxx INTRODUCTION xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxx Aaaaa, Bbbbbb, Ccccccc, and Dddddd xxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxx ABSTRACT xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxx INTRODUCTION xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx xxxxxxxxxxxxxxxxxxxxxx Aaaaa, Bbbbbb, Ccccccc, and Dddddd ----------------------- ----------------------- ----------------------- ----------------------- 専門領域で調査が必要な事項が発生 文献調査 調査内容まとめ 10
11 製造業における仕事でデータ 分析コンペがどう役立ってい るか、執筆してもらえません か? 色々なタスクのコンペ に参加して得られた Kaggleでの学びを、 材料開発をはじめとす る製造業の現場に適用
してきた経験が今こそ 役立つのでは… 解説記事「実務にデータ分析コンペは有効か」を執筆(電子情報通信学会誌Vol.107に掲載) 経緯 URL:https://www.journal.ieice.org/summary.php?id=k107_10_973&year=2024&lang=J 例1
【背景】 ・データ分析コンペ(例:Kaggle)は実務と異なり、課題設定や現場適用の工程がないが、データ理解~モデル構築の高度なスキルを養える 【実務とコンペの比較】 《実務のプロセス》 ①課題理解・選定 → ②データ収集・理解 → ③アプローチ策定 →
④データ加工 → ⑤モデル構築 → ⑥評価 → ⑦現場適用・運用 《コンペのプロセス》 ②’データ理解 → ③’アプローチ策定 → ④’データ加工 → ⑤’モデル構築 → ⑥’評価 ※①,⑦は主催者側が担い、評価指標やデータは事前提供 【得られるスキル】 ・データ構造の把握力 ・多様なアプローチ検討力 ・評価・検証の精緻化(リーク検出、CV設計など) ・失敗からの学び(実務では困難な試行錯誤など) 【製造業への応用】 ・テーブルデータ ・材料構造データ(有機/無機) ・画像データ ・テキストデータ(生成AIタスク含む) 【まとめ】 ・コンペは実務全体の一部をカバーするが、共通領域のスキル習得に有効 ・技術の実践的習得にも活用可能 ・最新技術のキャッチアップにも有効 出典:阪田隆司,高原渉,“実務にデータ分析コンペは有効か”,電子情報通信学会誌,Vol.107, No.10, pp.973-978, 2024. 解説記事「実務にデータ分析コンペは有効か」 12
13 材料開発をはじめとした製造 業で、テーブルデータだけで はなく、画像データ・テキス トデータ(生成AI含む)・材 料構造など各種タスクを網羅 的に実務の傍らにおける書籍 を執筆してもらえませんか? 書籍「マテリアルズ・インフォマティクス 実践ハンドブック」(森北出版)を執筆
色々なタスクのコンペ に参加して得られた Kaggleでの学びを、 材料開発をはじめとす る製造業の現場に適用 してきた経験が今こそ 役立つのでは… 経緯 URL:https://www.morikita.co.jp/books/mid/085841 材料開発をはじめとした製造 業で、テーブルデータだけで はなく、画像データ・テキス トデータ(生成AI含む)・材 料構造など各種タスクを網羅 的に実務の傍らにおける書籍 を執筆してもらえませんか? 例2
URL:https://www.morikita.co.jp/books/mid/085841 書籍「マテリアルズ・インフォマティクス 実践ハンドブック」 14
はじめに 序章 マテリアルズ・インフォティクスの世界へようこそ 1 マテリアルズ・インフォマティクスとは? 2 材料開発×データサイエンス 3 どのようなフローでデータを活用するのか? 第1章
MIにおける機械学習 1 MIの中核をなす技術:機械学習 2 機械学習とは? 3 教師あり学習の活用 4 材料開発におけるデータの特性 第2章 データ分析のフロー Step1 材料開発における現状を整理する Step2 目的を設定する Step3 データを準備する Step4 データを理解する Step5 機械学習モデル構築のタスク設計を行う Step6 機械学習モデルを構築する Step7 機械学習モデルを評価する Step8 機械学習モデルを運用する Step9 結果と分析コードを共有する 個別の機械学習アルゴリズムの使用 第3章 データ分析のハンズオン Step1 材料開発における現状を整理する Step2 目的を設定する Step3 データを準備する Step4 データを理解する Step5 機械学習モデル構築のタスク設計を行う Step6 機械学習モデルを構築する Step7 機械学習モデルを評価する Step8 機械学習モデルを運用する Step9 結果と分析コードを共有する 第4章 材料分野別,タスク別のMI適用アプローチ 1 画像データ分析 2 テキストデータ分析(自然言語処理) 3 有機材料の材料構造データ分析 4 無機材料の材料構造データ分析 5 スペクトルデータ分析 6 時系列データ分析 第5章 分析を一歩進めるためのTips Step1 材料開発における現状を整理する Step2 目的を設定する Step3 データを準備する Step4 データを理解する Step5 機械学習モデル構築のタスク設計を行う Step6 機械学習モデルを構築する Step7 機械学習モデルを評価する Step8 機械学習モデルを運用する Step9 結果と分析コードを共有する その他のTips 第6章 継続的な学習とスキルの向上 1 MI推進に必要なスキルセットの復習 2 材料ドメイン知識 3 プロジェクト推進力 4 データサイエンス力 5 データエンジニアリング力 おわりに 参考文献 索引 出典:高原渉,福岡誠之,“マテリアルズ・インフォマティクス 実践ハンドブック”,森北出版,2025. 目次 15 URL:https://www.morikita.co.jp/books/mid/085841
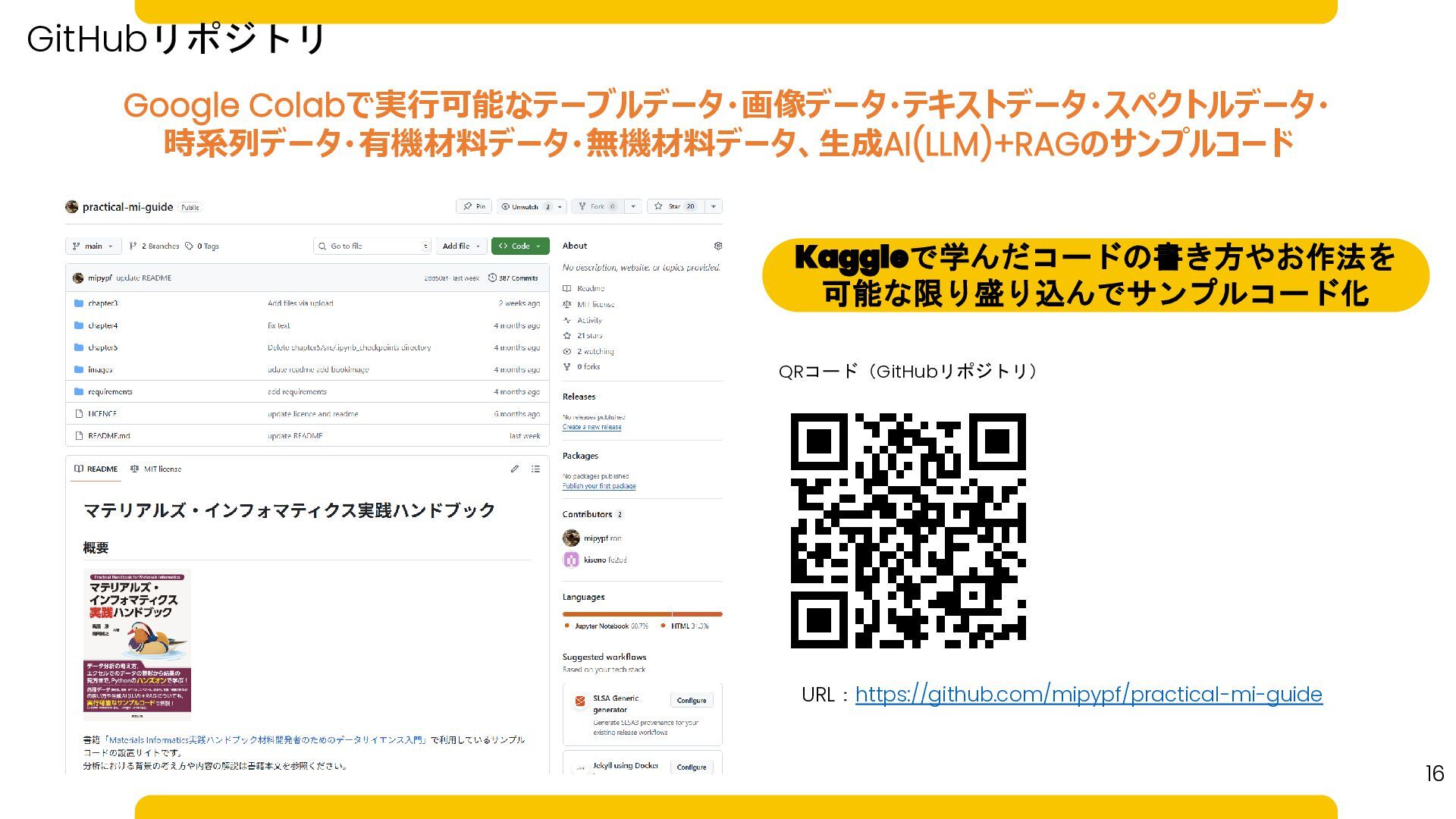
Google Colabで実行可能なテーブルデータ・画像データ・テキストデータ・スペクトルデータ・ 時系列データ・有機材料データ・無機材料データ、生成AI(LLM)+RAGのサンプルコード 16 URL:https://github.com/mipypf/practical-mi-guide QRコード(GitHubリポジトリ) GitHubリポジトリ Kaggleで学んだコードの書き方やお作法を 可能な限り盛り込んでサンプルコード化
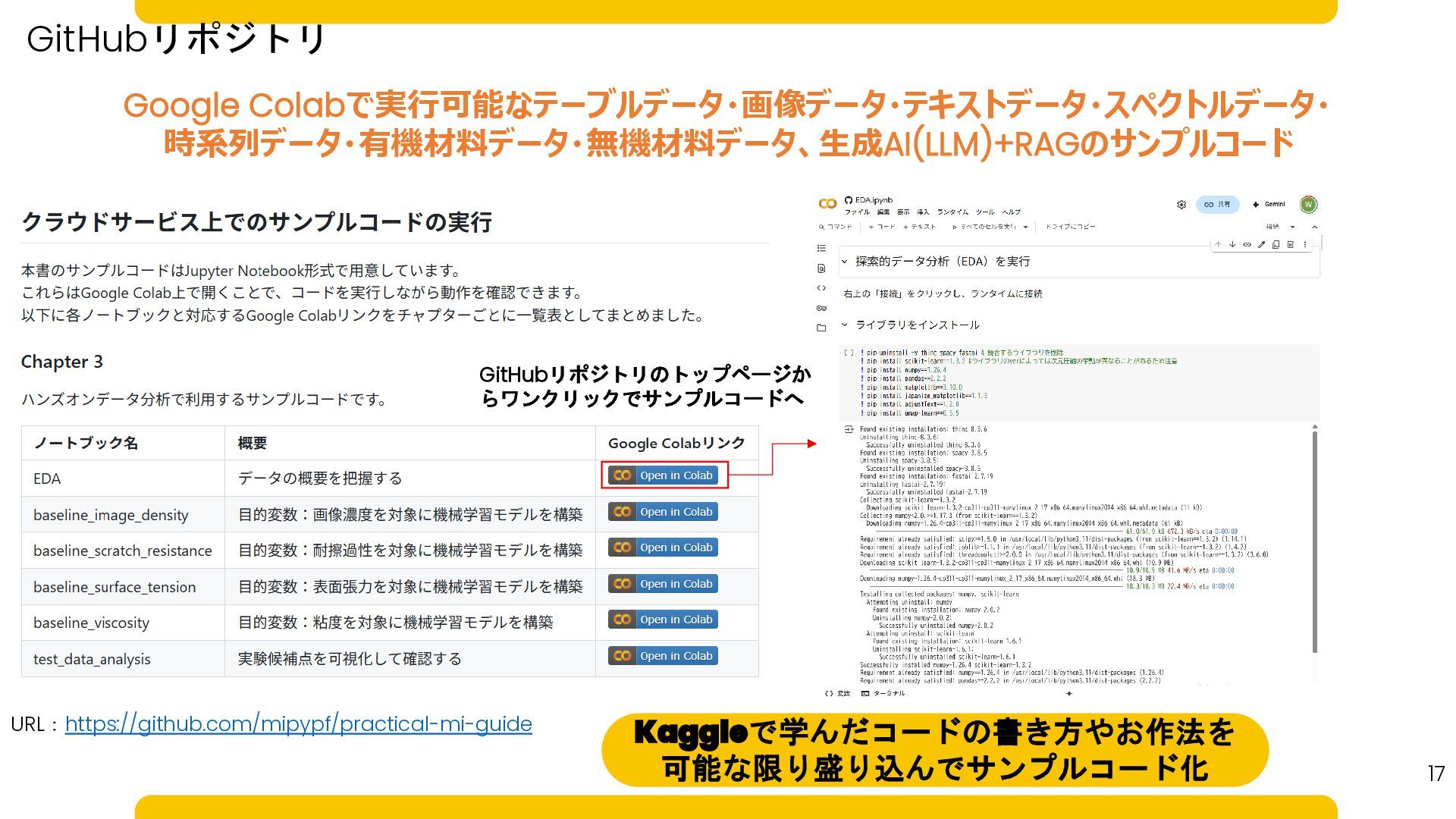
17 URL:https://github.com/mipypf/practical-mi-guide GitHubリポジトリのトップページか らワンクリックでサンプルコードへ Kaggleで学んだコードの書き方やお作法を 可能な限り盛り込んでサンプルコード化 GitHubリポジトリ Google Colabで実行可能なテーブルデータ・画像データ・テキストデータ・スペクトルデータ・ 時系列データ・有機材料データ・無機材料データ、生成AI(LLM)+RAGのサンプルコード
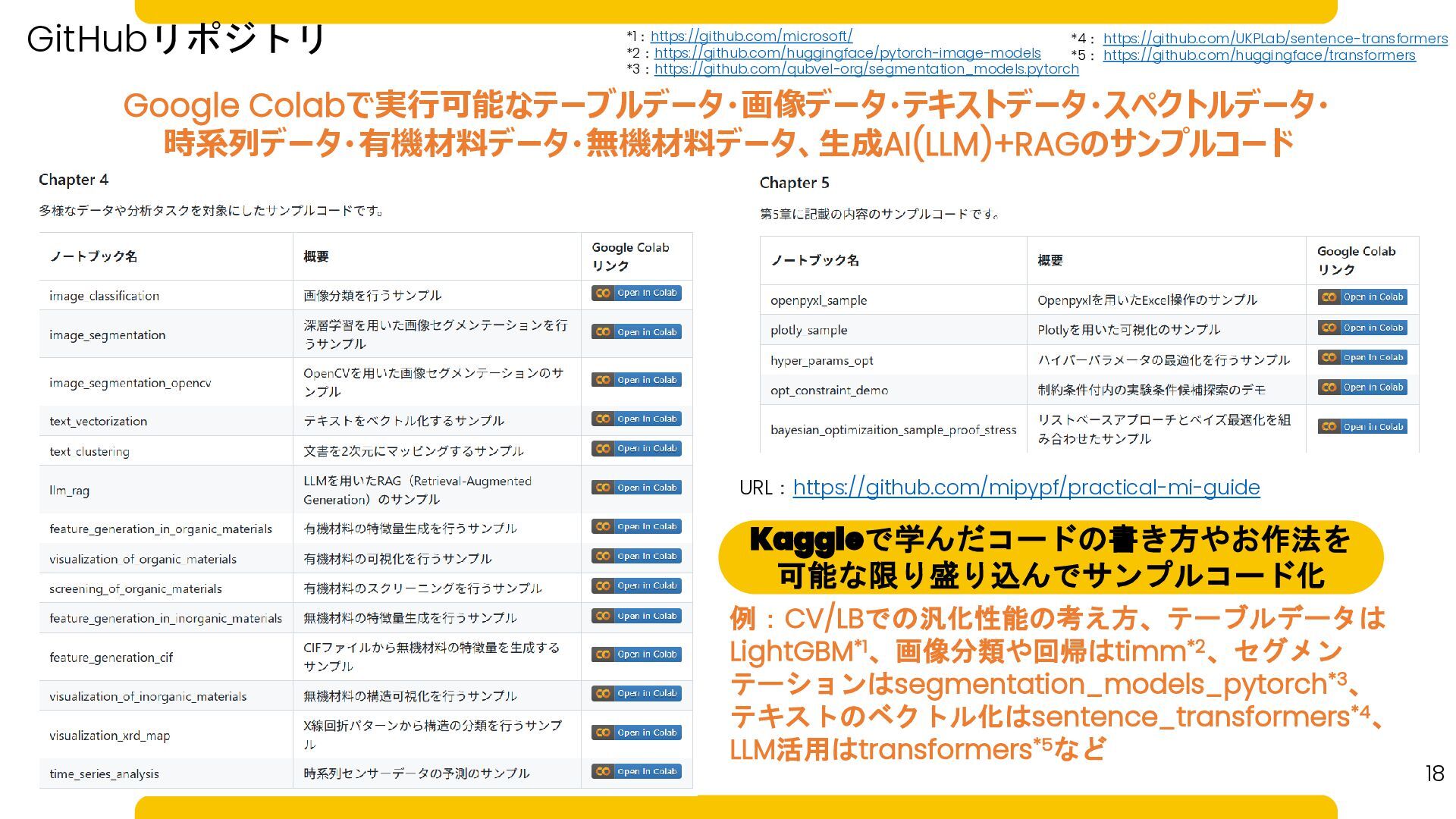
18 URL:https://github.com/mipypf/practical-mi-guide Kaggleで学んだコードの書き方やお作法を 可能な限り盛り込んでサンプルコード化 例:CV/LBでの汎化性能の考え方、テーブルデータは LightGBM*1、画像分類や回帰はtimm*2、セグメン テーションはsegmentation_models_pytorch*3、 テキストのベクトル化はsentence_transformers*4、 LLM活用はtransformers*5など GitHubリポジトリ
Google Colabで実行可能なテーブルデータ・画像データ・テキストデータ・スペクトルデータ・ 時系列データ・有機材料データ・無機材料データ、生成AI(LLM)+RAGのサンプルコード *1:https://github.com/microsoft/ *2:https://github.com/huggingface/pytorch-image-models *3:https://github.com/qubvel-org/segmentation_models.pytorch *4: https://github.com/UKPLab/sentence-transformers *5: https://github.com/huggingface/transformers
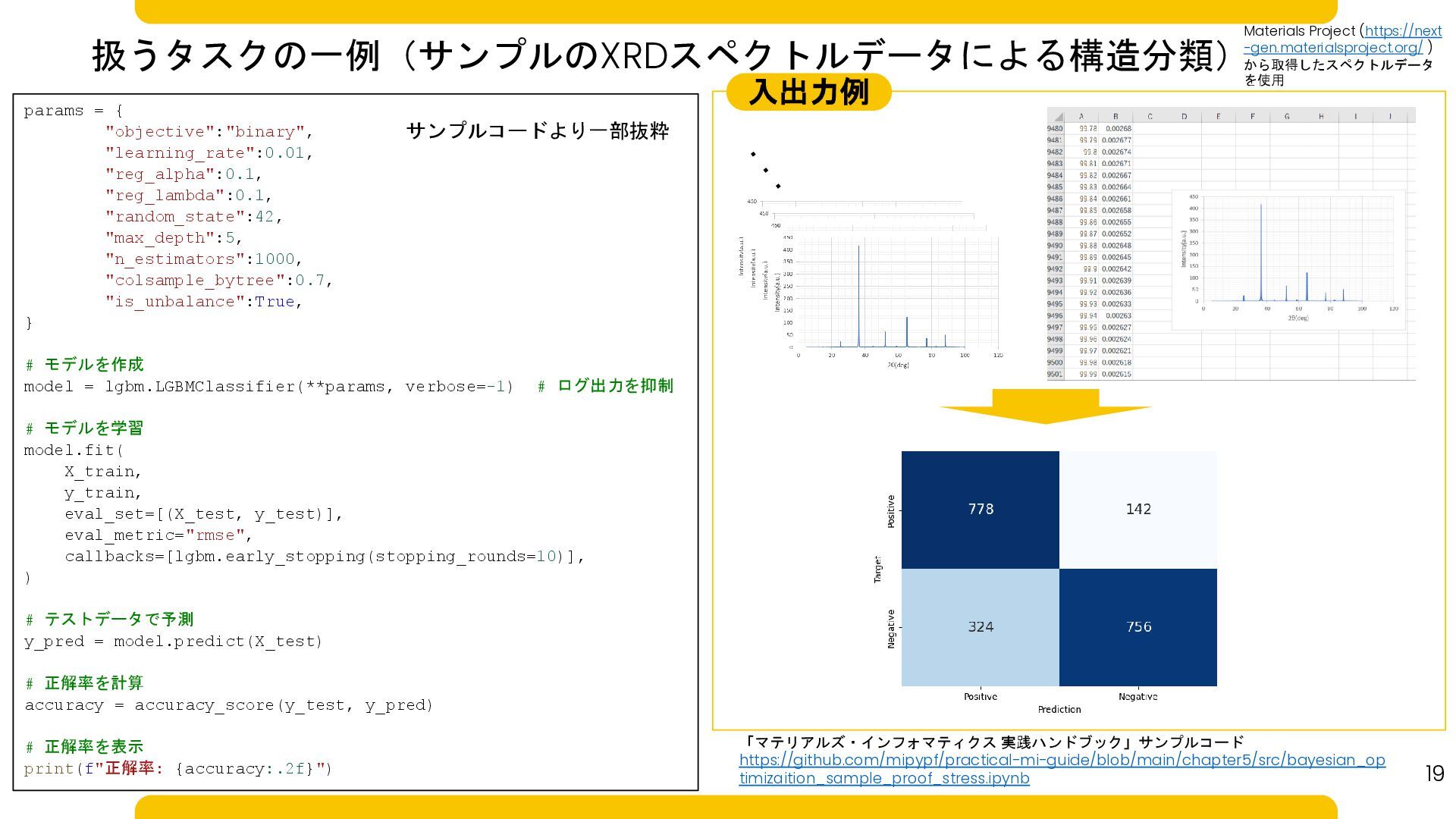
19 params = { "objective":"binary", "learning_rate":0.01, "reg_alpha":0.1, "reg_lambda":0.1, "random_state":42, "max_depth":5,
"n_estimators":1000, "colsample_bytree":0.7, "is_unbalance":True, } # モデルを作成 model = lgbm.LGBMClassifier(**params, verbose=-1) # ログ出力を抑制 # モデルを学習 model.fit( X_train, y_train, eval_set=[(X_test, y_test)], eval_metric="rmse", callbacks=[lgbm.early_stopping(stopping_rounds=10)], ) # テストデータで予測 y_pred = model.predict(X_test) # 正解率を計算 accuracy = accuracy_score(y_test, y_pred) # 正解率を表示 print(f"正解率: {accuracy:.2f}") 「マテリアルズ・インフォマティクス 実践ハンドブック」サンプルコード https://github.com/mipypf/practical-mi-guide/blob/main/chapter5/src/bayesian_op timizaition_sample_proof_stress.ipynb サンプルコードより一部抜粋 扱うタスクの一例(サンプルのXRDスペクトルデータによる構造分類) 入出力例 Materials Project (https://next -gen.materialsproject.org/ ) から取得したスペクトルデータ を使用
# データセットの作成 class ImageDataset(Dataset): def __init__(self, df, transform=None): self.df =
df self.transform = transform def __len__(self): return len(self.df) def __getitem__(self, idx): file_path = self.df["file_path"].values[idx] image = cv2.imread(file_path) image = cv2.cvtColor( image, cv2.COLOR_BGR2RGB ) # cv2.imreadで読み込んだ画像はBGRで読み込まれるため、RGBに変換する。p ilowで画像を読み込む場合は、変換の必要はない。 if self.transform: image = self.transform(image=image)["image"] label = self.df["label"].values[idx] return image, label 20 # モデルの作成 model = timm.create_model( "resnet18", pretrained=False, num_classes=1 ) # num_clases=1として2値分類を行うため、最終層の出力ユニット数を1に設定する。 model = model.to(device) # 損失関数の設定 criterion = nn.BCEWithLogitsLoss() # オプティマイザの設定 optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4) 扱うタスクの一例(サンプルのSEM画像データによる画像分類) サンプルコードより一部抜粋 「マテリアルズ・インフォマティクス 実践ハンドブック」サンプルコード https://github.com/mipypf/practical-mi-guide/blob/main/chapter4/src/image_ classification.ipynb サンプルコードより一部抜粋 入出力例 データセットの参考文献 - https://b2share.eudat.eu/records/80df 8606fcdb4b2bae1656f0dc6db8ba
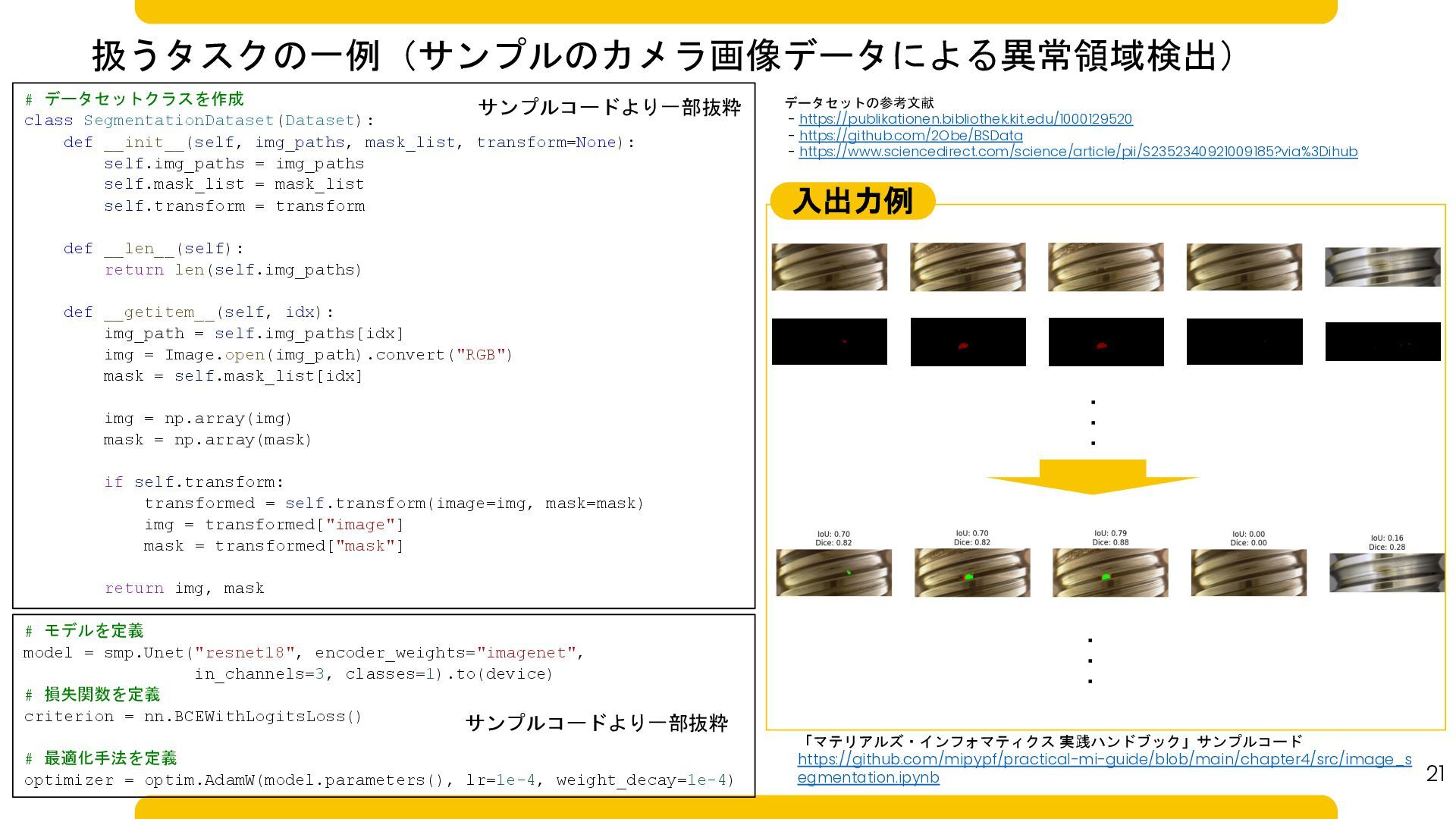
21 扱うタスクの一例(サンプルのカメラ画像データによる異常領域検出) # モデルを定義 model = smp.Unet("resnet18", encoder_weights="imagenet", in_channels=3, classes=1).to(device)
# 損失関数を定義 criterion = nn.BCEWithLogitsLoss() # 最適化手法を定義 optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4) サンプルコードより一部抜粋 ・・・ ・・・ 「マテリアルズ・インフォマティクス 実践ハンドブック」サンプルコード https://github.com/mipypf/practical-mi-guide/blob/main/chapter4/src/image_s egmentation.ipynb # データセットクラスを作成 class SegmentationDataset(Dataset): def __init__(self, img_paths, mask_list, transform=None): self.img_paths = img_paths self.mask_list = mask_list self.transform = transform def __len__(self): return len(self.img_paths) def __getitem__(self, idx): img_path = self.img_paths[idx] img = Image.open(img_path).convert("RGB") mask = self.mask_list[idx] img = np.array(img) mask = np.array(mask) if self.transform: transformed = self.transform(image=img, mask=mask) img = transformed["image"] mask = transformed["mask"] return img, mask サンプルコードより一部抜粋 データセットの参考文献 - https://publikationen.bibliothek.kit.edu/1000129520 - https://github.com/2Obe/BSData - https://www.sciencedirect.com/science/article/pii/S2352340921009185?via%3Dihub 入出力例
22 扱うタスクの一例(ドキュメントデータによるLLM+RAGでの質問回答) # SentenceTransformerを使用して埋め込みを生成 embedding_model = SentenceTransformer("hotchpotch/static-embedding-japanese") embeddings = embedding_model.encode(documents,
convert_to_tensor=False) # FAISSインデックスを作成 d = embeddings[0].shape[0] # 埋め込みの次元 index = faiss.IndexFlatL2(d) index.add(np.array(embeddings)) tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b-jpn-it") model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b-jpn-it", device_map="auto",torch_dtype=torch.bfloat16) # テキスト生成パイプラインを設定 text_gen_pipeline = pipeline("text-generation", model=model, tokenizer=tokenizer) def ask_question(question): # 質問を埋め込みに変換 question_embedding = embedding_model.encode([question], convert_to_tensor=False) # FAISSで最も近いチャンクを検索 _, indices = index.search(np.array(question_embedding), k=1) retrieved_text = documents[indices[0][0]] # 質問と関連情報、回答の間に改行を追加 input_text = f"質問: {question}¥n¥n関連情報: {retrieved_text}¥n¥n回答: “ # パイプラインを使用して回答を生成 outputs = text_gen_pipeline(input_text, max_new_tokens=256) # リストから文字列を取得 assistant_response = outputs[0]["generated_text"].strip() return assistant_response サンプルコードより一部抜粋 「マテリアルズ・インフォマティクス 実践ハンドブック」サンプルコード https://github.com/mipypf/practical-mi-guide/blob/main/chapter4/ src/llm_rag.ipynb 入出力例 質問: MIとは何ですか? 回答: MI(Materials Informatics)とは、材料の特性や性能を 分析し、設計・開発を効率化するための、材料科学とデー タ分析の融合技術です。 簡単に言うと: 材料のデータを集めて分析し、より良い材料の開発を支援 する技術です。 材料の特性や性能を数値化し、設計段階で最適な材料を選 択できるようになります。 MIのメリット: 材料開発のスピードアップ: 大量のデータから、最適な材料 を見つけることができます。 コスト削減: 設計段階で失敗を減らし、無駄な材料や工程を 削減できます。 材料の性能向上: データ分析によって、材料の性能を向上さ せるための設計が可能になります。
Kagglerの皆さまに色々なアドバイスや叱咤激励をいただき、なんとか出 版までこぎつけました。(書籍の謝辞にも入れさせていただきました ) ありがとうございました! Kaggleは執筆にも役立つ! URL:https://www.morikita.co.jp/books/mid/085841 おわりに 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}