AI技術はグラフィックデザインの領域に革命をもたらし、クリエイティブなプロセスを根本から変えようとしています。かつてはタイポグラフィやレイアウトなど個々の要素を扱う断片的な研究が主流でしたが、近年の大規模言語モデル(LLM)やマルチモーダル技術の進化は、デザイン全体を統合的に扱う新たな潮流を生み出しています。
本発表では、この急速に進化するAI駆動グラフィックデザイン(AIGD)の全貌を、最新の包括的サーベイ論文「From Fragment to One Piece: A Survey on AI-Driven Graphic Design (Zou et al. - 2025)」 に基づき詳細に解説します。
- 📝:https://arxiv.org/abs/2507.17202
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
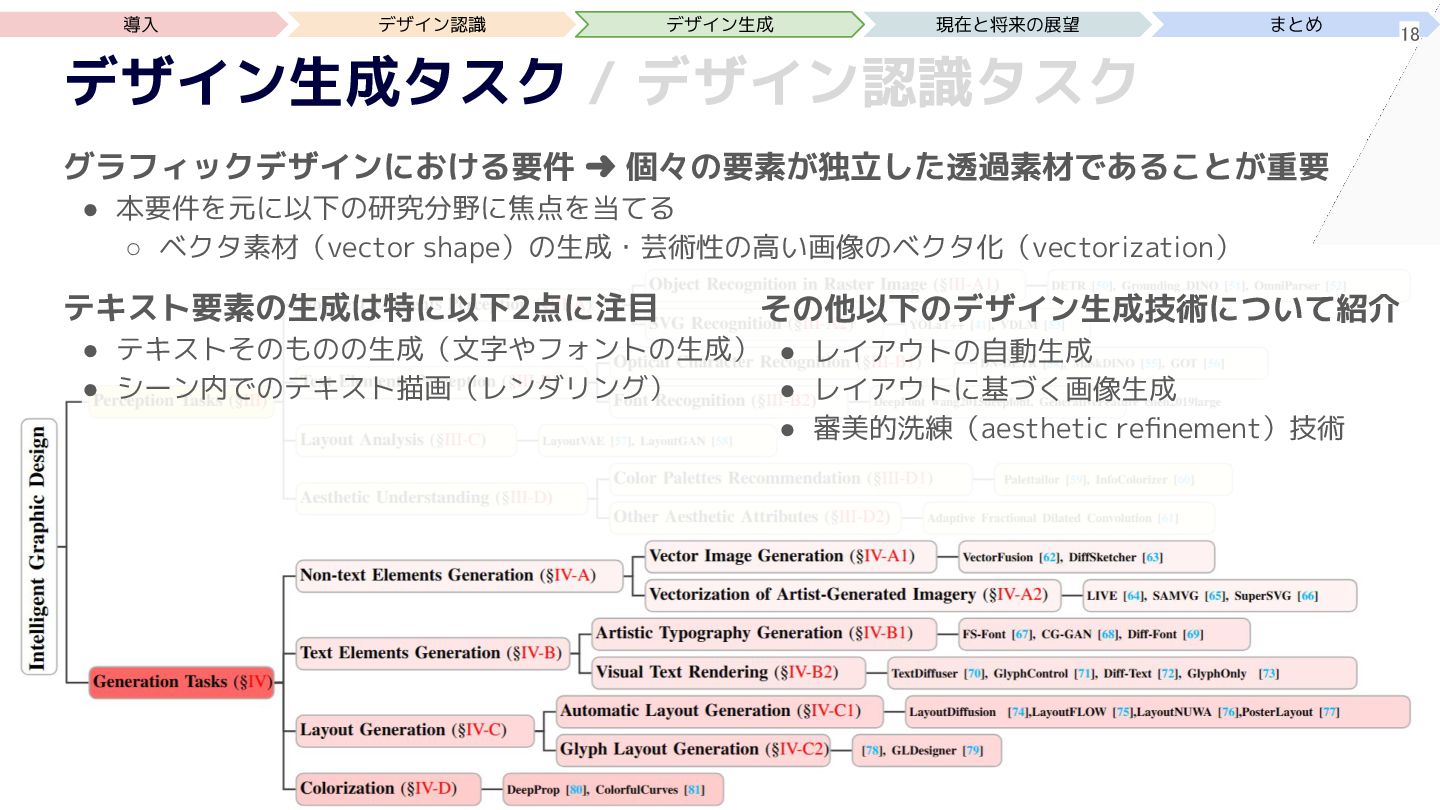{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
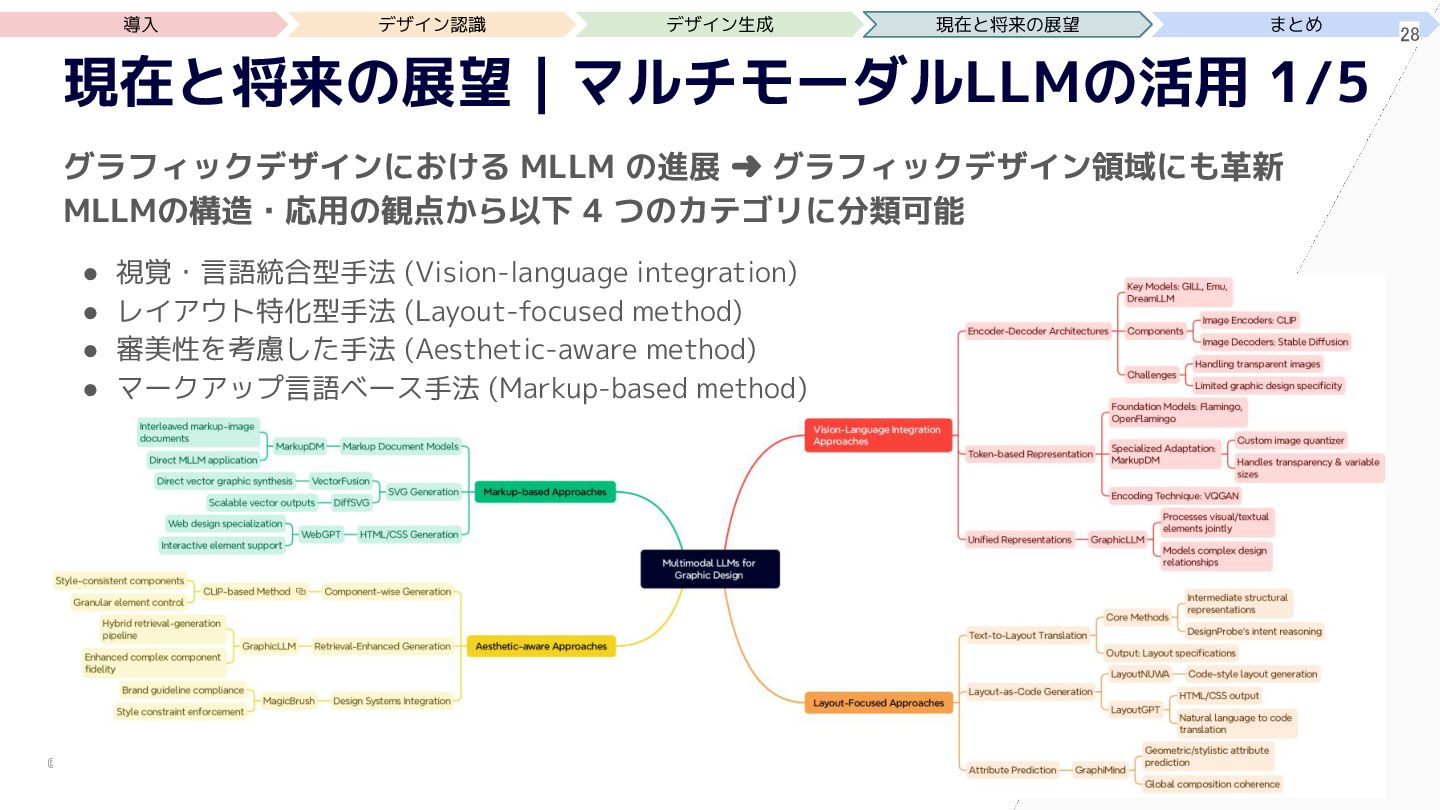{kind=link}
{kind=link}
{kind=link}
{kind=link}
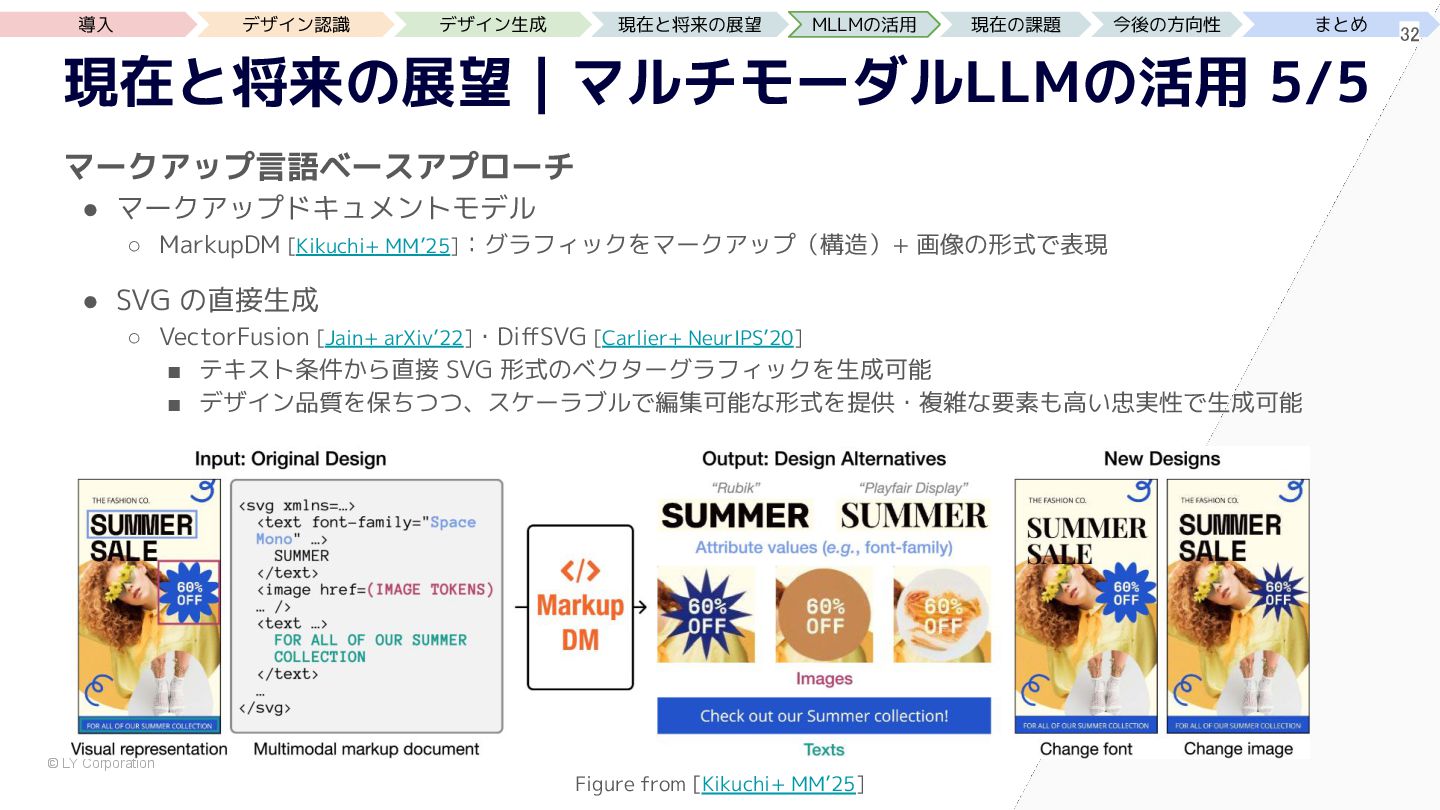{kind=link}
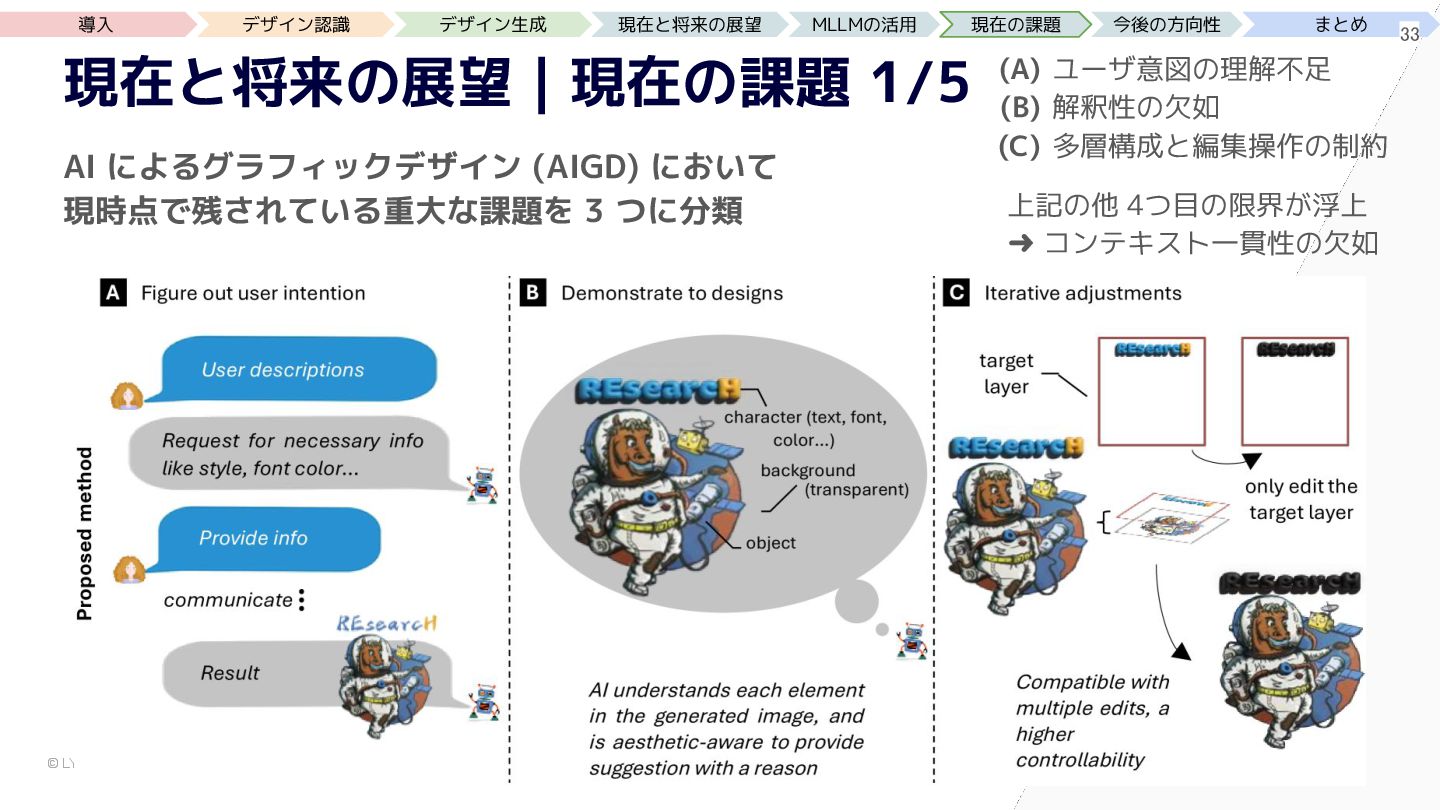{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
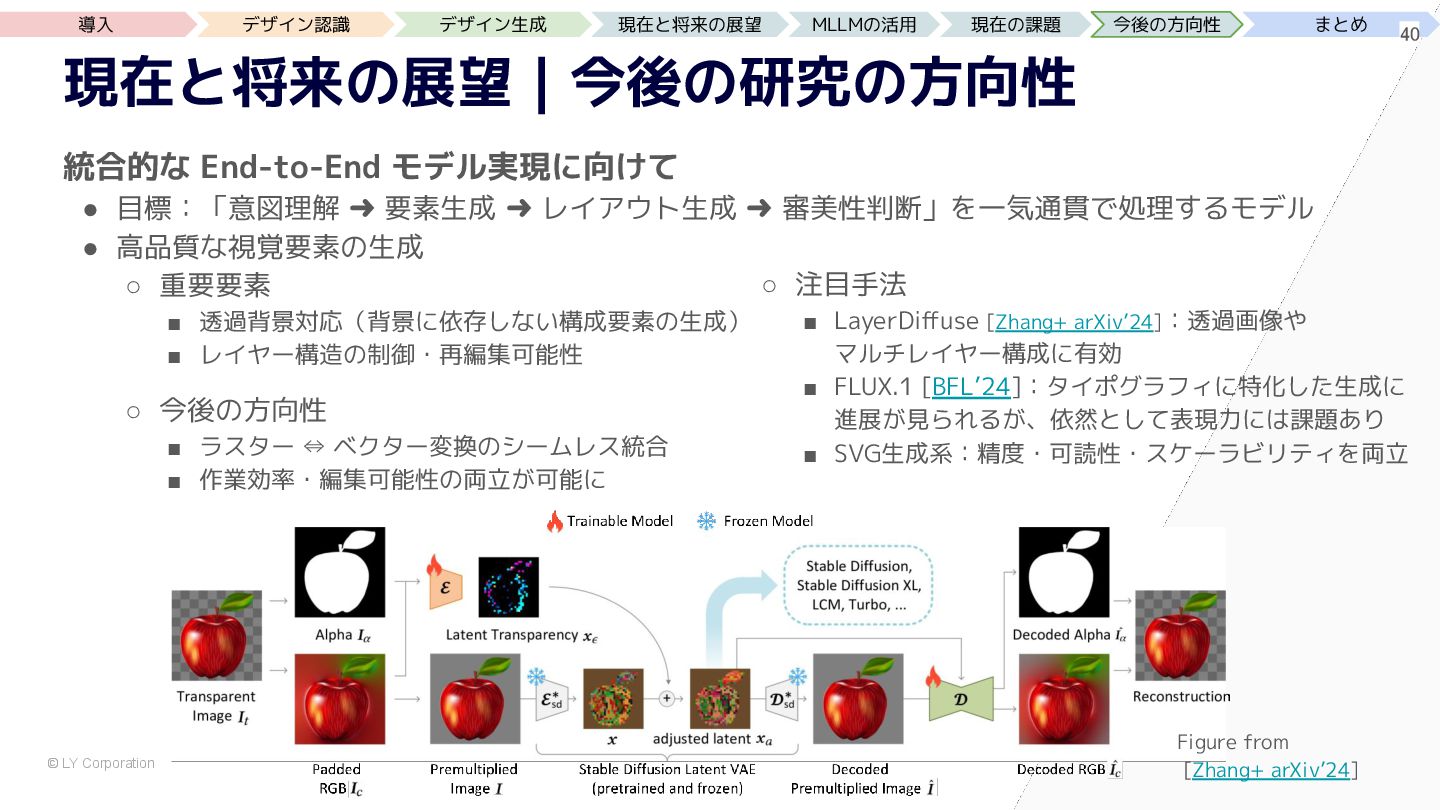{kind=link}
{kind=link}
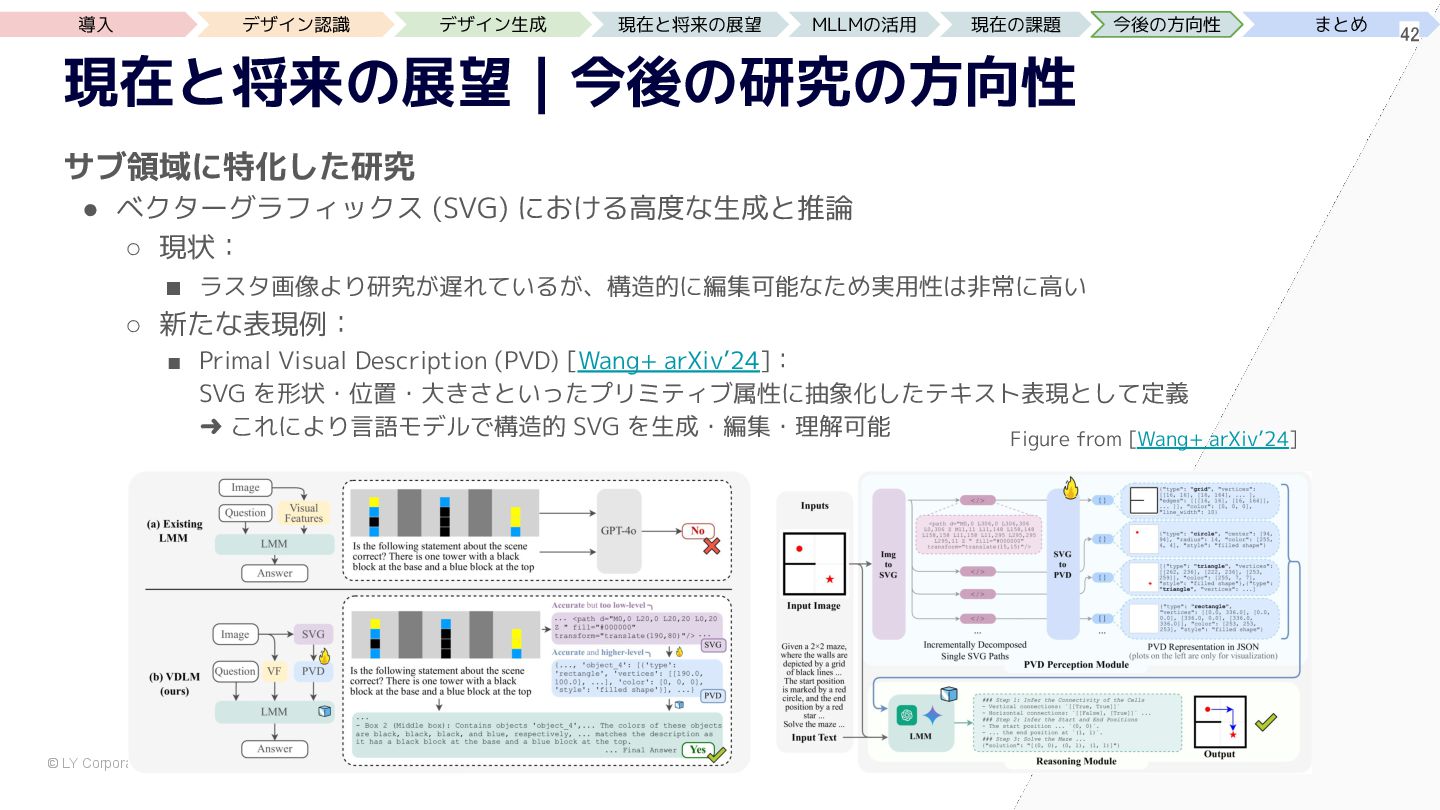{kind=link}
{kind=link}