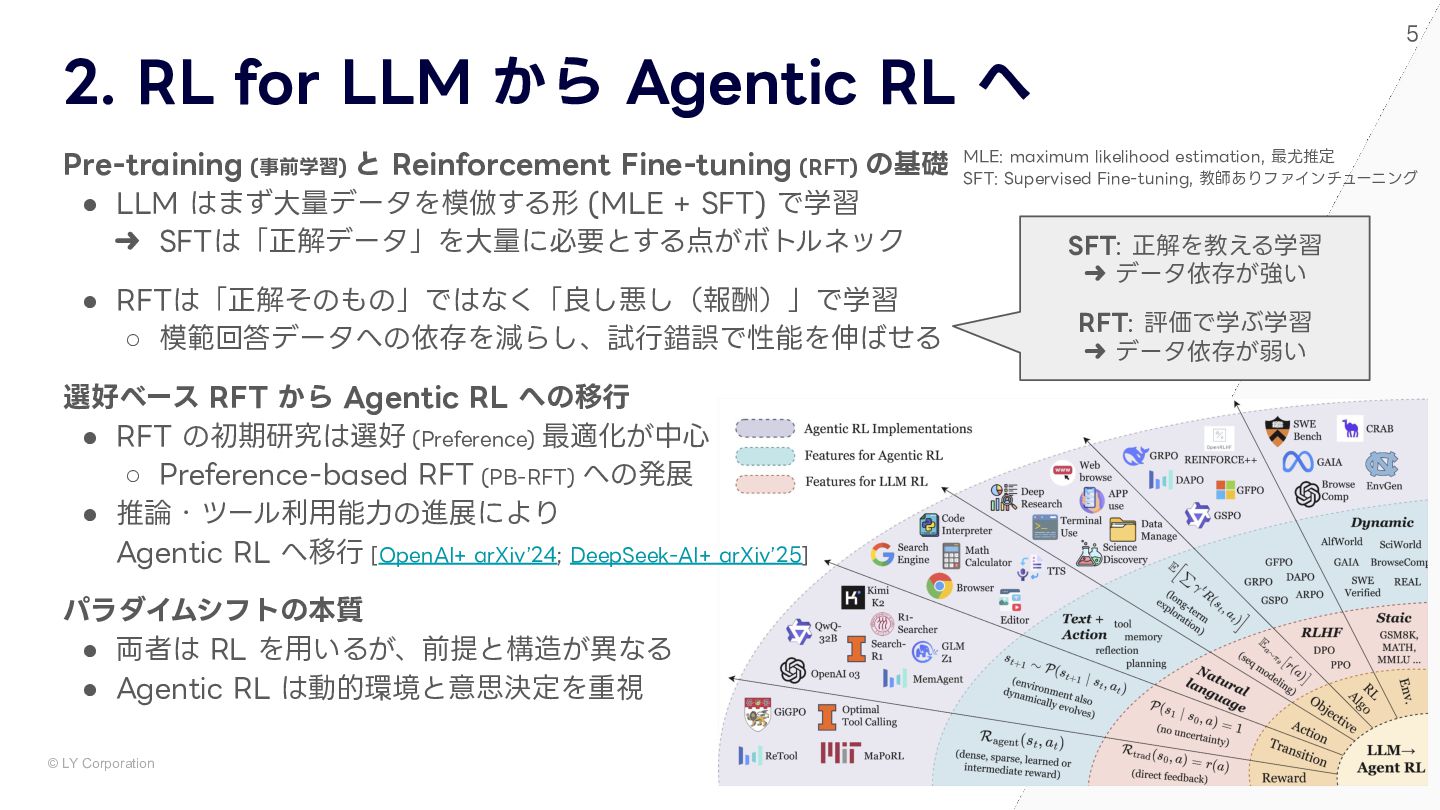
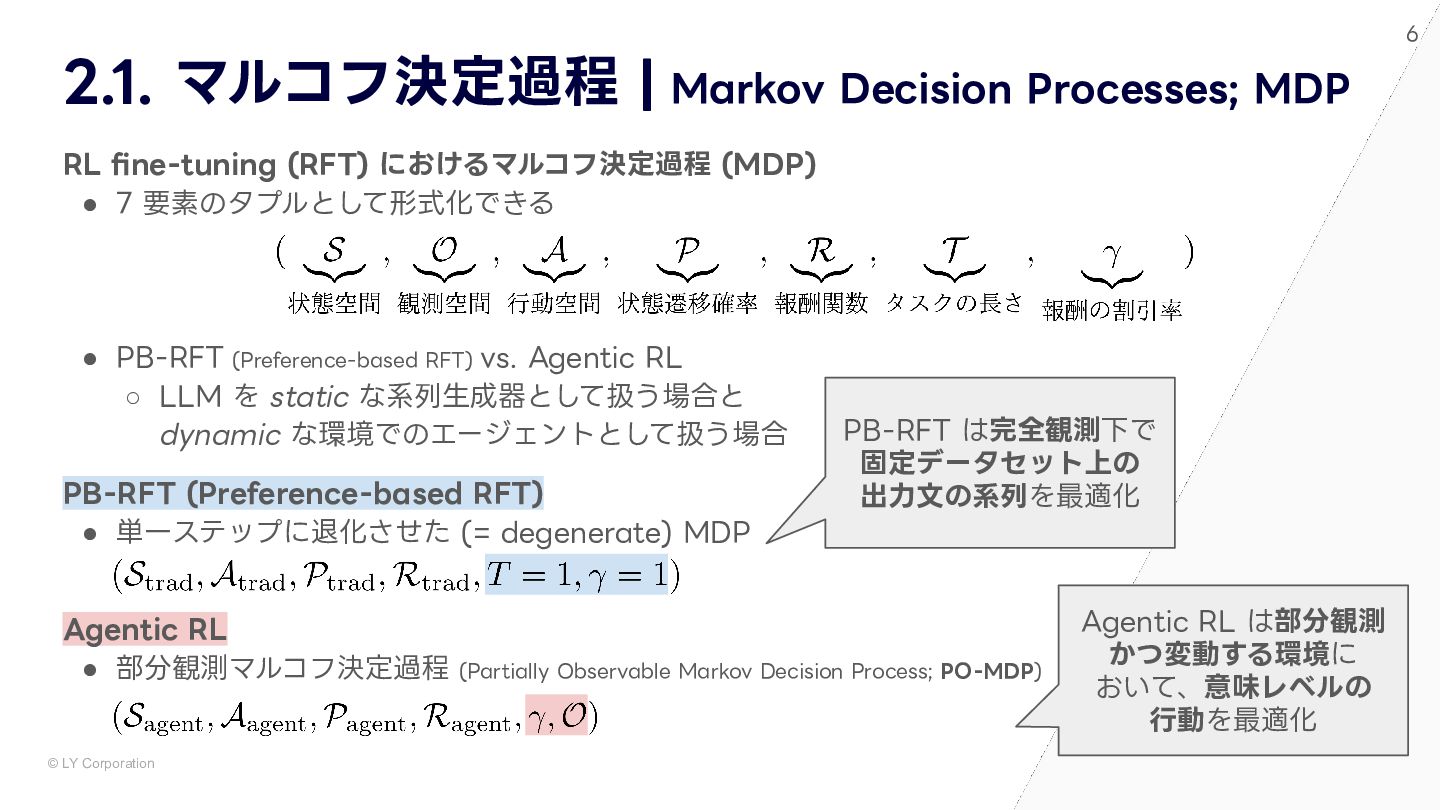
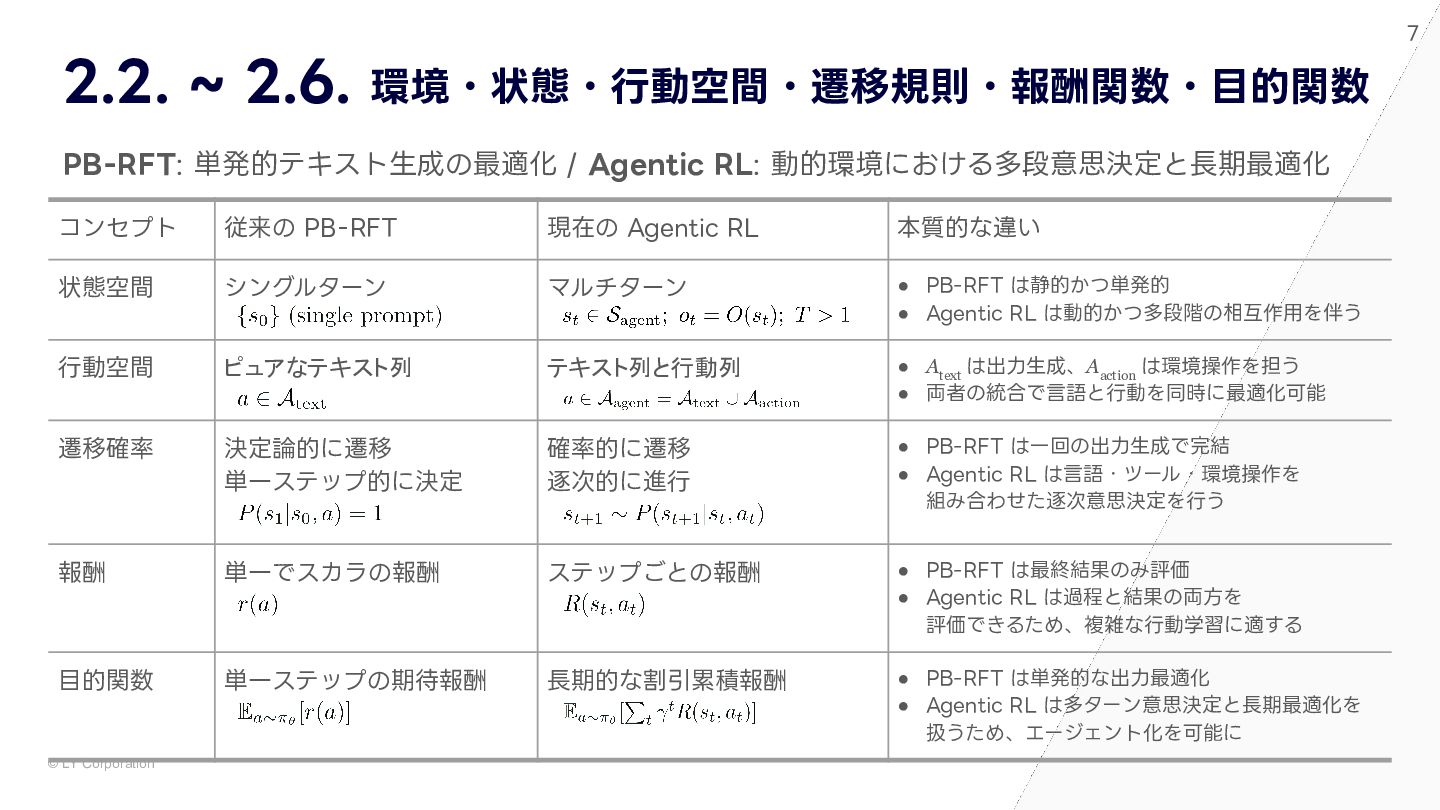
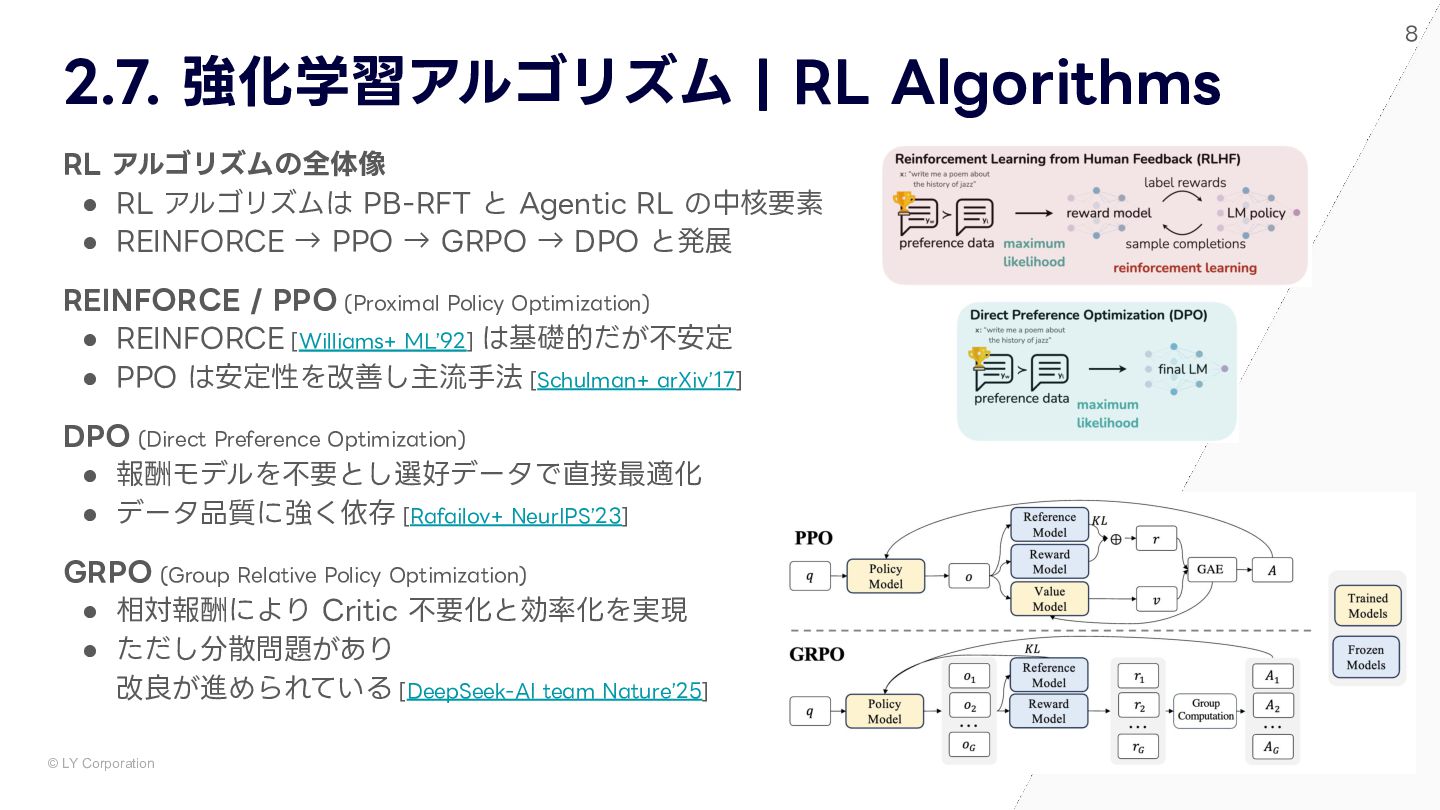
大規模言語モデル(LLM)に強化学習を組み合わせた「Agentic RL」は,自律的な意思決定や動的な環境適応能力により,人工知能の新たなフロンティアを切り開いています。本資料では,この急速に進化するAgentic RLの全体像を,最新の包括的サーベイ論文「Agentic Reinforcement Learning: A Survey(2025)」に基づき詳細に解説します。
- 📝:https://arxiv.org/abs/2509.02547
- 🐙:https://github.com/xhyumiracle/Awesome-AgenticLLM-RL-Papers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
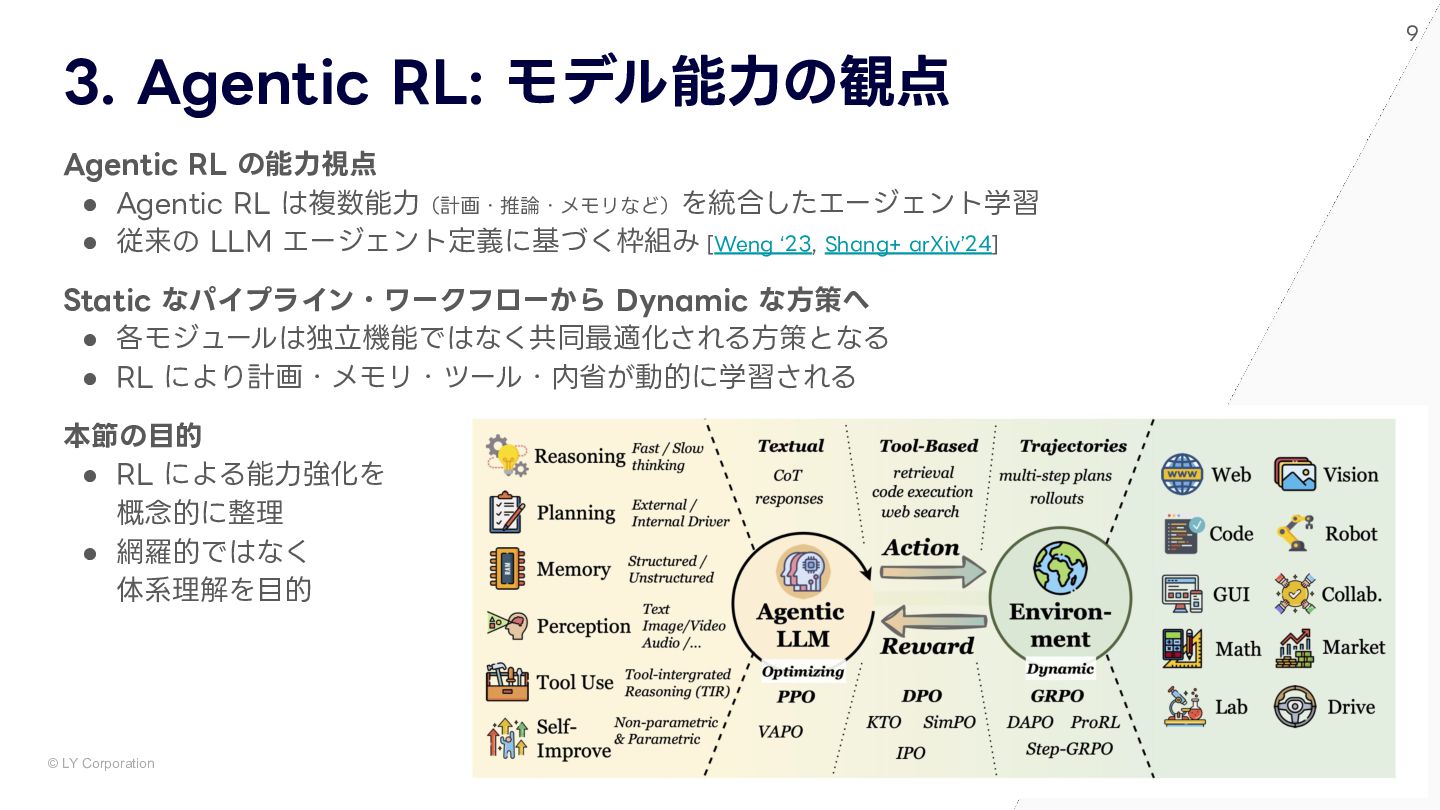{kind=link}
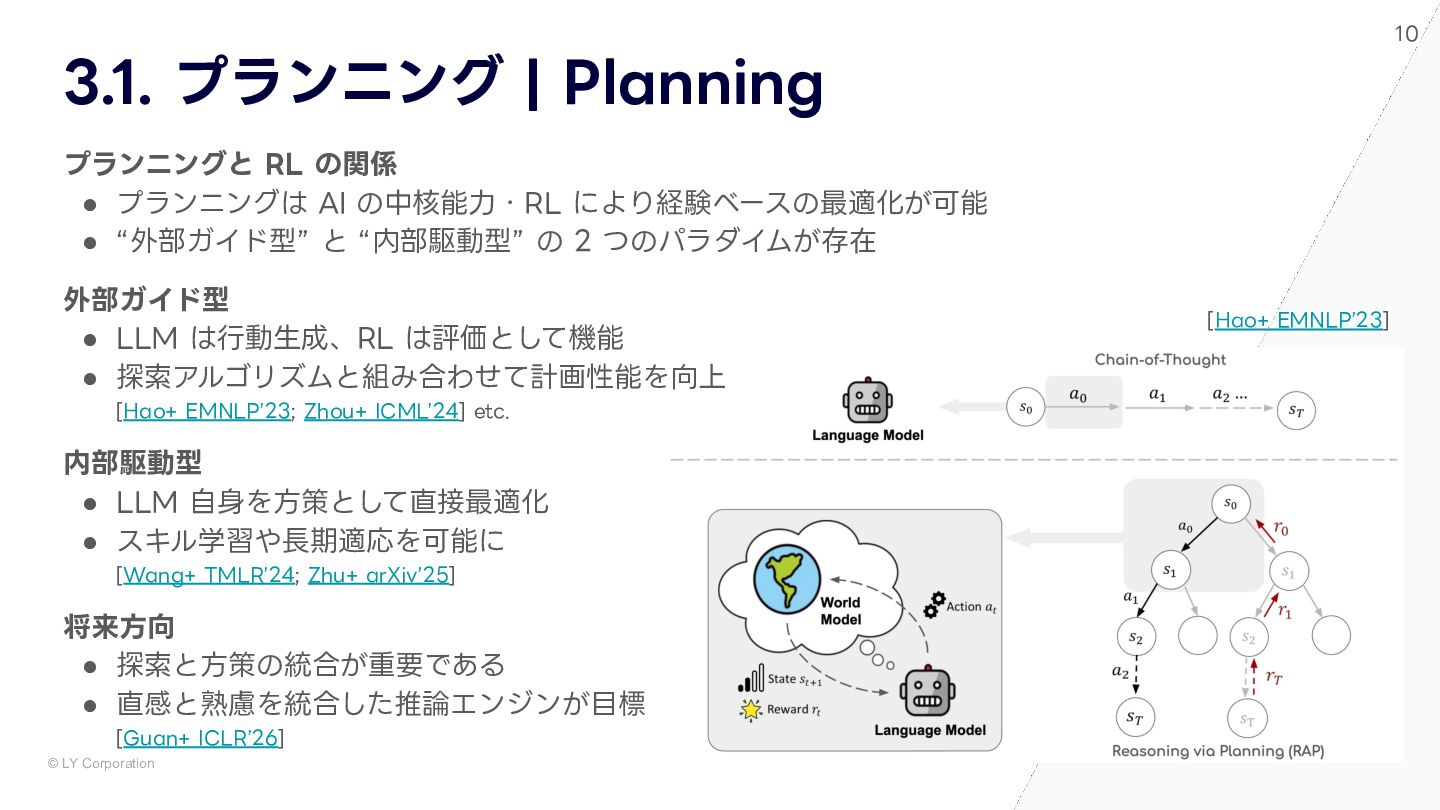{kind=link}
![© LY Corporation ツール利⽤の進化 • ツール利⽤は ReAct [Yao+ ICLRʼ23] から](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_10.jpg){kind=link}
![© LY Corporation メモリの進化: メモリは受動保存から能動制御へと進化 • RL により保存・検索・忘却を最適化 [Wu+ arXivʼ25]](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_11.jpg){kind=link}
![© LY Corporation Self-Improvementの全体像: RL は内省を通じた継続的⾃⼰改善の中核機構である • ⾃⼰⽣成フィードバックにより学習が進化する [Gao+ TMLRʼ26]](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_12.jpg){kind=link}
{kind=link}
![© LY Corporation [Liu+ ICCVʼ25] Perceptionの全体像 • Large Vision-Language Model](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_14.jpg){kind=link}
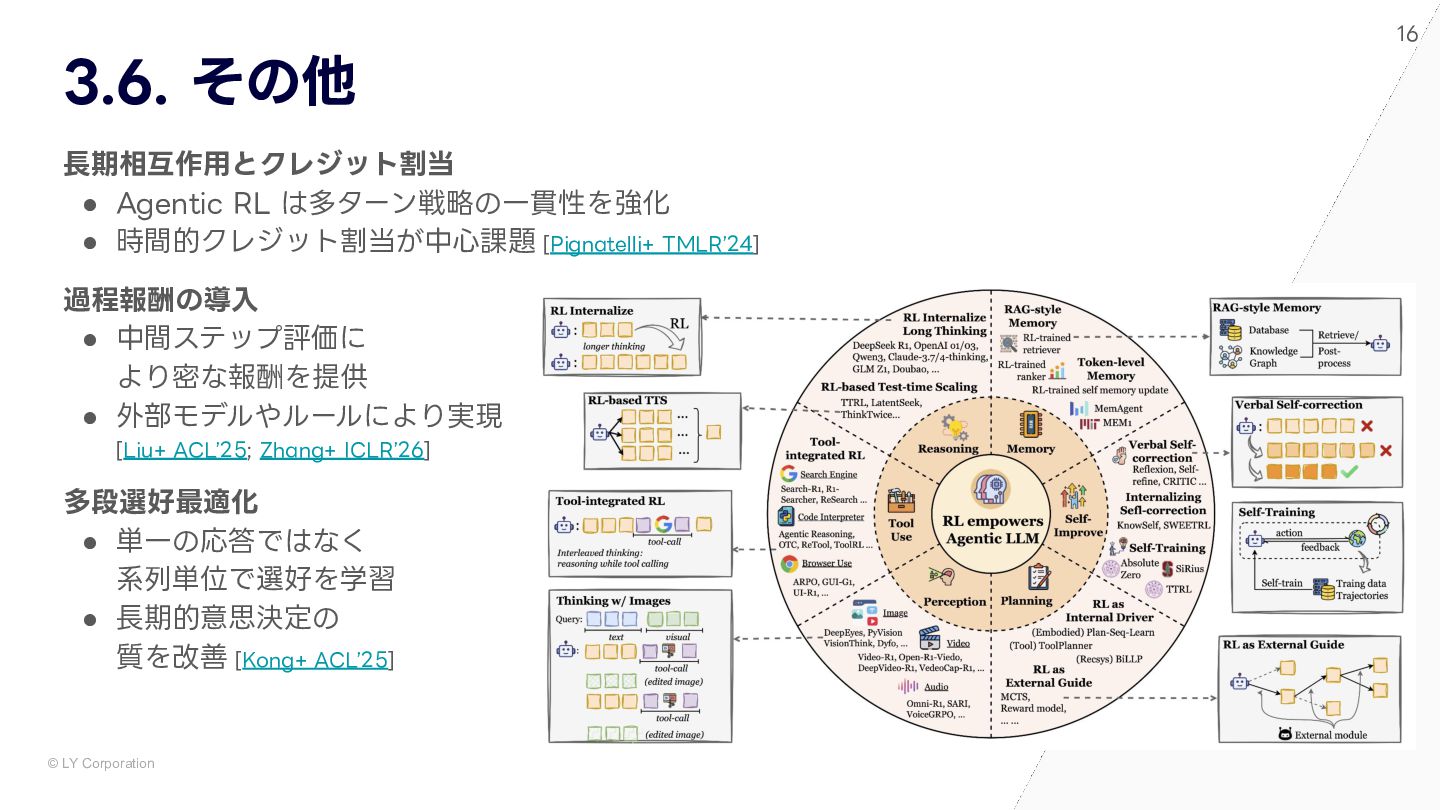{kind=link}
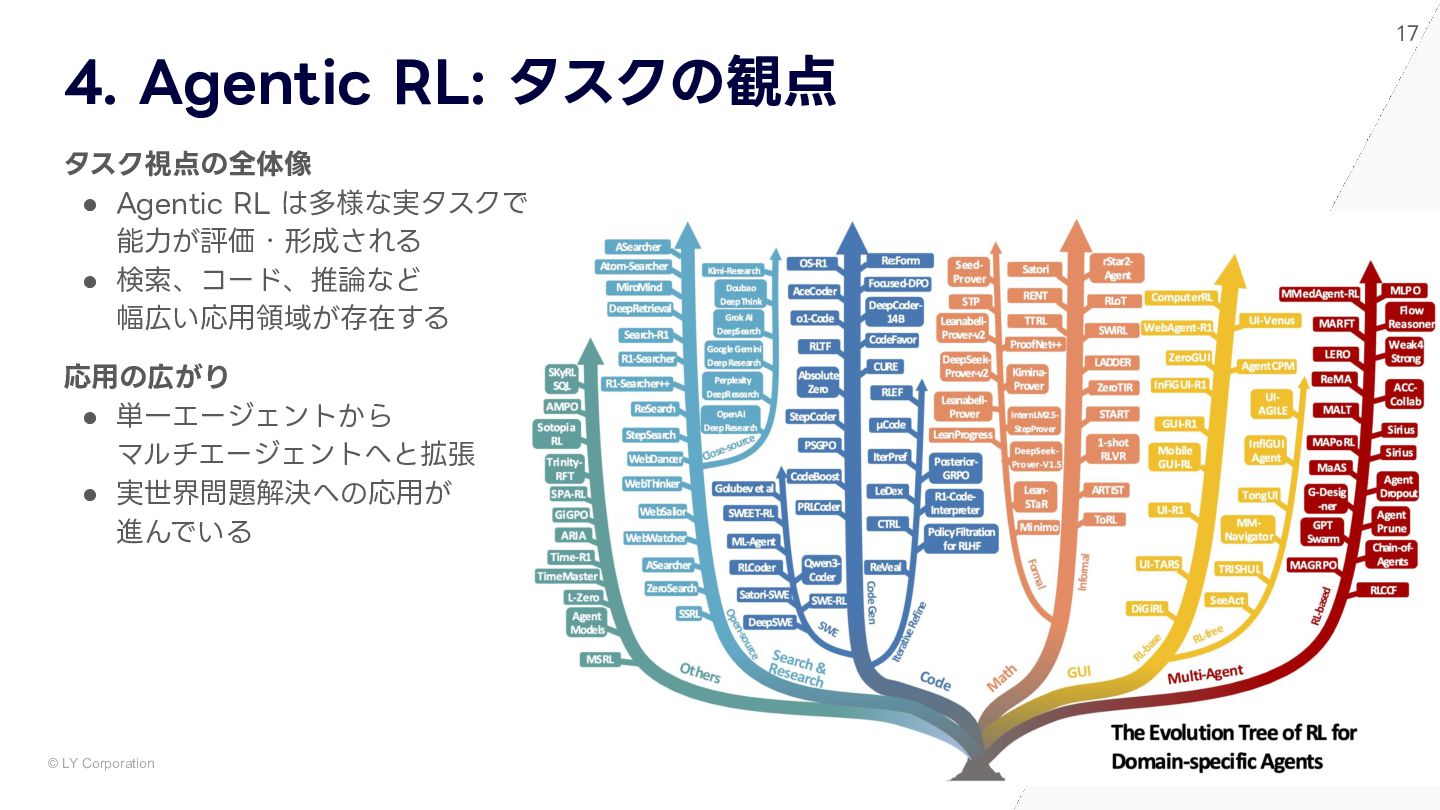{kind=link}
{kind=link}
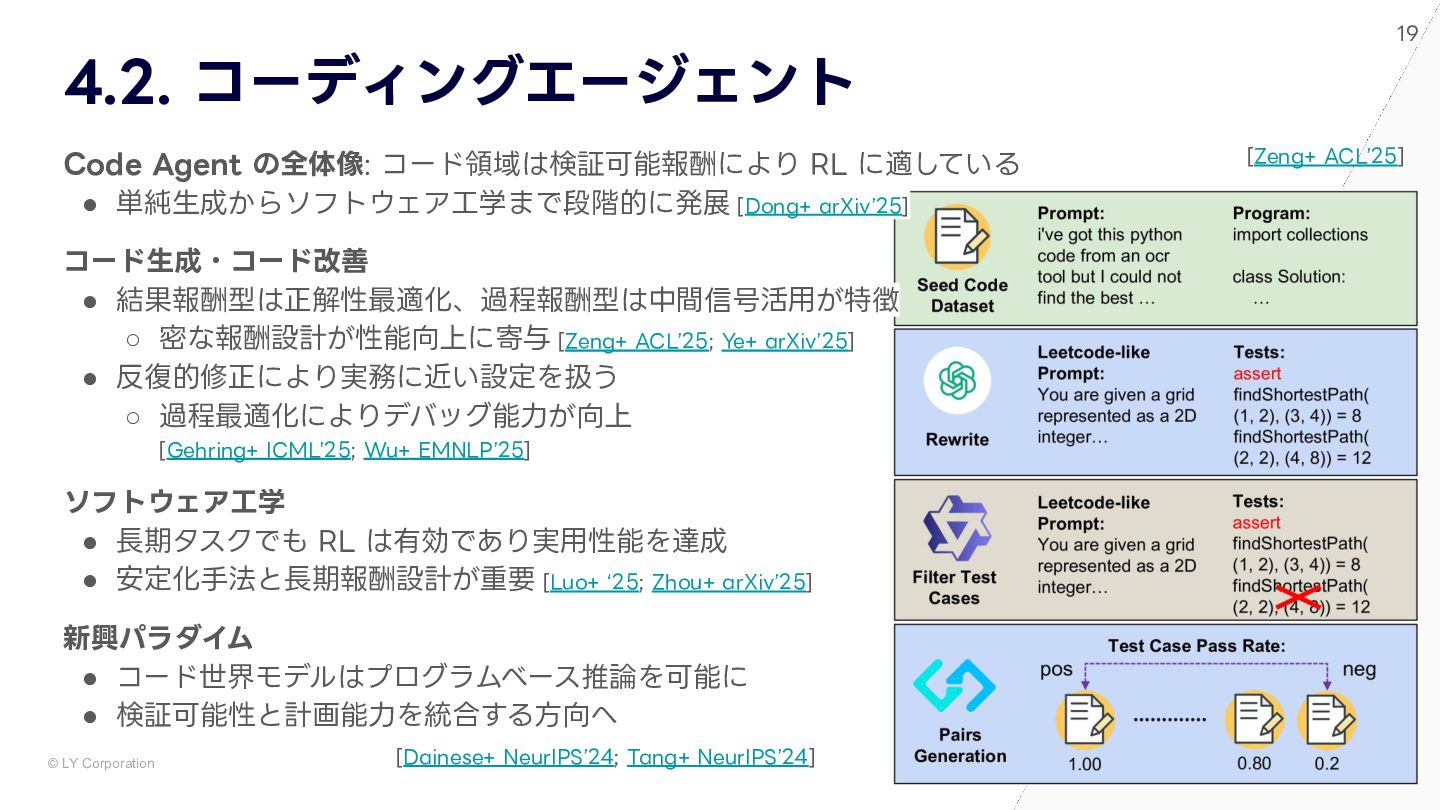{kind=link}
{kind=link}
{kind=link}
{kind=link}
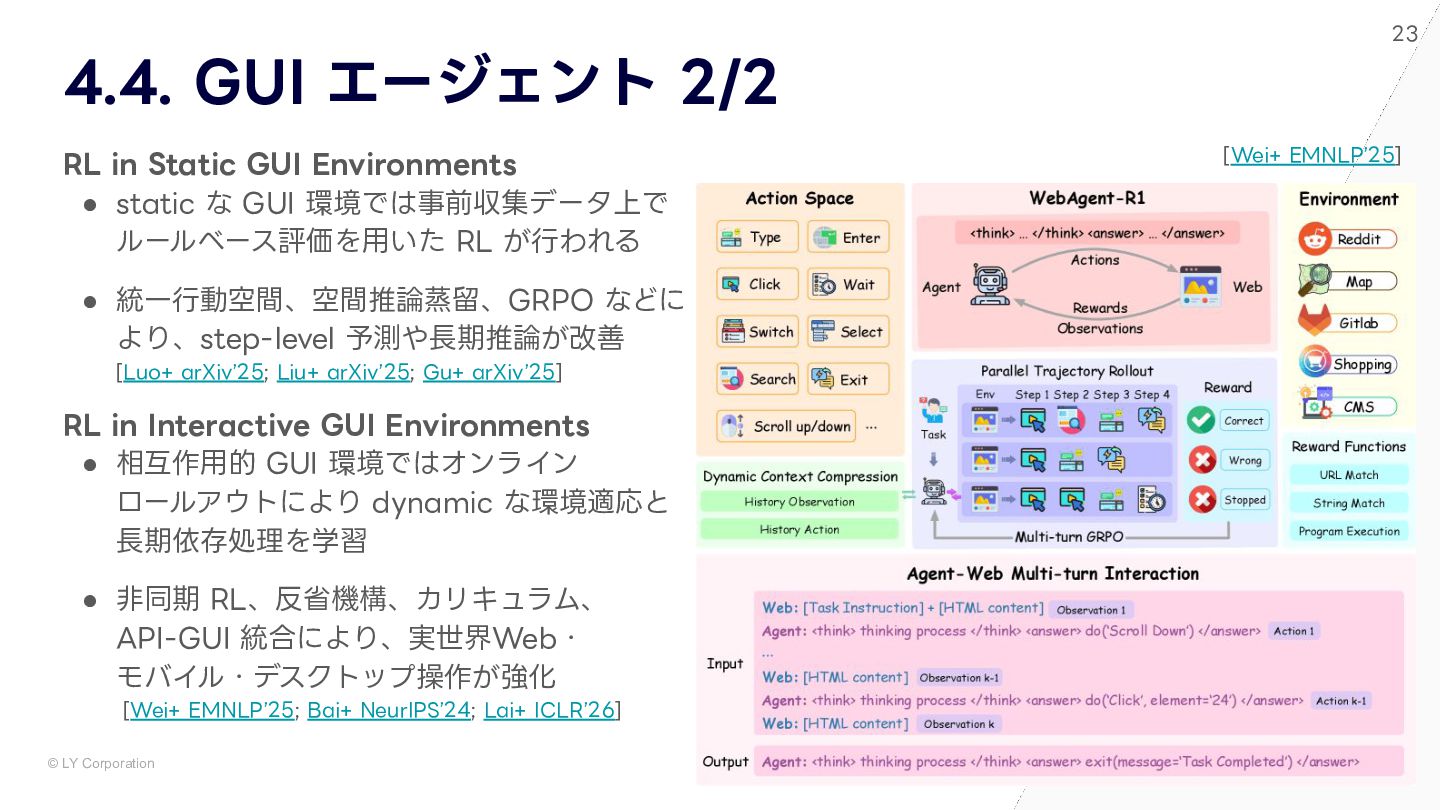{kind=link}
{kind=link}
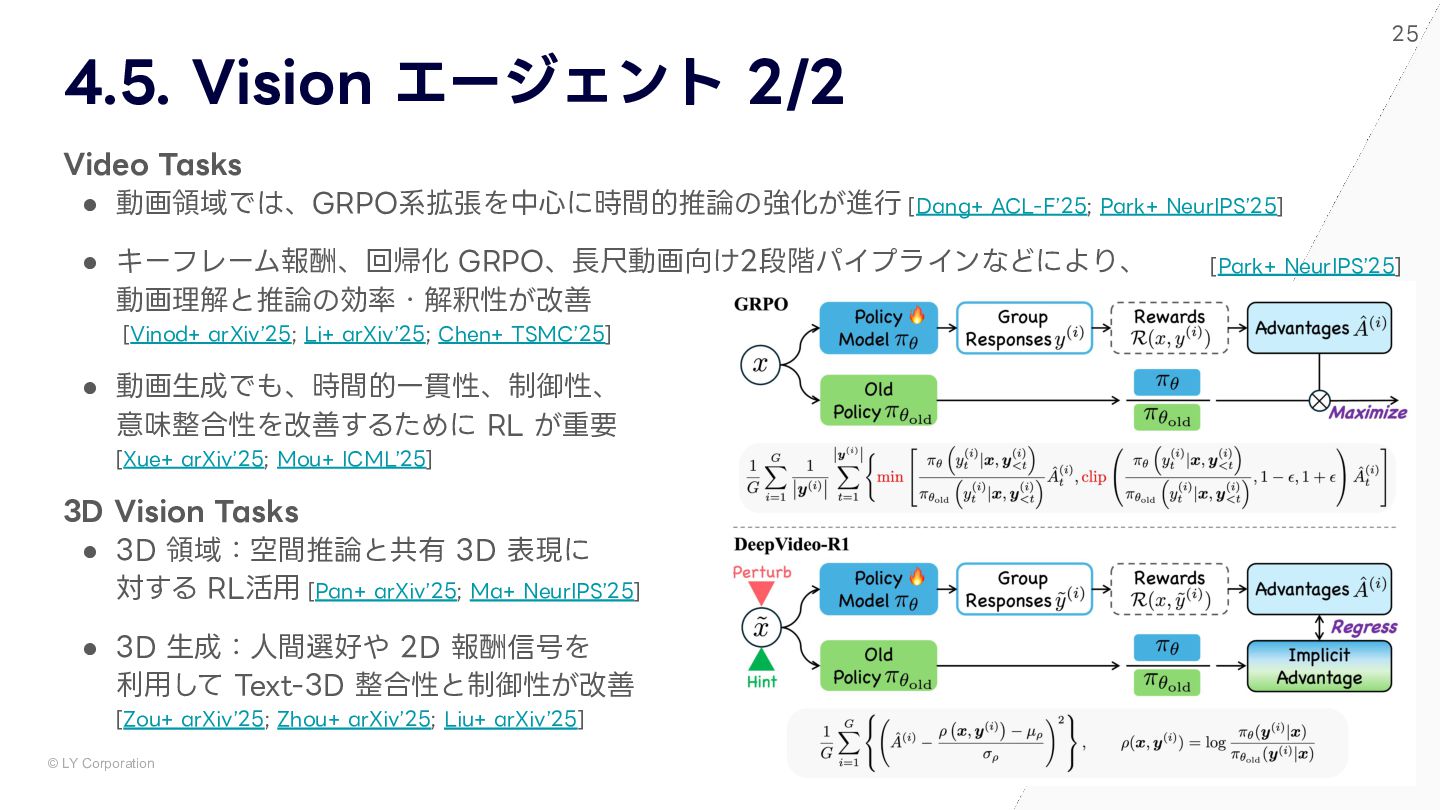{kind=link}
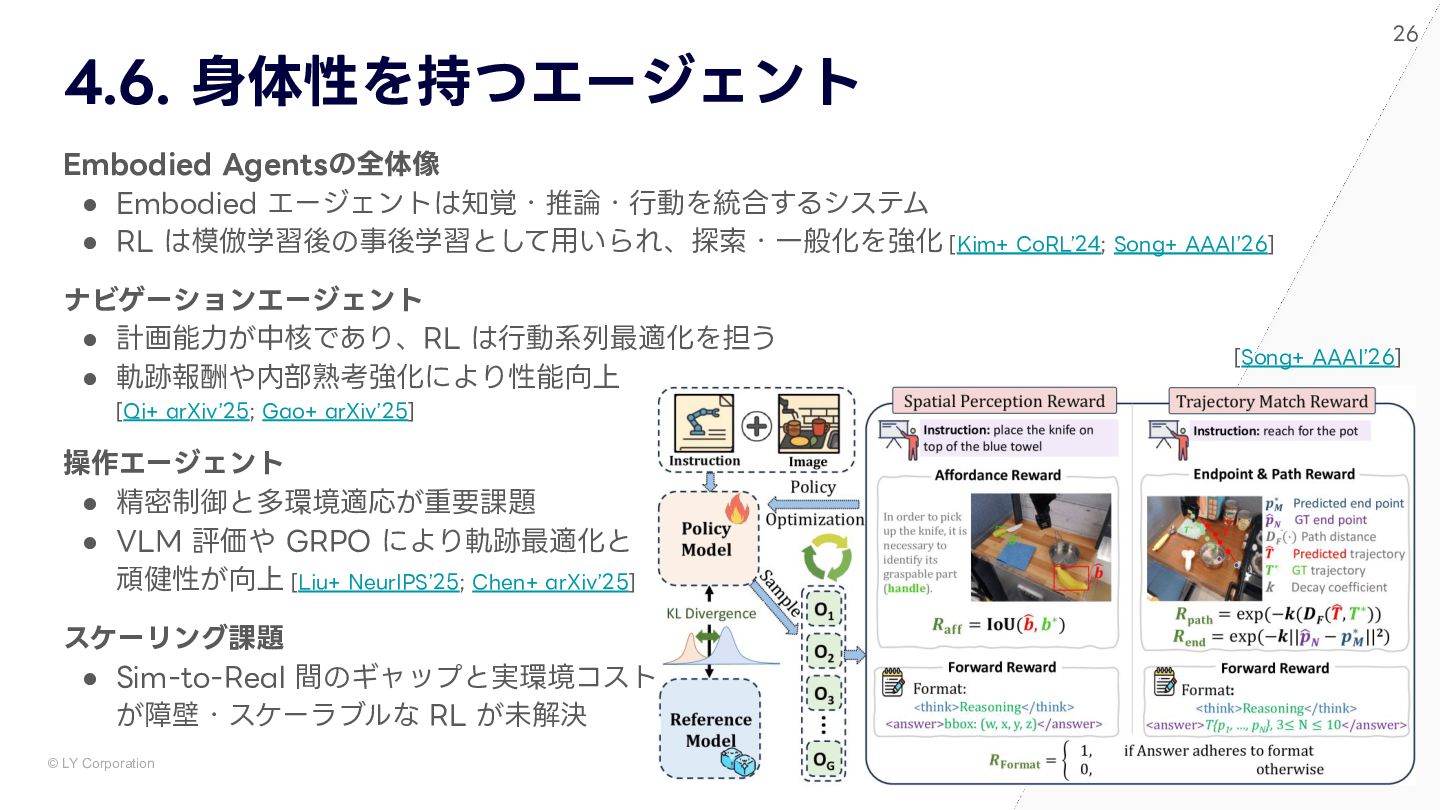{kind=link}
{kind=link}
![© LY Corporation TextGame • 報酬設計によりクレジット割当と学習安定性が改善 [Yang+ NeurIPSʼ25; Feng+ NeurIPSʼ25]](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_27.jpg){kind=link}
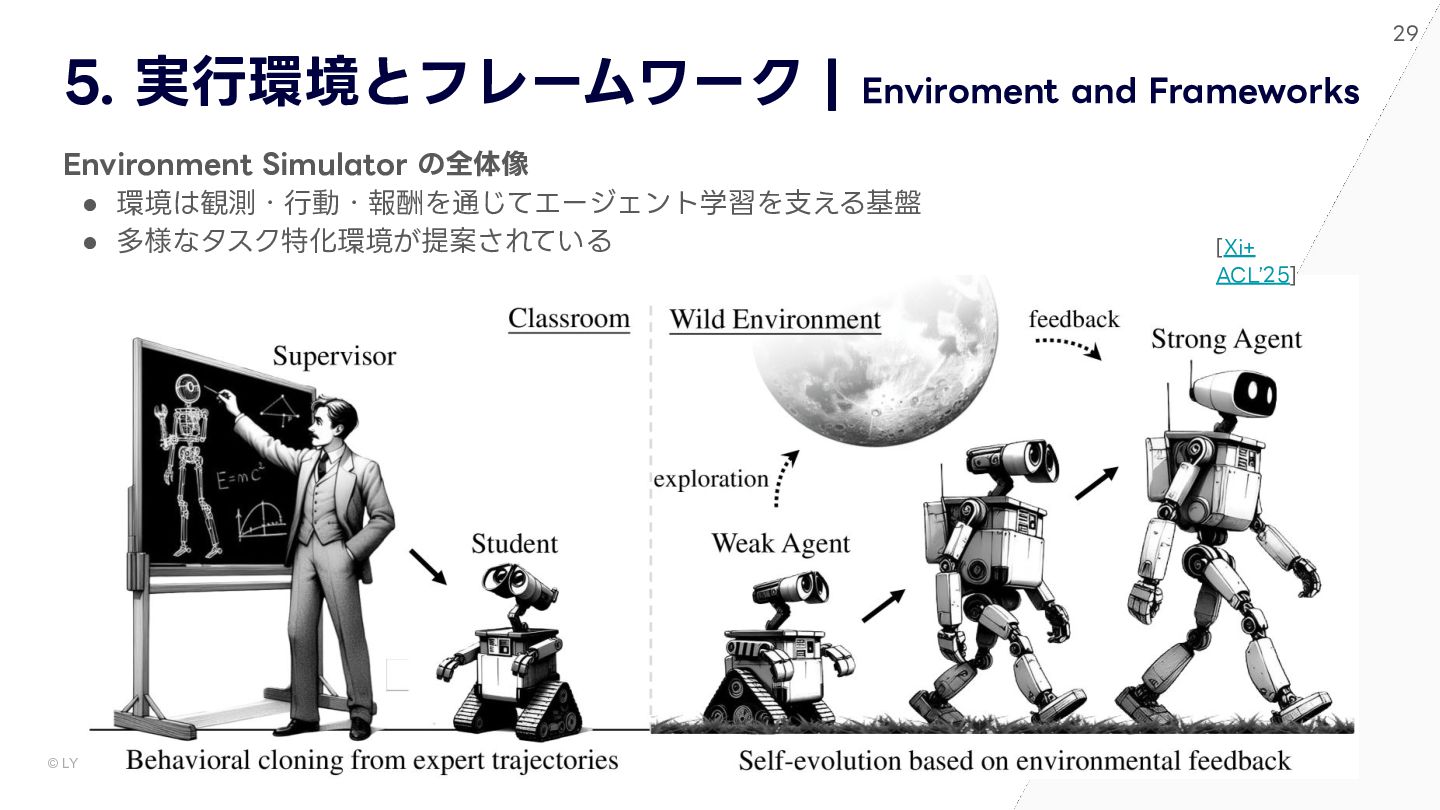{kind=link}
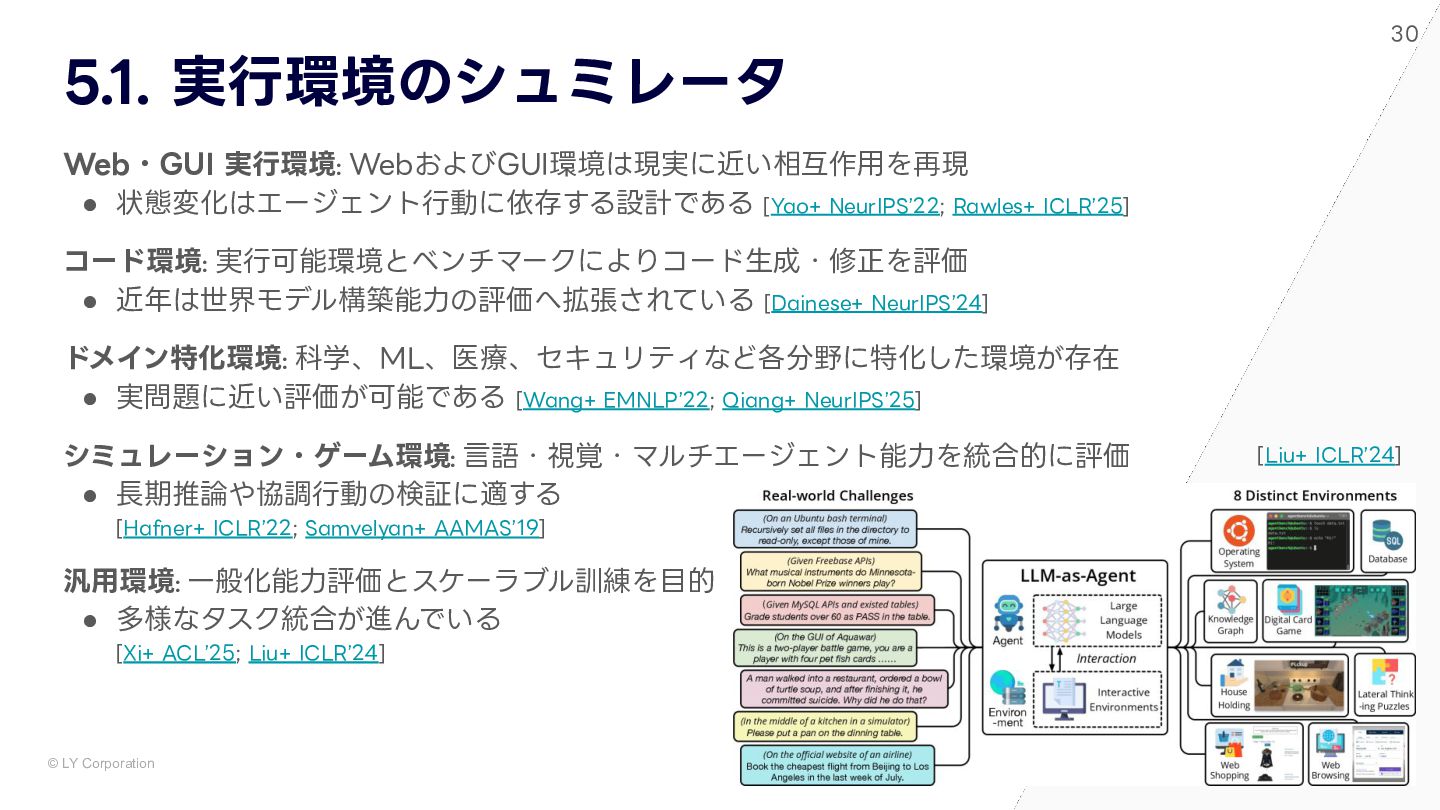{kind=link}
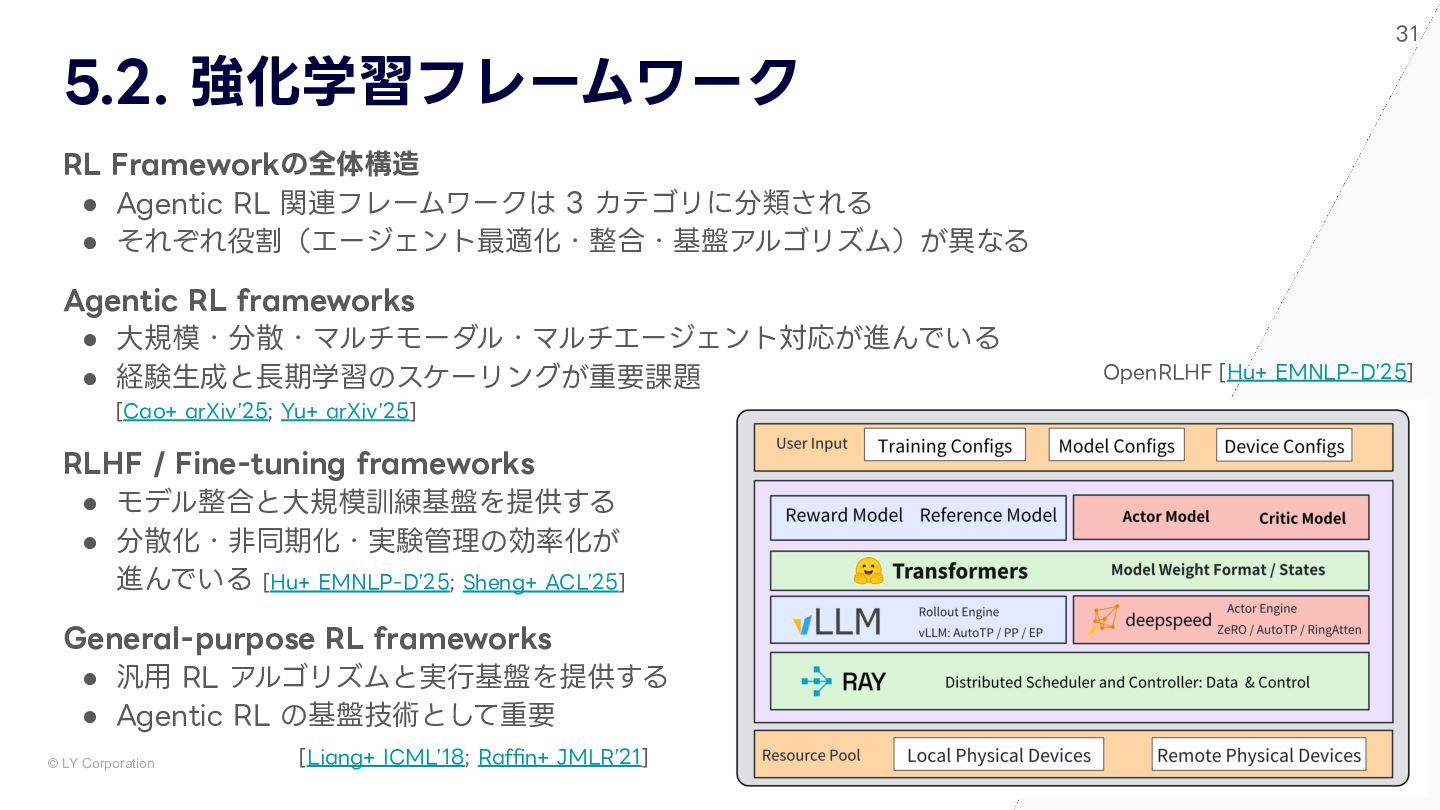{kind=link}
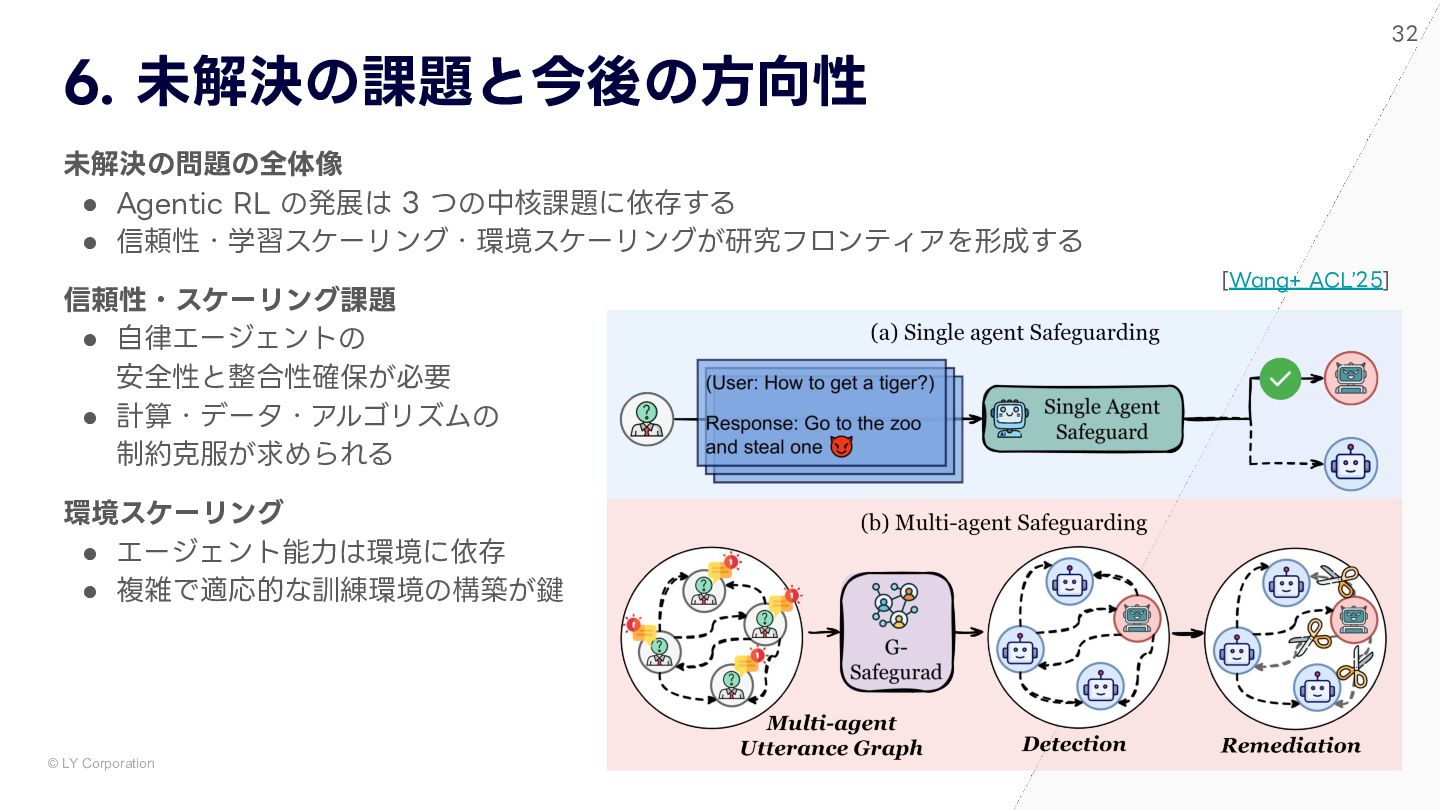{kind=link}
{kind=link}
{kind=link}
![© LY Corporation 環境スケーリングのパラダイム転換: 環境を静的から動的・最適化対象へと捉える転換 • 既存環境の限界を受け、エージェントと環境の共進化が重視 [Zheng+ arXivʼ25] 報酬設計の⾃動化:](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_34.jpg){kind=link}
{kind=link}
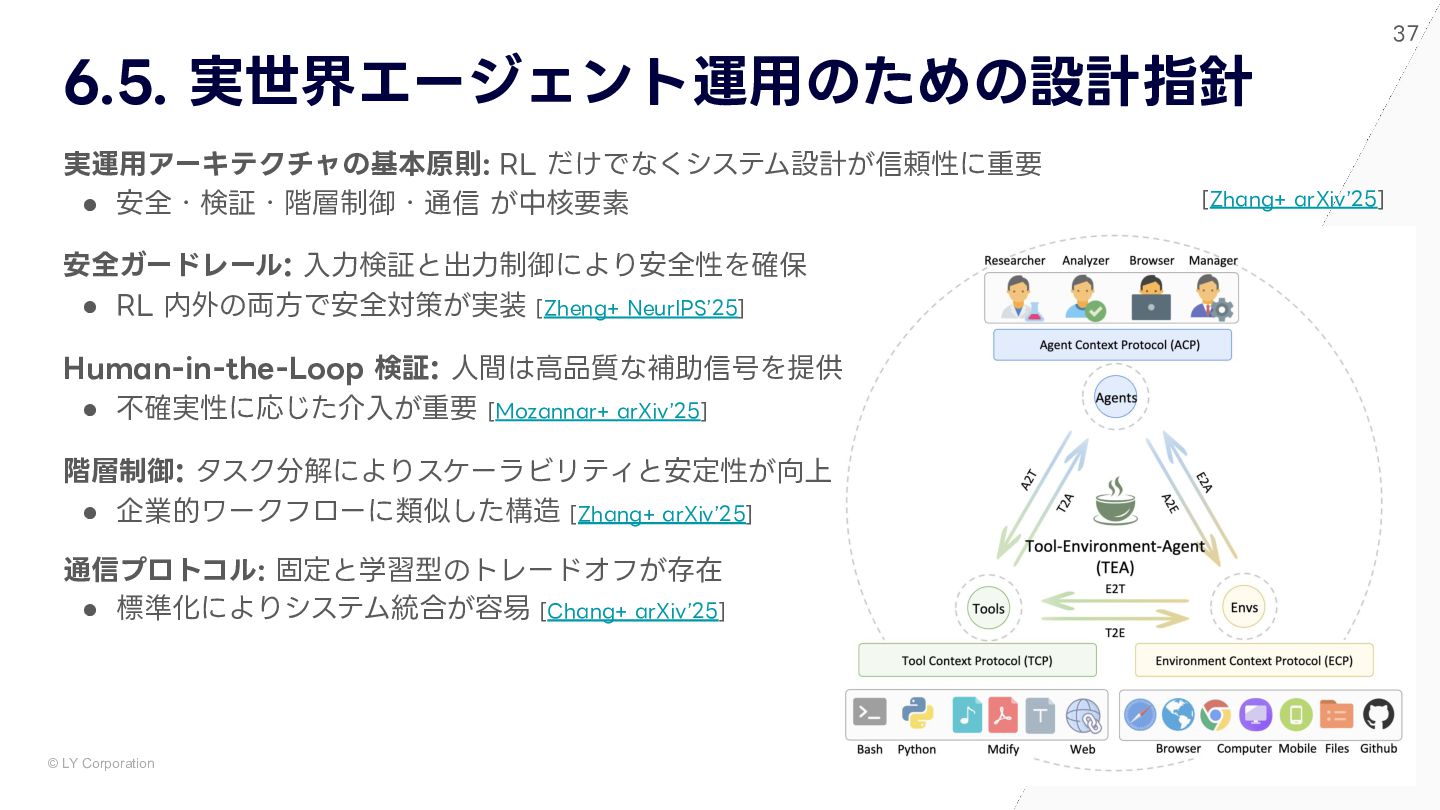{kind=link}
{kind=link}
![© LY Corporation 労働市場への影響 • エージェントは知識労働の⾃動化を加速する ◦ 特にビギナーな業務への影響が⼤きい [Eloundou+ arXivʼ23]](https://files.speakerdeck.com/presentations/538096fe8d70456a8b7164c40e4a4c90/slide_38.jpg){kind=link}
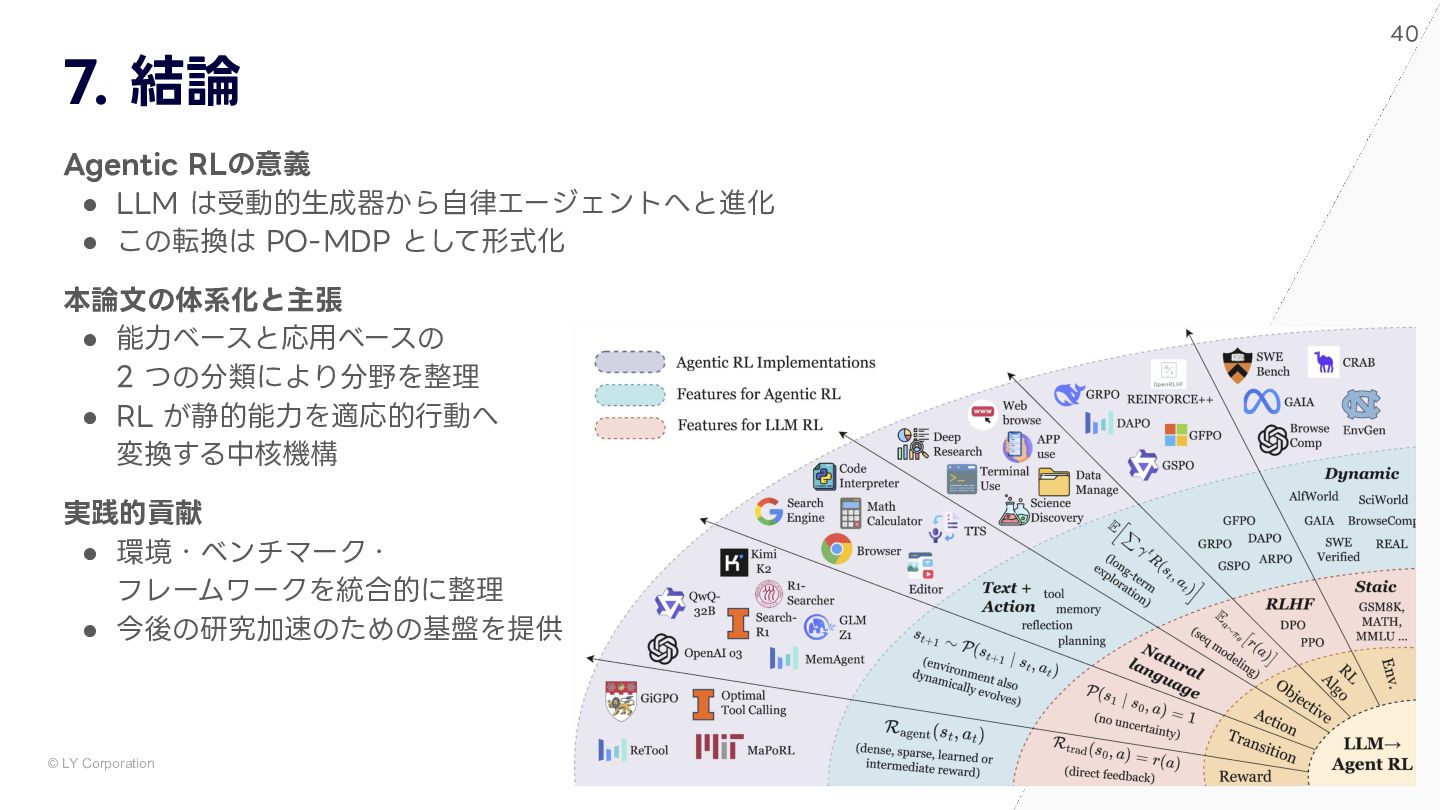{kind=link}