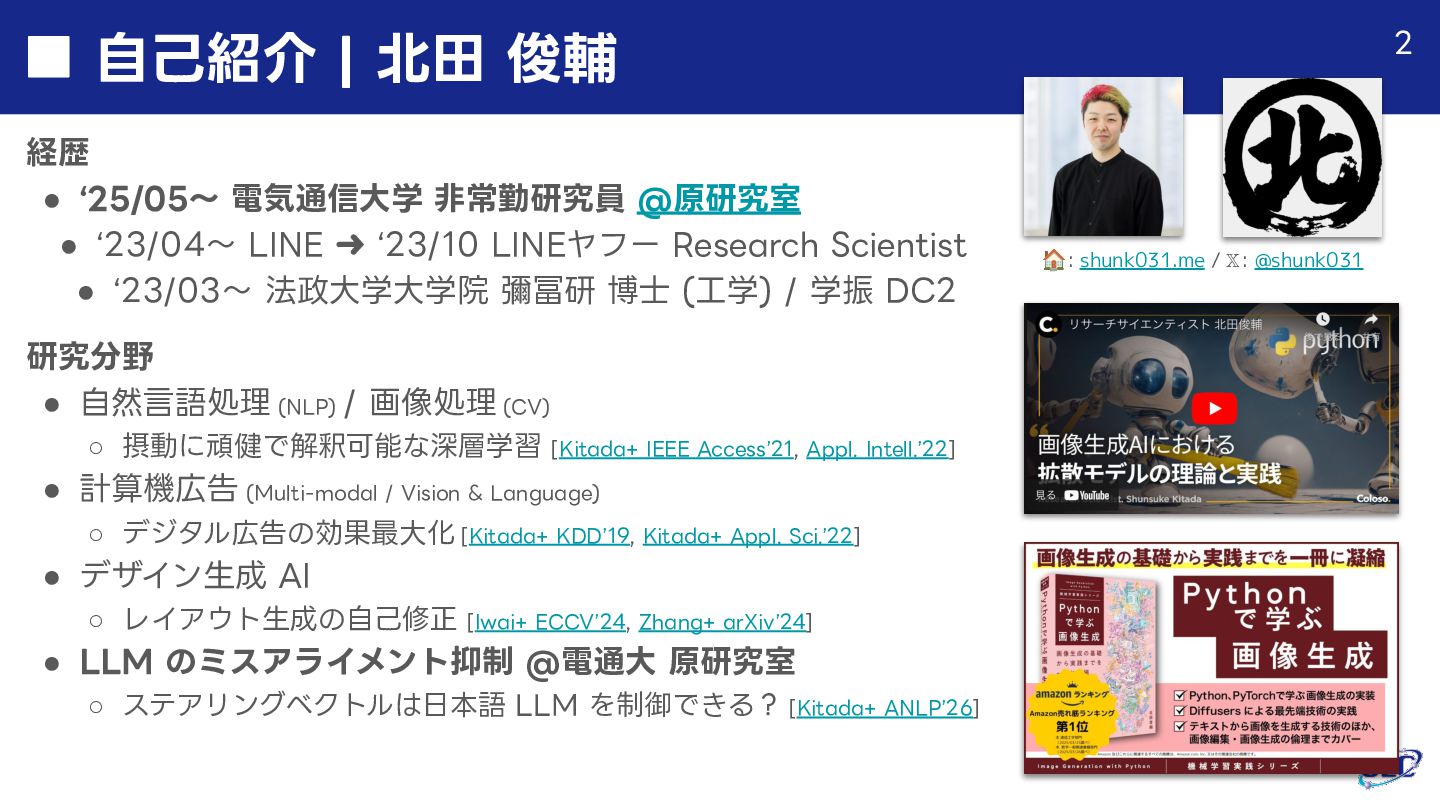
大規模言語モデル(LLM)に対する内部介入(steering / intervention)は、重み更新を伴わずに推論時の振る舞いを制御できる手法として、近年急速に注目を集めています。本発表では、この軽量かつ柔軟な制御パラダイムの可能性と限界について、言語処理学会 2026 における関連研究を体系的に整理しながら概観します。特に、北田+「ステアリングベクトルは日本語LLMを堅牢に制御できるか?」を中心に、評価・安全性・多言語制御・表現学習といった観点から、内部介入がどこまで信頼できる制御として機能するのかを議論します。
■【Sansan × IVRy】NLP2026 参加報告会
https://sansan.connpass.com/event/388590/
■ 登壇概要
タイトル:その LLM 制御、本当に信頼できますか?
■ 言語処理学会第32回年次大会(NLP2026)
https://www.anlp.jp/nlp2026/
■ 北田+ "ステアリングベクトルは日本語 LLM を堅牢に制御できるか?"
https://www.anlp.jp/proceedings/annual_meeting/2026/pdf_dir/B1-13.pdf
![その LLM 制御、 本当に信頼できますか? 北⽥ 俊輔 電気通信⼤学 原研究室 [email protected] 【Sansan×](https://files.speakerdeck.com/presentations/844c7498cae448b29cf2272408322fec/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![本発表者の 北⽥ が関わった NLPʼ26 の研究 B1-13 [北⽥+ら]: ⽇本語 LLM で差分ベクトル介⼊は安定か?](https://files.speakerdeck.com/presentations/844c7498cae448b29cf2272408322fec/slide_4.jpg){kind=link}
![LLM の安全性を直接良くする研究 B2-17 [⾨⾕+]: もっともらしい誤答を減らす • 嘘をつきやすい⽅向を打ち消し、事実寄りの内部表現へ動かす • 2 つのモデルを同時に回す](https://files.speakerdeck.com/presentations/844c7498cae448b29cf2272408322fec/slide_5.jpg){kind=link}
![LLM の出⼒や推論を制御する研究 B4-6 [⾵間+ら]: 途中の考え⽅をよくする • 最終答えではなく、途中の reasoning の軌道をよい領域へ寄せる •](https://files.speakerdeck.com/presentations/844c7498cae448b29cf2272408322fec/slide_6.jpg){kind=link}
![LLM の知識介⼊・編集とその限界 B6-19 [⽯垣+]: 知識編集は積み重ねると崩れやすい • ⼀つの編集が次の編集に⼲渉し、既編集知識と未編集知識の保持が難しくなる • しかもグラフ上の次数や距離だけでは説明しきれない B9-8](https://files.speakerdeck.com/presentations/844c7498cae448b29cf2272408322fec/slide_7.jpg){kind=link}
![結論 全体の結論 • 研究の焦点は「介⼊を作る」から 「介⼊が壊れにくいことを⽰す」に 移⾏しつつある 発表者の北⽥らの研究の位置づけ • B1-13 [北⽥+]](https://files.speakerdeck.com/presentations/844c7498cae448b29cf2272408322fec/slide_8.jpg){kind=link}